GraphRAG性能飞跃:结合向量搜索与Agent路由,实现知识图谱复杂问题高效解答
本文介绍了如何在知识图谱增强大模型GraphRAG应用中,通过结合Kuzu数据库的向量检索与LLM驱动的agent路由,实现检索智能化和工作流性能显著提升。包括系统架构、BAML工作流、全流程代码实例和实验评测,适合工程科研和企业探索RAG/Agent智能方案参考。
摘要
本文介绍了如何在知识图谱增强大模型GraphRAG应用中,通过结合Kuzu数据库的向量检索与LLM驱动的agent路由,实现检索智能化和工作流性能显著提升。包括系统架构、BAML工作流、全流程代码实例和实验评测,适合工程科研和企业探索RAG/Agent智能方案参考。

正文
1. 背景与挑战
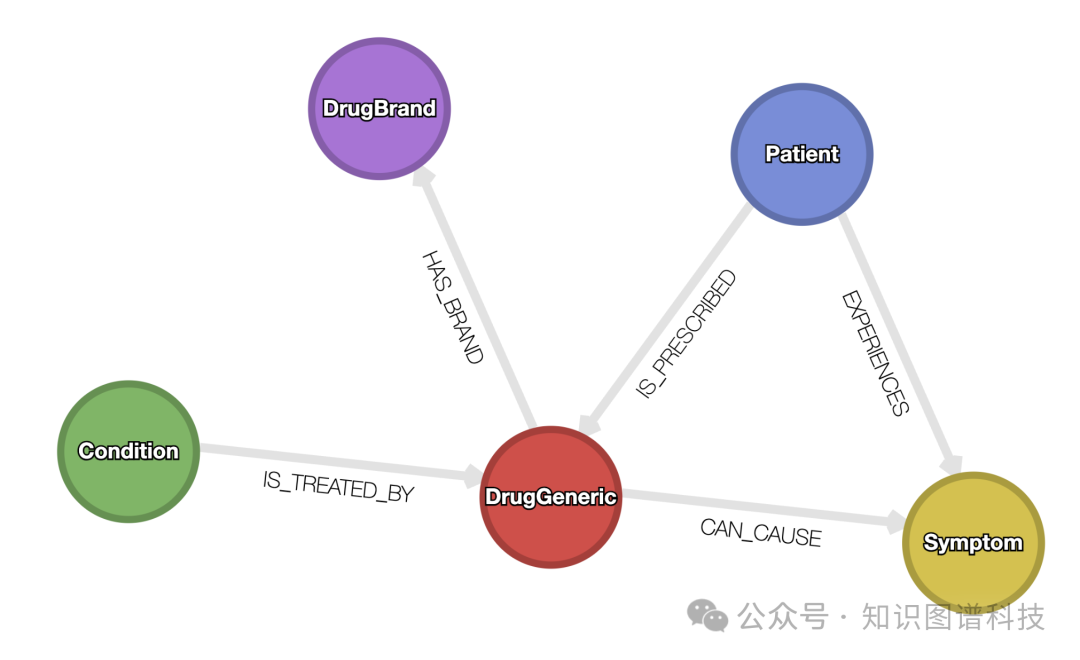
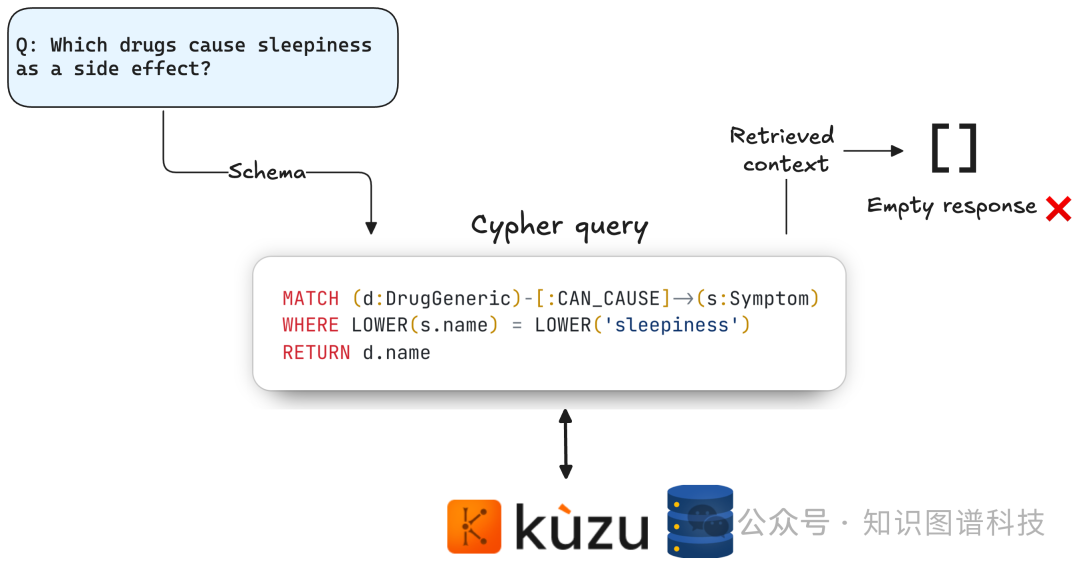
在搭建RAG(Retrieval Augmented Generation)应用时,知识图谱与向量检索的结合极为重要。但很多实践者在用Text2Cypher实现Graph RAG时,会遇到Cypher查询结果为空的困扰:比如用户问“哪些药物的副作用是sleepiness”,而数据库里只有“drowsiness”这个表达,导致精确匹配失效、检索中断,LLM无法生成答案。
2. Agentic Graph RAG的新范式
2.1 Agentic思想
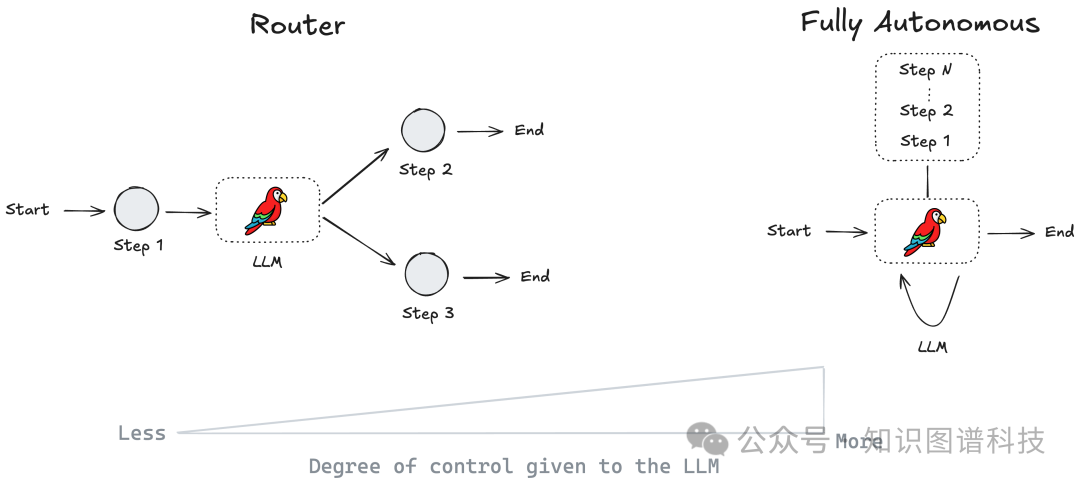
不是“零或一”的全自动,而是不同程度的智能自治,往往同时包含由LLM驱动的智能agent组件和硬编码的可控组件。
Agent定义:LLM负责部分流程的决策(如选择工具和控制分支),而不是所有控制流都靠固定代码。
Agentic系统本质上是“可恢复的”——能自动处理查询失败、检索空结果等异常情境,迭代获得更优答案。
2.2 为什么Graph RAG天然适合Agentic?
-
Text2Cypher LLM把用户问题和图谱结构翻译为Cypher查询,构造检索路径。
-
单次查询严格依赖字符串精确匹配,当实体表述不一致时易失败。
-
Vector Search弥补了Graph RAG的“严格精确匹配”短板,通过语义相似检索改善召回。
3. 系统实现与关键流程
3.1 数据预处理与向量索引
- 采用如sentece-transformers的embedding模型,将图谱节点属性转为embedding,存储于Kuzu的Symptom/Condition节点表。
- 创建向量索引,支持语义“近义词”检索。
示例代码片段(Python, polars, kuzu, sentence-transformers):
python
import kuzu
import polars as pl
from sentence_transformers import SentenceTransformer
db = kuzu.Database("ex_kuzu_db")
conn = kuzu.Connection(db)
model = SentenceTransformer('all-MiniLM-L6-v2')
symptom_ids = conn.execute("""MATCH (s:Symptom) RETURN s.name AS id""").get_as_pl()
symptom_embeddings = model.encode(symptom_ids["id"].to_list()).tolist()
# ...批量写入embedding略
conn.execute("""ALTER TABLE Symptom ADD IF NOT EXISTS symptoms_embedding FLOAT[384];""")
conn.execute("""LOAD FROM symptoms_df MATCH (s:Symptom {name : id}) SET s.symptoms_embedding = symptoms_embedding""")
- 向量查询范例:
python
query_vector = model.encode("sleepiness").tolist()
response = conn.execute(
"""CALL QUERY_VECTOR_INDEX( 'Symptom', 'symptoms_index', \$query_vector, 100 ) RETURN node.name AS symptom, distance ORDER BY distance LIMIT 1""",
{"query_vector": query_vector}
)
# 输出:drowsiness 距离0.199
表1:「sleepiness」相似结果示例
| symptom | distance |
|---|---|
| drowsiness | 0.199042 |
3.2 Agentic Router的核心工作流
-
用户以自然语言提问
-
LLM(BAML Prompt)基于schema生成Cypher查询
-
查询Kuzu数据库
-
- 查询非空,返回结果
- 查询为空,引入Router Agent,通过PickTool自动决定调用哪类工具(向量搜索-症状/疾病/等)
-
Vector Search获取相似实体
-
用新context再走Text2Cypher
-
结果不理想可多轮agent loop(自动重试),保障鲁棒性
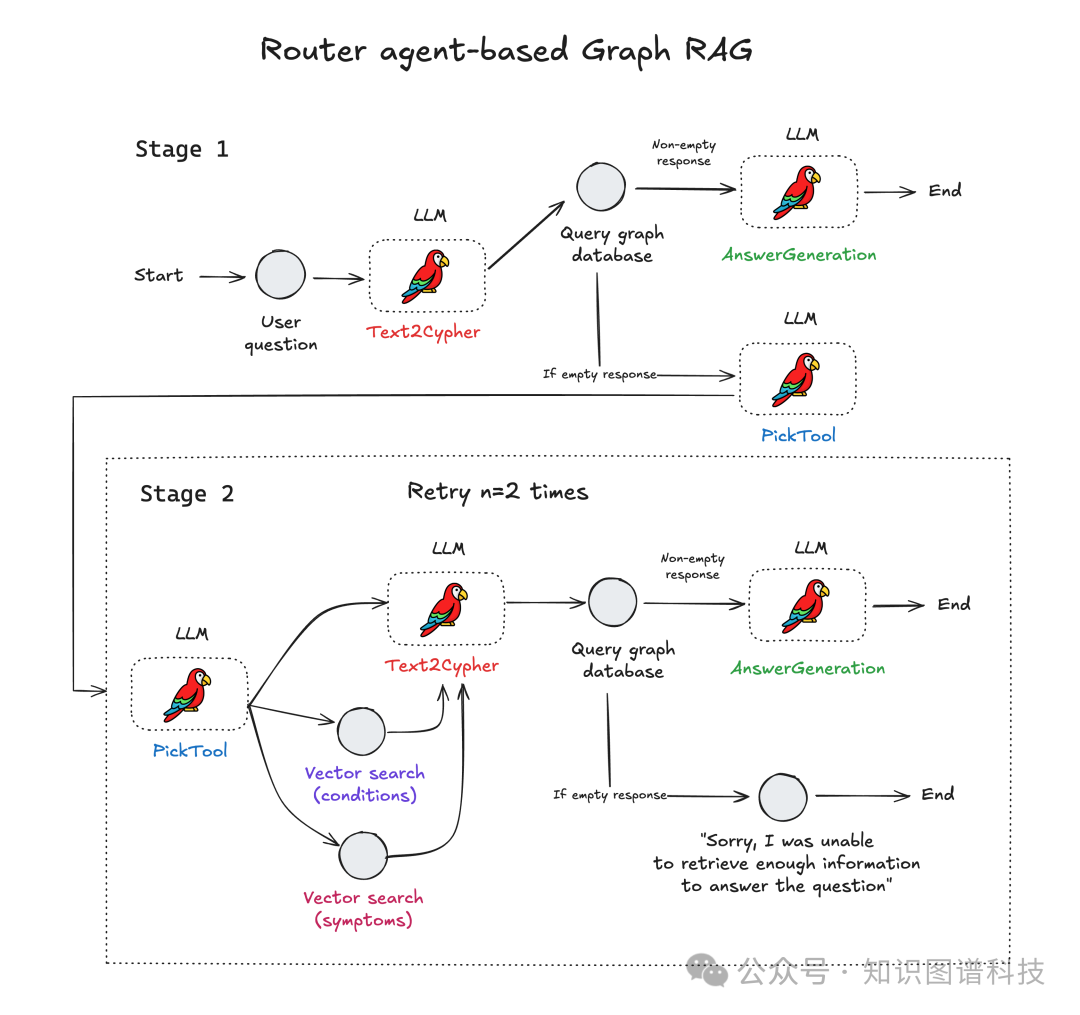
3.3 全流程Agentic Graph RAG系统架构
系统分层:
-
BAML
:结构化Prompt与类型定义,对LLM生成行为约束
-
FastAPI
:将BAML client封装为API端点,供前端/流服务使用
-
Streamlit
:Web用户界面,便于专家终端交互
结构图:
**
**
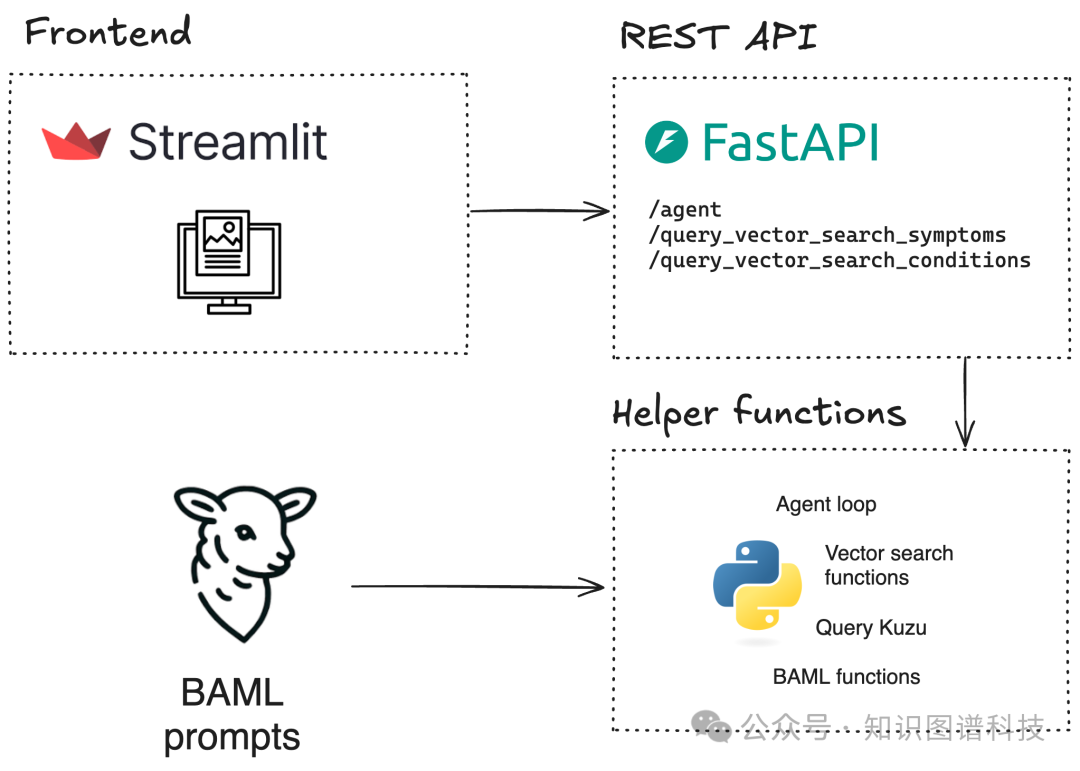
- 前端输入 → 2. FastAPI转发 → 3. 调用BAML/LLM → 4. Agentic router(自动选工具)→ 5. 知识图谱+向量索引 → 6. 回传答案
4. 核心BAML工作流详解
4.1 Text2Cypher
利用BAML自定义函数/类将schema、问题转为Cypher,没有换行,充分利用schema“全路径”表示法,降低LLM理解难度:
baml
classQuery{ cypher string @description("Valid Cypher query with no newlines") }
functionRAGText2Cypher(schema: string, question: string, additional_context: string | null) -> Query{ ... }
"全路径"schema格式更适合LLM解读,兼顾节点-关系-属性一体,关系方向直观且token数更小。
4.2 Router Agent Tool调用
- Tool枚举声明:
baml
enum Tool {
Text2Cypher @description("Translate question to Cypher")
VectorSearchSymptoms @description("Search symptoms or side effects")
VectorSearchConditions @description("Search for a condition")
}
- PickTool prompt让LLM基于上一轮失败自动决策,最大化召回相关语义节点:
5. 整体Agent Loop典型流程
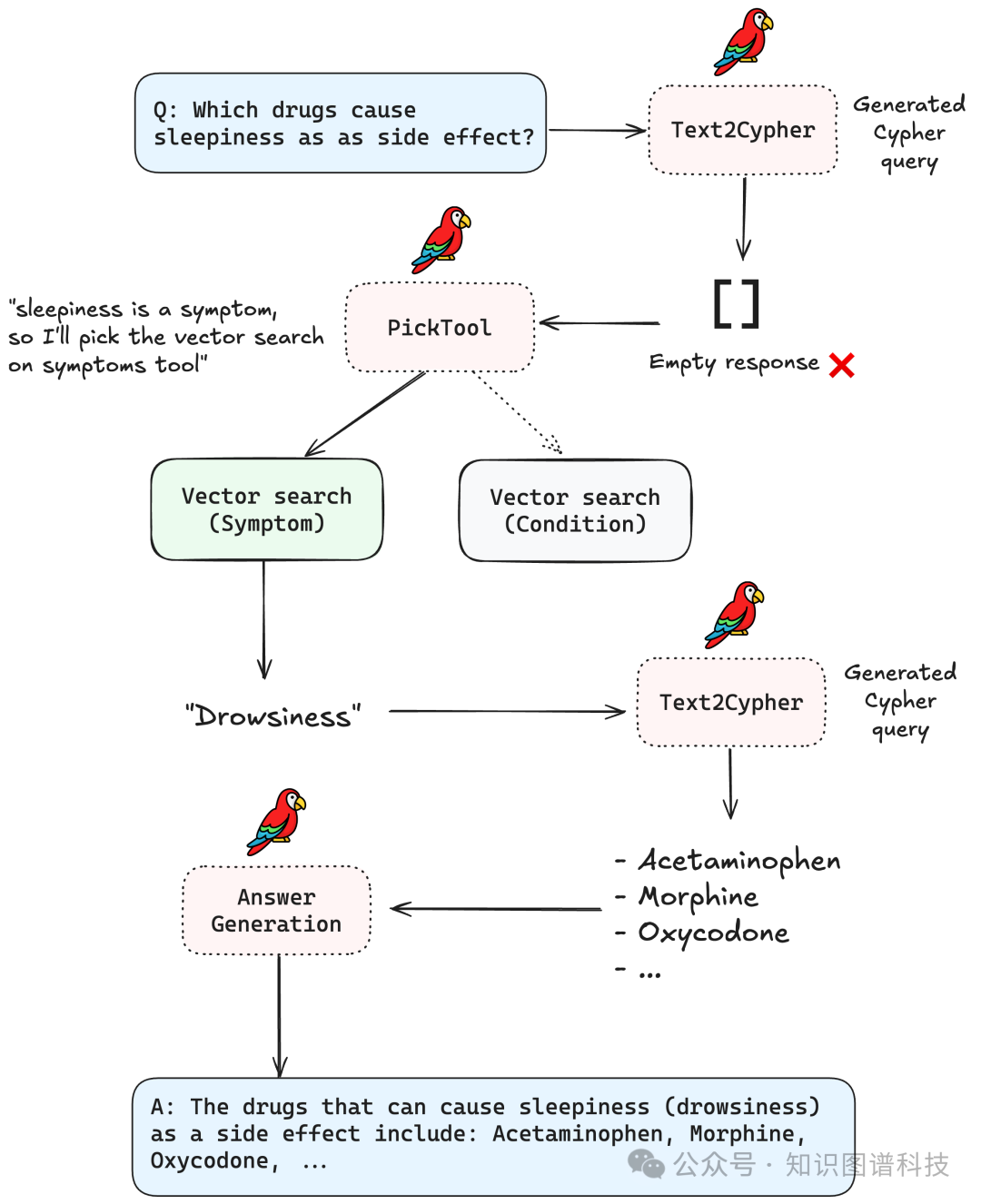
- 用户提问:“哪些药物会导致sleepiness?”
- Text2Cypher生成以“sleepiness”为条件的查询,但库里实际只有“drowsiness”
- 查询结果为空,Router Agent通过语义路由选用VectorSearchSymptoms工具
- 向量搜索召回“drowsiness”→ 再次尝试新Cypher
- 最终返回含有“drowsiness”作为副作用的药物信息
自动补全、语义纠错、无缝多轮循环显著提升复杂问题的命中率与用户体验。
6. 性能评测与对比实验
6.1 用例/测试集
设计10个“路径型问答”覆盖图谱关系、属性推理与模糊召回:
https://github.com/kuzudb/baml-kuzu-demo/tree/main/src/tests
| 问题描述 | 期望答案关键词 |
|---|---|
| Q4: Ambien的副作用有哪些? | drowsiness, dizziness, confusion, headache |
| Q6: 哪些患者因“sleepiness”副作用? | L4D8Z |
| Q7: Vancomycin是否会导致vomiting? | yes |
| … | … |
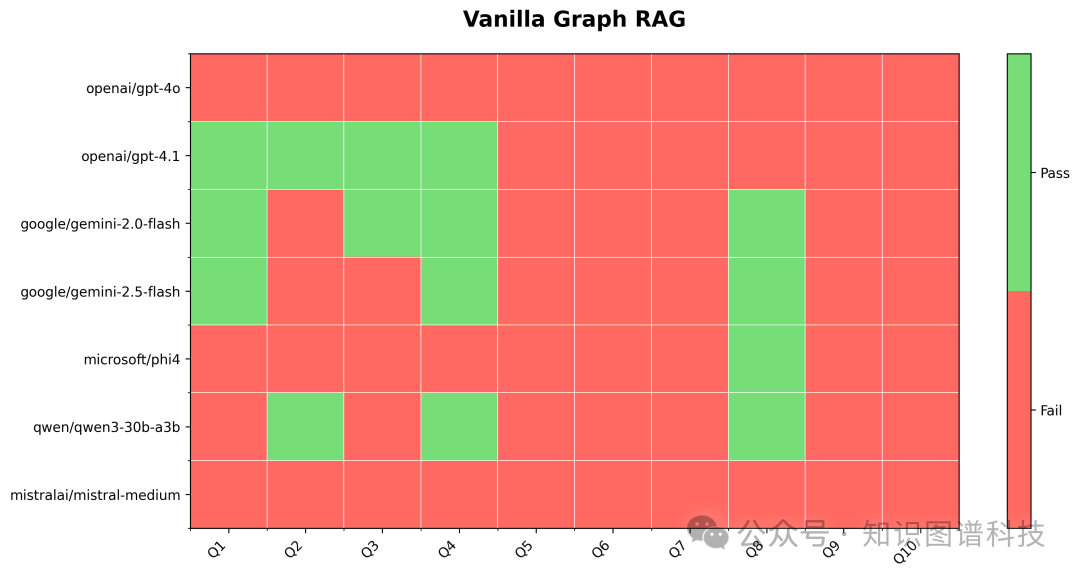
6.2 实验结果(主流LLM对比)
-
Vanilla Graph RAG
-
-
gpt-4.1:10题4题通过
-
gemini-2.0-flash:次优
-
小模型(phi4、qwen3-30b、mistral-medium)效果明显落后
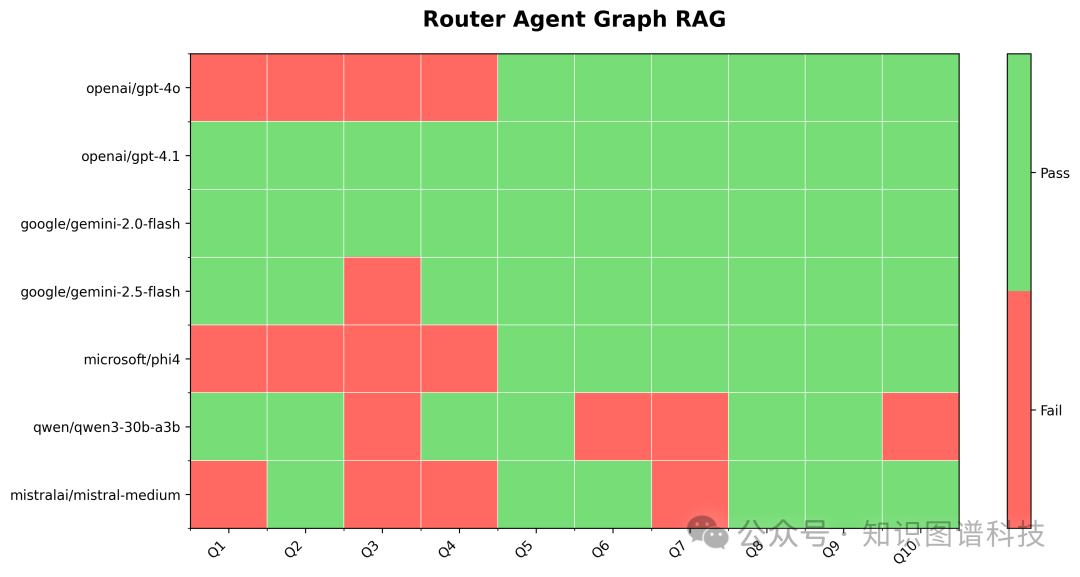
-
-
Agentic Router Graph RAG
(即加入工具调用/自动loop):
-
-
gpt-4.1 & gemini-2.0-flash:全部10题通过
-
gemini-2.5-flash:9题通过(Q3语法错误)
-
其他小模型但得分提升,但仍不稳定
-
错误示例(Cypher语法错误片段):
cypher
MATCH (patient:Patient { patient_id : 'B9P2T' } ) - [: IS_PRESCRIBED { dosage : 'dosage' , frequency : 'frequency' } ] -> (drug:DrugGeneric)
RETURN drug.name, IS_PRESCRIBED.dosage, IS_PRESCRIBED.frequency
6.3 成本估算
| Model | Cost/Query | Queries per $1 |
|---|---|---|
| openai/gpt-4.1 | $0.001 | 1000 |
| google/gemini-2.0-flash | $0.0001 | 10,000 |
| microsoft/phi4 | $0.00003 | 33,333 |
| qwen/qwen3-30b-a3b | $0.002 | 500 |
| mistralai/mistral-medium | $0.0003 | 3,333 |
最新大模型价格下降快, 性能与成本兼顾值得长期关注。
7. 可扩展性与未来展望
- 强Agentic系统需组件化:可插拔“Tool Pool”如混合检索、规划agent、批量分解、多步答案整合。
- MCP(multi-capability protocol)工具成为未来趋势,例如混合向量检索+关键字召回,丰富agent调用。
评价体系与持续测试
- 强调开发多样化测试集,结合主观“评审agent”、人机联合等多维度评测体系
- “Memory”也是关键研究方向,串联对话、上下文、长期用户数据增强agent智能。
8. 结论&开源资源
本文展示了如何通过向量检索及路由agent大幅度优化知识图谱RAG检索能力,业内顶尖LLM(gpt-4.1、gemini-2.0-flash)配合agentic routing显著提高全流程通过率,有效支持现实复杂检索场景。
附:全部开源代码与数据已发布在GitHub,可复现全流程。
步答案整合。
- MCP(multi-capability protocol)工具成为未来趋势,例如混合向量检索+关键字召回,丰富agent调用。
评价体系与持续测试
- 强调开发多样化测试集,结合主观“评审agent”、人机联合等多维度评测体系
- “Memory”也是关键研究方向,串联对话、上下文、长期用户数据增强agent智能。
8. 结论&开源资源
本文展示了如何通过向量检索及路由agent大幅度优化知识图谱RAG检索能力,业内顶尖LLM(gpt-4.1、gemini-2.0-flash)配合agentic routing显著提高全流程通过率,有效支持现实复杂检索场景。
附:全部开源代码与数据已发布在GitHub,可复现全流程。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 27
27 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)