Apache IoTDB 流计算框架全解析:从插件开发到任务落地,手把手教你玩转实时数据处理
本文围绕 IoTDB 流计算框架展开全面解析,先介绍核心概念 “Pipe 任务”,其包含抽取(Source)、处理(Process)、发送(Sink)三个子任务,支持 Java 自定义插件逻辑,可通过 SQL 配置实现灵活 ETL。接着详细讲解自定义插件开发,涵盖依赖配置、事件驱动模型(两种核心事件)及三大插件接口实现。还介绍了插件管理(加载、删除、查看)、系统预置插件,以及流处理任务全流程管理(


Apache IoTDB 流计算框架全解析:从插件开发到任务落地,手把手教你玩转实时数据处理
本文围绕 IoTDB 流计算框架展开全面解析,先介绍核心概念 “Pipe 任务”,其包含抽取(Source)、处理(Process)、发送(Sink)三个子任务,支持 Java 自定义插件逻辑,可通过 SQL 配置实现灵活 ETL。接着详细讲解自定义插件开发,涵盖依赖配置、事件驱动模型(两种核心事件)及三大插件接口实现。还介绍了插件管理(加载、删除、查看)、系统预置插件,以及流处理任务全流程管理(创建、启动、停止、删除、查看)与状态迁移,同时提及权限管理和性能配置参数,助力读者从基础到实践,掌握 IoTDB 流计算框架的使用与优化,满足实时数据处理需求。

在物联网场景里,实时数据的处理效率直接影响着业务决策的快慢。而IoTDB作为专为物联网设计的时序数据库,其自带的流处理框架更是解决实时数据ETL需求的关键工具。今天这篇文章,就从基础概念到实际操作,带你全方位吃透IoTDB流计算框架,不管是自定义插件开发,还是任务管理配置,都能让你看完就会用。
一、IoTDB流处理框架基础:什么是Pipe任务?
咱们先从最核心的概念说起——流处理任务,在IoTDB里它有个专属名字叫“Pipe”。一个完整的Pipe任务,其实就是把数据从“源头”拿到,经过“处理”,再送到“目的地”的全过程,具体拆成三个核心子任务:
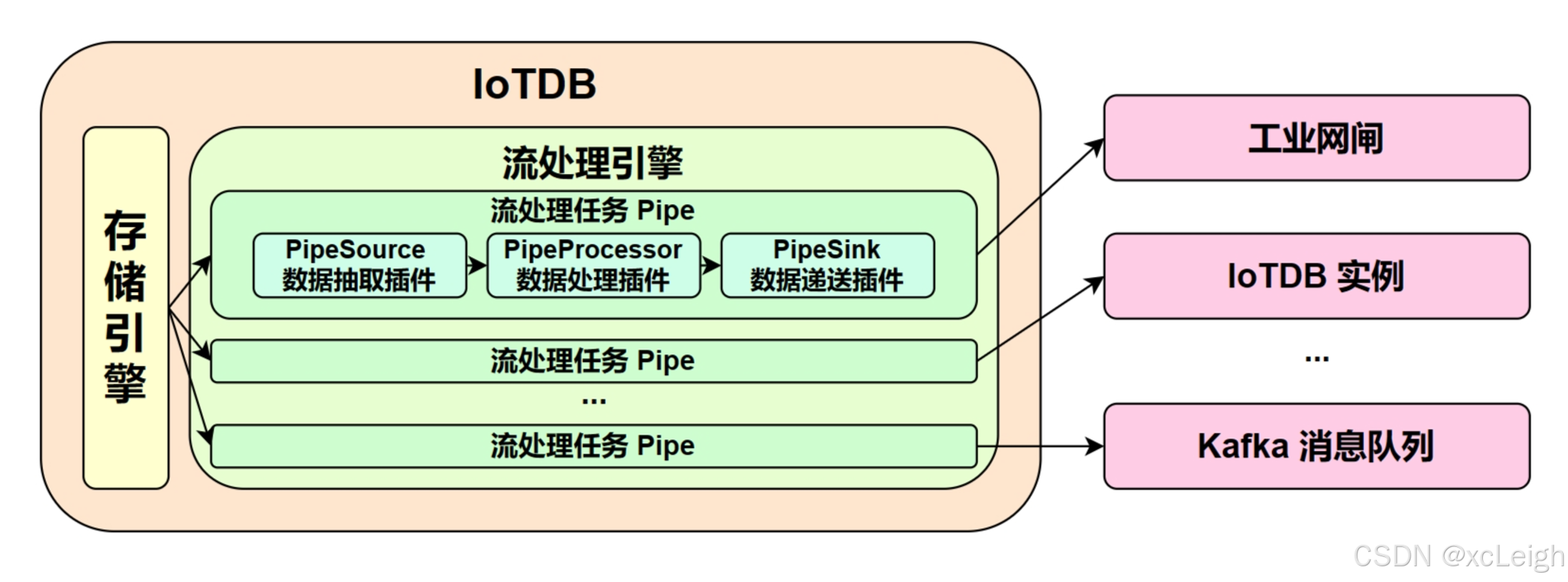
- 抽取(Source):负责从IoTDB存储引擎里把数据“抓”出来,不管是实时写入的数据,还是已经存好的历史数据,都得靠它获取。
- 处理(Process):拿到数据后,想过滤掉无用信息、转换数据格式?这些活儿都交给它,你可以按自己的需求定义处理逻辑。
- 发送(Sink):处理好的数据总不能放在那儿吧?这一步就是把数据推送到外部系统,比如另一个IoTDB实例、Kafka消息队列之类的。
这三个子任务不是孤立的,数据会像流水一样,依次经过Source、Process、Sink三个插件的处理,最后抵达目标系统。而且最灵活的是,你可以用Java语言自定义这三个插件的逻辑,就像写UDF(用户自定义函数)一样,按需调整数据处理的每一步。
想配置一个Pipe任务也很简单,不用写复杂的代码,直接用SQL语句就能声明三个子任务的属性。比如想指定抽哪些数据、怎么处理、发到哪里,一条SQL就能搞定,轻松实现灵活的数据ETL能力。像端边云数据同步、异地灾备、读写负载分库这些常见需求,用这个流处理框架搭条完整的数据链路就能满足。
二、自定义流处理插件开发:从依赖配置到接口实现
如果你想让流处理任务更贴合自己的业务场景,自定义插件是绕不开的一步。下面就从开发前的准备,到具体的接口实现,一步步教你怎么做。
2.1 第一步:准备编程开发依赖
开发插件首先得把依赖搭好,推荐用Maven构建项目,只需要在pom.xml里加一段依赖配置就行。这里要注意一个关键点:依赖的版本必须和你的IoTDB服务器版本保持一致,不然很容易出现兼容性问题。
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>pipe-api</artifactId>
<version>1.3.1</version> <!-- 这里的版本要和你的IoTDB版本对应 -->
<scope>provided</scope>
</dependency>
2.2 理解事件驱动编程模型:两种核心事件要分清
IoTDB流处理插件的编程接口是按事件驱动模型设计的,简单说就是“数据来了就处理”。这里的“事件(Event)”就是数据的抽象表示,你不用管底层是怎么执行的,只需要关注数据来了之后该怎么处理就行。
流处理引擎会先捕获数据库的写入操作,然后把这些操作包装成事件,依次传给Source、Process、Sink三个插件,触发你写的处理逻辑。不过这里有个细节:为了兼顾低负载时的低延迟和高负载时的高吞吐,引擎会在操作日志和数据文件之间动态选处理对象,所以你需要处理两种事件:
1. 操作日志写入事件(TabletInsertionEvent)
它是对用户写入请求的高层抽象,不管你用的是单机部署还是分布式部署,也不管你调用的是InsertRecord、InsertTablet哪种写入接口,它都能给你提供一个统一的操作视图,帮你屏蔽掉底层数据结构的差异——这下不用再纠结不同部署方式、不同写入接口的区别了,编程门槛一下子就降下来了。
比如在单机部署时,它是对写前日志(WAL)条目的封装;在分布式部署时,又变成了对节点共识协议操作日志条目的封装。但对你来说,调用它提供的方法就能操作数据,比如按行处理数据的processRowByRow方法,或者直接处理整个Tablet的processTablet方法。
/** TabletInsertionEvent 用来定义数据插入相关的事件 */
public interface TabletInsertionEvent extends Event {
/**
* 按行处理数据,处理结果通过RowCollector收集
*
* @return 包含处理结果的新TabletInsertionEvent列表
*/
Iterable<TabletInsertionEvent> processRowByRow(BiConsumer<Row, RowCollector> consumer);
/**
* 直接处理整个Tablet,处理结果通过RowCollector收集
*
* @return 包含处理结果的新TabletInsertionEvent列表
*/
Iterable<TabletInsertionEvent> processTablet(BiConsumer<Tablet, RowCollector> consumer);
}
2. 数据文件写入事件(TsFileInsertionEvent)
它是对数据库文件落盘操作的抽象,简单说就是把多个TabletInsertionEvent打包成了一个“文件级”的事件。为什么需要它呢?这得从IoTDB的存储引擎说起——IoTDB用的是LSM结构,数据写入时先落盘到日志文件,同时存在内存里;等内存满了,就会把数据刷成数据库文件(TsFile),还会经过编码压缩和通用压缩两次压缩,文件体积比原始数据小多了。
在某些场景下,传文件比传一条条的操作日志更划算。比如网络不好的时候,传压缩后的TsFile能省不少带宽,速度也更快。当然,凡事都有两面性,处理文件里的数据需要额外的文件I/O操作,这也是要考虑的成本。
那什么时候会遇到TsFileInsertionEvent呢?主要两种情况:
- 历史数据抽取:流处理任务开始前,已经存在的历史数据都是以TsFile形式存储的,所以抽取时会以这个事件呈现。
- 实时数据积压:任务运行时,如果实时处理日志的速度赶不上数据写入速度,没处理的日志会被存成TsFile,之后抽取这些数据就会触发这个事件。
它还有个实用方法toTabletInsertionEvents,能把文件级的事件拆成一个个TabletInsertionEvent,方便你按原来的方式处理数据。
/**
* TsFileInsertionEvent 用来定义TsFile写入相关的事件
* 事件数据存在磁盘上,经过编码和压缩,处理时需要消耗I/O资源
*/
public interface TsFileInsertionEvent extends Event {
/**
* 把TsFileInsertionEvent转换成多个TabletInsertionEvent
*
* @return TabletInsertionEvent列表
*/
Iterable<TabletInsertionEvent> toTabletInsertionEvents();
}
2.3 三大核心插件接口:手把手教你写自定义逻辑
理解了事件模型,接下来就是实现三个核心插件的接口了。不管是Source、Process还是Sink,都有清晰的生命周期和方法定义,跟着步骤来就行。
1. 数据抽取插件(PipeSource):做存储引擎和流引擎的“桥梁”
Source插件的作用很明确:监听存储引擎的行为,把数据写入事件抓出来,传给后面的Processor。它的生命周期和关键方法如下,你按这个流程写逻辑就行:
- 参数校验(validate):任务创建时,会先调用这个方法校验SQL里配置的参数(比如Source的路径前缀、时间范围)是否合法,不合法就抛异常。
- 自定义配置(customize):校验通过后,在任务启动前调用,这里可以解析用户配置的参数,设置运行时的属性(比如线程数、超时时间)。
- 启动插件(start):配置完成后调用,启动监听逻辑,准备捕获事件。
- 提供事件(supply):任务运行中不断被调用,每次返回一个捕获到的事件,传给Processor;如果暂时没数据,返回null就行。
- 关闭插件(close):任务被删除(执行DROP PIPE)时调用,用来释放资源,比如关闭连接、停止线程。
public interface PipeSource extends PipePlugin {
/**
* 校验参数,在customize之前调用
* @param validator 用来校验参数的工具
* @throws Exception 参数不合法时抛异常
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* 自定义配置,在validate之后调用
* @param parameters 解析用户输入的参数
* @param configuration 设置Source的运行属性
* @throws Exception 配置出错时抛异常
*/
void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
throws Exception;
/**
* 启动Source,在customize之后调用
* 启动后,supply方法就能返回事件了
* @throws Exception 启动失败时抛异常
*/
void start() throws Exception;
/**
* 提供事件,在start之后调用
* @return 捕获到的事件,没数据时返回null
* @throws Exception 获取事件出错时抛异常
*/
Event supply() throws Exception;
}
2. 数据处理插件(PipeProcessor):做数据的“过滤器”和“转换器”
Processor插件主要负责过滤(比如只保留某个设备的数据)、转换(比如修改时间格式、计算平均值)事件数据。它的生命周期和方法设计也很清晰:
- 参数校验(validate):和Source类似,校验用户配置的处理参数是否合法。
- 自定义配置(customize):解析参数,设置运行属性,比如过滤条件、转换规则。
- 处理事件(process):任务运行中,会根据事件类型调用对应的process方法:
- 处理TabletInsertionEvent:直接处理单条日志事件。
- 处理TsFileInsertionEvent:默认会把它拆成Tablet事件再处理,你也可以重写这个方法自定义文件处理逻辑。
- 处理通用Event:应对其他类型的事件,比如心跳事件。
处理完的数据通过EventCollector收集,传给Sink。
- 关闭插件(close):释放处理过程中用到的资源。
public interface PipeProcessor extends PipePlugin {
/**
* 校验参数,在customize之前调用
* @param validator 参数校验工具
* @throws Exception 参数不合法时抛异常
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* 自定义配置,在validate之后、处理事件前调用
* @param parameters 解析用户参数
* @param configuration 设置Processor运行属性
* @throws Exception 配置出错时抛异常
*/
void customize(PipeParameters parameters, PipeProcessorRuntimeConfiguration configuration)
throws Exception;
/**
* 处理TabletInsertionEvent
* @param tabletInsertionEvent 要处理的事件
* @param eventCollector 收集处理后的结果事件
* @throws Exception 处理出错时抛异常
*/
void process(TabletInsertionEvent tabletInsertionEvent, EventCollector eventCollector)
throws Exception;
/**
* 处理TsFileInsertionEvent(默认实现)
* 把文件事件拆成Tablet事件,再调用上面的process方法处理
* @param tsFileInsertionEvent 要处理的事件
* @param eventCollector 收集处理后的结果事件
* @throws Exception 处理出错时抛异常
*/
default void process(TsFileInsertionEvent tsFileInsertionEvent, EventCollector eventCollector)
throws Exception {
for (final TabletInsertionEvent tabletInsertionEvent :
tsFileInsertionEvent.toTabletInsertionEvents()) {
process(tabletInsertionEvent, eventCollector);
}
}
/**
* 处理通用Event
* @param event 要处理的事件
* @param eventCollector 收集处理后的结果事件
* @throws Exception 处理出错时抛异常
*/
void process(Event event, EventCollector eventCollector) throws Exception;
}
3. 数据发送插件(PipeSink):做数据的“传送门”
Sink插件是流处理的最后一步,负责把处理好的事件发给外部系统。它支持多种通信协议(比如Thrift、MQTT),关键是要处理好连接管理——毕竟断连了数据可就发不出去了。它的生命周期和核心方法如下:
- 参数校验(validate):校验目标系统的参数(比如IP、端口、账号密码)是否正确。
- 自定义配置(customize):解析参数,设置发送相关的属性(比如超时时间、重试次数)。
- 建立连接(handshake):在customize之后调用,和目标系统建立连接;如果后面心跳检测发现断连了,也会重新调用这个方法重连。
- 心跳检测(heartbeat):任务运行中定期调用,检查和目标系统的连接是否还活着,断连了就抛异常,触发重连。
- 发送事件(transfer):和Processor类似,根据事件类型调用对应的transfer方法,把事件序列化成二进制数据发给目标系统。
- 关闭插件(close):任务删除时调用,关闭连接,释放资源。
public interface PipeSink extends PipePlugin {
/**
* 校验参数,在customize之前调用
* @param validator 参数校验工具
* @throws Exception 参数不合法时抛异常
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* 自定义配置,在validate之后、handshake之前调用
* @param parameters 解析用户参数
* @param configuration 设置Sink运行属性
* @throws Exception 配置出错时抛异常
*/
void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
throws Exception;
/**
* 和目标系统建立连接
* 在customize之后,或者心跳检测失败时调用
* @throws Exception 连接建立失败时抛异常
*/
void handshake() throws Exception;
/**
* 心跳检测,定期调用
* @throws Exception 连接断开时抛异常
*/
void heartbeat() throws Exception;
/**
* 发送TabletInsertionEvent
* @param tabletInsertionEvent 要发送的事件
* @throws PipeConnectionException 连接断开时抛异常
* @throws Exception 发送出错时抛异常
*/
void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
/**
* 发送TsFileInsertionEvent(默认实现)
* 拆成Tablet事件后发送,最后关闭TsFile资源
* @param tsFileInsertionEvent 要发送的事件
* @throws PipeConnectionException 连接断开时抛异常
* @throws Exception 发送出错时抛异常
*/
default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
try {
for (final TabletInsertionEvent tabletInsertionEvent :
tsFileInsertionEvent.toTabletInsertionEvents()) {
transfer(tabletInsertionEvent);
}
} finally {
tsFileInsertionEvent.close();
}
}
/**
* 发送通用Event(比如心跳事件)
* @param event 要发送的事件
* @throws PipeConnectionException 连接断开时抛异常
* @throws Exception 发送出错时抛异常
*/
void transfer(Event event) throws Exception;
}
三、自定义流处理插件管理:加载、删除、查看一步到位
写好自定义插件后,怎么把它放到IoTDB里用呢?别担心,IoTDB提供了专门的SQL语句来管理插件,加载、删除、查看都很方便。
3.1 加载插件:把jar包“装”进IoTDB
首先得把你写的插件类编译打包成jar文件,然后用CREATE PIPEPLUGIN语句把它加载到IoTDB里。语法很简单,关键要填对三个信息:插件的别名(方便后续调用)、全类名(找到插件的具体位置)、jar包的URI(告诉IoTDB从哪下载jar包)。
比如你写了一个全类名为edu.tsinghua.iotdb.pipe.ExampleProcessor的处理插件,jar包放在https://example.com:8080/iotdb/pipe-plugin.jar,想给它起个别名“example”,那SQL就这么写:
CREATE PIPEPLUGIN IF NOT EXISTS example
AS 'edu.tsinghua.iotdb.pipe.ExampleProcessor'
USING URI 'https://example.com:8080/iotdb/pipe-plugin.jar'
这里的IF NOT EXISTS很实用,能避免你重复创建同一个插件导致报错——如果插件已经存在,这条语句就不会执行,省得你先查再创建。
3.2 删除插件:不用了就“卸”下来
如果某个插件不用了,想从系统里删掉,用DROP PIPEPLUGIN语句就行。同样,加上IF EXISTS更稳妥,防止你删一个不存在的插件时出错。比如要删除别名是“example”的插件,SQL是这样的:
DROP PIPEPLUGIN IF EXISTS example
3.3 查看插件:看看系统里有哪些插件
想知道当前IoTDB里加载了哪些插件,一条SHOW PIPEPLUGINS语句就能搞定,执行后会列出所有插件的信息,比如别名、全类名、jar包路径之类的,方便你管理。
四、系统预置的流处理插件:不用自定义也能快速上手
如果你只是想实现简单的流处理需求,比如把数据从一个IoTDB同步到另一个,根本不用自己写插件——IoTDB已经内置了几个常用的插件,直接用就行,省了不少开发时间。
4.1 预置Source插件:iotdb-source
这个插件是专门用来抽取IoTDB内部数据的,不管是历史数据还是实时数据都能抽。它的配置参数很灵活,你可以根据需求调整:
| 参数名 | 说明 | 取值范围 | 是否必填(默认值) |
|---|---|---|---|
| source | 插件标识,必须填“iotdb-source” | String: iotdb-source | 是 |
| source.pattern | 筛选时间序列的路径前缀,只有匹配的路径才会被抽取 | String: 任意时间序列前缀 | 否(默认root) |
| source.history.start-time | 抽取历史数据的开始事件时间(包含该时间) | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 否(默认Long.MIN_VALUE) |
| source.history.end-time | 抽取历史数据的结束事件时间(包含该时间) | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 否(默认Long.MAX_VALUE) |
| start-time(V1.3.1+) | 同步所有数据的开始事件时间(包含该时间),配置后会覆盖上面两个历史时间参数 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 否(默认Long.MIN_VALUE) |
| end-time(V1.3.1+) | 同步所有数据的结束事件时间(包含该时间),配置后会覆盖上面两个历史时间参数 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 否(默认Long.MAX_VALUE) |
这里有几个参数需要特别注意:
- source.pattern的格式:如果路径里有特殊字符(比如@、数字开头),得用反引号包起来,比如
root.a@b、`root.`123。而且当pattern设为“root”时,抽取效率最高,其他格式会稍微影响性能。另外,路径前缀不用是完整路径,比如设为root.aligned.1,那root.aligned.1TS、root.aligned.1TS.1这些路径的数据都会被抽出来,但`root.aligned.`1、root.aligned.123``就不会。 - 时间参数的格式:start-time和end-time得用ISO格式,比如
2011-12-03T10:15:30或者2011-12-03T10:15:30+01:00。 - 事件时间和到达时间:数据有两个关键时间——event time是数据实际产生的时间,arrival time是数据到达IoTDB的时间。iotdb-source抽数据分两个阶段:先抽arrival time小于任务创建时间的历史数据,历史数据抽完了,再抽arrival time大于等于任务创建时间的实时数据,两个阶段是串行的,不用担心数据乱序。
4.2 预置Processor插件:do-nothing-processor
这个插件特别简单,就是“不做任何处理”——把Source传过来的事件原封不动地传给Sink。如果你不需要过滤或转换数据,用它就最合适了,配置也只有一个参数:
| 参数名 | 说明 | 取值范围 | 是否必填(默认值) |
|---|---|---|---|
| processor | 插件标识,必须填“do-nothing-processor” | String: do-nothing-processor | 是 |
4.3 预置Sink插件:do-nothing-sink
和上面的Processor类似,这个Sink插件也什么都不做——收到Processor传过来的事件后,不往任何外部系统发送。它主要用来测试,比如你想验证Source和Processor是否正常工作,就可以用它当Sink,配置也只有一个参数:
| 参数名 | 说明 | 取值范围 | 是否必填(默认值) |
|---|---|---|---|
| sink | 插件标识,必须填“do-nothing-sink” | String: do-nothing-sink | 是 |
五、流处理任务管理:创建、启动、停止全流程操作
插件准备好了,接下来就是创建和管理流处理任务了。IoTDB提供了一套完整的SQL语句,从创建到删除,每个步骤都很清晰。
5.1 创建流处理任务:用CREATE PIPE搭数据链路
创建任务的核心是CREATE PIPE语句,你需要指定任务的唯一ID(PipeId),以及Source、Process、Sink三个插件的配置。咱们举个例子,比如要把root.timecho路径下、2011年到2022年的历史数据,以及之后的实时数据,同步到另一个IoTDB实例(IP:127.0.0.1,端口:6667),SQL可以这么写:
CREATE PIPE iotdb_sync_pipe -- 任务ID,全局唯一
WITH SOURCE (
'source' = 'iotdb-source', -- 用预置的Source插件
'source.pattern' = 'root.timecho', -- 只抽这个路径下的数据
'source.history.start-time' = '2011-12-03T10:15:30+01:00', -- 历史数据开始时间
'source.history.end-time' = '2022-12-03T10:15:30+01:00', -- 历史数据结束时间
)
WITH PROCESSOR (
'processor' = 'do-nothing-processor', -- 不处理数据
)
WITH SINK (
'sink' = 'iotdb-thrift-sink', -- 用Thrift协议发送到另一个IoTDB
'sink.ip' = '127.0.0.1', -- 目标IoTDB的IP
'sink.port' = '6667', -- 目标IoTDB的端口
)
这里有几个关键点要注意:
- 参数的必填性:PipeId是必须填的,而且要全局唯一;Source和Processor是选填的,如果不填,系统会用默认实现(Source默认是iotdb-source,Processor默认是do-nothing-processor);Sink是必填的,必须配置。
- Sink的复用能力:如果两个任务的Sink配置完全一样(所有key和value都相同,不管顺序),系统只会创建一个Sink实例,这样能节省连接资源。比如你创建两个任务,Sink都是
iotdb-thrift-sink,IP和端口也一样,那这两个任务会共用一个Sink实例。 - 避免循环同步:千万别搞出数据循环的场景,比如IoTDB A同步到IoTDB B,IoTDB B又同步回IoTDB A,或者自己同步自己——这样会导致数据无限循环,把系统搞崩。
如果你的需求很简单,比如把全量数据同步到另一个IoTDB,那SQL可以更简洁,不用配置Source和Processor:
CREATE PIPE simple_sync_pipe
WITH SINK (
'sink' = 'iotdb-thrift-sink',
'sink.ip' = '127.0.0.1',
'sink.port' = '6667',
)
这条语句的意思是:把当前IoTDB的全量历史数据和后续实时数据,都同步到127.0.0.1:6667的IoTDB实例上。
5.2 启动流处理任务:用START PIPE让任务跑起来
创建任务后,任务的状态会根据IoTDB版本不同而不同:1.3.0版本创建后是STOPPED状态,不会立刻处理数据;1.3.1及以上版本创建后是RUNNING状态,会直接开始处理。
如果是1.3.0版本,或者你把任务停了之后想重新启动,用START PIPE语句就行,比如启动ID为iotdb_sync_pipe的任务:
START PIPE iotdb_sync_pipe
5.3 停止流处理任务:用STOP PIPE让任务暂停
想让任务暂时停止处理数据,用STOP PIPE语句,比如停止iotdb_sync_pipe任务:
STOP PIPE iotdb_sync_pipe
停止后,任务状态会变成STOPPED,之后想继续处理,再用START PIPE启动就行。
5.4 删除流处理任务:用DROP PIPE彻底删掉任务
如果某个任务不用了,想彻底删除,用DROP PIPE语句。不管任务当前是RUNNING还是STOPPED状态,执行这条语句后,任务都会先停止,然后被删除。比如删除iotdb_sync_pipe任务:
DROP PIPE iotdb_sync_pipe
不用先执行STOP,DROP语句会自动处理停止的步骤。
5.5 查看流处理任务:用SHOW PIPES了解任务状态
想知道系统里有哪些任务,以及每个任务的状态,用SHOW PIPES语句,执行后会返回这样的结果:
| ID | CreationTime | State | PipeSource | PipeProcessor | PipeSink | ExceptionMessage |
|---|---|---|---|---|---|---|
| iotdb-kafka | 2022-03-30T20:58:30.689 | RUNNING | … | … | … | {} |
| iotdb-iotdb | 2022-03-31T12:55:28.129 | STOPPED | … | … | … | TException: … |
结果里会显示任务的ID、创建时间、状态、使用的三个插件,以及异常信息(如果有的话)。
如果只想看某个特定任务的信息,在后面加任务ID就行,比如查看iotdb_sync_pipe的状态:
SHOW PIPE iotdb_sync_pipe
另外,还能查看某个任务的Sink被多少个任务复用了,用WHERE子句过滤,比如查看iotdb_sync_pipe的Sink被哪些任务使用:
SHOW PIPES
WHERE SINK USED BY iotdb_sync_pipe
5.6 流处理任务的状态迁移:了解任务的“一生”
一个任务从创建到删除,会经历三种状态,状态之间的转换也有明确的规则,搞清楚这些能帮你更好地管理任务:
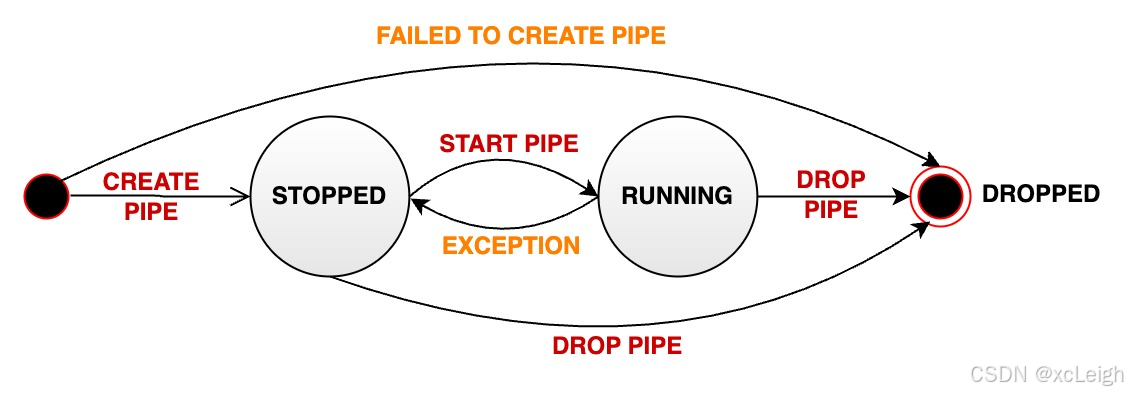
- RUNNING(运行中):任务正常处理数据。1.3.1及以上版本创建任务后,默认就是这个状态;如果任务之前是STOPPED,执行START PIPE后也会变成RUNNING。
- STOPPED(已停止):任务不处理数据。可能的情况有三种:1.3.0版本创建任务后默认是这个状态;用户执行STOP PIPE后会变成这个状态;任务运行中出现无法恢复的错误(比如Sink连接一直断连),也会自动变成这个状态。
- DROPPED(已删除):任务被彻底删除,执行DROP PIPE后会进入这个状态,之后就找不到这个任务了。
六、权限管理:谁能操作流处理任务和插件?
在生产环境里,权限控制很重要——总不能谁都能创建、删除任务吧?IoTDB里,操作流处理任务和插件都需要“USE_PIPE”权限,具体能做什么如下:
6.1 流处理任务相关权限
只要有USE_PIPE权限,就能做这些操作:
- 注册(创建)流处理任务。
- 开启(START)流处理任务。
- 停止(STOP)流处理任务。
- 卸载(DROP)流处理任务。
- 查询(SHOW)流处理任务。
而且这些权限和数据路径无关,有这个权限就能操作所有任务。
6.2 流处理插件相关权限
同样,有USE_PIPE权限就能操作插件:
- 注册(CREATE)流处理插件。
- 卸载(DROP)流处理插件。
- 查询(SHOW)流处理插件。
七、配置参数:调整流处理框架的运行性能
在IoTDB的配置文件iotdb-system.properties里,有一些和流处理相关的参数,你可以根据服务器的硬件配置和业务需求调整,优化流处理的性能。不同版本的参数略有不同,这里分别列出来:
7.1 V1.3.0版本的配置参数
####################
### Pipe Configuration
####################
# 配置插件的存放目录,Windows和Linux路径格式不一样
# Windows平台:如果路径以驱动器号+“\\”开头,或者以“\\\\”开头,就是绝对路径,否则是相对路径
# pipe_lib_dir=ext\\pipe
# Linux平台:如果路径以“/”开头,就是绝对路径,否则是相对路径
# pipe_lib_dir=ext/pipe
# PipeSubtaskExecutor能使用的最大线程数,实际线程数会取这个值和“CPU核心数/2”中的较小值
# pipe_subtask_executor_max_thread_num=5
# Thrift客户端的连接超时时间(毫秒)
# pipe_connector_timeout_ms=900000
# 异步连接器能使用的最大选择器数量
# pipe_async_connector_selector_number=1
# 异步连接器的核心客户端数量
# pipe_async_connector_core_client_number=8
# 异步连接器的最大客户端数量
# pipe_async_connector_max_client_number=16
7.2 V1.3.1+版本的配置参数
####################
### Pipe Configuration
####################
# 插件存放目录,和V1.3.0一样
# Windows平台
# pipe_lib_dir=ext\\pipe
# Linux平台
# pipe_lib_dir=ext/pipe
# PipeSubtaskExecutor的最大线程数,规则和V1.3.0一样
# pipe_subtask_executor_max_thread_num=5
# Thrift客户端的连接超时时间(毫秒),参数名改了,注意区分
# pipe_sink_timeout_ms=900000
# Sink能使用的最大选择器数量,建议不超过最大客户端数
# pipe_sink_selector_number=4
# Sink能使用的最大客户端数量
# pipe_sink_max_client_number=16
调整这些参数时,建议根据实际情况测试——比如CPU核心数多,就可以适当调大线程数;网络不好,就调大超时时间,避免频繁断连。
总结
IoTDB流处理框架的灵活性和实用性都很强,不管是简单的数据同步,还是复杂的自定义数据处理,都能满足需求。从自定义插件开发,到任务创建管理,再到权限和配置调整,整个流程都很清晰。希望这篇文章能帮你快速上手IoTDB流计算,让实时数据处理变得更简单!如果在实际使用中遇到问题,建议多看看官方文档,或者在社区里和其他开发者交流,毕竟实践才是最好的学习方式。
🌐 附:IoTDB的各大版本
📄 Apache IoTDB 是一款工业物联网时序数据库管理系统,采用端边云协同的轻量化架构,支持一体化的物联网时序数据收集、存储、管理与分析 ,具有多协议兼容、超高压缩比、高通量读写、工业级稳定、极简运维等特点。
| 版本 | IoTDB 二进制包 | IoTDB 源代码 | 发布说明 |
|---|---|---|---|
| 2.0.5 | - All-in-one - AINode - SHA512 - ASC |
- 源代码 - SHA512 - ASC |
release notes |
| 1.3.5 | - All-in-one - AINode - SHA512 - ASC |
- 源代码 - SHA512 - ASC |
release notes |
| 0.13.4 | - All-in-one - Grafana 连接器 - Grafana 插件 - SHA512 - ASC |
- 源代码 - SHA512 - ASC |
release notes |
✨ 去获取:https://archive.apache.org/dist/iotdb/
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注:本文撰写于CSDN平台,作者:xcLeigh(所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 207
207 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)