Stardog-基于知识图谱的企业级人机协同Agent智能体
以大型语言模型(LLM)为核心的智能代理需要通过知识图谱和本体获取民主化且高质量的企业数据,才能像人类一样有效且可靠地工作。然而,人类具备不可替代的责任感,这点机器无法企及。
大模型智能体需要知识图谱和本体获取高质量企业数据,实现实时准确决策。本体提供结构化知识框架,防止幻觉并提升理解能力。神经符号AI结合LLM与本体,增强代理可靠性和推理能力。本体推理提高查询鲁棒性,应对数据变化。代理创建本体缩短开发时间,降低成本。人类责任感不可替代,AI应作为辅助而非替代。AI与数据质量形成良性循环,互相促进。

摘要
以大型语言模型(LLM)为核心的智能代理需要通过知识图谱和本体获取民主化且高质量的企业数据,才能像人类一样有效且可靠地工作。然而,人类具备不可替代的责任感,这点机器无法企及。
关键点概览 (Key Takeaways)
-
实时、准确、上下文一致的数据访问:智能代理的决策效率依赖于获取一致、可靠且实时的企业数据。
-
本体的重要性:本体为智能代理提供结构化的企业知识框架,避免产生幻觉(hallucinations),提升理解精准性。
-
神经符号 GenAI 结合:将 LLM 与本体相结合的神经符号 AI 能增强代理的可靠性,同时支持更复杂的推理能力。
-
更强的查询鲁棒性:通过本体推理(如类树和属性树扩展),代理能在应对模式变化和数据结构漂移时表现得更具韧性。
-
代理驱动的本体创建:相比传统方法,代理创建本体的过程显著缩短了开发时间并降低了成本。
-
人类责任不可替代:重点应放在代理辅助完成部分人类任务,而非取代人类,因人类的责任感无法被复制。
-
AI 和数据质量间的良性循环:AI 的使用与数据质量的提升相辅相成,二者互相促进。
正文
知识工作者需要民主化的数据访问,以便做出更好、更快的决策,从而提高生产力。从字面上看,没有人对此提出异议,甚至没有一点点。AI 和数据这一坚不可摧的定律是牢不可破的——没有好的数据,就会得到糟糕的 AI——对代理来说,不亚于对人的评价。
那么,我们来谈谈企业知识图谱如何满足基于 LLM 的代理的数据需求 —
- 使用实时运营数据做出实时决策,这需要具有实时数据集成的知识图谱平台
- 收集准确的数据,通过KG来防止或减少 LLM 幻觉
- 用企业特定的政策和知识(只有企业内部知道的)补充 LLM 的一般知识(原则上每个人都知道的)
- 通过集成的企业知识目录(作为知识图谱的目录)动态发现数据
这与 Stardog 相关,因为它将语义层、数据结构和知识目录的以代理为中心的优势结合在一个统一的知识图谱平台中。
企业需要可靠、及时、互联的数据
*代理不需要这些特定技术。但代理确实需要语义层、数据结构和目录提供的核心功能,*即实时访问一致、及时、准确和上下文化的数据(和元数据)。
企业数据态势的智能体视图
| 量规 | 源 | |
|---|---|---|
| 背景知识 | 每个人都可以或应该了解的关于世界的信息。 | 针对文本进行训练的 LLM |
| 领域知识 | 哪些不能更改,哪些只有企业知道,包括它如何开展业务;有时称为“分类数据”。 | 本体 |
| 交易数据 | 关于业务及其商业、法律和其他关系的专有事实。 | 数据库和其他数据孤岛 |
但可以肯定的是,您在想…当然,客服总有一天会在需要回答问题时只看仪表板。开玩笑?不是开玩笑!座席已经可以这样做,但他们没有。他们为什么不这样做的真相是痛苦的:仪表板并不能为客服提供答案,就像它们为人提供答案一样。
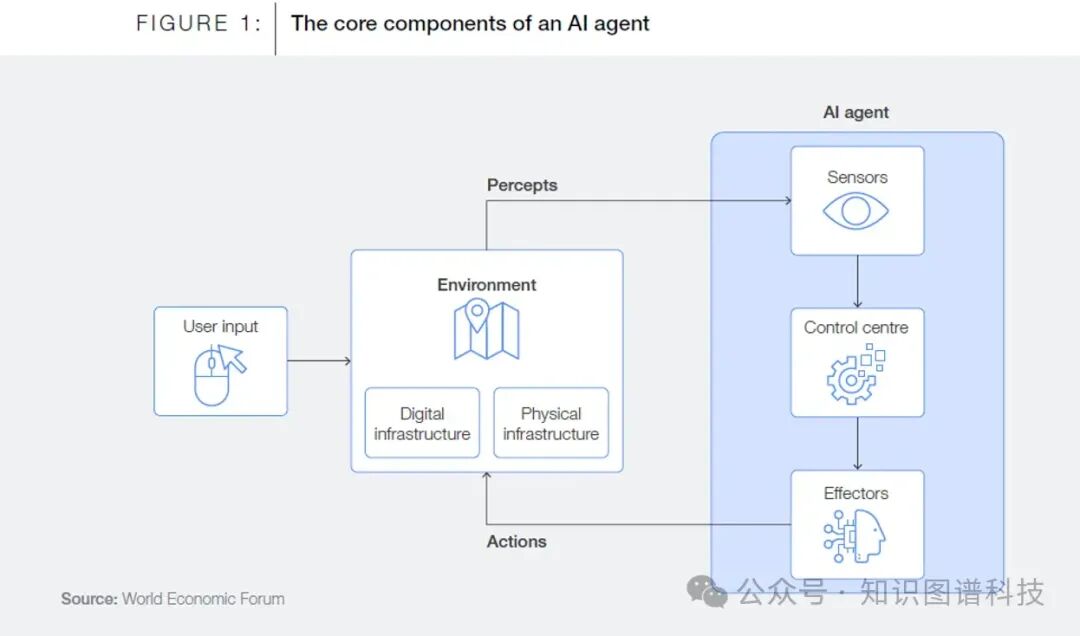
代理必须掌握不断变化的和静态业务规则
为了实现半自主数据访问,代理需要许多技术功能; 但我想专注于代理以它可以可靠地理解的格式访问正式的域不变量的需求。**简而言之,**代理需要本体。
本体正式描述了定义特定域的基本规则和模式。“正式的域不变量”是“业务中无法改变的事情”的一种奇特说法。这就是本体以机器可理解的形式描述的内容。
**LLM 之所以引人注目,是因为它们压缩了每个人都可以了解的关于世界的信息,在其权重和参数中存储了大量的背景知识。**因此,LLM 为代理提供了一种访问常识的编程方式,这一突破推动了 LLM 的大部分价值。
但是,尽管这很强大,但这还不够,因为两家银行或两家生命科学公司之间的区别几乎完全在于他们知道而其他人不知道的东西。如果代理人要成为忠实、真实和乐
于助人的合作伙伴来提高人类绩效,他们也需要获得这些知识。
揭开本体论的神秘面纱
LLM 驱动的代理确实擅长理解自然语言,但他们仍然会犯一些愚蠢的错误,使他们偏离轨道。数据是补救措施,而本体是刚才讨论的各种数据的最佳容器。在本体中,本体(至少)有两个关键目的:
- 将知识集中在一个地方,从而更轻松地访问、维护和管理更改;为代理提供一个可靠的框架,用于理解和处理不同情况下的数据;
- 减少不确定性,同时提高输出质量,特别是在防止幻觉方面。
这两个目的动态地协同工作:**通过拥有企业知识的单一事实来源,代理可以更自信、更精确地进行操作,而本体的正式结构提供了保持代理输出可靠、真实和相关性所需的护栏。**结果是更强大、更值得信赖的代理,可以更好地满足企业需求。这种方法在准确性和合规性是关键的受监管行业中特别有价值。
NeuroSymbolic AI 的数据模型
所以我们谈论的是结合统计和逻辑类型的 AI。这就是所谓的 NeuroSymbolic AI。正如所讨论的,这种 AI 对于 Agentic AI 的工作至关重要。代理需要一个数据模型,我们认为本体和知识图谱绝对至关重要。NeuroSymbolic AI 将神经网络的优势与符号推理相结合,这需要一个数据模型和数据集成技术,既可以表示学习模式(即“我们将互联网压缩成一个大文件”)又可以表示显式规则(即“在大型制药公司,我们在 A 和 B 等情况下从事 X 和 Y 等业务”)。
这种混合方法使代理能够利用 LLM 的灵活性和本体论知识的精确性。通过将 LLM 输出建立在定义明确的架构和本体中,我们可以实现更可靠和可验证的代理行为,同时保持使 LLM 如此强大的自然语言功能。
这种混合方法具有以下几个优点 —
- 通过将明确的本体论规则与神经功能相结合,我们可以更好地验证和验证代理的输出。
- 该集成通过将代理反应与具体的企业知识相结合,帮助防止幻觉。
- 这种融合实现了更复杂的推理,利用了学习到的模式和正式的业务逻辑。
但是,本体论能够为智能体提供何种“高级推理”支持呢?在《星狗语音盒愿景》一文中,我们曾讨论过多重期望和大海捞针的问题。
通过架构偏差进行推理实现弹性查询
本体推理包括两种动态模式推理,它们使查询(以及来自人们的问题)变得不那么脆弱:类树扩展和属性树扩展。
类树扩展允许代理在查询父类时自动包含所有子类。例如,当查询“当前纬度 1 海里以内的车辆”时,类树扩展会自动包含基本 “vehicle” 类型的所有特化,以包括例如“汽车”、“卡车”、“摩托车”和“非法渔船”,而无需明确命名每个车辆——事实上,它将始终在所有模式更改中自动包含每种车辆。因此,随着我们对域和用例的理解不断发展,包括未来的专业化,例如,“疑似间谍拖网渔船”,初始查询(“当前纬度 1 海里范围内的车辆”)是动态的,并且始终是新鲜的。也就是说,由于本体推理,今天跟踪船只货物的查询可以跟踪明天的武器贩运。
**这种动态推理功能使查询更加健壮和灵活,减少了由于查询模式过于具体或脆弱而丢失相关数据的可能性,并且它完全独立于任何特定的用例或领域。**我在这里使用了一个正在运行的智能示例,但该功能适用于金融(KYC、欺诈、AML)、制造(供应链异常或数字孪生流程故障)、生命科学(批次参数、药物基因组交互)等。
属性树扩展允许代理在处理相关关系、属性(即事物之间的连接类型)时遵循类似的模式。例如,在查询 “owns” 时,系统会自动包含更具体的所有权关系,如 “leases” 或 “licenses”,而无需在查询中显式枚举。这意味着即使组织及其数据不断变化,人员和代理也可以继续提出问题。此功能可确保全面的查询结果,同时保持语义准确性。
查询(和此类问题)“告诉我一些关于所有类似事物的信息,只是更具体”,对树分支处和分支之间的变化具有弹性。
包含本体推理的知识图谱查询在面对架构漂移和变化时具有弹性,因为查询时推理意味着查询会自动适应不断发展的数据模型而不会中断。**当业务概念发生变化或出现新关系时,可以在现有查询继续工作的同时更新本体。**随着企业知识随着时间的推移而发展,这种动态适应对于维持可靠的代理操作至关重要。
成本如何?
虽然我不会在这里详细介绍,但 Stardog 正在率先使用代理来构建企业本体。
这种方法不仅缩短了实现价值的时间和成本,而且还体现了 AI 的引导效应,其中 LLM 飞轮迭代地提高了数据质量,从而增强了代理和 AI 的价值。AI 的引导效应在 LinkedIn 上关于 AI 影响的公开讨论中往往缺失。是的,生成式 AI 需要良好的企业数据输入,而很多企业数据不是很好;但同样真实的是,企业正忙于通过生成式 AI 提高数据质量。这两件事同样正确。转动飞轮 - 迭代、迭代!

将数据质量和 AI 视为一个良性循环,有助于消除关于企业是否为 AI “准备好”的人为非此即彼的争论。现实情况是,AI 采用和数据质量改进同时发生,两者相互加速。这种务实的观点认识到,开始看到价值不需要完美,同时也承认持续改进的重要性。

构建企业本体的传统方法是劳动密集型且成本高昂的,需要专业知识工程师团队(又名“本体论者”)工作多年。这种方法的问题 — 除了成本和较长的价值实现时间之外 — 还有两个非常有害的影响:
- 它分散而不是集中问责制;谁在这里真正负责:拥有工具专业知识的本体论者还是拥有领域知识的 SME?
- 真正的 SME 与产出疏远;他们必须表达他们所知道的由外部专家介导的内容,因为了解本体数据建模和业务的罕见独角兽是,嗯,一个🦄!
我们教 Stardog Voicebox 如何直接在 Stardog Designer 中构建本体的方法通过消除本体论的角色来避免这两种有害影响。没关系,我们不需要那么多:GenAI 本体代理可以在与有企业的 SME 直接对话中构建本体**。**这只是一个更好的方法。
Stardog-知识图谱增强大模型企业智能体平台Voicebox的愿景
企业级大模型智能体为什么需要融合知识图谱- Stardog的Voicebox实践
Stardog Voicebox智能体: 知识图谱&LLM双轮驱动、释放自动化的创造力
不要把海洋煮沸!
用于构建本体的 LLM 支持的代理以多种方式显著降低了这些成本:
- 更快的开发:代理可以在几分钟而不是几周内起草初始本体,从而加快知识图谱项目的价值实现时间。
- 减少专家时间:虽然人类专家仍在审查和优化代理创建的本体,但他们的时间投入显着减少。
- 迭代改进:Agent 可以根据反馈和新数据不断完善和扩展本体,使维护过程更加高效。
最重要的是,这创造了一个强大的反馈循环:随着代理创建更好的本体,其他代理在他们的任务中变得更加有效,这反过来又产生了更好的数据,用于进一步的本体优化。这种良性循环推动了持续改进,同时保持成本明显低于传统方法。成本节省不仅仅是直接的开发费用。更好的本体意味着整个企业中更有效的代理,从而提高运营效率并减少错误。这种乘数效应使代理创建的本体的 ROI 特别引人注目。
AI 驱动的生产力
让我们退后一步。关于招聘代理将候选人提供给招聘代理,而面试代理则与两者互动,有很多讨论。当然,为什么不呢?
但这种观点过于简单化。与其考虑用代理一对一地替换人类角色,不如设想代理处理角色的各个部分——每个角色都执行要完成的特定工作。
在这篇文章中,我重点介绍了支持人工决策的 “收集相关数据” 工作。这分为不同的任务:发现新数据、验证数据准确性、检索当前事实、确保遵守业务规则以及根据新情况调整标准操作程序。这些任务中的每一个都可以进一步细分,并且每个任务可能都有独特的要求。
但关键是:**代理和人类一样,需要高质量的数据才能有效运作。**他们可能是理性的行为者(尽管有局限性),通过计算、数据和有目的的任务的组合来运作。人类,至少是我们中最好的人,都以把事情做好的基本承诺为指导;AI 代理不知道这意味着什么,这就是为什么他们比我们更需要获得高质量的数据。
你的秘密武器是问责制
你如何让计算机程序负责?
归根结底,在工作中将人们联系在一起的是三件事:
- 团结一致(“她是个好队友”),
- 共同目标(即部分或完全重叠的自身利益)
- 责任感(愿意面对自己和彼此信守承诺)。
AI 代理不是真正的人。AI 代理不是道德代理,他们缺乏任何道德敏感性。这就是为什么 AI 革命不会导致人们在工作中被代理集体取代的关键原因。
如果没有人们对自己和彼此负责,企业怎么能存在?代理 AI 可能是通货紧缩的,它可能会使运营支出和收入增长脱钩——至少我欢迎后者。但是,你不能让 AI 代理承担责任,因为 AI 代理既不做出也不信守承诺。
因此,**您在代理未来的秘密武器是快乐地坚持对履行承诺负责。**人,而不是代理,做出并遵守承诺。人,而不是代理,要求自己和他人对努力和结果负责。在一个越来越多地被 AI 代理占据的世界里,他们永远不会教代理学习独特的人类问责能力。
人机协同是我们正在构建的世界
我们对 Stardog 的愿景是,**任何人都可以询问有关任何数据的任何问题,并立即获得快速、准确、无幻觉的答案。**我在这篇文章中的目标是让您看到“任何人”既是指从事知识工作的人,也是指代理 AI,这两者都需要民主化的数据访问。我们的国防和情报合作伙伴非常关注这一双重现实,他们称之为人机合作,这是完全正确的。
**知识图谱、本体和神经符号 AI 为代理及其数据访问奠定了坚实的基础,包括在与人类主题专家的对话中使用代理快速引导本体。**令人高兴的是,这些方法也适用于人类!
目标是让您看到“任何人”既是指从事知识工作的人,也是指代理 AI,这两者都需要民主化的数据访问。我们的国防和情报合作伙伴非常关注这一双重现实,他们称之为人机合作,这是完全正确的。
**知识图谱、本体和神经符号 AI 为代理及其数据访问奠定了坚实的基础,包括在与人类主题专家的对话中使用代理快速引导本体。**令人高兴的是,这些方法也适用于人类!
与可以通过共同目标和道德能动性来承担责任的人不同,AI 代理缺乏这些基本品质。这一重要差异表明,虽然 AI 代理将增强和支持人类工作,但它们无法完全取代人类工人——企业最终依赖于只有人才能提供的责任感。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 7
7 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)