手把手实战:零基础教程!LLaMA-Factory微调Qwen2-VL
具体实现过程看以下实战步骤。LLaMA-Factory微调Qwen2-VL实战步骤1、部署环境1)点击LLaMA-Factory镜像,准备开始部署2)点击配置&部署按钮3)填写自定义集群信息—>点击部署按钮4)部署完成之后,选择Notes.txt 显示登录地址5)设置微调参数最后参数会生成相关命令:以下是本次训练的核心参数与说明:为了让模型更贴近文旅领域的真实应用场景,本次微调采用了名为的图文对话
你是否想过,借助一张图片、几段文字,就能让 AI 帮你生成详尽的景区讲解词?能在文旅服务中做到“图文并茂”、智能交互?这不再是梦想。今天,我们就通过 LLaMA-Factory + Qwen2-VL,带你一步步构建一个面向文旅行业的 大模型助手。

背景介绍:Qwen2-VL 与 LLaMA-Factory
Qwen2-VL-2B-Instruct 是阿里推出的小体量多模态语言模型,支持图文联合理解,适用于问答、描述生成、图像理解等任务。由于其开放权重、较低算力门槛,非常适合领域微调。
LLaMA-Factory 是一款开源的大模型微调框架,专为简化 LLM 的微调流程而设计。它支持包括 LLaMA、Qwen、Baichuan、ChatGLM 等众多主流模型,通过统一的接口和高效的微调策略,让你只需几行命令,即可完成指令微调(SFT)、LoRA 参数高效微调、推理部署等全流程操作。
无论你是研究人员、开发者,还是企业级应用构建者,LLaMA-Factory 都能帮助你:
-
快速启动模型微调
-
支持多种微调方法:全参数微调、LoRA、QLoRA 等
-
一键推理部署 Gradio 网页应用
-
支持 INT4、INT8 等量化部署优化
本文带大家构建一个输入景区图片+提示词,自动生成解说文案的多模态助手。我们一起先看下微调前和微调后的效果对比👇:
输入图片为:

微调前:
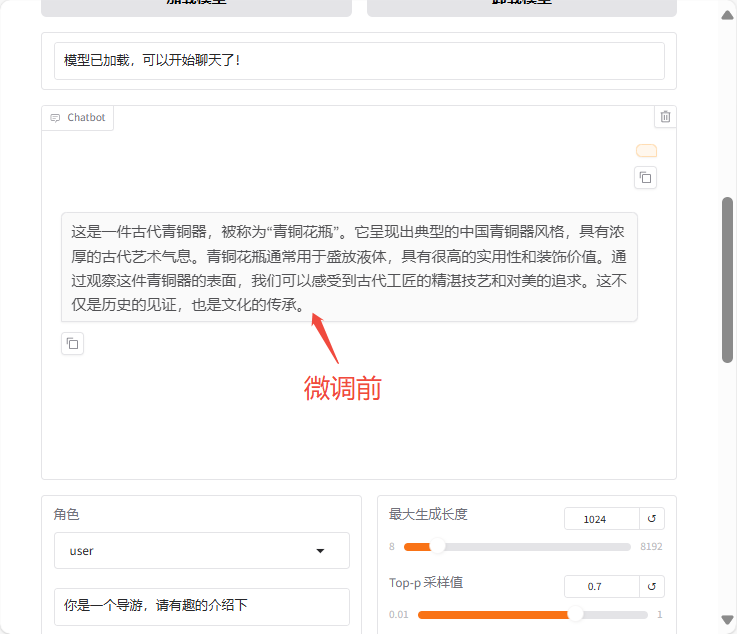
微调后:
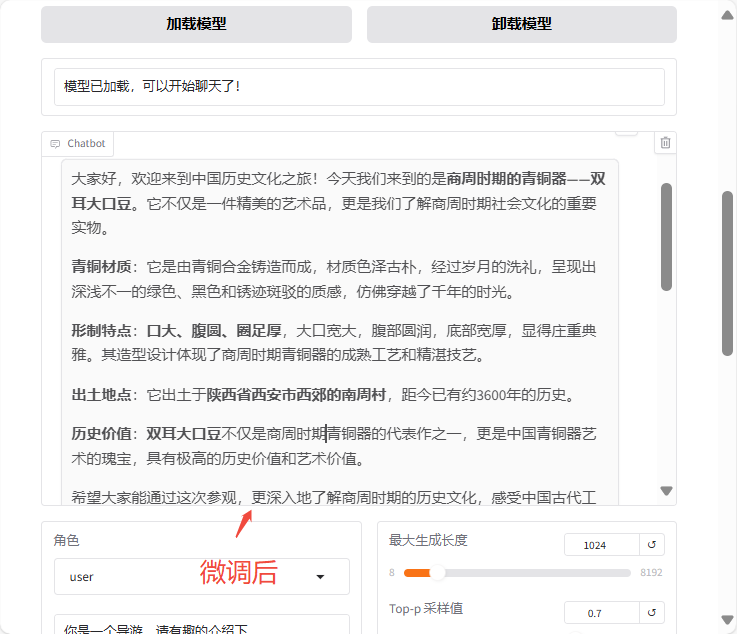
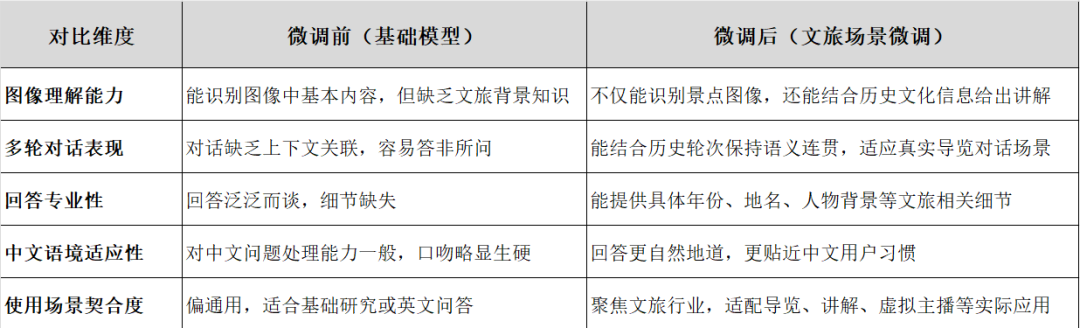
微调前 vs 微调后对比总结
具体实现过程看以下实战步骤。
LLaMA-Factory微调Qwen2-VL实战步骤
1、部署环境
1)点击LLaMA-Factory镜像,准备开始部署
2)点击配置&部署按钮
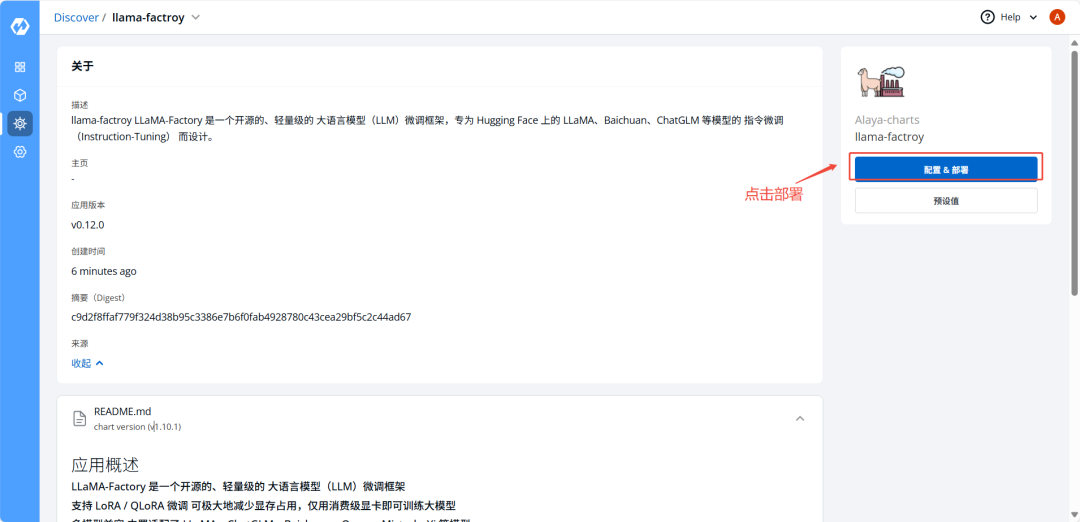
3)填写自定义集群信息—>点击部署按钮

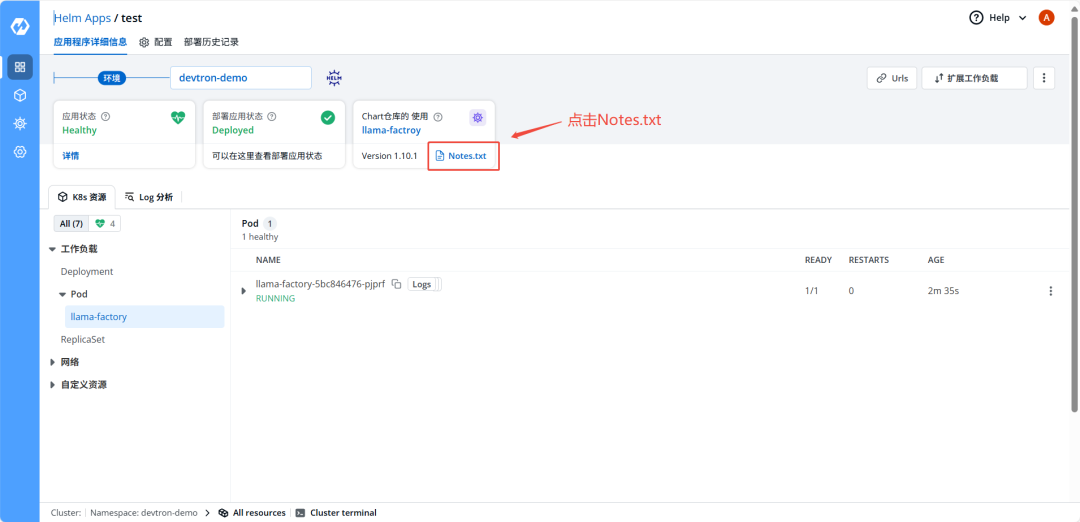
4)部署完成之后,选择Notes.txt 显示登录地址
5)设置微调参数
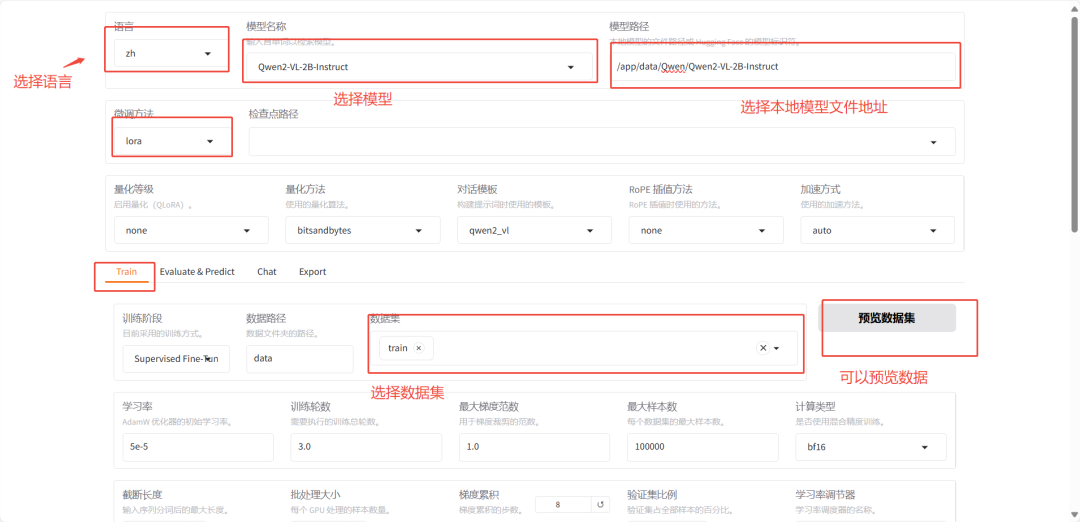
最后参数会生成相关命令:

以下是本次训练的核心参数与说明:

模型下载命令:
huggingface-cli download --resume-download Qwen/Qwen2-VL-2B-Instruct --local-dir /app/data/Qwen/Qwen2-VL-2B-Instruct为了让模型更贴近文旅领域的真实应用场景,本次微调采用了名为 Qwen2-VL-History 的图文对话数据集。该数据集由阿里达摩院团队开源发布。
微调数据集下载:
cd /app/datawget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/llama_factory/Qwen2-VL-History.zipunzip Qwen2-VL-History.zip
数据集内容结构:
该数据集经过精心设计,主要包含以下内容:
-
图像文件(JPG/PNG):多数为中国各地名胜古迹、博物馆展品、文化遗产等照片;
-
多轮对话 JSON 文件:每张图片配有多轮对话示例,模拟用户和导览AI之间的交流,例如:
-
用户提问:“图中这是什么建筑?”
-
AI 回答:“这是北京故宫太和殿,明清两代皇帝登基、举行大典的地方。”
-
-
每条对话条目包含字段:
-
image: 图像路径 -
conversations: 对话数组,包含角色(user/assistant)及内容 -
history: 上下文轮次的简要总结(用于对多轮对话建模)
-
该数据集由 阿里巴巴达摩院发布于其 ModelZoo 资源库,命名为 Qwen2-VL-History。数据内容涵盖图文对话、历史文化问答等任务,主要用于多模态语言模型在文旅领域的微调实验。
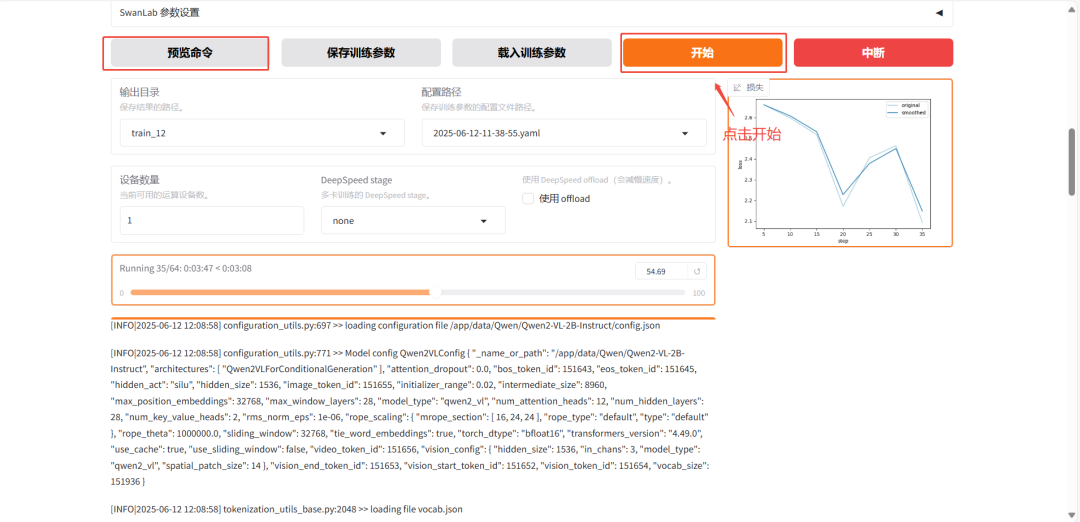
6)开始微调
7)微调完成之后,测试微调后的模型
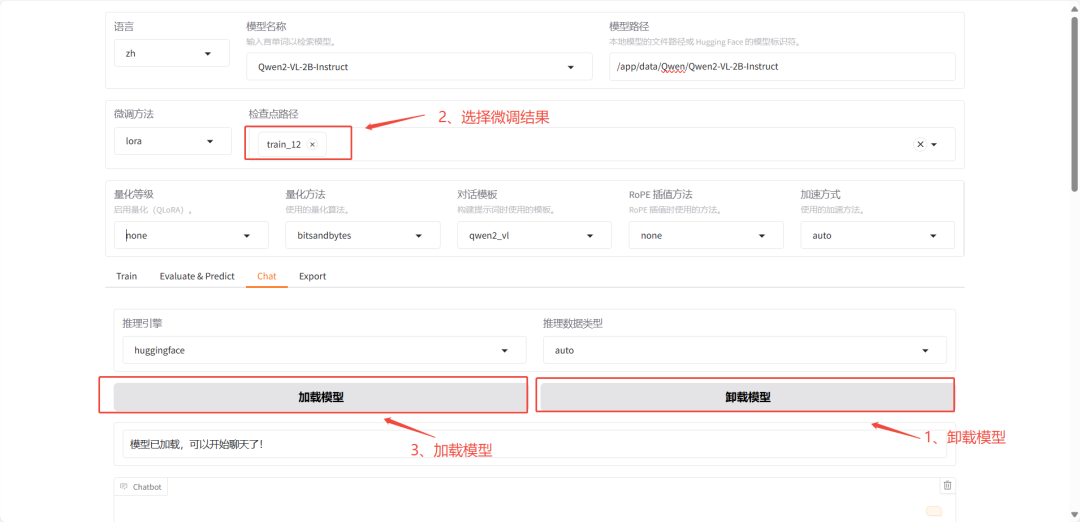
2、微调
1)点击开始 开始微调
2)微调完成之后,测试微调后的模型
3)测试微调模型
效果可以见文章开头部分,微调前后的对比。
LLaMA-Factory + Qwen2-VL 提供了一个极具性价比的多模态微调解决方案。只需少量数据和计算资源,就能快速打造一个实用的垂类图文 AI 助手。未来,随着文旅数字化的发展,这类技术将越来越多地落地于智慧景区、数字人导游等场景。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 16
16 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)