python爬取多页json数据,简单易懂,适合小白
手把手教学,python爬虫,适合0基础小白快速爬取数据,简单易懂
1. json数据与python数据转换
json是一种轻量级数据交换格式,适合用于数据交互,本质是具有特定格式的字符串,但采用完全独立与编程语言的文本格式来存储和表示数据。
json键值对用来保存Javascript对象的一种方式,键值对组合中的键名写在最前面,并用双引号包裹,使用冒号分隔,然后紧接着值。例如:
{
"website":[
{"name":"哔哩哔哩","url":"www.bilibili.com"},
{"name":"百度","url":"www.baidu.com"}
]
}python中用来解码和编码json数据主要为两个函数json.dumps()和json.loads()
improt json
data = {
'name':'myname',
'age':100
}
json_str = json.dumps(data) #将python数据结构转换为json
data = json.loads(json_str) #将json数据结构转换为python2. 网站解析
豆瓣电影:https://movie.douban.com/j/chart
腾讯音乐招聘:https://join.tencentmusic.com/social?job_class=T
接下来对上面两个网址进行解析,爬取需要的数据,使用的是谷歌浏览器,先对豆瓣网页进行解析:
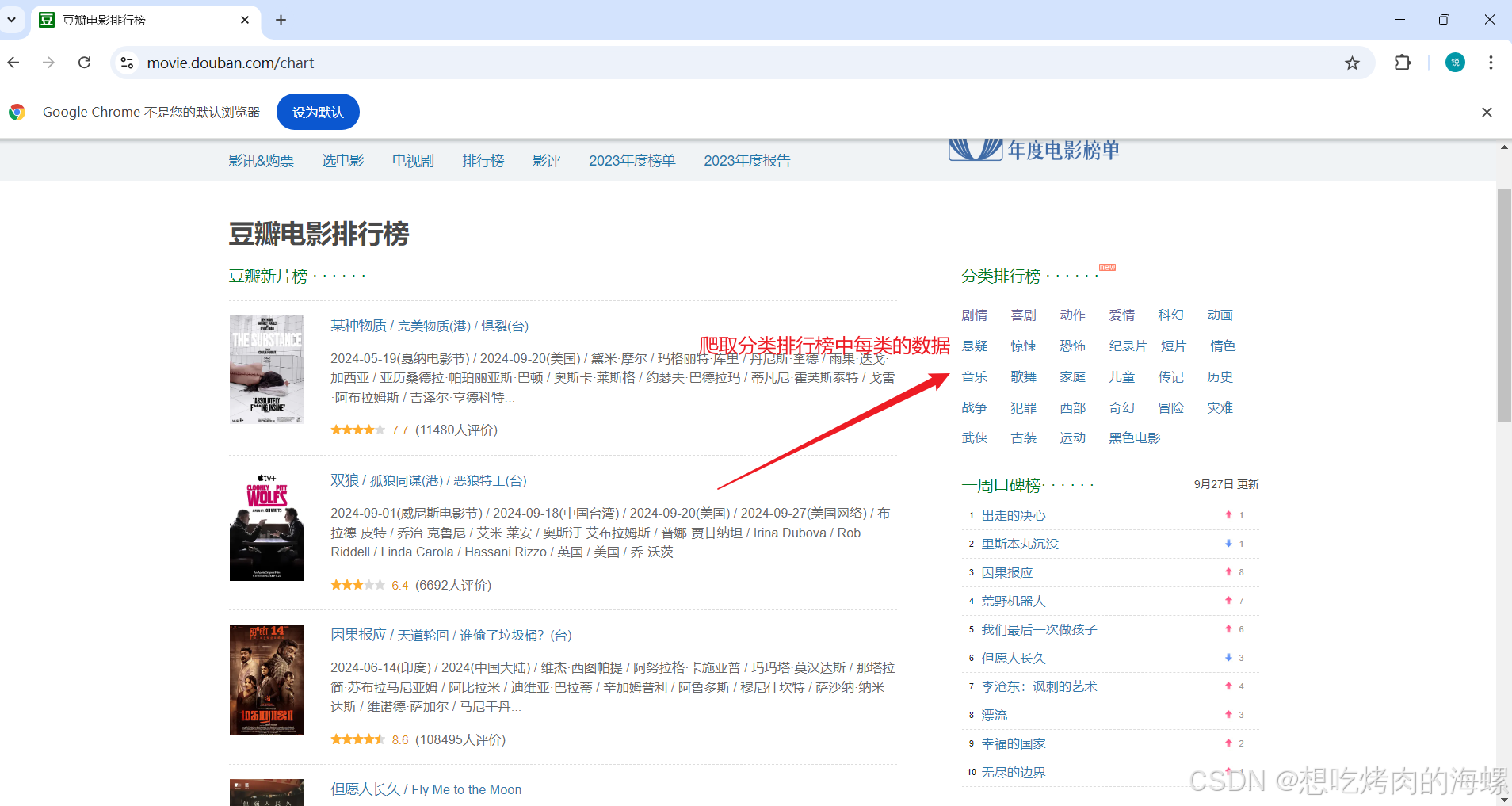
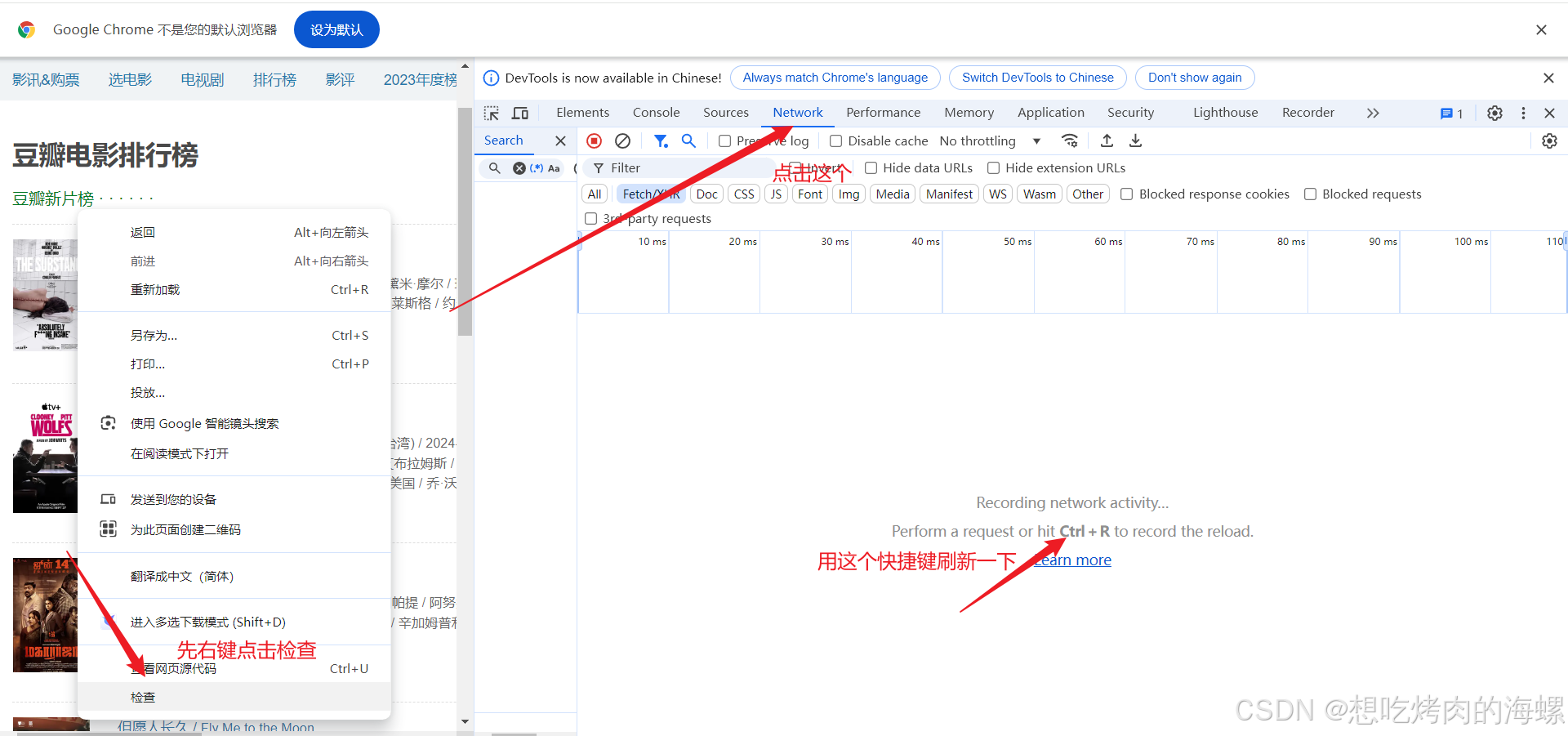
最后我们就可以得到以下信息
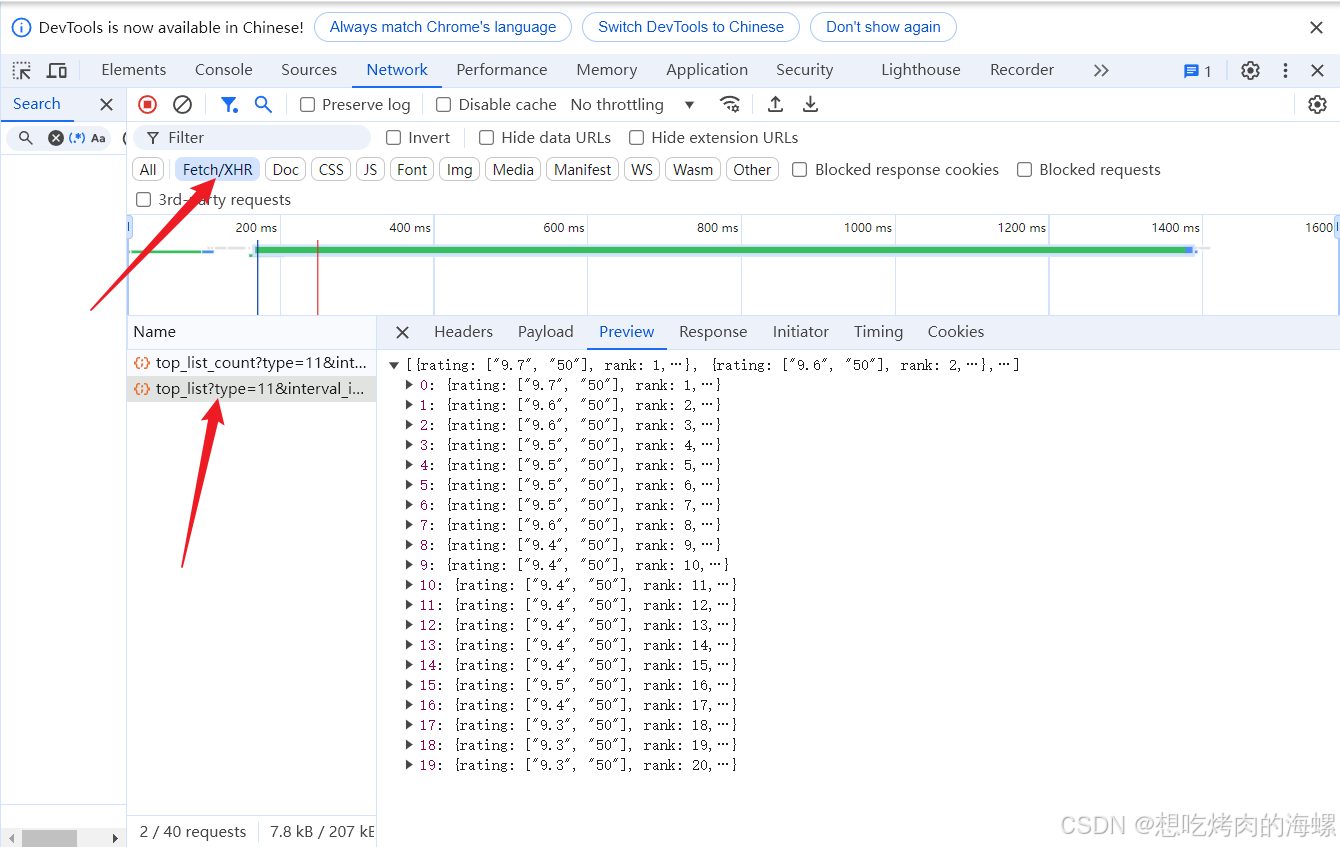
解析另一个网站也是同样的方法,但我们可以看到有很多list的XHR数据,后面会讲解怎么快速获取这些数据
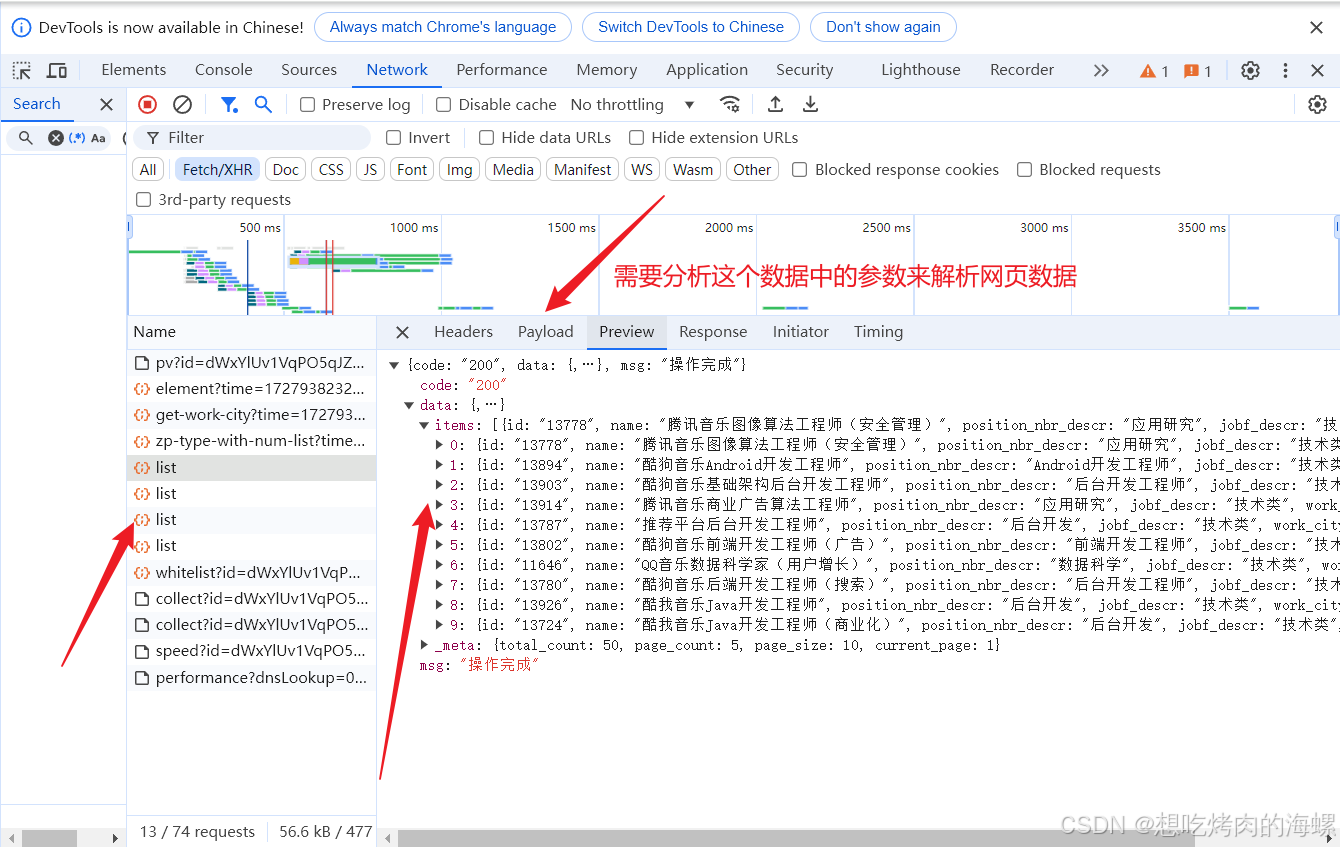
3.爬取网页数据
在我们解析完这些网页之后,我们通过requests库来请求这些数据,在headers中找到这些,取?之前的作为url,注意是GET请求,然后找到User-Agent,设置params值


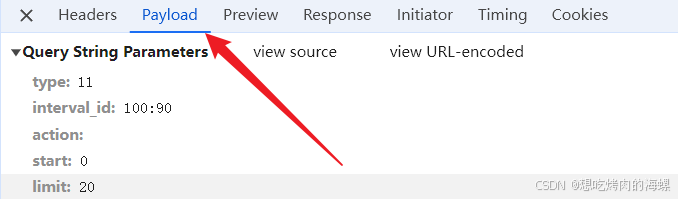
我们就可以对网站发出请求了,获取到json数据
import requests
import pandas as pd
url = "https://movie.douban.com/j/chart/top_list"
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
param = {
"type": '13',
"interval_id": '100:90',
"action": '',
"start": '0',
"limit": '20'
}
res = requests.get(url=url, headers=header, params=param)
print(res.json())但我们是需要获取到多页数据,以上代码只能帮我们获取到这个网页初始呈现的数据,因此我们需要分析params的参数值
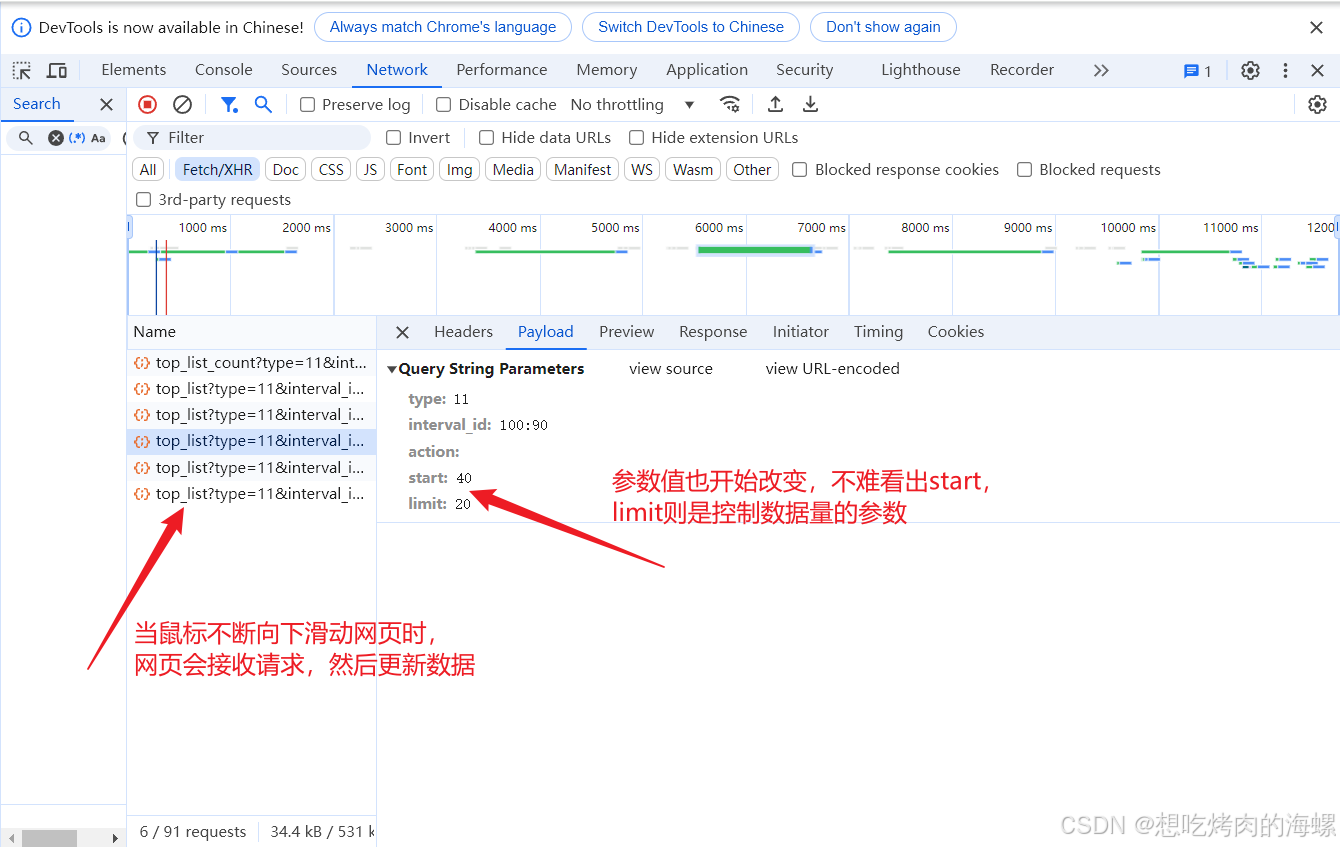
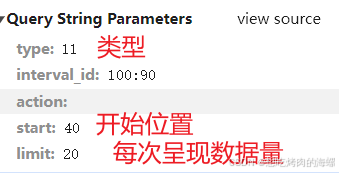
那么要爬取较多的数据和不同类型的数据,就更改参数即可
import requests
import pandas as pd
url = "https://movie.douban.com/j/chart/top_list"
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
type_list = [11,5,13]
head = ['电影名','演员','排名','时间','地区']
for n in type_list:
info_list = []
param = {
"type": f'{n}', # 电影类型
"interval_id": '100:90',
"action": '',
"start": '0',
"limit": '100' # 电影页数,网页默认显示每20条数据为1页
}
res = requests.get(url=url, headers=header, params=param)
for i in range(int(param['limit'])):
info = res.json()[i]
info_list.append([info["title"],info["actors"],info["rank"],info["release_date"],info["regions"]])
df = pd.DataFrame(info_list,columns=head)
# df.to_csv(f"{param['type']}类型电影.csv")
print(df)以下是获取数据结果


另一种情况是网页不是下拉更新数据的,而是设置了分页功能来更新数据
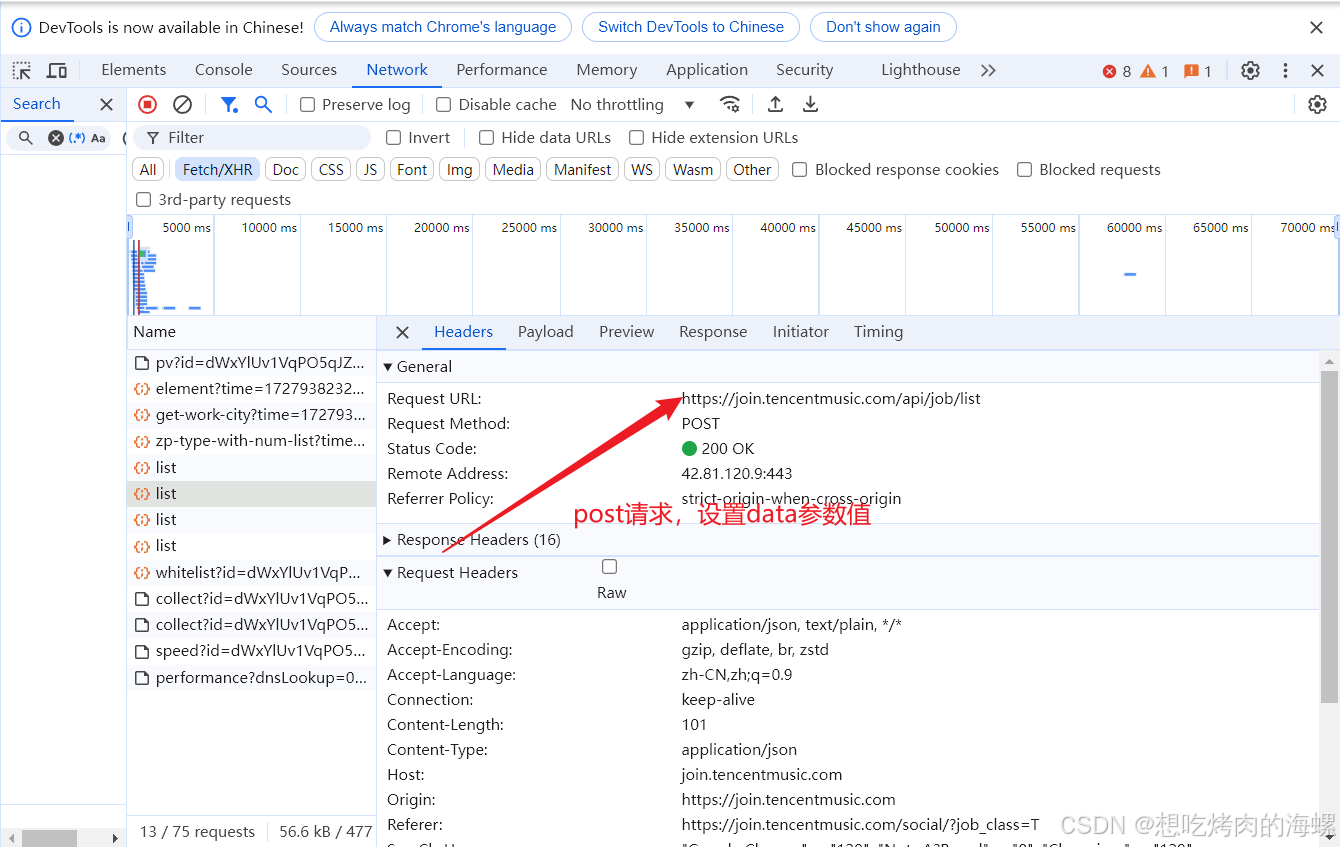

类别的设置也和data参数有关
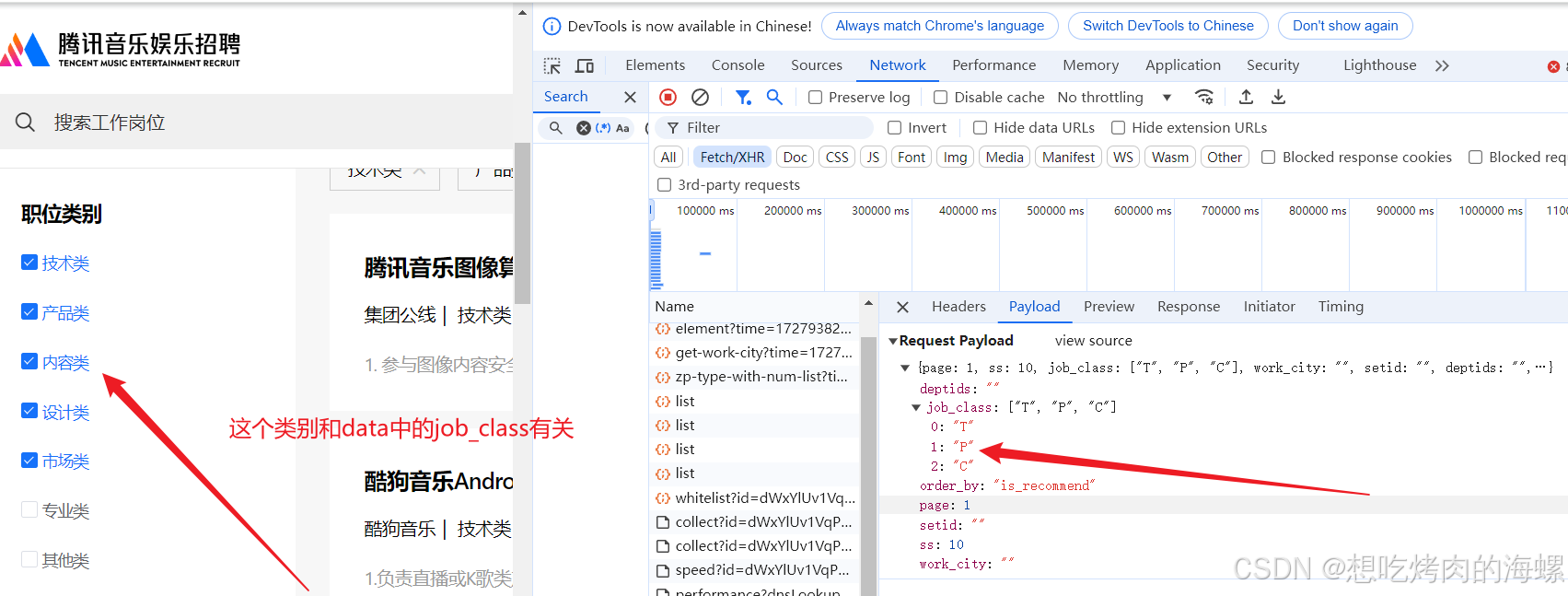

我们可以写出爬取数据代码,需要主义的是,因为不能保证每页的数据量都是10条,所以在遍历时会报错,解决方法也很简单,只需要加个异常处理就行了,来让程序执行完整
import requests
import pandas as pd
url = "https://join.tencentmusic.com/api/job/list"
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
page = 6
head = ['id','职位','类别','工作地点','需求人数']
row_list = []
for n in range(1,page+1):
data = {
"page": n,
"ss": 10,
"job_class": [
"P" #增加类别
],
"work_city": "",
"setid": "",
"deptids": "",
"order_by": "is_recommend"
}
res = requests.post(url=url,headers=header,data=data)
for i in range(data['ss']):
try:
info = res.json()['data']['items'][i]
row = [info['id'],info['name'],info['jobf_descr'],info['work_city'],info['need_num']]
row_list.append(row)
except:
break
df = pd.DataFrame(row_list,columns=head)
# df.to_csv("招聘信息(产品类).csv")
print(df)以下是获取数据结果



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)