c++判断字符串是否为utf8编码
如果想要查看文本文件的编码方式,可以用记事本打开文件,然后选择"另存为"菜单,即可查看当前的编码方式。在windows平台下,win7系统文本文件默认为ANSI即多字节编码,而win10和win11默认为utf-8编码。不论是ANSI,还是UTF-8,在打开文件之前,都无法得知其编码方式。常用的方法是先按照ANSI读取,然后判断字符串是否UTF-8编码,如果是,再转换为ANSI编码。1、bool
在解析文本文件时,如果不能提前知道它的编码方式,就有可能出现乱码的情况。在windows平台下,win7系统文本文件默认为ANSI即多字节编码,而win10和win11默认为utf-8编码。
如果想要查看文本文件的编码方式,可以用记事本打开文件,然后选择"另存为"菜单,即可查看当前的编码方式。如下图所示,文件为utf-8编码。在winwin11系统下,也可以直接从右下角状态栏获取编码方式。
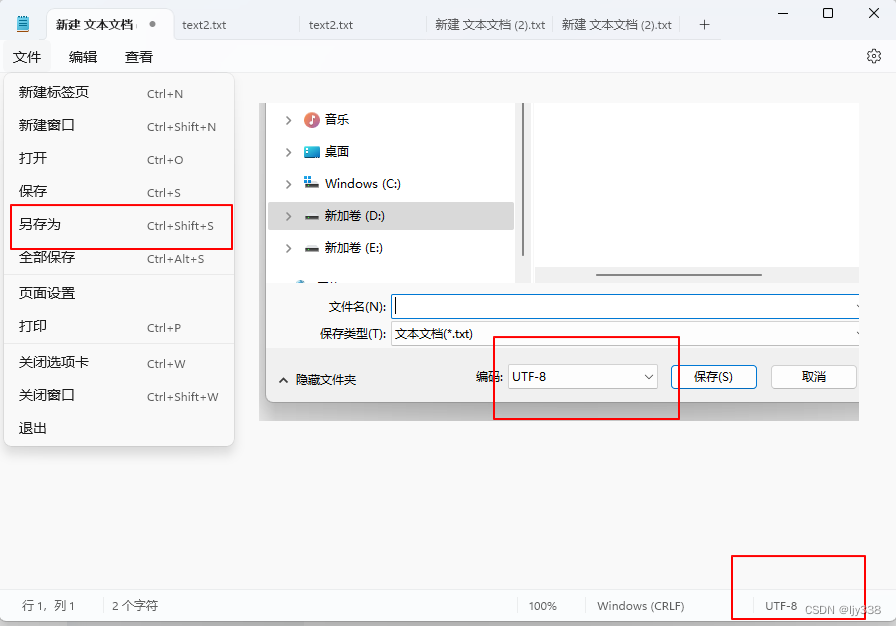
不论是ANSI,还是UTF-8,在打开文件之前,都无法得知其编码方式。常用的方法是先按照ANSI读取,然后判断字符串是否UTF-8编码,如果是,再转换为ANSI编码。
判断字符串是否为UTF-8编码,参考下面博客:
https://blog.csdn.net/zison_sun/article/details/5815746
代码如下:
bool IsUTF8(const void *pBuffer, int size)
{
bool IsUTF8 = false;
unsigned char *start = (unsigned char *)pBuffer;
unsigned char *end = (unsigned char *)pBuffer + size;
while (start < end)
{
if (*start < 0x80) // (10000000): 值小于0x80的为ASCII字符
{
start++;
}
else if (*start < (0xC0)) // (11000000): 值介于0x80与0xC0之间的为无效UTF-8字符
{
IsUTF8 = false;
break;
}
else if (*start < (0xE0)) // (11100000): 此范围内为2字节UTF-8字符
{
IsUTF8 = true;
if (start >= end - 1)
break;
if ((start[1] & (0xC0)) != 0x80)
{
IsUTF8 = false;
break;
}
start += 2;
}
else if (*start < (0xF0)) // (11110000): 此范围内为3字节UTF-8字符
{
IsUTF8 = true;
if (start >= end - 2) break;
if ((start[1] & (0xC0)) != 0x80 || (start[2] & (0xC0)) != 0x80)
{
IsUTF8 = false; break;
}
start += 3;
}
else if (*start < (0xF8)) // (11111000): 此范围内为4字节UTF-8字符
{
IsUTF8 = true;
if (start >= end - 3) break;
if ((start[1] & (0xC0)) != 0x80 || (start[2] & (0xC0)) != 0x80 || (start[3] & (0xC0)) != 0x80)
{
IsUTF8 = false; break;
}
start += 4;
}
else
{
IsUTF8 = false;
break;
}
}
return IsUTF8;
}
与原始代码相比,做了两处修正。
1、bool IsUTF8 = false,默认为非UFT8,直到遇到UFT8为止,这样更加准确。
2、增加4字节长度判断,即 else if (*start < (0xF8))行。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)