DL-批训练&&加速神经网络训练&&Optimizer 优化器 (Speed Up Training)
批训练要点Torch 中提供了一种帮助整理数据结构的好东西, 叫做DataLoader,能用它来包装自己的数据, 进行批训练. 而且批训练可以有很多种途径DataLoaderDataLoader是 torch 给你用来包装你的数据的工具.所以要将自己的 (numpy array 或其他) 数据形式装换成 Tensor, 然后再放进这个包装器中.使用DataLoader的好处帮你有效地迭代数据, 举
批训练
要点
Torch 中提供了一种帮助整理数据结构的好东西, 叫做 DataLoader,
能用它来包装自己的数据, 进行批训练. 而且批训练可以有很多种途径
DataLoader
DataLoader 是 torch 给你用来包装你的数据的工具.
所以要将自己的 (numpy array 或其他) 数据形式装换成 Tensor, 然后再放进这个包装器中.
使用 DataLoader 的好处
帮你有效地迭代数据, 举例
import torch
import torch.utils.data as Data
torch.manual_seed(1) # reproducible
BATCH_SIZE = 5 # 批训练的数据个数
x = torch.linspace(1, 10, 10) # x:1-10十个数
y = torch.linspace(10, 1, 10) # y10-1十个数
# 先转换成 torch 能识别的 Dataset,放入数据库(数据、目标)
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 把 dataset 放入 DataLoader(将数据分成小批量)
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
for epoch in range(3): # 训练所有!整套!数据 3 次
for step, (batch_x, batch_y) in enumerate(loader): # 每一步 loader 释放一小批数据用来学习
# 假设这里就是你训练的地方...
# 打出来一些数据
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
"""#打乱顺序
Epoch: 0 | Step: 0 | batch x: [ 6. 7. 2. 3. 1.] | batch y: [ 5. 4. 9. 8. 10.]
Epoch: 0 | Step: 1 | batch x: [ 9. 10. 4. 8. 5.] | batch y: [ 2. 1. 7. 3. 6.]
Epoch: 1 | Step: 0 | batch x: [ 3. 4. 2. 9. 10.] | batch y: [ 8. 7. 9. 2. 1.]
Epoch: 1 | Step: 1 | batch x: [ 1. 7. 8. 5. 6.] | batch y: [ 10. 4. 3. 6. 5.]
Epoch: 2 | Step: 0 | batch x: [ 3. 9. 2. 6. 7.] | batch y: [ 8. 2. 9. 5. 4.]
Epoch: 2 | Step: 1 | batch x: [ 10. 4. 8. 1. 5.] | batch y: [ 1. 7. 3. 10. 6.]
"""注:enumerate()每次循环都施加一个索引step++
batch_size是每一小次训练多少
epoch是训练的总次数
可以看出, 每步都导出了5个数据进行学习. 然后每个 epoch 的导出数据都是先打乱了以后再导出.
改变一下 BATCH_SIZE = 8, step=0 会导出8个数据, 但是, step=1 时只给返回这个 epoch 中剩下的数据
BATCH_SIZE = 8 # 批训练的数据个数
...
for ...:
for ...:
...
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
"""
Epoch: 0 | Step: 0 | batch x: [ 6. 7. 2. 3. 1. 9. 10. 4.] | batch y: [ 5. 4. 9. 8. 10. 2. 1. 7.]
Epoch: 0 | Step: 1 | batch x: [ 8. 5.] | batch y: [ 3. 6.]
Epoch: 1 | Step: 0 | batch x: [ 3. 4. 2. 9. 10. 1. 7. 8.] | batch y: [ 8. 7. 9. 2. 1. 10. 4. 3.]
Epoch: 1 | Step: 1 | batch x: [ 5. 6.] | batch y: [ 6. 5.]
Epoch: 2 | Step: 0 | batch x: [ 3. 9. 2. 6. 7. 10. 4. 8.] | batch y: [ 8. 2. 9. 5. 4. 1. 7. 3.]
Epoch: 2 | Step: 1 | batch x: [ 1. 5.] | batch y: [ 10. 6.]
"""加速神经网络训练 (Speed Up Training)
越复杂的神经网络 , 越多的数据 , 需要在训练神经网络的过程上花费的时间也就越多.
Stochastic Gradient Descent (SGD)
最基础的方法就是 SGD , 想像红色方块是我们要训练的 data,
如果用普通的训练方法, 就需要重复不断的把整套数据放入神经网络 NN训练, 这样消耗的计算资源会很大.
换一种思路, 如果把这些数据拆分成小批小批的, 然后再分批不断放入 NN 中计算, 这就是 SGD .
每次使用批数据, 虽然不能反映整体数据的情况, 不过却很大程度上加速了 NN 的训练过程, 而且也不会丢失太多准确率.

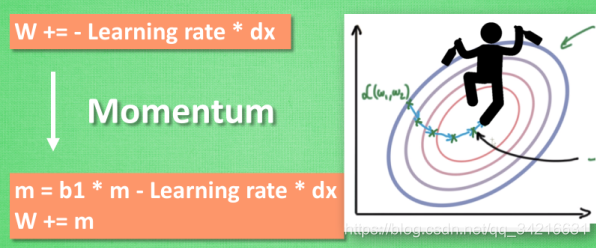
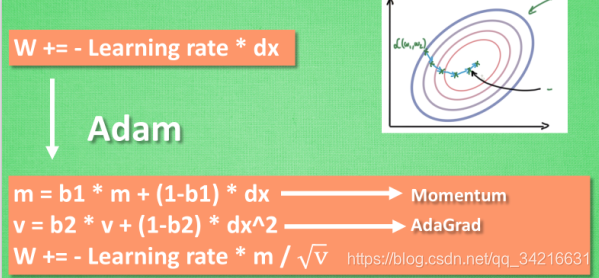
Momentum 更新方法
大多数其他途径是在更新神经网络参数上动动手脚.
传统的参数 W 的更新是把原始的 W 累加上一个负的学习率(learning rate) 乘以校正值 (dx).
这种方法可能会让学习过程曲折无比, 看起来像 喝醉的人回家时, 摇摇晃晃走了很多弯路.
我们把这个人从平地上放到了一个斜坡上, 只要他往下坡的方向走一点点, 由于向下的惯性, 他不自觉地就一直往下走, 走的弯路也变少了.
这就是 Momentum 参数更新.
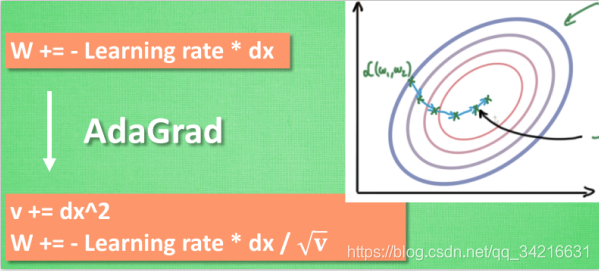
AdaGrad 更新方法 ¶
在学习率上面动手脚, 使得每一个参数更新都会有自己与众不同的学习率,
他的作用和 momentum 类似, 不过他是给喝醉酒的人一双不好走路的鞋子, 使得他一摇晃着走路就脚疼, 鞋子成为了走弯路的阻力, 逼着他往前直着走.
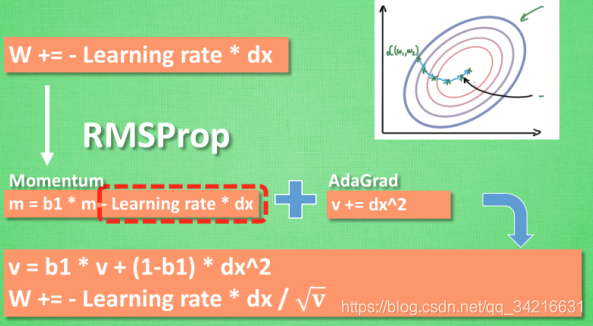
RMSProp 更新方法
有了 momentum 的惯性原则 , 加上 adagrad 的对错误方向的阻力,合并让 RMSProp同时具备两种方法的优势.
不过细心的同学们肯定看出来了, 似乎在 RMSProp 中少了些什么. 原来我们还没把 Momentum合并完全, RMSProp 还缺少了 momentum 中的 这一部分.
Adam 更新方法
计算m 时有 momentum 下坡的属性, 计算 v 时有 adagrad 阻力的属性, 然后再更新参数时 把 m 和 V 都考虑进去.
实验证明, 大多数时候, 使用 adam 都能又快又好的达到目标, 迅速收敛. 所以, 在加速神经网络训练的时候, 一个下坡, 一双破鞋子, 功不可没.
Optimizer 优化器
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
torch.manual_seed(1) # reproducible
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
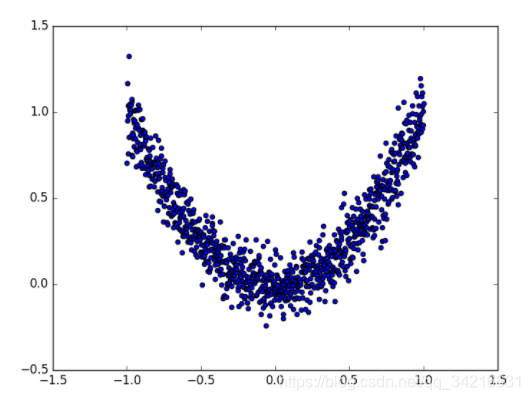
# fake dataset伪数据
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
# plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show()
# 使用上节内容提到的 data loader
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)编的伪数据图
每个优化器优化一个神经网络
为对比每一种优化器, 给他们各自创建一个神经网络, 但神经网络都来自同一个 Net 形式.
# 默认的 network 形式
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
# 为每个优化器创建一个 net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]创建不同的优化器来训练不同的网络
创建不同的优化器, 用来训练不同的网络. 并创建一个 loss_func 用来计算误差.
我们用几种常见的优化器, SGD, Momentum, RMSprop, Adam.
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # 记录 training 时不同神经网络的 loss训练
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader):
# 对每个优化器, 优化属于他的神经网络
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # 得到每个net输出
loss = loss_func(output, b_y) # 计算每个net的损失
opt.zero_grad() # 梯度清0
loss.backward() # 反向传播计算梯度
opt.step() # 更新梯度
l_his.append(loss.data.numpy()) #记录损失和 loss 画图
运行结果:
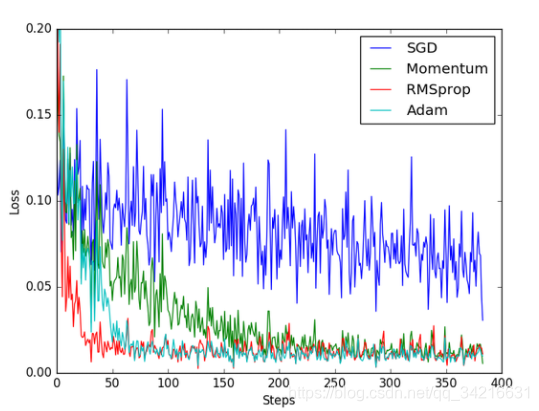
SGD 是最普通的优化器, 也可以说没有加速效果,
Momentum 是 SGD 的改良版, 它加入了动量原则.
RMSprop 又是 Momentum 的升级版.
Adam 又是 RMSprop 的升级版.
不过从这个结果中我们看到, Adam 的效果似乎比 RMSprop 要差一点.
所以说并不是越先进的优化器, 结果越佳.
我们在自己的试验中可以尝试不同的优化器, 找到那个最适合你数据/网络的优化器.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)