图像生成领域新概念,“RAE”是什么?
昨天刚提到AI领域发展快,今天又看到一篇新的公众号文章,提到VAE要过时了,谢赛宁提出了新 的RAE,要知道VAE编码器可是图形图像领域里边非常关键的一个基础,如果这里发生了质变,那么图像生成领域可能又会有新的变数。
 先不管是不是真的可以颠覆,我们先来了解下论文中提到的“RAE”到底是个啥。
先不管是不是真的可以颠覆,我们先来了解下论文中提到的“RAE”到底是个啥。
首先附个原始论文链接:https://pan.quark.cn/s/d829a5984db7
这篇论文核心是改进图像生成模型(扩散Transformer,简称DiT)的“中间处理环节”,让它生成的图像更逼真、训练更快,还能少走弯路。
咱们用大白话拆成
“原来的问题”
“新方案”
“解决新问题的小技巧”
“最终效果”
四部分讲:
一、先懂背景:原来的图像生成是怎么干活的?
现在想让AI生成高清图(比如用DiT这种模型),通常要走两步:
1. 压缩环节:用一个叫VAE的模型,把像素(比如256×256的图片)变成一种“中间表示”(可以理解成“图像密码”)——这个“密码”维度低(比如从百万像素压成几千维),方便后续处理;
2.生成环节:DiT模型(当然之前的diffusion模型也是一样的)在这个“中间表示”上干活,逐步把“噪声”变成有意义的“密码”,最后再用VAE的另一半(解码器)把“密码”还原成像素图。
以上方法就是大家之前熟悉的加噪降噪环节了。
但问题来了:VAE这一步太拉胯了!
- 技术老:用的是老架构,计算慢还不灵活;
- 密码“存不下信息”:维度太低,只能记住局部像素(比如这一块是红色),记不住全局语义(比如这是一只猫);
- 学的东西没用:VAE只练“怎么压缩再还原”,没学“图像的语义逻辑”,导致DiT后续生成时,要么细节糊,要么逻辑乱(比如猫长了狗耳朵)。
其实本质上来说,就是太暴力了,能压缩能生成就行,学的东西有点不求甚解,主打一个能用就行。
二、论文的核心新方案:换个“中间处理工具”——RAE
既然VAE不行,论文就想:能不能用更懂“图像语义”的模型来做“中间表示”?
于是提出了“表示自动编码器(RAE)”,它的思路很简单:
- 不用VAE做“压缩”了,改用已经训练好的“图像理解模型”(比如DINO、SigLIP这些——这些模型本来是用来“认图”的,能分清猫和狗、知道哪里是眼睛哪里是尾巴,懂语义);
- 给这些“认图模型”配一个轻量级的“解码器”(专门负责把“语义密码”还原成像素图)。
这样一来,RAE的“中间表示”就比VAE强太多了:
- 懂语义:能记住“这是猫”“耳朵在头顶”这种全局逻辑,不是只记像素;
- 信息多:维度比VAE高(能存更多细节),还原出来的图更清晰;
- 算得快:架构比VAE简单,压缩/还原的速度是VAE的3-6倍。
三、新问题:RAE的“密码”太复杂,DiT处理不了怎么办?
RAE的“中间表示”维度高(比如原来VAE是几千维,RAE是几千到上万维),但原来的DiT是为VAE的“低维密码”设计的——直接用DiT处理RAE的“高维密码”,要么学不会(模型卡住),要么学不好(生成的图还是糊)。
论文针对性解决了3个小问题,相当于给DiT“升级装备”:
让DiT“够宽”:原来的DiT“通道宽度”比RAE的“密码维度”小,就像用细管子装大水流——把DiT的“宽度”调大到至少等于RAE的“密码维度”,就能装下所有信息了;
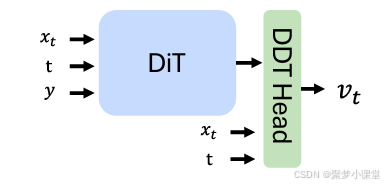
(实际上也就是刚刚提到的dit模型,本来输入项是针对vae出来的latent进行还原,现在通过一个宽头设计,让Dit能接受现在更高的维度,能塞进去就能用😄)
调整“噪声节奏”:DiT训练时要给“密码”加噪声再去消噪(这是扩散模型的核心),但原来的“加噪声节奏”是给低维密码设计的——高维密码得按“维度大小”调整节奏,不然噪声加太多/太少,DiT都学不会;
下边这张图虽然是用来表示算力消耗差异的,但也可以用来理解俩模型架构的不同,所以噪声节奏也得对应着调整一下。
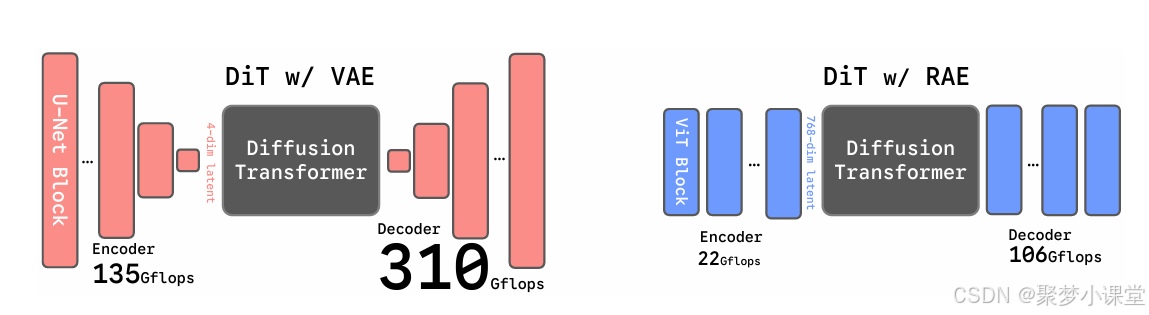
让解码器“抗造”:RAE的解码器本来只练过“还原干净的密码”,但DiT生成的“密码”多少带点噪声(不可能100%完美)——训练解码器时故意加一点噪声,让它提前适应“不完美的密码”,后续还原时就不会“懵”了。
四、再给DiT“加个小外挂”:DiT^DH
解决了RAE的适配问题后,论文还嫌DiT不够高效——如果为了处理高维密码,把整个DiT都加宽,算力会翻倍涨。 于是给DiT加了个 宽但浅的头 (叫DDT头) :
嗯,还是这张图:
不用把整个DiT变宽,只在最后加一个“短平快”的模块(比如2层、但维度很高),专门负责“消噪”。这样既满足了“处理高维密码”的需求,又不用多花算力,相当于“花小钱办大事”。
五、最终效果:又快又好,刷新纪录
在ImageNet(有1000类图像的标准数据集)上测试,
结果很顶:
生成256×256的图:没加额外引导时,“像真图”的评分(FID,数字越小越好)是1.51;加引导后是1.13(比之前所有方法都低);
生成512×512的图:加引导后评分也是1.13,细节能到“猫的胡须根根分明”“树叶的纹理清晰”;
训练还快:
比之前靠VAE的方法快47倍,比靠额外语义训练的方法快16倍,还不用额外加训练目标(少走弯路)(主要是编码器不用训了,用现有的,只需训练解码器的部分就行)。
总结一下
这篇论文干了件“换工具”的事:把原来“笨笨的压缩工具(VAE)”换成“聪明的语义工具(RAE)”,再给DiT加几个“适配小技巧”和“效率外挂”,最终让AI生成图像又快、又像、又懂语义——相当于给图像生成模型“换了个更强大的大脑”。
附录一个VAE和RAE的对比
两者的本质差异,源于设计目标的不同:VAE 是 “为了压缩重建”,RAE 是 “为了语义表征 + 高效生成”,具体区别如下:
| 对比维度 | VAE 的 latent(文档核心特性) | RAE 的语义 latent(文档核心特性) |
|---|---|---|
| 1. 核心目标 | 以 “低成本重建图像” 为核心,追求 “压缩率”—— 把高分辨率图像(如 256×256)压成低维 latent(如 32×32×4),减少存储和计算成本。 | 以 “高质量语义表征” 为核心,追求 “信息完整性”—— 用预训练的语义编码器(如 DINO、SigLIP)捕捉图像的全局语义,同时保留细节,不刻意压缩。 |
| 2. 维度与信息密度 | 高压缩、低维度、信息有限:比如 256×256 图像会被压成 32×32×4 的 latent(维度仅 4096),只能保留局部像素信息(如 “这一块是红色”),丢失全局语义(如 “这是猫的耳朵”)。 | 低压缩、高维度、信息丰富:比如用 DINOv2-B 做编码器,256×256 图像会生成 256 个 token(每个 token 维度 768),总维度 196608,能同时保留 “猫的语义” 和 “毛发纹理” 等细节。 |
| 3. 语义能力 | 几乎无语义:VAE 仅通过 “重建损失” 训练(只练 “怎么压缩再还原像素”),没学过图像的语义逻辑,latent 里没有 “这是猫 / 狗 / 树” 的概念。文档中提到,SD-VAE 的线性探针精度(衡量语义表征能力)仅 8%,连基本的图像类别都分不清。 | 强语义:RAE 的编码器是冻结的预训练模型(如 DINO、SigLIP)—— 这些模型本来就是为 “理解图像语义” 设计的(比如 DINO 能分清猫和狗、知道耳朵的位置),所以 latent 天生携带 “语义逻辑”。文档中 DINOv2-B 的线性探针精度达 84.5%,能精准识别图像类别。 |
| 4. 生成逻辑与稳定性 | 概率性、稳定性弱:latent 是从 “概率云” 中随机采样的,同一幅图像每次生成的 latent 都有差异,且因为压缩过度,latent 空间 “不连续”—— 比如从 “猫” 的 latent 插值到 “狗” 的 latent,中间可能出现无意义的模糊图像。 | 确定性为主、稳定性强:RAE 的编码器是冻结的,同一幅图像会输出几乎固定的 latent(仅在训练解码器时加少量噪声,让解码器适应扩散模型的微小误差),latent 空间 “语义连续”—— 从 “猫” 的 latent 插值到 “狗” 的 latent,中间会出现 “猫狗过渡形态” 的合理图像。 |
关键补充1:VAE 的 latent 是 “压缩包”,RAE 的语义 latent 是 “带注释的说明书”
- VAE 的 latent 像把一本 “图像百科全书” 压缩成一个 “加密压缩包”:体积小,但只有解码器能勉强还原成 “模糊的书”,里面没有 “章节标题(语义)”,只有 “文字碎片(像素信息)”;
- RAE 的语义 latent 像把 “图像百科全书” 整理成一本 “带章节注释的精简版”:体积比压缩包大,但保留了 “章节标题(这是猫)”“段落逻辑(耳朵在头顶)”,解码器能还原出 “清晰且逻辑通顺的书”,后续扩散模型(DiT)也能顺着 “注释” 高效生成新内容。
关键补充2:两者与扩散模型的分工
无论 VAE 还是 RAE,都只负责 “图像→latent” 的转换;“加噪→纯噪声→消噪生成新 latent” 是扩散模型(DiT)的工作:
- 用 VAE 时,DiT 要在 “低维、无语义的 latent” 上工作,所以需要额外适配(比如加辅助损失),且生成质量受限;
- 用 RAE 时,DiT 在 “高维、有语义的 latent” 上工作,只需简单调整(如匹配 DiT 宽度、调整噪声节奏),就能更快收敛、生成更逼真的图像。
emm, 整体听起来还是很靠谱的,期待后续这个技术的发展,如果可以的话,或许图像视频领域生成的质量和效率又可以有新的跨越了。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 34
34 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)