基于地震数据的Spark数据处理与分析
本毕业设计构建了一个基于大数据技术的地震数据分析平台,旨在处理海量地震数据并支持地震预测和灾害评估。系统采用Hadoop分布式存储和Spark数据处理框架,实现TB/PB级数据的存储与分析。技术架构包括数据采集层(USGS等权威数据源)、存储层(HDFS)和处理层(Spark),支持数据清洗、特征提取、统计分析和时空模式识别。应用场景涵盖热点区域识别、关联性分析和灾害风险评估。系统采用Python
·
系统概述
设计背景与目标
本毕业设计系统旨在利用当前主流的大数据技术构建一套完整的地震数据分析平台。随着全球地震监测网络的完善和传感器技术的发展,地震相关数据呈现爆炸式增长,传统的数据处理方法已无法满足海量地震数据的存储和分析需求。本系统通过大数据技术架构,能够高效处理TB级甚至PB级的地震数据,为地震预测、灾害评估和应急响应提供数据支持。
技术架构
数据采集层
系统从多个权威数据源采集全球地震数据,包括:
- 美国地质调查局(USGS)的实时地震数据API
- 中国地震台网中心的观测数据
- 欧洲地中海地震中心(EMSC)的历史地震数据库
数据存储层
采用Hadoop分布式文件系统(HDFS)作为核心存储方案,其优势包括:
- 高容错性:数据自动在集群节点间复制(默认3副本)
- 高扩展性:支持PB级数据存储
- 低成本:可运行在普通商用服务器上
数据处理层
基于Spark框架实现高效数据处理,主要功能模块:
- 数据清洗:处理缺失值、异常值
- 特征工程:提取震级、震源深度、地理位置等关键特征
- 统计分析:计算地震频次、强度分布等指标
- 时空分析:研究地震活动的时空分布规律
分析应用场景
- 地震热点区域识别:通过历史数据聚类分析识别高频地震带
- 地震关联性分析:研究余震与主震的时间/空间关系
- 灾害风险评估:结合人口密度数据评估潜在影响
技术实现细节
开发环境
- 编程语言:Python 3.8+(主要数据分析库:Pandas, NumPy, SciPy)
- 大数据框架:Spark 3.0+(PySpark接口)
- 可视化工具:Matplotlib, Seaborn, Plotly
- 集群环境:Hadoop 3.x, YARN资源调度
核心算法
- 时空聚类算法:DBSCAN改进算法,用于识别地震活跃区
- 时间序列分析:ARIMA模型预测地震活动趋势
- 关联规则挖掘:Apriori算法分析地震序列模式
可视化方案
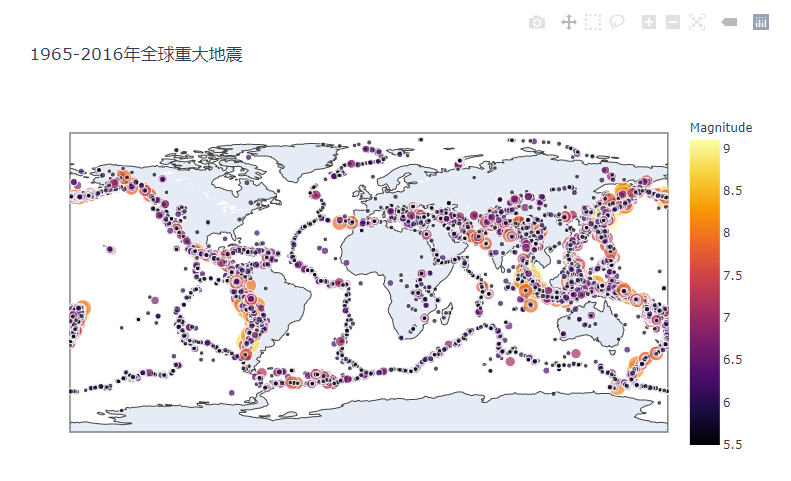
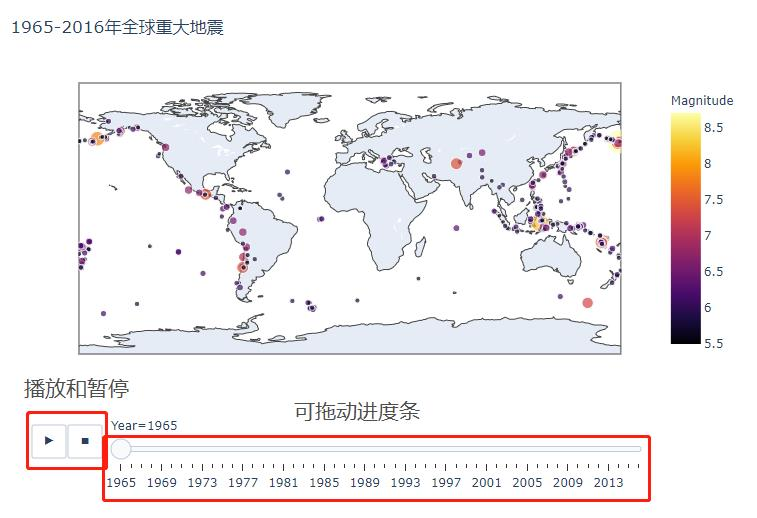
- 交互式全球地震地图(基于Folium库)
- 时间趋势折线图(展示地震频次/强度变化)
- 三维震源分布图(展示深度维度特征)
- 热力图展示地震密度分布
系统优势
- 处理效率:Spark内存计算使分析速度提升10-100倍
- 扩展性:模块化设计便于添加新的分析功能
- 可视化效果:多维度展示分析结果,支持交互式探索
- 应用价值:为地震研究和防灾减灾提供数据支撑
预期成果
- 完整的全球地震数据分析平台
- 地震活动特征分析报告
- 可视化展示系统
- 基于历史数据的预测模型

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)