深度学习之Transformer模型
本文通过学习李沐基于pytorch的深度学习课程第68课Transformer,对该模型的原理做出总结并展示代码,作为本人学习笔记。
一、Transformer架构
基于编码器与解码器架构来处理序列对,跟使用注意力的seq2seq不同(去掉RNN),该模型纯基于注意力。如下图所示,是该模型的架构图,主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。
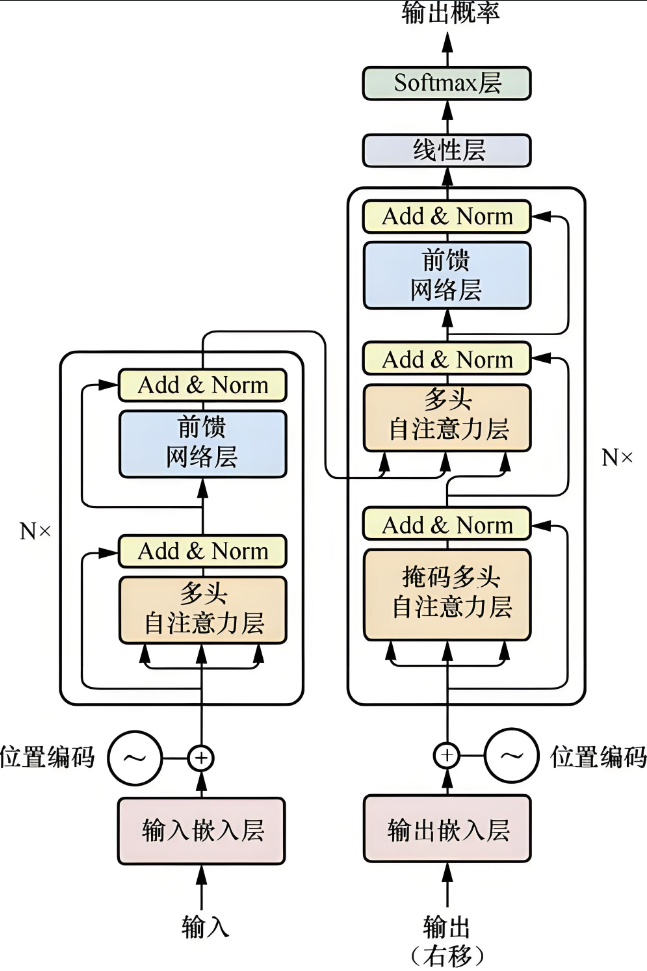
(这里的讲解我观看了这位UP主的视频,通俗易懂,支持!) 【Transformer 其实是个简单到令人困惑的模型【白话DeepSeek06】】
从图片中我们能够看到该模型内部如何处理输入输出:
从左边输入开始,将输入内容通过词嵌入的方式转换为词向量矩阵并加入位置编码(再加一个形状一样的矩阵,该矩阵包含词的位置信息),再经过多头注意力机制的处理(输出的矩阵会给每个词向量添加了上下文信息),继续添加残差网络和归一化处理(解决梯度消失使更加稳定),可以看到整个transformer架构中像这样的多头自注意力层共有三个,其流程一致。
左边部分叫做编码器,右边部分叫做解码器,训练这个神经网络的过程为:输入要翻译的文本,经过词嵌入、引入位置编码,经过多头注意力、残差、归一化处理,接着送入一个全连接神经网络,再残差和归一化处理,结果送入解码器中一个多头注意力的两个输入中,作为KV矩阵。右边解码器部分输出是翻译后的结果,同样经过词嵌入、位置编码、多头注意力、残差和归一化,送入上方多头注意力的输入中,作为Q矩阵。和刚刚从编码器中送入的KV矩阵,再经过多头注意力、残差和归一化,再全连接层,再残差归一化。最后,经过一层线性变换,投射到词表向量中并用Softmax转换为概率(输出概率,代表预测的下一个词在词表中的概率分布,取概率最高的就是就是下一个词)。
除此之外,整个框架图中我们发现有一块不太一样:掩码多头自注意力层,掩码(Masked)的作用是把后面的词遮挡住,以便训练的时候模拟真实推理场景时的过程,后面细说。
总之,每个块里使用多头(自)注意力(multi-head attention),基于位置的前馈网络(Positionwise FFN),残差连接和层归一化。如果训练有偏差,就计算损失函数,再反向传播调整结构中的各种权重矩阵,直到学习好为止。
因此,Transformer模型的核心是多头注意力,接下来具体说一说什么是多头注意力机制。
二、多头注意力Multi-Head Attention
1. 多头注意力机制
多头注意力机制的核心思想是将输入序列通过三个不同的线性变换层分别得到Query(查询)、Key(键)和Value(值)。这些变换后的向量被划分为若干个“头”,每个头都有自己独立的Q、K、V矩阵。对于每个头,都执行一次Scaled Dot-Product Attention(缩放点积注意力)运算,最后将所有头的输出拼接在一起,并通过一个线性层进行融合,得到最终的注意力输出向量。
在李沐课堂中,更简练的描述是:
对同一个 key 、value 、query 抽取不同的信息,例如短距离关系和长距离关系。
多头注意力使用 h 个独立的注意力池化,合并各个头(head)输出得到最终输出。
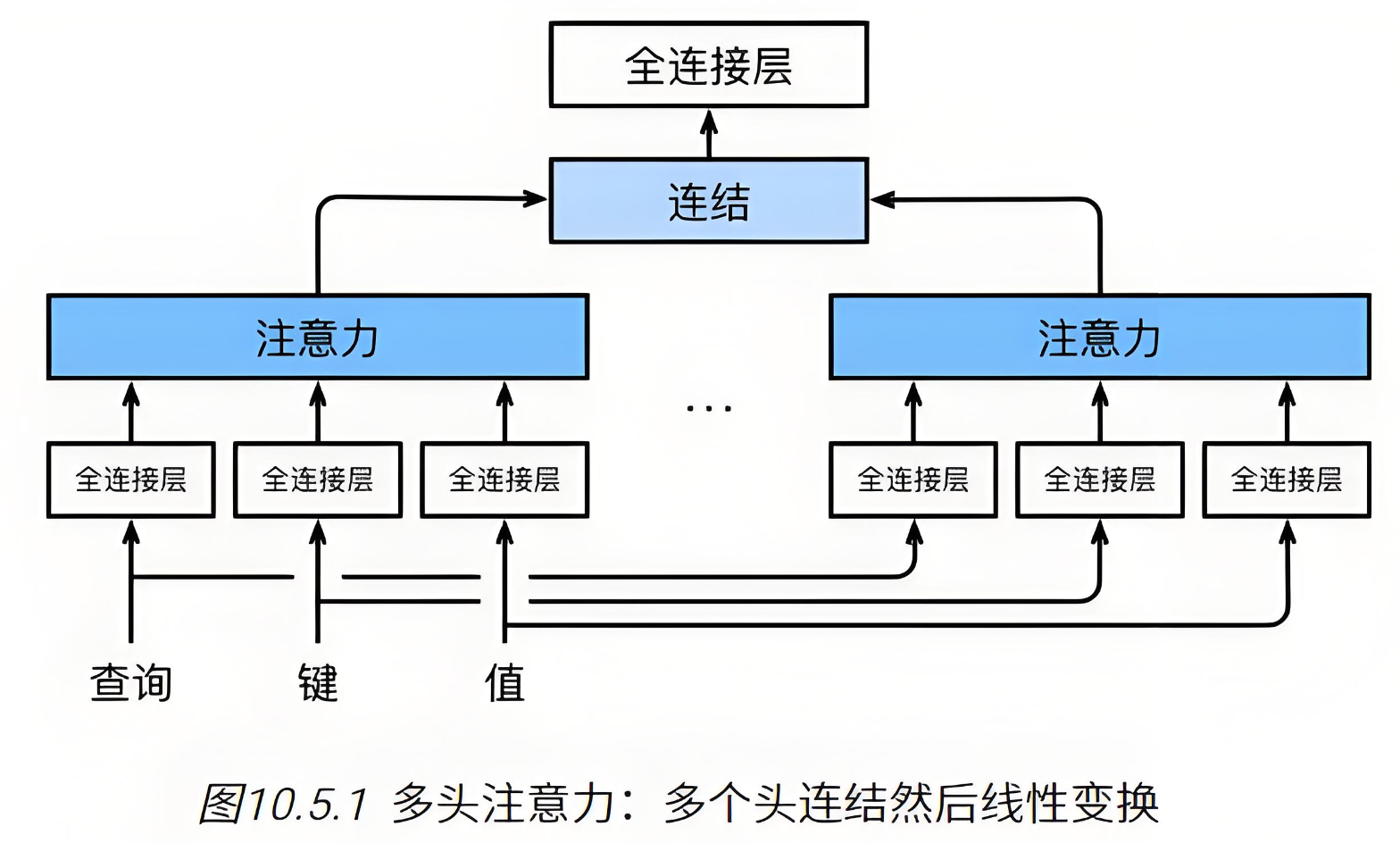
通过具体公式,我们能更好地理解上述过程:
所谓注意力机制,就是QK矩阵相乘再缩放,再经过softmax处理后,与V相乘。
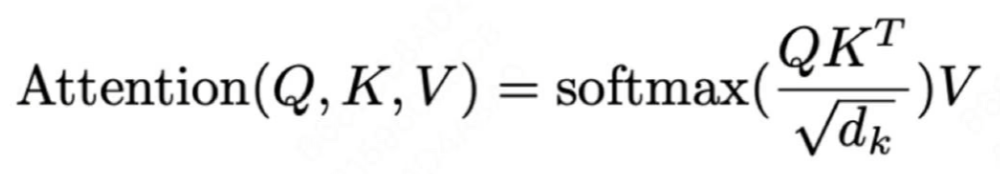
对于多头情况,就是先将QKV矩阵经过多个权重矩阵,拆分到多个头中,分别进行注意力机制,再合并起来,再经过一次矩阵运算得到输出。

2. 有掩码的多头注意力
我们知道,Attention是没有时间信息的,在第i个输出时可以看见后面所有的东西,在编码是没关系的,但在解码这样是不行的,因为不应该去考虑该元素本身和之后的元素(不然怎么实现预测),我们不能偷看“未来”的信息,所以使用有掩码的多头注意力。
当计算Xi的输出时,假设当前的序列长度是Xi,把后面所有东西隐藏掉,具体使用时,在Softmax前,将未来位置的分数加上掩码值(如-inf)。
3. 代码实现
展示一下实现多头注意力的核心代码:
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self,query_size,key_size,value_size,num_hiddens,num_heads,dropout,bias=False):
super(MultiHeadAttention,self).__init__()
self.num_heads = num_heads
self.attention = d2l.torch.DotProductAttention(dropout) # 点积注意力模块
self.W_q = nn.Linear(query_size,num_hiddens,bias=bias) # query变换矩阵
self.W_k = nn.Linear(key_size,num_hiddens,bias=bias) # key变换矩阵
self.W_v = nn.Linear(value_size,num_hiddens,bias=bias) # value变换矩阵
self.W_o = nn.Linear(num_hiddens,num_hiddens,bias=bias) # 输出变换矩阵
# query_size/key_size/value_size:输入Q/K/V的维度;num_hiddens:注意力层的隐藏维度
# num_heads:多头注意力的头数;dropout防止过拟合;bias:线性变换是否使用偏置项。
def forward(self,queries,keys,values,valid_lens):
# 线性变换并分头
queries = transpose_qkv(self.W_q(queries),self.num_heads)
keys = transpose_qkv(self.W_k(keys),self.num_heads)
values = transpose_qkv(self.W_v(values),self.num_heads)
# 处理有效长度(掩码)
if valid_lens is not None:
valid_lens = torch.repeat_interleave(valid_lens,repeats=self.num_heads,dim=0)
# 计算注意力并拼接多头
output = self.attention(queries,keys,values,valid_lens)
output_concat = transpose_output(output,self.num_heads)
return self.W_o(output_concat)这里还需要定义一个辅助函数transpose_qkv使多个头并行计算:
def transpose_qkv(X,num_heads):
'''将线性变换后的Q/K/V拆分为多头,便于并行计算'''
# 输入X形状(batch_size, seq_len, num_hiddens)
X = X.reshape(X.shape[0],X.shape[1],num_heads,-1) # 拆分为多头
X = X.permute(0,2,1,3) # # 调整维度为(batch_size, num_heads, seq_len, head_dim)
return X.reshape(-1,X.shape[2],X.shape[3])
def transpose_output(X,num_heads):
'''将多头的注意力结果合并回原始维度'''
# 输入X形状(batch_size, num_heads, seq_len, head_dim)
X = X.reshape(-1,num_heads,X.shape[1],X.shape[2])
X = X.permute(0,2,1,3)
# 恢复为(batch_size, seq_len, num_heads, head_dim)
return X.reshape(X.shape[0],X.shape[1],-1) # 拼接多头三、Transformer代码
在上述多头注意力机制的基础上,实现Transformer模型。
首先,定义“基于位置的前馈网络”,包含两个全连接层和一个ReLU。
import math
import d2l.torch
import torch
from torch import nn
import pandas as pd
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self,ffn_num_inputs,ffn_num_hiddens,ffn_num_outputs):
# 参数:输入特征的维度、隐藏层维度、输出维度
super(PositionWiseFFN,self).__init__()
self.dense1 = nn.Linear(ffn_num_inputs,ffn_num_hiddens) # 第一层全连接
self.relu = nn.ReLU() # 激活函数
self.dense2 = nn.Linear(ffn_num_hiddens,ffn_num_outputs) # 第二层全连接
def forward(self,X): # 前向传播
return self.dense2(self.relu(self.dense1(X)))计算流程:输入X通过第一层线性变换(dense1)然后应用ReLU激活函数(引入非线性),再通过第二层线性变换(dense2)输出结果。输入X形状为(batch_size, seq_len, ffn_num_inputs),输出为(batch_size, seq_len, ffn_num_outputs)。
接下来,实现了一个残差连接(Add)与层规范化(Norm)的组合模块,也是Transformer架构中的关键设计之一。下面代码先对比不同维度的层规范化和批量规范化的效果,直观输出示例(每一个样本内部均值为0,方差为1):
ln = nn.LayerNorm(3) # 层归一化,对最后一个维度(特征维度)归一化
bn = nn.BatchNorm1d(3) # 批归一化,对特征维度归一化(沿batch维度计算统计量)
X = torch.tensor([[1,2,3],[8,9,10],[15,16,17]],dtype=torch.float32) # 输入x
print('layer_norm :',ln(X),'\nbatch_norm : ',bn(X))
'''
结果:
layer_norm : tensor([[-1.2247, 0.0000, 1.2247],
[-1.2247, 0.0000, 1.2247],
[-1.2247, 0.0000, 1.2247]], grad_fn=<NativeLayerNormBackward0>)
batch_norm : tensor([[-1.2247, -1.2247, -1.2247],
[ 0.0000, 0.0000, 0.0000],
[ 1.2247, 1.2247, 1.2247]], grad_fn=<NativeBatchNormBackward0>)
'''层归一化计算方式是对每个样本独立归一化,计算每个样本所有特征的均值和方差。输出特点是每个样本的特征均值为0,方差为1,且不受batch大小影响,适合变长序列(如NLP任务)。
批量归一化计算方式是对每个特征跨样本归一化,计算每个特征在所有样本中的均值和方差。输出特点是每个特征的跨样本分布均值为0,方差为1,依赖batch统计量,对小batch效果不稳定。
所以,通过这段代码,可以清晰理解这两种归一化的核心差异及其适用场景,Transformer使用LayerNorm是因为避免小batch导致的训练抖动,且与残差连接配合稳定深层网络训练。
接下来,残差连接后进行层规范化:
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self,normalized_shape,dropout):
# normalized_shape是需规范化的特征维度,通常是输入X的最后一维
super(AddNorm,self).__init__()
self.dropout = nn.Dropout(dropout) # Dropout层,随机置零部分神经元输出
self.layer_norm = nn.LayerNorm(normalized_shape=normalized_shape) # 对最后一维进行层归一化,稳定训练,加速收敛。
def forward(self,X,Y):
return self.layer_norm(self.dropout(Y)+X)计算过程为:先利用Dropout对Y进行随机丢弃(如dropout=0.1则丢弃10%的值),在进行残差连接,将Dropout后的Y与原始输入X相加;最后,层归一化对相加结果进行规范化。
接下来,实现编码器的一个层。
class EncoderBlock(nn.Module):
"""transformer编码器块"""
def __init__(self,query_size,key_size,value_size,num_hiddens,normalized_shape,ffn_num_inputs,ffn_num_hiddens,num_heads,dropout,use_bias=False):
super(EncoderBlock,self).__init__()
# 多头自注意力层
self.multihead_attention = d2l.torch.MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout,use_bias)
# 第一个AddNorm对多头注意力的输出做残差连接 + 层归一化
self.addnorm1 = AddNorm(normalized_shape,dropout)
# 前馈网络:两层全连接+ReLU激活
self.ffn = PositionWiseFFN(ffn_num_inputs,ffn_num_hiddens,num_hiddens)
# 第二个AddNorm对FFN的输出做残差连接 + 层归一化
self.addnorm2 = AddNorm(normalized_shape,dropout)
def forward(self,X,valid_lens):
# 多头自注意力 + 残差连接
Y = self.addnorm1(X,self.multihead_attention(X,X,X,valid_lens))
# 前馈网络 + 残差连接
return self.addnorm2(Y,self.ffn(Y))演示使用一个 Transformer编码器块(EncoderBlock) 处理输入数据,编码器中的任何层都不会改变其输入的形状,输入输出形状大小相同:
X = torch.ones(size=(2,100,24)) # 形状:(batch_size=2, seq_len=100, feature_dim=24)
valid_lens = torch.tensor([3,2]) # 两个序列的有效长度分别为3和2
encoder_block = EncoderBlock(query_size=24,key_size=24,value_size=24,num_hiddens=24,normalized_shape=[100,24],ffn_num_inputs=24,ffn_num_hiddens=48,num_heads=8,dropout=0.5,use_bias=False)
# 关键配置:8个头,每个头维度24/8=3,输入/输出维度保持一致
# 隐藏层维度扩展为48,对每个样本的(100, 24)矩阵独立归一化
encoder_block.eval() # 关闭Dropout
encoder_block(X,valid_lens).shape # 前向计算
'''
torch.Size([2, 100, 24])
'''然后实现一个完整的 Transformer编码器(TransformerEncoder),它由多个EncoderBlock堆叠而成,并包含词嵌入(Embedding)和位置编码(PositionalEncoding)模块。
class TransformerEncoder(d2l.torch.Encoder):
"""transformer编码器"""
def __init__(self,vocab_size,query_size,key_size,value_size,num_hiddens,normalized_shape,ffn_num_inputs,ffn_num_hiddens,num_heads,num_layers,dropout,use_bias=False):
super(TransformerEncoder,self).__init__()
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size,num_hiddens) # 词嵌入层
self.positionalEncoding = d2l.torch.PositionalEncoding(num_hiddens,dropout) # 位置编码
self.encoder_blocks = nn.Sequential() # 堆叠多个EncoderBlock
for i in range(num_layers):
self.encoder_blocks.add_module(f'encoder_block{i}',
EncoderBlock(query_size,key_size,value_size,num_hiddens,normalized_shape,ffn_num_inputs,ffn_num_hiddens,num_heads,dropout,use_bias=use_bias))
def forward(self, X,valid_lens, *args):
# 词嵌入 + 位置编码
X = self.positionalEncoding(self.embedding(X)*math.sqrt(self.num_hiddens))
# 逐层通过EncoderBlock
self.attention_weights = [None]*len(self.encoder_blocks)
for i,encoder_block in enumerate(self.encoder_blocks):
X = encoder_block(X,valid_lens)
# 记录每层的注意力权重
self.attention_weights[i] = encoder_block.multihead_attention.attention.attention_weights
return X接下来指定超参数来演示transformer编码器,编码器输出的形状是(批量大小,时间步数目,num_hiddens),依旧不变。
transformer_encoder = TransformerEncoder(200,24,24,24,24,[100,24],24,48,8,2,0.5,use_bias=False)
transformer_encoder.eval()
transformer_encoder(torch.ones(size=(2,100),dtype=torch.long),valid_lens).shape
'''
torch.Size([2, 100, 24])
'''开始实现了一个 Transformer解码器块(DecoderBlock),是Transformer解码器的核心组件。相比编码器块,解码器块更复杂,因为它需要处理自回归生成任务中的掩码多头注意力,并接收编码器的输出作为额外输入。
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self,query_size,key_size,value_size,num_hiddens,normalized_shape,ffn_num_inputs,ffn_num_hiddens,num_heads,dropout,i,use_bias=False):
super(DecoderBlock,self).__init__()
self.i = i # i:当前解码器块的索引(用于状态管理)
# 带掩码的多头自注意力层(防止看到未来信息)
self.mask_multihead_attention1 = d2l.torch.MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout,bias=use_bias)
self.addnorm1 = AddNorm(normalized_shape,dropout)
# 普通的跨注意力层(关注编码器输出)
self.mutilhead_attention2 = d2l.torch.MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout,bias=use_bias)
self.addnorm2 = AddNorm(normalized_shape,dropout)
# 位置前馈网络
self.ffn = PositionWiseFFN(ffn_num_inputs,ffn_num_hiddens,num_hiddens)
self.addnorm3 = AddNorm(normalized_shape,dropout)
# 三个AddNorm层分别对应三个子层的残差连接和层归一化
def forward(self,X,state):
enc_outputs,enc_valid_lens = state[0],state[1]
if state[2][self.i] is None:
keys_values = X
else:
keys_values = torch.cat([state[2][self.i],X],dim=1)
state[2][self.i] = keys_values
# 训练时的掩码处理
if self.training:
batch_size,num_step,_ = X.shape
dec_valid_lens = torch.arange(1,num_step+1,device=X.device).repeat(batch_size,1)
else:
dec_valid_lens = None
# 掩码自注意力:只关注已生成的部分
X2 = self.mask_multihead_attention1(X,keys_values,keys_values,dec_valid_lens)
Y = self.addnorm1(X,X2)
# 编码器-解码器注意力:关注编码器输出
Y2 = self.mutilhead_attention2(Y,enc_outputs,enc_outputs,enc_valid_lens)
Z = self.addnorm2(Y,Y2)
# 前馈网络
return self.addnorm3(Z,self.ffn(Z)),state演示Transformer解码器块:(输入形状与输出一致,符合残差连接要求)
decoder_block = DecoderBlock(24,24,24,24,[100,24],24,48,8,0.5,0,use_bias=False)
decoder_block.eval()
X = torch.ones(size=(2,100,24)) # 解码器输入
state = [encoder_block(X,valid_lens),valid_lens,[None]] # 初始状态
decoder_block(X,state)[0].shape
'''
torch.Size([2, 100, 24])
'''下段代码实现了一个完整的Transformer解码器(TransformerDecoder),它是Transformer架构中用于序列生成(如机器翻译、文本生成)的核心组件。最后的注意力权重属性,存储每层的两种注意力权重:掩码自注意力权重(解码器自身)和编码器-解码器注意力权重。
class TransformerDecoder(d2l.torch.Decoder):
def __init__(self,vocab_size,query_size,key_size,value_size,num_hiddens,normalized_shape,ffn_num_inputs,ffn_num_hiddens,num_heads,num_layers,dropout,use_bias=False):
super(TransformerDecoder,self).__init__()
self.num_hiddens = num_hiddens # 隐藏层维度
self.num_layers = num_layers # 解码器层数
self.embedding = nn.Embedding(vocab_size,num_hiddens) # 词嵌入层
self.positionalEncoding = d2l.torch.PositionalEncoding(num_hiddens,dropout) # 位置编码
self.decoder_blocks = nn.Sequential() # 堆叠的解码器块
for i in range(num_layers):
self.decoder_blocks.add_module(f'decoder_block{i}',
DecoderBlock(query_size,key_size,value_size,num_hiddens,normalized_shape,ffn_num_inputs,ffn_num_hiddens,num_heads,dropout,i,use_bias=use_bias)) # 注意传入层索引i
self.dense = nn.Linear(num_hiddens,vocab_size) # 输出层
def init_state(self, enc_outputs, enc_valid_lens,*args):
return [enc_outputs,enc_valid_lens,[None]*self.num_layers]
def forward(self, X, state):
# 词嵌入 + 位置编码
X = self.positionalEncoding(self.embedding(X)*math.sqrt(self.num_hiddens))
# 逐层通过解码器块
self._attention_weights = [[None]*len(self.decoder_blocks) for _ in range(2)]
for i,decoder_block in enumerate(self.decoder_blocks):
X,state = decoder_block(X,state)
# 记录两种注意力权重
self._attention_weights[0][i] = decoder_block.mask_multihead_attention1.attention.attention_weights
self._attention_weights[1][i] = decoder_block.mutilhead_attention2.attention.attention_weights
# 输出层
return self.dense(X),state
@property
def attention_weights(self):
return self._attention_weights模型搭建完成,开始Transformer机器翻译模型训练:
batch_size, num_steps = 64, 10 # 批量大小64、序列长度10
query_size, key_size, value_size, num_hiddens = 32, 32, 32, 32 # 注意力维度
normalized_shape = [32] # 层归一化维度
ffn_num_inputs, ffn_num_hiddens = 32, 64 # FFN维度
num_heads, num_layers, dropout = 4, 2, 0.1 # 4注意力头、2层、10%丢弃率
use_bias = False # 线性层无偏置
lr, num_epochs, device = 0.005, 300, d2l.torch.try_gpu() # 学习率0.005、300轮、自动选择GPU
train_iter,src_vocab,tgt_vocab = d2l.torch.load_data_nmt(batch_size,num_steps) # 数据准备
# 编码器
transformer_encoder = TransformerEncoder(len(src_vocab),query_size,key_size,value_size,num_hiddens,normalized_shape,ffn_num_inputs,ffn_num_hiddens,num_heads,num_layers,dropout,use_bias=use_bias)
# 解码器
transformer_decoder = TransformerDecoder(len(tgt_vocab),query_size,key_size,value_size,num_hiddens,normalized_shape,ffn_num_inputs,ffn_num_hiddens,num_heads,num_layers,dropout,use_bias=use_bias)
# Seq2Seq封装
net = d2l.torch.EncoderDecoder(transformer_encoder,transformer_decoder)
d2l.torch.train_seq2seq(net,train_iter,lr,num_epochs,tgt_vocab,device)训练结果:
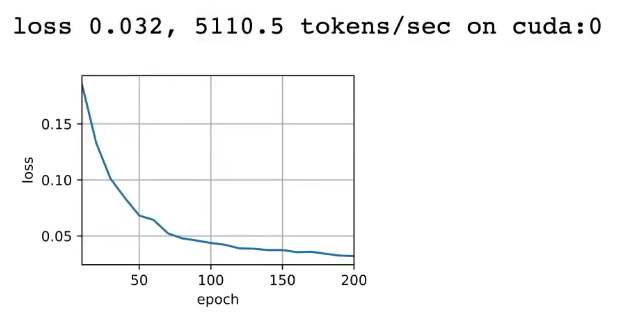
后面课堂上还介绍了自注意力权重可视化的相关内容,这里不做展示。
至此,Transformer模型展示完毕。通过这些代码,可以完整实现一个基础的Transformer翻译模型。虽然参数规模较小,但完整展现了Transformer在Seq2Seq任务中的核心机制,可作为更复杂应用的开发基础。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)