预训练核心技术:掩码语言建模(MLM)与因果语言建模(CLM)
语言建模的目标是通过给定文本的部分内容,预测缺失的部分或生成下一个词。它是自然语言处理任务中的基础,许多高级任务(如机器翻译、问答系统等)都可以从一个良好的语言模型开始。掩码语言建模(MLM)和因果语言建模(CLM)是两种不同的预训练目标,它们在训练方式和应用场景上有所不同。MLM注重上下文的双向理解,主要应用于理解性任务,而CLM通过顺序预测来生成文本,广泛应用于生成任务。在选择模型时,需要根据
目录
预训练核心技术:掩码语言建模(MLM)与因果语言建模(CLM)
近年来,基于Transformer的语言模型,如BERT和GPT,在自然语言处理(NLP)领域取得了令人瞩目的成果。这些模型的核心技术便是语言建模(Language Modeling),它们通过不同的训练目标来学习语言的规律。掩码语言建模(MLM)和因果语言建模(CLM)是其中两种重要的预训练目标。本文将深入讲解这两种技术的原理,并通过代码实践对比它们的区别。
1. 什么是语言建模?
语言建模的目标是通过给定文本的部分内容,预测缺失的部分或生成下一个词。它是自然语言处理任务中的基础,许多高级任务(如机器翻译、问答系统等)都可以从一个良好的语言模型开始。
语言建模的分类:
- 自回归语言建模(Causal Language Modeling, CLM):该方法生成每个词时,只依赖于该词之前的内容,模型是顺序的。
- 掩码语言建模(Masked Language Modeling, MLM):该方法通过随机掩码(遮蔽)输入句子中的一些词,训练模型去预测这些被掩码的词。
接下来,我们将深入对比这两种建模方法的原理,并通过代码实践来展示它们的实现。
2. 掩码语言建模(MLM)
掩码语言建模(MLM)首先通过掩盖输入句子中的一些词(即将词替换成[MASK]符号),然后要求模型预测这些被掩码的词。这一目标的核心在于通过上下文信息推断被掩码的词。
2.1 原理
- 在训练时,输入句子中的一部分词会被随机掩码,模型的任务是根据上下文预测这些被掩码的词。
- 掩码语言建模并不要求预测词的顺序,它可以在任意位置进行掩码。
公式:对于输入句子S = w_1, w_2, ..., w_n,其中一部分词被掩码,目标是训练模型预测掩码部分的词w_i,即:
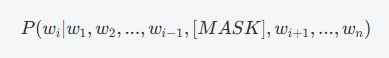
2.2 代码示例(BERT)
在BERT模型中,输入文本的部分词会被随机替换为[MASK],模型的任务是基于上下文预测这些词。以下是一个简化的BERT模型掩码语言建模代码示例:
import torch
from transformers import BertTokenizer, BertForMaskedLM
# 初始化BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
# 输入文本
text = "The quick brown fox jumps over the lazy dog."
# 将文本转为token
inputs = tokenizer(text, return_tensors="pt")
input_ids = inputs["input_ids"]
# 掩码一些token
masked_index = 4 # 假设我们将“brown”替换为[MASK]
input_ids[0, masked_index] = tokenizer.mask_token_id
# 输入到BERT模型中,进行预测
outputs = model(input_ids)
logits = outputs.logits
# 获取[MASK]位置的预测词
mask_token_logits = logits[0, masked_index]
predicted_token_id = torch.argmax(mask_token_logits)
predicted_token = tokenizer.decode(predicted_token_id)
print(f"原文: {text}")
print(f"预测词: {predicted_token}")
在这个示例中,我们将文本中的“brown”词替换为[MASK],然后使用BERT模型来预测被掩码的词。
3. 因果语言建模(CLM)
因果语言建模(CLM),也叫自回归语言建模,是指在生成文本时,模型基于前文的上下文来预测当前词的概率。它不同于MLM,CLM模型通过当前和之前的词生成下一个词,这使得生成过程是有顺序的。
3.1 原理
- 在训练时,模型通过左到右的顺序来生成文本。对于每个位置,模型只考虑该位置之前的词来预测下一个词。
- 因为是顺序生成,所以CLM模型是自回归的。
公式:对于输入句子S = w_1, w_2, ..., w_n,模型的任务是逐步生成下一个词,目标是训练模型根据前文生成当前词:
P(wi+1∣w1,w2,...,wi)P(wi+1∣w1,w2,...,wi)
3.2 代码示例(GPT)
GPT模型是典型的因果语言模型,它的输入是一个序列,模型根据该序列逐步预测下一个词。以下是一个简化的GPT模型因果语言建模代码示例:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 初始化GPT模型和tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 输入文本
text = "The quick brown fox"
# 将文本转为token
inputs = tokenizer(text, return_tensors="pt")
# 输入到GPT模型中,进行预测
outputs = model(**inputs, labels=inputs["input_ids"])
# 获取下一个词的预测
logits = outputs.logits
predicted_token_id = torch.argmax(logits[0, -1, :]) # 预测最后一个词
predicted_token = tokenizer.decode(predicted_token_id)
print(f"原文: {text}")
print(f"预测下一个词: {predicted_token}")
在这个示例中,GPT模型会基于“quick brown fox”生成下一个词。
4. MLM与CLM的对比
为了帮助大家更好地理解掩码语言建模(MLM)与因果语言建模(CLM)的异同,我们可以通过以下表格进行对比。
| 特性 | 掩码语言建模(MLM) | 因果语言建模(CLM) |
|---|---|---|
| 训练目标 | 预测掩码位置的词 | 预测下一个词 |
| 上下文依赖 | 使用全局上下文(左右上下文) | 仅使用左侧上下文(前文) |
| 模型结构 | BERT(双向编码) | GPT(单向编码) |
| 输入数据 | 输入中随机掩码一些词 | 输入为一个完整的句子或片段 |
| 适用任务 | 主要用于文本分类、填空等任务 | 主要用于文本生成、对话生成等任务 |
| 训练方式 | 随机掩码词并进行预测 | 自回归预测下一个词 |
| 模型训练顺序 | 无顺序约束,可以同时考虑前后文 | 有顺序约束,只能考虑前面的词 |
5. 选择哪种模型?
- BERT(MLM):适用于需要理解上下文关系、做分类、填空的任务,如情感分析、问答等。BERT模型由于其双向训练的特性,能够更好地捕捉上下文信息。
- GPT(CLM):适用于文本生成任务,如对话生成、文章写作等。GPT模型的自回归特性使其能生成流畅的文本内容,广泛应用于生成式任务。
6. 总结
掩码语言建模(MLM)和因果语言建模(CLM)是两种不同的预训练目标,它们在训练方式和应用场景上有所不同。MLM注重上下文的双向理解,主要应用于理解性任务,而CLM通过顺序预测来生成文本,广泛应用于生成任务。在选择模型时,需要根据任务的需求选择合适的训练目标。
希望本文能帮助您更好地理解这两种预训练技术,并能够根据实际需求在应用中做出合理的选择。如果有任何问题,欢迎留言讨论!
推荐阅读:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)