基于机器学习的电商评论情感分析系统
本项目开发了一个基于大数据和深度学习的电商评论情感分析系统,采用Django+Vue.js框架实现前后端分离。系统通过PySpark进行数据清洗,结合百度NLP接口实现文本情感分类,并构建LSTM模型预测评分趋势。核心功能包括数据可视化看板、评论管理、实时情感分析和趋势预测。该系统有效解决了海量评论分析难题,为消费者和商家提供决策支持。未来可扩展实时爬虫、多模态分析和个性化推荐功能,进一步提升商业
1. 项目背景
在移动互联网高度发达的今天,电子商务平台(如京东、天猫、亚马逊等)已成为大众消费的主要渠道。海量的商品评论数据中蕴含着极高的商业价值:对于消费者而言,真实的评价是购买决策的重要参考;对于商家而言,分析用户的反馈可以发现产品缺陷、提升服务质量、优化营销策略。
然而,面对成千上万条评论,人工阅读和分析效率极低。因此,开发一套能够自动抓取、清洗、分析并预测电商评论情感趋向的系统具有重要的现实意义。本项目以此为出发点,结合大数据处理技术与深度学习算法,构建了一个端到端的电商评论情感分析系统。
演示视频及代码资料下载:https://www.bilibili.com/video/BV19N6oB2EAr/

配套论文
2. 技术架构
系统采用了典型的“前后端分离”模式,并集成了大数据生态系统与机器学习框架。
- 后端框架:Python Django 2.0
- 前端框架:Vue.js + Element UI
- 数据库:MySQL 5.7
- 大数据处理:
- HDFS:分布式文件系统,用于存储大规模原始数据。
- Hive:数据仓库工具,用于结构化数据的存储与 SQL 查询。
- PySpark:用于大规模数据的清洗、预处理和离线分析。
- 机器学习/NLP:
- 情感分类:实现正向、负向、中性的精准识别。
- 评分预测:基于 Keras/TensorFlow构建 LSTM (长短期记忆网络),对评分趋势进行时间序列预测。
3. 数据库设计
系统核心数据存储在 MySQL 中,进行 ORM 映射。主要表结构包括:
3.1 京东评论数据表 (jdcommentdata)
存储原始抓取的评论详细信息:
commentid: 评论唯一标识evaluationcontent: 评论文本内容ratingdetails: 用户评分(1-5分)industry/brand/model: 商品行业、品牌、型号等元数据evaluationtime: 评价时间
3.2 用户信息表 (yonghu)
管理系统操作员及普通用户:
zhanghao: 登录账号mima: 加密密码xingming: 用户姓名
3.3 预测结果表 (jdcommentdataforecast)
存储 LSTM 模型生成的预测数据,用于前端图表展示。
4. 系统实现核心逻辑
4.1 大数据清洗 (PySpark)
在 [shive_v.py]中,系统通过 PySpark 对原始 CSV 数据进行预处理:
def jdcommentdata_spakr_clear(csvpath):
spark = SparkSession.builder.appName("SentimentAnalysis").getOrCreate()
df = spark.read.csv(csvpath, header=False, inferSchema=True)
# 1. 删除空值
df_cleaned = df.dropna()
# 2. 去除重复行
df_cleaned = df_cleaned.dropDuplicates()
# 3. 格式化时间字段
df_cleaned = df_cleaned.withColumn("evaluationtime", date_format(col("evaluationtime"), 'yyyy-MM-dd HH:mm:ss'))
# 保存结果
df_cleaned.coalesce(1).write.csv('output_dir', mode="overwrite")
4.2 情感分类 (Baidu NLP)
系统通过封装baidubce_api.py 类调用百度云接口:
def sentiment_classify(self, text):
token = self.get_alitoken()
url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?access_token=' + token
# 发送请求并解析返回的情感标签:0(负向), 1(中性), 2(正向)
# ...
4.3 趋势预测 (LSTM)
在 Jdcommentdataforecast_v.py中,构建了 LSTM 神经网络模型:
- 数据处理:使用
MinMaxScaler归一化,将时间序列转化为监督学习数据。 - 模型结构:
- 两层 LSTM 网络(每层 50 个单元)。
- 引入
Dropout(0.2)层防止过拟合。 - 全连接输出层使用
ReLU激活函数。
- 训练配置:使用
Adam优化器,损失函数为mean_squared_error。
5. 系统功能展示
用户管理
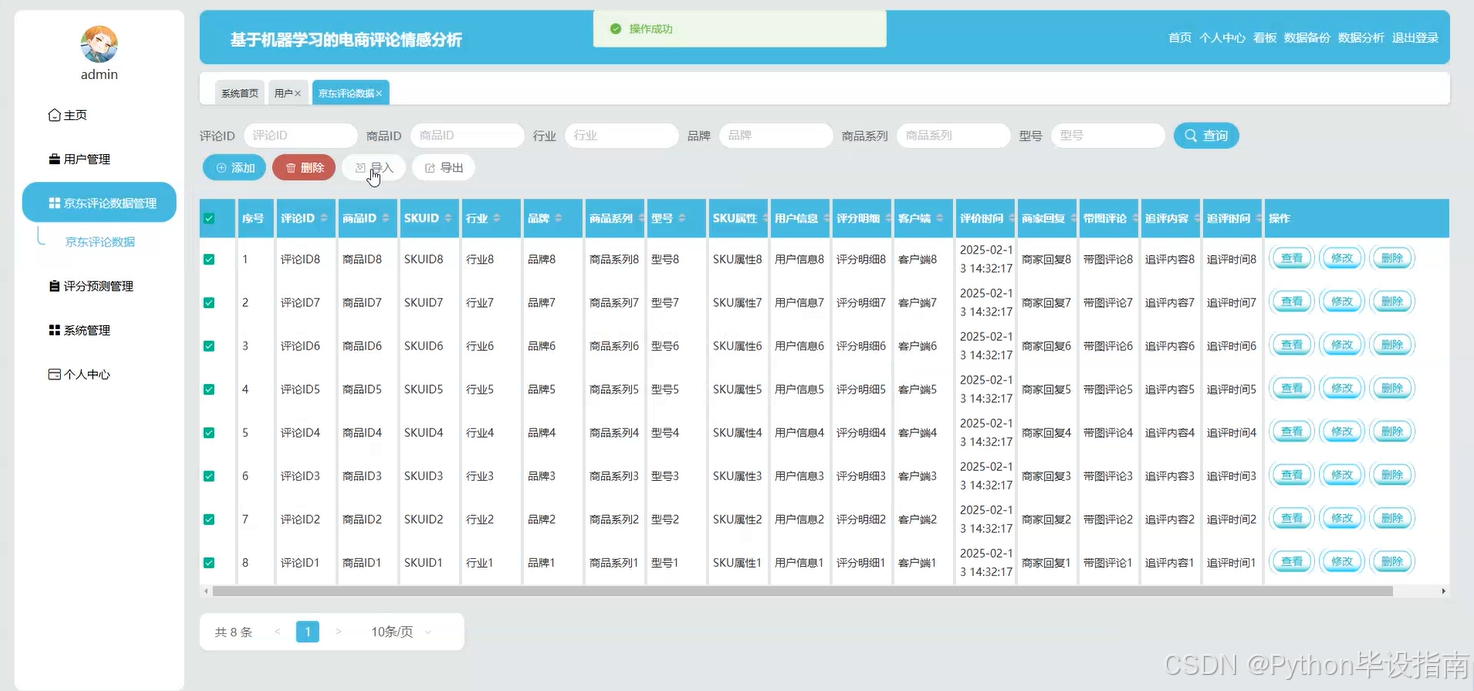
- 评论管理:支持对采集到的评论进行查询、修改及批量删除。
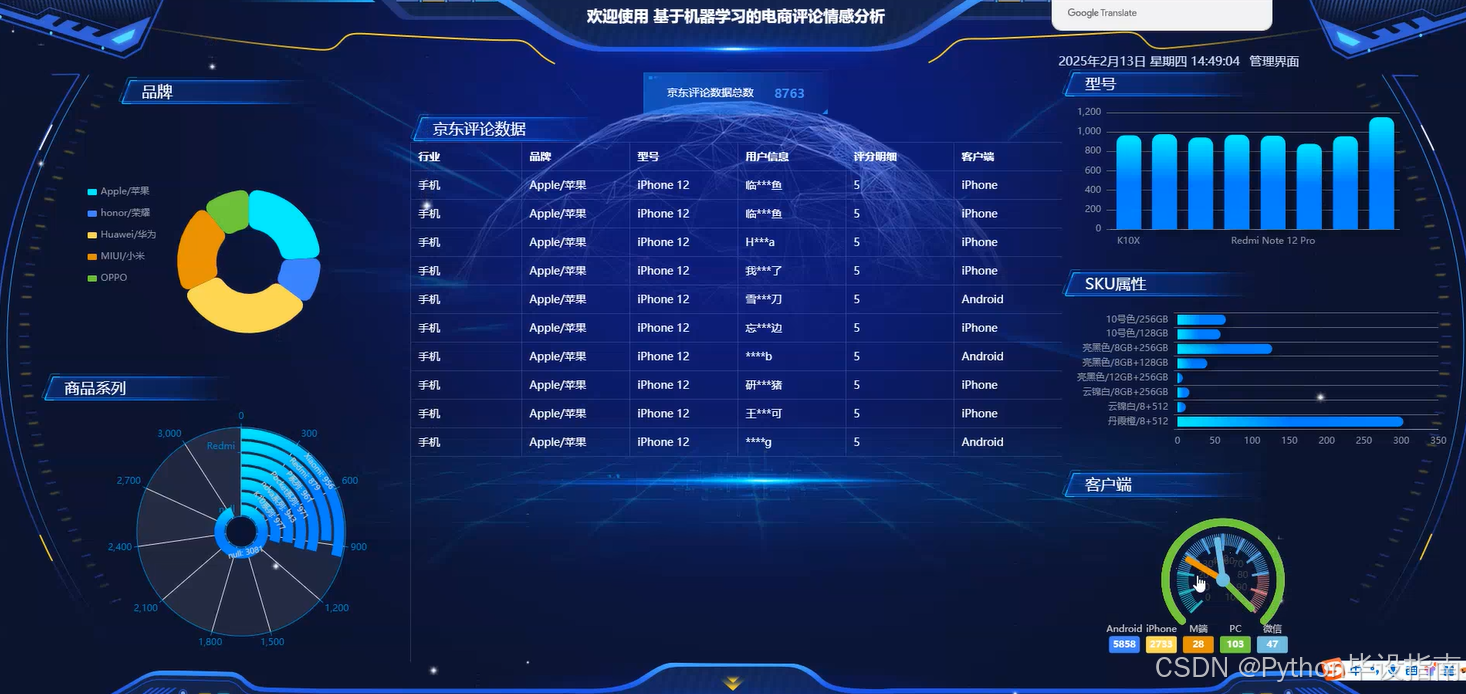
6. 总结与展望
项目总结
本项目成功实现了从数据采集、清洗、存储到深度分析的完整流程。解决了海量评论数据的处理瓶颈,利用 Baidu NLP 保证了语义理解的准确度,结合 LSTM 探索了电商评价的时间序列规律。系统不仅能“看懂”现在的评论,还能“预测”未来的趋势。
未来展望
- 实时抓取:目前数据以离线导入为主,未来可集成 Scrapy-Redis 实现实时分布式爬虫。
- 多模态分析:除了文本评论,未来可加入对用户上传图片的识别与情感分析。
- 个性化推荐:结合情感分析结果,为用户提供更精准的商品推荐服务。
演示视频及代码资料下载:https://www.bilibili.com/video/BV19N6oB2EAr/

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)