基于Hadoop的招聘网站数据可视化分析系统--28651(免费领源码)原创的定制程序,java、PHP、python、C#小程序、文案全套、毕设程序定制/毕设成品等等.
摘要: 本研究构建了一个基于Hadoop的招聘网站数据可视化分析系统,通过Python爬虫技术从主流招聘网站采集招聘信息,利用Hadoop框架进行数据清洗和分析。系统采用B/S架构,结合MySQL数据库存储结构化数据,实现了招聘数据的多维度统计与可视化展示。研究内容包括:1)基于Scrapy框架的招聘信息爬取;2)使用HDFS存储和MapReduce处理海量数据;3)通过Spark进行薪资分布、学
随着互联网技术的发展,招聘行业对数据处理和分析的需求日益增长。然而,传统招聘网站在海量数据的采集、清洗及分析方面存在不足,难以满足企业和求职者对精准信息匹配的需求。本研究旨在构建一个基于Hadoop的招聘网站数据可视化分析系统,以解决上述问题。
系统通过Python爬虫技术从主流招聘网站抓取招聘信息,并利用MapReduce算法进行数据去重与清洗。获取的数据存储于HDFS中,随后使用Spark进行多维度分析,涵盖薪资分布、学历要求、工作地点等关键指标。这些分析结果不仅展示了当前招聘市场的趋势,还为企业决策提供了有力支持。为实现系统的高效运行,我们明确了普通用户、招聘公司和管理员的角色及其功能模块。此外,招聘数据来源于爬虫程序抓取的真实数据,通过结构化处理后分列为多个字段,确保数据的准确性和完整性。
系统的开发具有重要的理论与实践意义。一方面,它填补了传统招聘网站在数据深度挖掘和可视化方面的空白,为招聘行业的数字化转型提供了技术支持;另一方面,通过精准的职位推荐和全面的数据分析,有效提升了求职者与企业之间的匹配效率,促进了人力资源市场的健康发展。
关键词:Python;Hadoop;招聘网站数据可视化分析;大数据
With the development of Internet technology, there is a growing demand for data processing and analysis in the recruitment industry. However, traditional recruitment websites are deficient in the collection, cleaning and analysis of massive data, which is difficult to meet the needs of enterprises and job seekers for accurate information matching. The purpose of this study is to construct a data visualization and analysis system for recruitment websites based on Hadoop to solve the above problems.
The system uses Python crawler technology to scrape recruitment information from mainstream recruitment websites, and uses MapReduce algorithm to deduplicate and clean data. The acquired data is stored in HDFS, and then Spark is used for multi-dimensional analysis, covering key indicators such as salary distribution, educational requirements, and work location. These analyses not only demonstrate current trends in the recruitment market, but also provide strong support for corporate decision-making. In order to achieve the efficient operation of the system, we have clarified the roles and functional modules of general users, recruitment companies, and administrators. In addition, the recruitment data comes from the real data captured by the crawler, which is structured and divided into multiple fields to ensure the accuracy and completeness of the data.
The development of the system has important theoretical and practical significance. On the one hand, it fills the gap of traditional recruitment websites in terms of data in-depth mining and visualization, and provides technical support for the digital transformation of the recruitment industry. On the other hand, through accurate job recommendation and comprehensive data analysis, the matching efficiency between job seekers and enterprises has been effectively improved, and the healthy development of the human resources market has been promoted.
Keywords: Python; Hadoop; Visualization and analysis of recruitment website data; Big data
目录
1.1选题背景
随着信息技术的迅猛发展,互联网已成为人们获取信息的主要渠道之一,尤其是在招聘领域,各类在线招聘平台如雨后春笋般涌现,极大地改变了求职者与企业之间的互动方式。然而,随着招聘信息量的爆炸式增长,如何有效地采集、处理和分析这些海量数据成为了一个亟待解决的问题。传统招聘网站在数据整合、深度挖掘及可视化展示方面存在明显不足,难以满足用户对高效信息匹配的需求。因此,探索新的技术手段来提升招聘网站的数据处理能力显得尤为重要。
大数据技术的发展为解决上述问题提供了可能。大数据不仅意味着数据量的巨大,更涵盖了数据类型的多样性、数据生成速度的快速性以及对数据价值的深度挖掘。爬虫技术作为大数据采集的重要手段,能够自动化地从网络上抓取大量公开的信息资源,是构建高效招聘网站不可或缺的一环。通过Python等编程语言编写的爬虫程序,可以从多个招聘网站批量获取招聘信息,并将其存储到分布式文件系统中进行后续处理。
然而,仅仅拥有大量的原始数据并不足以支持有效的决策制定,还需要对这些数据进行清洗、去重和分析。Hadoop作为一个开源的大数据处理框架,提供了一套完整的解决方案,包括分布式文件系统HDFS用于数据存储,MapReduce用于大规模数据集的并行计算。借助于Hadoop的强大功能,可以轻松应对海量招聘信息的处理需求;同时,利用Spark进行实时数据分析,可以迅速提取出有价值的信息,如薪资分布、学历要求、行业趋势等。此外,为了更好地服务于不同用户群体,系统还需具备多维度的数据分析能力。通过对爬取的数据进行细致的分类和标签化管理,可以实现更加精准的职位推荐和服务优化。对于企业而言,则可以通过分析市场上的招聘需求,调整自身的招聘策略以吸引更多优秀人才。
值得注意的是,虽然当前市场上已经存在一些基于大数据技术的招聘平台,但在实际应用中仍面临诸多挑战。一方面,由于招聘行业的特殊性,数据来源广泛且形式多样,如何保证数据的质量和及时更新是一个关键问题;另一方面,随着隐私保护意识的增强,如何在合法合规的前提下合理利用用户数据也成为了研究的重点方向。为此,本研究将深入探讨如何利用先进的大数据技术和合理的数据治理策略,构建一个既能够充分挖掘招聘信息价值又能保障用户隐私安全的招聘网站数据可视化分析系统。这不仅有助于提升用户体验,促进人力资源市场的健康发展,同时也为相关领域的理论研究和技术实践提供了宝贵的参考。
1.2研究目的和意义
本研究旨在通过整合爬虫技术、Hadoop大数据处理框架以及先进的数据分析方法,构建一个高效、精准的招聘网站数据可视化分析系统。具体而言,本研究将开发一套自动化工具,用于从多个主流招聘网站批量抓取招聘信息,并利用Hadoop及其相关组件对这些数据进行清洗、去重和多维度分析。此外,系统还将设计用户友好的前端界面,以直观的图表形式展示分析结果,为求职者提供个性化的职位推荐服务,为企业提供全面的数据支持,帮助其优化招聘策略。最终,该系统不仅能够显著提升信息匹配效率,还将探索如何在保障用户隐私的前提下合理利用大数据资源。
本研究具有重要的理论与实践意义。理论上,它填补了传统招聘平台在大数据采集、处理及深度挖掘方面的不足,为招聘行业的数字化转型提供了新的思路和技术路径。通过深入探讨基于Hadoop的大规模数据处理方案,本研究不仅丰富了大数据技术的应用场景,还为后续研究奠定了坚实的基础。实践上,本系统通过提供精准的信息服务,有效解决了求职者与企业之间信息不对称的问题,提升了人力资源市场的运作效率。特别是,在当前快速变化的就业市场中,系统提供的实时数据分析功能可以帮助企业和求职者及时了解行业动态,制定更为科学合理的决策。此外,本研究强调数据治理和隐私保护的重要性,提出了一系列保障措施,确保在合法合规的前提下充分利用大数据资源,这为其他领域的数据应用提供了有益的借鉴。因此,无论是对于推动招聘行业的创新发展,还是对于促进大数据技术的广泛应用,本研究都具有不可忽视的价值。
1.3国内外研究现状
在国内,招聘网站数据处理与分析的研究起步相对较晚,但随着互联网技术的快速发展和大数据时代的到来,相关领域的研究取得了显著进展。近年来,国内学者和企业开始关注如何利用Hadoop、Spark等大数据技术解决海量招聘信息的存储与计算问题,并结合Python等工具进行数据挖掘与可视化分析。例如,部分高校和科研机构已开展基于爬虫技术的信息采集研究,为企业提供精准的市场洞察。同时,国内主流招聘平台如前程无忧、智联招聘等也在积极探索智能化服务,通过算法推荐提升用户匹配效率。然而,在基础理论研究和技术创新方面,国内仍需进一步加强,特别是在跨学科融合与国际前沿技术接轨上存在一定的提升空间。
在国外,招聘网站数据分析的研究起步较早,尤其是在欧美国家,相关领域已形成较为成熟的理论体系和技术框架。自20世纪末以来,国外学者便开始探索如何利用信息技术优化人力资源配置,并逐步将大数据、人工智能等先进技术应用于招聘行业。目前,国外研究主要集中在以下几个方面:一是利用分布式计算框架实现大规模数据的高效处理;二是通过机器学习算法改进职位匹配精度;三是借助先进的数据可视化工具为用户提供直观的分析结果。此外,国外企业普遍注重用户体验和个性化服务,例如LinkedIn等平台已成功将社交网络与招聘功能深度融合,形成了独具特色的商业模式。总体来看,国外在该领域的研究水平处于全球领先地位,但仍面临成本控制和技术更新等挑战。
1.4主要研究内容
本研究的核心在于构建一个基于Hadoop的招聘网站数据可视化分析系统,通过整合爬虫技术、大数据处理框架以及数据分析工具,实现对海量招聘信息的有效采集、处理与分析。以下是具体的研究内容点:
1.爬取数据展示和分析
通过对从各大招聘网站爬取的数据进行清洗和整理后,使用Python中的Pandas和Matplotlib等库进行初步的数据探索性分析,包括但不限于薪资分布、学历要求、工作地点等维度。这些分析结果将通过前端界面以直观的图表形式展示给用户,如柱状图、饼图和折线图,帮助用户快速理解当前市场的招聘趋势和个人竞争力评估。
2.系统用例图搭建
系统设计阶段首先绘制详细的用例图,明确普通用户、招聘公司及管理员三类角色的功能需求。普通用户可以浏览职位信息、预约面试;招聘公司能够管理发布的职位和审核面试预约;管理员则负责整个平台的数据统计、系统管理和公告发布等工作。用例图详细描述了每个角色在不同场景下的操作流程,确保系统开发过程中功能模块的设计合理性和完整性。
3.爬取数据来源
数据来源主要为国内外知名的招聘网站,如智联招聘、前程无忧等,通过编写Python爬虫脚本定期抓取最新的招聘信息。获取的数据首先存储于HDFS中,然后利用MapReduce算法进行数据清洗,去除重复记录,并确保数据的一致性和准确性。接下来,采用Spark对清洗后的数据进行多维度分析,包括但不限于薪资范围、学历要求、工作经验年限等,揭示市场趋势和潜在机会。
4.招聘数据来源
招聘数据来源于上述爬虫程序抓取的真实招聘信息,经过结构化处理后被分割成多个字段,如职位名称、公司名称、薪资范围、学历要求、工作地点等。这些字段不仅有助于提高数据检索效率,也为后续的数据分析提供了基础。在数据库设计阶段,根据实际业务需求定义相应的表结构,将爬取的信息按照预设的字段进行分类存储,以便于查询和分析。同时,通过合理的索引设计优化查询性能,保证系统的高效运行。
综上所述,本研究通过一系列的技术手段实现了从数据采集到最终可视化的全流程覆盖,旨在为用户提供精准的信息服务,为企业提供全面的数据支持,从而推动人力资源市场的健康发展。
1.5论文结构安排
本文共分为七章,章节内容安排如下:
第一章为引言,此章节对所设计和实现的系统的背景和意义、以及国内外现状进行详细的论述以及说明,同时对主要研究内容和论文整体框架的结构进行了简要介绍。
第二章为相关理论和技术介绍,主要对系统的框架、开发语言和数据库进行了简要概述。
第三章为项目概述,章节所做的主要的工作是对项目背景、项目的可行性分析与相关技术和工具简介进行了描述;对系统实行了总体功能的需求、用例进行了分析。
第四章为系统的设计,主要是对系统的功能结构进行设计,并对系统数据库的概念结构以及物理结构的设计进行了分析。
第五章就是对系统的实现,根据系统功能的划分,分别的对系统所需要实现的前台客户功能和后台管理员功能进行了分析和说明。
第六章:系统测试。主要对系统的部分界面进行测试并对主要功能进行测试
第七章:总结。
第 2 章相关理论和技术
2.1B/S体系结构介绍
B/S体系,即Browser/Server体系,是一种常见的网络应用程序架构。其工作原理基于客户端与服务器之间的请求-响应模型。用户通过浏览器向服务器发送请求,服务器接收到请求后进行处理,并生成相应的响应结果,最终将响应返回给客户端。浏览器接收到服务器返回的响应后,解析其中的标记语言(如HTML),并根据CSS样式表和PythonScript脚本来渲染页面,呈现给用户。用户可以与页面进行交互,例如点击链接、填写表单等操作,这些操作会触发新的请求,循环执行上述过程。
2.2Hadoop框架介绍
Hadoop是一种开源的分布式计算框架,专为处理大规模数据集而设计,由Apache软件基金会开发。其核心组件包括HDFS(Hadoop分布式文件系统)和MapReduce编程模型。HDFS通过将数据分布存储在多个节点上,提供了高容错性和可靠性,即使部分节点故障也能保证数据的安全与完整性。MapReduce则是一种并行计算范式,能够将复杂的计算任务分解为多个子任务,在集群中并行执行,最终汇总结果,从而大幅提升数据处理效率。此外,Hadoop生态系统还包含Hive、Spark、HBase等工具,分别支持SQL查询、实时计算和NoSQL数据库等功能。凭借强大的扩展性与灵活性,Hadoop被广泛应用于大数据存储、分析和挖掘领域,成为企业处理海量数据的核心技术之一,尤其适合需要高效处理非结构化或半结构化数据的场景。
2.3MySQL数据库
MySQL是一种广泛使用的开源关系型数据库管理系统(RDBMS),其稳定性、可靠性和卓越性能使其成为众多应用程序的首选数据库。MySQL支持标准SQL语法,并提供丰富的功能和特性,如事务处理、触发器和存储过程等,以满足开发者对数据管理和操作的需求。MySQL具有良好的可扩展性,支持主从复制、分布式架构和集群部署,适用于各种规模和负载的应用场景。作为一个开源项目,MySQL拥有庞大的用户社区和活跃的开发者社区,为用户提供了丰富的文档、教程和支持资源。总之,MySQL是一款可靠、强大且灵活的关系型数据库管理系统,通过其卓越性能和可扩展性,帮助开发者高效地管理和操作数据,并得到了广大用户的认可和应用。
2.4Python语言
Python是一种简洁易读、跨平台且功能强大的编程语言。它拥有庞大而活跃的社区,提供了丰富的第三方库和框架,如NumPy、Pandas和Django,使开发人员能够快速构建各种应用程序。Python在数据处理和科学计算方面表现出色,通过相关库和工具,可以进行数据分析、机器学习和科学计算等任务。此外,Python广泛应用于Web开发、自动化脚本、网络爬虫等领域,其多样性使其成为一个全能的编程语言。无论你是初学者还是有经验的开发者,Python的简单语法、跨平台性以及强大的社区支持都能为你提供高效、优雅和可靠的编程体验。总之,Python是一个强大而灵活的编程语言,深受开发人员喜爱,并在各个领域得到广泛应用。
2.5Scrapy爬虫技术
Scrapy是一款高效、可扩展的开源爬虫框架,能够快速构建爬虫程序以采集网页数据。在本系统中,爬虫模块通过分析目标网站的HTML结构,提取招聘公司、公司规模、招聘职位、招聘薪资、招聘学历、招聘人数、工作地点、招聘要求、招聘地点等关键招聘数据信息,并将这些数据清洗后存储到MySQL数据库中。此外,系统还利用Scrapy的内置功能实现定时任务调度,确保招聘数据的实时更新。相比传统的手动数据收集方式,Scrapy不仅提高了数据采集的效率和准确性,还为系统的数据分析与可视化提供了可靠的数据基础。
3.1系统可行性分析
在软件开发的过程中,可行性分析是至关重要的,它旨在评估问题的可行性,以便尽可能快地解决,同时也要考虑到不同的解决方案的优势和劣势,以及实施这些方案所带来的经济效益。通过对招聘网站数据可视化分析系统的可行性分析,我们可以从技术、经济和操作三个方面来评估其可行性,从而为其提供有效的支持和保障。
3.1.1技术可行性分析
本系统基于Hadoop分布式框架和Python数据分析工具,技术成熟且开源资源丰富。Hadoop能够高效处理海量招聘信息,Python则提供强大的数据清洗与可视化能力。结合爬虫技术实现数据采集,前端使用ECharts展示分析结果,整体技术栈稳定可靠,开发难度可控,具备良好的技术可行性。
3.1.2经济可行性分析
系统主要依赖开源软件如Hadoop、Python等,大幅降低了开发成本。硬件方面,利用普通服务器搭建集群即可满足需求,无需高昂的专用设备投入。此外,系统可扩展性强,可根据业务增长灵活调整资源配置,总体经济投入合理,具备较高的性价比和经济可行性。
3.1.3操作可行性分析
系统设计了清晰的角色分工和功能模块,操作界面简洁直观,用户可通过简单培训快速上手。管理员后台提供便捷的数据管理工具,招聘公司可自主维护招聘信息,普通用户能轻松完成职位搜索与预约面试。同时,系统的自动化数据采集与分析流程减少了人工干预,提升了操作效率和可行性。
3.2系统需求分析
3.2.1功能需求分析
本系统旨在满足普通用户、招聘公司和管理员三类角色的不同需求,提供招聘信息的采集、管理、查询与分析功能。通过整合爬虫技术、Hadoop大数据处理框架和Python数据分析工具,系统实现了从数据采集到可视化展示的全流程支持,同时为普通用户提供职位搜索与预约服务,为招聘公司提供招聘信息管理和面试预约审核功能,为管理员提供全面的数据统计与系统管理能力。具体功能描述如下:
首页:展示热门职位推荐、最新公告及行业资讯,帮助用户快速获取关键信息。支持按行业、地区等条件筛选职位,提升查找效率。
公告消息:提供系统发布的通知和重要信息,确保用户及时了解平台动态。支持消息分类查看和历史记录查询。
招聘资讯:提供职业发展建议、行业趋势等内容,帮助用户了解市场动态。支持按类别浏览和关键词搜索。
招聘信息:提供职位详情查询功能,包括薪资、学历要求等信息。支持多条件筛选和排序,方便用户精准定位目标职位。
我的账户:管理个人资料和隐私设置,确保信息安全。支持密码修改和绑定邮箱/手机号管理。
个人中心:展示已收藏职位、预约面试记录和个人评论。支持一键取消收藏或删除评论。
2.招聘公司功能:
后台首页:展示公司发布职位的状态统计,提供直观的图表分析,帮助公司了解招聘效果。
招聘信息管理:支持新增、修改和删除职位信息,确保信息准确性和时效性。提供批量操作功能,提升管理效率。
面试预约管理:审核用户的面试预约请求,并反馈审核结果。支持查看历史预约记录和导出相关数据。
3.管理员功能:
后台首页:提供综合数据统计面板,展示招聘数据、薪资分布、学历要求等关键指标。支持自定义报表生成和导出功能。
招聘数据统计:分析职位数量、地域分布和行业趋势,生成可视化图表。支持按时间维度进行对比分析。
薪资数据统计:统计各行业薪资水平分布,揭示市场薪酬趋势。支持分学历、经验层次进行细化分析。
招聘学历统计:分析不同学历层次的岗位需求比例,为政策制定提供参考。支持多维度交叉分析。
招聘信息统计:按时间、行业和地区统计职位发布情况,评估市场供需关系。支持历史数据回溯和预测分析。
面试预约统计:统计预约人数、通过率和完成率,评估招聘流程效率。支持异常数据预警和问题追踪。
系统用户管理:管理普通用户和招聘公司账号,包括注册审核和权限分配。支持批量导入和导出用户数据。
招聘数据管理:提供数据查询、重置、删除、爬取和添加功能,确保数据完整性。支持日志记录和操作追溯。
薪资数据管理:维护薪资相关信息,支持动态更新和校验。确保数据准确性和一致性。
经验数据管理:管理工作经验相关数据,支持按年限和行业分类。为职位匹配提供基础支撑。
学历数据管理:维护学历相关信息,支持多维度管理和更新。确保数据覆盖全面且标准化。
招聘职位管理:管理职位分类和标签体系,支持灵活扩展。提升职位搜索和推荐的精准度。
轮播图管理:管理首页轮播图内容,支持图片上传和顺序调整。提升用户体验和视觉效果。
公告消息管理:发布和管理公告消息,支持定时推送和撤回功能。确保信息传递及时准确。
资源管理:管理招聘资讯和资讯分类,支持内容审核和归档。提升内容质量和管理水平。
3.2.2非功能需求分析
非功能性分析旨在评估招聘网站数据可视化分析系统的非功能需求和性能要求。通过对性能、可靠性、安全性、可用性和扩展性等方面进行评估,确保平台能够满足用户和系统运行的要求。具体如下3-1表格中:
表3-1招聘网站数据可视化分析系统非功能需求表
|
非功能性要求 |
说明 |
|
性能 |
评估响应时间、并发用户数、吞吐量等指标,以确保平台稳定高效地运行。 |
|
可靠性 |
评估系统的稳定性、容错能力和数据完整性,保障系统在故障情况下正常运行。 |
|
安全性 |
评估用户身份认证、数据加密和访问控制等,保护用户信息和交易的安全。 |
|
可用性 |
评估系统的稳定性、故障处理能力和用户界面友好性,提供良好的用户体验。 |
|
扩展性 |
评估系统的可扩展性和灵活性,以便根据需求进行功能扩展和升级。 |
3.3系统用例分析
系统用例分析是对招聘网站数据可视化分析系统中各个功能模块的用户需求和行为进行分析,以识别和描述不同的用户用例。通过系统用例分析,可以深入了解用户在平台上的操作流程和交互方式,为系统设计和开发提供指导,并确保平台能够满足用户的需求和期望。
普通用户主要围绕职位搜索、信息管理及互动展开。通过首页浏览热门职位或使用筛选功能查找目标岗位,用户可以查看详细招聘信息并进行面试预约或收藏。此外,用户还能在个人中心管理已收藏的职位、评论以及预约记录,同时通过公告消息和招聘资讯模块获取行业动态与职业建议,满足求职过程中的多样化需求。普通用户角色用例图如图3-1所示:
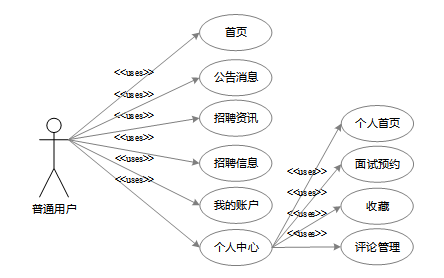
图3-1 普通用户角色用例图
招聘公司聚焦于招聘信息管理和面试预约审核。企业可通过后台发布、修改或删除职位信息,实时更新招聘需求;同时,针对用户的面试预约请求,招聘公司能够逐一审核并反馈结果,确保招聘流程高效推进。系统提供的数据统计功能还可帮助企业评估招聘效果,优化资源配置。招聘公司角色用例图如图3-2所示:
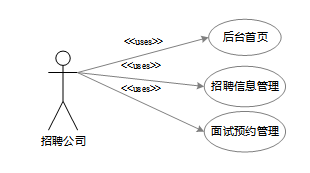
图3-2 招聘公司角色用例图
管理员涵盖系统运维、数据管理和用户维护等全方位职责。通过后台首页,管理员可全面掌握平台运行状况,并生成各类统计数据报表。在数据管理方面,管理员负责爬取、维护和重置招聘数据,确保信息准确性和完整性;同时,还需管理普通用户和招聘公司账号权限,维护公告消息和资源内容,保障系统的正常运转与用户体验。管理员角色用例图如图3-3所示:
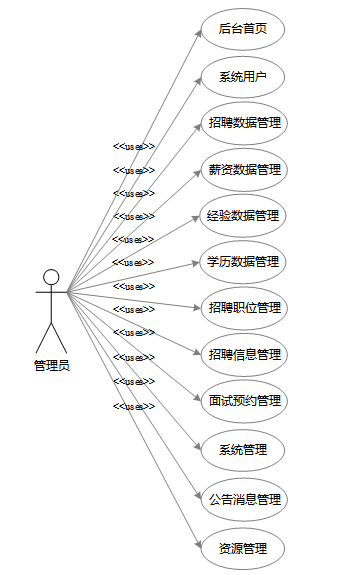
图3-3管理员角色用例图
3.4系统流程分析
业务流程是用一些特定的符合和线条来进行演示用户在使用系统时的过程,在进行系统分析的时候,业务流程可以帮助开发人员更好的理解业务,发现错误,完善系统。
3.4.1程序操作流程
用户访问平台网站,可以选择进行注册或登录操作。注册成功后,用户可以使用注册的账号登录平台。登录后的用户可以进入系统功能界面,使用自己权限内的功能操作。程序操作流程图如下图所示。
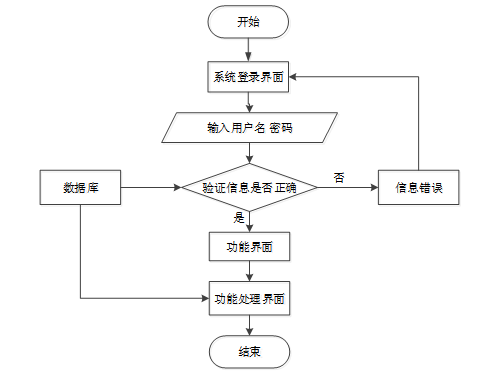
图3-4 程序操作流程图
3.4.2登录流程
用户访问平台的网站,进入登录页面页面,输入其用户名和密码,后端服务接收登录请求,验证用户提供的用户名和密码是否匹配数据库中存储的信息,验证通过即可登录成功。登录流程图如下图所示。
图3-5 登录流程图
3.4.3注册流程
未有账号的用户可进入注册界面进行注册操作,填写注册表格,包括用户名、密码、电子邮件等必要信息。后台系统验证并保存用户提交的信息。分配唯一用户标识符。注册成功后,用户可以使用账号密码进行登录。用户注册流程图如下图所示。
图3-6 注册流程图
4.1系统架构设计
在系统架构设计中,我们将确定系统的整体结构和组件之间的关系。这包括选择适当的架构风格,划分系统的层次结构,并定义各个模块的职责和交互方式。架构图如下图4-1所示。
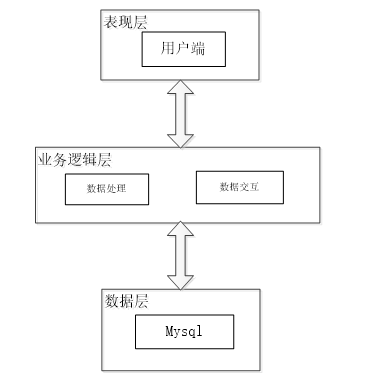
图4-1招聘网站数据可视化分析系统架构设计图
表现层(Presentation Layer):负责与用户进行交互,将系统的功能和数据以易于理解和操作的方式展示给用户。通常包括用户界面、页面设计和用户输入验证等。
业务逻辑层(Business Logic Layer):处理系统的核心业务逻辑,包括对用户请求的处理、业务规则的执行以及数据的处理和转换。它独立于表现层和数据层,实现了业务逻辑的封装和复用。
数据层(Data Layer):负责数据的存储、访问和管理,包括数据库和持久化机制。数据层提供了对数据的增删改查操作,并与业务逻辑层进行交互,使系统能够有效地存储和检索数据。
这三个层次相互独立,通过明确的接口和协议进行通信,实现了系统的模块化和可扩展性。表现层负责将用户的请求传递给业务逻辑层,业务逻辑层处理请求并返回结果,最后数据层负责与数据库交互并提供数据支持。这种分层架构有助于实现系统的可维护性、灵活性和可测试性。
4.2系统功能模块设计
通过整体功能模块设计,我们将根据需求分析的结果,将系统的功能划分为不同的模块。每个模块负责实现特定的功能,并与其他模块进行协作。我们将详细定义每个模块的输入、输出、处理逻辑和相互依赖关系。具体的功能模块图如图4-2所示。
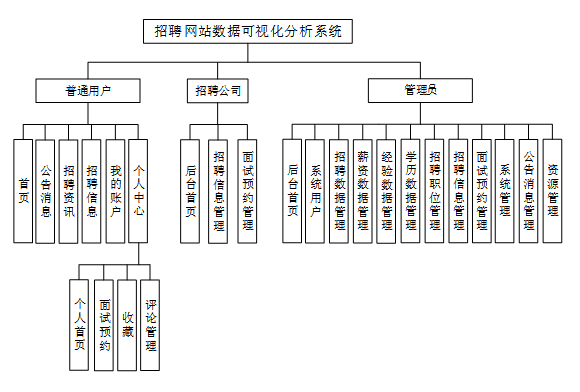
图4-2 招聘网站数据可视化分析系统功能模块图
4.3数据库设计
数据库设计是系统开发中至关重要的一环,它涉及到数据的组织、存储和管理。在数据库设计中,我们将根据系统的需求设计数据库的概念结构和逻辑结构,包括定义实体、属性、关系和约束等。
4.3.1数据库概念结构设计
数据库概念结构设计主要涉及数据库的实体和实体之间的关系。通过实体-关系模型或者其他适当的模型,我们将定义系统中涉及的各个实体以及它们之间的联系。下面是整个招聘网站数据可视化分析系统中主要的数据库表总E-R实体关系图。
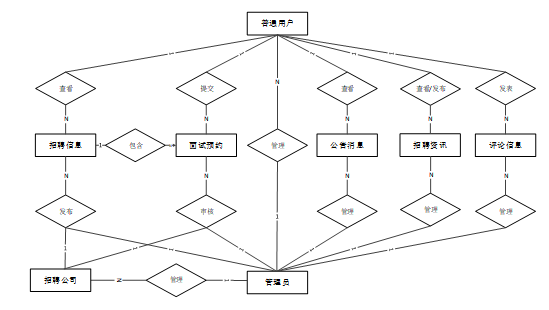
图4-3招聘网站数据可视化分析系统总E-R关系图
4.3.2数据库逻辑结构设计
数据库逻辑结构设计则是在概念结构的基础上,进行具体的数据库表设计。我们将定义每个表的结构、字段和约束,并建立表与表之间的关系。具体如下:
表access_token (登陆访问时长)
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
token_id |
int |
10 |
0 |
N |
Y |
临时访问牌ID |
|
|
2 |
token |
varchar |
64 |
0 |
Y |
N |
临时访问牌 |
|
|
3 |
info |
text |
65535 |
0 |
Y |
N |
||
|
4 |
maxage |
int |
10 |
0 |
N |
N |
2 |
最大寿命:默认2小时 |
|
5 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
6 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
7 |
user_id |
int |
10 |
0 |
N |
N |
0 |
用户编号: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
article_id |
mediumint |
8 |
0 |
N |
Y |
文章id:[0,8388607] |
|
|
2 |
title |
varchar |
125 |
0 |
N |
Y |
标题:[0,125]用于文章和html的title标签中 |
|
|
3 |
type |
varchar |
64 |
0 |
N |
N |
0 |
文章分类:[0,1000]用来搜索指定类型的文章 |
|
4 |
hits |
int |
10 |
0 |
N |
N |
0 |
点击数:[0,1000000000]访问这篇文章的人次 |
|
5 |
praise_len |
int |
10 |
0 |
N |
N |
0 |
点赞数 |
|
6 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
7 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
8 |
source |
varchar |
255 |
0 |
Y |
N |
来源:[0,255]文章的出处 |
|
|
9 |
url |
varchar |
255 |
0 |
Y |
N |
来源地址:[0,255]用于跳转到发布该文章的网站 |
|
|
10 |
tag |
varchar |
255 |
0 |
Y |
N |
标签:[0,255]用于标注文章所属相关内容,多个标签用空格隔开 |
|
|
11 |
content |
longtext |
2147483647 |
0 |
Y |
N |
正文:文章的主体内容 |
|
|
12 |
img |
varchar |
255 |
0 |
Y |
N |
封面图 |
|
|
13 |
description |
text |
65535 |
0 |
Y |
N |
文章描述 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
type_id |
smallint |
5 |
0 |
N |
Y |
分类ID:[0,10000] |
|
|
2 |
display |
smallint |
5 |
0 |
N |
N |
100 |
显示顺序:[0,1000]决定分类显示的先后顺序 |
|
3 |
name |
varchar |
16 |
0 |
N |
N |
分类名称:[2,16] |
|
|
4 |
father_id |
smallint |
5 |
0 |
N |
N |
0 |
上级分类ID:[0,32767] |
|
5 |
description |
varchar |
255 |
0 |
Y |
N |
描述:[0,255]描述该分类的作用 |
|
|
6 |
icon |
text |
65535 |
0 |
Y |
N |
分类图标: |
|
|
7 |
url |
varchar |
255 |
0 |
Y |
N |
外链地址:[0,255]如果该分类是跳转到其他网站的情况下,就在该URL上设置 |
|
|
8 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
9 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
auth_id |
int |
10 |
0 |
N |
Y |
授权ID: |
|
|
2 |
user_group |
varchar |
64 |
0 |
Y |
N |
用户组: |
|
|
3 |
mod_name |
varchar |
64 |
0 |
Y |
N |
模块名: |
|
|
4 |
table_name |
varchar |
64 |
0 |
Y |
N |
表名: |
|
|
5 |
page_title |
varchar |
255 |
0 |
Y |
N |
页面标题: |
|
|
6 |
path |
varchar |
255 |
0 |
Y |
N |
路由路径: |
|
|
7 |
parent |
varchar |
64 |
0 |
Y |
N |
父级菜单 |
|
|
8 |
parent_sort |
int |
10 |
0 |
N |
N |
0 |
父级菜单排序 |
|
9 |
position |
varchar |
32 |
0 |
Y |
N |
位置: |
|
|
10 |
mode |
varchar |
32 |
0 |
N |
N |
_blank |
跳转方式: |
|
11 |
add |
tinyint |
3 |
0 |
N |
N |
1 |
是否可增加: |
|
12 |
del |
tinyint |
3 |
0 |
N |
N |
1 |
是否可删除: |
|
13 |
set |
tinyint |
3 |
0 |
N |
N |
1 |
是否可修改: |
|
14 |
get |
tinyint |
3 |
0 |
N |
N |
1 |
是否可查看: |
|
15 |
field_add |
text |
65535 |
0 |
Y |
N |
添加字段: |
|
|
16 |
field_set |
text |
65535 |
0 |
Y |
N |
修改字段: |
|
|
17 |
field_get |
text |
65535 |
0 |
Y |
N |
查询字段: |
|
|
18 |
table_nav_name |
varchar |
500 |
0 |
Y |
N |
跨表导航名称: |
|
|
19 |
table_nav |
varchar |
500 |
0 |
Y |
N |
跨表导航: |
|
|
20 |
option |
text |
65535 |
0 |
Y |
N |
配置: |
|
|
21 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
22 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
code_token_id |
int |
10 |
0 |
N |
Y |
||
|
2 |
token |
varchar |
255 |
0 |
Y |
N |
||
|
3 |
code |
varchar |
255 |
0 |
Y |
N |
验证码 |
|
|
4 |
expire_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
失效时间 |
|
5 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
6 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
collect_id |
int |
10 |
0 |
N |
Y |
收藏ID: |
|
|
2 |
user_id |
int |
10 |
0 |
N |
N |
0 |
收藏人ID: |
|
3 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表: |
|
|
4 |
source_field |
varchar |
255 |
0 |
Y |
N |
来源字段: |
|
|
5 |
source_id |
int |
10 |
0 |
N |
N |
0 |
来源ID: |
|
6 |
title |
varchar |
255 |
0 |
Y |
N |
标题: |
|
|
7 |
img |
varchar |
255 |
0 |
Y |
N |
封面: |
|
|
8 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
9 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
comment_id |
int |
10 |
0 |
N |
Y |
评论ID: |
|
|
2 |
user_id |
int |
10 |
0 |
N |
N |
0 |
评论人ID: |
|
3 |
reply_to_id |
int |
10 |
0 |
N |
N |
0 |
回复评论ID:空为0 |
|
4 |
content |
longtext |
2147483647 |
0 |
Y |
N |
内容: |
|
|
5 |
nickname |
varchar |
255 |
0 |
Y |
N |
昵称: |
|
|
6 |
avatar |
varchar |
255 |
0 |
Y |
N |
头像地址:[0,255] |
|
|
7 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
8 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
9 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表: |
|
|
10 |
source_field |
varchar |
255 |
0 |
Y |
N |
来源字段: |
|
|
11 |
source_id |
int |
10 |
0 |
N |
N |
0 |
来源ID: |
表educational_background_data (学历数据)
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
educational_background_data_id |
int |
10 |
0 |
N |
Y |
学历数据ID |
|
|
2 |
recruitment_positions |
varchar |
64 |
0 |
Y |
N |
招聘职位 |
|
|
3 |
recruitment_salary |
varchar |
64 |
0 |
Y |
N |
招聘薪资 |
|
|
4 |
recruitment_requirements |
varchar |
64 |
0 |
Y |
N |
招聘要求 |
|
|
5 |
recruitment_experience |
varchar |
64 |
0 |
Y |
N |
招聘经验 |
|
|
6 |
recruitment_education |
varchar |
64 |
0 |
Y |
N |
招聘学历 |
|
|
7 |
recruitment_company |
varchar |
64 |
0 |
Y |
N |
招聘公司 |
|
|
8 |
company_stage |
varchar |
64 |
0 |
Y |
N |
公司阶段 |
|
|
9 |
recruitment_industry |
varchar |
64 |
0 |
Y |
N |
招聘行业 |
|
|
10 |
recruitment_skills |
varchar |
64 |
0 |
Y |
N |
招聘技能 |
|
|
11 |
recruitment_city |
varchar |
64 |
0 |
Y |
N |
招聘城市 |
|
|
12 |
recruitment_area |
varchar |
64 |
0 |
Y |
N |
招聘区域 |
|
|
13 |
company_address |
varchar |
64 |
0 |
Y |
N |
公司地址 |
|
|
14 |
company_size |
varchar |
64 |
0 |
Y |
N |
公司规模 |
|
|
15 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
16 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
|
17 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表 |
|
|
18 |
source_id |
int |
10 |
0 |
Y |
N |
来源ID |
|
|
19 |
source_user_id |
int |
10 |
0 |
Y |
N |
来源用户 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
empirical_data_id |
int |
10 |
0 |
N |
Y |
经验数据ID |
|
|
2 |
recruitment_positions |
varchar |
64 |
0 |
Y |
N |
招聘职位 |
|
|
3 |
recruitment_salary |
varchar |
64 |
0 |
Y |
N |
招聘薪资 |
|
|
4 |
recruitment_requirements |
varchar |
64 |
0 |
Y |
N |
招聘要求 |
|
|
5 |
recruitment_experience |
varchar |
64 |
0 |
Y |
N |
招聘经验 |
|
|
6 |
recruitment_education |
varchar |
64 |
0 |
Y |
N |
招聘学历 |
|
|
7 |
recruitment_company |
varchar |
64 |
0 |
Y |
N |
招聘公司 |
|
|
8 |
company_stage |
varchar |
64 |
0 |
Y |
N |
公司阶段 |
|
|
9 |
recruitment_industry |
varchar |
64 |
0 |
Y |
N |
招聘行业 |
|
|
10 |
recruitment_skills |
varchar |
64 |
0 |
Y |
N |
招聘技能 |
|
|
11 |
recruitment_city |
varchar |
64 |
0 |
Y |
N |
招聘城市 |
|
|
12 |
recruitment_area |
varchar |
64 |
0 |
Y |
N |
招聘区域 |
|
|
13 |
company_address |
varchar |
64 |
0 |
Y |
N |
公司地址 |
|
|
14 |
company_size |
varchar |
64 |
0 |
Y |
N |
公司规模 |
|
|
15 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
16 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
|
17 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表 |
|
|
18 |
source_id |
int |
10 |
0 |
Y |
N |
来源ID |
|
|
19 |
source_user_id |
int |
10 |
0 |
Y |
N |
来源用户 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
hits_id |
int |
10 |
0 |
N |
Y |
点赞ID: |
|
|
2 |
user_id |
int |
10 |
0 |
N |
N |
0 |
点赞人: |
|
3 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
4 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
5 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表: |
|
|
6 |
source_field |
varchar |
255 |
0 |
Y |
N |
来源字段: |
|
|
7 |
source_id |
int |
10 |
0 |
N |
N |
0 |
来源ID: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
interview_appointment_id |
int |
10 |
0 |
N |
Y |
面试预约ID |
|
|
2 |
recruitment_company |
int |
10 |
0 |
Y |
N |
0 |
招聘公司 |
|
3 |
company_size |
varchar |
64 |
0 |
Y |
N |
公司规模 |
|
|
4 |
recruitment_title |
varchar |
64 |
0 |
Y |
N |
招聘标题 |
|
|
5 |
recruitment_positions |
varchar |
64 |
0 |
Y |
N |
招聘职位 |
|
|
6 |
recruitment_salary |
varchar |
64 |
0 |
Y |
N |
招聘薪资 |
|
|
7 |
recruitment_education |
varchar |
64 |
0 |
Y |
N |
招聘学历 |
|
|
8 |
work_location |
varchar |
64 |
0 |
Y |
N |
工作地点 |
|
|
9 |
recruitment_requirements |
varchar |
64 |
0 |
Y |
N |
招聘要求 |
|
|
10 |
recruitment_location |
varchar |
64 |
0 |
Y |
N |
招聘地点 |
|
|
11 |
ordinary_users |
int |
10 |
0 |
Y |
N |
0 |
普通用户 |
|
12 |
user_name |
varchar |
64 |
0 |
Y |
N |
用户姓名 |
|
|
13 |
time_of_appointment |
datetime |
19 |
0 |
Y |
N |
预约时间 |
|
|
14 |
appointment_remarks |
varchar |
64 |
0 |
Y |
N |
预约备注 |
|
|
15 |
examine_state |
varchar |
16 |
0 |
N |
N |
未审核 |
审核状态 |
|
16 |
examine_reply |
varchar |
16 |
0 |
Y |
N |
审核回复 |
|
|
17 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
18 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
|
19 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表 |
|
|
20 |
source_id |
int |
10 |
0 |
Y |
N |
来源ID |
|
|
21 |
source_user_id |
int |
10 |
0 |
Y |
N |
来源用户 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
notice_id |
mediumint |
8 |
0 |
N |
Y |
公告id: |
|
|
2 |
title |
varchar |
125 |
0 |
N |
N |
标题: |
|
|
3 |
content |
longtext |
2147483647 |
0 |
Y |
N |
正文: |
|
|
4 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
5 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
ordinary_users_id |
int |
10 |
0 |
N |
Y |
普通用户ID |
|
|
2 |
user_name |
varchar |
64 |
0 |
Y |
N |
用户姓名 |
|
|
3 |
user_gender |
varchar |
64 |
0 |
Y |
N |
用户性别 |
|
|
4 |
user_age |
varchar |
64 |
0 |
Y |
N |
用户年龄 |
|
|
5 |
examine_state |
varchar |
16 |
0 |
N |
N |
已通过 |
审核状态 |
|
6 |
user_id |
int |
10 |
0 |
N |
N |
0 |
用户ID |
|
7 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
8 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
praise_id |
int |
10 |
0 |
N |
Y |
点赞ID: |
|
|
2 |
user_id |
int |
10 |
0 |
N |
N |
0 |
点赞人: |
|
3 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
4 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
5 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表: |
|
|
6 |
source_field |
varchar |
255 |
0 |
Y |
N |
来源字段: |
|
|
7 |
source_id |
int |
10 |
0 |
N |
N |
0 |
来源ID: |
|
8 |
status |
bit |
1 |
0 |
N |
N |
1 |
点赞状态:1为点赞,0已取消 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
recruitment_company_id |
int |
10 |
0 |
N |
Y |
招聘公司ID |
|
|
2 |
corporate_name |
varchar |
64 |
0 |
Y |
N |
公司名称 |
|
|
3 |
company_type |
varchar |
64 |
0 |
Y |
N |
公司类型 |
|
|
4 |
company_address |
varchar |
64 |
0 |
Y |
N |
公司地址 |
|
|
5 |
company_size |
varchar |
64 |
0 |
Y |
N |
公司规模 |
|
|
6 |
examine_state |
varchar |
16 |
0 |
N |
N |
已通过 |
审核状态 |
|
7 |
user_id |
int |
10 |
0 |
N |
N |
0 |
用户ID |
|
8 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
9 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
recruitment_data_id |
int |
10 |
0 |
N |
Y |
招聘数据ID |
|
|
2 |
recruitment_positions |
varchar |
64 |
0 |
Y |
N |
招聘职位 |
|
|
3 |
recruitment_salary |
varchar |
64 |
0 |
Y |
N |
招聘薪资 |
|
|
4 |
recruitment_requirements |
varchar |
64 |
0 |
Y |
N |
招聘要求 |
|
|
5 |
recruitment_experience |
varchar |
64 |
0 |
Y |
N |
招聘经验 |
|
|
6 |
recruitment_education |
varchar |
64 |
0 |
Y |
N |
招聘学历 |
|
|
7 |
recruitment_company |
varchar |
64 |
0 |
Y |
N |
招聘公司 |
|
|
8 |
company_stage |
varchar |
64 |
0 |
Y |
N |
公司阶段 |
|
|
9 |
recruitment_industry |
varchar |
64 |
0 |
Y |
N |
招聘行业 |
|
|
10 |
recruitment_skills |
varchar |
64 |
0 |
Y |
N |
招聘技能 |
|
|
11 |
recruitment_city |
varchar |
64 |
0 |
Y |
N |
招聘城市 |
|
|
12 |
recruitment_area |
varchar |
64 |
0 |
Y |
N |
招聘区域 |
|
|
13 |
company_address |
varchar |
64 |
0 |
Y |
N |
公司地址 |
|
|
14 |
company_size |
varchar |
64 |
0 |
Y |
N |
公司规模 |
|
|
15 |
salary_data_limit_times |
int |
10 |
0 |
N |
N |
0 |
薪资统计限制次数 |
|
16 |
empirical_data_limit_times |
int |
10 |
0 |
N |
N |
0 |
经验统计限制次数 |
|
17 |
educational_background_data_limit_times |
int |
10 |
0 |
N |
N |
0 |
学历统计限制次数 |
|
18 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
19 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
表recruitment_information (招聘信息)
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
recruitment_information_id |
int |
10 |
0 |
N |
Y |
招聘信息ID |
|
|
2 |
recruitment_company |
int |
10 |
0 |
Y |
N |
0 |
招聘公司 |
|
3 |
company_size |
varchar |
64 |
0 |
Y |
N |
公司规模 |
|
|
4 |
recruitment_title |
varchar |
64 |
0 |
Y |
N |
招聘标题 |
|
|
5 |
recruitment_positions |
varchar |
64 |
0 |
Y |
N |
招聘职位 |
|
|
6 |
recruitment_salary |
varchar |
64 |
0 |
Y |
N |
招聘薪资 |
|
|
7 |
recruitment_education |
varchar |
64 |
0 |
Y |
N |
招聘学历 |
|
|
8 |
number_of_recruits |
double |
9 |
2 |
Y |
N |
0.00 |
招聘人数 |
|
9 |
work_location |
varchar |
64 |
0 |
Y |
N |
工作地点 |
|
|
10 |
recruitment_requirements |
varchar |
64 |
0 |
Y |
N |
招聘要求 |
|
|
11 |
recruitment_location |
varchar |
64 |
0 |
Y |
N |
招聘地点 |
|
|
12 |
cover_photo |
varchar |
255 |
0 |
Y |
N |
封面图片 |
|
|
13 |
recruitment_introduction |
longtext |
2147483647 |
0 |
Y |
N |
招聘简介 |
|
|
14 |
hits |
int |
10 |
0 |
N |
N |
0 |
点击数 |
|
15 |
collect_len |
int |
10 |
0 |
N |
N |
0 |
收藏数 |
|
16 |
comment_len |
int |
10 |
0 |
N |
N |
0 |
评论数 |
|
17 |
recommend |
int |
10 |
0 |
N |
N |
0 |
智能推荐 |
|
18 |
interview_appointment_limit_times |
int |
10 |
0 |
N |
N |
0 |
预约面试限制次数 |
|
19 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
20 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
recruitment_positions_id |
int |
10 |
0 |
N |
Y |
招聘职位ID |
|
|
2 |
recruitment_positions |
varchar |
64 |
0 |
Y |
N |
招聘职位 |
|
|
3 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
4 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
salary_data_id |
int |
10 |
0 |
N |
Y |
薪资数据ID |
|
|
2 |
recruitment_positions |
varchar |
64 |
0 |
Y |
N |
招聘职位 |
|
|
3 |
recruitment_salary |
varchar |
64 |
0 |
Y |
N |
招聘薪资 |
|
|
4 |
recruitment_requirements |
varchar |
64 |
0 |
Y |
N |
招聘要求 |
|
|
5 |
recruitment_experience |
varchar |
64 |
0 |
Y |
N |
招聘经验 |
|
|
6 |
recruitment_education |
varchar |
64 |
0 |
Y |
N |
招聘学历 |
|
|
7 |
recruitment_company |
varchar |
64 |
0 |
Y |
N |
招聘公司 |
|
|
8 |
company_stage |
varchar |
64 |
0 |
Y |
N |
公司阶段 |
|
|
9 |
recruitment_industry |
varchar |
64 |
0 |
Y |
N |
招聘行业 |
|
|
10 |
recruitment_skills |
varchar |
64 |
0 |
Y |
N |
招聘技能 |
|
|
11 |
recruitment_city |
varchar |
64 |
0 |
Y |
N |
招聘城市 |
|
|
12 |
recruitment_area |
varchar |
64 |
0 |
Y |
N |
招聘区域 |
|
|
13 |
company_address |
varchar |
64 |
0 |
Y |
N |
公司地址 |
|
|
14 |
company_size |
varchar |
64 |
0 |
Y |
N |
公司规模 |
|
|
15 |
create_time |
datetime |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间 |
|
16 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间 |
|
17 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表 |
|
|
18 |
source_id |
int |
10 |
0 |
Y |
N |
来源ID |
|
|
19 |
source_user_id |
int |
10 |
0 |
Y |
N |
来源用户 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
schedule_id |
smallint |
5 |
0 |
N |
Y |
日程ID:[0,32767] |
|
|
2 |
content |
varchar |
255 |
0 |
Y |
N |
日程内容 |
|
|
3 |
scheduled_time |
datetime |
19 |
0 |
Y |
N |
计划时间 |
|
|
4 |
user_id |
int |
10 |
0 |
N |
N |
用户id |
|
|
5 |
create_time |
datetime |
19 |
0 |
Y |
N |
创建时间 |
|
|
6 |
update_time |
datetime |
19 |
0 |
Y |
N |
更新时间 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
score_id |
int |
10 |
0 |
N |
Y |
评分ID: |
|
|
2 |
user_id |
int |
10 |
0 |
N |
N |
0 |
评分人: |
|
3 |
nickname |
varchar |
64 |
0 |
Y |
N |
昵称: |
|
|
4 |
score_num |
double |
5 |
2 |
N |
N |
0.00 |
评分: |
|
5 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
6 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
7 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表: |
|
|
8 |
source_field |
varchar |
255 |
0 |
Y |
N |
来源字段: |
|
|
9 |
source_id |
int |
10 |
0 |
N |
N |
0 |
来源ID: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
slides_id |
int |
10 |
0 |
N |
Y |
轮播图ID: |
|
|
2 |
title |
varchar |
64 |
0 |
Y |
N |
标题: |
|
|
3 |
content |
varchar |
255 |
0 |
Y |
N |
内容: |
|
|
4 |
url |
varchar |
255 |
0 |
Y |
N |
链接: |
|
|
5 |
img |
varchar |
255 |
0 |
Y |
N |
轮播图: |
|
|
6 |
hits |
int |
10 |
0 |
N |
N |
0 |
点击量: |
|
7 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
8 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
upload_id |
int |
10 |
0 |
N |
Y |
上传ID |
|
|
2 |
name |
varchar |
64 |
0 |
Y |
N |
文件名 |
|
|
3 |
path |
varchar |
255 |
0 |
Y |
N |
访问路径 |
|
|
4 |
file |
varchar |
255 |
0 |
Y |
N |
文件路径 |
|
|
5 |
display |
varchar |
255 |
0 |
Y |
N |
显示顺序 |
|
|
6 |
father_id |
int |
10 |
0 |
Y |
N |
0 |
父级ID |
|
7 |
dir |
varchar |
255 |
0 |
Y |
N |
文件夹 |
|
|
8 |
type |
varchar |
32 |
0 |
Y |
N |
文件类型 |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
user_id |
int |
10 |
0 |
N |
Y |
用户ID:[0,8388607]用户获取其他与用户相关的数据 |
|
|
2 |
state |
smallint |
5 |
0 |
N |
N |
1 |
账户状态:[0,10](1可用|2异常|3已冻结|4已注销) |
|
3 |
user_group |
varchar |
32 |
0 |
Y |
N |
所在用户组:[0,32767]决定用户身份和权限 |
|
|
4 |
login_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
上次登录时间: |
|
5 |
phone |
varchar |
11 |
0 |
Y |
N |
手机号码:[0,11]用户的手机号码,用于找回密码时或登录时 |
|
|
6 |
phone_state |
smallint |
5 |
0 |
N |
N |
0 |
手机认证:[0,1](0未认证|1审核中|2已认证) |
|
7 |
username |
varchar |
16 |
0 |
N |
N |
用户名:[0,16]用户登录时所用的账户名称 |
|
|
8 |
nickname |
varchar |
16 |
0 |
Y |
N |
昵称:[0,16] |
|
|
9 |
password |
varchar |
64 |
0 |
N |
N |
密码:[0,32]用户登录所需的密码,由6-16位数字或英文组成 |
|
|
10 |
|
varchar |
64 |
0 |
Y |
N |
邮箱:[0,64]用户的邮箱,用于找回密码时或登录时 |
|
|
11 |
email_state |
smallint |
5 |
0 |
N |
N |
0 |
邮箱认证:[0,1](0未认证|1审核中|2已认证) |
|
12 |
avatar |
varchar |
255 |
0 |
Y |
N |
头像地址:[0,255] |
|
|
13 |
open_id |
varchar |
255 |
0 |
Y |
N |
针对获取用户信息字段 |
|
|
14 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
|
1 |
group_id |
mediumint |
8 |
0 |
N |
Y |
用户组ID:[0,8388607] |
|
|
2 |
display |
smallint |
5 |
0 |
N |
N |
100 |
显示顺序:[0,1000] |
|
3 |
name |
varchar |
16 |
0 |
N |
N |
名称:[0,16] |
|
|
4 |
description |
varchar |
255 |
0 |
Y |
N |
描述:[0,255]描述该用户组的特点或权限范围 |
|
|
5 |
source_table |
varchar |
255 |
0 |
Y |
N |
来源表: |
|
|
6 |
source_field |
varchar |
255 |
0 |
Y |
N |
来源字段: |
|
|
7 |
source_id |
int |
10 |
0 |
N |
N |
0 |
来源ID: |
|
8 |
register |
smallint |
5 |
0 |
Y |
N |
0 |
注册位置: |
|
9 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
|
10 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
5.1前台功能模块的实现
5.1.1前台首页模块
前台首页界面是用户访问系统的入口页面,它应该展示平台的主要功能和特色,并提供导航链接以便用户浏览和搜索招聘信息、招聘资讯。首页界面的设计应注重页面的美观性和用户体验,同时也需要考虑页面的加载速度和响应性能。其主界面展示如下图5-1所示。
图5-1系统首页界面图
5.1.2登录模块
用户登录模块为用户提供安全快捷的访问方式。登录页面设计简洁明了,用户只需输入用户名及密码即可完成身份验证。系统采用验证码进行用户认证,支持多因素认证增强安全性。登录成功后,用户将被重定向至系统首页页面。对于忘记密码的用户,提供了找回密码功能,通过邮箱或手机号接收重置链接,保障账户安全。用户登录流程如图5-2所示,登录界面如下图5-3所示。
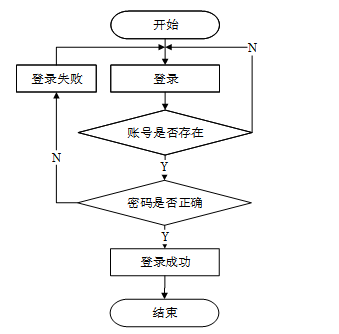
图5-2 用户登录流程
系统登录界面如下图所示。
图5-3登录界面图
用户登录关键代码如下:
def Login(self, ctx):
"""
登录API
@param {Object} ctx http请求上下文
"""
print("===================登录=====================")
ret = {
"error": {
"code": 70000,
"message": "账户不存在",
}
}
body = ctx.body
# 获取用户
password = md5hash(body["password"]) or ""
obj = service_select("user").Get_obj(
{"username": body["username"]}, {"like": False}
)
if obj:
# 检查用户所属用户组
user_group = service_select("user_group").Get_obj({'name': obj['user_group']}, {"like": False})
if user_group and user_group['source_table'] != '':
user_obj = service_select(user_group['source_table']).Get_obj({"user_id": obj['user_id']},
{"like": False})
if user_obj['examine_state'] == '未通过':
ret = {
"error": {
"code": 70000,
"message": "账户未通过审核",
}
}
return ret
if user_obj['examine_state'] == '未审核':
ret = {
"error": {
"code": 70000,
"message": "账户未审核",
}
}
return ret
5.1.3注册模块
用户注册模块为新用户提供便捷的账户创建流程,用户需要填写必要的个人信息并选择合适的用户名和密码。通过简洁的表单设计,收集用户的必要信息,如用户名、密码、邮箱或手机号等,并进行输入验证以确保数据准确性。注册流程图如图5-4所示,注册界面展示如下图5-5所示。
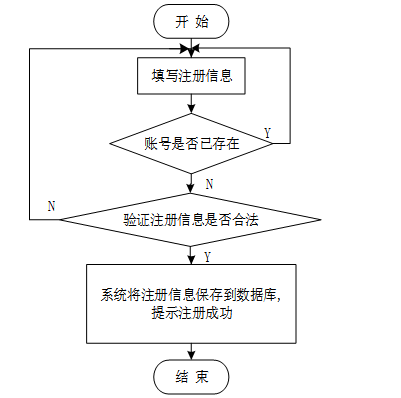
图5-4注册流程图
图5-5 前台注册界面图
注册关键代码如下:
def Register(self, ctx):
"""
注册API
@param {Object} config 配置参数
"""
print("===================注册=====================")
userService = service_select("user")
body = ctx.body
# 判断必须信息
if "username" not in body and body["username"] == '':
return {"error": {
"code": 70000,
"message": "用户名不能为空",
}}
if "user_group" not in body and body["user_group"] == '':
return {
"error": {
"code": 70000,
"message": "用户组不能为空",
}
}
if "password" not in body and body["password"] == '':
return {
"error": {
"code": 70000,
"message": "密码不能为空",
}
}
# 取出表单
post_param = body
post_param['nickname'] = body["nickname"] or ""
post_param['password'] = md5hash(body["password"])
# 校验是否存在用户
obj = userService.Get_obj({"username": post_param['username']}, {"like": False})
if obj:
return {
"error": {
"code": 70000,
"message": "用户名已存在",
}
}
ret = {
"error": {
"code": 70000,
"message": "注册失败",
}
}
# 添加
bl = userService.Add(post_param)
if bl:
ret = {
"result": {
"bl": True,
"message": "注册成功"
}
}
return ret
5.1.4公告消息模块
公告信息模块用于向所有用户发布重要信息,如网站介绍、政策变更和服务更新。管理员可以在后台管理系统中创建和管理公告内容,设置发布时间和有效期。前端通过专门的公告栏展示最新的公告信息,用户可以在公告信息模块查看详细内容。公告消息界面如下图5-6所示。
图5-6公告消息界面图
5.1.5招聘资讯模块
招聘资讯模块提供丰富的热门文章、面试技巧等信息,设计上强调内容的专业性和实用性,分类详细便于浏览。实现过程中,管理员可通过后台管理界面便捷地添加或修改资讯内容,保证信息的时效性与准确性。招聘资讯详情界面如下图5-7所示。
图5-7招聘资讯界面图
查询招聘资讯列表的逻辑代码如下所示。
def Get_obj(self, ctx):
"""
查一条
@param {Object} ctx http请求上下文
@return {Object} 返回json-rpc格式结果
"""
query = dict(ctx.query)
config_plus = {}
if "field" in query:
field = query.pop("field")
config_plus["field"] = field
obj = self.service.Get_obj(query, obj_update(self.config, config_plus))
if self.service.error:
return {"error": self.service.error}
if obj:
self.interact_obj(ctx, obj)
return {"result": {"obj": obj}}
5.1.6招聘信息模块
用户可通过招聘信息模块查看系统中所有招聘的基本详情,包括招聘公司、公司规模、招聘标题、招聘职位、招聘薪资、招聘学历、招聘人数、工作地点、招聘要求、招聘地点等信息。用户点击具体招聘信息后,可进一步浏览招聘内容介绍,并进行预约面试,通过收藏或评论功能与内容互动。招聘信息详情界面如下图5-8所示。
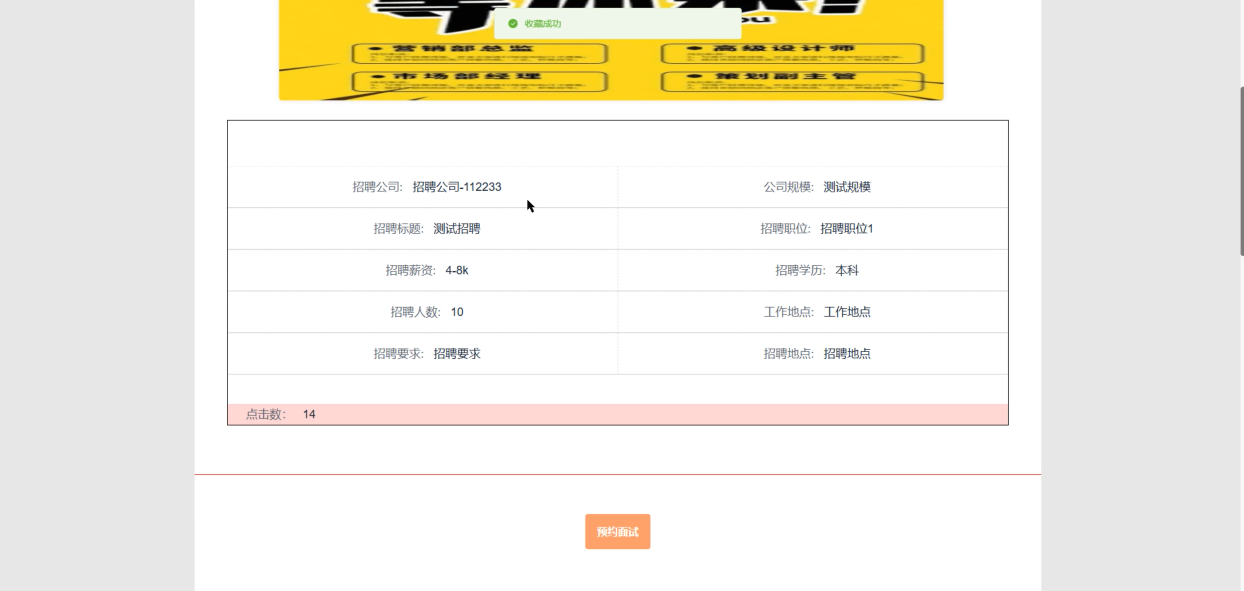
图5-8招聘信息详情界面图
预约面试界面如下图5-9所示。
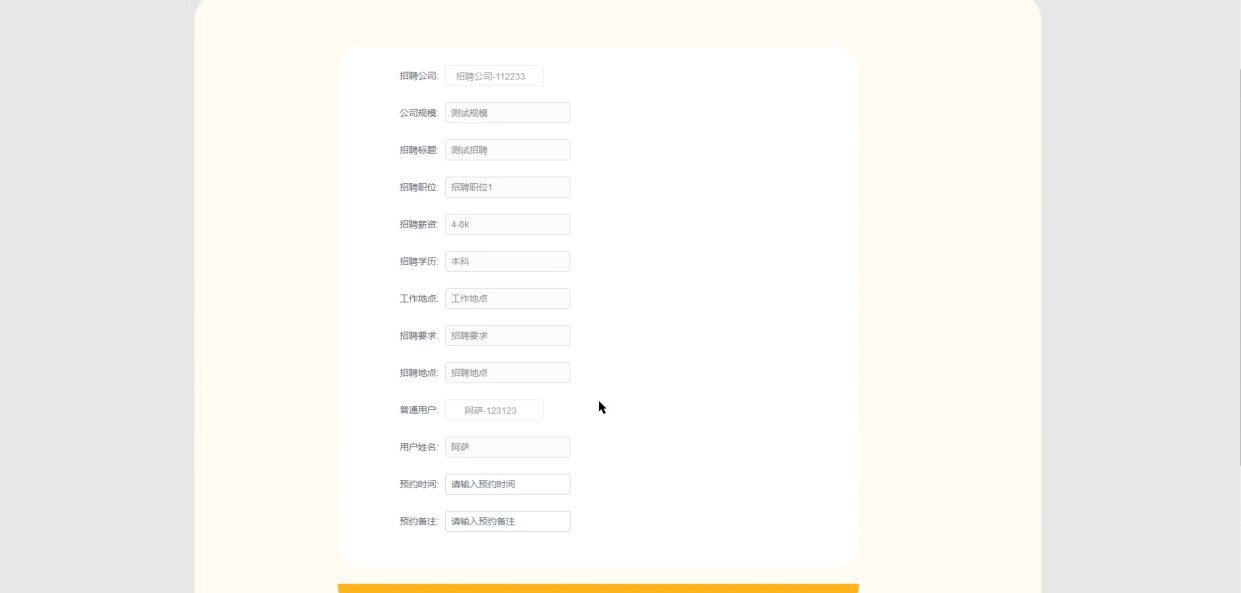
图5-9预约面试界面图
提交面试预约信息的逻辑代码如下所示。
def Add(self, ctx):
"""
增
@param {Object} ctx http请求上下文
@return {Object} 返回json-rpc格式结果
"""
body = ctx.body
unique = self.config.get("unique")
obj = None
if unique:
qy = {}
for i in range(len(unique)):
key = unique[i]
qy[key] = body.get(key)
obj = self.service.Get_obj(qy)
5.1.7个人中心模块
个人中心模块为用户提供一个个性化的空间,展示用户的个人首页、面试预约、收藏、评论管理等互动记录。允许用户申请面试并填写简历信息,支持查看预约状态和面试结果反馈;将感兴趣的职位加入收藏夹,便于后续查看;也可以查看和管理自己对招聘信息或资讯的评论。用户个人中心管理如下图5-10所示。
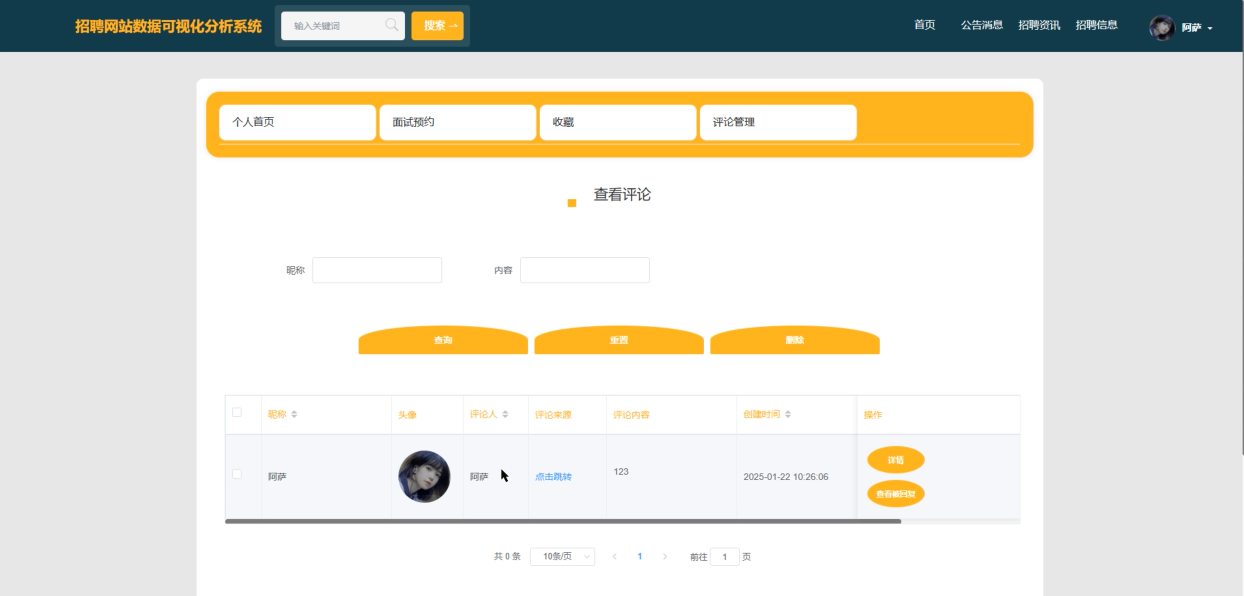
图5-10用户个人中心界面图
5.2招聘公司管理模块的实现
5.2.1后台登录模块
招聘公司注册后可进入登录界面,输入账号密码,点击“登录”按钮可以进行登录,使用各项系统功能,并可对个人信息和密码进行管理。后台登录模块界面如下图5-11所示。

图5-11后台登录界面图
5.2.2招聘信息管理模块
招聘公司的招聘信息管理模块主要用于职位信息的发布、更新和维护。在操作设计上,系统提供直观的表单界面,招聘公司可填写职位名称、薪资范围、学历要求、工作地点等详细信息。基于Python开发的后端接口负责数据交互,管理员审核通过后,职位信息将实时同步至前端展示页面,供用户查询和预约面试。招聘信息添加界面如下图5-12所示。
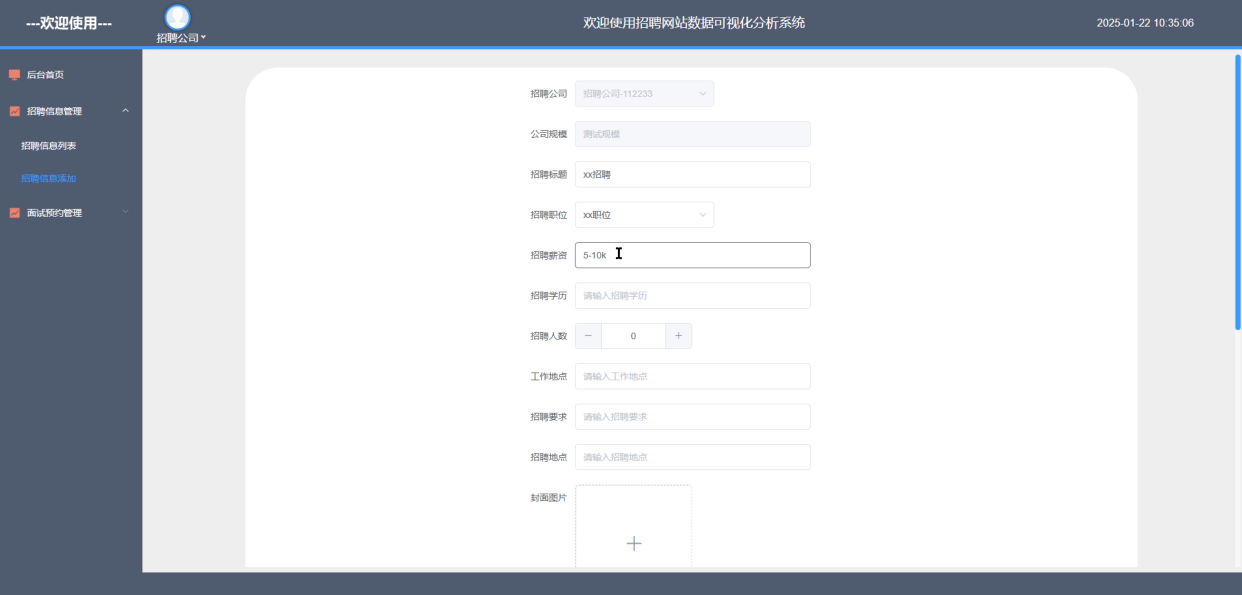
图5-12 招聘信息添加界面图
添加招聘信息的逻辑代码如下所示。
def Add(self, ctx):
"""
增
@param {Object} ctx http请求上下文
@return {Object} 返回json-rpc格式结果
"""
body = ctx.body
unique = self.config.get("unique")
obj = None
if unique:
qy = {}
for i in range(len(unique)):
key = unique[i]
qy[key] = body.get(key)
obj = self.service.Get_obj(qy)
5.2.3面试预约管理模块
面试预约管理模块为招聘公司提供了高效的面试预约审核与跟踪工具。系统以列表形式展示用户的预约请求,包含申请人信息、申请职位、预约时间及状态等字段,并支持按条件筛选和排序。招聘公司可通过点击“审核”按钮快速查看申请详情并反馈结果,审核状态会实时更新至数据库。面试预约审核界面如下图5-13所示。
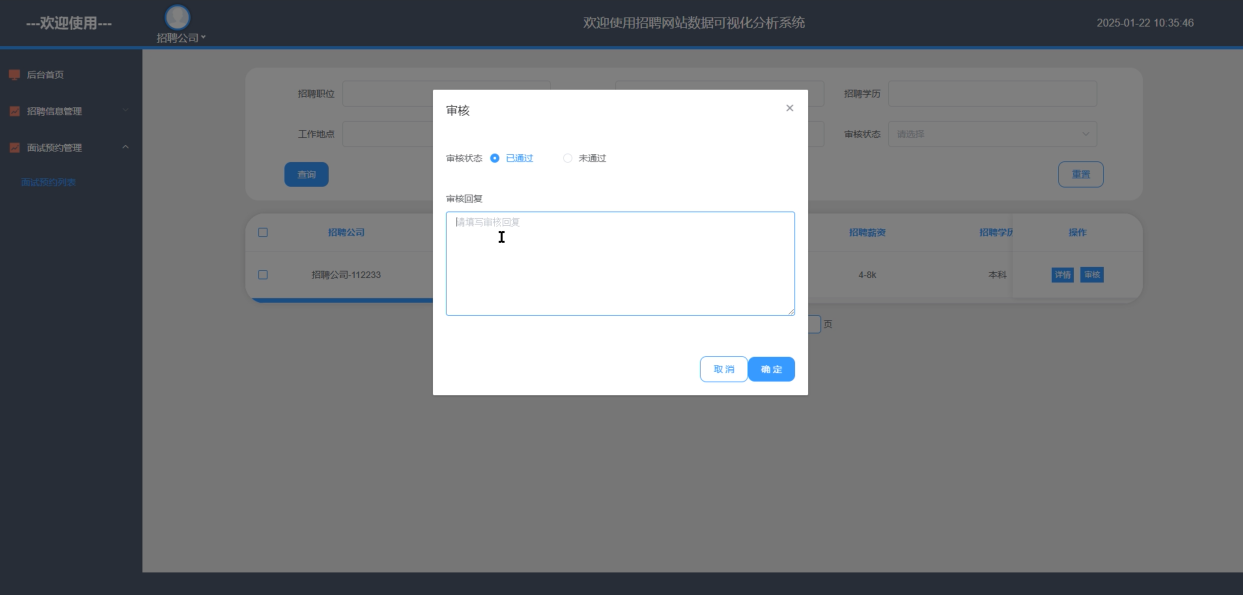
图5-13 面试预约审核界面图
审核面试预约信息的逻辑代码如下所示。
def Set(self, ctx):
"""
改
@param {Object} ctx http请求上下文
@return {Object} 返回json-rpc格式结果
"""
# 修改数据前
error = self.Set_before(ctx)
if error["code"]:
return {"error": error}
error = self.Events("set_before", ctx, None)
if error["code"]:
return {"error": error}
query = ctx.query
if 'page' in query.keys():
del ctx.query['page']
if 'size' in query.keys():
del ctx.query['size']
if 'orderby' in query.keys():
del ctx.query['orderby']
if 'sqlwhere' in query.keys():
del ctx.query['sqlwhere']
# 修改数据
result = self.service.Set(ctx.query, ctx.body, self.config)
5.3后台管理员模块的实现
5.3.1后台首页模块
管理员的后台首页是系统的核心数据展示模块,通过直观的图表和统计数据呈现招聘市场的整体状况。首页提供多维度统计面板,包括招聘数据、薪资分布、学历要求、面试预约等关键指标。在实现方面,基于Hadoop生态中的Hive和Spark技术进行数据汇总与分析,生成实时更新的可视化图表,同时利用前端ECharts将结果以交互式形式展示,帮助管理员全面掌握平台运行状态。后台首页界面如下图5-14所示。
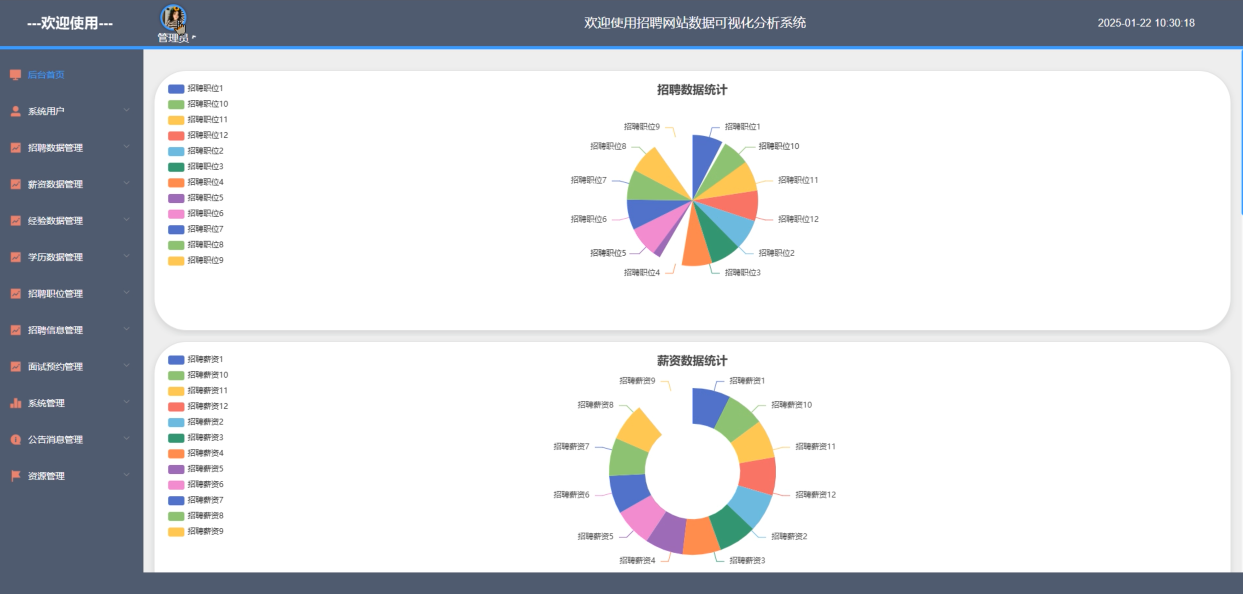
图5-14后台首页界面图
5.3.2系统用户模块
系统用户管理模块用于维护普通用户和招聘公司的账号信息及权限分配。操作设计上,管理员可通过搜索框快速定位目标用户,查看其注册时间、角色类型及活跃状态,并执行审核、禁用或删除等操作。实现方面,用户数据存储于HDFS中,结合MySQL数据库进行结构化管理,利用Python脚本完成数据校验与权限控制逻辑,确保用户信息的安全性和一致性。系统用户界面如下图5-15所示。
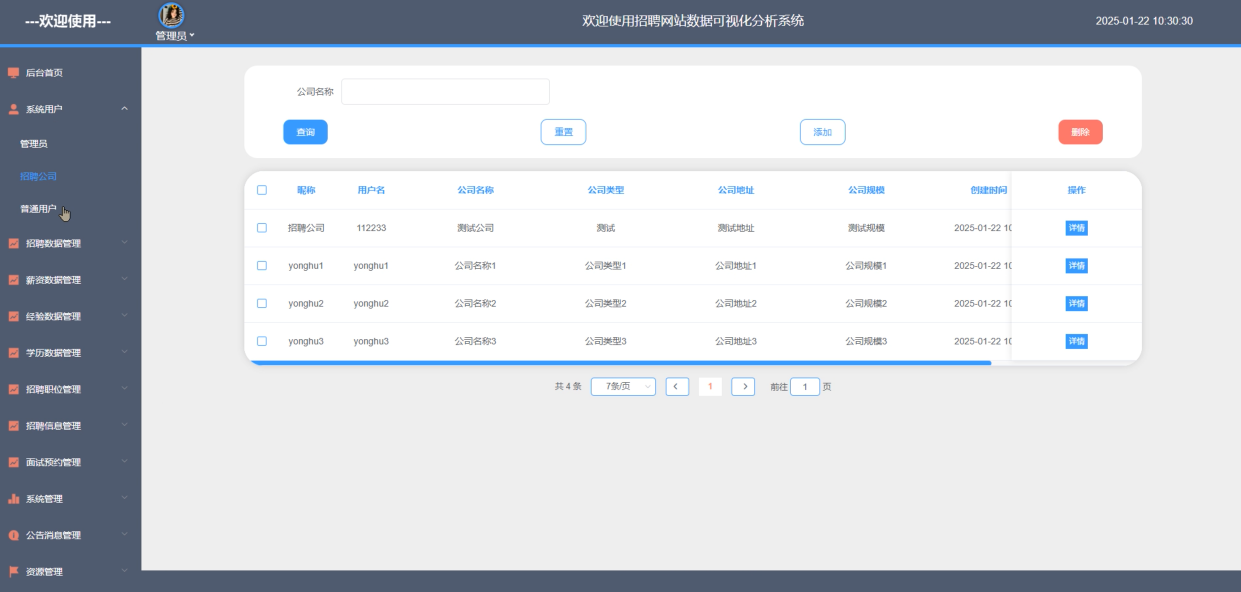
图5-15 系统用户界面图
5.3.3招聘数据管理模块
招聘数据管理模块支持管理员对招聘信息的查询、重置、删除、爬取操作,也可以手动添加招聘数据。操作设计上,提供灵活的筛选条件,便于精准定位目标数据。实现方面,通过爬虫程序定时抓取外部招聘网站数据并存储至HDFS,利用MapReduce清洗重复或无效信息,再通过后端接口供管理员调用和管理。招聘数据管理界面如下图5-16所示。
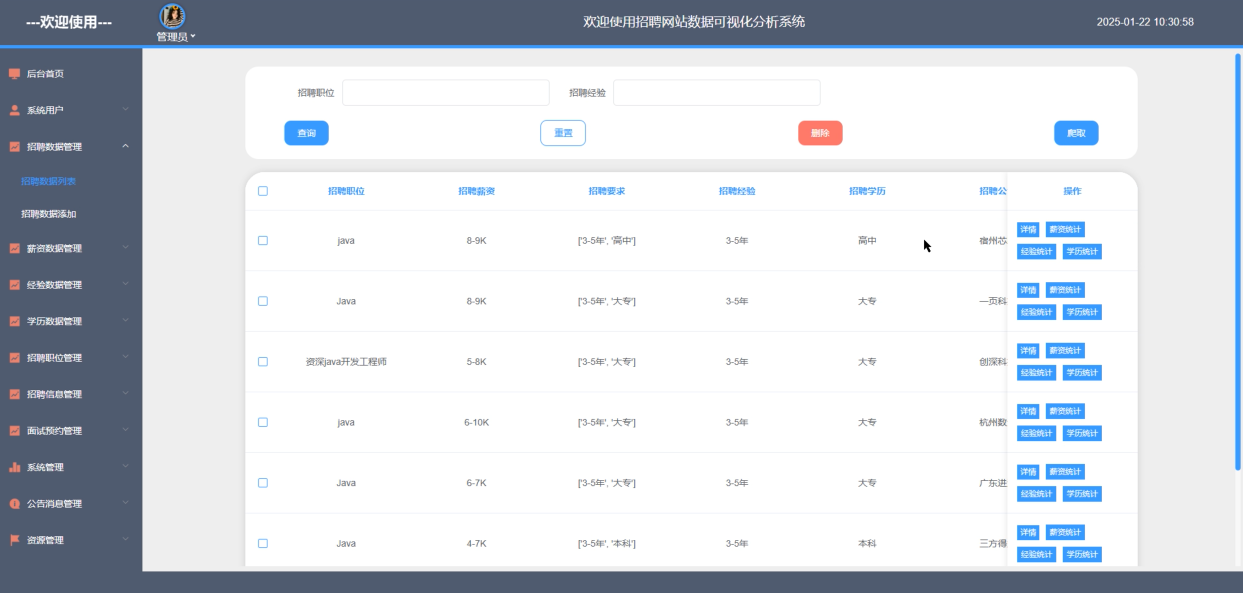
图5-16招聘数据管理界面图
爬取招聘数据的逻辑代码如下所示。
def Add(self, ctx):
"""
增
@param {Object} ctx http请求上下文
@return {Object} 返回json-rpc格式结果
"""
body = ctx.body
unique = self.config.get("unique")
obj = None
if unique:
qy = {}
for i in range(len(unique)):
key = unique[i]
qy[key] = body.get(key)
obj = self.service.Get_obj(qy)
5.3.4招聘职位管理模块
招聘职位管理模块主要用于维护职位分类和标签体系,提升职位搜索与推荐的精准度。管理员可新增、修改或删除职位分类,并为每个分类设置对应的标签属性。招聘职位管理界面如下图5-17所示。
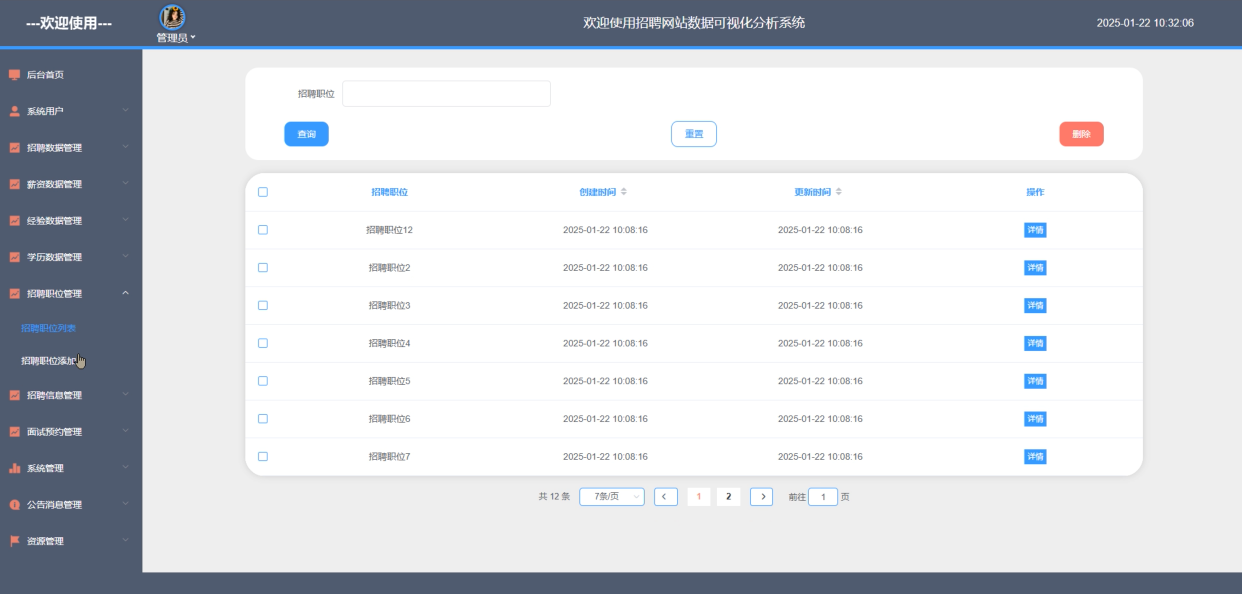
图5-17招聘职位管理界面图
5.3.5系统管理模块
轮播图管理模块负责首页轮播图内容的上传、排序和展示配置。操作设计上,管理员可通过拖拽方式调整图片顺序,支持图片预览、替换和删除操作。实现方面,图片文件存储于HDFS中,元数据则存入MySQL数据库,前端通过API接口动态加载轮播图资源,确保展示效果流畅且易于维护。轮播图管理界面如下图5-18所示。
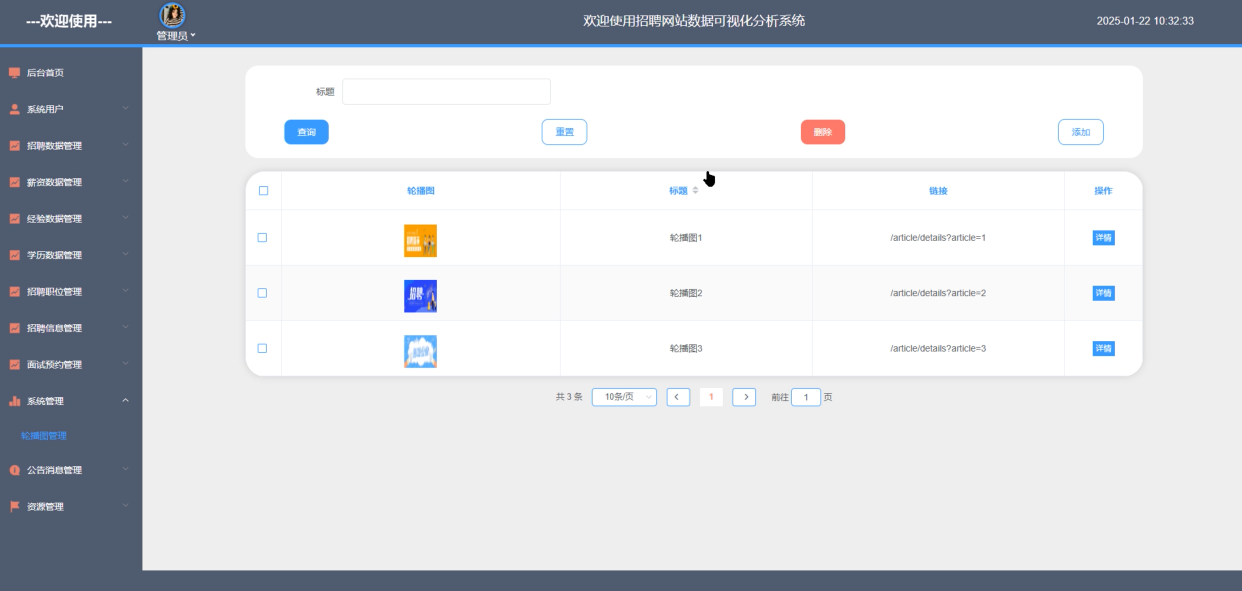
图5-18轮播图管理界面图
5.3.6资源管理模块
资源管理模块专注于招聘资讯的内容管理和分类维护。操作设计上,管理员可新增、编辑或删除资讯文章,并为其分配合适的分类标签。实现方面,资讯内容存储于分布式数据库中,分类关系由Python脚本动态维护,前端通过分类导航栏展示资讯列表,支持按关键词搜索和分页浏览,从而提升用户体验与内容管理效率。资源管理界面如下图5-19所示。
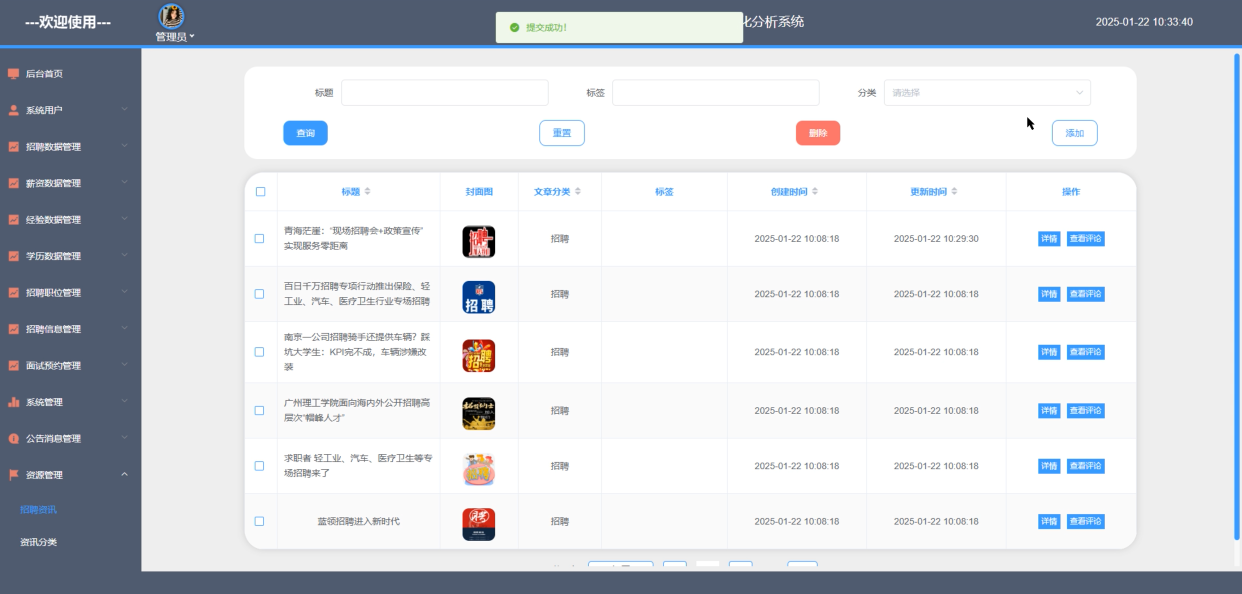
图5-19 资源管理界面图
6.1测试的目的
测试目的是为了验证系统的功能、性能和稳定性,以确保系统在实际应用中能够达到预期的要求。通过测试,可以发现潜在的问题和缺陷,并及时进行修复和改进。测试还可以评估系统的可靠性、安全性和用户体验,以提供一个高质量和可信赖的产品。此外,测试也有助于验证系统是否满足用户需求和预期,是否符合相应的标准和规范。总之,测试的目的是为了确保系统的质量和可靠性,从而为用户提供良好的使用体验和价值。
6.2功能测试
对以下功能进行测试,包括用户注册、用户登录、修改密码、招聘数据添加、招聘信息查看、预约面试功能测试,具体测试用例如下表所示。
表6-1用户注册测试用例
|
测试编号 |
测试内容 |
预期结果 |
|
TC-001 |
输入有效信息 |
注册成功,跳转到登录页面 |
|
TC-002 |
输入已存在账号 |
显示账号已存在的提示信息 |
|
TC-003 |
输入无效信息 |
显示注册失败的提示信息,要求重新输入有效信息 |
表6-2用户登录测试用例
|
测试编号 |
测试内容 |
预期结果 |
|
TC-004 |
输入正确的账号密码 |
登录成功,跳转到个人主页 |
|
TC-005 |
输入错误的账号密码 |
显示登录失败的提示信息,要求重新输入正确的账号密码 |
表6-3 修改密码测试用例
|
测试编号 |
测试内容 |
预期结果 |
|
TC-006 |
输入有效密码 |
密码修改成功,显示修改成功的提示信息 |
|
TC-007 |
输入无效密码 |
显示密码无效的提示信息,要求重新输入有效密码 |
|
TC-008 |
输入错误原密码 |
显示原密码错误的提示信息,要求重新输入正确原密码 |
表6-4 招聘数据添加测试用例
|
测试编号 |
测试内容 |
预期结果 |
|
TC-009 |
输入有效的招聘数据 |
招聘数据成功,显示添加成功的提示信息 |
|
TC-010 |
输入无效的招聘数据 |
显示添加失败的提示信息,要求重新输入有效信息 |
表6-5 查看招聘信息测试用例
|
测试编号 |
测试内容 |
预期结果 |
|
TC-011 |
点击查看招聘信息 |
显示招聘信息页面,展示相关的招聘内容 |
|
TC-012 |
选择其他招聘职位 |
显示所选招聘职位的相关招聘信息等内容 |
|
TC-013 |
无可用招聘信息 |
显示暂无招聘信息的提示信息,提醒用户重新选择招聘职位 |
表6-6 面试预约添加测试用例
|
测试编号 |
测试内容 |
预期结果 |
|
TC-014 |
输入有效的面试预约信息 |
面试预约信息添加成功,显示添加成功的提示信息 |
|
TC-015 |
输入无效的面试预约信息 |
显示添加失败的提示信息,要求重新输入有效信息 |
6.3系统测试结果
综上所述,招聘网站数据可视化分析系统在功能测试中表现良好,通过了所有测试用例。系统提供的用户注册、用户登录、修改密码、招聘数据添加、招聘信息查看、预约面试等主要功能都能正常运行,并能够给出预期的提示信息和结果。然而,为了确保系统的全面稳定性和质量,仍建议进行更多的综合性测试,包括性能测试、安全性测试和用户体验测试等,以进一步验证和改进系统的功能和性能。
本文描述了招聘网站数据可视化分析系统的原理和开发过程,在开发本招聘网站数据可视化分析系统之前,首先通过网上查询现有的招聘网站数据可视化分析系统功能、线下通过问卷调查的方式,了解用户对招聘网站数据可视化分析展示方面的具体需求,对系统的开发背景以及推荐系统的研究现状进行研究,设计了本招聘网站数据可视化分析系统具体实现的功能。
确定好功能后,第二步就是开发工具的选择,在设计招聘网站数据可视化分析系统的时候,确定了采用现下比较流程的Python语言,采用Hadoop框架与爬虫技术,数据的存储方面采用的是开源的MySQL数据库,接下来就是对系统需求的分析,在文中主要通过对招聘网站数据可视化分析系统进行可行性、性能、功能、用例四个方面进行分析,确定了本招聘网站数据可视化分析系统的具体功能,功能确定后就是对系统的设计以及,包括前后台、数据库等方面,最终完成系统的开发,对系统进行测试总结。
在开发本招聘网站数据可视化分析系统的过程中我成长了很多,学习到了很多书本上没有的知识,目前系统虽然已经完成,但是还有许多地方需要改进,比如界面布局方面,代码的编写方面,都可以进一步完善,由于自己专业知识的浅薄,系统做的并不是十分完美,以后我会不断进行学习,对系统进行完善,希望有机会能够投入到学校的使用当中,给同学们提供便利。
[1]Laurier N ,Robert T J ,Tom A , et al.Optimizing use of an electronic medical record system for quality improvement initiatives in hemodialysis: Review of a single center experience.[J].Hemodialysis international. International Symposium on Home Hemodialysis,2024,
[2]黄媛.基于网络爬虫技术的网络招聘信息分析[J].长江工程职业技术学院学报,2024,41(03):30-34.
[3]Wan L ,Xu J .Research on Internet talent recruitment and talent management based on big data[J].Journal of Human Resource Development,2024,6(3):
[4]Joanna N .Enhancing taxonomy-based extraction: Leveraging information from online community platforms for digital skills demand identification in job ads[J].Statistical Journal of the IAOS,2024,40(3):591-602.
[5]张三群. 基于Python的某直聘大数据岗位招聘数据爬取与可视化分析 [J]. 电脑知识与技术, 2024, 20 (36): 63-66.
[6]郭瑾. 基于Python的招聘数据爬取与数据可视化分析研究 [J]. 轻工科技, 2024, 40 (02): 94-96+99.
[7]付腾达,李卫勇,王士信,等. 基于Python爬虫技术的招聘信息数据可视化分析 [J]. 电脑知识与技术, 2024, 20 (07): 77-82.
[8]李浩,郭嘉莉,梁艳,等.网络招聘的人岗匹配度算法研究[J].电脑与信息技术,2024,32(04):19-22+35.
[9]王佳.德国招聘门户网站“我的图书馆职位”的建立与启示[J].国际公关,2024,(13):29-31.
[10]Chen L ,Li C ,Tang T .The impact of working from home on urban commuting in China: A comprehensive analysis using social media and recruitment website data[J].Cities,2024,148104868-.
[11]杜宇灏,闫长青,李环宇.招聘网站数据薪资K-means聚类分析可视化[J].现代计算机,2023,29(23):64-68+91.
[12]陈亮.基于协同过滤算法的智能岗位分析系统的设计与实现[J].软件工程,2023,26(10):58-62.
[13]高凤毅,葛苏慧,林喜文,等.基于Python的招聘网站数据爬取与分析[J].电脑编程技巧与维护,2023,(09):70-72.
[14]张加会.基于数据挖掘技术的线上招聘信息分析与应用[D].阜阳师范大学,2023.
[15]田圻,杨佳骏,覃天. 基于Hadoop平台的岗位需求分析——以计算机软件行业为例 [J]. 软件, 2023, 44 (08): 153-155.
[16]刘静,王凤,孟星,等.Python在数据可视化中的应用案例分析[J].电子技术,2023,52(05):391-393.
[17]汤飞弘.基于Python爬虫的招聘信息数据可视化分析[J].软件,2023,44(01):176-179.
[18]苏明焱.基于Python的招聘网站信息的爬取与数据分析[J].信息与电脑(理论版),2022,34(24):193-195.
[19]刘一,王跟成.基于Python的就业趋势可视化分析系统[J].信息与电脑(理论版),2021,33(05):99-101.
[20]叶惠仙.基于Hadoop+Hive技术的招聘网站数据分析研究[J].网络安全技术与应用,2020,(12):77-79.
致谢
时光荏苒,大学的学业生涯即将画上美好的句号。在这段时光里,我深感老师的热情与友谊,校长对学生的关爱深深印在我的心中。老师们时常关心我们的生活状况,关切我们的饮食、寝室和学习环境,使我们感受到了温馨与关怀。在此,我想表达对那些曾经给予我帮助的人们的深深感激之情。
首先,我要衷心感谢我的导师。无论是在学业上还是生活中,您都给予我巨大的支持与启发。这些年来,在您的教导下,我不仅学到了丰富的知识,还领悟了做人的真谛。您的认真和待人之道让我受益匪浅,我感激能够成为您的学生。
同时,感谢我的专业课老师们。没有你们的精心教导,我的论文也不可能如此顺利。我所学到的知识将成为我未来发展的重要动力。
感谢同学们,写作过程中遇到的问题,得到了同学们的耐心指导和丰富参考材料。你们给予了我很多帮助,感谢你们对我的支持。
最后,感谢我的父母,是你们的支持和鼓励让我能够顺利完成学业。你们为我付出了辛勤的努力和无私的关爱,是我坚强前行的后盾。在即将离开校园,我深感家庭的温馨和爱意,这些将是我未来奋斗的力量源泉。
感谢你们一直以来的支持和陪伴,让我在大学的日子里无论遇到什么困难都感到温馨而坚定。未来,我将以更加饱满的热情投入社会工作,为家人和自己创造更美好的未来。再次感谢大家的陪伴与关爱!
点赞❤关注+私信博主,免费领取项目源码,谢谢

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 35
35 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)