PyTorch深度学习实践(二)
·
笔记来源:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
一、处理多维特征的输入
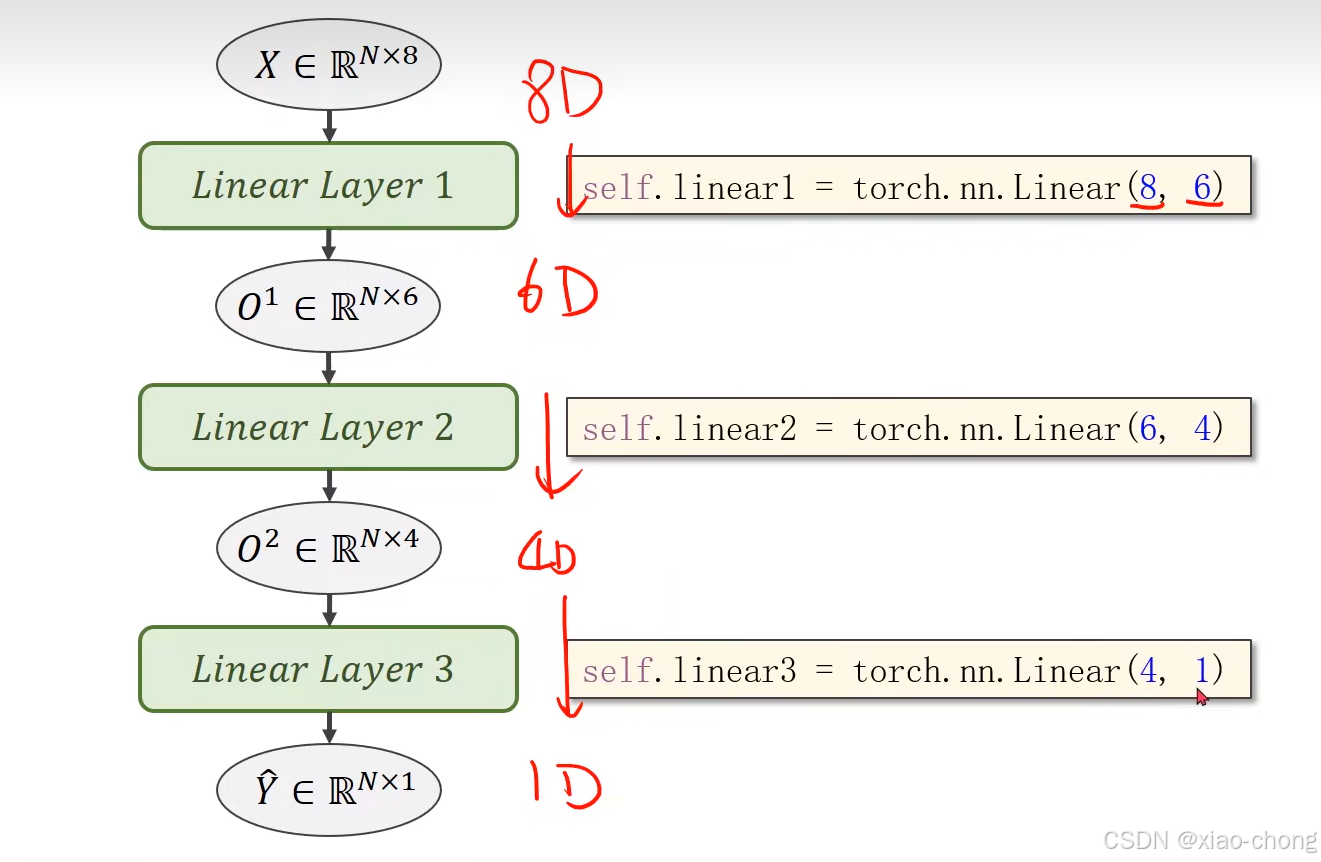

二、加载数据集
torch自带的数据集:
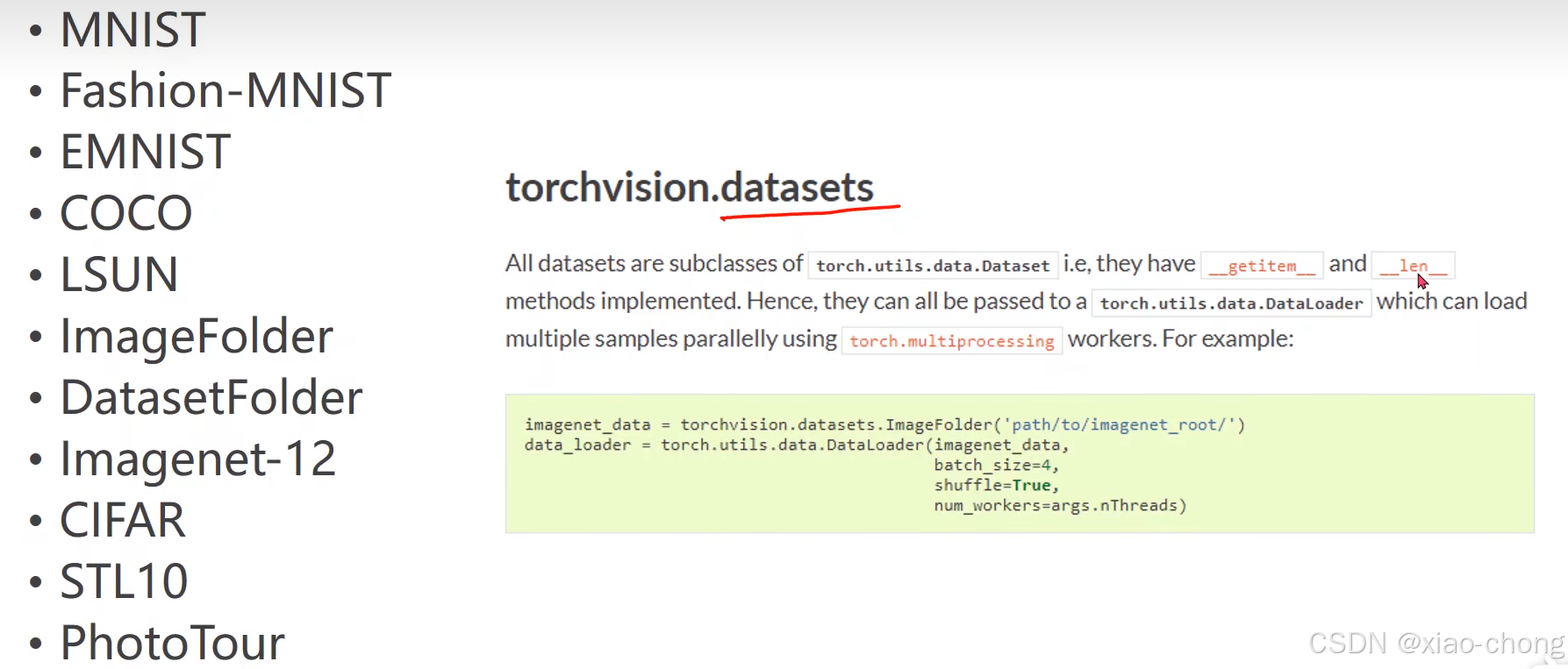
数据集的加载方式:
import numpy as np
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy=np.loadtxt(filepath,delimiter=",",dtype=np.float32)
self.len=xy.shape[0]
self.x_data=torch.from_numpy(xy[:,:-1])
self.y_data=torch.from_numpy(xy[:,[-1]])
def __getitem__(self,index):#该方法可实现数据下标操作,可以通过索引提取数据
return self.x_data[index],self.y_data[index]
def __len__(self):#可以返回数据的条数(整个的数量)
return self.len
dataset= DiabetesDataset("")
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
三、多分类问题
多分类问题用softmax解决。
softmax是怎么实现的呢,实现公式:
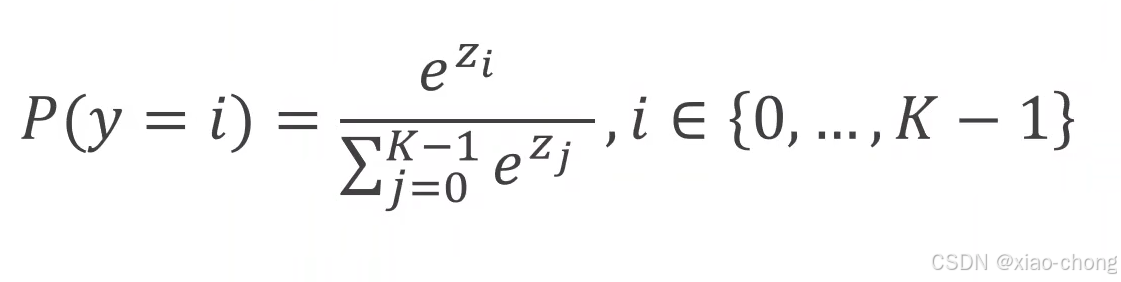
多分类的损失计算:
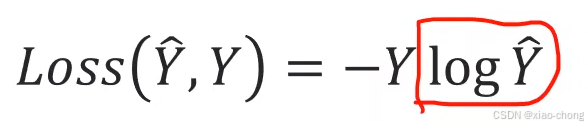
CrossEntropyLoss()中包含Softmax:
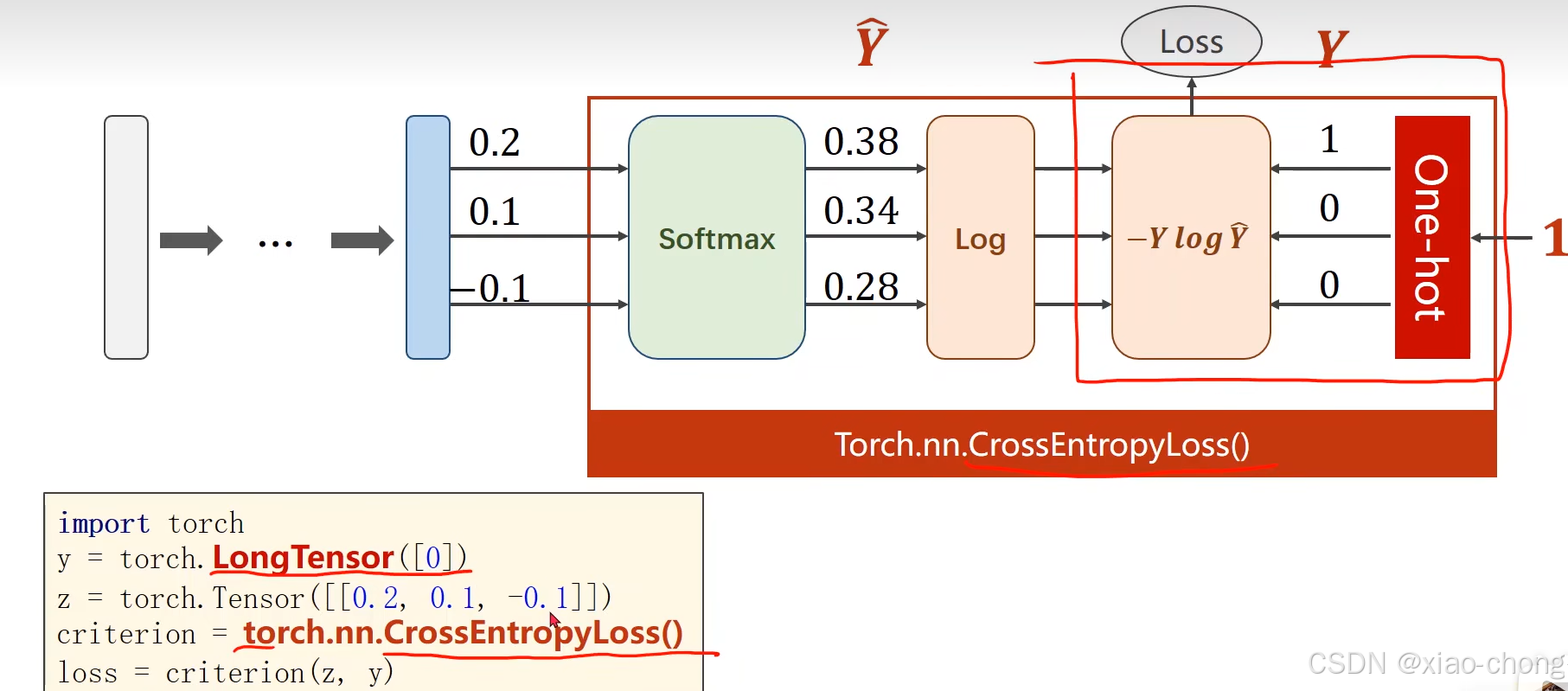
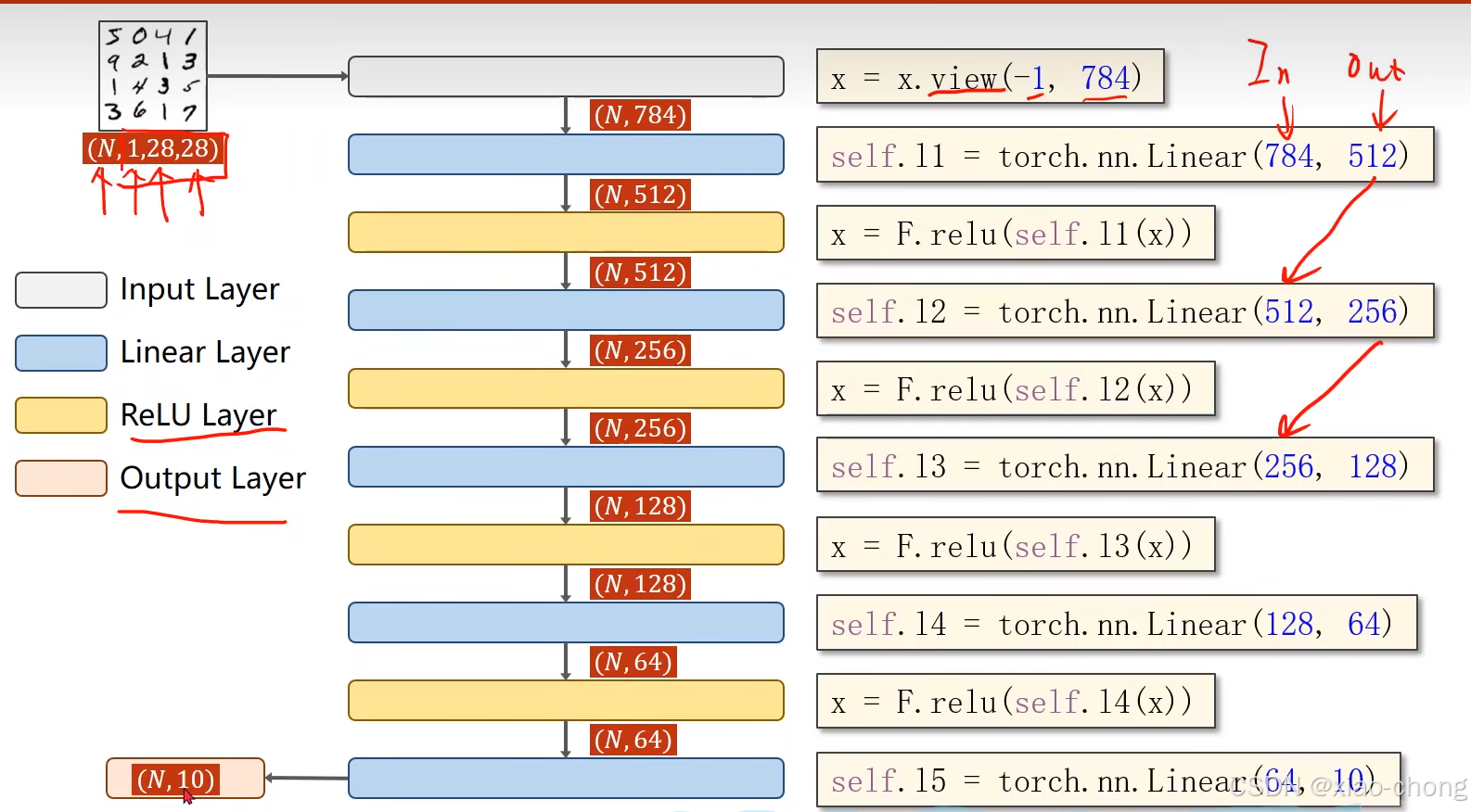
用pytorch解决数字分类问题
四、循环神经网络(基础)
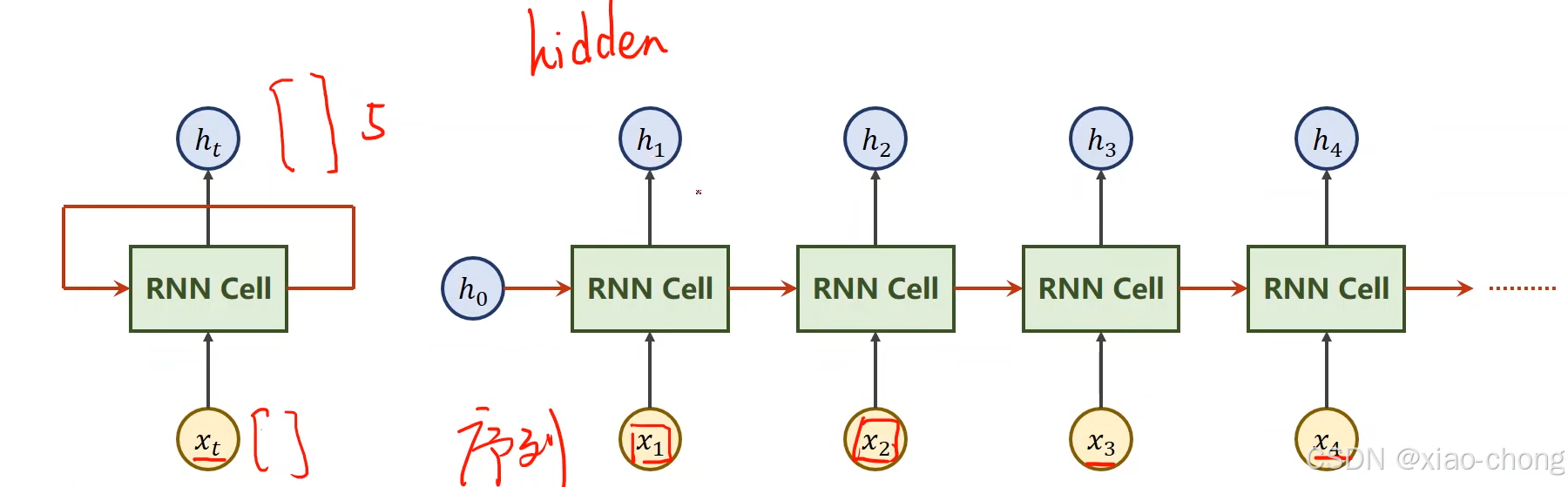
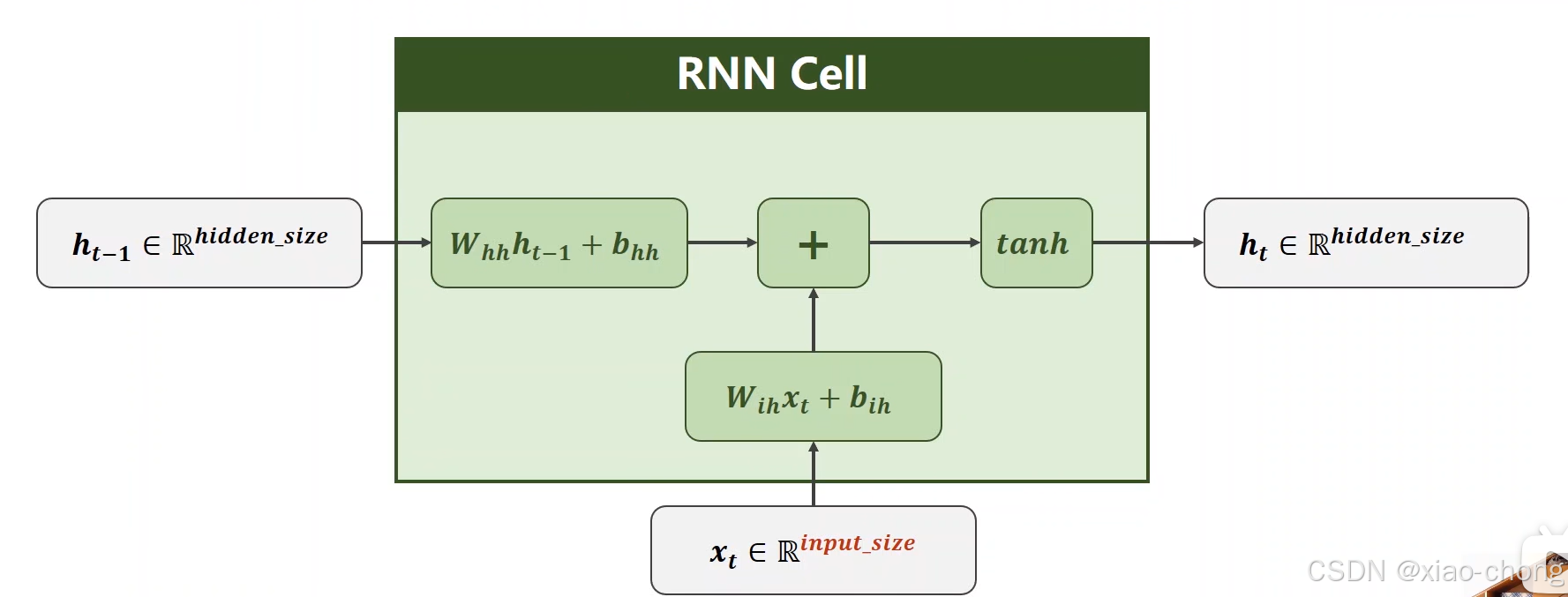
上图中的RNNCell是循环使用的,比较不好想象的可能就是从xt到ht的维度转换,xt的维度是(input_size,1),ht的维度是(hidden_size,1),Wih:(hidden_size,input_size),Whh:(hidden_size,hidden_size)
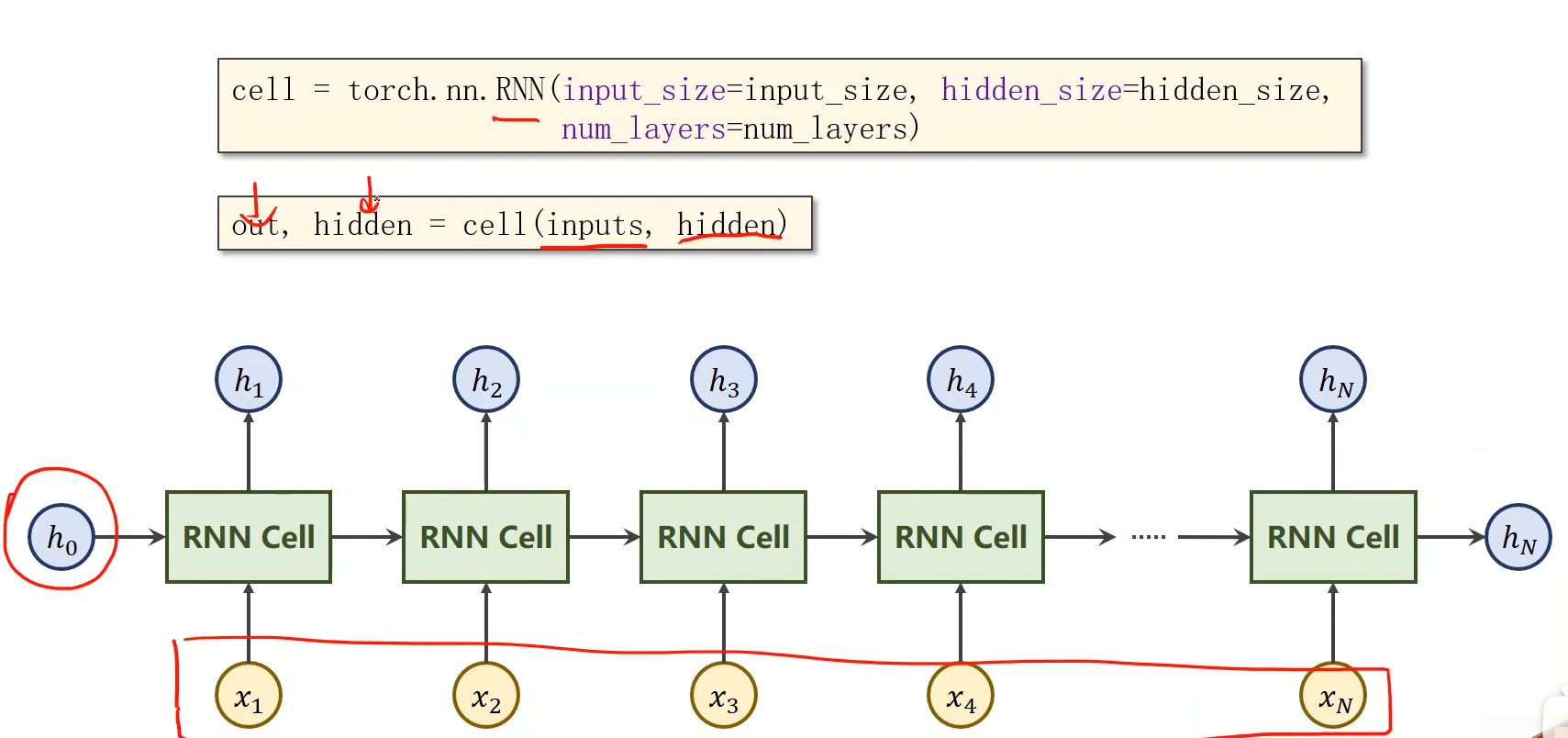
下图为pytorch中RNN的使用方式,cell()中的参数inputs为所有的x,hidden为h0;输出的out为h1-hN,hidden为hN。
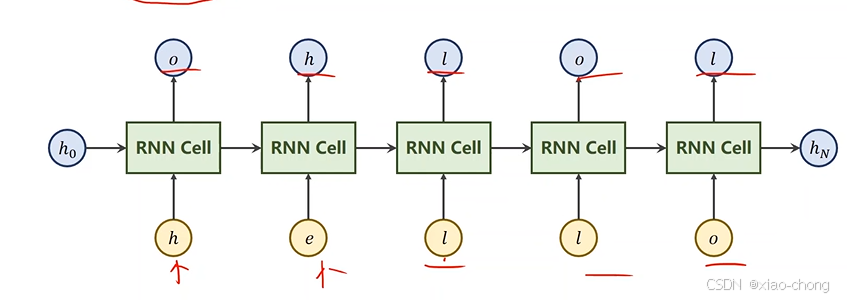
以"hello" -> "ohlol"为例,实践一下:
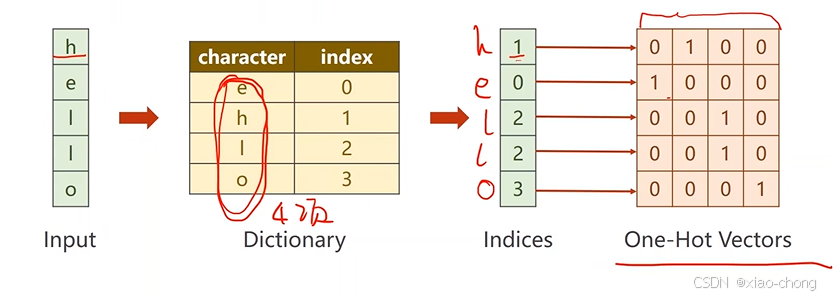
先向量化:
代码:
import torch
input_size=4
hidden_size=4
batch_size=1
idx2char=['e','h','l','o']#字典
x_data=[1,0,2,2,3]
y_data=[3,1,2,3,2]
one_hot_lookup=[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot=[one_hot_lookup[x] for x in x_data]
inputs=torch.Tensor(x_one_hot).view(-1,batch_size,input_size)#view 函数中,-1 表示自动推断该维度的大小,保证张量元素总数不变
labels=torch.LongTensor(y_data).view(-1,1)
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size):
super(Model,self).__init__()
self.batch_size=batch_size
self.input_size=input_size
self.hidden_size=hidden_size
self.rnncell=torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)
def forward(self,input,hidden):
hidden=self.rnncell(input,hidden)
return hidden
def init_hidden(self) :
return torch.zeros(self.batch_size,self.hidden_size)
net=Model(input_size,hidden_size,batch_size)
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(),lr=0.1)
for epoch in range(30):
loss=0
optimizer.zero_grad()
hidden=net.init_hidden()
print('Predicted string:',end='')#end='':取消换行,使后续输出在同一行
for input,label in zip(inputs,labels):
hidden=net(input,hidden)
loss+=criterion(hidden,label)
_,idx=hidden.max(dim=1)
print(idx2char[idx.item()],end='')
loss.backward()
optimizer.step()
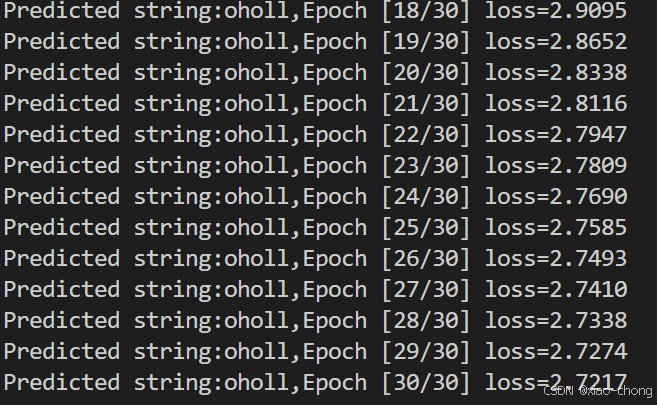
print(',Epoch [%d/30] loss=%.4f'% (epoch+1,loss.item()))循环了30 次的结果:
当数据集比较大的时候,独热向量会维度很高,很稀疏,不利于计算,于是引入了embedding,把 独热向量变得低维,稠密,如下:
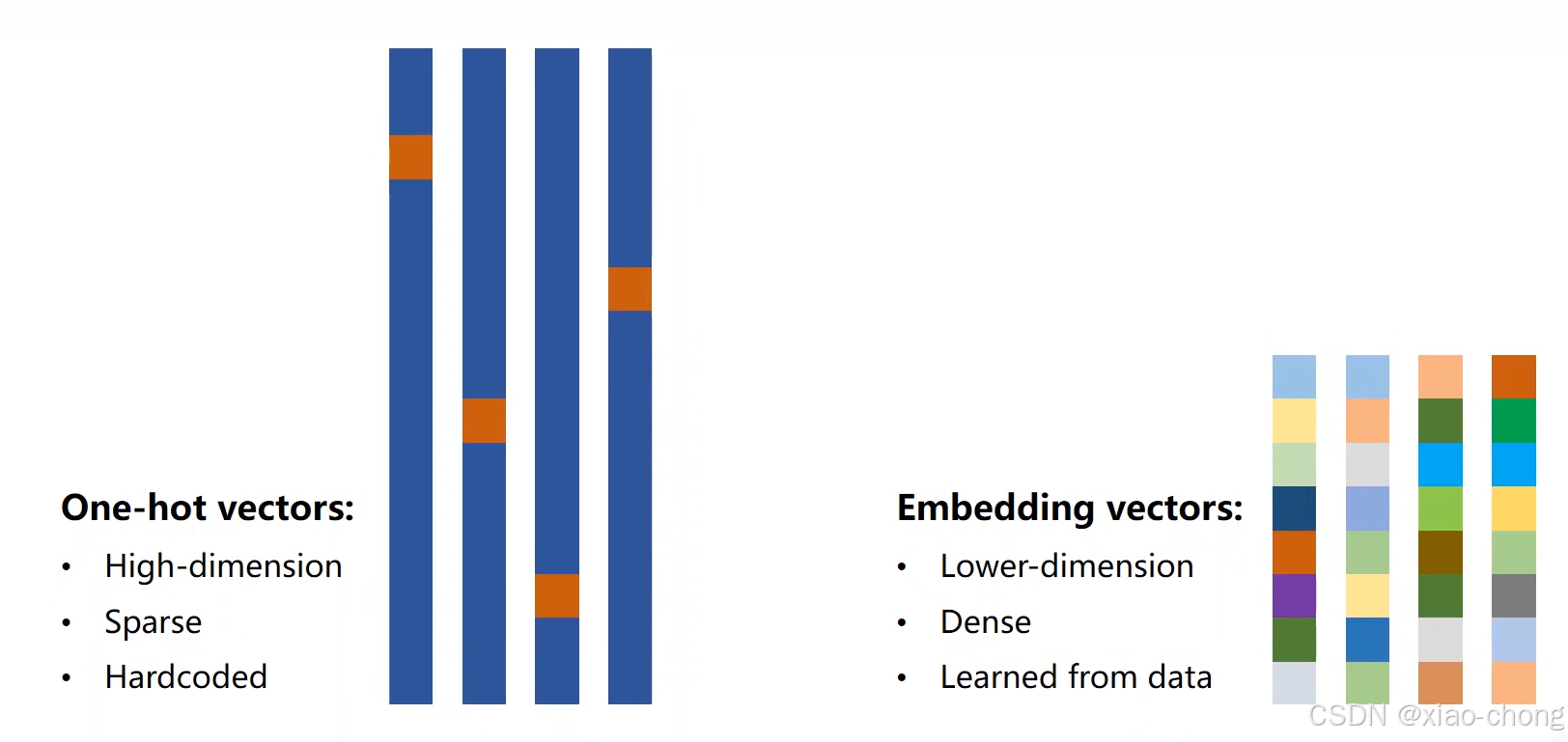
加入embedding后的结果:
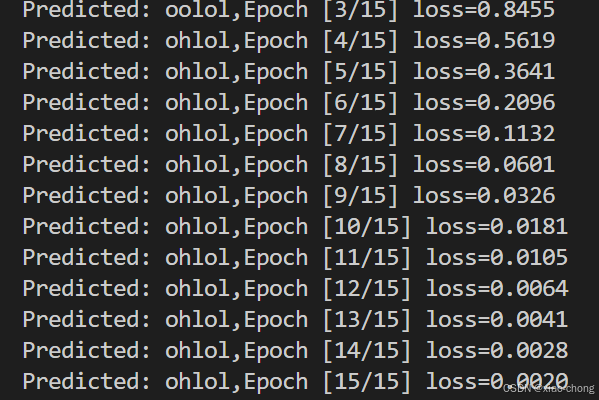
代码:
#比(1)加了词嵌入
import torch
input_size=4
hidden_size=8
batch_size=1
embedding_size=10
num_class=4
seq_len=5
num_layers=2
idx2char=['e','h','l','o']#字典
x_data=[[1,0,2,2,3]]
y_data=[3,1,2,3,2]
inputs=torch.LongTensor(x_data)
labels=torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.emb=torch.nn.Embedding(input_size,embedding_size)
self.rnn=torch.nn.RNN(input_size=embedding_size,hidden_size=hidden_size,num_layers=num_layers,batch_first=True)
self.fc=torch.nn.Linear(hidden_size,num_class)
def forward(self,x):
hidden=torch.zeros(num_layers,x.size(0),hidden_size)
x=self.emb(x)
x,_=self.rnn(x,hidden)
x=self.fc(x)
return x.view(-1,num_class)
net=Model()
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(),lr=0.1)
for epoch in range(15):
optimizer.zero_grad()
outputs=net(inputs)
loss=criterion(outputs,labels)
loss.backward()
optimizer.step()
_,idx=outputs.max(dim=1)
idx=idx.data.numpy()
print('Predicted:',''.join([idx2char[x] for x in idx ]),end='')
print(',Epoch [%d/15] loss=%.4f'% (epoch+1,loss.item()))五、循环神经网络(高级)
这节用循环神经网络实现对不同国家名字的分类。
1.处理数据:

数据长短不一,补齐:
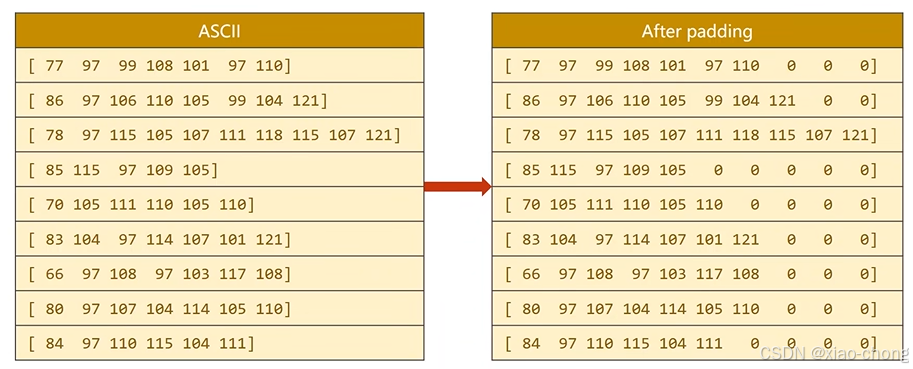
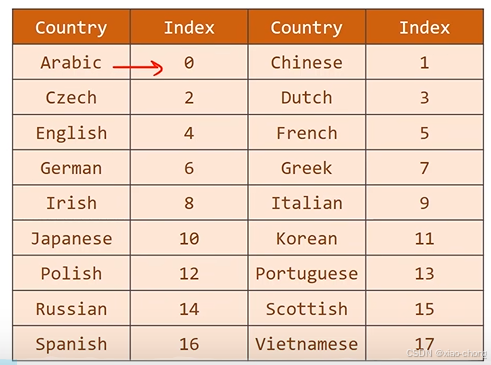
目标数据处理:
Embedding层的输入输出向量的维度:

GRU的输入输出向量的维度:

代码 (没有数据集,只是把整个流程敲了一遍):
import torch
import gzip
import csv
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import time
from torch.nn.utils.rnn import pack_padded_sequence
import math
HIDDEN_SIZE=100
BATCH_SIZE=256
N_LAYER=2
N_EPOCHS=100
N_CHARS=128
USE_GPU=False
class NameDataset(Dataset):
def __init__(self,is_train_set=True):
filename='data/names_train.csv.gz'if is_train_set else 'data/names_test.csv.gz'
with gzip.open(filename,"rt") as f:
reader=csv.reader(f)
rows=list(reader)
self.names=[row[0]for row in rows]
self.len=len(self.names)
self.countries=[row[1]for row in rows]
self.country_list=list(sorted(set(self.countries)))
self.country_dict=self.getCountryDict()
self.country_num=len(self.country_list)
def __getitem__(self,index):
return self.names[index],self.country_dict[self.countries[index]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict=dict()
for idx,country_name in enumerate(self.country_list,0):
country_dict[country_name]=idx
return country_dict
def idx2country(self,index):
return self.country_list[index]
def getCountriesNum(self):
return self.country_num
trainset=NameDataset(is_train_set=True)
trainloader=DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=False)
testset=NameDataset(is_train_set=False)
testloader=DataLoader(testset,batch_size=BATCH_SIZE,shuffle=False)
N_COUNTRY=trainset.getCountriesNum()
def name2list(name):
arr=[ord(c) for c in name]
return arr,len(arr)
def create_tensor(tensor):
if USE_GPU:
device=torch.device("cuda:0")
tensor=tensor.to(device)
return tensor
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassifier,self).__init__()
self.hidden_size=hidden_size
self.n_layers=n_layers
self.n_directions=2 if bidirectional else 1
self.embedding=torch.nn.Embedding(input_size,hidden_size)
self.gru=torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)
self.fc=torch.nn.Linear(hidden_size*self.n_directions,output_size)#全连接层
def _init_hidden(self,batch_size):
hidden=torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden)
def forward(self,input,seq_lengths):
input=input.t()
batch_size=input.size(1)
hidden=self._init_hidden(batch_size)
embedding=self.embedding(input)
gru_input=pack_padded_sequence(embedding,seq_lengths)
output,hidden=self.gru(gru_input,hidden)
if self.n_directions==2:
hidden_cat=torch.cat([hidden[-1],hidden[-2]],dim=1)
else:
hidden_cat=hidden[-1]
fc_output=self.fc(hidden_cat)
return fc_output
#把名字变成张量
def make_tensors(names,countries):
sequences_and_lengths=[name2list(name) for name in names]
name_sequences=[sl[0] for sl in sequences_and_lengths]
seq_lengths=torch.LongTensor(sl[1]for sl in sequences_and_lengths)
countries=countries.long()
seq_tensor=torch.zeros(len(name_sequences),seq_lengths.max()).long()
for idx,(seq,seq_len)in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx,:seq_len]=torch.LongTensor(seq)
seq_lengths,perm_idx=seq_lengths.sort(dim=0,descending=True)
seq_tensor=seq_tensor[perm_idx]
countries=countries[perm_idx]
return create_tensor(seq_tensor),\
create_tensor(seq_lengths),\
create_tensor(countries)
def time_since(since):
s=time.time()-since
m=math.floor(s/60)
s-=m*60
return "%dm %ds"%(m,s)
def trainModel():
total_loss=0
for i,(names,countries)in enumerate(trainloader,1):
inputs,seq_lengths,target=make_tensors(names,countries)
output=classifier(inputs,seq_lengths)
loss=criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss+=loss.item()
if i%10 ==0:
print(f"[{time_since(start)}]Epoch{epoch}",end="")
print(f"[{i*len(inputs)}/{len(trainset)}]",end="")
print(f"loss={total_loss/(i*len(inputs))}",end="")
return total_loss
def testModel():
correct=0
total=len(testset)
print("evaluating trained model...")
with torch.no_grad():
for i,(names,countries) in enumerate(testloader,1):
inputs,seq_lengths,target=make_tensors(names,countries)
output=classifier(inputs,seq_lengths)
pred=output.max(dim=1,keepdim=True)
correct+=pred.eq(target.view_as(pred)).sum().item()
percent='%2f'%(100*correct/total)
print(f"Test set:Accuracy{correct}/{total} {percent}%")
return correct/total
if __name__=="__main__":
classifier=RNNClassifier(N_CHARS,HIDDEN_SIZE,N_COUNTRY,N_LAYER)
if USE_GPU:
device=torch.device("cuda:0")
classifier.to(device)
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(classifier.parameters(),lr=0.001)
start=time.time()
print("Training for %d epochs..."% N_EPOCHS)
acc_list=[]
for epoch in range(1,N_EPOCHS+1):
trainModel()
acc=testModel()
acc_list.append(acc)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)