基于LM-CNN-SVM的自动驾驶目标检测
本文提出一种结合局部多卷积神经网络与支持向量机(LM-CNN-SVM)的混合系统,用于自动驾驶中的目标识别与行人检测。通过图像分块、特征提取、PCA降维及SVM分类,系统在Caltech-101和Caltech行人数据集上表现出优于传统方法的准确率与鲁棒性,有效应对光照变化、遮挡和复杂背景等挑战。
深度学习在自动驾驶应用中的目标识别与检测
1. 引言
几十年来,目标识别与检测一直是自动驾驶汽车实际应用中的重要问题。这些功能具有多种应用场景,包括通过检测道路上的白色线条实现的车道偏离预警系统和车道保持辅助系统,利用立体图像检测车辆前方障碍物,基于红外相机获取的图像实现的行人检测预警系统,以及结合激光测距传感器和相机系统对道路环境中车辆的检测。在自动驾驶车辆应用中,识别、跟踪并检测诸如汽车、卡车、动物、摩托车、交通标志、建筑物和行人在内的动态与静态物体至关重要。目标或行人的检测与识别是计算机视觉领域中日益增长且富有挑战性的问题。其挑战来源于诸多影响目标分类性能的因素,例如光照条件的变化、形变的多样性、部分遮挡、阴影的存在以及周围背景的杂乱干扰。
为了解决这个问题,一些研究工作致力于开发新的特征提取算法,例如尺度不变特征变换(SIFT),梯度方向直方图(HOG),二进制鲁棒独立基本特征(BRIEF),加速稳健特征(SURF),以及快速视网膜关键点(FREAK)。一些研究提出了更强大的分类算法,例如支持向量机(SVMs),球面/椭圆分类器,极限学习机(ELMs),AdaBoost、决策森林和朴素贝叶斯,以及级联增强结构用于识别和检测物体,而另一些研究则通过结合优良的特征描述符与优良的分类器(如词袋(BoW)方法)实现精确的物体分类。在词袋(BoW)方法中,特征通过SIFT和SURF等方法提取,然后从某些间隔过程步骤获得的判别性数据使用分类器进行分类。
近年来,深度学习方法已成为目标识别与检测的强大机器学习方法。深度学习方法不同于传统方法,它们能够直接从输入图像的原始像素中自动且快速地学习特征,而无需使用SIFT、HOG和SURF等方法。在深度学习方法中,局部感受野逐层增长。低层提取精细特征,例如线条、边界和角点,而高层则表现出更高层次的特征,例如行人部件等目标部分或汽车和交通标志等完整目标。换句话说,它们能够端到端地以不同粒度表示一个目标。这些方法在具有挑战性的ImageNet分类任务上取得了成功,该任务涵盖数千个类别,所用的深度神经网络类型称为卷积神经网络(CNN)。研究表明,卷积神经网络(CNNs)的识别性能优于使用传统特征提取方法的分类器。然而,当将CNN应用于整幅图像时,使用CNN提取的全局特征会显著受到光照、噪声或遮挡的影响。
因此,本文提出一种结合CNN和支持向量机(SVM)的新系统,以应对这些挑战。最近,一些研究已经包含了CNN和支持向量机(SVM)的不同组合方式。例如,有研究基于核组合,利用局部卷积神经网络(CNN)和支持向量机(SVM)实现了鲁棒的人脸检测。通过收集与CNN不同层相关的特征并将其导入支持向量机(SVM)的输入,实现了场景识别。另一项研究提出了一种新颖的单一CNN-SVM分类器,用于识别手写数字。然而,与这些工作不同的是,本文提出通过为对象的局部区域定义多个卷积神经网络(CNN)来确定局部鲁棒特征,然后使用支持向量机(SVM)识别和检测所有目标。因此,所提出的混合局部多卷积神经网络-支持向量机(LM-CNN-SVM)系统能够比单一CNN提取更鲁棒且高效的特征。此外,我们采用了两种CNN架构。其中一种是预训练AlexNet架构,包含八个层(不包括输入层),另一种是包含九个层(不包括输入层)的CNN架构,结构类似于AlexNet。AlexNet具有五个卷积层和三个全连接层的架构。我们倾向于选择该网络,因为它已成功应用于ImageNet数据集的目标识别任务。我们进行了详细的实验来评估所提出的CNN。本文是我们先前会议论文的扩展版本。
本文其余部分组织如下。在第2节中,描述了SVM、卷积神经网络以及混合LM-CNN-SVM系统的原理。第3节展示并讨论了实验结果。在第4节中,对本文进行了总结。
2. 新的混合局部多重卷积神经网络-支持向量机系统
本节简要回顾了用于生成新型混合LM-CNN-SVM分类器的卷积神经网络和SVM分类器。
2.1. 卷积神经网络
卷积神经网络(CNNs)的基本结构受到动物视觉皮层组织的启发。休贝尔和威塞尔在1968年发表了一项关于“局部感受野”的研究,他们发现动物视觉皮层在视觉场的小子区域中具有复杂的细胞排列。与卷积神经网络相关的最初思想最早由福岛于1980年提出,他采用层次化组织的图像变换方法,利用休贝尔和威塞尔的概念来模拟人类视觉系统。然而,与传统的卷积神经网络不同,他的工作并未包含共享权重。在1990年代初期,卷积神经网络开始出现在文献中,但存在计算负荷大的缺点。如今,随着高性能图形处理器(GPU)的出现,卷积神经网络(CNNs)作为强大的特征提取器和分类器而广受欢迎。短时间内,卷积神经网络(CNNs)已成功应用于许多计算机视觉领域,如自动驾驶车辆、语音识别和医学影像任务。
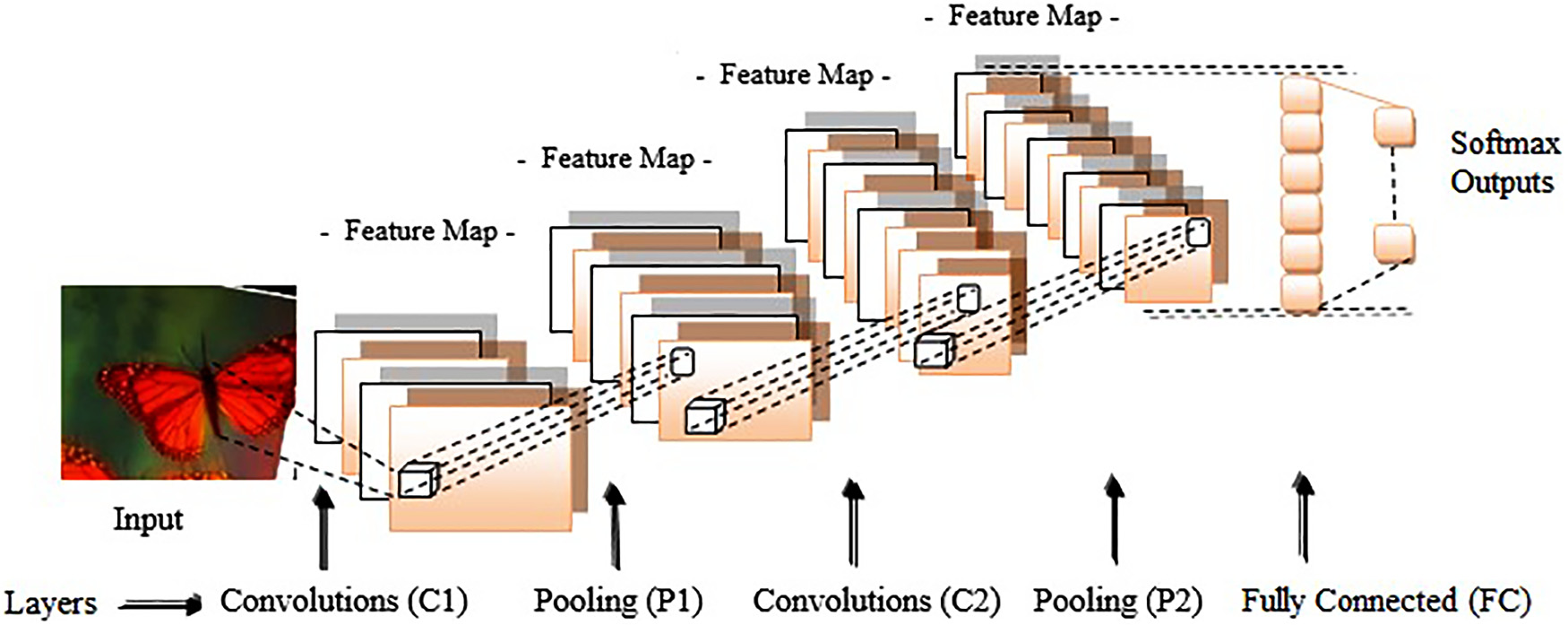
卷积神经网络(CNNs)由多个类似于前馈神经网络的层组成。这些层的输入和输出以一组图像数组的形式给出。卷积神经网络可以通过卷积层、池化层和全连接层的不同组合,并结合逐点非线性激活函数构建而成。典型的CNN架构如图1所示。

卷积神经网络(CNNs)的层定义简要描述如下。
输入层 :图像直接导入网络的输入端。
卷积层 :该层执行卷积神经网络(CNNs)中的主要运算。在卷积神经网络中,使用卷积操作替代传统前馈神经网络中的矩阵乘法,以减少权重数量,从而降低网络复杂度。输入图像通过卷积核或可学习滤波器进行卷积,卷积操作在输出图像中生成特征图。得到的特征图将作为后续卷积层的输入。
池化层 :该层用于降低特征维度。因此,特征图的分辨率被降低,并实现了空间不变性。输入图像被划分为一组不重叠的矩形区域。每个区域通过非线性下采样操作(如最大值或平均值)进行下采样。该层实现了更快的收敛、更好的泛化能力,以及对平移和扭曲的小幅度不变性。这些层通常位于连续的卷积层之间,以减小空间尺寸。
修正线性单元(ReLU)层 :该层包含使用整流器以实现尺度不变性的单元。该层的激活函数在数学上被描述为 $f(x) = \max(0,x)$,其中输入为 $x$。由于该函数,在正区域中梯度不会饱和,并且可以获得较小且非零的梯度,从而提高卷积神经网络(CNN)的准确率。此外,该计算通过简单的阈值实现,比使用sigmoid函数和tanh函数的等效方法更快。然而,该激活函数在原点处的梯度是未定义的。实际上,通常采用平滑函数 $f(x) = \ln(1+ e^x)$ 来替代,使其导数等于逻辑函数。
全连接层 :该层位于多个卷积层、最大池化层和ReLU层之后。此层类似于传统前馈神经网络中的层,其神经元与前一层的所有激活值完全连接。该层被视为最终的特征选择层。输出通过矩阵乘法和偏置加法计算得出。此外,与传统的前馈神经网络一样,这些层的权重通过最小化训练误差来估计。
损失层 :在卷积神经网络的最后一层,应用损失函数来衡量卷积神经网络预测结果与真实目标之间的差异。存在多种损失函数。欧氏损失可用于实值回归问题。Softmax损失用于从K个互斥类别中分配单个类别的标签。交叉熵损失通常用于分类问题中计算0到1范围内的K个独立概率输出。
卷积神经网络(CNNs)使用随机梯度下降进行训练。首先,输入数据通过前向传播通过不同层进行方向传递。其次,在数字滤波器提取每一层的显著特征后,计算输出值。然后,计算实际输出与网络输出之间的误差,并通过反向传播来最小化该误差。卷积神经网络(CNNs)的权重进一步调整以进行微调。因此,端到端学习过程在卷积神经网络(CNNs)中得以成功,实现了从原始输入图像数据到目标类别的直接映射,而无需先验知识和人为干预。
2.2. 支持向量机
给定 $L$ 个训练样本 $(x_1, y_1), \ldots, (x_L, y_L)$,其中 $x \in \mathbb{R}^n$, $y \in {-1, 1}$,支持向量机构造一个最优分离面,形式为 $y_i(w^T \phi(x_i) + b) \geq 1$,其中 $\phi(\cdot)$ 是一个线性/非线性映射函数,$w \in \mathbb{R}^n$ 表示法向量,$b \in \mathbb{R}$ 确定分离超平面的偏移量。通过最大化两类中最靠近超平面的点之间的最小距离 $\frac{2}{|w|}$(称为边界),可以获得最优分离面。此外,支持向量机的公式允许存在被错误分类的边界内训练样本,即 $y_i(w^T \phi(x_i) + b) < 1$。带有不等式约束的支持向量机公式旨在同时最小化训练误差和泛化误差,如下所示:
$$
\min_{w, b, \xi} \quad C \sum_{i=1}^{L} \xi_i + \frac{1}{2} |w|^2 \tag{1}
$$
$$
\text{subject to} \quad y_i(w^T \phi(x_i) + b) \geq 1 - \xi_i, \quad \xi_i \geq 0 \tag{1a}
$$
其中,第一项绝对误差之和${\xi_1}$表示类内边界错误分类训练样本与分离超平面之间距离的度量。第二项定义了边界,$C$ 是一个参数,用于控制训练集中每个错误分类点所导致的惩罚。通常,较大的 $C$ 值会导致支持向量机结构的边界更小且训练准确率更高。另一方面,相对较小的 $C$ 值可以产生更大的边界和更好的泛化准确率。
首先将拉格朗日乘子法应用于式(1)中的原始问题,如下所示:
$$
\hat{L} {\text{primal}}(w, b, \xi, \lambda, \beta) = C \sum {i=1}^{L} \xi_i + \frac{1}{2} |w|^2 - \sum_{i=1}^{L} \lambda_i [y_i(w^T \phi(x_i) + b) - 1 + \xi_i] - \sum_{i=1}^{L} \beta_i \xi_i \tag{2}
$$
其中 $\lambda_i \geq 0$ 和 $\beta_i \geq 0$ 是拉格朗日乘子。
通过关于$w$、$b$和$\xi_i$最小化以及关于$\lambda_i$和$\beta_i$最大化来求解(2)中的无约束问题,如下所示:
$$
\frac{\partial \hat{L} {\text{primal}}}{\partial w} = 0 \Rightarrow w = \sum {i=1}^{L} \lambda_i y_i \phi(x_i) \tag{3}
$$
$$
\frac{\partial \hat{L} {\text{primal}}}{\partial b} = 0 \Rightarrow \sum {i=1}^{L} \lambda_i y_i = 0 \tag{4}
$$
$$
\frac{\partial \hat{L}_{\text{primal}}}{\partial \xi_i} = 0 \Rightarrow \lambda_i + \beta_i = C \tag{5}
$$
并应用卡鲁什-库恩-塔克最优条件:
$$
\lambda_i[y_i(w^T \phi(x_i) + b) - 1 + \xi_i] = 0 \tag{6}
$$
$$
\beta_i \xi_i = 0 \Rightarrow 0 \leq \lambda_i \leq C \quad \text{for} \quad \lambda_i \geq 0, \beta_i \geq 0, \xi_i \geq 0, \quad \text{for} \quad i = 1,\ldots,L \tag{7}
$$
通过引入$\lambda_i$的使用,以及(3)中的所有原始变量,并引入核函数$K(x_i, x_j) = \phi(x_i)^T \phi(x_j)$(假设为对称正定),可得到如下称为(2)的对偶形式的二次优化问题:
$$
\max_{\lambda} \quad L_{\text{dual}}(\lambda) = -\frac{1}{2} \sum_{i,j=1}^{L} \lambda_i \lambda_j y_i y_j K(x_i, x_j) + \sum_{i=1}^{L} \lambda_i \tag{8}
$$
$$
\text{subject to} \quad \sum_{i=1}^{L} y_i \lambda_i = 0, \quad 0 \leq \lambda_i \leq C, \quad i = 1,\ldots,L \tag{8a}
$$
通过使用二次规划求解对偶问题(8)中的 $\lambda_i$,构建支持向量机的分离超平面如下:
$$
f(x) = \text{sign}\left( \sum_{\text{support vectors}} y_i \lambda_i K(x_i, x_j) + b \right) \tag{9}
$$
其中支持向量是对应于 $\lambda_i > 0$ 的数据点 $x_i$,$K(x_i, x_j)$ 是一个核函数。对于线性基,其定义为 $K(x_i, x_j) = (x_i)^T (x_j)$;对于径向基,其定义为 $K(x_i, x_j) = \exp\left(-\frac{|x_i - x_j|^2}{2\sigma^2}\right)$,其中 $\sigma$ 是核函数的扩散参数。
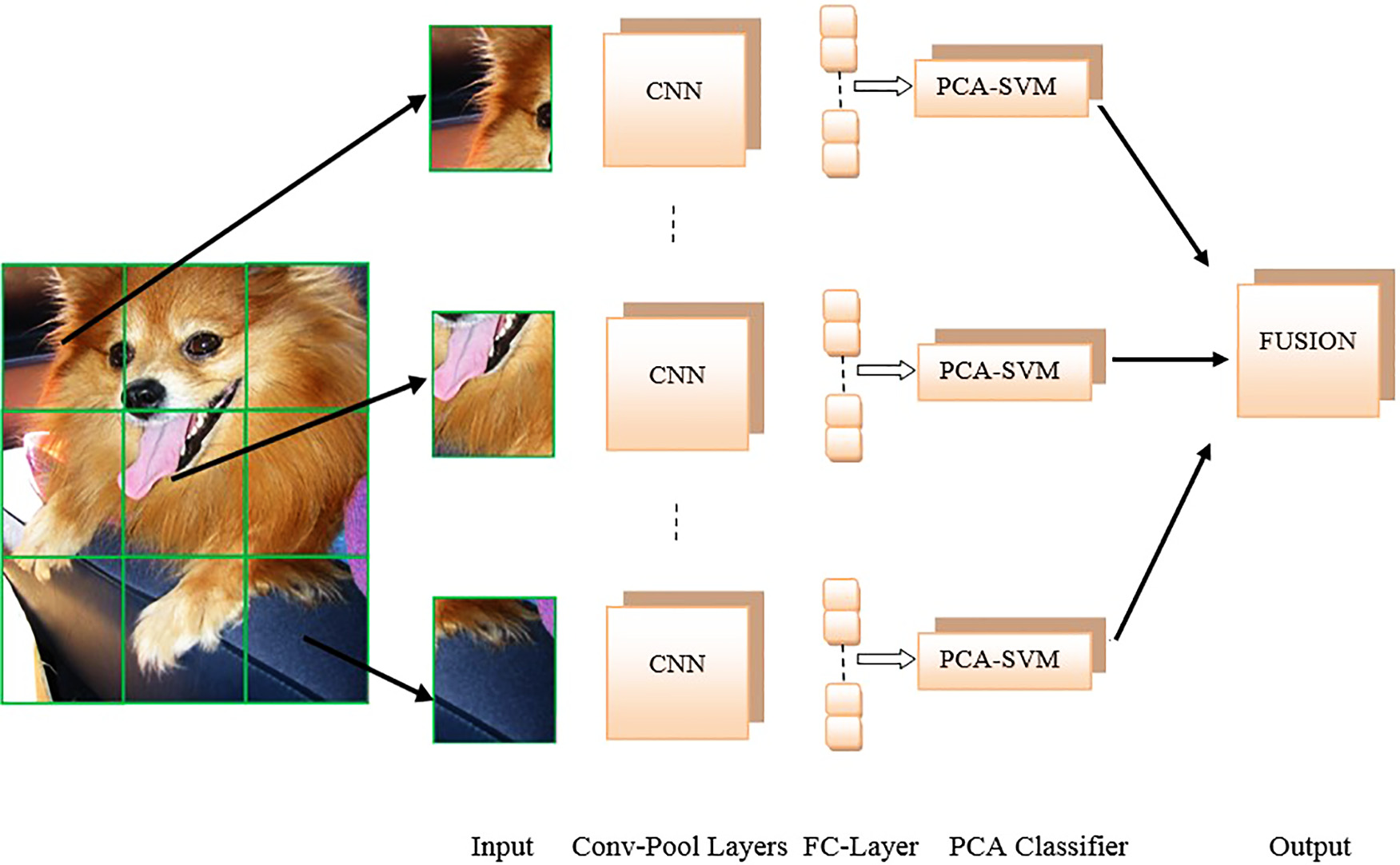
2.3. 提出的局部多CNN-SVM系统
在本文中,我们提出使用混合LM-CNN系统替代单一CNN系统,以学习与完整目标相关的显著特征。我们首先将整幅图像划分为局部区域,并应用LM-CNNs提取局部区域的判别性特征。CNN训练仅基于训练误差最小化,类似于前馈神经网络。前馈神经网络的泛化性能低于支持向量机(SVM),因为SVM同时最小化结构风险和经验风险。因此,我们将局部卷积神经网络的最后一层输出层替换为SVM分类器,以弥补CNN的局限性。CNN的全连接层表示为前一层隐藏层输出的线性组合,该组合由权重和偏置项表示。此外,该层的输出作为CNN最后一层的输入。CNN通过softmax激活函数为每幅输入图像提供类别概率。另一方面,我们的工作将CNN全连接层的输出用作SVM的输入。我们通过从CNN获得的特征提高了SVM的泛化性能。因此,我们克服了CNN的局限性,结合了卷积神经网络和支持向量机分类器。所提出的方法类似于特征融合,但该方法的特征提取过程与传统学习方法不同。

该提出的算法按以下八个步骤进行应用。
(1) 所有图像被划分为局部区域。(2) 每个图像块被调整为固定大小,即64×64×3,并转换为灰度图像。(3) 每个图像块被输入到预训练的AlexNet(如表1所示)和所提出的卷积神经网络(如表2所示)。(4) 所有网络均通过随机梯度下降进行训练。(5) 从网络的最终全连接层中提取的显著特征被保存。(6) 采用主成分分析(PCA)对保存的特征进行降维。(7) 对降维后的特征应用SVM分类器。使用一对余方法解决多类分类问题。(8) 采用决策融合来合并多类SVM分类器的输出。
注意,池化层用于在卷积神经网络中对卷积后的特征进行选择,而PCA则用于在将卷积神经网络获得的大量特征导入输入之前对其进行降维。
支持向量机。因此,所获得的特征是去相关的,并且分类能够以较少的计算量快速实现。在本文中,特征维度固定为800以实现快速且准确的解决方案。此外,我们在所提出的算法中采用了两种不同的网络架构。在第一种架构中,我们构建了一个预训练的AlexNet。AlexNet具有五个卷积层,其中一些卷积层后接最大池化层,以及三个全连接层,如表1所示。当我们使用预训练的AlexNet网络时,会将每张图像或每个图像块(227×227)调整大小,以匹配AlexNet输入的维度。在第二种架构中,我们构建了一个九层卷积神经网络,其架构如表2所示。在此网络架构中,相较于AlexNet增加了两个卷积层,并减少了一个全连接层。因此设计了一个更深的模型,从而带来更好的性能。
所提出的系统也可用于目标检测。在目标检测中,每幅图像被划分为多个图像块,然后将其调整为固定输入尺寸。使用预训练的AlexNet和所提出的网络来提取与每个图像块相关的特征。一个二分类
| 表1. AlexNet的全卷积结构。 |
|---|
| Type |
| 输入 |
| 卷积1 |
| 最大池化1 |
| 卷积2 |
| 最大池化2 |
| 卷积3 |
| 卷积4 |
| 卷积5 |
| 最大池化5 |
| 全连接6 |
| 全连接7 |
| 全连接8 |
| 表2. 提出的卷积神经网络的全卷积结构。 |
| :— |
| Type | 滤波器-步长 | 特征图 |
| 输入 | 64×64 | 1 |
| 卷积1 | 3×3-1 | 64 |
| 卷积2 | 3×3-1 | 64 |
| 平均池化2 | 2×2-2 | 64 |
| 卷积3 | 3×3-1 | 96 |
| 最大池化3 | 2×2-2 | 96 |
| 卷积4 | 5×5-1 | 256 |
| 最大池化4 | 3×3-2 | 256 |
| 卷积5 | 3×3-1 | 384 |
| 卷积6 | 3×3-1 | 384 |
| 卷积7 | 3×3-1 | 256 |
| 最大池化7 | 3×3-2 | 256 |
| 全连接8 | 6×6-1 | 4096 |
| 全连接9 | 1×1 | 1×1×类别数量 |
然后使用这些特征训练线性SVM分类器用于目标检测。
3. 实验
为了评估所提出的LM-CNN-SVM系统的性能,我们在本节中对两个知名数据集进行了实验——Caltech-101 和Caltech行人。我们使用MATLAB中的 MatConvNet和Vlfeat工具箱进行实验。MatConvNet是一个计算机视觉工具箱,得益于CUDA的支持,可以利用GPU。在我们的实验中,我们使用了NVIDIA GTX960。
3.1. 目标识别的实验结果
我们使用了Caltech-101数据库进行目标识别。该数据库包含101个物体类别,以及一个由9144张图像组成的背景类别,各类别之间具有较大的类间差异性。每 个类别的图像数量不同,介于31到800张之间。数据库既包括刚性物体,例如飞机、汽车、自行车、椅子、汽车和相机,也包括非刚性物体,例如羊、狮子和牛。为了公平比较,我们根据先前研究中使用的实验设置流程构建了训练集和测试集。我们通过每种类别随机选择15张或30张图像来构建训练集,而测试集则每类不超过50张图像,因为某些类别的维度非常小。我们通过对所有图像的每个像素减去像素均值的方式对每张图像进行了归一化处理。
将每张图像划分为九个区域,然后将其调整为64×64×3。我们将所有图像转换为灰度图像,并将所有图像按数组形式排列成矩阵。我们采用随机梯度下降方法,最小批量大小为30,权重和偏置的学习率分别为0.001和0.02。在使用LM-CNNs提取特征后,我们对最终全连接层的输出应用了主成分分析(PCA)。将降维后的特征作为输入送入线性SVM分类器。为了确定正则化参数,我们在$2^{-10}$到 $2^{10}$的范围内采用了五折交叉验证。我们融合了与每个路径相关的SVM分类器的输出。为此,我们采用基于加权多数投票规则的决策融合规则。
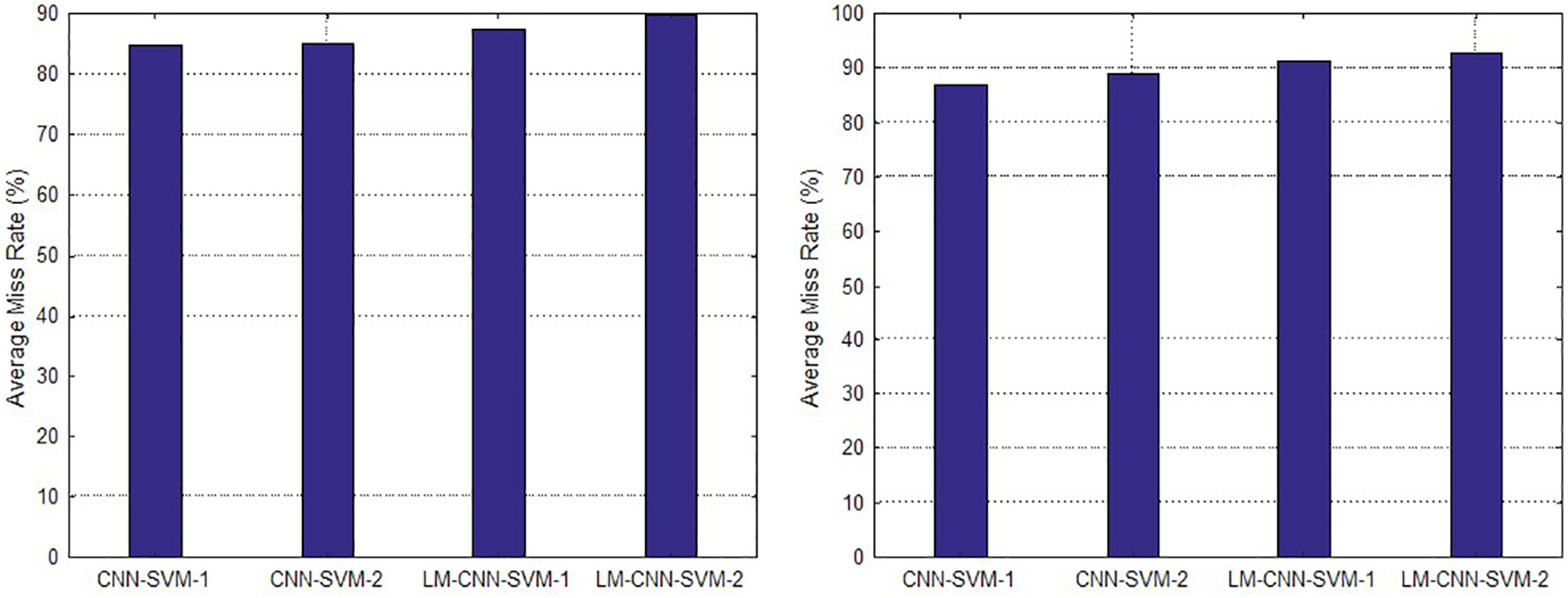
所有实验均使用不同随机选择的训练和测试图像重复了10次,并记录每次运行中每类识别率的平均值。在图表中,CNN-SVM-1和CNN-SVM-2分别表示使用 AlexNet和所提出的CNN架构的获得系统。图4显示了所提出的单CNN-SVM-1和2系统以及LM-CNN-SVM-1和2系统在Caltech-101数据库上的分类准确率。如图4所示,对于每类15张图像的情况,所提出的单CNN-SVM-1和2系统以及LM-CNN-SVM-1和2系统的每类识别率平均值分别为84.80、84.93、87.43和89.80;而对于每类30张图像的情况,它们分别为86.80、88.80、91.13和92.80。单CNN-SVM系统与LM-CNN-SVM系统之间的比较表明,LM-CNN-SVM系统始终优于单
| 表3. 所提出的局部多重卷积神经网络-支持向量机(LM-CNN-SVM)模型与其它最先进的模型在Caltech-101基准数据集上的比较。 |
|---|
| 方法 |
| 多路径分层匹配追踪模型50 |
| 线性空间金字塔匹配模型51 |
| 大卷积网络模型52 |
| 应用空间金字塔池化过程层的CNN模型53 |
| 慢速CNN模型54 |
| 提出的局部多重卷积神经网络-支持向量机 |
M-HMP:多路径分层匹配追踪模型;ScSPM:线性空间金字塔匹配模型;LCNM:大规模卷积网络模型;SPP-Net:应用空间金字塔池化过程层的CNN模型;CNN S TUNE-CLS:慢速CNN模型。
CNN-SVM系统。从卷积神经网络(CNNs)中提取的特征使得SVM分类器更加准确,因为每个局部区域都表现出相似纹理结构的特性。此外,我们评估了当前最先进的方法,包括深度学习和空间金字塔匹配(SPM),后者被称为词袋模型(BoW)的扩展版本。这些方法简要定义如下:
M-HMP50:多路径分层匹配追踪模型,通过多路径从图像中提取表达性特征,类似于深度学习。
ScSPM51:使用线性核的线性SPM模型,基于SIFT稀疏编码的空间金字塔池化。
LCNM52:使用多层反卷积网络方法来可视化特征激活的大规模卷积网络模型。
应用空间金字塔池化过程层的CNN模型53:一种通过应用空间金字塔池化过程层来消除卷积神经网络固定尺寸约束的卷积神经网络。
CNN S TUNE-CLS54:使用深度表示与线性SVM组合的慢速CNN模型,包含小步长滤波器。
所提出的LM-CNN-SVM系统与多种先进方法的详细对比结果方法的每类准确率平均值如表3所示。对于每类15张图像的情况,ScSPM和LCNM的性能分别为73.20%和83.80±0.50%。对于每类30张图像的情况,M-HMP、ScSPM、LCNM、SPP-Net和CNN S TUNE-CLS的性能分别为81.40±0.33%、84.30%、86.50±0.5%、91.44±0.70%和88.35±0.56%。我们取得的最佳结果为:每类15张图像时达到89.80±0.50%,每类30张图像时达到92.80±0.43%。可以看出,我们的局部多混合系统在目标识别方面优于竞争对手。此外,训练图像数量的增加也提升了性能。这表明丰富特征对于大类别和大尺寸图像的识别至关重要。
3.2. 行人检测实验结果
在目标检测应用中,我们使用了Caltech行人基准数据集。Caltech数据集是在城市环境中,通过一辆行驶在常规交通中的车辆拍摄的640×480分辨率、30 Hz的视频,经过11个会话采集而成。我们使用前五个子集进行训练,其余部分用于测试。我们使用了行人图像高度大于50像素且至少有65%的身体部分可见。我们生成了Dollar等人中的标签和评估代码。在此应用中,由于行人的维度较小,我们将图像划分为16个图像块以实现正确的行人检测。我们移除了结果图像中不包含行人的区域。与Sun55的方法类似,我们采用平均漏检率来总结检测器的性能,如同之前的方法一样。图5显示了提出的算法在Caltech行人数据集上的平均漏检率。从图5可以看出,所提出的单CNN-SVM-1和2系统以及LM-CNN-SVM-1和2系统的平均漏检率分别为41.12%、39.44%、33.43%和30.00%。LM-CNN-SVM-2的性能优于LM-CNN-SVM-1和其他单卷积神经网络(CNNs)。
| 表4. 所提出的局部多卷积神经网络-支持向量机(LM-CNN-SVM)模型与Caltech行人数据集上其他的最先进的模型的比较。 |
|---|
| 方法 |
| ConvNet56 |
| 直方图交集核支持向量机57 |
| 梯度方向直方图支持向量机6 |
| JointDeep58 |
| 包含多个可切换层的CNN模型59 |
| MT-DPM+ Context60 |
| 应用滑动窗口于图像的CNN模型61 |
| DeepCascade62 |
| Katamari63 |
| 提出的LM-CNN-SVM-2 |
HIKSVM:直方图交集核支持向量机;HOG-SVM:梯度方向直方图支持向量机;SDN:包含多个可切换层的CNN模型;DNNSliding:应用滑动窗口于图像的CNN模型。
我们将所提出的方法与最先进的模型(包括深度学习和HOG)进行了比较。这些方法如下所示。
ConvNet56:通过无监督和有监督方法结合生成的卷积神经网络模型。
直方图交集核支持向量机57:一种使用直方图交集核 (HIK)和SVM分类器的快速模型。
HOGSVM6:一种用于目标检测的基础模型,结合了HOG和支持向量机。
JointDeep 58:一种结合了快速特征级联、全特征提取、遮挡处理、形变处理和分类的统一深度模型。
SDN59:基于受限玻尔兹曼机构建的包含多个可切换层的CNN模型。
MT-DPM+ Context60:应用多分辨率感知变换和HOG的上下文多任务可变形部件模型。
DNNSliding61:应用滑动窗口于图像的CNN模型。
DeepCascade62:使用深度网络构建的极快级联分类器。
Katamari63:扩展积分通道特征方法。
从表4给出的结果可以看出,ConvNet、HIKSVM、HOG-SVM、JointDeep、SDN、MT-DPM+ Context、DNNSliding、DeepCascade 和 Katamari 的平均漏检率分别为77.20%、73.39%、66%、39.3%、37.8%、37.64%、32.4%、26.1% 和 22.0%,而LM-CNN-SVM-2的平均漏检率为30%。通过这些分析可以明显看出,所提出的平均漏检率为30%的LM-CNN-SVM-2方法优于大多数基于深度学习和HOG的方法。但有一个例外。根据贝嫩森等人63的研究可知,尽管Katamari方法提供了较低的平均漏检率,但其误报值非常高。这些误报在自动驾驶车辆应用中可能引发交通事故。另一方面,级联深度分类器比我们提出的方法更快,因为他们未使用SVM等额外的分类器。实验表明,所提出的深度模型优于最先进的算法,但贝嫩森等人提出的方法63除外。所提出的LM-CNN-SVM系统在部分遮挡、阴影和背景杂乱情况下进行行人检测时取得了良好的效果。
4. 结论
在本研究中,我们提出了一种结合卷积神经网络和支持向量机的混合系统,用于目标识别和行人检测。在真实环境中,物体的外观由于光照条件的变化、部分遮挡、阴影的存在以及周围背景的杂乱,情况各不相同。在自动驾驶车辆应用中,这可能导致错误的目标识别和目标检测,从而引发危险事件。本文提出了一种LM-CNN-SVM系统来应对这些挑战。在我们的系统中,使用了预训练AlexNet架构和一种包含九层的新CNN架构。我们将整幅图像分割成若干图像块,并利用CNN提取其判别性特征。然后对CNN获取的特征进行主成分分析(PCA),以实现去相关性和降维。最后,将这些特征输入到SVM分类器中,以提高系统的泛化能力,并最终通过多数投票规则有效融合图像结果。
通过Caltech-101数据集上每类准确率的平均值验证了所提出的目标识别方法的有效性。实验结果表明,该方法在目标识别中表现优异。观察到LM-CNN-SVM系统在每类15和每类30张图像的情况下分别达到了89.80±0.50和92.80±0.5的最高准确率。同时,对深度学习方法和HOG方法进行了比较研究。结果表明,LM-CNN-SVM系统在识别性能方面显著优于最先进的方法。
LM-CNN-SVM系统还被应用于目标检测。其性能通过Caltech行人数据集上的平均漏检率进行评估。实验结果表明,所提出的方法在目标识别中达到了较低的漏检率。该方法将继续提升目标识别与检测的准确率和速度,以适用于实时应用。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)