快速理解强化学习DDPG算法
DDPG结合了策略梯度方法(Policy Gradient)和值函数方法(Value Function),使用深度神经网络(Deep Neural Networks, DNN)来近似策略函数和值函数。在DDPG算法中,有两个主要的神经网络:Actor(策略网络)和Critic(值网络)。Actor网络用于生成当前状态下的动作,Critic网络用于估计当前状态和动作对应的动作值。Critic网络的更
一、引言
强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过与环境交互来学习最佳行为策略。DDPG(Deep Deterministic Policy Gradient)算法是一种基于深度学习的强化学习算法,适用于连续动作空间的问题。DDPG结合了策略梯度方法(Policy Gradient)和值函数方法(Value Function),使用深度神经网络(Deep Neural Networks, DNN)来近似策略函数和值函数。
本文将详细介绍DDPG算法的结构图、算法流程、计算处理过程、主要公式,并给出一个Matlab代码示例和效果图。代码示例将不使用深度学习工具箱,而是使用基本的Matlab函数和自定义神经网络类来实现。
二、DDPG算法结构图
DDPG算法的结构图如下:
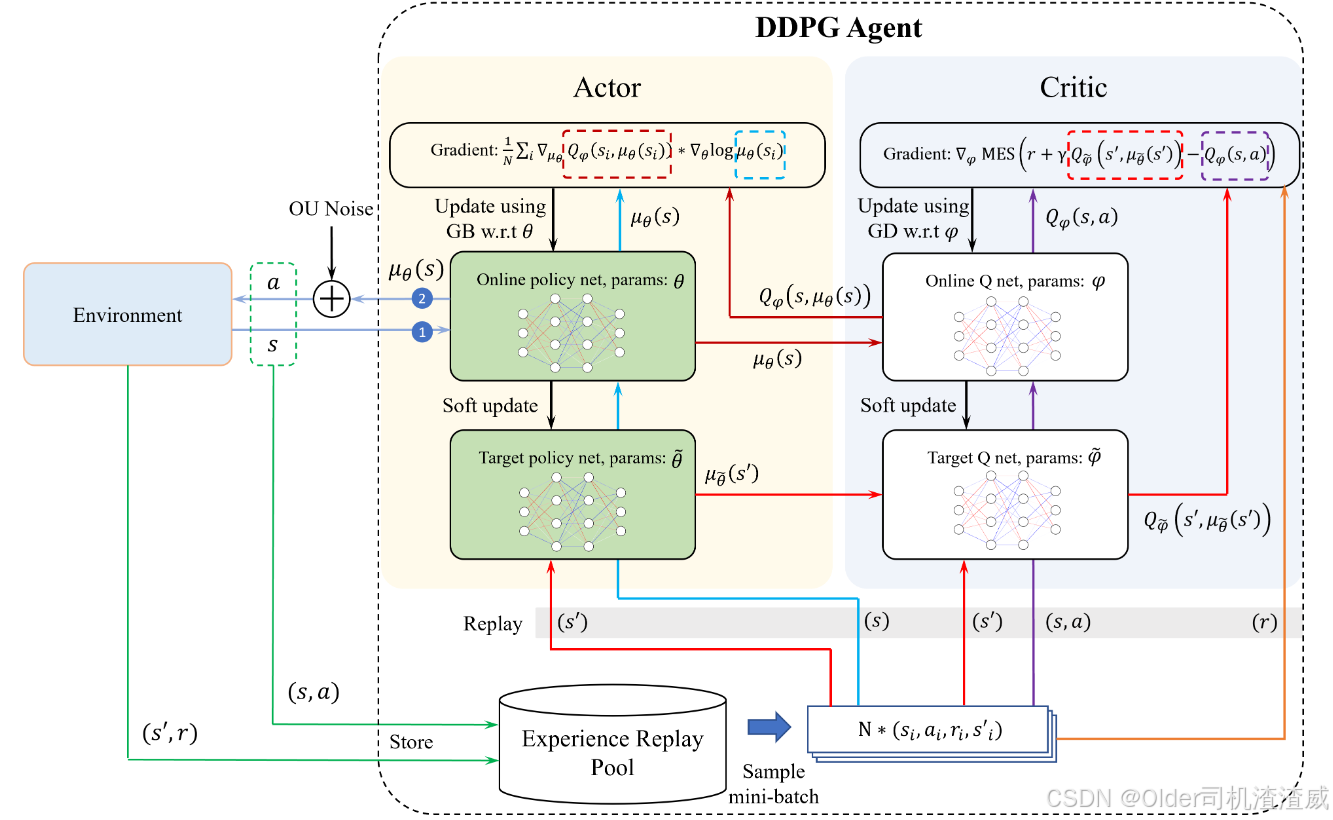
在DDPG算法中,有两个主要的神经网络:Actor(策略网络)和Critic(值网络)。Actor网络用于生成当前状态下的动作,Critic网络用于估计当前状态和动作对应的动作值。经验回放(Experience Replay)用于存储和随机采样过去的经验(状态、动作、奖励、下一状态),以稳定学习过程。目标网络(Target Network)用于生成目标值,以稳定训练过程。
三、DDPG算法流程
DDPG算法的流程如下:
- 初始化Actor网络(策略网络)θQ,以及目标网络θQ'。
- 初始化经验回放缓冲区(Experience Replay Buffer)D。
- 对于每个训练回合(Episode):
a. 初始化环境状态s_0。
b. 对于每个时间步(Time Step)t:
i. 使用Actor网络选择动作a_t = μ(s_t | θ^μ)。
ii. 执行动作a_t,观察奖励r_t和下一状态s_{t+1}。
iii. 将经验(s_t, a_t, r_t, s_{t+1})存储到经验回放缓冲区D中。
iv. 从D中随机采样一批经验(s_i, a_i, r_i, s_{i+1})。
v. 使用目标网络计算目标值y_i = r_i + γ * Q'(s_{i+1}, μ'(s_{i+1} | θQ')。
vi. 使用均方误差(Mean Squared Error, MSE)损失函数更新Critic网络θ^Q。
vii. 使用策略梯度方法更新Actor网络θ^μ。
viii. 定期将Actor网络和Critic网络的参数复制到目标网络θQ'。
c. 直到达到终止条件(如达到最大时间步数或满足某个性能标准)。 - 返回训练好的Actor网络和Critic网络。
四、计算处理过程和主要公式
1. 策略网络(Actor)
策略网络μ(s | θ^μ)用于生成当前状态s下的动作a。它通常是一个多层感知器(Multi-Layer Perceptron, MLP)神经网络。
输出动作a的计算公式为:
a = μ(s | θ^μ)
2. 值网络(Critic)
值网络Q(s, a | θ^Q)用于估计当前状态s和动作a对应的动作值Q。它也是一个多层感知器神经网络。
动作值Q的估计公式为:
Q(s, a | θ^Q)
3. 目标网络(Target Network)
目标网络Q'(s', a' | θμ')用于生成目标值y,以稳定训练过程。目标网络的参数θμ'通常是策略网络和值网络参数的延迟副本。
目标值y的计算公式为:
y = r + γ * Q'(s', μ'(s' | θQ')
4. 经验回放(Experience Replay)
经验回放缓冲区D用于存储过去的经验(s_t, a_t, r_t, s_{t+1})。在训练过程中,从D中随机采样一批经验,用于更新值网络。
5. 策略梯度方法(Policy Gradient Method)
Actor网络的更新使用策略梯度方法,通过最大化期望回报来更新策略参数θ^μ。
策略梯度方法的目标函数为:
J(θ^μ) = ∫π(a | s, θ^μ) * Q(s, a | θ^Q) * d_a
对目标函数求导得到策略梯度:
∇_θμ) = ∇_θμ) * ∇a Q(s, a | θ^Q) |{a=μ(s)}
Actor网络的更新公式为:
θμ + α_μ * ∇_θμ) * ∇a Q(s, a | θ^Q) |{a=μ(s)}
其中,α_μ是学习率。
6. 均方误差(Mean Squared Error, MSE)损失函数
Critic网络的更新使用均方误差损失函数,通过最小化预测值和目标值之间的误差来更新值网络参数θ^Q。均方误差损失函数的公式为:
L(θ^Q) = (1/N) * Σ_i (Q(s_i, a_i | θ^Q) - y_i)^2
Critic网络的更新公式为:
θQ - α_Q * ∇_θQ)
其中,α_Q是学习率,N是批量大小。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)