机器学习过程(线性回归)—— 模型构造与优化
一,机器学习基本过程
机器学习模型训练三大步骤:
- 建模(找函数):Function with Unknown Parameters
- 定义损失函数(Loss Function):Define Loss from Training Data
- 优化(Optimization)
以预测明日文章订阅量的任务(Regression,回归)为例。在此例中,机器学习的过程就是通过前几个月甚至几年的数据,机器找到一个函数能够预测明日的订阅情况,即
1.Function with Unknown Parameters
第一步需要我们写出一个代表未知参数的函数式,简单来说就是先猜测一下这个能预测明日订阅情况的函数式。以最简单的线性形式为例(guess based on domain knowledge),我们假设这个式子是
是明日的订阅量,准备预测的数值
是昨日的订阅量,已知值。
是未知参数,要通过之前的数据算出。
称为bias,
称为weight。
这个函数式就是我们常说的Model。此模型称为线性模型(Linear models)
2.Define Loss from Training Data
Loss称为损失函数,写作。它通过计算模型预测值和真实目标值(label)的差距,给函数的拟合效果打分(判断参数选择的好坏)。值越小表示参数选择的越好。
Loss函数实际上根据任务的不同有多种不同的形式,这里的回归任务(Regression)通常使用MSE/MAE,MAE全称Mean Absolute Error,写为,
是真实值,称为label。MSE全称Mean Square Error,写为
。
假设,则
,
。接下来利用过去数据计算此函数式预测的每日的误差,然后都加起来取平均:
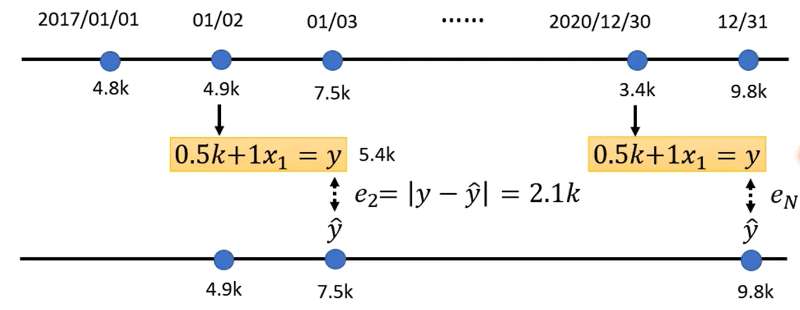
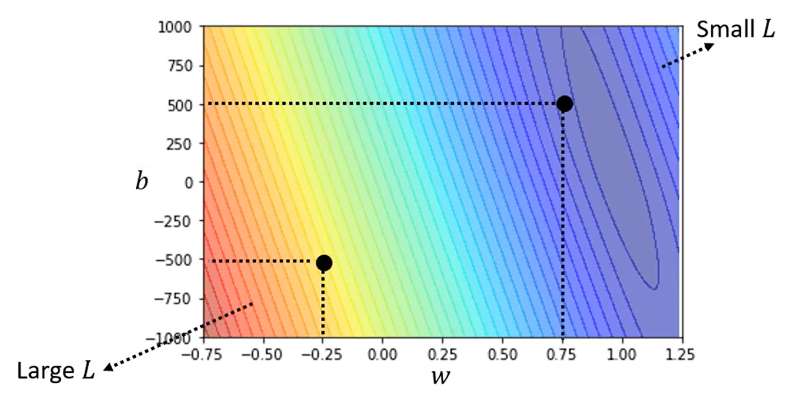
我们可以选取不同的,计算得到不同的Loss,Loss值最小的那个
就是我们要找的。如下图不同
组合得到的Loss值,颜色越浅代表Loss越小。
3.Optimization
在此案例中,Optimization的目的就是找一个最佳的使
最小,即
要找到最佳,最常用的方法是梯度下降(Gradient Desent)。对
分别进行Gradient Desent,下面以
为例:
与
的数值对应关系如下曲线所示。
第一步要随机选取初始点(此处为随机选取,之后可能会有更多的方法来选取一个合适的初始点):
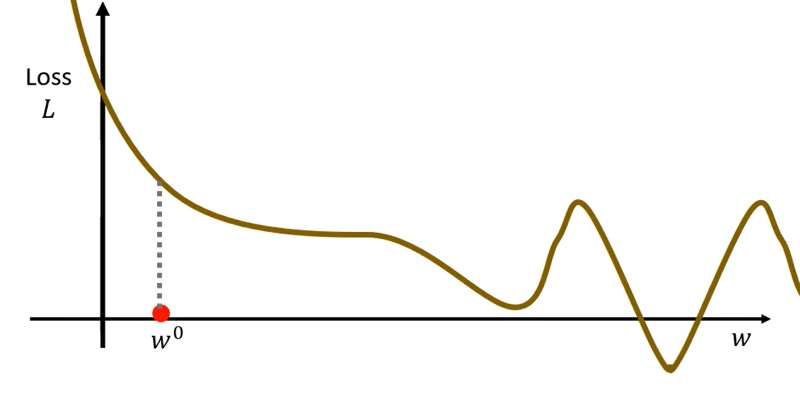
第二步计算处
对
的微分,即
。如果计算出来是负数表示左高右低,则将
增加。
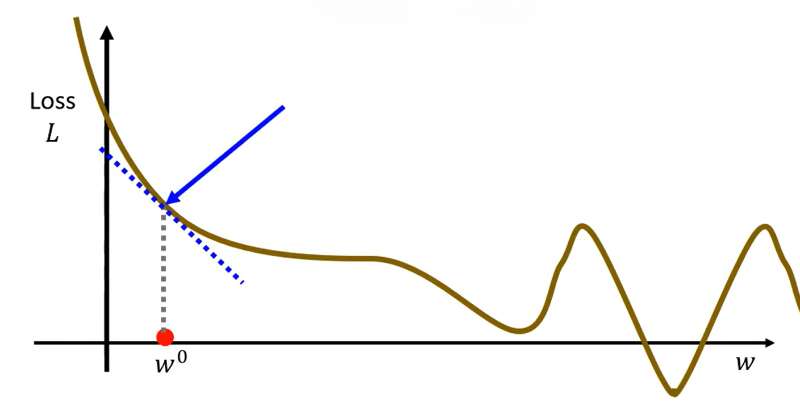
第三步更新的值。更新长度为
,也就是取决于微分大小和
(Learning Rate,学习率)。(
是一个超参数(hyperparameters),所谓超参数是指在模型训练开始前,由人工预先设定、无法通过训练数据自动学习得到的参数,用于控制模型的训练流程、结构设计与优化策略,是调控模型性能和训练行为的外部配置项)
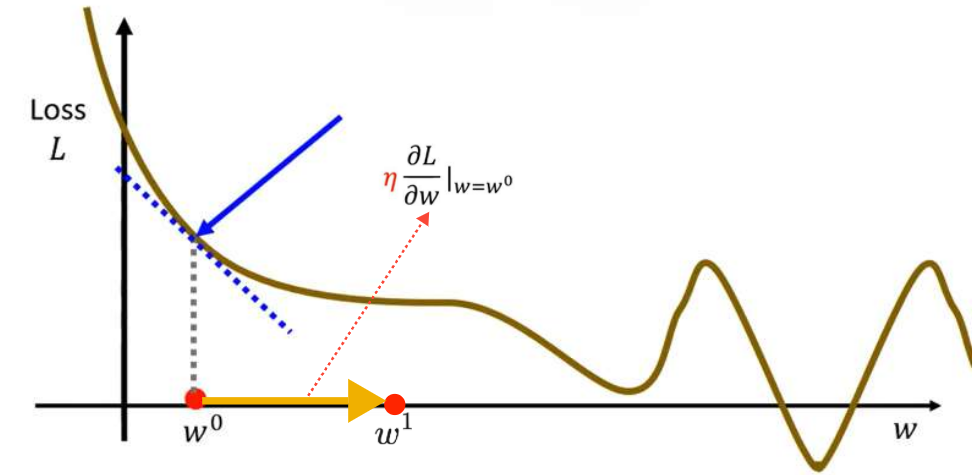
接下来重复上述操作,计算处梯度,根据梯度值再更新
。最终会停止更新(两种情况下会停止,第一种情况是自己设定要参数更新几次停止,这也是一个hyperparameters;第二种情况是更新到最小值处,最小值处梯度为0,不再更新)
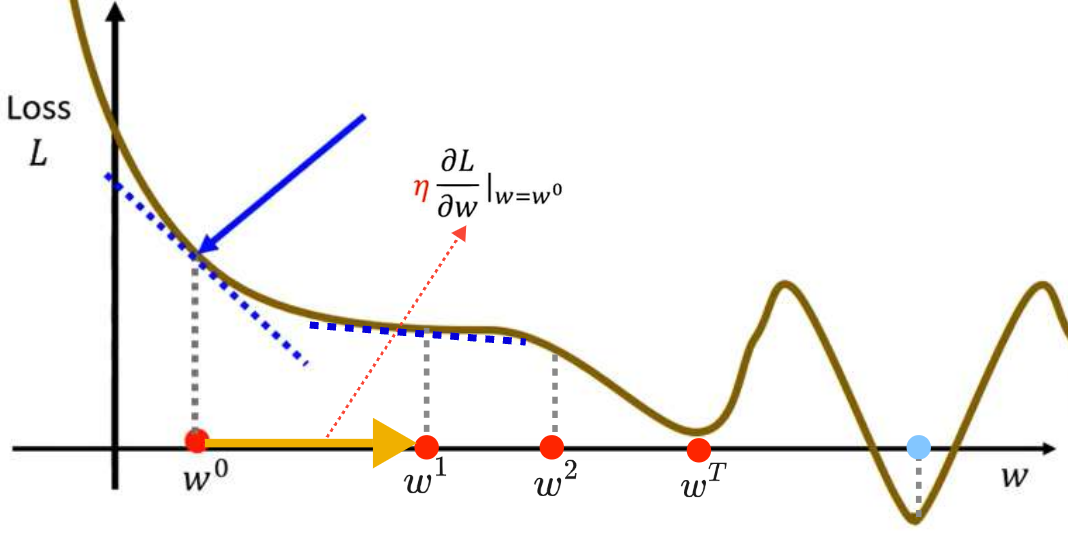
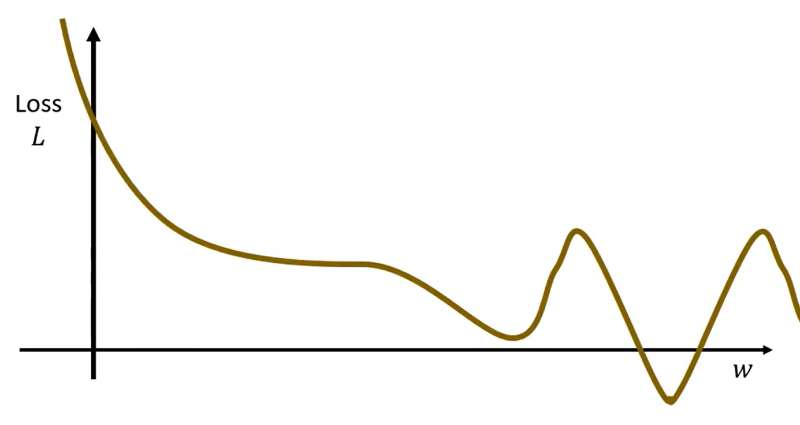
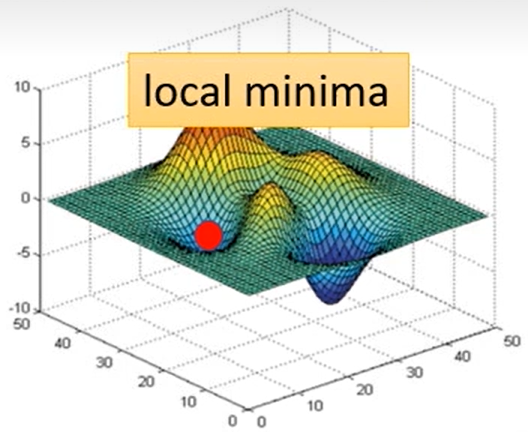
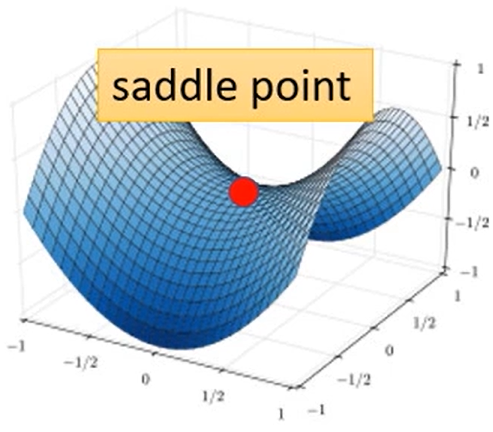
⭐但是Gradient Desent这个方法会有两个临界点(critical point)问题,导致Loss不下降或者下降到一定程度就不再下降:
- 局部最优问题(local minima):看上图介绍的更新过程就可以发现蓝点才是真正最优的点,但是我们找到局部最优的
就停止了,这就是梯度下降的局部最优问题,具体体现为该点邻域内损失值最小,但并非全局最小。全局最优点称为global minima,局部最优点称为local minima。
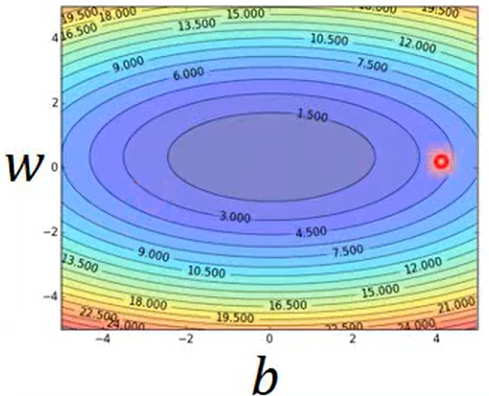
在Linear Regression中,损失函数是凸面的(convex),它的俯视图就如右图所示,所以不存在局部最优问题。
- 鞍点问题(saddle point):鞍点同样是损失函数梯度
的临界点,具体体现为在部分参数维度上是局部极小,另一些维度上是局部极大,不属于极值点;高维空间中鞍点周围会形成梯度趋近于 0 的平坦高原区,梯度下降会在此处停滞、收敛极慢;
- 在深度学习神经网络中,高维参数空间出现的局部最优点很少,并且绝大多数局部极小值的损失值、模型性能与全局最优高度接近,极少出现 “劣质局部最优”;而参数维度越高,鞍点数量呈指数级增长,并且鞍点的平坦区会让梯度模长趋近于 0, vanilla 梯度下降会陷入长期停滞,是训练收敛缓慢的核心原因之一。后续学习过程中会介绍解决方法。
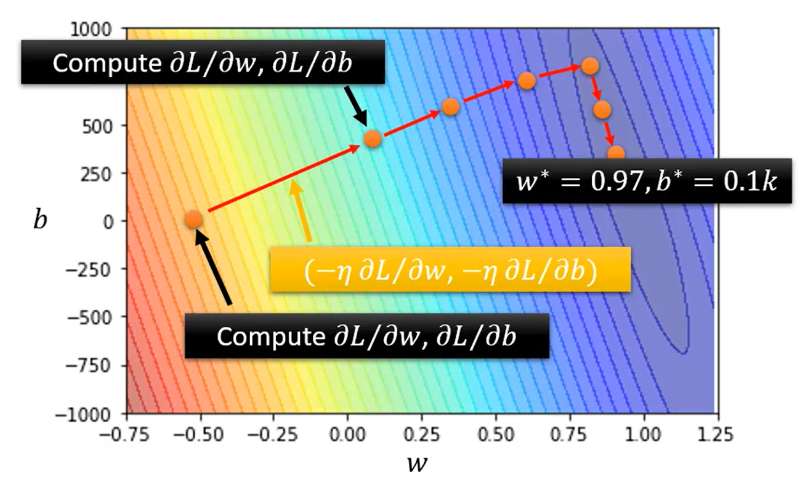
两个参数的Optimization的过程和上述是一样的:
- (Randomly) Pick initial values
- Compute:
- Update
二,模型改进与优化
线性模型改进
按照训练数据推导出的最佳模型是:
经过计算,此数据在训练集上的误差,在测试集上的误差
。下面是预测测试集2021.1.1-2021.2.14几天的订阅数据,红线为真实数据,蓝线为上述模型预测的数据。
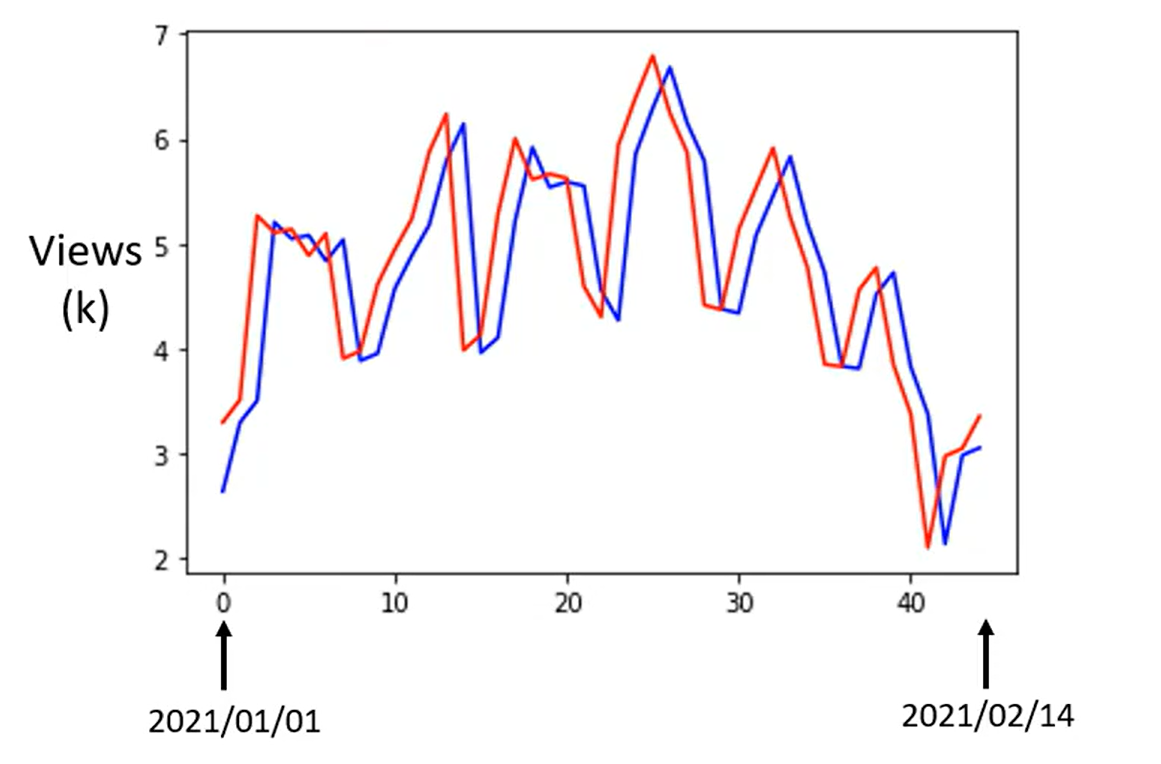
通过上图可以看到订阅数有一个明显的周期性(周期为7),为了进一步减小预测误差,我们可以考虑改进模型,改进思路是通过前7日的数据来预测明日的数据。改进模型:
经过计算,此模型在训练集上的误差,在测试集上的误差
。其中
与
的最佳值如下:

接下来继续改进模型考虑前28天:
经过计算,此模型在训练集上的误差,在测试集上的误差
继续改进模型考虑前56天:
经过计算,此模型在训练集上的误差,在测试集上的误差
可以看到误差几乎没有变化了,再考虑天数来改进模型的思路不会有太大效果了。
非线性模型改进
上述对线性模型的改进是通过考虑多个样本之间的关联性,在线性模型中加上更多的一次项,这是一种改进思路,它考虑了文章订阅量的周期性。
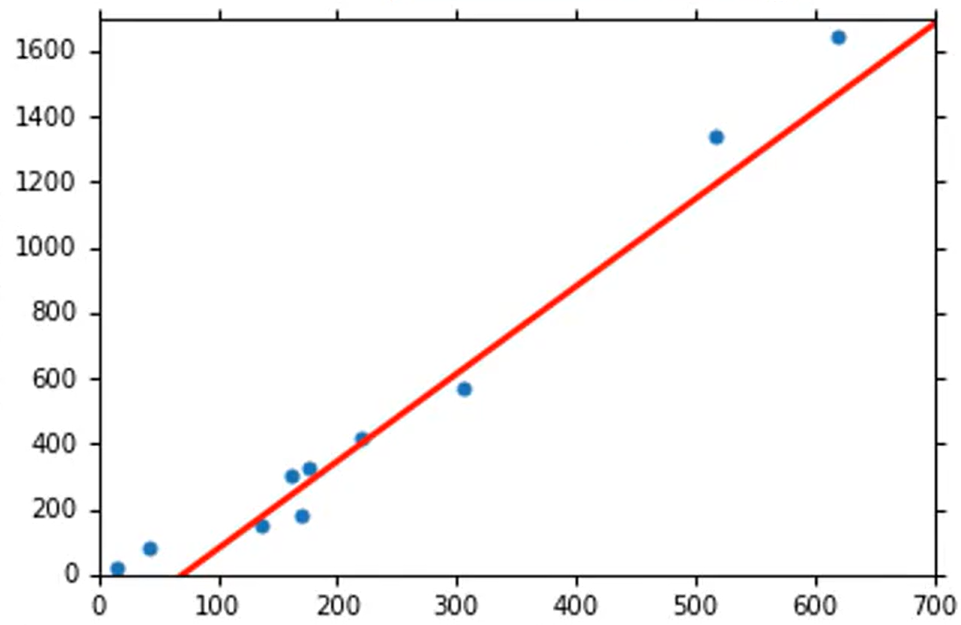
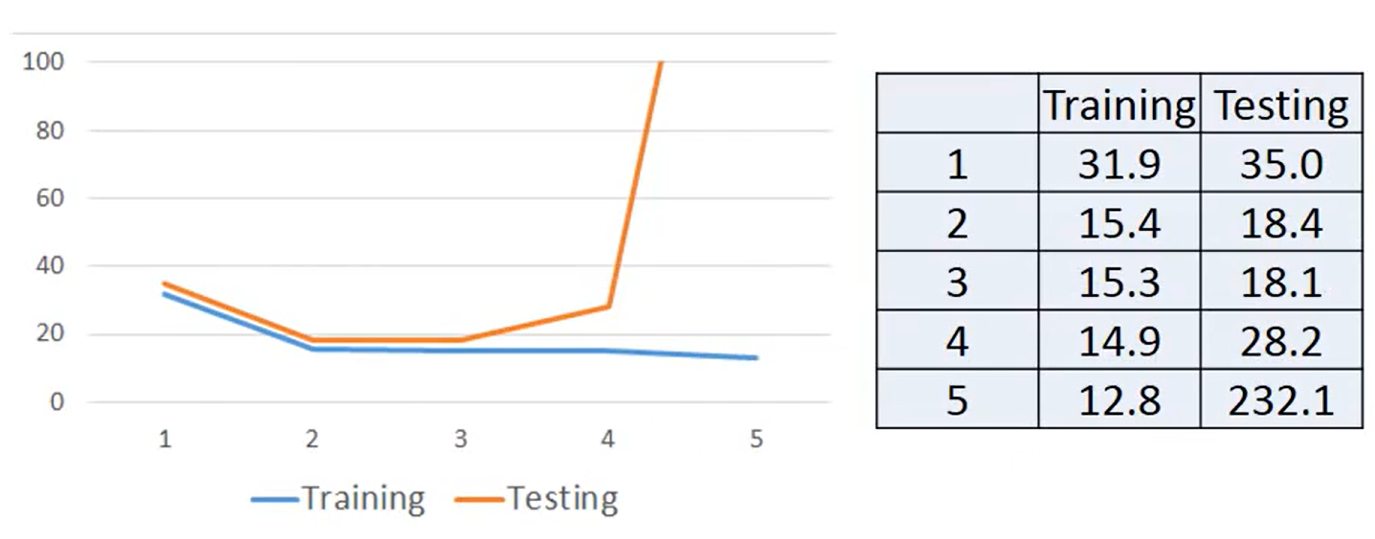
对于非周期性的数据,其改进思路是在原本的线性模型中加上二次项、三次项等非线性元素。如下所示某任务通过纯线性模型对于实验数据预测的最优曲线如下所示。此时在训练集上Average Error=35.0,在测试集上 Average Error=31.9。
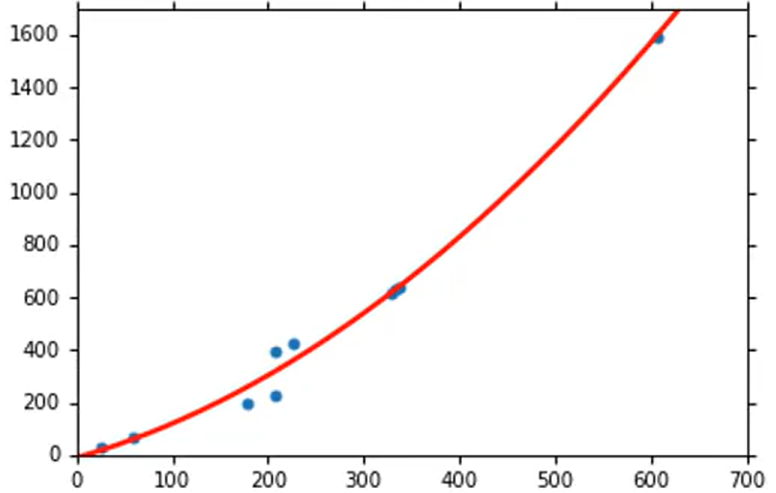
当将模型修改为后,最优曲线如下。此时在训练集上Average Error=15.4,在测试集上 Average Error=18.4。
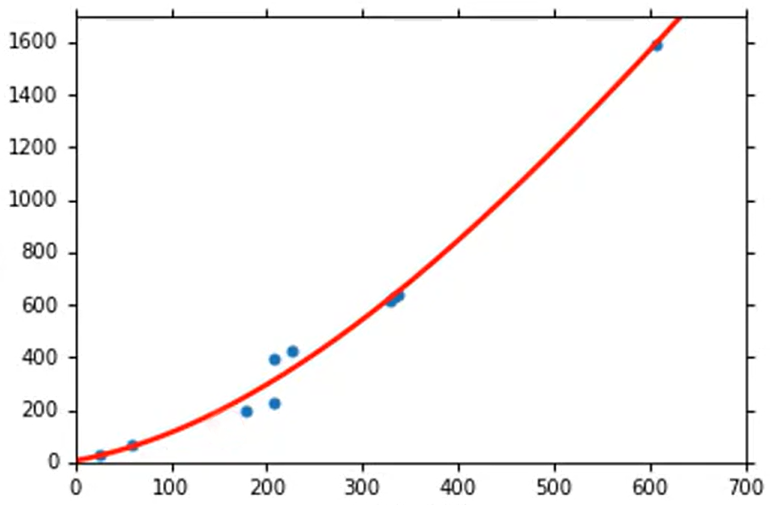
将模型修改为后,最优曲线如下。此时在训练集上Average Error=15.3,在测试集上 Average Error=18.1。
将模型修改为后,最优曲线如下(左图数据点为训练集,右图数据点为测试集)。此时在训练集上Average Error=14.9,在测试集上 Average Error=28.8。可以看到出现了明显的Overfitting。
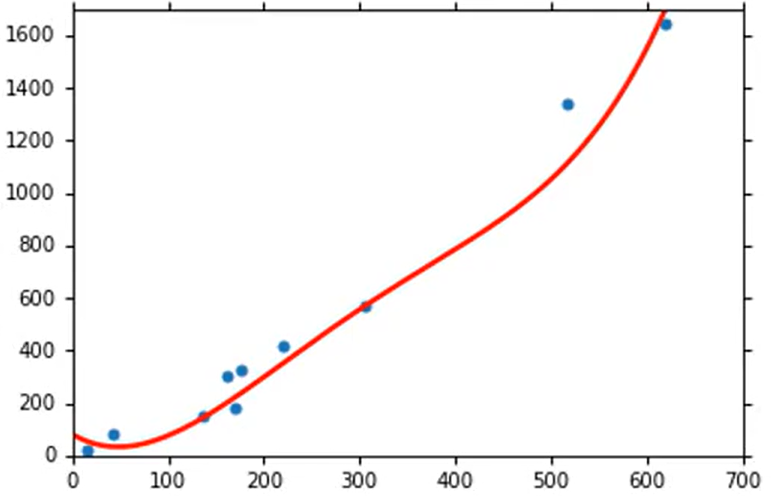
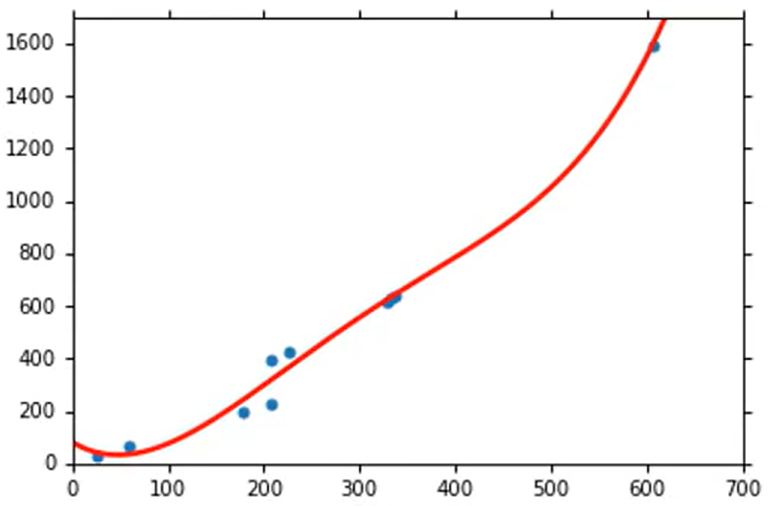
将模型修改为后,最优曲线如下(左图数据点为训练集,右图数据点为测试集)。此时在训练集上Average Error=12.8,在测试集上 Average Error=232.1。出现了更严重的Overfitting。
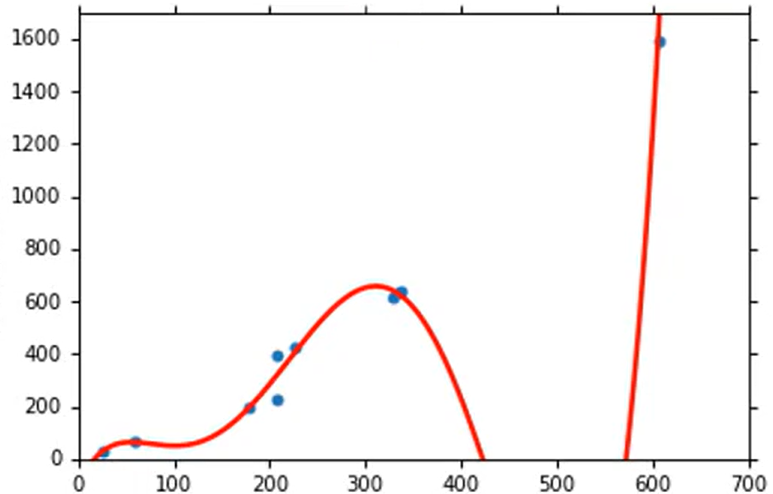
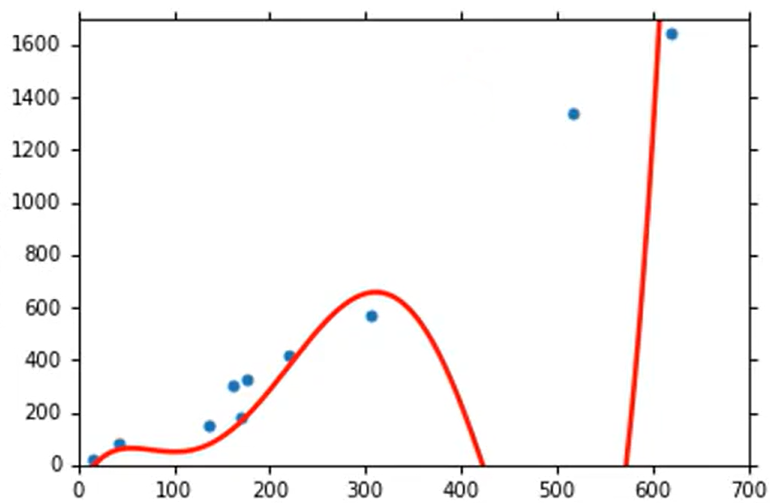
各种非线性模型数据总结如下:
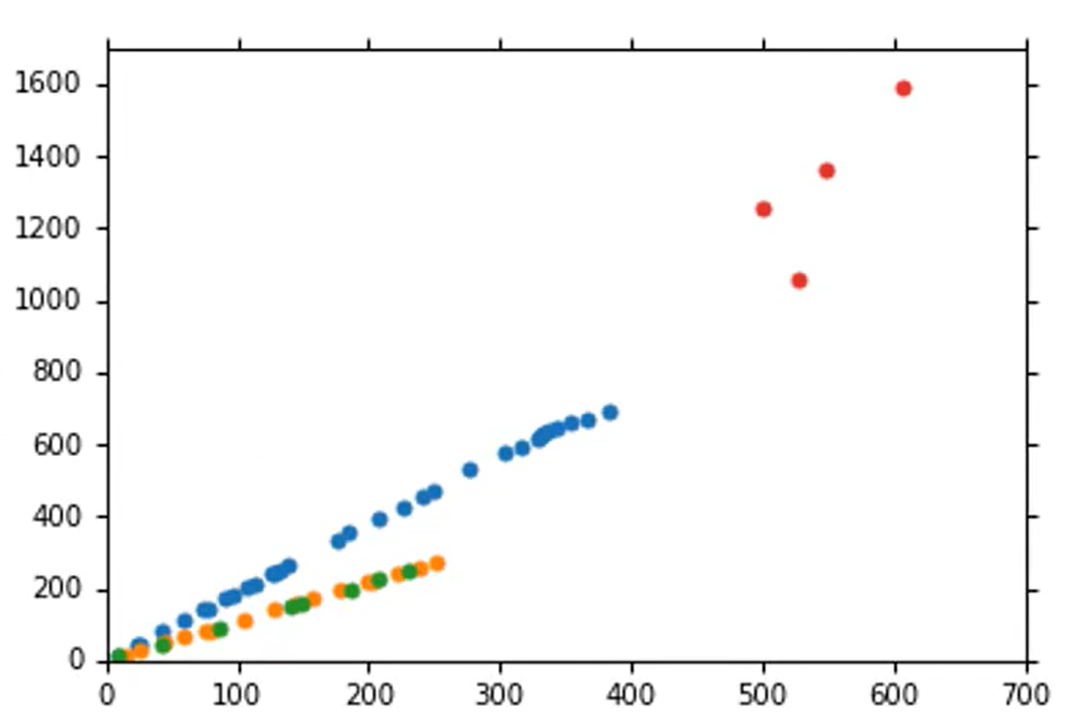
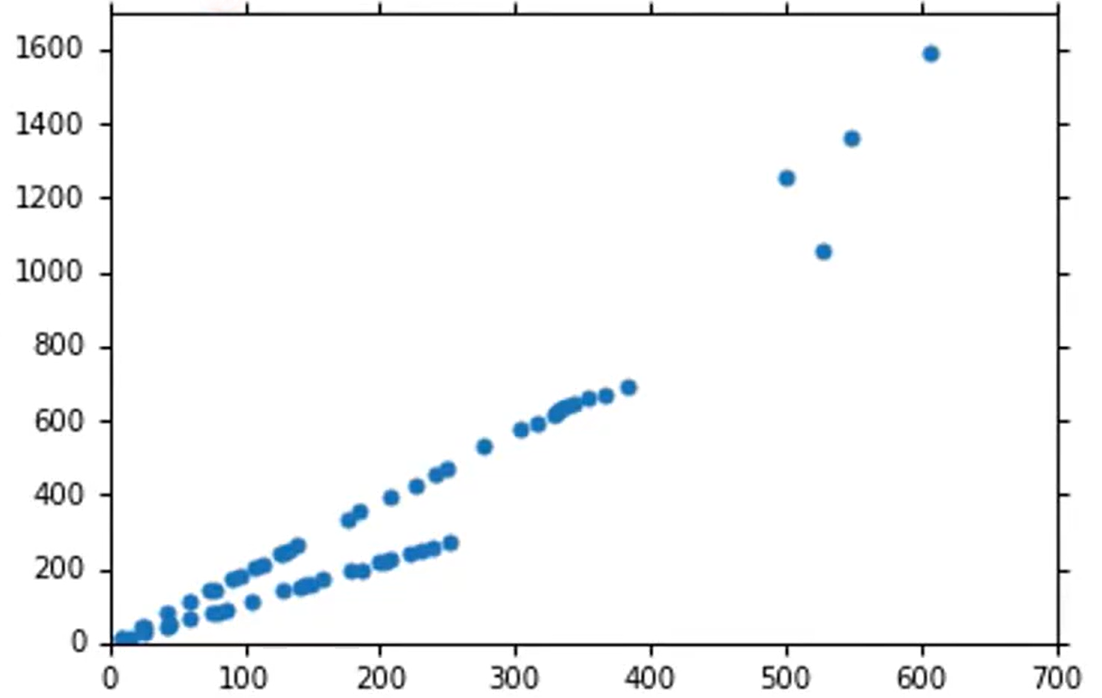
当数据出现明显的差别时,如下所示,数据出现了明显的聚类特征,这时要进行回归就不能只使用之前的改进方案。可以考虑使用分段函数。分段的前提是要知道哪个因素导致了这种聚类,通过研究样本数据发现是不同种类的样本之间的函数关系存在不同,如下右图所示,蓝色、红色、黄色、绿色数据点各属于一个种类,对这些不同种类分别找一个函数来做回归(种类要已知)。
构建模型如下所示:
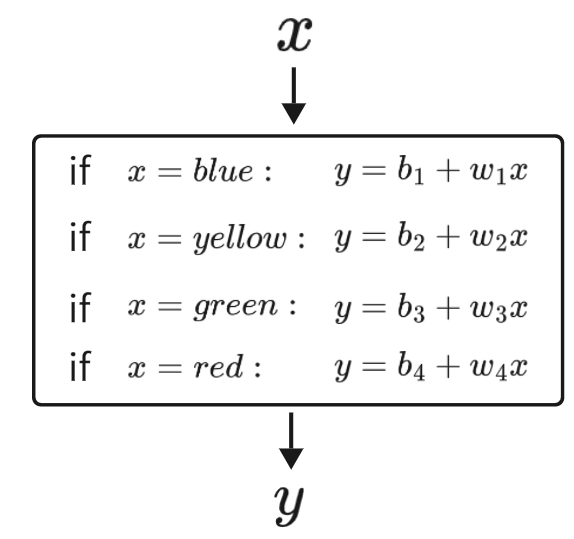
实际上这个模型就类似于预测明日订阅数的周期性模型,展开得
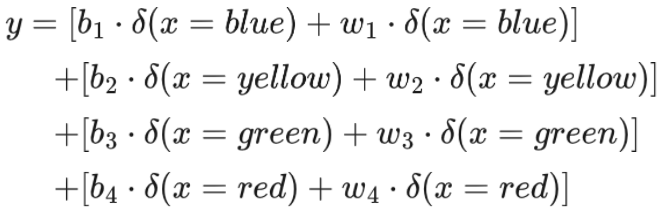
其中如果,则
,否则为0。
同理。
最终得到的最优曲线如下所示。此时在训练集上Average Error = 3.8,在测试集上 Average Error=14.3。
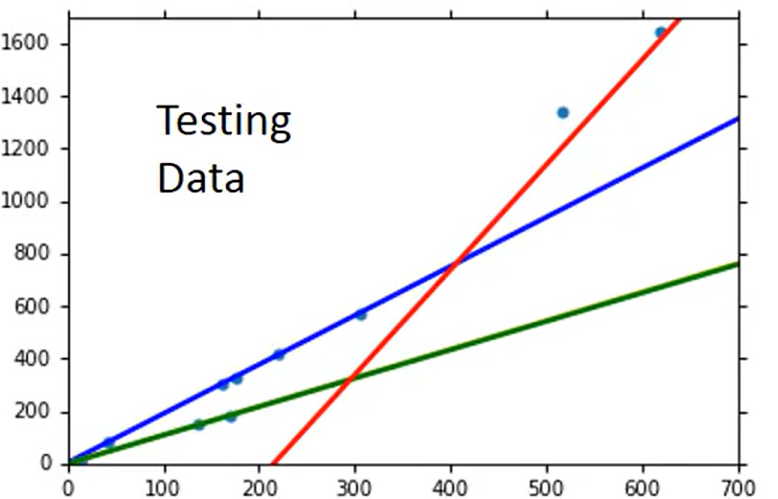
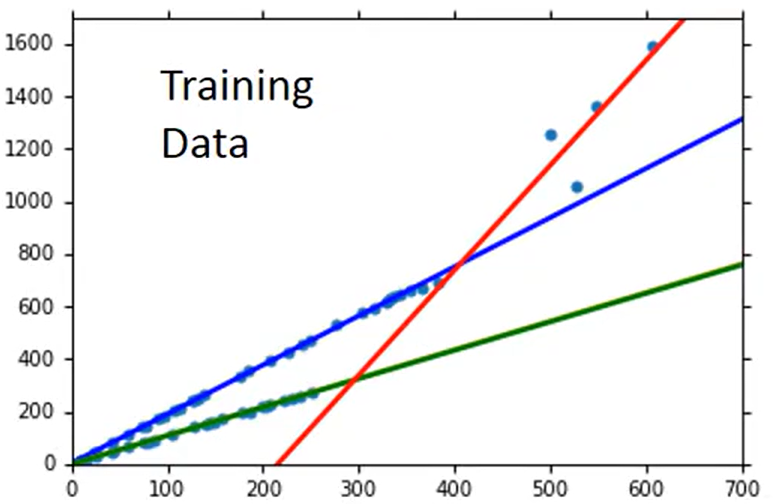
继续对上述模型进行优化。如果你觉得可能有其他因素,比如身高()、体重(
)、时间(
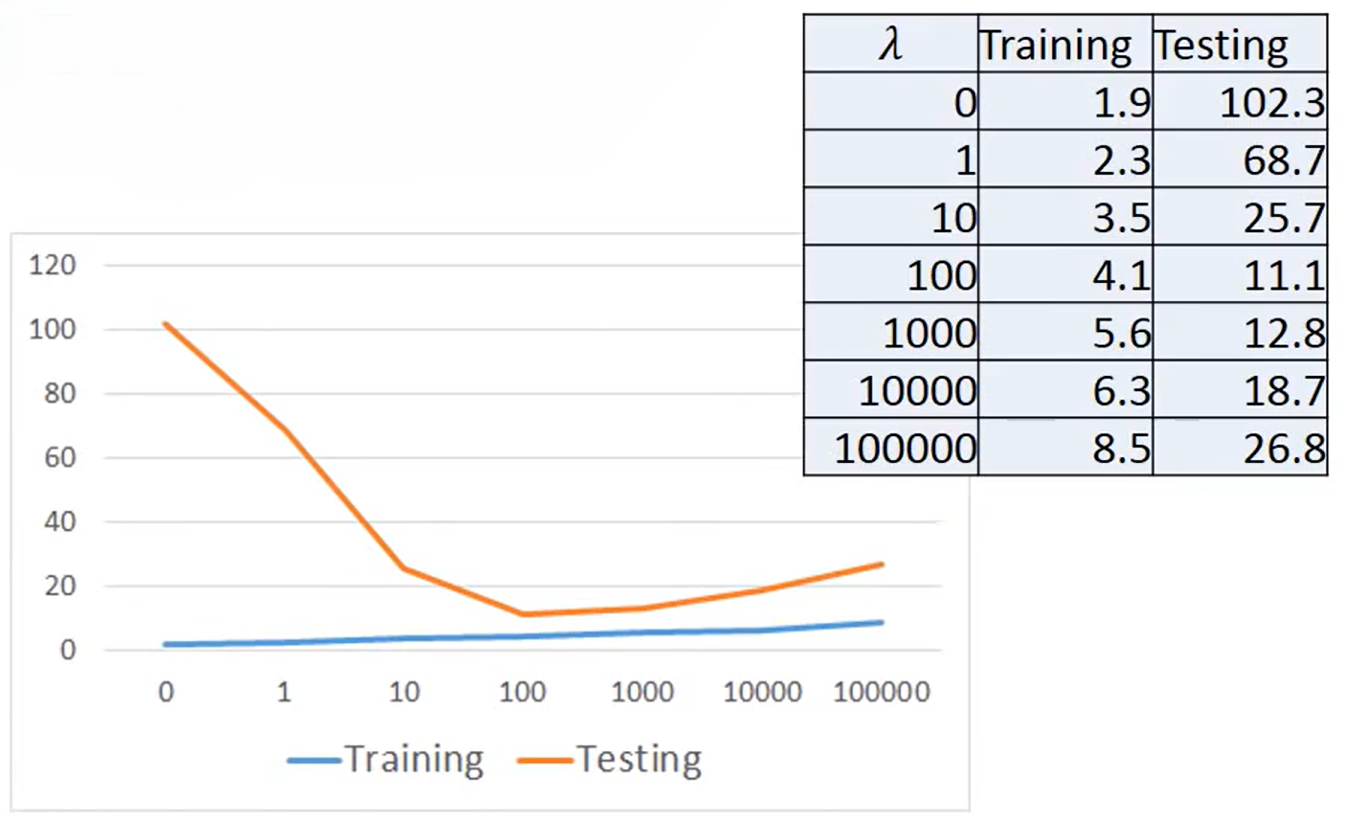
)等因素对此数据可能有影响,那么你可以在将其加入到模型中。然后结合之前的非线性,可以写一个复杂的模型训练试一试,如下所示,最终得到在训练集上Average Error = 1.9,在测试集上 Average Error=102.3。可以看到这个模型过拟合了,说明这个模型太复杂,仍需优化。
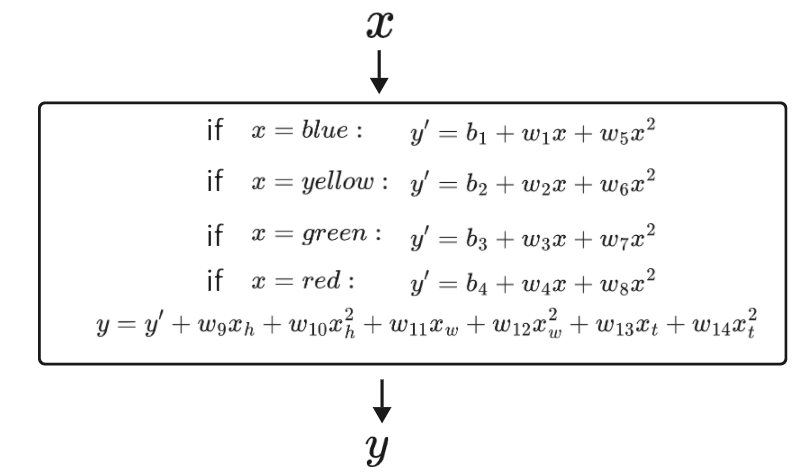
构造模型的过程本身就是一个未知的过程,你可以将你认为重要的因素加进去作为输入,你可以通过线性、非线性(二次、三次、四次等)来构建模型,也可以考虑到实际数据的周期性或者是数据样本的种类区别来构造不同的模型,就像上面的过程一样。
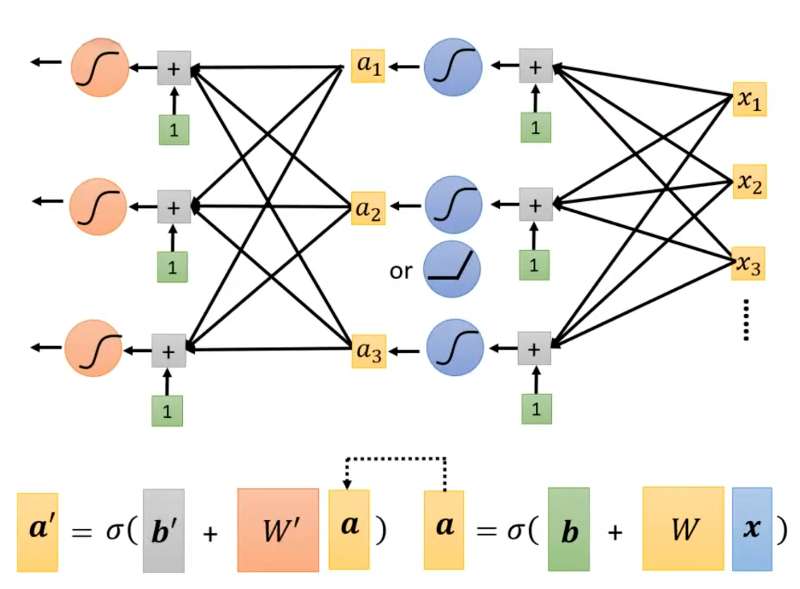
在经典的神经网络中,通常通过激活函数Sigmoid来将线性模型非线性化,利用激活函数优化模型的过程如下:
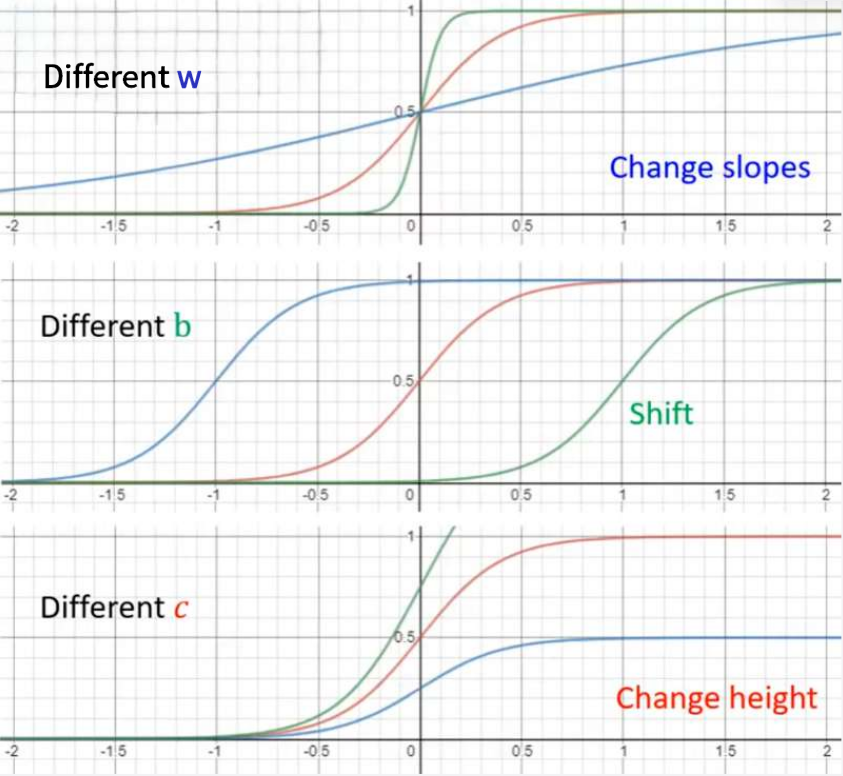
Linear models可以很好表示符合直线分布的数据,选取不同的和不同的
就可以表示不同的斜率、高度。
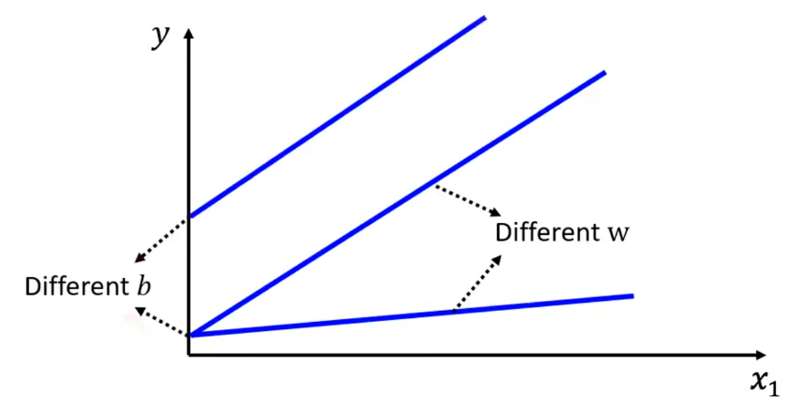
但是对于折线、曲线使用Linear models就会出现很大的偏差。(Linear models有很大的限制,称为Linear Bias) 我们需要一个更复杂更有弹性的model去表示更复杂的折线、曲线。
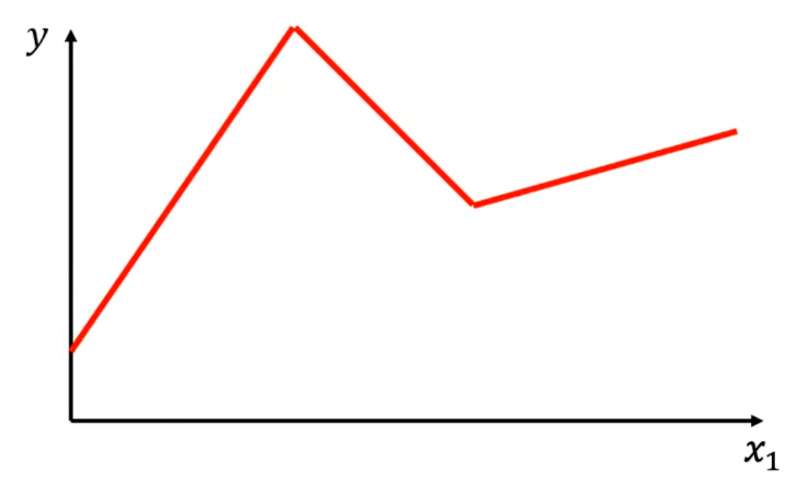
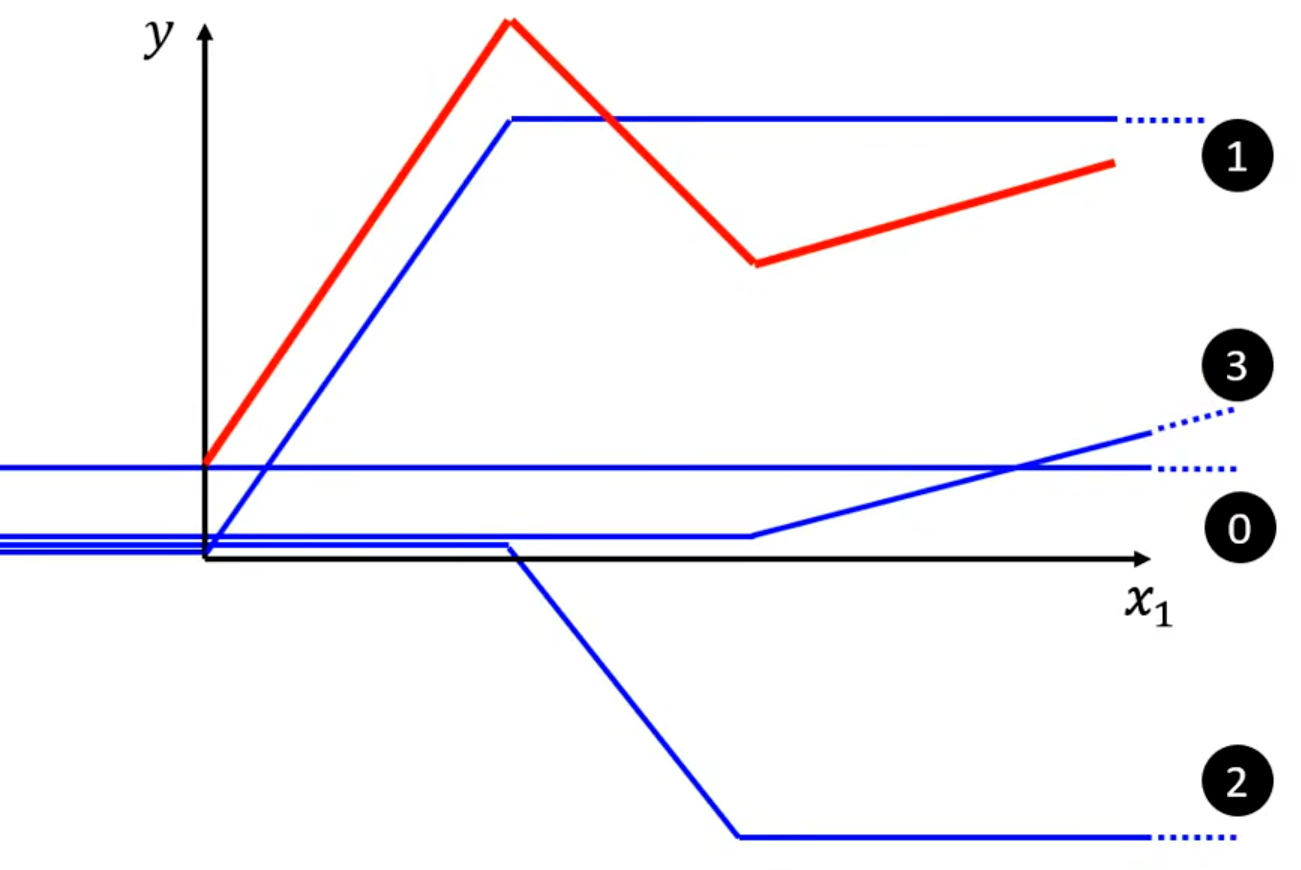
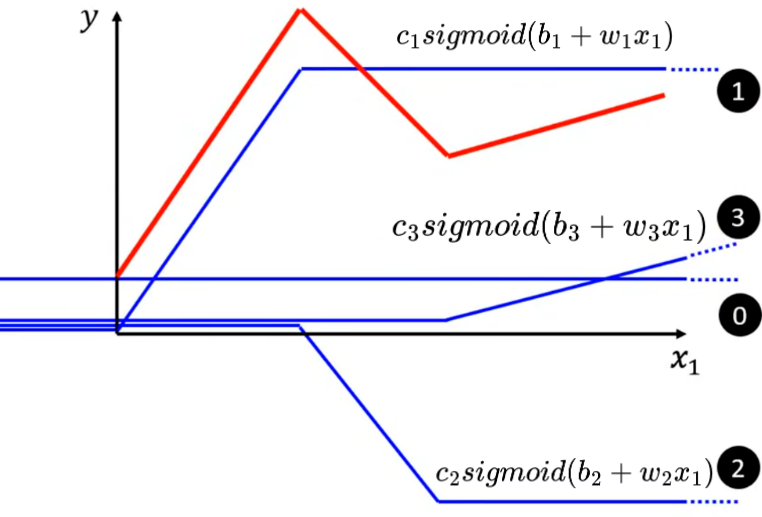
任意的折线都可以用 常数 + 一段特殊折线 表示,即:

以上图红色折线为例,选取常数项(标号0)、特殊折线1、特殊折线2、特殊折线3(每段特殊折线的中间部分的斜率与其对应红色折线的斜率相等)。将这几段折线加到一起即可得到红色折线。(折线有几段线段就需要几个特殊折线拼出)
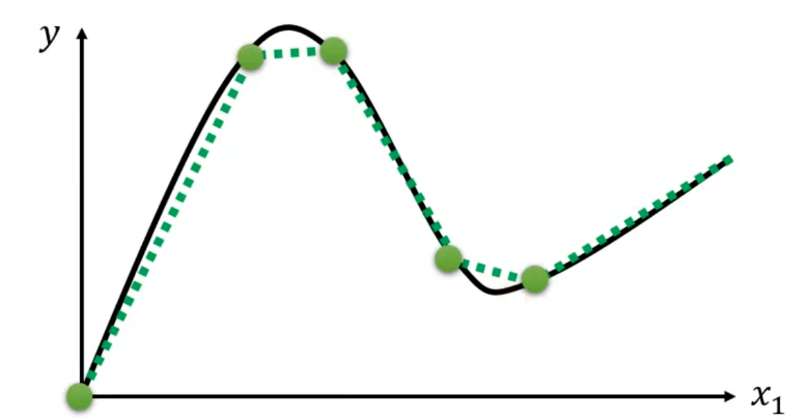
对于曲线,可以看成是由很多段折线组成。只要点取的越多,最终的图像就越逼近曲线,同时需要的特殊折线也就更多(也是一个hyperparameters)。
这段特殊折线(Hard Sigmoid)通常用一段类似的曲线函数(Sigmoid或ReLU)来近似表示(以Sigmoid Function为例):
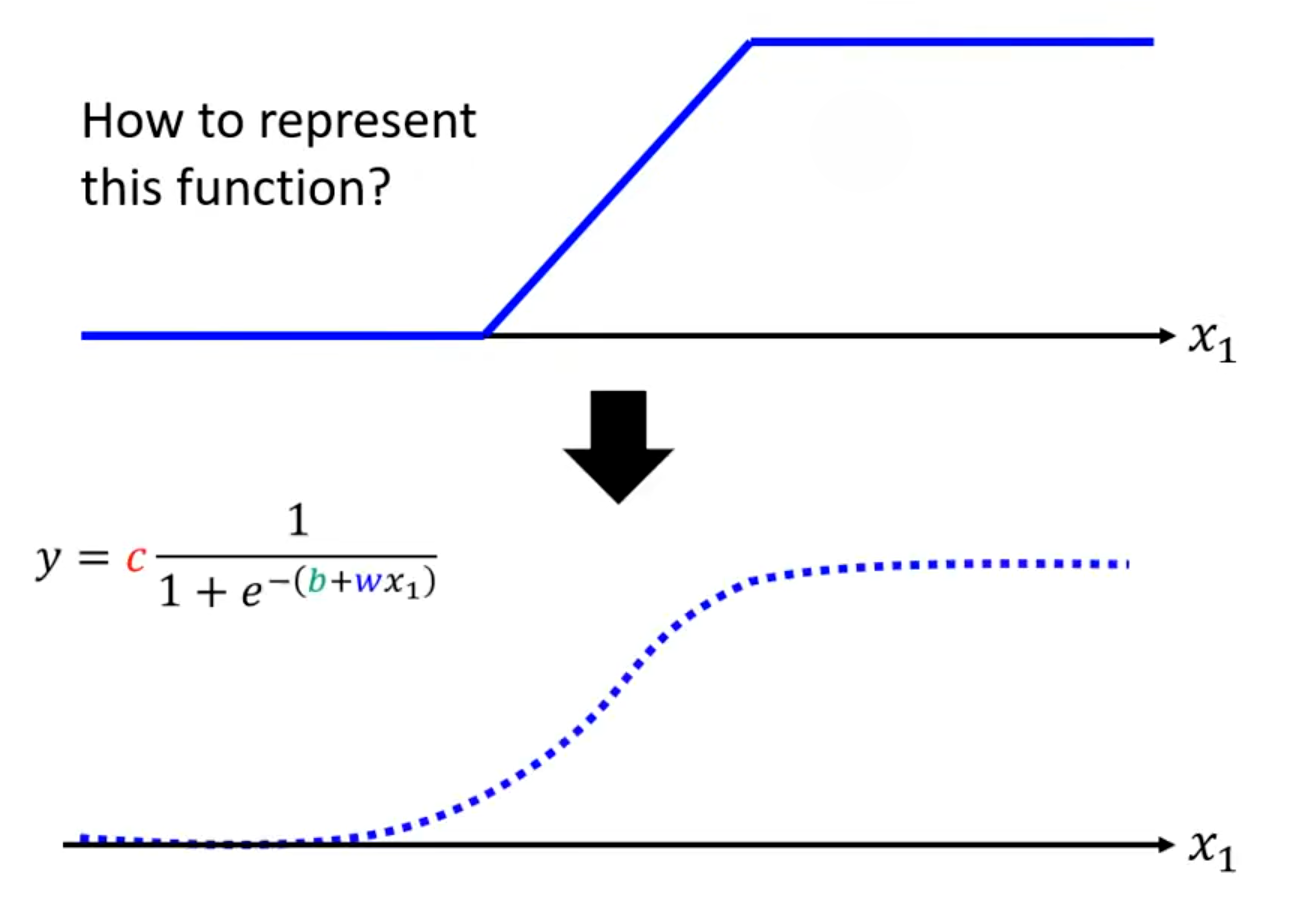
。不同的
分别决定了Hard Sigmoid的斜率、平移、高度。
仍以下图折线为例,将Hard Sigmoid1、Hard Sigmoid2、Hard Sigmoid3加起来后得到:
补充:ReLU
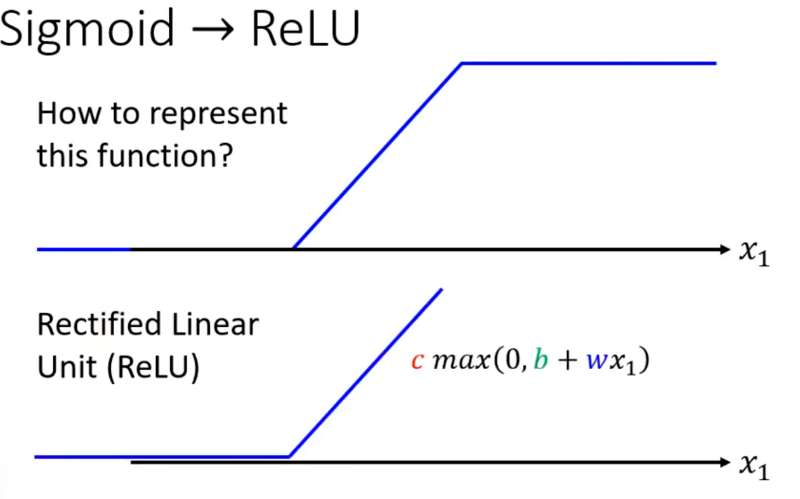
Sigmoid和ReLU在机器学习里称为激活函数(Activation function)
通过Sigmoid得到New Model:
假设,
:
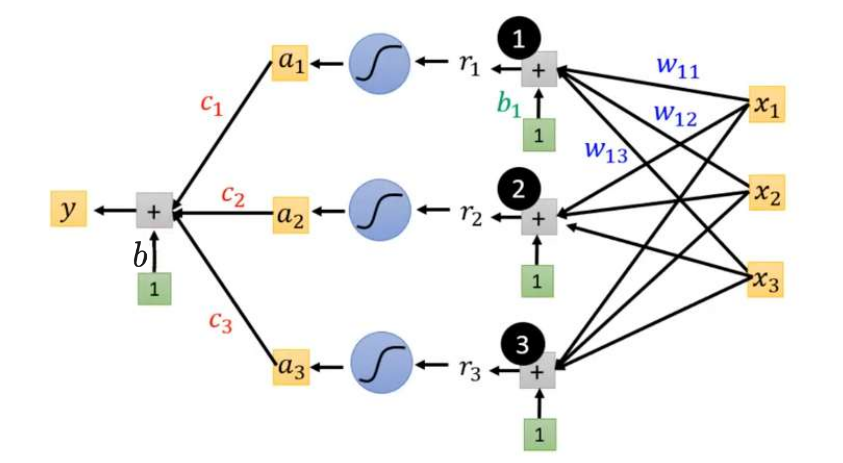
其中:
用矩阵表示为:
用向量表示为:
所以上述图像可以表示为:
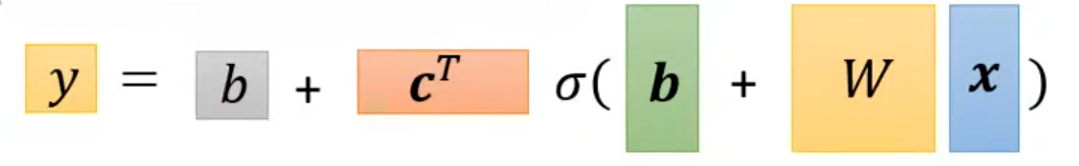
未知参数(Unknown parameters)为:
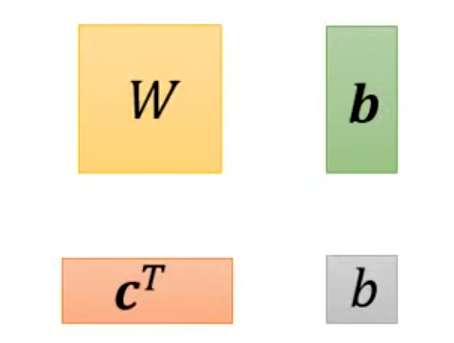
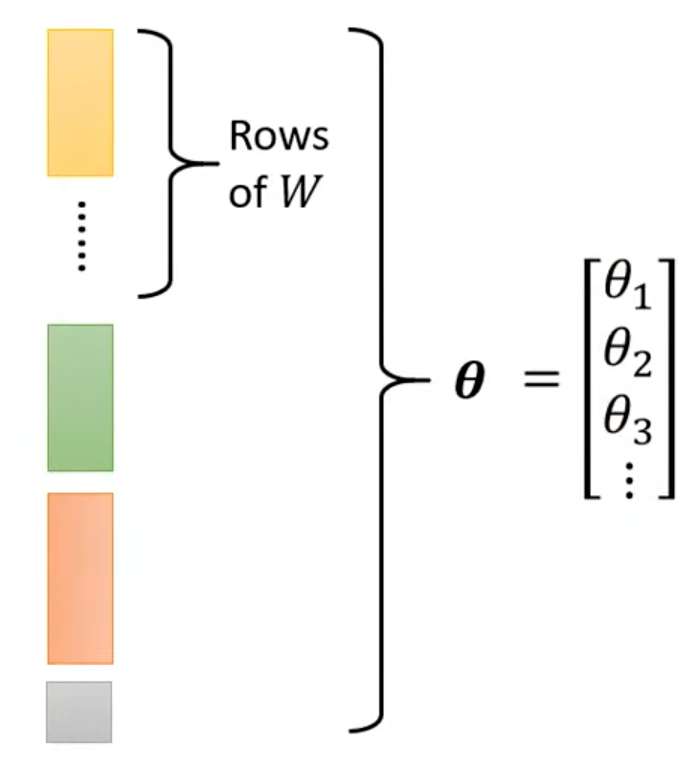
将这些参数排成一列,统一用表示:
在New Model上的损失函数,计算方法与之前一样;Optimization的步骤也与之前相同,求解:
- 1.(Randomly) Pick initial values
- 2.Compute:
,也写作
- 3.Update
interatively:
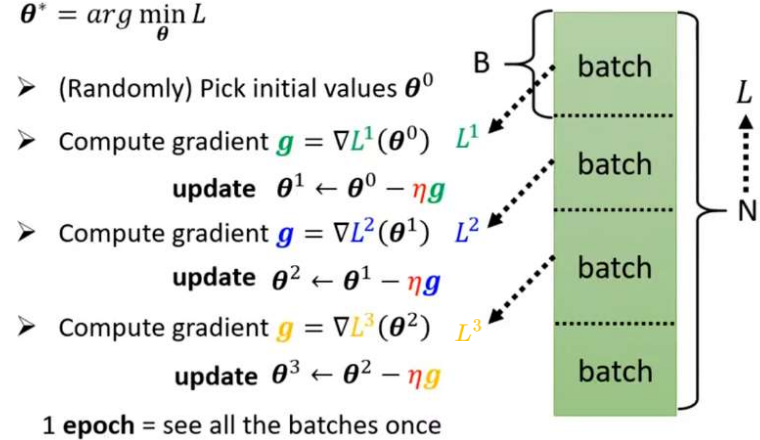
⭐实际上进行Gradient Descent时并不是直接使用这种 “全数据集算梯度→一次性更新参数”的批量梯度下降(Batch Gradient Descent,BGD),而是使用随机梯度下降(Stochastic Gradient Descent,SGD)和小批量SGD(Mini-batch SGD)。
不管是 BGD 还是 SGD,核心目的都是最小化损失函数(比如预测房价的误差、分类图片的错误率),通过沿着损失函数的负梯度方向更新模型参数,逐步让模型的预测结果越来越准。两者的唯一区别是用多少样本计算梯度
。
批量梯度下降(BGD)每次更新参数时,用全部训练样本计算损失函数的梯度,即
(
为总样本数,
是单个样本的损失)
随机梯度下降(SGD)每次更新参数时,随机抽取 1 个训练样本计算梯度,用单个样本的梯度代替全量样本的平均梯度,即
(
是随机选的单个样本)
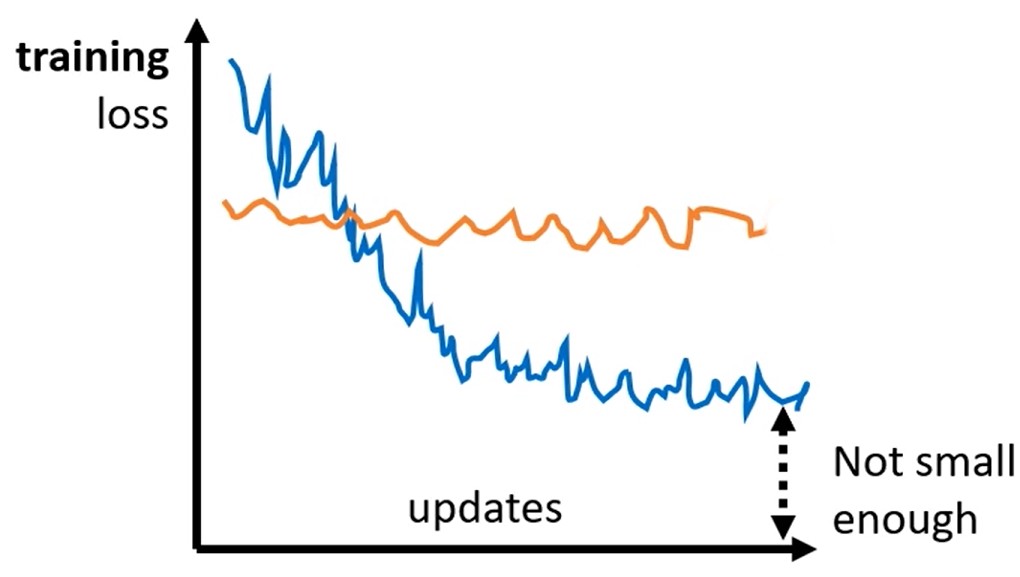
小批量随机梯度下降(Mini-Batch SGD)工程中最常用的折中方案(也常被直接称作 SGD),每次随机抽取 一小批样本(如 32/64/128 个)计算梯度。如下图所示,将N个数据随机分成一组一组的batch,每个batch里有B个数据。每一组batch计算梯度并进行更新(Update)。所有batch均梯度下降更新一轮称为一个epoch。
BGD梯度准确,更新一步就离真实值很近,但需要计算所有样本的梯度,样本多了极慢。使用SGD代替BGD可以大幅降低计算量,提升训练速度,适配大数据集;除此之外,它还可以引入梯度噪声,帮助跳出鞍点 / 平坦区 / 局部最优。
使用New Model得到的最小误差如下:
| Linear | 10Sigmoid | 100Sigmoid | 1000Sigmoid | |
| 数据集 | 0.32K | 0.32K | 0.28K | 0.27K |
| 测试集 | 0.46K | 0.45K | 0.43K | 0.43K |
可以看到叠加再多的Sigmoid效果也不会显著,甚至不变化。于是继续改进模型:将Sigmoid嵌套做几次,如下图所示。要做几次是一个hyperparameters。
改进Model得到的最小误差如下:
| 1layer | 2layer | 3layer | 4layer | |
| 数据集 | 0.28K | 0.18K | 0.14K | 0.10K |
| 测试集 | 0.43K | 0.39K | 0.38K | 0.44K |
上述Sigmoid嵌套的过程称为Neural Network(神经网络),Neural Network的Layer(层数)就是Sigmoid运算了几次。每一步Sigmoid称为一个Neuron(神经元)。输入经过多层神经元计算得到输出,这整个过程称为深度学习(Deep Learning)。深度学习发展过程中,神经网络层越叠越多,错误率也从16.4%减少到6.7%。但并不是层数越多越好,上述数据在Layer达到4层时,在数据集误差进一步减小,但在测试集误差却增加了,这称为过拟合(Overfitting)。
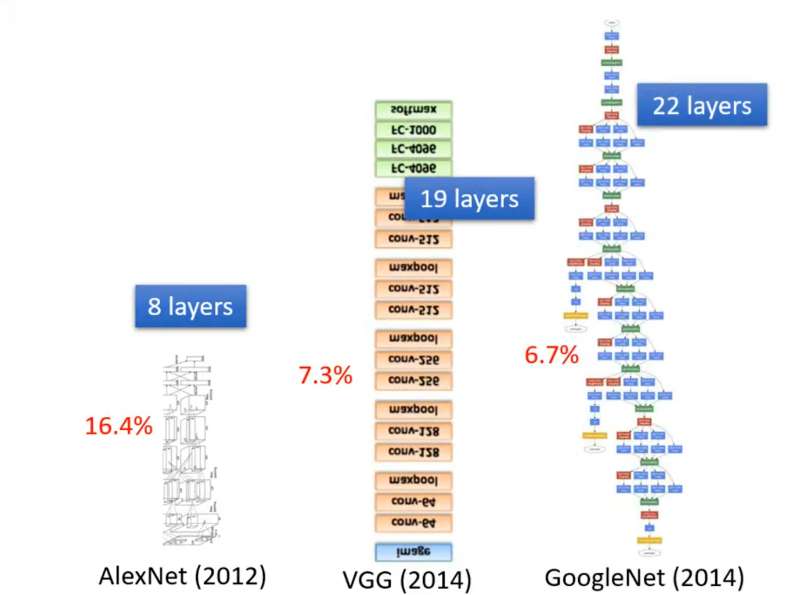
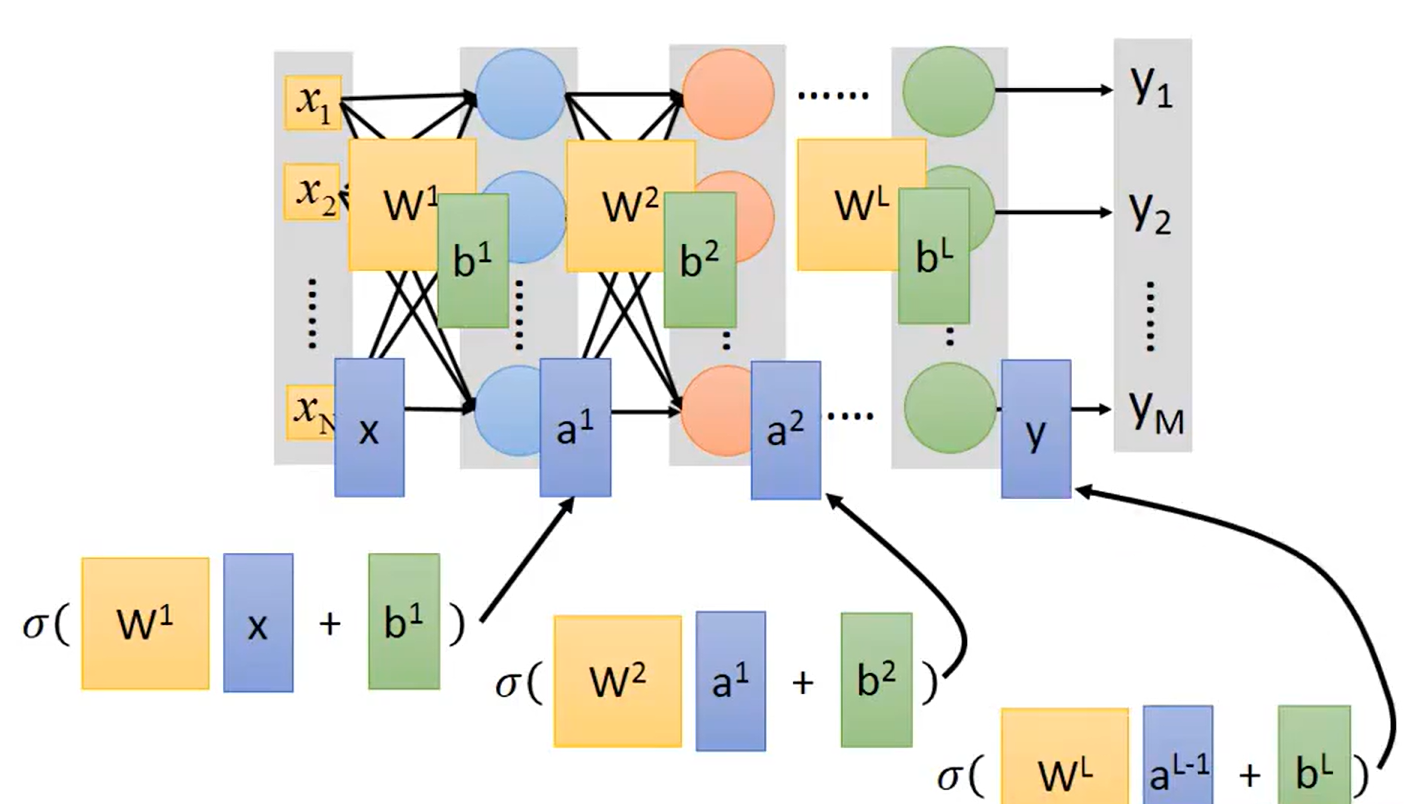
上述的所使用的神经网络结构称为全连接层(Fully Connect Network,也成为线性层),其一般结构如下所示:
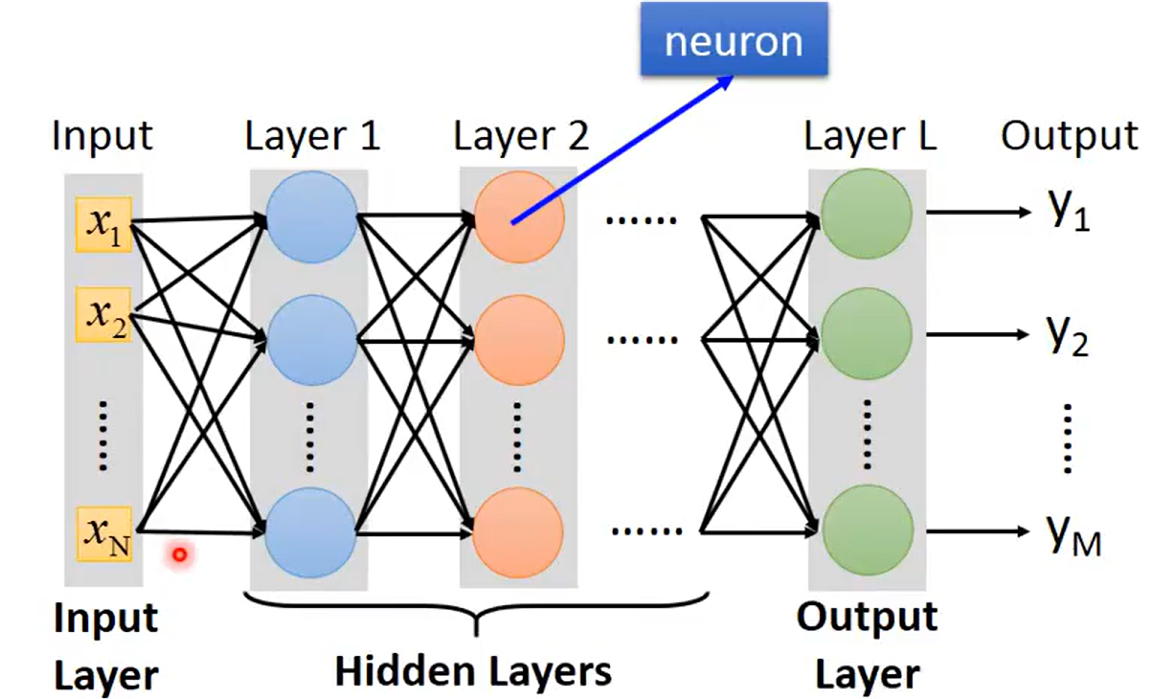
Neural Network的核心运算是矩阵运算(Matrix Operation),输入是一个
维矩阵,输出
是一个
维矩阵,第一层至第L层神经网络的参数
均为一个多维矩阵。每一个Neuron对线性值进行Sigmoid后得到
。
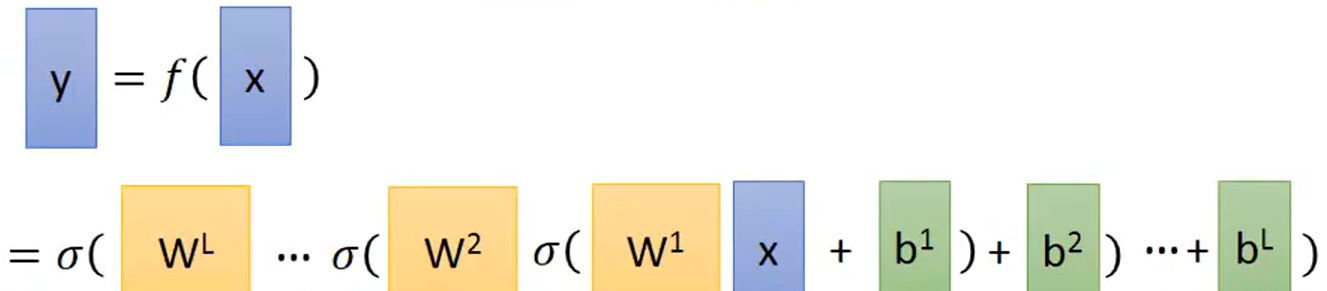
正则化(Regularization)
之前介绍的模型如果很复杂那么很容易出现过拟合(Overfitting)现象,这是因为模型学到了训练数据中的噪声和无关模式。正则化的目的就是在保持模型拟合能力的同时,约束模型参数的复杂度,避免参数过度自由而 “死记硬背” 训练数据。
正则化的实现方式就是在原始损失函数(如均方误差、交叉熵)的基础上,额外增加一个 “惩罚项”(正则项),形成新的损失函数:
![]()
λ:正则化强度超参数,控制惩罚力度(λ 越大,惩罚越强,模型越简单)
在之前所用的模型中(如下所示),其损失函数只考虑了预测结果与正确值之间的误差关系。
我们可以在原本的损失函数加上一个正则项,即:
如果正则项为称为L2正则化;如果正则项为
称为L1正则化
上式为线性回归 + L2 正则化(岭回归 Ridge Regression)的典型形式
在原始损失函数的基础上,又将模型中所有参数的平方加在一起。我们对参数更新优化的目的是使损失函数
尽可能得小,如果加上
项就意味着参数越小越好,之所以要使参数更小是为了使模型的变化更加平滑,也就是对输入的变化不敏感,从而避免噪声的干扰。
加了正则化之后的模型训练结果如下:
反向传播(Backpropagation, BP)
反向传播(Backpropagation, BP)用于多层神经网络计算参数梯度,它是在神经网络正向传播得到预测值与损失后,依托链式求导法则从输出层向输入层反向逐层计算损失函数对所有权重、偏置的梯度,为梯度下降更新参数提供梯度数据的算法。是神经网络训练的"梯度计算器",和梯度下降配合完成模型参数优化。
“正向传播算损失 → 反向传播算梯度 → 梯度下降更新参数”三步构成神经网络完整训练流程。
反向传播数学根基是链式求导法则(Chain Rule):
若函数嵌套为,则复合函数导数为:
若函数嵌套为,则复合函数的导数为:
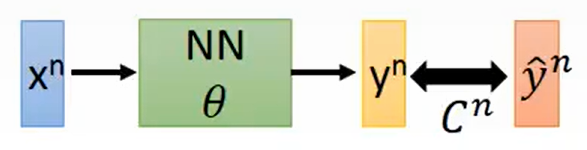
而神经网络是多层函数嵌套,BP 就是把这个法则从输出层反向递推到每一层参数,拆解复杂梯度为多层简单梯度的乘积。如下神经网络,假设此神经网络的参数为,输入input为
,输出output为
,
与真实值
之间的差值函数为
。则此神经网络的损失函数为:
接下来就不需要再计算,而是计算每一个样本数据的
就可以了。
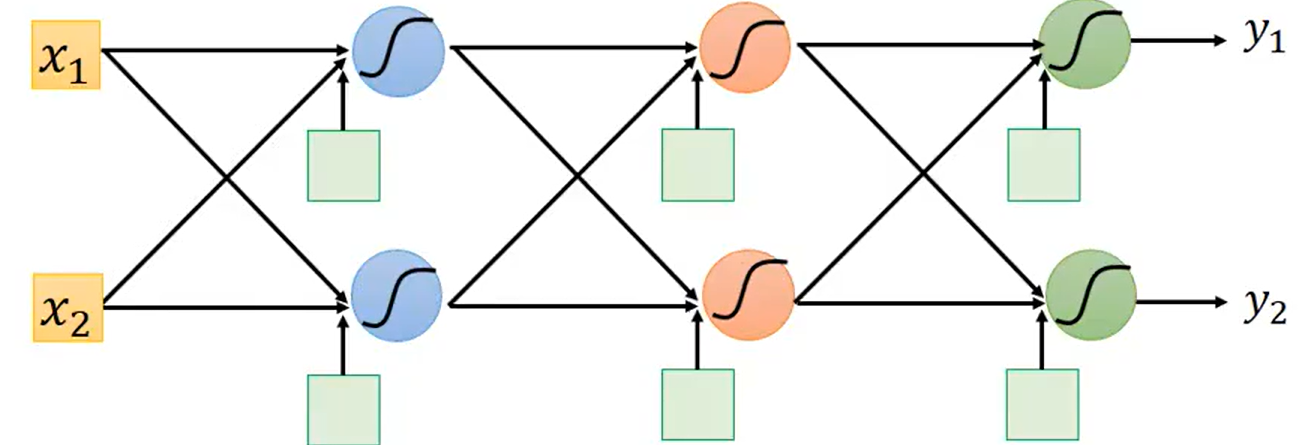
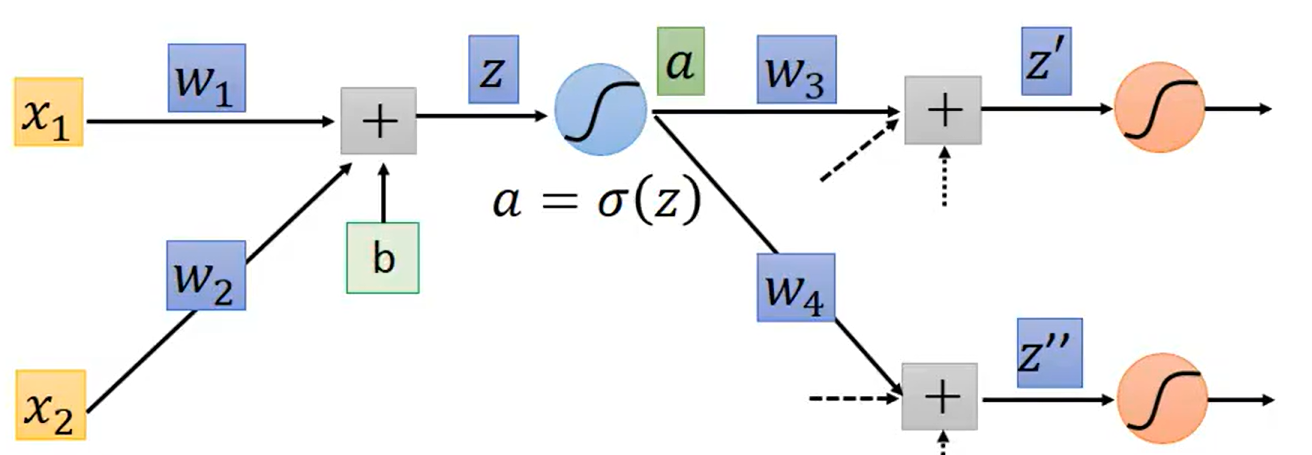
计算具体方法如下:
我们可以先考虑一个Neuron
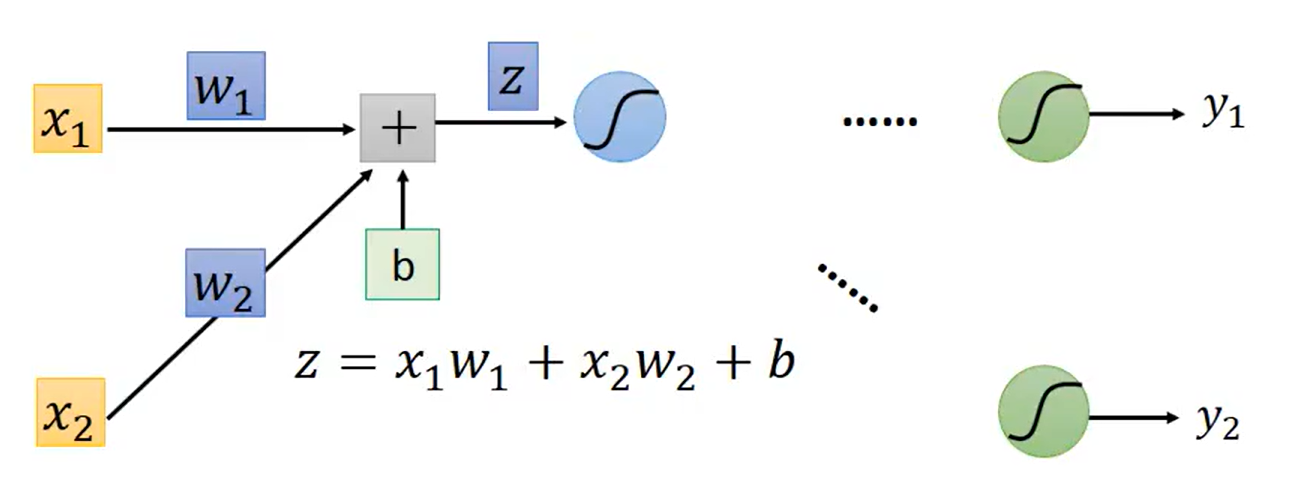
此Neuron是输入经过权重
,然后再加上偏置
得到的,值为
,之后
经过Sigmoid然后再经过后续一系列神经网络层得到最终的输出。我们的目的是计算
(以计算权重
为例,
的计算同理)。由Chain Rule可以知道
,对于
的计算很简单,根据公式
可知
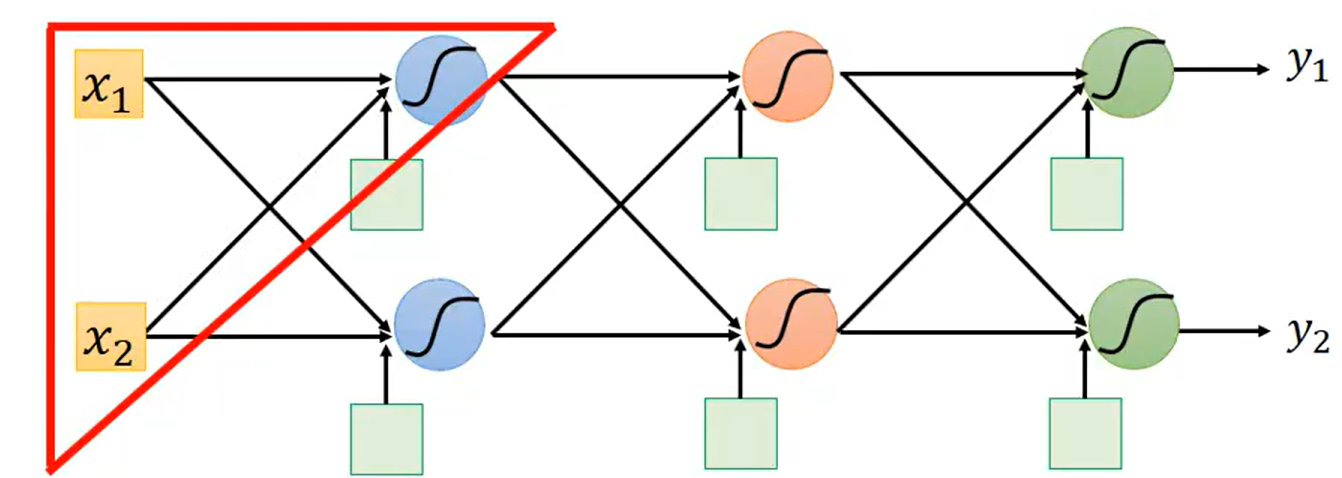
,这称为Forward pass;而
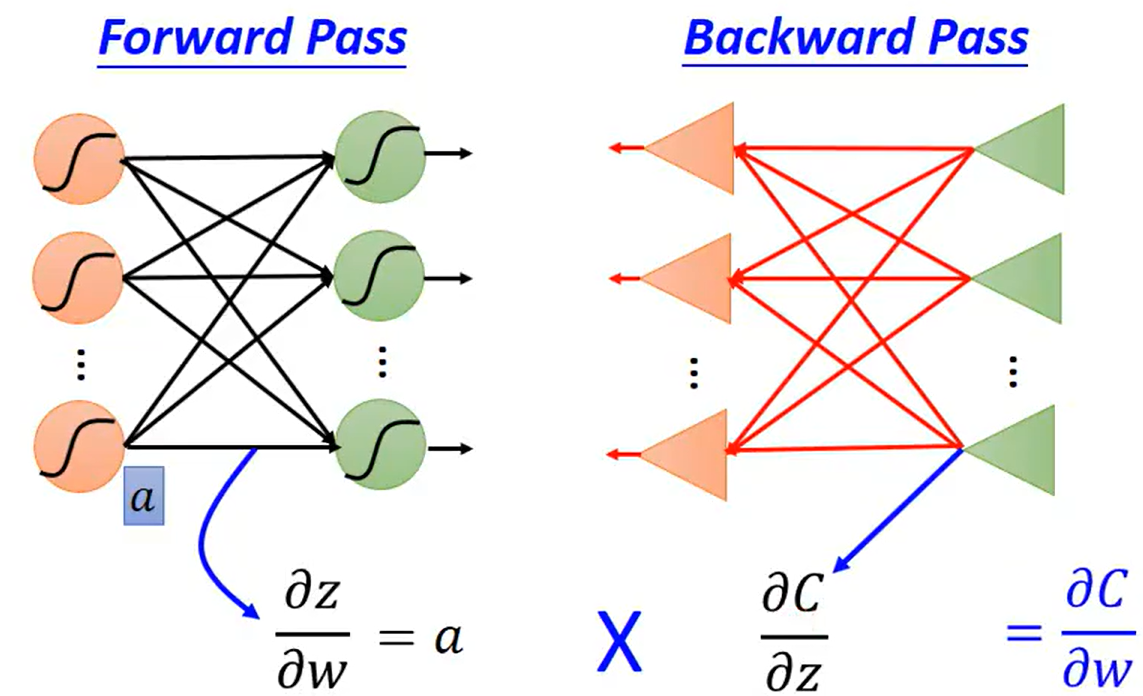
计算起来比较麻烦,要通过反向的方式计算,称为Backward pass。反向传播Backpropagation的核心两步就是Forward pass与Backward pass。
Backpropagation---Forward pass:
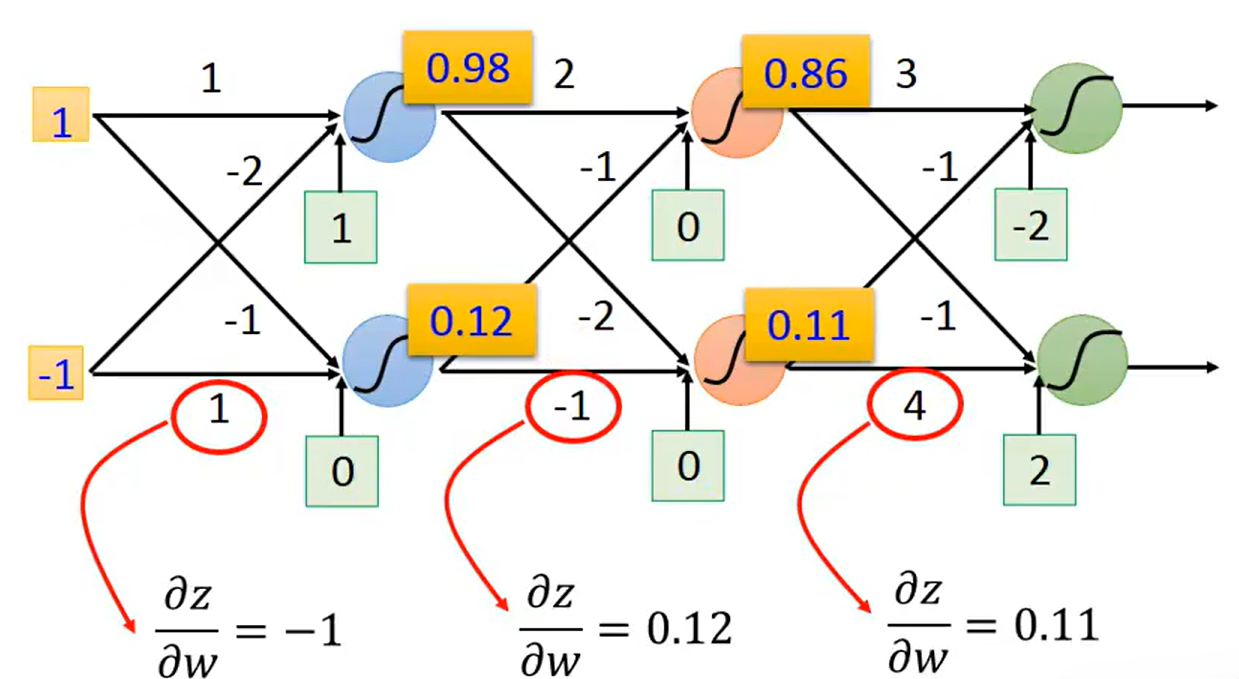
Backpropagation---Backward pass:,
可以计算。根据链式法则
,其中
。
由此可以得到
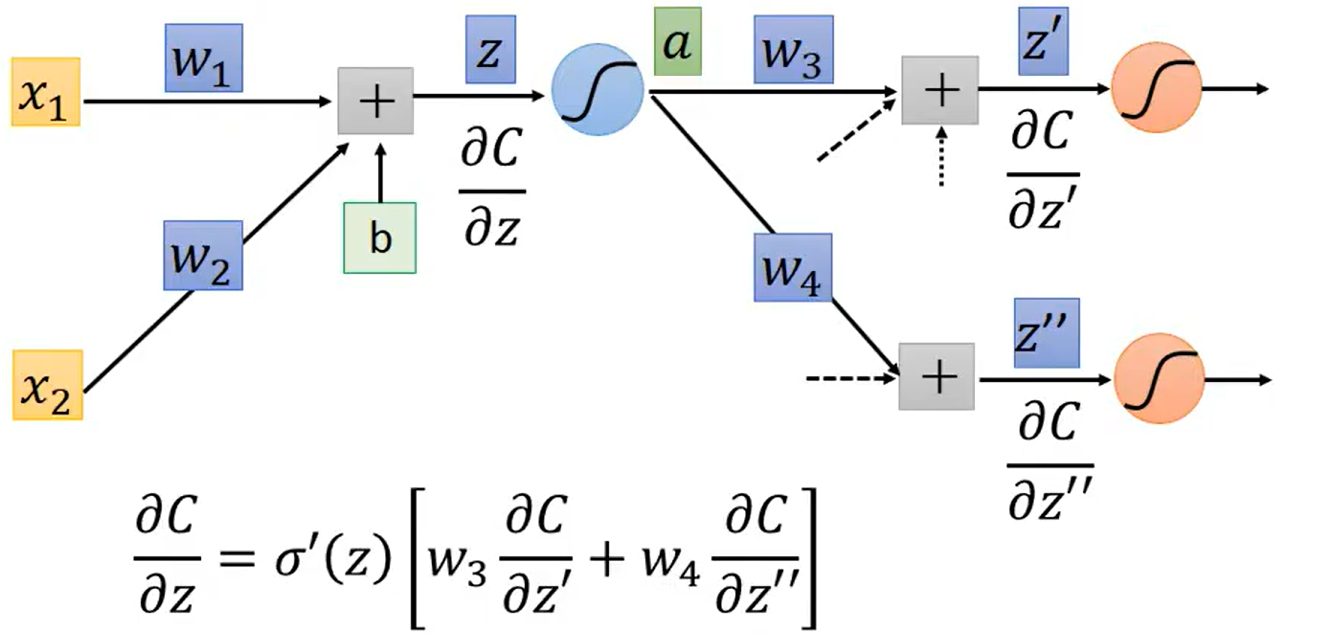
可以从反向角度看上述式子
:神经网络的输入为
和
,经过权重
后再乘上
(常数)得到输出
。这是反向传播的基本思路。
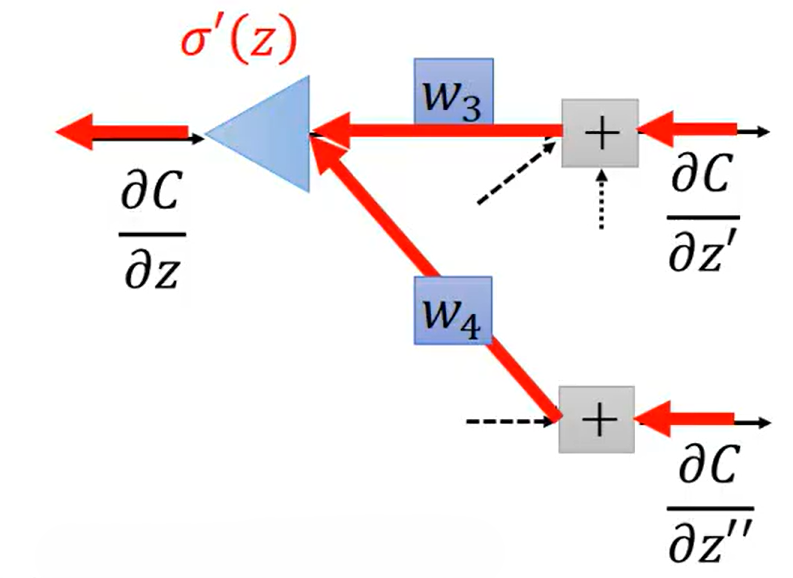
要求解,就要知道
和
,如果此神经网络过只有两层,即
之后直接跟输出
,那么
,求解也就结束了。
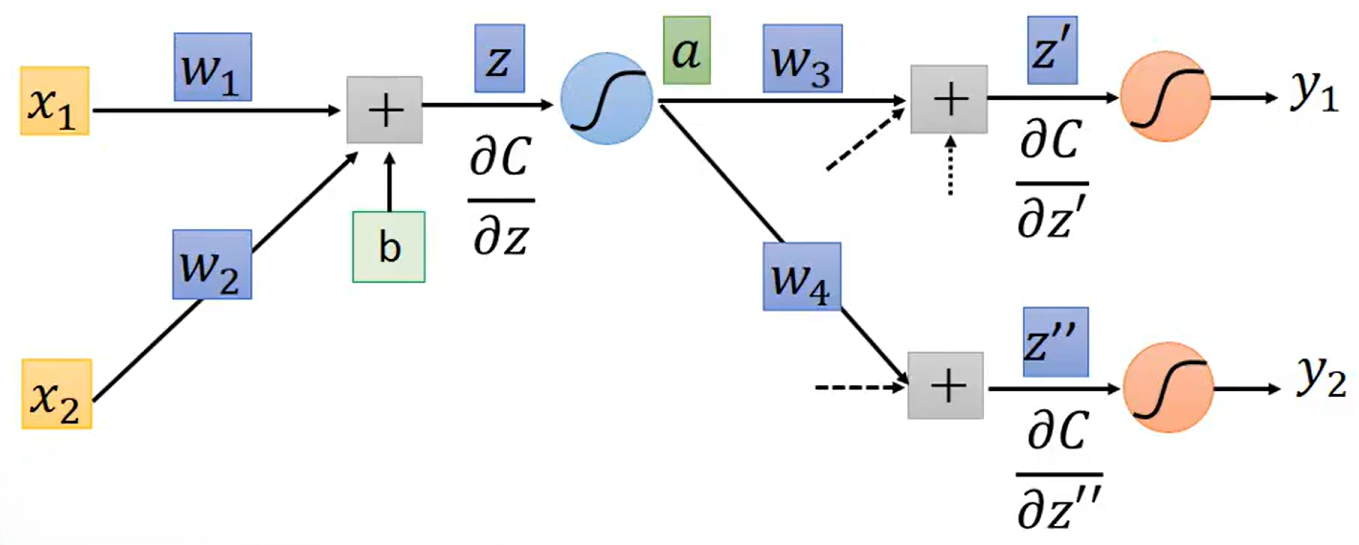
如果此神经网络不止两层,那么要求解和
又回到了一开始的
,
,也就是要知道
和
。
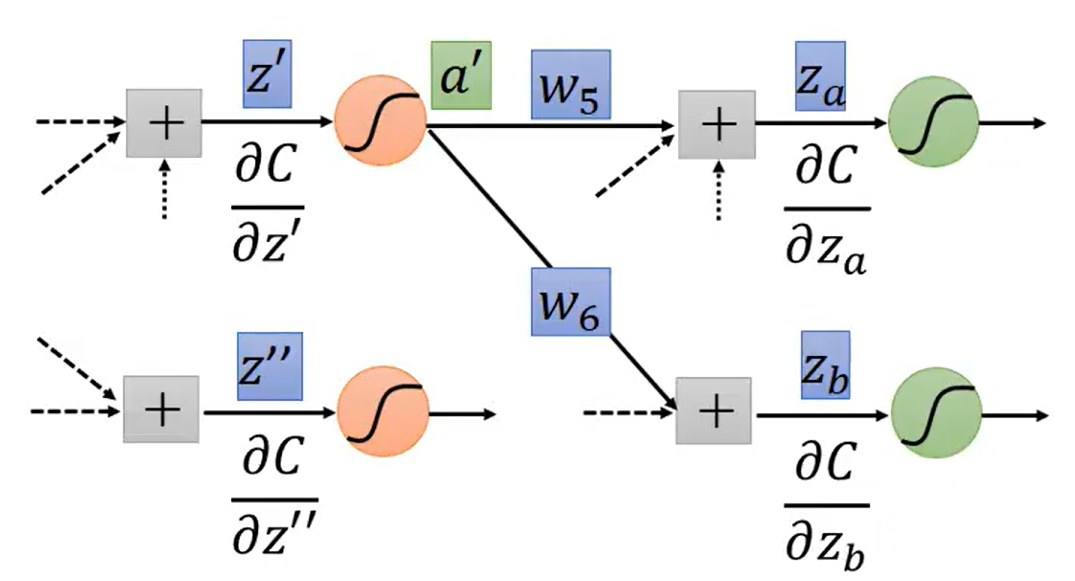
根据之前的公式可知,只有知道后一个网络层Neuron的
才能通过反向计算的方式得到此网络层的
,即下面所示的
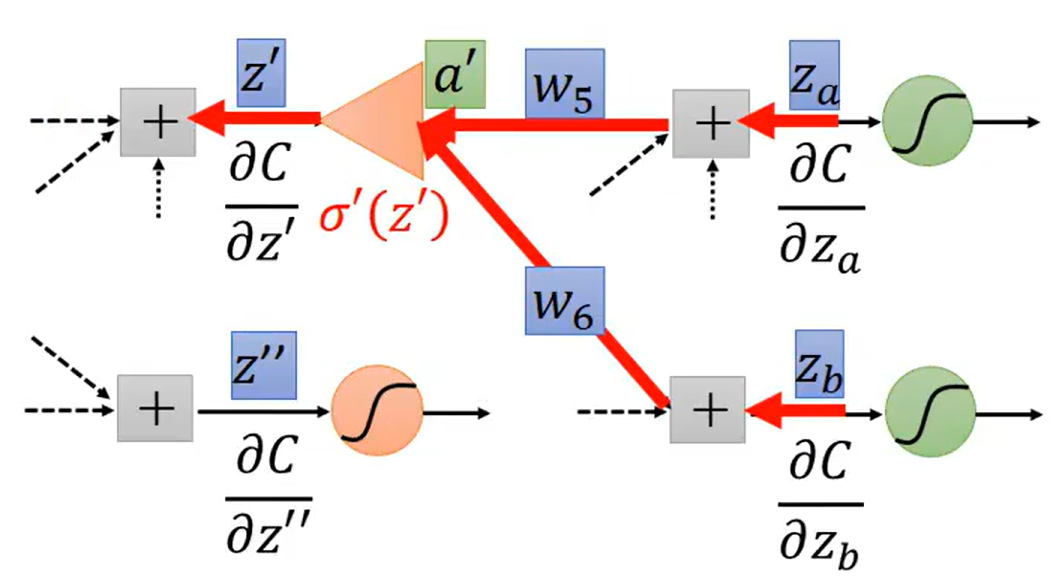
所以反向传播的Backward pass就是反向算的过程,即先算
和
,再利用这两项去计算
和
,依次类推。
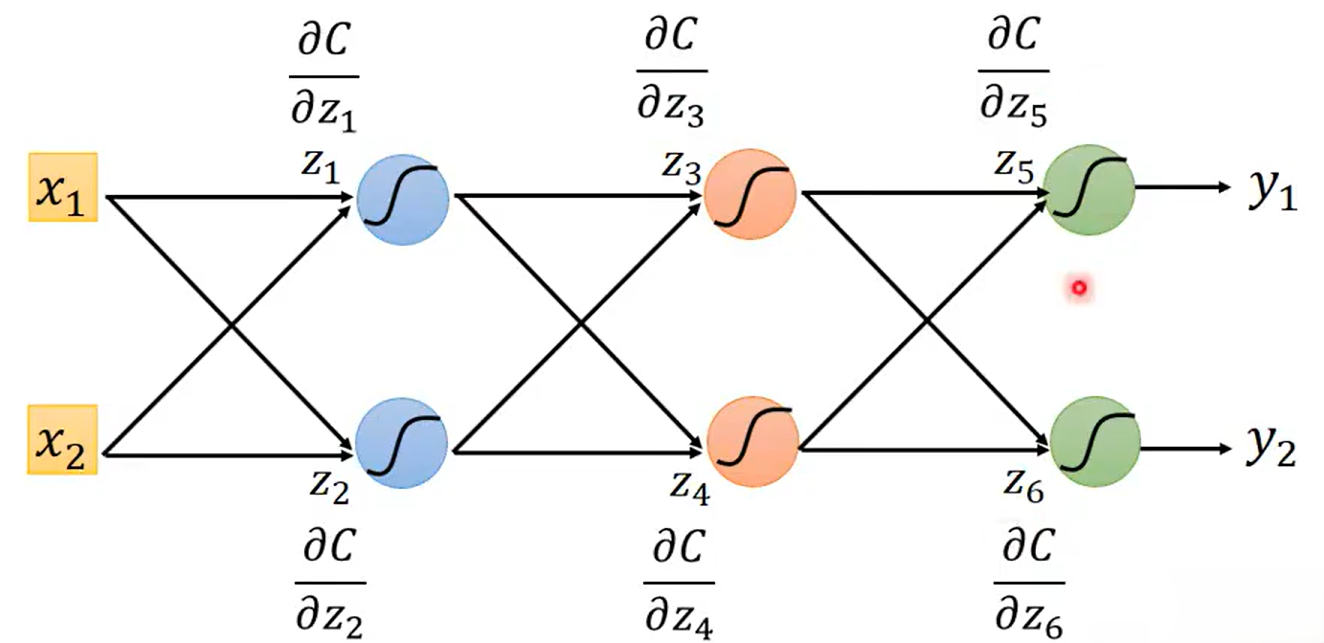
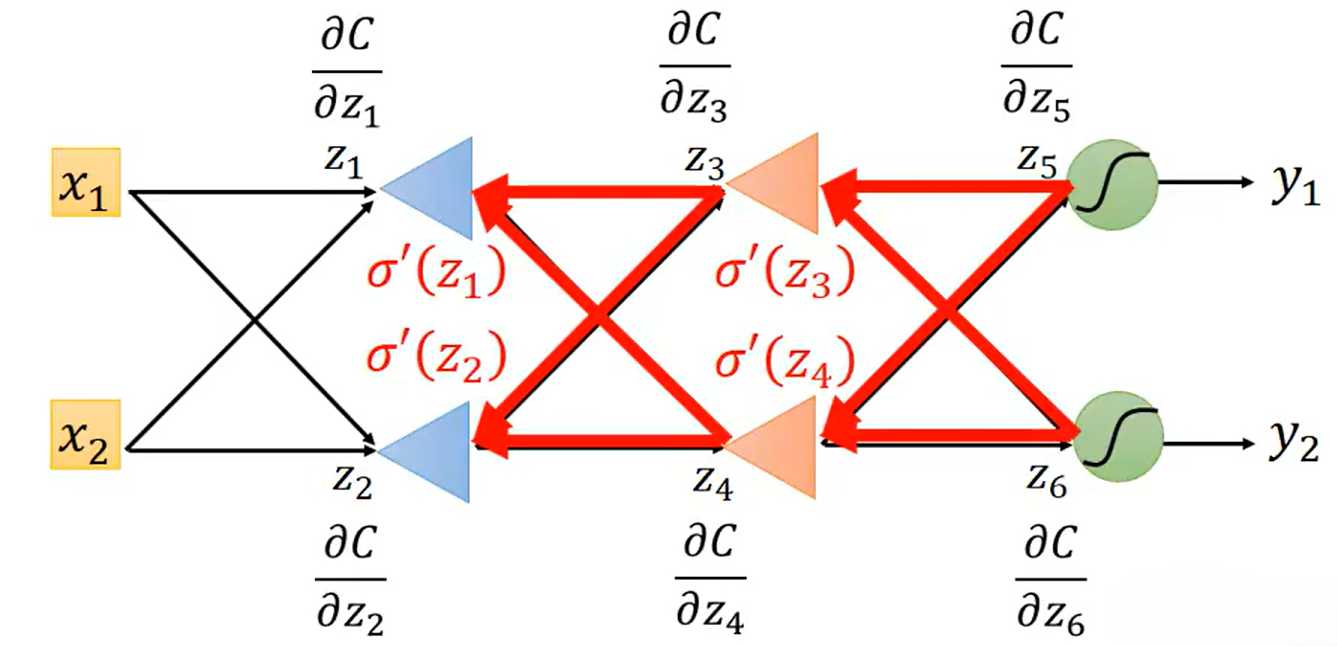
总结而言,Backpropagation的Forward Pass过程计算,Backward Pass过程计算
,最后相乘就可以得到损失函数对某个参数的偏微分
。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)