再谈AI芯片:GPU、TPU 与 NPU:有何区别
除了大众熟悉的中央处理器(CPU)外,神经网络处理器(NPU)、图形处理器(GPU)与张量处理器(TPU)也已加入处理器阵营。
众所周知,人工智能(AI)正驱动着技术创新,尤其是在大规模数据处理领域。旨在解决复杂问题并能自主学习的机器学习(ML)与深度学习(DL)算法,正在不断突破计算机能力的边界。
随着需要计算机处理的问题日趋复杂,其运行进程数量也呈现爆炸式增长。这一增长催生了专用处理器与大量新术语的涌现。
除了大众熟悉的中央处理器(CPU)外,神经网络处理器(NPU)、图形处理器(GPU)与张量处理器(TPU)也已加入处理器阵营。
接下来我们将具体解析这些专用处理器的工作原理及相互差异。若您对此感兴趣,不妨再驻足片刻聆听一节IT历史课——我将深入探讨近百年来硬件与软件发展融合中更具技术性的概念。
中央处理器(CPU):运算元老
可将CPU视作计算机的将军。它主要由算术逻辑单元(ALU)和控制单元构成:ALU负责执行算术运算(加、减等)与逻辑运算(与、或、非等);控制单元则调控ALU、内存及输入/输出功能,指示它们如何响应刚从存储器读取的程序。
理解CPU运行机制最直观的方式是追踪其输入/输出流程:CPU接收请求(输入),访问计算机内存获取任务指令,将执行委派给自身ALU或其他专用处理器,随后在控制单元整合所有数据,最终采取统一行动(输出)。
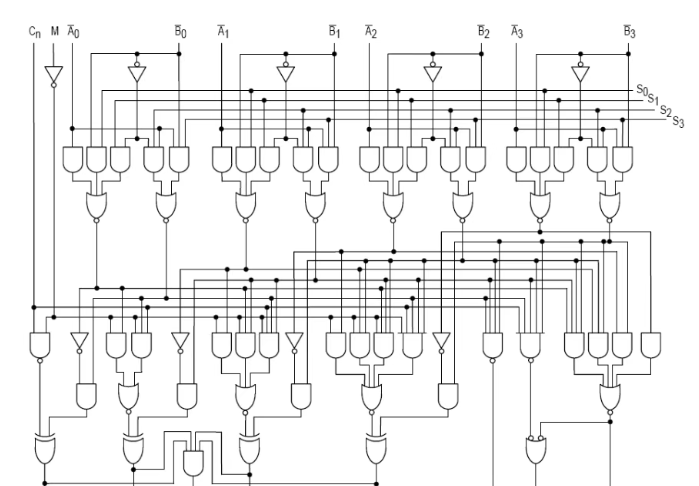
下图是1970年ALU的电路结构图:
但更重要的是,以下这张示意图清晰地展示了CPU的运作逻辑:
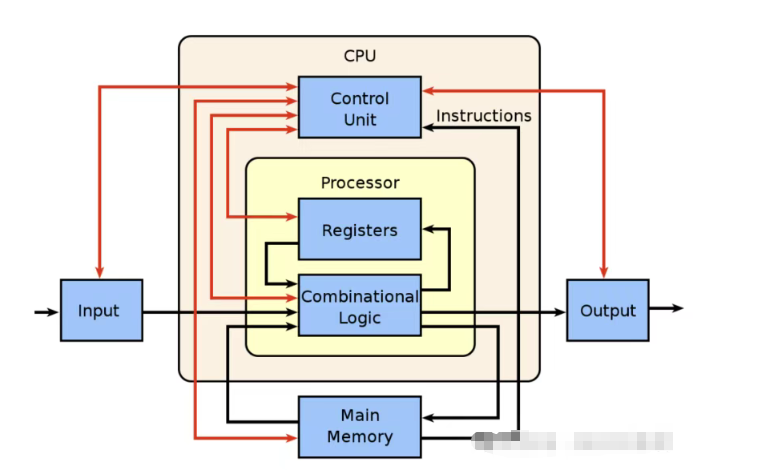
随着从单核处理器发展到多核处理器,CPU 的性能日益强大。其核心在于由多个算术逻辑单元(ALU)协同执行任务,这些运算单元受 CPU 控制单元调度,实现并行处理。这种架构使 CPU 能与 GPU 等专用 AI 处理器高效协同工作。
专用处理器的崛起
当计算机接收任务时,处理器首先需要与内存通信——包括用于启动等固定任务的程序存储器(ROM),以及用于加载应用、编辑文档、浏览网页等频繁变更操作的数据存储器(RAM)。连接这些组件的总线是数据传输通道,但其每次只能访问一种内存类型。
过去处理器运行速度慢于内存访问,但随着处理器技术演进,这种情况已发生逆转。如今当需要处理海量数据时,CPU 常因总线传输拥堵而被迫等待内存访问,不仅降低效率更导致能耗激增。计算领域将这一现象称为「冯·诺依曼瓶颈」。随着 AI 等复杂任务的出现,突破此瓶颈迫在眉睫。
解决方案之一是开发针对特定任务优化的芯片。专用芯片可有效解决机器学习算法对 CPU 造成的处理压力。在打造最佳 AI 处理器的竞争中,谷歌、IBM、微软、英伟达和华为等巨头通过专用处理器实现更复杂的逻辑查询,其技术路径各有特色。下面让我们具体解析 GPU、TPU 与 NPU 的特性:
图形处理器(GPU)
GPU 最初是专业图形处理器,常被误认为包含更多硬件的显卡。其设计初衷是支持海量并行处理,通过与 CPU 协同工作(完全集成在主板上或作为独立硬件应对高负载任务),但高能耗导致的发热问题不容忽视。
GPU 长期应用于游戏领域,直到 21 世纪初英伟达推动其转向通用计算。除芯片设计外,英伟达推出的 CUDA 专有平台允许程序员直接调用 GPU 虚拟指令集和并行计算单元,这意味着可搭建计算内核(协同工作的处理器集群)专攻特定任务,而不过度占用其他资源。下图直观展示其工作流程:
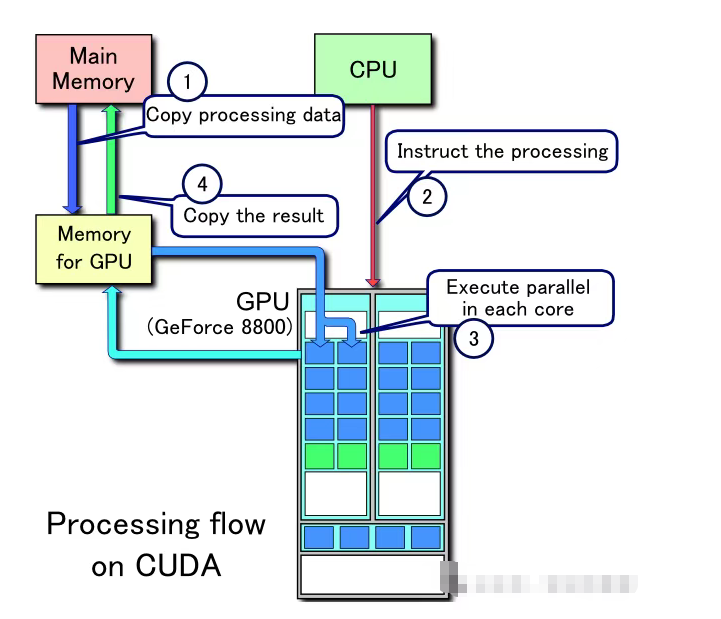
这使得GPU能够广泛应用于机器学习任务,其优势在于利用了现有成熟的技术体系。换言之:在寻找解决方案时,最终胜出的方案并非总是纯粹性能最优的。如果某项技术需要彻底改变用户行为或让所有人重新学习技能,往往会遭遇推广阻力。因此GPU能很好地兼容现有系统、编程语言等特性,极大促进了其普及。虽未达到即插即用程度,但核心优势显而易见。
随着技术发展,如今也出现了受到行业巨头(包括英伟达)支持的开源GPU平台,其中规模最大的是OpenCL。此外,人们还增加了张量核心(关于其原理,本文后续将阐述)。
张量处理器(TPU)
好消息是:这个术语简单来说就是谷歌的专有AI处理器。谷歌自2015年起在自有数据中心使用,2016年向公众发布,现有若干商用型号。它们基于ASIC(硬蚀刻芯片,后文详述)和谷歌TensorFlow软件运行。
与GPU相比,TPU的特别之处在于采用稍低的计算精度,这使其能更灵活应对不同类型的工作负载。谷歌的阐释尤为精辟:
"若窗外下雨,你无需确知每秒雨滴数量——只需了解雨势大小。同理,神经网络预测通常不需要32位甚至16位浮点数的精度。通过优化,使用8位整数计算神经网络预测仍可保持适当精度。"(摘自谷歌云博客)
而GPU最初为图形处理与渲染设计,其效果依赖各像素点间的精确关系。若点位精度不足,向量计算会产生误差放大,最终效果将如同《PS2版小龙斯派罗》与《PS4版小龙斯派罗》的画质差异。
与CPU和GPU的另一关键设计差异在于:TPU采用脉动阵列架构。这种架构构建了一个处理器网络,每个节点执行部分计算任务,然后将结果传递至下一节点,直至完成整个处理流程。节点通常是固定且相同的,但节点间运行的程序可定制化配置。这种结构被称为数据处理单元(DPU)。
神经网络处理器(NPU)
"NPU"有时被用作所有专用AI处理器的统称,但更多特指为移动设备设计的处理器。
NPU包含完成AI处理所需的全部组件,其运行基于突触权重原理。这一从生物学借鉴的概念描述了两个神经元之间的连接强度:当两个神经元频繁传递信息时,它们之间的连接会实质增强,使能量传递更高效——这正是习惯形成背后的科学原理。许多神经网络模拟了这一机制。
AI算法的学习过程正体现于此:系统持续追踪潜在可能性,并强化相关节点的连接权重。这对功耗控制意义重大。虽然并行处理可同步执行多个任务,但在任务完成度协调方面存在不足,尤其在架构扩展导致处理单元分散时更为明显。
计算机中的神经网络与决策机制
人类的决策过程实际上是由一系列连续判断组成,最终决策受此前所有考虑因素影响。由于计算机基于严格二进制运行,它们并不天然具备通过信息情境化来优化决策的能力。神经网络正是解决这一问题的方案——其基于矩阵数学构建,架构如下图所示:
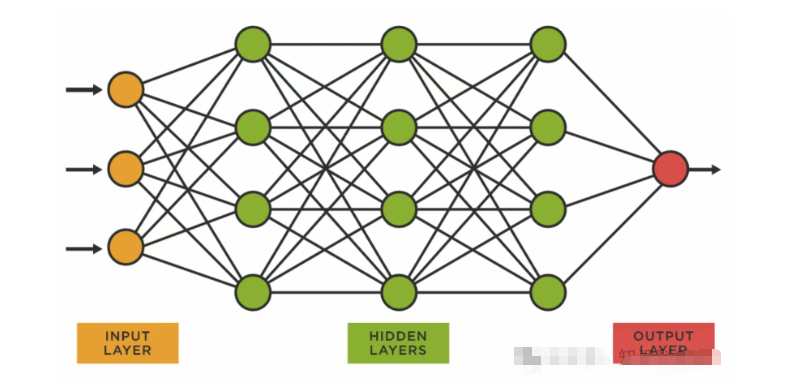
本质上,这是让计算机对每个潜在决策进行全局可能性评估,权衡结果,并从自身经验与感知信息中学习。这一切都意味着需要同时运行更多计算。
核心差异总结
信息量较大,以下是关键要点:
-
功能定位:GPU最初为图形渲染开发,而TPU和NPU是专为AI/机器学习工作负载构建的。
-
并行处理:GPU为并行处理设计,适合训练复杂神经网络。TPU将此特性专业化,专注于张量运算以实现更高速度和能效。
-
定制程度:TPU和NPU为AI任务高度定制化,而GPU则提供适用于各种计算任务的通用方案。
-
应用场景:GPU常用于数据中心和工作站进行AI研究与训练;TPU广泛应用于谷歌云基础设施;NPU则普遍存在于智能手机和物联网设备等AI赋能设备中。
-
可用性:GPU由多家制造商广泛提供,研究人员、开发者和爱好者均可获取;TPU是谷歌云服务的专属资源;NPU则集成于特定设备中。
这些差异重要吗?
不同处理器的定义初看可能相似。多核处理器是在中央控制单元下集成多个ALU;GPU是在专用处理器下集成更多ALU;TPU则是在类似于CPU的DPU下集成多个计算节点。
归根结底,处理器间的设计选择存在细微差别,但其真正影响体现在大规模应用层面而非消费者层面。专用处理器能更高效处理大型数据集,意味着用更少电力实现更快处理(不过随着AI工具更频繁使用,总耗电量可能上升)。
同样重要的是,这些术语本身处于快速演变的新兴领域。谷歌TPU于2015年发布,距今仅10年。我数不清有多少讨论最终以对AI将如何改变世界的夸张想象收场,这很大程度上源于人们认为其能力没有边界。
但,使AI成为可能的创新是由真实的人类创造的。(尽管未来AI或许能自我编程,谁又知道呢?)而驱动AI的芯片是真实的物理存在——源自硅料,并在实验室中加工制造。理解这些物理现实、我们曾必须克服的挑战及其解决方案,能帮助我们更高效地利用这些工具——并在未来创造更酷炫的事物。
硬件发展简史
这就引出了我们的历史课。要更深入理解今天的话题,需略晓计算机的物理构建方式。计算机最基础的语言是二进制代码,由0和1序列表示。这些值对应电路的开闭状态:电路闭合时电流无法通过,开路时则可以通过。晶体管用于调节电流、产生电信号,并充当开关或门控。将大量晶体管与电路连接,便构成集成电路芯片。
晶体管开闭状态的组合模式可被计算机读取。随着晶体管数量增加,能用二进制代码表示的数字范围也越来越大。这影响了我们测量比特和字节的基本计算基础:八个晶体管存储一字节数据(每个晶体管有两种状态,所有可能性的组合(2^8)即为256种开闭门(比特)组合)。因此,8比特=1字节,可表示0到255之间的任何数字。
晶体管尺寸的缩小与单芯片上晶体管密度的提升,推动了计算能力、速度和能效的进步。这主要得益于半导体材料提纯技术的突破、化学蚀刻等精密工艺的运用以及无尘车间技术的改进。这一切都始于集成电路芯片的诞生。
约在1958年,多位科学家几乎同时攻克了不同技术难题,共同促成了集成电路的发明。德州仪器的杰克·基尔比研制出混合集成电路,尺寸约为7/16×1/16英寸(11.1×1.6毫米)。而后来英特尔联合创始人罗伯特·诺伊斯则开创了单片集成电路(将所有电路集成于同一芯片),其尺寸与之相仿。
值得注意的是,最初的芯片仅能容纳约60个晶体管。而当今的微芯片能在更小的尺寸上蚀刻数十亿个晶体管。下图展示了拆解后的集成电路实物图:

现在芯片的实际尺寸比一枚硬币还要小
朋友们,这正是如今智能手机能化身口袋电脑的重要原因之一。可想而知,现代笔记本电脑或机架式服务器凭借其更大体积,能更高效地集成更多此类元件,从而催生了人工智能的崛起。
什么是FPGA?
上文所述均为芯片上固定的物理单元,但芯片性能同样受软件影响。软件定义了所有组件协同工作的逻辑与指令。因此制造芯片时有两种选择:要么针对特定软件定制专用芯片,要么采用可随时重构的"空白芯片"。
第一种称为专用集成电路(ASIC)。但如同所有专有制造工艺,必须大规模生产才能盈利,且生产周期较长。CPU和GPU通常都基于这类硬接线芯片运作。
可重构芯片被称为现场可编程门阵列(FPGA)。它们具备高度灵活性,为开发者提供多种标准接口。这对AI应用(尤其是深度学习算法)极具价值——当技术快速迭代时,FPGA能在同一芯片上通过重编程实现多功能,让开发者快速完成测试、迭代和上市。其灵活性最突出的体现是可重编程输入/输出接口,从而降低延迟突破瓶颈。正因如此,业界常将整个ASIC处理器类别(CPU/GPU/NPU/TPU)与FPGA进行效能对比,这也催生了混合解决方案。
总结:芯片技术令人惊叹
材料科学与微芯片制造的进步为AI所需处理能力奠定基础,行业巨头(英伟达、华为、英特尔、谷歌、微软等)利用这些芯片开发出专用处理器。
与此同时,软件技术实现了多处理核心组网,通过负载分配提升运算速度。所有这些进展共同催生了满足AI巨大需求的专用芯片。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)