基于卷积神经网络 (CNN) 的 MNIST 手写数字识别模型
本文介绍了使用PyTorch搭建卷积神经网络(CNN)进行MNIST手写数字识别的完整流程。首先加载MNIST数据集并创建数据加载器,然后定义包含三个卷积块和全连接层的CNN模型结构。通过训练函数实现前向传播、损失计算和反向传播,测试函数评估模型性能。使用交叉熵损失和Adam优化器进行10个epoch的训练,并采用学习率调度器动态调整学习率。最后绘制训练过程中的准确率和损失曲线,展示了CNN在图像
·
目录
简介
之前我们用过深度网络模型进行MNIST 手写数字识别
深度学习之第三课PyTorch( MNIST 手写数字识别神经网络模型)
而现在我们学习过卷积神经网络cnn,我们就用卷积神经网络模型来进行MNIST 手写数字识别
一、搭建卷积神经网络
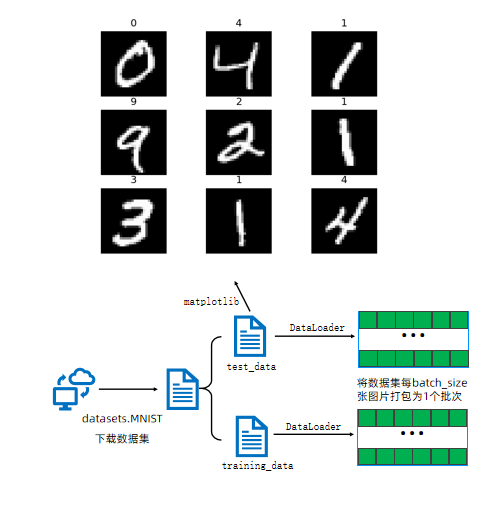
1. 导入必要的库
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensortorch:PyTorch 深度学习框架的核心库nn:神经网络模块,包含各种层和损失函数DataLoader:用于数据加载和批处理datasets:包含常用数据集,这里使用 MNISTToTensor:将图像转换为 PyTorch 张量的转换器
2. 加载 MNIST 数据集
# 下载训练集的图片+标签
training_data = datasets.MNIST(
root='data', # 数据存储路径
train=True, # 加载训练集
download=True, # 如果本地没有则下载
transform=ToTensor(),# 数据转换:将图像转为张量
)
# 下载测试集的图片+标签
test_data = datasets.MNIST(
root='data',
train=False, # 加载测试集
download=True,
transform=ToTensor(),
)MNIST 是一个手写数字数据集,包含 60,000 个训练样本和 10,000 个测试样本,每个样本是 28×28 的灰度图像。
3. 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64) DataLoader用于批量加载数据,支持自动批处理、打乱数据和并行加载等功能,这里设置批次大小为 64。
4. 选择计算设备
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")自动选择可用的计算设备:优先使用 NVIDIA GPU (cuda),其次是 Apple GPU (mps),最后使用 CPU。
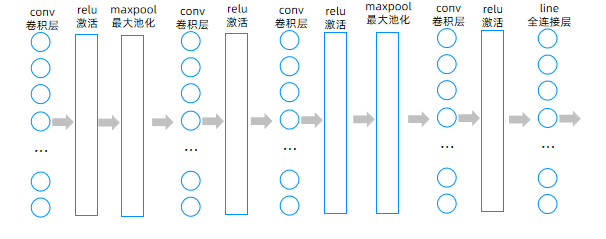
5. 定义 CNN 模型(重点)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 第一个卷积块:卷积+ReLU+池化
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, 5, 1, 2), # 输入通道1,输出通道16,卷积核5×5,步长1,填充2
nn.ReLU(), # ReLU激活函数
nn.MaxPool2d(kernel_size=2) # 最大池化,2×2
)
# 第二个卷积块:两个卷积+ReLU+池化
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2),
)
# 第三个卷积块:卷积+ReLU
self.conv3 = nn.Sequential(
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(),
)
# 全连接层,输出10个类别(0-9)
self.out = nn.Linear(64*7*7, 10)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1) # 展平操作,将特征图转为一维向量
output = self.out(x)
return output模型结构说明:
- 输入是 28×28 的灰度图像
- 通过三个卷积块提取特征,逐步增加通道数 (1→16→32→64)
- 池化操作将特征图尺寸从 28×28→14×14→7×7
- 最后通过全连接层输出 10 个类别的预测结果
6. 初始化模型、
model = CNN().to(device)
print(model)创建模型实例并将其移动到之前选择的计算设备上
7. 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train() # 切换到训练模式
batch_size_num = 1
for X, y in dataloader:
X, y = X.to(device), y.to(device) # 将数据移到计算设备
# 前向传播
pred = model.forward(X)
loss = loss_fn(pred, y) # 计算损失
# 反向传播和参数更新
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
loss = loss.item()
batch_size_num += 1训练过程包括:
- 将模型设为训练模式
- 遍历数据集中的批次
- 执行前向传播计算预测值和损失
- 执行反向传播计算梯度并更新模型参数
8. 定义测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() # 切换到评估模式
test_loss, correct = 0, 0
with torch.no_grad(): # 禁用梯度计算,节省内存和计算资源
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()
# 计算正确预测的数量
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# 计算平均损失和准确率
test_loss /= num_batches
correct /= size
print(f"Test result:\n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f}")测试过程包括:
- 将模型设为评估模式
- 禁用梯度计算以提高效率
- 遍历测试集计算损失和准确率
- 输出测试结果
9. 训练配置
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于分类问题
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# 学习率调度器:每10个epoch将学习率乘以0.5
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)10. 执行训练和测试
epochs = 10 # 训练轮数
acc_s = []
loss_s = []
for t in range(epochs):
print(f"Epoch {t+1}\n-----------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
scheduler.step() # 更新学习率
print("Done!")循环指定的训练轮数,每轮先训练模型,再在测试集上评估性能,并更新学习率。
11. 绘制训练效果曲线
from matplotlib import pyplot as plt
plt.subplots(1, 2, 1)
plt.plot(range(0, epochs), acc_s)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.subplots(1, 2, 2)
plt.plot(range(0, epochs), loss_s)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
print("done!")
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 32
32 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)