机器视觉:Swin Transformer 深度解读
Swin Transformer通过分层特征表示和移位窗口自注意力,有效解决了ViT的高计算复杂度和单分辨率特征图问题。其核心创新包括:1)采用类似CNN的多尺度特征构建方式,通过补丁合并实现分层特征输出;2)设计移位窗口自注意力机制,在局部窗口内计算自注意力以降低复杂度,并通过窗口移位建立跨窗口连接。这些改进使Swin Transformer成为首个能同时适配分类、检测和分割任务的通用视觉Tra
文章目录
1. 引言:视觉Backbone的演进与ViT的困境
在计算机视觉领域,卷积神经网络(CNN)长期占据统治地位——从AlexNet的横空出世,到ResNet、EfficientNet等架构的持续优化,CNN凭借局部感受野、权重共享等特性,在图像分类、检测、分割等任务中展现出强大的适配性。但随着自然语言处理(NLP)领域Transformer的爆发,研究者们开始探索将这种“注意力即一切”的架构迁移到视觉领域,核心代表便是Vision Transformer(ViT)。上一篇博客中详细介绍了Vision Transformer的提出以及原理,还不了解的可以看一下:机器视觉:Vision Transformer——打破CNN垄断的视觉革命先锋
ViT的核心思路是将图像分割为固定大小的补丁(Patch),视为“视觉token”后直接输入Transformer编码器,通过全局自注意力建模token间依赖。这一突破证明了Transformer在视觉任务中的潜力,但它存在两个致命缺陷,导致难以成为通用视觉Backbone:
- 单分辨率特征图:ViT仅输出单一低分辨率特征图,无法适配目标检测、语义分割等需要多尺度特征的密集预测任务(这类任务依赖FPN、U-Net等多尺度融合结构);
- 二次计算复杂度:全局自注意力的计算量与token数量(图像分辨率)的平方成正比,面对高分辨率图像(如512×512)时,计算开销会急剧膨胀,无法落地应用。
正是为了解决这两个核心问题,微软亚洲研究院提出了Swin Transformer——一种基于“移位窗口”的分层视觉Transformer,它既保留了Transformer的全局建模能力,又具备CNN的分层特征和高效计算特性,最终成为首个能无缝适配分类、检测、分割等全场景视觉任务的Transformer Backbone。
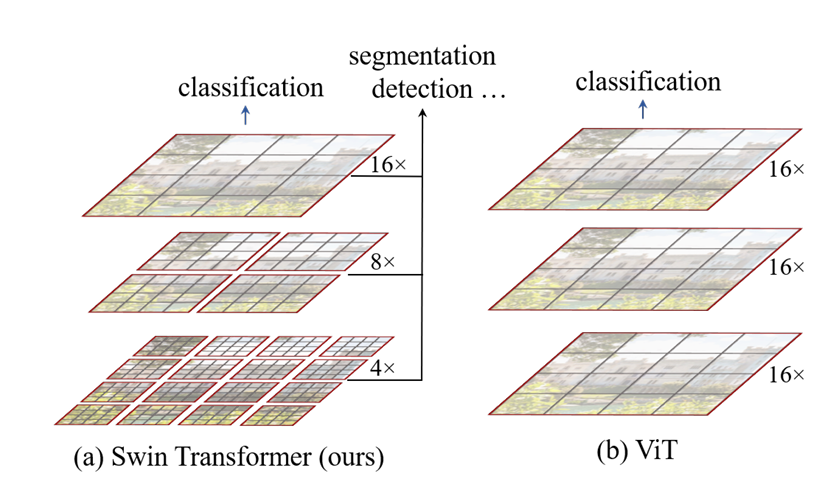
(a) 所提 Swin Transformer 通过在深层合并图像块(灰色所示)构建分层特征图,且因仅在各局部窗口(红色所示)内计算自注意力,其计算复杂度与输入图像尺寸呈线性关系,因此可作为适用于图像分类和密集型识别任务的通用骨干网络。(b) 相比之下,早期视觉 Transformer [20] 仅生成单一低分辨率特征图,且由于需计算全局自注意力,其计算复杂度与输入图像尺寸呈二次关系
2. 核心创新点总览
Swin Transformer的成功源于两个革命性设计,再加上细节优化,共同实现了“高效+通用”的目标:
- 分层特征表示(Hierarchical Feature Maps):模仿CNN的多尺度特征构建方式,通过“补丁合并”(Patch Merging)逐步减少token数量、提升特征维度,输出与CNN一致的多分辨率特征图(1/4、1/8、1/16、1/32下采样率),完美适配密集预测任务;
- 移位窗口自注意力(Shifted Window Self-Attention):将自注意力的计算限制在局部非重叠窗口内(降低复杂度),同时通过窗口移位建立跨窗口连接(保证建模能力),实现“线性复杂度+全局依赖建模”的平衡;
- 细节优化:相对位置偏置(提升空间建模精度)、循环移位+掩码(高效处理移位窗口)等,进一步强化性能与效率。
3. 原理详解:一步步拆解Swin Transformer
3.1 整体架构:分层特征的构建逻辑
Swin Transformer的整体架构与CNN类似,通过4个Stage逐步构建分层特征,每个Stage包含“补丁合并”(仅前3个Stage有)和“多个Swin Transformer Block”。以基础版Swin-T(Tiny)为例,架构流程如下: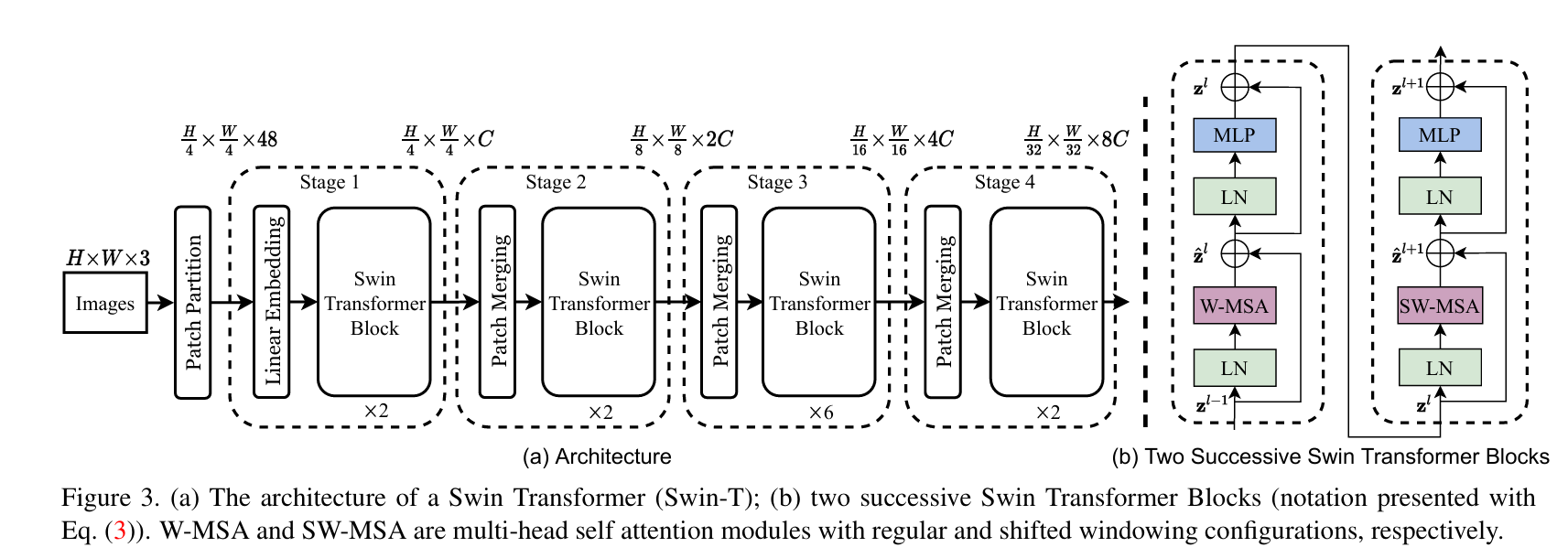
(a)展示从输入图像到4个Stage的特征演变;(b)展示W-MSA(常规窗口注意力)和SW-MSA(移位窗口注意力)的交替使用。
第一步:输入处理与Patch Embedding
- Patch Partition(补丁划分):将输入RGB图像(如224×224×3)划分为非重叠的4×4补丁(Patch)。每个补丁包含4×4×3=48个像素值,整个图像会被划分为(224/4)×(224/4)=56×56个补丁,即56×56个“视觉token”;
- Linear Embedding(线性嵌入):通过一个线性层将每个48维的补丁特征映射到指定维度C(Swin-T中C=96),最终得到56×56×96的特征图。这一步对应ViT的Patch Embedding,但Swin的补丁更小(4×4 vs ViT的16×16),为后续分层特征奠定基础。
第二步:Stage 1~4:分层特征的递进
Swin的4个Stage逐步降低特征图分辨率、提升特征维度,过程如下:
| Stage | 核心操作 | 输入特征 | 输出特征 | 作用 |
|---|---|---|---|---|
| 1 | 2个Swin Block | 56×56×96 | 56×56×96 | 初步特征提取,无下采样 |
| 2 | Patch Merging + 2个Swin Block | 56×56×96 | 28×28×192 | 下采样2倍,特征维度翻倍 |
| 3 | Patch Merging + 6个Swin Block | 28×28×192 | 14×14×384 | 下采样2倍,特征维度翻倍 |
| 4 | Patch Merging + 2个Swin Block | 14×14×384 | 7×7×768 | 下采样2倍,特征维度翻倍 |
关键模块解释:
- Patch Merging(补丁合并):实现下采样的核心操作。将2×2相邻的4个补丁的特征拼接(如56×56×96 → 28×28×(96×4)),再通过一个线性层将维度减半(96×4 → 192),最终得到28×28×192的特征图。这一步既减少了token数量(4倍减少),又提升了特征的感受野;
- Swin Transformer Block:每个Block是特征变换的核心,结构为“LN → 注意力模块 → 残差连接 → LN → MLP → 残差连接”。与标准Transformer Block的区别在于:注意力模块交替使用W-MSA(常规窗口注意力) 和SW-MSA(移位窗口注意力)(如上图(b)所示),通过这种交替建立跨窗口连接。
3.2 核心:移位窗口自注意力(SW-MSA)
这是Swin Transformer最具创新性的部分,直接解决了ViT的“复杂度高”和“无跨窗口连接”两大问题。我们分5步拆解其设计逻辑:
第一步:为什么要“局部窗口”?—— 复杂度的降维打击
全局自注意力的计算复杂度是ViT的致命伤,其公式为:
Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C \Omega(MSA) = 4hwC^2 + 2(hw)^2C Ω(MSA)=4hwC2+2(hw)2C
其中, h w hw hw是token数量(如56×56=3136), C C C 是特征维度。可以看到,复杂度与 (hw) 的平方成正比(二次复杂度)——当图像分辨率提升到512×512时,(hw=128×128=16384),((hw)^2) 会达到2.68亿,计算量完全无法承受。
Swin的解决方案是局部窗口注意力(W-MSA):将特征图划分为非重叠的局部窗口,仅在每个窗口内计算自注意力。假设窗口大小为 M × M M×M M×M(默认M=7),则每个窗口包含 M 2 M^2 M2 个token,复杂度公式变为:
Ω ( W − M S A ) = 4 h w C 2 + 2 M 2 h w C \Omega(W-MSA) = 4hwC^2 + 2M^2hwC Ω(W−MSA)=4hwC2+2M2hwC
此时,复杂度与 h w hw hw成正比(线性复杂度)——因为 M M M 是固定值(如7), M 2 = 49 M^2=49 M2=49是常数。同样以512×512图像为例,计算量会从“亿级”降至“百万级”,效率提升显著。
第二步:常规窗口的问题——缺乏跨窗口连接
局部窗口虽然高效,但窗口间是孤立的——一个窗口内的token无法与其他窗口的token建立注意力连接,导致模型难以建模长距离依赖(比如图像中跨窗口的物体),建模能力受限。
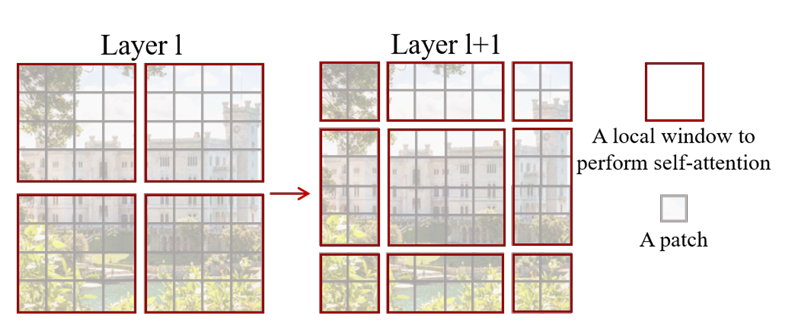
第三步:移位窗口(SW-MSA)—— 建立跨窗口连接
为了解决窗口孤立问题,Swin提出“移位窗口”策略:在连续的Swin Block中,交替使用“常规窗口”和“移位窗口”。具体操作是:
- 第l层Block使用常规窗口(W-MSA):窗口从特征图左上角开始,均匀划分;
- 第l+1层Block使用移位窗口(SW-MSA):将窗口沿x轴和y轴各移位 ⌊ M / 2 ⌋ \lfloor M/2 \rfloor ⌊M/2⌋个像素(如M=7时移位3个像素)。
移位后,新窗口会跨越原窗口的边界,自然建立起不同窗口间的token连接。例如,原窗口A和窗口B的边界token,在移位后的窗口中会被划入同一个窗口,从而实现注意力交互。
第四步:高效批量计算——循环移位+掩码
移位窗口虽然解决了连接问题,但会带来新的麻烦:移位后窗口数量会增加,且部分窗口会小于 M × M M×M M×M(比如特征图边缘的窗口)。以8×8特征图、M=4为例:
- 常规窗口:(8/4)×(8/4)=2×2=4个窗口(均为4×4);
- 移位窗口:(8/4 +1)×(8/4 +1)=3×3=9个窗口(边缘窗口为2×2)。
如果直接对9个窗口计算注意力,会产生大量小窗口,导致计算效率低、内存访问碎片化。Swin提出“循环移位(Cyclic Shift)+ 掩码(Masking)”的高效解决方案,步骤如下: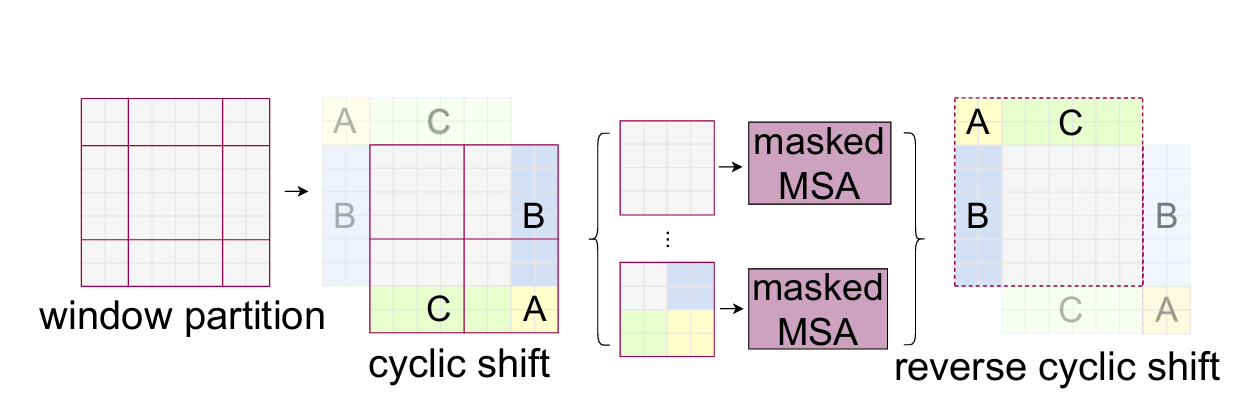
展示如何通过循环移位将小窗口拼接为完整窗口,再通过掩码屏蔽无效注意力。
- 循环移位:将特征图沿x轴和y轴循环移位 ⌊ M / 2 ⌋ \lfloor M/2 \rfloor ⌊M/2⌋ 个像素,原本分散在边缘的小窗口会被拼接成完整的 (M×M) 窗口;
- 合并窗口:拼接后,窗口数量恢复为常规窗口的数量(如2×2=4个),可批量计算注意力;
- 掩码屏蔽:由于循环移位后,部分窗口内的token来自原特征图的不同区域(并非真实相邻),需要用一个二进制掩码屏蔽这些“无效连接”——让这些token间的注意力权重为-∞(SoftMax后接近0),避免虚假依赖;
- 反向循环移位:注意力计算完成后,将特征图反向循环移位,恢复到原始位置。
通过这四步,既能保证跨窗口连接,又能维持与常规窗口相同的计算效率,完美解决了移位窗口的工程实现问题。
第五步:相对位置偏置——提升空间建模精度
自注意力机制本身是“位置无关”的——它只关注token间的内容相似性,不考虑空间位置关系。ViT通过添加“绝对位置嵌入”解决这一问题,但绝对位置嵌入存在两个缺陷:
- 缺乏平移不变性:训练时学到的“位置1”的嵌入,无法泛化到其他位置;
- 不适配不同窗口大小:如果微调时改变窗口大小,预训练的绝对位置嵌入会失效。
Swin提出相对位置偏置(Relative Position Bias),直接建模窗口内token的相对位置关系。具体设计如下:
- 在自注意力计算中加入偏置项 (B),公式为:
A t t e n t i o n ( Q , K , V ) = S o f t M a x ( Q K T d + B ) V Attention(Q, K, V) = SoftMax\left( \frac{QK^T}{\sqrt{d}} + B \right) V Attention(Q,K,V)=SoftMax(dQKT+B)V
其中, B ∈ R M 2 × M 2 B \in \mathbb{R}^{M^2 \times M^2} B∈RM2×M2 是相对位置偏置矩阵, M 2 M^2 M2 是窗口内token的数量(如M=7时为49); - 参数高效化:由于token的相对位置范围是 [ − M + 1 , M − 1 ] [-M+1, M-1] [−M+1,M−1](如M=7时,x轴相对位置为-6~6),无需为 M 2 × M 2 M^2×M^2 M2×M2个位置对都分配参数,只需参数化一个更小的矩阵 B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat{B} \in \mathbb{R}^{(2M-1) \times (2M-1)} B^∈R(2M−1)×(2M−1)(如M=7时为13×13),再通过索引映射得到 (B);
- 泛化性:预训练的 B ^ \hat{B} B^可通过双三次插值适配不同窗口大小,无需重新训练。
论文的消融实验证明,相对位置偏置能显著提升性能——在ADE20K分割任务中,相比无偏置的版本,mIoU提升2.3%。
3.3 架构变体:适配不同场景需求
Swin Transformer提供了4种架构变体,通过调整“初始特征维度C”和“各Stage的Block数量”,平衡性能与计算开销:
| 变体 | 初始维度C | 各Stage Block数量 | 参数量 | 适用场景 |
|---|---|---|---|---|
| Swin-T | 96 | [2, 2, 6, 2] | 29M | 轻量场景、边缘设备 |
| Swin-S | 96 | [2, 2, 18, 2] | 50M | 平衡性能与效率 |
| Swin-B | 128 | [2, 2, 18, 2] | 88M | 基准模型、大部分场景 |
| Swin-L | 192 | [2, 2, 18, 2] | 197M | 高精度场景、大模型需求 |
这些变体的复杂度与ResNet系列对应:Swin-T≈ResNet-50,Swin-S≈ResNet-101,方便开发者直接替换现有CNN Backbone。
4. 实验验证:Swin的性能碾压级表现
Swin Transformer在图像分类、目标检测、语义分割三大核心任务中均超越当时的SOTA模型,充分证明了其“通用Backbone”的能力。
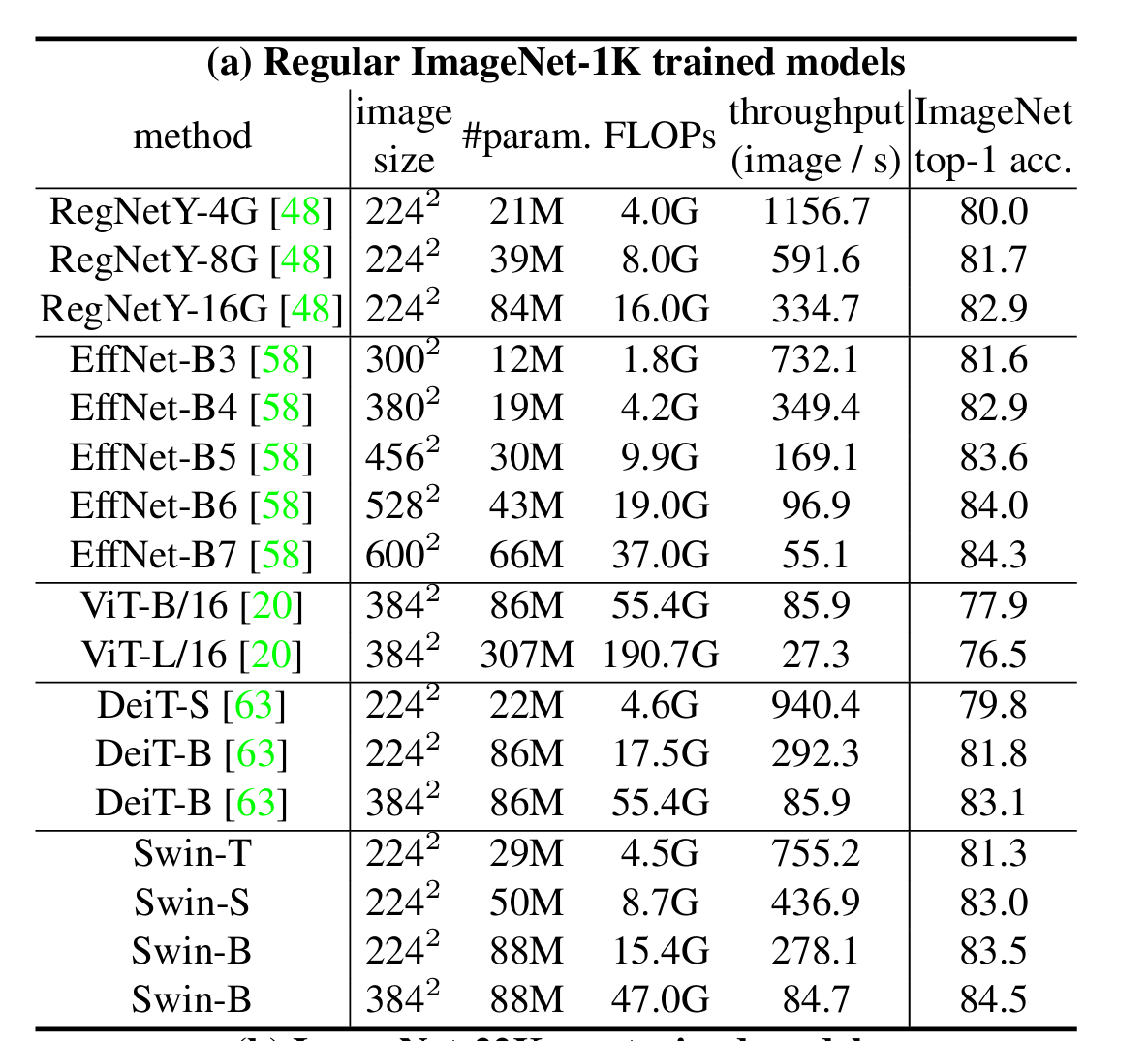
4.1 图像分类(ImageNet-1K)
- 最高性能:Swin-L(ImageNet-22K预训练)在384×384输入下达到87.3% top-1准确率,超越ViT-L(85.2%)和EfficientNet-B7(84.3%);
- 效率优势:相同复杂度下,Swin-T(81.3%)优于DeiT-S(79.8%),Swin-B(84.5%)优于DeiT-B(83.1%)。
- 常规训练结果;
- ImageNet-22K预训练结果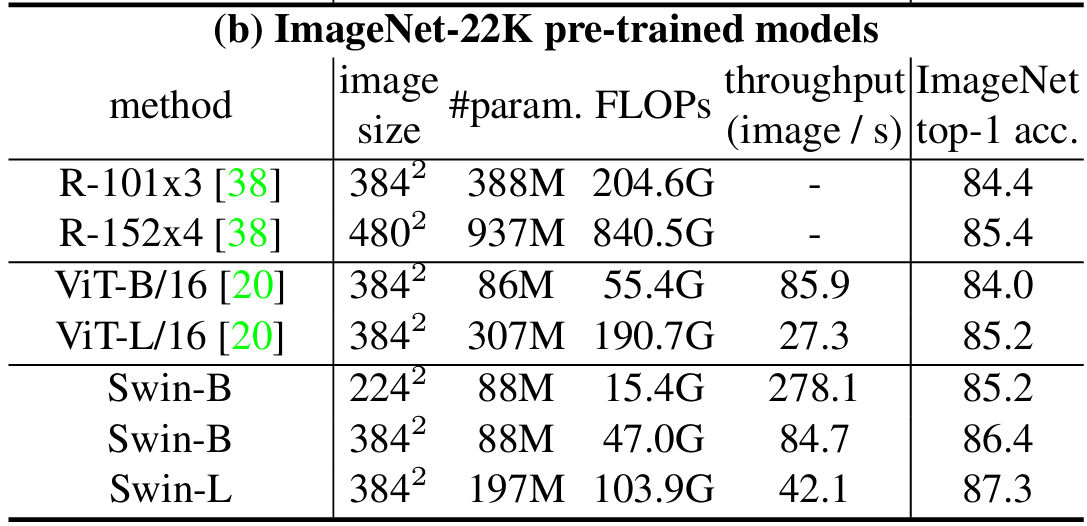
4.2 目标检测与实例分割(COCO)
- 检测性能:Swin-L + HTC++框架在COCO test-dev集上达到58.7 box AP、51.1 mask AP,超越此前SOTA(Copy-paste的56.0 box AP、DetectoRS的48.5 mask AP);
- 对比ResNet:相同框架下,Swin-T(50.5 box AP)比ResNet-50(46.3 box AP)提升4.2 AP,且参数量相近。
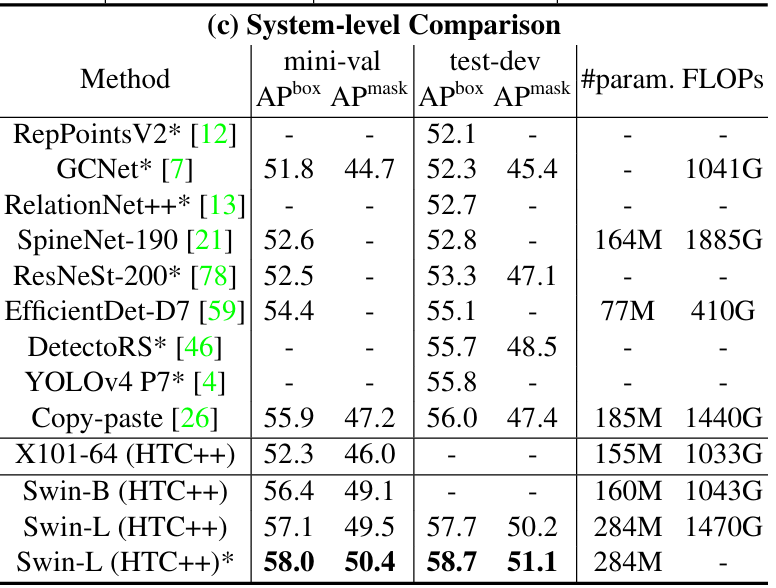
展示Swin在COCO检测任务上的SOTA表现
4.3 语义分割(ADE20K)
- 分割性能:Swin-L + UperNet在ADE20K val集上达到53.5 mIoU,超越SETR(50.3 mIoU)+3.2 mIoU;
- 对比DeiT:Swin-S(49.3 mIoU)比DeiT-S(44.0 mIoU)提升5.3 mIoU,计算开销相近。
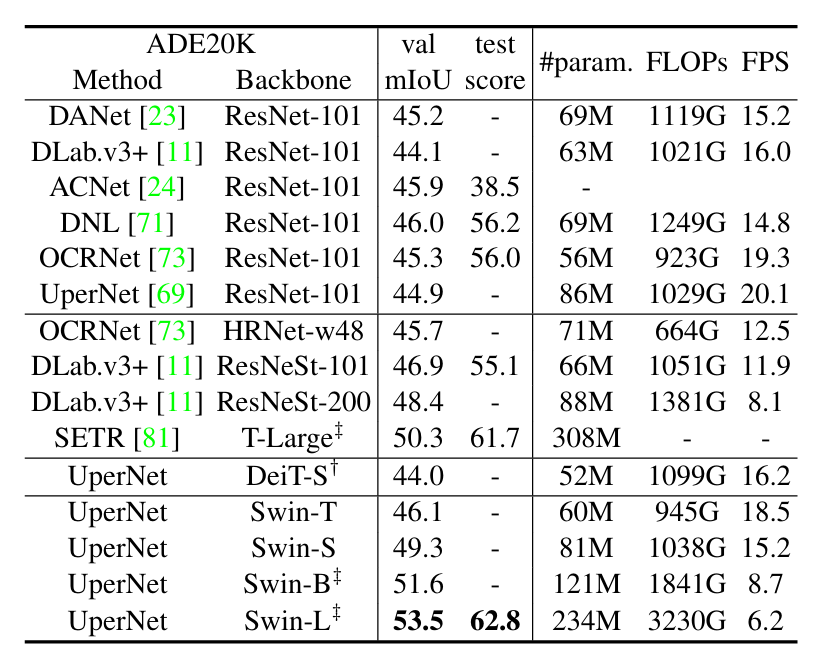
4.4 消融实验:核心设计的有效性验证
论文通过消融实验验证了关键设计的必要性(以Swin-T为例):
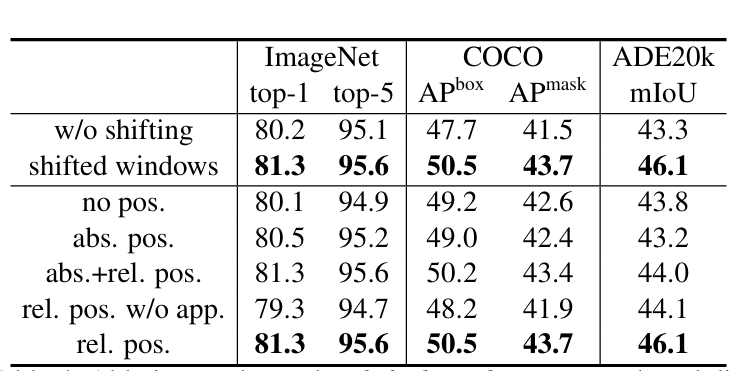
- 移位窗口:无移位时(仅用W-MSA),ImageNet top-1下降1.1%,COCO box AP下降2.8%,证明跨窗口连接的重要性;
- 相对位置偏置:无偏置时,ADE20K mIoU下降2.3%;使用绝对位置嵌入时,检测/分割性能反而下降,证明相对位置偏置更适配视觉任务;
- 循环移位优化:相比直接padding小窗口,循环移位+掩码使推理速度提升13%~18%,且性能无损。
5. 总结与展望
5.1 核心贡献
Swin Transformer的最大贡献是首次实现了Transformer在视觉任务中的“通用性”——它通过分层特征解决了密集预测适配问题,通过移位窗口解决了效率问题,最终让Transformer像CNN一样成为视觉任务的通用Backbone。具体贡献可概括为:
- 提出分层特征表示,适配分类、检测、分割等全场景视觉任务;
- 创新移位窗口自注意力,平衡线性计算复杂度与全局依赖建模能力;
- 设计相对位置偏置,提升空间建模精度与泛化性;
- 验证了Vision与NLP统一架构的可行性,为跨模态建模(如图文生成)奠定基础。
5.2 未来方向
Swin Transformer的设计思路已成为后续视觉Transformer的重要参考,未来可探索的方向包括:
- 窗口大小自适应:根据图像内容动态调整窗口大小(如前景区域用小窗口、背景区域用大窗口),进一步提升效率;
- 更高效的移位策略:简化循环移位+掩码的实现,降低硬件 latency;
- 轻量化优化:针对移动设备,设计更轻量的架构变体(如更小的C和窗口大小)。
6. 资源获取
- 官方代码:https://github.com/microsoft/Swin-Transformer(支持PyTorch,包含分类、检测、分割全场景实现);
- 预训练模型:提供ImageNet-1K/22K预训练权重,可直接用于下游任务微调;
- 配套工具:兼容MMDetection、MMSegmentation等主流视觉框架,替换Backbone即可使用。
Swin Transformer的出现,标志着视觉领域正式进入“CNN与Transformer并存”的时代。它不仅在性能上碾压传统CNN,更在架构上打通了视觉与NLP的壁垒——未来,我们可能会看到更多基于Transformer的统一架构,实现“一张网络搞定所有模态任务”的目标。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)