python-xpath解析基本用法
python-xpath解析基本用法
常用便捷高效
原理:
1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
2调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
环境安装:
--pip install lxml
--如何实例化一个etree对象
--1.将本地的html文档的源码数据加载到etree的对象中:
etree.parse(filepath)
--2.将从互联网上获取源码数据加载到该对象中
etree.HTML('page_text')
--xpath('xpath表达式')
-/:表示从根节点开始定位。表示的是一个层级
-//:表示多个层级。可以表示从任意位置开始定位
-属性定位://div[@class='song'] tag[@attrName='attrValue']
-索引定位://div[@class='song']/p[3] (表示:所有div下class='song'属性下的p标签下第3个标签(索引是从1开始))
-取文本:
-/text()获取的是标签中直系的文本内容
-//text()标签中非直系的文本内容(所有的文本内容)
-取属性:
/@attrName
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
|
实例:
获取html页面中的title内容
1.查看代码需要获取的内容:
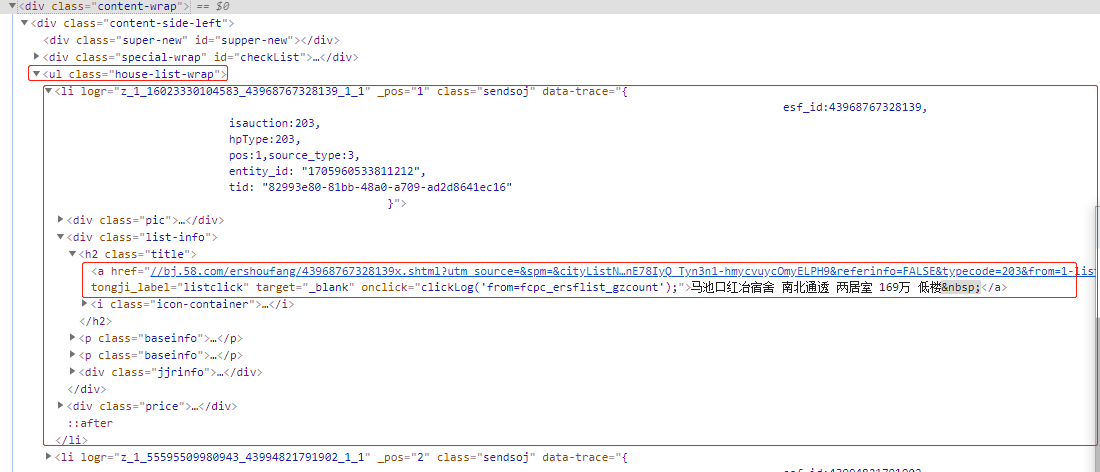
2.分析:
可以发现需要的内容在url class ="house-list-wrap"下的li标签下的第二个div标签下的a标签里
而li标签并不单一,因此需要先遍历出所有li标签,在li标签下在进行获取
3.实现:
(1)由于是本地加载会有编码上的问题,因此需要在parse中传入一个parser参数
|
1 2 3 |
|
(2)这里'/li'为了定位到所有'li'标签需要加上,这样返回了一个包含所有li的标签列表,(记住加了哪个标签最终定位到哪个标签,并返回该标签的列表)
[<Element li at 0x2106ef5bec0>, <Element li at 0x2106ef5be40>, <Element li at 0x2106f620680>, <Element li ....]
(3)对get_list中的li标签再进行xpath解析
li标签下的第二个div下的h2/a标签的text()
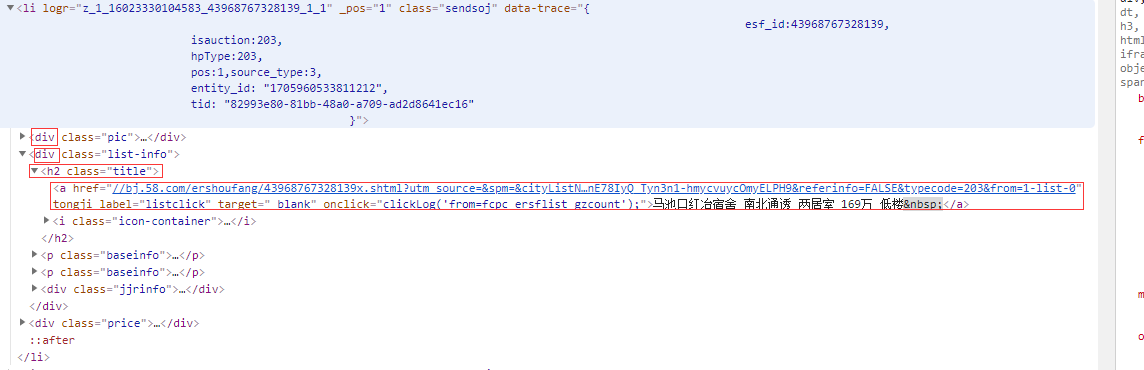
'.'表示当前li标签开始定位,若无'.'则会从根目录开始
|
1 2 3 4 5 |
|
返回所有title内容


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)