大模型部署指南:参数量选择与本地工具全解析
本文详细探讨了不同参数量大模型(1.5B至32B+)的性能差异、成本效益及硬件需求,指出32B是当前性价比拐点。同时,全面对比了Ollama、LMStudio等本地部署工具的特点和适用场景,并介绍了Page Assist、CherryStudio等相关工具。文章强调,领域适配和创新架构可降低大模型部署门槛,为开发者提供了实用的大模型部署参考。
本文详细探讨了不同参数量大模型(1.5B至32B+)的性能差异、成本效益及硬件需求,指出32B是当前性价比拐点。同时,全面对比了Ollama、LMStudio等本地部署工具的特点和适用场景,并介绍了Page Assist、CherryStudio等相关工具。文章强调,领域适配和创新架构可降低大模型部署门槛,为开发者提供了实用的大模型部署参考。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
应该部署多少参数量的模型
**32B 以下的模型不具备生产应用价值,不值得用于训练。**模型的回答要么像个傻子(1.5B),要么像个有点智慧的傻子(7B),要么就是看上去是对的,但反复核查后实际还是有些问题(14B)。
以下从技术角度展开说明:
规模与能力的非线性关系
- 1.5B模型:确实只能完成简单模式匹配,在复杂任务中表现接近随机(如Rouge-L低于15%)
- 7B模型(如Llama2-7B):在MMLU基准上达到约35%准确率,可处理简单推理但缺乏一致性
- 13B-14B模型(如Pythia-12B):在LAMBADA文本续写任务中达到约65%准确率,开始显现涌现能力
- 32B+模型:在GSM8K数学推理上出现质的飞跃(7B约15% vs 32B约45%)
生产应用的临界点
- 基础NLP任务(分类/实体识别):6B左右模型经领域适配后可达商用级(F1>0.9)
- 复杂推理任务:至少需要30B参数才能达到人类专家80%水平
- 长文本生成:32B模型在连贯性(Coherence Score)上比7B提升约40%
成本效益分析(以A100为例)
# 训练成本估算公式
def training_cost(params_B, tokens_T):
return 6e-3 * params_B * tokens_T # 美元计算
# 7B模型训练1T tokens约需42万美元
# 32B模型相同数据量需约200万美元
硬件限制
- 7B模型推理仅需24GB VRAM(INT8量化后)
- 32B模型需要4*A100(80GB)进行全精度推理
- 吞吐量对比:7B模型可达32B的5-8倍QPS
新兴技术的影响
- 模型压缩(如LLM.int8()):可使13B模型在单卡运行
- 混合专家(MoE):如Switch Transformer在1.6T参数下仅激活28B参数/样本
- 指令调优:FLAN-T5通过提示工程使11B模型超越原生30B模型
领域特异性案例
- 医学QA任务:BioMedLM-2.7B在专业测试中超越通用7B模型
- 代码生成:StarCoder-15B在HumanEval上超过通用30B模型
结论
- 对于通用场景,32B确实是当前性价比拐点
- 垂直领域通过知识蒸馏/领域适配可使小模型(<10B)达到生产要求
- 模型架构创新(如RetNet、MoE)正在改变规模效益曲线
- 推理优化技术使中等规模模型(13B-20B)逐渐具备实用价值
未来2-3年,随着3nm制程普及和稀疏化技术进步,7B-13B模型可能在边缘计算场景实现突破,但核心AI服务仍将依赖30B+基础模型。
本地部署有哪些工具
Ollama(推荐)
Ollama 提供了一套用于下载、运行和管理 LLMs 的工具和服务,简化了复杂模型的部署流程。

Ollama 的核心特点
本地化****部署
- 所有推理均在本地完成,确保数据隐私和安全,适用于敏感数据处理场景。
- 支持离线运行,降低延迟并提高可控性。
多模型支持
- 支持主流开源 LLM,如 Llama 3、DeepSeek、Mistral、Qwen、Gemma 等。
- 用户可通过
ollama pull命令快速下载模型,并通过ollama run运行。
简化管理与API集成
- 提供类似 Docker 的命令行工具(
ollama list、ollama rm等)管理模型。 - 兼容 OpenAI API 标准,便于开发者集成到现有应用。
跨平台支持
- 支持 Windows、macOS、Linux 及 Docker 部署。
- 优化 GPU 加速(CUDA/Metal),提高推理效率。
实时流式工具调用(v0.8.0+)
- 最新版本支持“边生成边调用工具”,提升交互体验,适用于智能助手、自动化流程等场景。
Ollama支持的模型
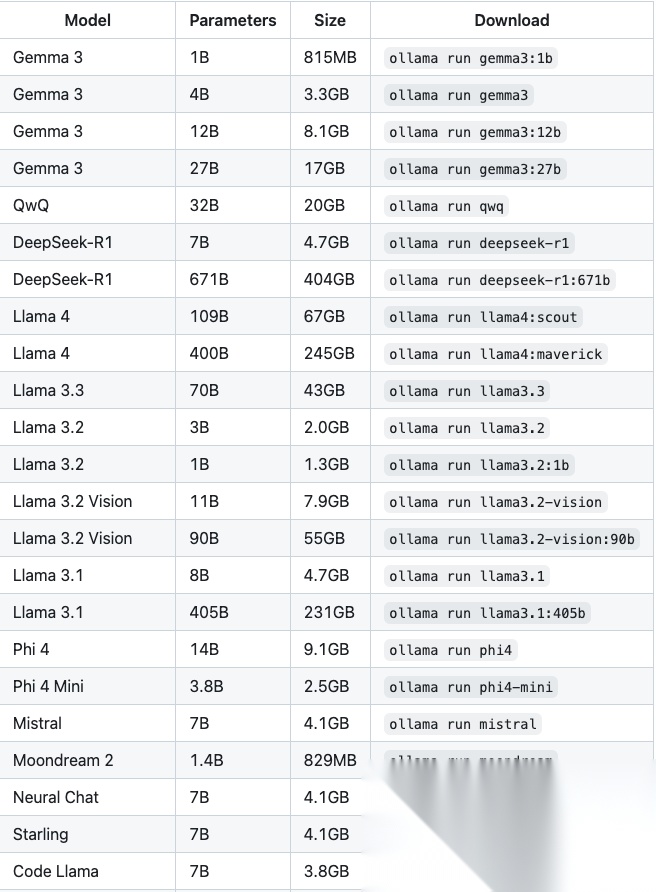
Ollama 持续更新模型库,支持 GGUF 量化 和 自定义导入,用户可根据硬件条件选择合适的模型。
Ollama 与其他 LLM 平台的区别
| 特性 | Ollama | 云端 LLM(如 ChatGPT) |
| 数据隐私 | ✅ 本地运行 | ❌ 依赖云端 |
| 模型选择 | ✅ 多模型支持 | ❌ 通常固定模型 |
| 成本 | ✅ 无持续计费 | ❌ 按使用量收费 |
| 延迟 | ✅ 低(本地) | ❌ 依赖网络 |
Ollama 是当前最受欢迎的本地 LLM 运行框架之一,尤其适合需要数据安全、低延迟和自定义模型的场景。其易用性和强大的 API 支持使其成为开发者构建私有 AI 应用的首选工具。
LMStudio(仅支持 M 系列芯片)
如果是 M 芯片,强烈推荐 LMStudio。因为它支持专门为M系列芯片优化过的模型文件,运行速度快了不止一点点(M2 上提升幅度不大,M4 Max 上提升较大)。
相比之下,Ollama 虽然也能在 M 芯片上运行,但默认使用 GGUF 量化模型,性能不如 LM Studio 的 MLX 优化版本。
LM Studio 是一个 本地化****大语言模型(LLM)运行平台,主打 易用性 和 苹果 M 芯片优化,适合非技术用户和开发者快速体验本地 AI 模型。
主要特点
- M 芯片优化:支持 MLX 框架,在 M 系列芯片上运行更快(M4 Max 上提升显著)。
- 图形化界面(GUI):无需命令行,一键下载、运行模型,适合新手。
- 多模型并行:支持 草稿模型(Speculative Decoding),可搭配小模型加速推理。
- OpenAIAPI兼容:可本地部署类似 ChatGPT 的 API 服务。
- 模型格式支持:主要支持 GGUF/MLX 量化模型,适合 CPU/GPU 混合计算。
适用场景
- 个人用户:想快速体验本地 LLM,无需复杂配置。
- M 芯片 Mac 用户:希望最大化硬件性能。
- 轻量级AI应用:如写作辅助、代码生成等。
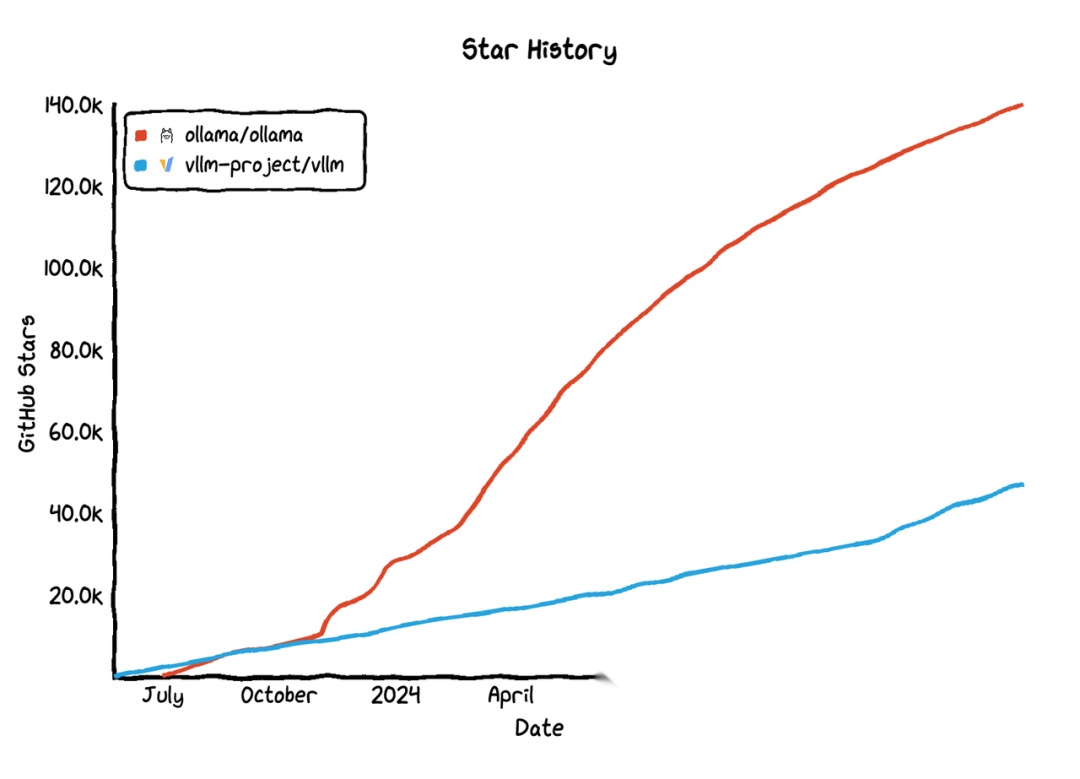
关注度
与上一代的模型管理(MLOps)明星项目相比,LLMOps 的关注度高了一个量级。
- 关注度差异的核心原因
- 模型规模与计算需求
- MLOps:管理传统 ML 模型(如分类、回归),通常在单 GPU 或 CPU 上可运行,推理成本较低。
- LLMOps:GPT-4、Llama 3 等模型参数量达千亿级,训练和推理需 大规模GPU/TPU 集群,成本高一个数量级。
- 应用场景的扩展性
- MLOps:主要用于 结构化数据预测(如推荐系统、风控模型),应用较垂直。
- LLMOps:覆盖 文本生成、代码补全、多模态交互,适用场景更广(如客服、医疗诊断、法律分析),企业需求激增。
- 技术栈的复杂度
- MLOps:依赖 Kubeflow(训练编排)、TF Serving(模型部署),流程相对标准化。
- LLMOps:需处理 提示工程(Prompt Engineering)、RAG(检索增强生成)、多模型协作,工具链更复杂(如 LangChain、LlamaIndex)
- LLMOps 相比 MLOps 的新挑战
| 维度 | MLOps(Kubeflow/TF Serving) | LLMOps |
| 模型训练 | 从零训练,超参数调优为主 | 以 微调预训练模型 为主,节省计算成本 |
| 数据管理 | 强调特征工程、数据清洗 | 更依赖 提示数据(Prompts)和 外部知识库(向量数据库) |
| 部署优化 | 低延迟 API(如 gRPC) | 需优化 Token 消耗、分布式推理、流式响应 |
| 监控重点 | 模型漂移、准确率下降 | 幻觉(Hallucination)、有害内容过滤、合规性 |
| 工具生态 | 成熟(MLflow、Kubeflow) | 新兴但快速迭代(Dify、Helicone、LLMOps 专用平台) |
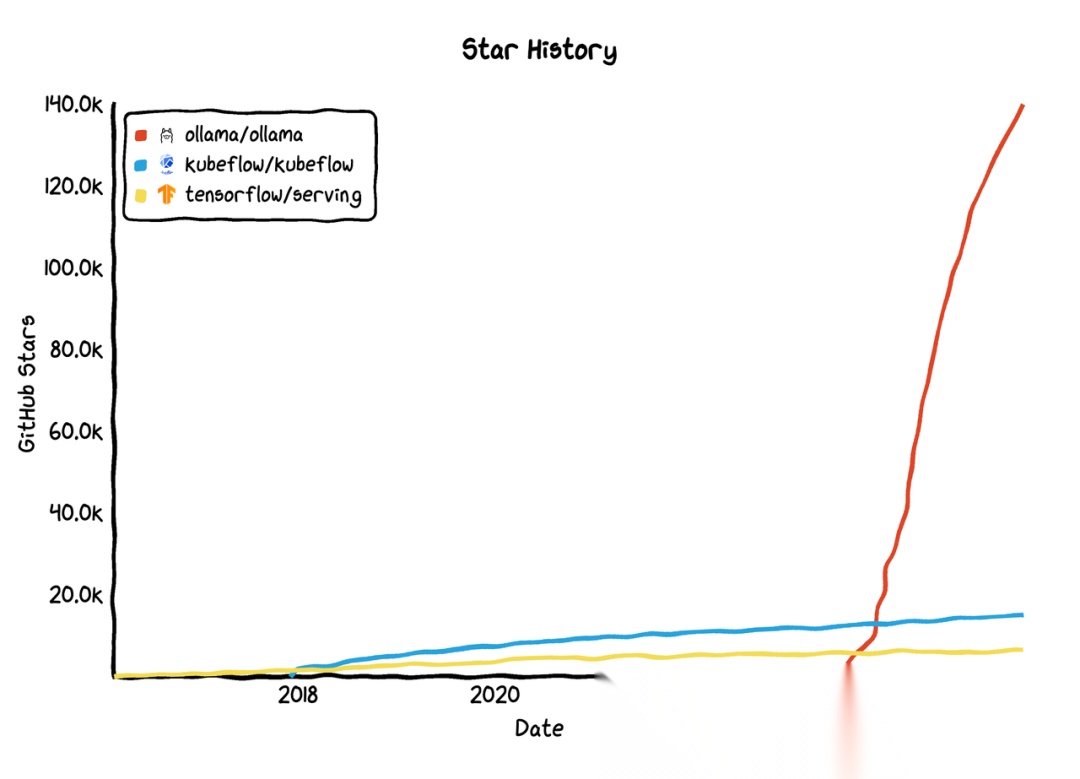
- 为什么 Kubeflow/Serving 不足以应对 LLMOps?
- 不支持大模型特有技术
- Kubeflow 擅长 传统 ML 流水线,但缺乏对 提示工程、RAG、多模型热切换 的原生支持。
- TF Serving 优化了 低维张量计算,但 LLM 需要 高并发 Token 生成优化(如 vLLM、TGI)。
- 企业级需求的变化
- LLM 应用需 知识库集成、角色权限管理、合规审计(如医疗、金融场景),传统 MLOps 工具未涵盖。
- 例如,星环科技的 LLMOps 平台强调 语料治理、多租户隔离,远超 Kubeflow 的数据管理能力。
LM Studio vs. Ollama 对比
| 对比维度 | LM Studio | Ollama |
| M 芯片优化 | ✅ 支持 MLX,速度更快 | ❌ 默认 GGUF,无 MLX 优化 |
| 易用性 | ✅ 图形界面,适合新手 | ❌ 命令行为主,需技术背景 |
| 模型格式 | GGUF/MLX | GGUF/PyTorch/Safetensors |
| API 兼容性 | OpenAI 风格 | REST API + 更多社区方案 |
| 企业级部署 | ❌ 较弱 | ✅ 支持 Docker/K8s |
| 适用人群 | 个人/轻量用户 | 开发者/企业用户 |
结论
- M 芯片用户(尤其是 M4 Max):强烈推荐 LM Studio,MLX 优化带来显著速度提升。
- 开发者/企业用户:Ollama 更灵活,支持更多模型格式和部署方式。
- 非 M 芯片设备:两者均可,但 Ollama 的跨平台支持更好。
如果你的主要需求是 快速体验本地 LLM 并最大化 M 芯片性能,LM Studio 是更好的选择;如果需要 深度定制或企业级集成,Ollama 更合适。
其他相关工具推荐
| 名称 | 地址 | 备注 |
| Page Assist | https://github.com/n4ze3m/page-assist | 浏览器插件 |
| CherryStudio | https://github.com/CherryHQ/cherry-studio | |
| Chatbox | https://github.com/Bin-Huang/chatbox | 有手机版 |
| ChatWise | https://github.com/egoist/chatwise-releases | |
| LobeChat | https://github.com/lobehub/lobe-chat | 服务端 |
- Page Assist
- 定位:浏览器插件,提供本地大模型(如 DeepSeek、Llama)的 Web UI 交互界面。
- 核心功能:
- 通过 Ollama 连接本地模型(如 DeepSeek),支持聊天、联网搜索、RAG(检索增强生成)。
- 支持文本转语音(TTS)、历史记录管理、模型参数调整(温度、上下文长度等)。
- 结合 cpolar 内网穿透,实现远程访问本地模型。
- 适用场景:个人用户快速在浏览器中体验本地 AI,无需复杂部署。
- Cherry Studio
- 定位:国产开源 AI 知识库管理工具,支持本地部署和多模型聚合。
- 核心功能:
- 支持 PDF/DOCX/网页等文件导入,结合 nomic-embed-text 实现语义检索。
- 集成 OpenAI、Gemini 等云端模型,也可连接本地 Ollama 模型(如 DeepSeek)。
- 提供企业级数据加密(AES-256)、增量备份、多用户协作。
- 适用场景:企业/研究机构构建私有知识库,需数据安全和深度定制。
- Chatbox
- 定位:轻量级 AI 聊天客户端,支持多平台(Windows/macOS/Linux)。
- 核心功能:
- 通过 Ollama 或 OpenAI API 连接模型,界面类似聊天软件,操作简单。
- 支持实时联网搜索、代码生成、多模型切换(如 DeepSeek、Llama3)。
- 开源免费,适合新手快速体验本地 AI。
- 适用场景:个人用户或开发者调试模型、日常问答。
- ChatWise
多模型支持
- 兼容 闭源模型(如 OpenAI GPT-4、Claude、Gemini)和 开源模型(如 Llama3、DeepSeek、Mistral)。
- 支持 Ollama 本地模型(如 DeepSeek-R1、Qwen2.5),提供可视化界面管理。
多模态交互
- 支持文本、图片、PDF 输入,并可结合 视觉模型(如 MiniCPM-V)进行图像分析。
隐私与****本地化
- 数据默认本地存储(除需 API 的模型外),适合敏感场景。
易用性优化
- 自动生成对话标题(依赖 Qwen2.5 模型)。
- 参数调节(温度、截断长度等)和 OpenAI 兼容 API。
跨平台支持
- 提供 Windows/macOS 客户端,界面简洁,适合非技术用户。
与 Ollama、LM Studio 的对比
| 工具 | ChatWise | Ollama | LM Studio |
| 核心定位 | 多模型聚合+可视化交互 | 本地模型命令行管理 | M 芯片优化+图形化界面 |
| 模型支持 | 开源/闭源均支持 | 仅开源模型(需手动加载) | 侧重 GGUF/MLX 格式优化 |
| 隐私性 | ✅ 本地/API 混合 | ✅ 完全本地 | ✅ 本地(MLX 优化) |
| 易用性 | 图形界面,适合新手 | 命令行,需技术背景 | 图形界面,Mac 专属优化 |
| 适用场景 | 多模型切换+轻量开发 | 开发者/企业本地部署 | M 芯片 Mac 极致性能需求 |
- LobeChat
- 定位:开源现代化 ChatGPT/LLMs 应用框架,支持云端和本地模型。
- 核心功能:
- 多模态交互:支持 GPT-4 Vision 图片识别、TTS/STT 语音对话、文生图(DALL·E 3)。
- 插件系统:联网搜索、代码执行、助手市场(类似 GPTs)。
- 支持 Ollama 本地模型(如 Llama3)、Docker 一键部署。
- 适用场景:开发者构建定制化 AI 应用,或企业部署私有聊天平台。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 20
20 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)