一文详解“频繁模式挖掘”算法
频繁模式挖掘是数据挖掘中用于发现数据集中高频出现的物品组合、序列或结构的方法。核心指标包括支持度(衡量普遍性)和置信度(衡量关联强度)。Apriori算法通过逐层搜索和剪枝发现频繁项集,但需多次扫描数据;FP-Growth算法则通过构建压缩的FP树结构,仅需两次扫描即可高效挖掘。两者对比显示FP-Growth在效率上优势明显,但实现更复杂。此外还有Eclat等垂直数据格式算法。实际应用中,FP-G
一、什么是频繁模式?
1. 核心概念
频繁模式是指在数据集中频繁出现的物品集合、子序列或子结构。
-
最典型的例子:超市购物篮分析。
-
项目集:顾客一次购买的商品集合,如
{牛奶,面包,黄油}。 -
频繁项集:如果很多顾客都同时购买了
{牛奶,面包},那么这个组合就是一个频繁项集。
-
2. 关键度量指标
要判断一个模式是否“频繁”,需要依赖以下两个核心指标:
-
支持度
-
定义:项集在所有交易中出现的频率。
-
公式:
Support(X) = (包含X的交易数) / (总交易数) -
作用:衡量项集的普遍重要性。支持度越高,说明它越常见。
-
-
置信度 (主要用于关联规则)
-
定义:在包含项集X的交易中,也包含项集Y的条件概率。
-
公式:
Confidence(X -> Y) = Support(X ∪ Y) / Support(X) -
作用:衡量规则的可信度。置信度越高,说明当X出现时,Y也出现的可能性越大。
-
示例:假设有5条交易记录:T1: {牛奶,面包}T2: {面包,尿布}T3: {牛奶,面包,尿布}T4: {牛奶,尿布}T5: {面包,啤酒}
-
Support({牛奶}) = 3/5 = 0.6(出现在T1, T3, T4中) -
Support({牛奶,面包}) = 2/5 = 0.4(出现在T1, T3中) -
Confidence(牛奶 -> 面包) = Support({牛奶,面包}) / Support({牛奶}) = 0.4 / 0.6 ≈ 0.67
这意味着购买牛奶的顾客中,有67%也会购买面包。
3. 关联规则挖掘
关联规则挖掘通常分为两步:
-
找出所有频繁项集:即支持度不低于用户设定的最小支持度阈值(min_sup)的项集。
-
生成强关联规则:从频繁项集中提取置信度不低于用户设定的最小置信度阈值(min_conf)的规则。
第一步是计算开销最大、最关键的步骤。下文介绍的算法主要聚焦于如何高效地完成第一步。
二、Apriori 算法
Apriori算法是挖掘频繁项集最经典、最基础的方法。其核心思想是:频繁项集的所有子集也一定是频繁的(反之,如果一个项集是非频繁的,那么它的所有超集也都是非频繁的)。这被称为 Apriori原理 或 “反单调性”。
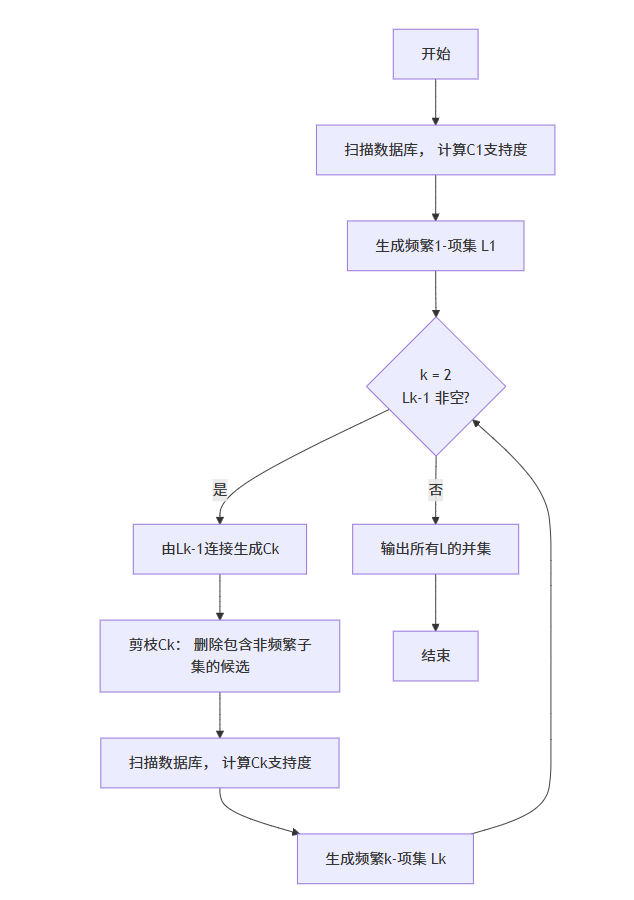
Apriori算法的步骤:
算法通过一种称为“逐层搜索”的迭代方法,由k项集产生(k+1)项集。
-
扫描与计数:扫描整个数据库,统计每个单项(1项集)的支持度。
-
剪枝:将支持度低于预设最小支持度阈值的项集剔除,保留频繁1项集(记为 L1)。
-
连接:基于上一步得到的频繁k项集(Lk),通过连接操作生成候选(k+1)项集(Ck+1)。例如,将L1与自身连接生成候选2项集C2。
-
剪枝:利用Apriori性质(反单调性)对候选集进行剪枝。即检查候选(k+1)项集的每个k项子集是否都在Lk中。如果某个子集不在Lk中,则该候选集不可能是频繁的,可以剪掉。
-
扫描与计数:再次扫描数据库,计算剪枝后剩余候选集的支持度。
-
重复:重复步骤3-5(连接->剪枝->计数),直到不能再产生新的频繁项集为止。
-
生成强关联规则:从所有找到的频繁项集中,生成置信度高于预设最小置信度阈值的规则。
实例演示:
设最小支持度 min_sup = 2 (即出现2次以上),数据集为上文的5条交易记录。
-
第1次扫描:计算所有单项的支持度。
项集 支持度计数 {牛奶} 3 {面包} 4 {尿布} 3 {啤酒} 1 得到 L1:
{牛奶}, {面包}, {尿布}(啤酒支持度计数为1,被淘汰) -
连接生成 C2:将L1中的项两两连接。
C2 = { {牛奶,面包}, {牛奶,尿布}, {面包,尿布} } -
第2次扫描:计算C2中所有项集的支持度。
项集 支持度计数 {牛奶,面包} 2 (T1, T3) {牛奶,尿布} 2 (T3, T4) {面包,尿布} 2 (T2, T3) 得到 L2:
{牛奶,面包}, {牛奶,尿布}, {面包,尿布}(全部满足min_sup) -
连接生成 C3:将L2中的项集连接。连接原则是:两个项集的前k-1项相同,最后一项不同。
-
{牛奶,面包}和{牛奶,尿布}的前一项相同,连接后得到{牛奶,面包,尿布}。 -
{牛奶,面包}和{面包,尿布}的前一项不同,不能连接。 -
{牛奶,尿布}和{面包,尿布}的前一项不同,不能连接。 -
所以
C3 = { {牛奶,面包,尿布} }
-
-
剪枝:检查C3中项集的所有子集是否都是频繁的。
-
{牛奶,面包,尿布}的子集有:{牛奶,面包}(频繁),{牛奶,尿布}(频繁),{面包,尿布}(频繁)。所有子集都在L2中,所以无需剪枝。
-
-
第3次扫描:计算C3的支持度计数。
项集 支持度计数 {牛奶,面包,尿布} 1 (仅T3) 支持度计数为1 < min_sup(2),因此被淘汰。得到 L3 = ∅。
-
算法结束。所有频繁项集为:L1 ∪ L2。
算法流程图:
Apriori算法的优点:
-
原理简单:算法思想易于理解,实现直接。
-
为后续算法奠定基础:其核心的“先验原理”是许多关联规则挖掘算法的基石。
Apriori算法的缺点:
-
需要产生大量候选集:这是其主要瓶颈。尤其是对于长频繁模式,会产生数量极其庞大的候选集(如100个频繁1项集会产生C(100,2)=4950个候选2项集)。
-
多次扫描数据库:每计算一层k项集的支持度,都需要对整个数据库进行一次完整的扫描。当数据库很大时,I/O开销巨大,效率很低。
三、FP-Growth 算法
为了解决Apriori算法的缺陷,Han Jiawei等人提出了FP-Growth(Frequent Pattern Growth,频繁模式增长)算法。它采用分治策略,仅需扫描数据库两次,并将数据集压缩到一棵FP树(频繁模式树)中,之后的所有操作都在内存中的这棵树上进行,极大提升了效率。
算法步骤:
-
第一次扫描:与Apriori类似,计算所有单项的支持度,丢弃非频繁项,并将频繁项按支持度降序排序。
-
上例中,排序后的频繁项列表为:
[面包:4, 牛奶:3, 尿布:3](假设面包支持度最高)
-
-
构建FP树:
-
创建树的根节点,记为
null。 -
第二次扫描数据库,按第一步生成的频繁项列表的顺序处理每条交易,并将其作为一条路径插入FP树。路径重叠的部分会共享节点,并增加计数。
-
-
从FP树中挖掘频繁项集:
-
为FP树中的每个项(通常从支持度最低的项开始)构建条件模式基。
-
条件模式基:前缀路径的集合,这些路径以当前项为结尾。
-
根据条件模式基构建条件FP树。
-
递归地挖掘条件FP树,得到所有的频繁项集。
-
实例演示(使用相同的数据和min_sup=2):
1. 第一次扫描:得到频繁1-项集及排序后的列表 L = [面包:4, 牛奶:3, 尿布:3]。
2. 构建FP树:
-
T1: {牛奶,面包} -> 排序后
{面包,牛奶}。在根节点下创建子节点面包:1,然后在其下创建牛奶:1。 -
T2: {面包,尿布} -> 排序后
{面包,尿布}。根节点下已有面包,计数+1变为面包:2。然后在面包下创建兄弟节点尿布:1?不对。FP树要求同一条路径上的项必须按顺序排列。所以应该在面包:2下创建新节点尿布:1。 -
T3: {牛奶,面包,尿布} -> 排序后
{面包,牛奶,尿布}。路径<面包:3 -> 牛奶:1 -> 尿布:1>。发现面包已存在,计数+1变面包:3。面包下原有节点牛奶:1,计数+1变牛奶:2。牛奶下没有尿布,因此创建新节点尿布:1。 -
T4: {牛奶,尿布} -> 排序后
{牛奶,尿布}(面包不在本交易中,因此被排除)。根节点下没有牛奶,因此创建新节点牛奶:1(注意:因为它是以牛奶开头的新分支),然后在其下创建尿布:1。 -
T5: {面包,啤酒} -> 啤酒非频繁,被移除。排序后
{面包}。根节点下已有面包:3,计数+1变面包:4。
最终构建的FP树如下图所示:
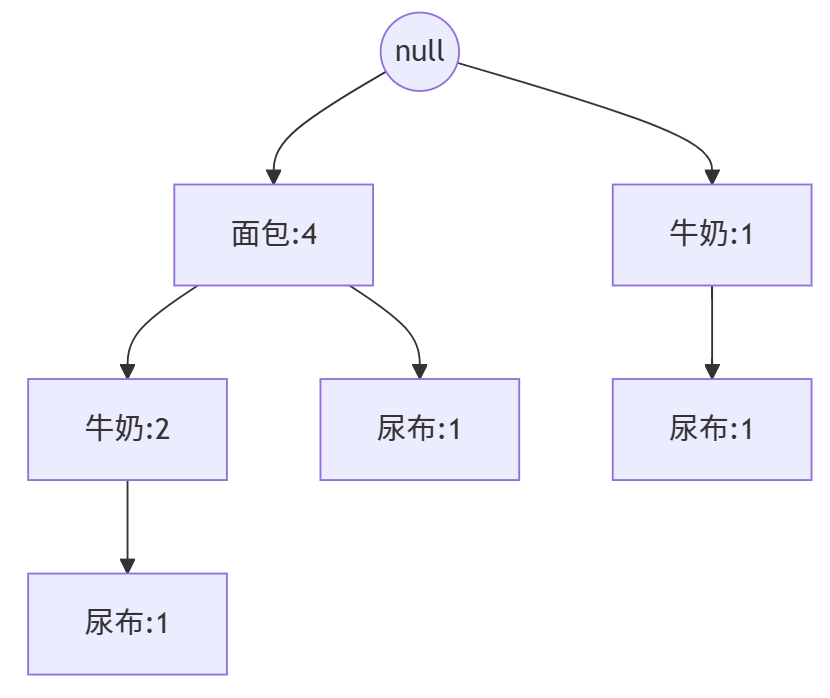
图示:FP树结构。同一颜色的节点代表同一个项。
3. 挖掘FP树(以‘尿布’为例)
-
寻找‘尿布’的条件模式基:
-
在FP树中找出所有以‘尿布’结尾的路径。
-
路径1:
面包:4 -> 牛奶:2 -> 尿布:1。其前缀路径是<面包, 牛奶:1>(计数由路径中最末尾的节点‘尿布:1’决定)。 -
路径2:
面包:4 -> 尿布:1。前缀路径是<面包:1>。 -
路径3:
牛奶:1 -> 尿布:1。前缀路径是<牛奶:1>。 -
‘尿布’的条件模式基 是:
{ {面包,牛奶}:1, {面包}:1, {牛奶}:1 }。
-
-
构建‘尿布’的条件FP树:
-
条件模式基中的项的支持度计数由路径的计数决定。
-
牛奶出现了两次(1+1),支持度计数为2 >= min_sup(2),保留。 -
面包出现了两次(1+1),支持度计数为2 >= min_sup(2),保留。 -
根据支持度排序(假设面包>牛奶),条件FP树只有一个分支
<面包:2 -> 牛奶:2>。注意计数是累加的。
-
-
挖掘‘尿布’的条件FP树:
-
条件FP树不是空的,说明存在频繁项集。
-
通过组合条件FP树中的项,可以生成包含‘尿布’的频繁项集:
-
{尿布}本身是频繁的(已知)。 -
{牛奶,尿布}:支持度为2(来自条件FP树中‘牛奶’的计数),是频繁的。 -
{面包,尿布}:支持度为2(来自条件FP树中‘面包’的计数),是频繁的。 -
{面包,牛奶,尿布}:支持度为2(来自条件FP树中路径的计数),是频繁的。
-
-
通过这种方式,可以递归地找到以每个项为后缀的所有频繁项集。
FP-growth算法的优点:
-
效率显著高于Apriori:通常比Apriori快一个数量级。
-
只需扫描数据库两次:第一次统计支持度,第二次构建FP树。大大减少了I/O开销。
-
不产生候选集:直接在压缩后的数据结构(FP树)上进行挖掘,避免了产生和测试大量候选集的开销。
FP-growth算法的缺点:
-
FP树的构建和存储开销可能很大:虽然数据库被压缩,但当数据集中频繁模式非常多、非常长时,FP树可能无法完全放入内存,尤其是条件FP树在递归过程中可能会被多次构建。
-
实现比Apriori复杂:递归挖掘FP树的过程相对不易理解和实现。
-
对数据分布敏感:数据的特性(如事务的相似度)会影响FP树的压缩效果。
四、总结与对比
| 特性 | Apriori 算法 | FP-Growth 算法 |
|---|---|---|
| 核心思想 | 使用候选集,通过逐层搜索和剪枝发现频繁项集 | 使用分治策略,将数据库压缩到FP树中,无候选集 |
| 扫描次数 | 多次(每轮迭代都需要扫描) | 两次 |
| 效率 | 较低,尤其当候选集很大时 | 很高,通常是Apriori的数量级倍快 |
| 主要开销 | 候选集生成与测试、多次扫描 | FP树的构建(内存消耗) |
| 实现难度 | 简单直观 | 相对复杂 |
五、其他算法
除了上述两种经典算法,还有:
-
Eclat算法:采用垂直数据格式(即记录每个项集出现在哪些事务中,TID列表),通过交集运算来计算支持度,非常适合内存计算。
-
LCQ算法:基于概念格的理论。
-
H-Mine算法:基于超链表结构。
在实际应用中,FP-Growth 及其变种因其高性能而被广泛采用。
希望这篇详细的讲解和图示能帮助你彻底理解频繁模式挖掘算法!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)