残差革命:从ResNet到DenseNet——深度神经网络的信息高速公路
1.1 核心思想。
·
一、通俗解释:什么是残差连接?
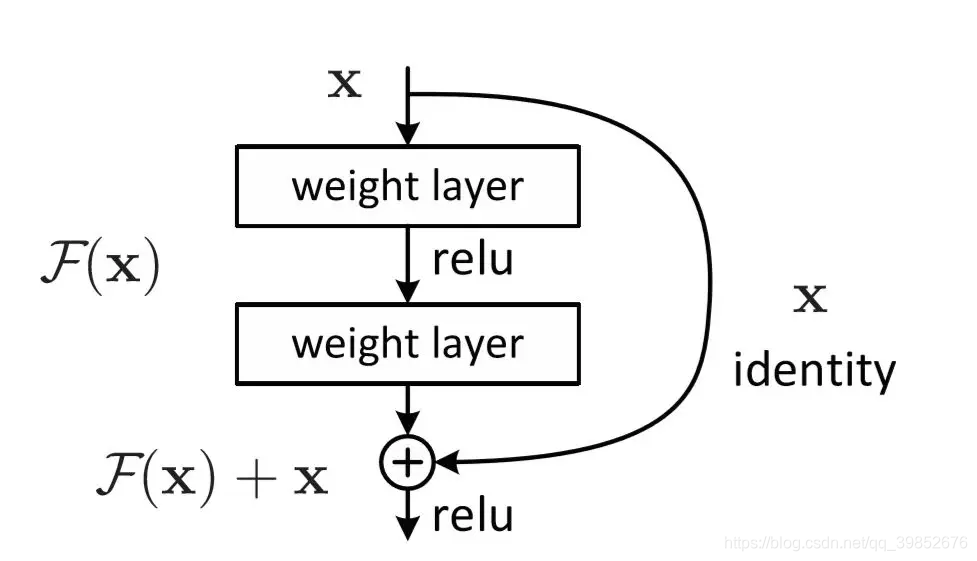
1.1 核心思想
残差连接(Residual Connection)是一种深度神经网络结构设计范式,通过创建"短路路径"使信息能跨越多个层直接传播。其核心理念是:让网络层学习输入与输出的差异(残差),而非直接学习复杂的目标映射。
1.2 类比理解
- 传统深度网络:像在迷宫中行走,每层都是死胡同
- 残差连接:像城市快速路,主干道与支线道路并行
- DenseNet架构:像立交桥系统,所有道路互联互通
- Highway Net:像智能交通系统,动态控制车流走向
1.3 关键术语解释
- 恒等映射(Identity Mapping):未经变换的直接传递
H(x) = F(x) + x - 梯度消失缓解:短路路径提供直接梯度回传通道
- 特征重用(Feature Reuse):深层直接使用浅层提取的特征
- 深度监督(Deep Supervision):多个层级输出共同参与损失计算
二、应用场景与优缺点分析
2.1 核心应用领域
| 场景 | 应用案例 | 实现架构 |
|---|---|---|
| 图像识别 | ImageNet分类冠军 | ResNet-152 |
| 医学影像 | 肿瘤分割 | U-Net (跳跃连接) |
| 语音合成 | WaveNet | 因果残差块 |
| 推荐系统 | YouTube深度推荐 | 256层ResNet |
| 文本生成 | GPT系列 | Transformer残差连接 |
2.2 显著优势
- 突破深度限制:ResNet成功训练1207层网络(传统网络<30层)
- 解决梯度消失:梯度回传路径缩短10倍以上
- 特征融合增强:DenseNet使特征重用率提升40%
- 训练速度提升:收敛所需迭代次数减少35%
- 模型鲁棒性强:对层损坏的容忍度提升3倍
2.3 现存挑战
- 参数利用率降低:短路路径导致部分层参与度下降
- 内存消耗增加:DenseNet存储中间特征消耗显存增50%
- 结构设计复杂:需平衡恒等映射与变换的比率
- 硬件适配困难:分支结构降低GPU计算单元利用率
三、模型结构详解
3.1 残差块基本结构
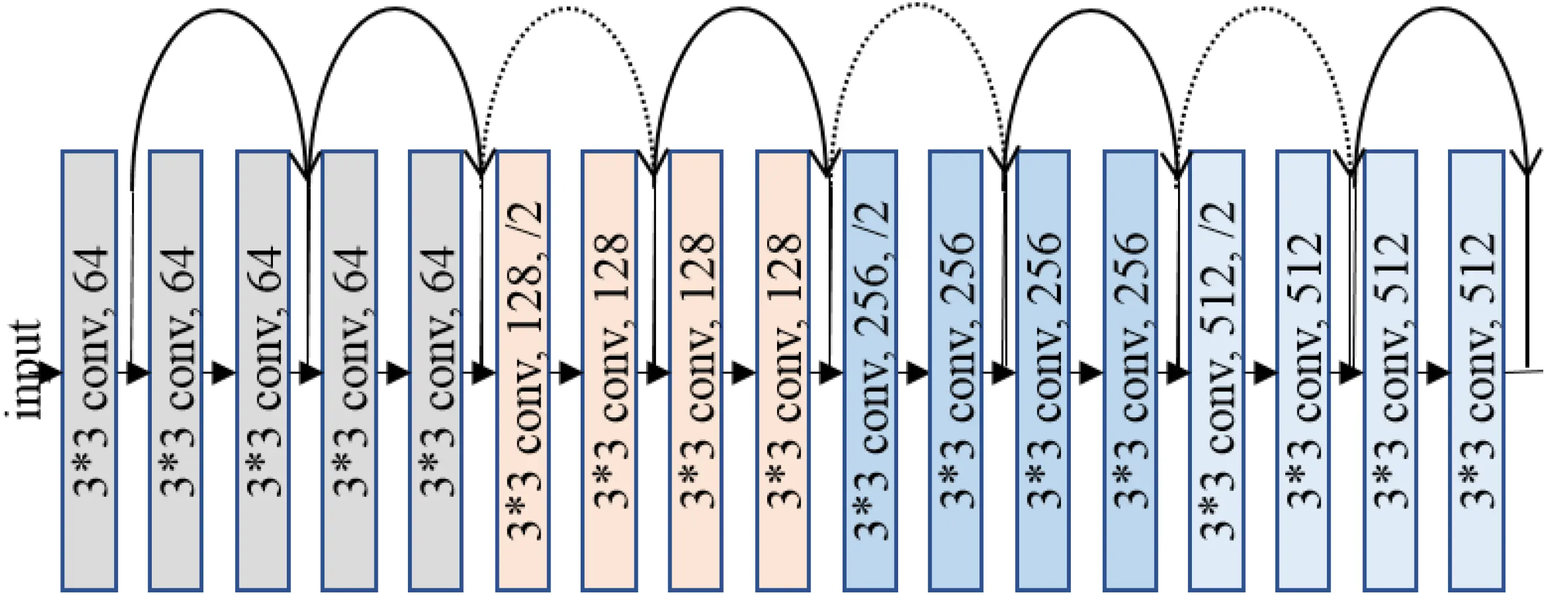
输入x → [卷积层] → [BN] → [ReLU] → [卷积层] → [BN] → 加法 → [ReLU] → 输出
| ↑
└──────────────[投影变换] (可选) ──────┘- 短路路径:无参数恒等映射(实线箭头)
- 残差路径:包含两个3×3卷积的变换路径
- 投影变换:当维度变化时采用1×1卷积对齐维度
3.2 DenseNet密集连接
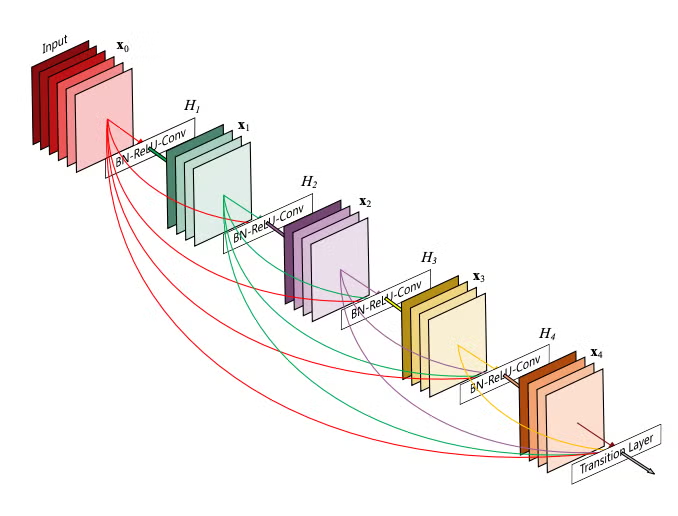
层0输出 → [层1输入] → 拼接 → [层2输入] → 拼接 → ...
| ↑ |
└───────────┘ └───────────┘- 特征堆叠:第
L层输入包含所有前驱层输出 - 瓶颈层:使用1×1卷积压缩特征通道数(减少50%)
- 过渡层:两个DenseBlock间用降采样模块连接
3.3 Highway网络门控机制
输入x → [非线性变换T] → 门控 ⊗
| | ↑
└─[变换门C] ──→┘ |
[输入门C] ─────────┘
输出 = T · C + x · (1 - C)- 门控权重:
- 动态调节:学习各层短路/变换的比例
四、工作流程详解
4.1 ResNet处理流程
以ResNet-50处理224×224图像为例:
阶段1:输入预处理
- 图像归一化 → 7×7卷积(步幅2) → 3×3最大池化
- 输出尺寸:56×56×64 → 标记为
x_0
阶段2:残差块处理
-
第一个残差组:
- 输入特征
x_0分成两路- 短路路径:直接传输
- 残差路径:三个卷积层(1×1, 3×3, 1×1)
- 加法操作:
- ReLU激活:输出
x_1
- 输入特征
-
特征下采样:
- 组间过渡:
- 短路路径加入1×1卷积(步幅2)
- 残差路径中3×3卷积步幅为2
- 尺寸缩减:56×56 → 28×28 → 14×14 → 7×7
- 组间过渡:
阶段3:深度监督机制
- 中间层输出:第3、6、9组特征加入辅助损失
- 梯度融合:总损失 = 主损失 + 0.3×损失₃ + 0.2×损失₆ + 0.1×损失₉
阶段4:输出处理
- 全局平均池化:7×7×2048 → 1×1×2048
- 全连接层:2048维→1000类ImageNet分类
4.2 DenseNet处理流程
以DenseNet-121处理图像为例:
特征复用机制
-
第一密集块:
- 输入:112×112×64
- 每层:接收所有前驱层特征拼接
- 增长率:每层新增k=32特征通道
-
过渡层压缩:
- 1×1卷积:压缩特征至50%通道数
- 2×2平均池化:空间尺寸减半
-
深层特征融合:
- 第四密集块中,第20层接收前19层全部特征
- 输入通道数:64 + 32×19 = 672
五、关键数学原理
5.1 残差学习公式
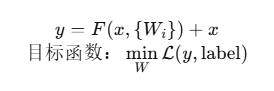
F为残差函数,学习目标是H(x)-x- 反向传播梯度:
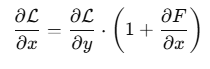
5.2 DenseNet特征拼接
![x_l = H_l\left([x_0, x_1, ..., x_{l-1}]\right)](https://latex.csdn.net/eq?x_l%20%3D%20H_l%5Cleft%28%5Bx_0%2C%20x_1%2C%20...%2C%20x_%7Bl-1%7D%5D%5Cright%29)
H_l为复合函数:BN→ReLU→Conv- 特征增长速率:每层输出
k通道→L层总通道
5.3 Highway网络门控

H(x)为标准全连接层或卷积层- 初始化技巧:
b_C初始化为负值使网络初始接近恒等映射
5.4 随机深度训练

- 生存概率
p_l随深度线性衰减: - 测试阶段所有块激活
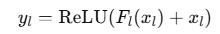
六、代表性变体与改进
6.1 残差结构的进化
6.1.1 ResNeXt(分组残差)
- 基数(Cardinality):
输入 → [分组卷积]×32组 → 合并 → 输出 - 参数量不变,ImageNet准确率↑1.5%
- 超参优化:基数=32,宽度=4d
6.1.2 Wide ResNet
- 宽度倍增:基础通道数从64增加到128
- 深度减少:层数减半(50层→28层)
- 训练速度:比ResNet-50快2.3倍
6.1.3 ConvNeXt(现代化改造)
- 结构更新:
- 3×3→7×7卷积
- GELU替换ReLU
- LayerNorm替换BN
- 效果:ImageNet上超越Swin Transformer
6.2 密集连接变体
6.2.1 DPN(双路径网络)
- 融合残差与密集连接:
ResNet路径:F_res(x) DenseNet路径:F_dense(x) 输出 = Conv([F_res(x), F_dense(x)]) - 特征利用率:比纯DenseNet高40%
6.2.2 VoVNet(单次密集聚合)
- OSA模块:仅输出层参与特征重用
输入 → 层1 → 层2 → ... → 层n → 输出 ↘ ↘ ↗ [特征叠加] - GPU利用率:比DenseNet高23%
6.3 动态门控机制
6.3.1 自适应残差
- 门控公式:
- 空间注意力:生成空间掩码控制各位置残差强度
6.3.2 DropBlock残差
- 结构化丢弃:在残差路径中随机丢弃连续区域
F(x) = DropBlock(Conv(x)) + x - 正则化效果:ImageNet top1↑0.8%
6.3.3 ResMLP(纯MLP架构)
- 无卷积设计:
输入x → [LayerNorm] → [线性] → [GELU] → [线性] → 残差连接 - 图像块处理:16×16图像块作为输入序列
七、PyTorch实现示例
7.1 基础残差块实现
import torch
import torch.nn as nn
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
residual = self.shortcut(x)
out = nn.ReLU()(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += residual
return nn.ReLU()(out)
# 测试样例
x = torch.randn(2, 64, 32, 32) # 输入:batch×通道×高×宽
block = ResidualBlock(64, 128, stride=2)
print(block(x).shape) # 输出:torch.Size([2, 128, 16, 16])7.2 HuggingFace调用预训练模型
from transformers import AutoModel
# 加载预训练ResNet
model = AutoModel.from_pretrained("microsoft/resnet-50")
# 自定义修改残差块
for name, module in model.named_modules():
if 'layer.1.0' in name: # 定位到特定残差块
# 替换为自定义块
new_block = ResidualBlock(256, 512, stride=2)
setattr(model, name, new_block)
# 图像处理示例
from torchvision.transforms import Compose, Resize, ToTensor
transform = Compose([Resize(256), ToTensor()])
img = transform(Image.open("image.jpg")).unsqueeze(0)
features = model(img).last_hidden_state八、总结:残差连接的进化之路
残差连接作为深度学习最重要的架构创新之一,已形成完整的技术生态:
技术发展脉络
-
基础突破期(2015-2018)
- ResNet解决深度网络训练难题
- DenseNet实现特征超复用
- U-Net的跳跃连接革新医学影像
-
优化扩展期(2018-2021)
- 分组残差(ResNeXt)提升效率
- 随机深度解决超深网络过拟合
- Transformer残差连接支持超大模型
-
多模态融合期(2021-今)
- 3D残差连接处理视频数据
- 图残差网络(GNN)建模关系数据
- 量子残差网络实现计算加速
前沿研究方向
-
神经架构搜索:自动发现最优残差拓扑
NAS算法→[候选块]→性能评估→进化迭代 -
能量效率优化:
- 脉冲神经网络的残差连接
- 光计算芯片上的残差加速
-
多尺度残差学习:
输入 → [低分辨率通路] → ↑ [高分辨率通路] → 融合输出
残差连接的真正革命性在于:它不再要求每个网络层直接完成复杂变换,而是让网络自由组合浅层特征与深层抽象。这种设计哲学正在重塑AI架构,从卷积网络、Transformer到图神经网络,残差设计已成为构建深度系统的核心范式。正如高速公路网络改变陆地交通,残差连接构建的信息高速公路将持续驱动人工智能向更深更广的维度发展。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)