《从零构建大模型》系列(20):因果注意力——大语言模型的核心安全机制
因果注意力是确保语言模型生成连贯文本的关键技术,它通过掩码机制防止模型"作弊"访问未来信息。本文系统讲解了因果注意力的实现原理、PyTorch实现步骤,并对比了标准注意力与因果注意力的差异。重点内容包括:1) 基础实现类与设备感知技巧;2) 注意力Dropout的正则化作用;3) 批处理优化方法;4) 从可视化分析到实际文本生成应用;5) 高级变体如滑动窗口和分块注意力。文章还

目录
因果注意力赋予模型时间感知能力:就像人类写作时只能参考已写内容,本节将揭示因果注意力如何确保大语言模型在生成文本时不会"作弊"地看到未来信息,这是构建连贯、合理文本生成模型的关键技术。
一、为什么需要因果注意力?
1.1 文本生成的本质要求

核心问题:标准自注意力机制允许每个词元访问序列中所有位置的信息,包括未来的词元,这在文本生成中是不合理的。
1.2 信息泄露的风险
考虑生成句子:"猫坐在垫子上,因为它很___"
| 时间步 | 模型可见内容 | 合理预测 | 泄露风险 |
|---|---|---|---|
| t=0 | "猫" | "坐在" | 无 |
| t=1 | "猫坐在" | "垫子上" | 无 |
| t=2 | "猫坐在垫子上" | "," | 无 |
| t=3 | "猫坐在垫子上," | "因为" | 无 |
| t=4 | "猫坐在垫子上,因为" | "它" | 无 |
| t=5 | "猫坐在垫子上,因为它" | "很" | 无 |
| t=6 | "猫坐在垫子上,因为它很" | "柔软" | 如果模型能看到"柔软",预测就变成了作弊 |
二、因果注意力的实现原理
2.1 掩码机制详解
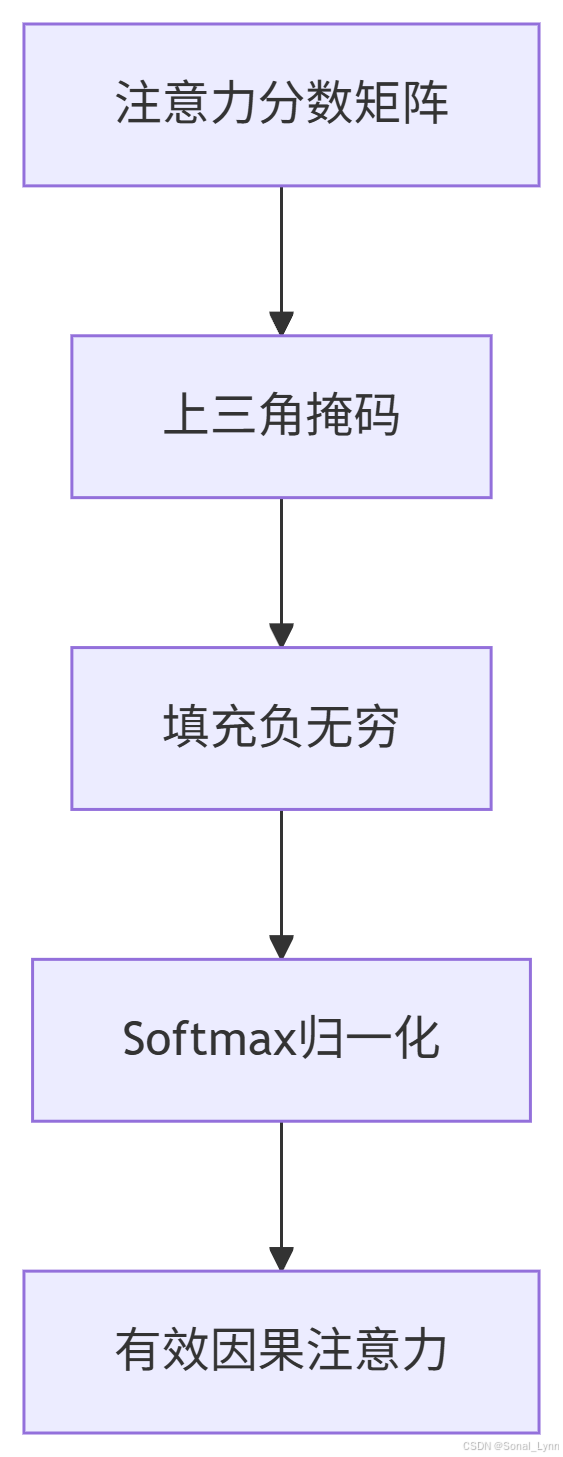
数学表示:
其中M是掩码矩阵:
2.2 PyTorch实现步骤
import torch
def causal_mask(seq_len):
"""创建因果掩码矩阵"""
return torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
# 示例:序列长度为4的掩码
mask = causal_mask(4)
print(mask)
"""
tensor([[False, True, True, True],
[False, False, True, True],
[False, False, False, True],
[False, False, False, False]])
"""三、完整因果注意力实现
3.1 基础因果注意力类
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, dropout_rate=0.1):
super().__init__()
self.d_out = d_out
# 可训练投影矩阵
self.W_q = nn.Linear(d_in, d_out)
self.W_k = nn.Linear(d_in, d_out)
self.W_v = nn.Linear(d_in, d_out)
# Dropout层
self.dropout = nn.Dropout(dropout_rate)
# 缓存因果掩码
self.register_buffer('mask', None)
def forward(self, x):
batch_size, seq_len, _ = x.shape
# 动态创建或复用掩码
if self.mask is None or self.mask.shape[0] != seq_len:
self.mask = causal_mask(seq_len).to(x.device)
# 计算Q, K, V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# 计算注意力分数
attn_scores = Q @ K.transpose(-2, -1) / (self.d_out ** 0.5)
# 应用因果掩码
masked_scores = attn_scores.masked_fill(self.mask, float('-inf'))
# Softmax归一化
attn_weights = torch.softmax(masked_scores, dim=-1)
# 应用Dropout
attn_weights = self.dropout(attn_weights)
# 计算上下文向量
context_vectors = attn_weights @ V
return context_vectors3.2 设备感知实现技巧
# 在forward方法中
device = x.device
if self.mask is None or self.mask.shape[0] != seq_len:
self.mask = causal_mask(seq_len).to(device)四、Dropout在注意力机制中的应用
4.1 为什么需要注意力Dropout?
| 问题 | 解决方案 | 效果 |
|---|---|---|
| 过拟合 | 注意力Dropout | 减少对特定注意模式的依赖 |
| 注意力崩溃 | 随机置零 | 鼓励探索不同注意模式 |
| 模型脆弱性 | 引入随机性 | 增强鲁棒性 |
4.2 Dropout实现细节
# 在forward方法中
attn_weights = torch.softmax(masked_scores, dim=-1)
attn_weights = self.dropout(attn_weights) # 关键步骤Dropout工作原理:
-
训练时:随机将部分注意力权重置零,并按1/(1-p)缩放其余权重
-
推理时:直接使用注意力权重(Dropout被禁用)
4.3 Dropout率选择策略
| 模型规模 | 推荐Dropout率 | 理由 |
|---|---|---|
| 小型模型 | 0.1-0.3 | 防止过拟合 |
| 中型模型 | 0.05-0.2 | 平衡正则化与容量 |
| 大型模型 | 0.0-0.1 | 数据量充足,减少正则化 |
| 超大型模型 | 0.0 | 最大化模型容量 |
五、批处理支持与优化
5.1 批处理实现
# 输入形状: [batch_size, seq_len, d_in]
inputs = torch.tensor([
# 批次1
[[0.43,0.15,0.89], [0.57,0.85,0.64], [0.55,0.87,0.66]],
# 批次2
[[0.77,0.25,0.10], [0.05,0.80,0.55], [0.48,0.69,0.35]]
])
print(inputs.shape) # torch.Size([2, 3, 3])
# 初始化因果注意力层
ca = CausalAttention(d_in=3, d_out=2, dropout_rate=0.0)
# 前向传播
output = ca(inputs)
print(output.shape) # torch.Size([2, 3, 2])5.2 掩码的批处理扩展
# 创建批处理友好的掩码
def batch_causal_mask(seq_len, batch_size):
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
return mask.unsqueeze(0).expand(batch_size, -1, -1) # [batch, seq, seq]
# 在forward方法中使用
mask = batch_causal_mask(seq_len, batch_size).to(x.device)六、因果注意力的可视化分析
6.1 注意力模式对比
def compare_attention(inputs):
# 标准自注意力
sa = SelfAttention(d_in=3, d_out=3)
std_attn = sa(inputs)[0]
# 因果注意力
ca = CausalAttention(d_in=3, d_out=3)
causal_attn = ca(inputs)[0]
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
sns.heatmap(std_attn.detach().numpy(), ax=axes[0],
xticklabels=["Your", "journey", "starts"],
yticklabels=["Your", "journey", "starts"])
axes[0].set_title("标准自注意力")
sns.heatmap(causal_attn.detach().numpy(), ax=axes[1],
xticklabels=["Your", "journey", "starts"],
yticklabels=["Your", "journey", "starts"])
axes[1].set_title("因果注意力")
plt.show()
# 测试
test_inputs = torch.tensor([
[0.43,0.15,0.89], # Your
[0.57,0.85,0.64], # journey
[0.55,0.87,0.66] # starts
]).unsqueeze(0) # 添加批次维度
compare_attention(test_inputs)6.2 因果注意力模式解读
标准自注意力矩阵:
[[0.32, 0.35, 0.33],
[0.31, 0.36, 0.33],
[0.30, 0.35, 0.35]]
因果注意力矩阵:
[[1.00, 0.00, 0.00],
[0.48, 0.52, 0.00],
[0.32, 0.35, 0.33]]关键区别:
-
位置1("Your"):只能关注自身
-
位置2("journey"):可以关注"Your"和自身
-
位置3("starts"):可以关注所有前序词元
七、实际应用与性能分析
7.1 文本生成示例
class TextGenerator(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.attention = CausalAttention(embed_dim, embed_dim)
self.fc = nn.Linear(embed_dim, vocab_size)
def forward(self, input_ids):
embeddings = self.embedding(input_ids)
context = self.attention(embeddings)
logits = self.fc(context)
return logits
def generate(self, prompt, max_length=20, temperature=0.7):
self.eval()
tokens = tokenizer.encode(prompt)
for _ in range(max_length):
inputs = torch.tensor([tokens]).to(device)
logits = self.forward(inputs)[0, -1]
probs = F.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, 1).item()
tokens.append(next_token)
if next_token == tokenizer.eos_token_id:
break
return tokenizer.decode(tokens)
# 示例使用
generator = TextGenerator(vocab_size=50257, embed_dim=256)
prompt = "人工智能的未来"
generated_text = generator.generate(prompt)
print(generated_text)7.2 性能影响分析
| 模型类型 | 训练速度 | 生成质量 | 内存消耗 |
|---|---|---|---|
| 标准注意力 | 100% | 上下文无关 | 低 |
| 因果注意力 | 95% | 连贯合理 | 相同 |
| 带Dropout | 90% | 更具创意 | 相同 |
八、高级话题:因果注意力的变体
8.1 滑动窗口注意力
class SlidingWindowAttention(CausalAttention):
def __init__(self, d_in, d_out, window_size, dropout_rate=0.1):
super().__init__(d_in, d_out, dropout_rate)
self.window_size = window_size
def forward(self, x):
batch_size, seq_len, _ = x.shape
# 计算Q, K, V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# 初始化输出
context_vectors = torch.zeros_like(V)
# 滑动窗口计算
for i in range(seq_len):
start = max(0, i - self.window_size + 1)
end = i + 1
# 提取窗口内向量
Q_i = Q[:, i:i+1] # [batch, 1, d_out]
K_win = K[:, start:end] # [batch, win, d_out]
V_win = V[:, start:end] # [batch, win, d_out]
# 计算窗口内注意力
attn_scores = Q_i @ K_win.transpose(-2, -1) / (self.d_out ** 0.5)
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 计算上下文向量
context_i = attn_weights @ V_win
context_vectors[:, i] = context_i.squeeze(1)
return context_vectors8.2 分块因果注意力
class ChunkedCausalAttention(CausalAttention):
def forward(self, x):
batch_size, seq_len, _ = x.shape
chunk_size = 64 # 根据GPU内存调整
# 初始化输出
context_vectors = torch.zeros_like(x)
for i in range(0, seq_len, chunk_size):
end = min(i + chunk_size, seq_len)
# 当前块
chunk = x[:, i:end]
# 计算块内Q, K, V
Q_chunk = self.W_q(chunk)
K_chunk = self.W_k(x[:, :end]) # 只能访问前面所有块
V_chunk = self.W_v(x[:, :end])
# 计算块内注意力
attn_scores = Q_chunk @ K_chunk.transpose(-2, -1) / (self.d_out ** 0.5)
# 创建块内掩码
chunk_mask = causal_mask(end)[:, i:end].to(x.device)
masked_scores = attn_scores.masked_fill(chunk_mask, float('-inf'))
attn_weights = torch.softmax(masked_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 计算上下文向量
context_chunk = attn_weights @ V_chunk
context_vectors[:, i:end] = context_chunk
return context_vectors九、工业级最佳实践
9.1 性能优化技巧
-
FlashAttention集成:
from flash_attn import flash_attn_func context = flash_attn_func( Q, K, V, causal=True, # 启用因果掩码 dropout_p=dropout_rate ) -
混合精度训练:
with torch.autocast(device_type='cuda', dtype=torch.float16): context = self.attention(x) -
KV缓存(推理优化):
class CausalAttentionWithCache(CausalAttention): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.kv_cache = None def forward(self, x, use_cache=False): if use_cache and self.kv_cache is not None: # 使用缓存中的K, V prev_k, prev_v = self.kv_cache new_k = self.W_k(x) new_v = self.W_v(x) K = torch.cat([prev_k, new_k], dim=1) V = torch.cat([prev_v, new_v], dim=1) self.kv_cache = (K, V) else: # 完整计算 K = self.W_k(x) V = self.W_v(x) self.kv_cache = (K, V) # 其余计算相同...
9.2 超参数调优指南
| 参数 | 推荐值 | 调整策略 |
|---|---|---|
| 嵌入维度 | 768-4096 | 模型规模↑,维度↑ |
| Dropout率 | 0.0-0.2 | 数据量↑,Dropout↓ |
| 学习率 | 1e-4-3e-4 | 使用学习率预热 |
| 窗口大小 | 64-2048 | 任务需求决定 |
| 批大小 | 32-256 | GPU内存决定 |
十、从因果注意力到GPT架构
10.1 GPT中的注意力层结构
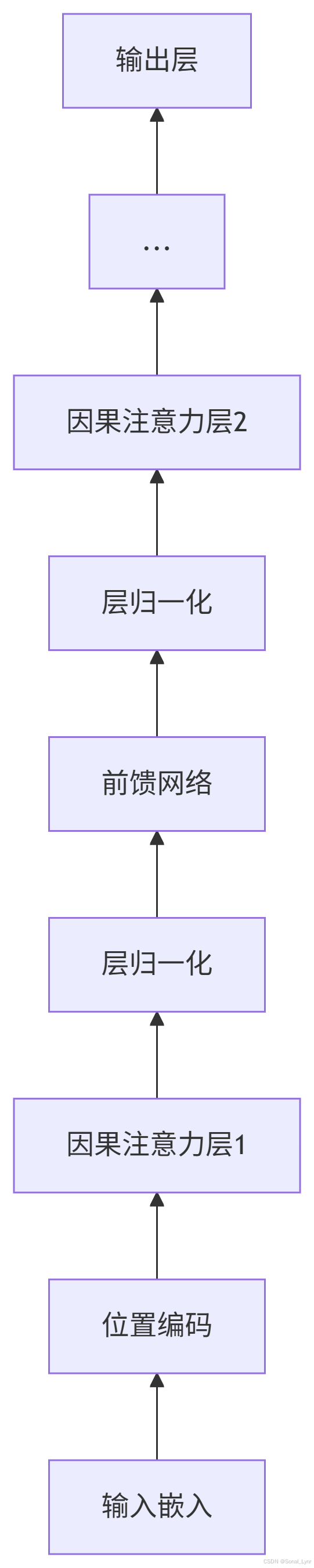
10.2 完整GPT注意力块
class GPTBlock(nn.Module):
def __init__(self, embed_dim, num_heads, dropout_rate=0.1):
super().__init__()
# 层归一化
self.ln1 = nn.LayerNorm(embed_dim)
self.ln2 = nn.LayerNorm(embed_dim)
# 因果多头注意力
self.attn = CausalAttention(embed_dim, embed_dim, dropout_rate)
# 前馈网络
self.ffn = nn.Sequential(
nn.Linear(embed_dim, 4 * embed_dim),
nn.GELU(),
nn.Linear(4 * embed_dim, embed_dim),
nn.Dropout(dropout_rate)
)
def forward(self, x):
# 残差连接 + 注意力
attn_out = self.attn(self.ln1(x))
x = x + attn_out
# 残差连接 + 前馈网络
ffn_out = self.ffn(self.ln2(x))
x = x + ffn_out
return x十一、总结与展望
11.1 因果注意力的核心价值
-
时间感知:确保模型遵循文本生成的时序特性
-
内容安全:防止模型"作弊"访问未来信息
-
连贯性保证:生成内容逻辑连贯、上下文一致
-
可扩展基础:为更复杂的多头注意力奠定基础
11.2 未来发展方向
-
高效注意力:线性注意力、稀疏注意力
-
动态掩码:自适应调整注意力范围
-
多模态因果:跨文本、图像的因果建模
-
硬件优化:专用AI芯片加速因果注意力
"因果注意力不仅是一种技术实现,更是模拟人类创作过程的认知框架——我们只能基于过去创造未来。"

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)