使用SWIFT微调大模型完成回归任务
传统大语言模型通过预测下一个token的概率来生成文本,其损失函数通常采用softmax分类器,这使得它们难以直接处理回归任务(需要输出连续数值)。然而,大模型具备强大的高维特征编码能力,我们可以利用预训练模型作为特征提取器,通过微调适配回归任务,从而获得优异的性能表现。• 训练方式:取最后一个token的隐藏状态(1,896),使用RMS损失函数计算回归结果。本示例使用大模型计算句子相似度,输出
文章目录
使用SWIFT微调大模型完成回归任务
传统大语言模型通过预测下一个token的概率来生成文本,其损失函数通常采用softmax分类器,这使得它们难以直接处理回归任务(需要输出连续数值)。然而,大模型具备强大的高维特征编码能力,我们可以利用预训练模型作为特征提取器,通过微调适配回归任务,从而获得优异的性能表现。
SWIFT框架对大模型任务提供了全面支持,最新版本已专门增加了回归任务功能。本文将详细介绍SWIFT框架实现回归任务的技术方案。
SWIFT执行回归命令
执行回归任务的命令示例如下:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-0.5B \
--train_type lora \
--dataset 'sentence-transformers/stsb:reg#20000' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 1 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4 \
--num_labels 1 \
--task_type seq_cls \
--use_chat_template false \
--problem_type regression
关键参数说明
必须指定的核心参数:
--num_labels 1 \
--task_type seq_cls
可选参数(框架会自动推断):
--problem_type regression
本示例使用大模型计算句子相似度,输出为0-1之间的连续相似度分数。
SWIFT框架回归任务的实现机制
损失函数设计
框架通过swift.trainers.Trainer类调用以下损失函数:
def ForSequenceClassificationLoss(labels: torch.Tensor, pooled_logits: torch.Tensor, config, **kwargs) -> torch.Tensor:
num_labels = config.num_labels
if config.problem_type is None:
if num_labels == 1:
config.problem_type = "regression"
elif num_labels > 1 and (labels.dtype in (torch.long, torch.int)):
config.problem_type = "single_label_classification"
else:
config.problem_type = "multi_label_classification"
labels = labels.to(pooled_logits.device)
if config.problem_type == "regression":
loss_fct = MSELoss()
if num_labels == 1:
return loss_fct(pooled_logits.squeeze(), labels.squeeze())
else:
return loss_fct(pooled_logits, labels)
if config.problem_type == "single_label_classification":
return fixed_cross_entropy(pooled_logits.view(-1, num_labels), labels.view(-1), **kwargs)
if config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
return loss_fct(pooled_logits, labels)
raise RuntimeError(f"Invalid problem type: {config.problem_type}")
关键实现细节:
• 当num_labels=1时自动设置为回归任务
• 使用MSE损失函数(均方误差)
• 通过squeeze()操作确保张量维度匹配
模型架构解析
运行日志显示模型结构如下:
[INFO:swift] model: PeftModelForSequenceClassification(
(base_model): LoraModel(
(model): Qwen2ForSequenceClassification(
(model): Qwen2Model(
(embed_tokens): Embedding(151936, 896)
(layers): ModuleList(
(0-23): 24 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): lora.Linear(
(base_layer): Linear(in_features=896, out_features=896, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=896, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=896, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear(
(base_layer): Linear(in_features=896, out_features=128, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=896, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=128, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear(
(base_layer): Linear(in_features=896, out_features=128, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=896, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=128, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear(
(base_layer): Linear(in_features=896, out_features=896, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=896, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=896, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
)
(mlp): Qwen2MLP(
(gate_proj): lora.Linear(
(base_layer): Linear(in_features=896, out_features=4864, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=896, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4864, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear(
(base_layer): Linear(in_features=896, out_features=4864, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=896, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4864, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear(
(base_layer): Linear(in_features=4864, out_features=896, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4864, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=896, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((896,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((896,), eps=1e-06)
(rotary_emb): Qwen2RotaryEmbedding()
)
(score): ModulesToSaveWrapper(
(original_module): Linear(in_features=896, out_features=1, bias=False)
(modules_to_save): ModuleDict(
(default): Linear(in_features=896, out_features=1, bias=False)
)
)
)
)
)
整个模型的架构类似如下: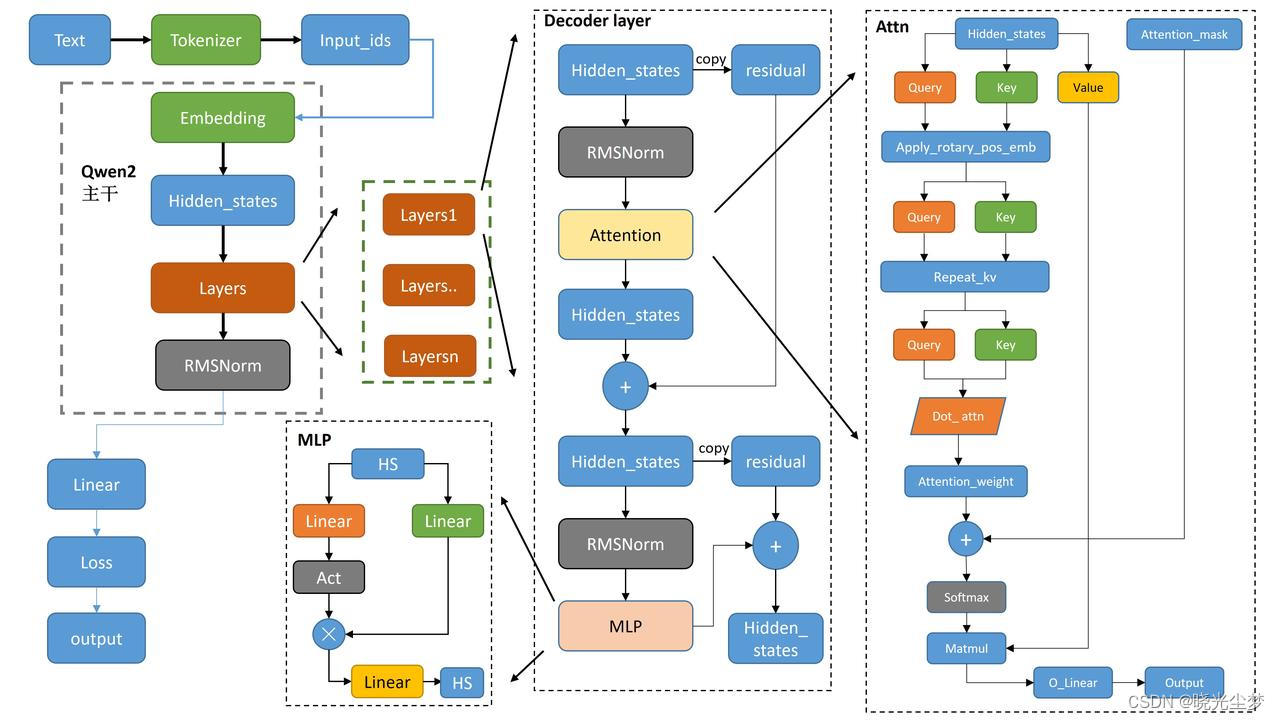
我觉得可能跟Llama2架构更像,但是还是有不一样的(有时间进行修改更新):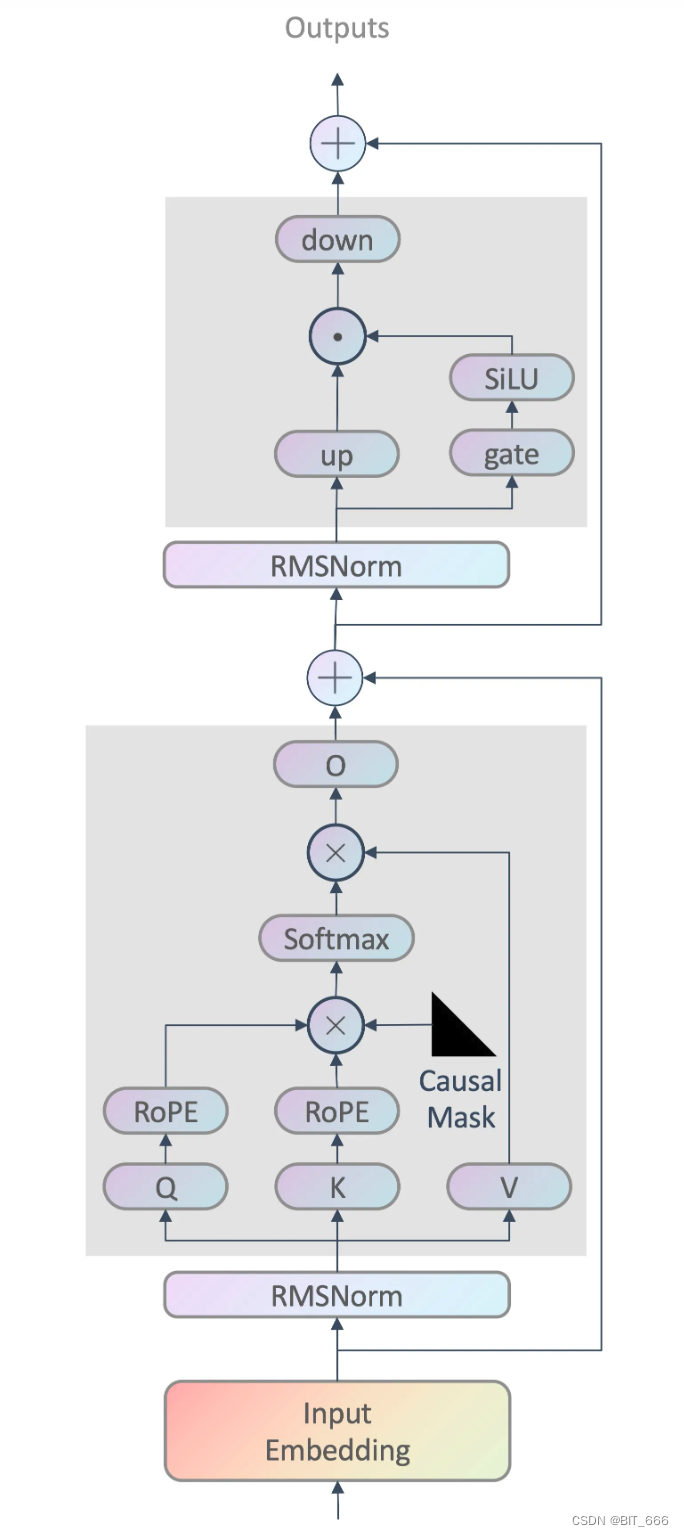
模型架构深度解析
核心组件
1. 基座模型Qwen2
• 类型:Decoder-only架构(24层堆叠)
• 关键参数:
◦ 词嵌入:151,936词汇表×896维度
◦ 注意力机制:7个注意力头,键/值维度128
◦ MLP扩展比:5.44倍(896→4864)
◦ 归一化:Qwen2RMSNorm(ε=1e-6)
◦ 位置编码:RoPE旋转位置编码
2. LoRA适配器
• 适配位置:
◦ 注意力层:q/k/v/o_proj
◦ MLP层:gate/up/down_proj
• 参数配置:
◦ 秩r=8
◦ 低秩分解公式:W' = W + B·A
◦ Dropout率:0.05
*3. 回归输出层
• 结构:Linear(896→1)
• 训练方式:取最后一个token的隐藏状态(1,896),使用RMS损失函数计算回归结果。
举一个例子(以下AI生成,大致看了一下修改了一下)
假设输入三个TOKEN
输入序列:[token₁, token₂, token₃]
目标输出:数值预测值 y ∈ ℝ
- 输入嵌入层(Embedding)
• 输入矩阵:X ∈ ℕ³(三个token的ID序列)
• 操作:Embedding(151936, 896)
• 输出矩阵:E ∈ ℝ³×896
• 计算过程:
E = embed_layer(X)
# 将每个token映射为896维向量
-
Decoder层处理(24层迭代)
每层包含以下关键操作:2.1 自注意力机制
• 输入矩阵:H_in ∈ ℝ³×896• 线性变换(带LoRA):
# 原始权重 W_q ∈ ℝ^{896×896} # LoRA分解:ΔW = B_q @ A_q,其中 A_q ∈ ℝ^{896×8}, B_q ∈ ℝ^{8×896} Q = (H_in @ W_q) + (H_in @ A_q.T @ B_q.T) # ∈ ℝ³×896 # 类似处理K ∈ ℝ³×128, V ∈ ℝ³×128 K = (H_in @ W_k) + (H_in @ A_k.T @ B_k.T) V = (H_in @ W_v) + (H_in @ A_v.T @ B_v.T)• 注意力计算:
attn_scores = Q @ K.T / √d_k # d_k=128 → ∈ ℝ³×³ attn_weights = softmax(attn_scores) # ∈ ℝ³×³ attn_output = attn_weights @ V # ∈ ℝ³×1282.2 注意力输出投影(带LoRA)
# 原始权重 W_o ∈ ℝ^{128×896} # LoRA分解:ΔW = B_o @ A_o,A_o ∈ ℝ^{128×8}, B_o ∈ ℝ^{8×896} attn_proj = (attn_output @ W_o) + (attn_output @ A_o.T @ B_o.T) # ∈ ℝ³×8962.3 残差连接
H_mid = H_in + attn_proj # ∈ ℝ³×8962.4 MLP层(带LoRA)
# 门控投影(gate_proj): gate = (H_mid @ W_gate) + (H_mid @ A_gate.T @ B_gate.T) # ∈ ℝ³×4864 # 上投影(up_proj): up = (H_mid @ W_up) + (H_mid @ A_up.T @ B_up.T) # ∈ ℝ³×4864 # 激活与门控: activated = SiLU(gate) * up # ∈ ℝ³×4864 # 下投影(down_proj): down = (activated @ W_down) + (activated @ A_down.T @ B_down.T) # ∈ ℝ³×8962.5 最终输出
H_out = H_mid + down # ∈ ℝ³×896 -
回归头计算
• 取最后一个token的表示:last_hidden = H_out[-1] # ∈ ℝ^896• 回归投影:
y_pred = last_hidden @ W_reg # W_reg ∈ ℝ^{896×1} → y_pred ∈ ℝ
关键矩阵维度表
| 操作阶段 | 核心矩阵 | 维度说明 |
|---|---|---|
| 输入嵌入 | E | (3, 896) |
| 自注意力Q/K/V | Q | (3, 896) |
| K | (3, 128) | |
| V | (3, 128) | |
| 注意力分数矩阵 | attn_scores | (3, 3) |
| 注意力输出 | attn_output | (3, 128) |
| MLP门控投影 | gate | (3, 4864) |
| 最终隐藏状态 | H_out (每层输出) | (3, 896) |
| 回归权重 | W_reg | (896, 1) |
计算过程可视化
输入序列: [tok₁, tok₂, tok₃]
│
▼
嵌入层: (3,896)
│
▼
[Decoder×24]: (3,896) → ... → (3,896)
│
▼
取最后token: (1,896)
│
▼
回归投影: (896,1) → y ∈ ℝ

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)