一文讲清:深度学习——自注意力机制是什么?
本文介绍了自注意力机制这一神经网络创新架构。首先阐述了其与传统模型的不同之处在于能够捕捉输入序列内部的动态关联。其次详细讲解了两种注意力评分函数(加性注意力和缩放点积注意力)的计算原理及适用场景。最后深入解析了多头注意力机制,说明了其通过多个注意力头并行计算来提取更丰富特征的方法,并提供了完整的PyTorch实现代码。文章还指出AI大模型发展迅速,相关人才缺口巨大,建议读者把握机遇学习这一前沿技术
在传统神经网络架构中,权重系数的计算通常依赖于X与Y的关联性建模,但自注意力机制提出了一种创新范式。
该机制能够更有效地捕捉输入序列X内部各元素间的动态关联,并量化这些关联对Y输出的影响权重,进而显著增强模型的泛化能力。
作为深度学习领域的重要突破,自注意力机制已得到广泛应用,其核心思想更构成了Transformer模型的基础架构。
对于自注意力机制的内容本文从以下三个方面讲述:
1、什么是自注意力机制?
2、注意力评分函数有哪些?
3、什么是多头注意力?
一、什么是自注意力机制?
传统模型通常聚焦于X与Y的关联分析,而自注意力机制的创新之处在于揭示了X内部元素间潜在的重要关联。
以文本预测任务为例,模型不仅需要理解前文句子的表层含义,还需捕捉句子内部词汇组合对后续内容产生的深层影响。
为解决这一挑战,自注意力机制通过动态计算序列中每个元素(如a1与a2、a3的交互关系)的关联强度,结合反向传播算法,智能识别对当前任务最具关键性的特征部分。
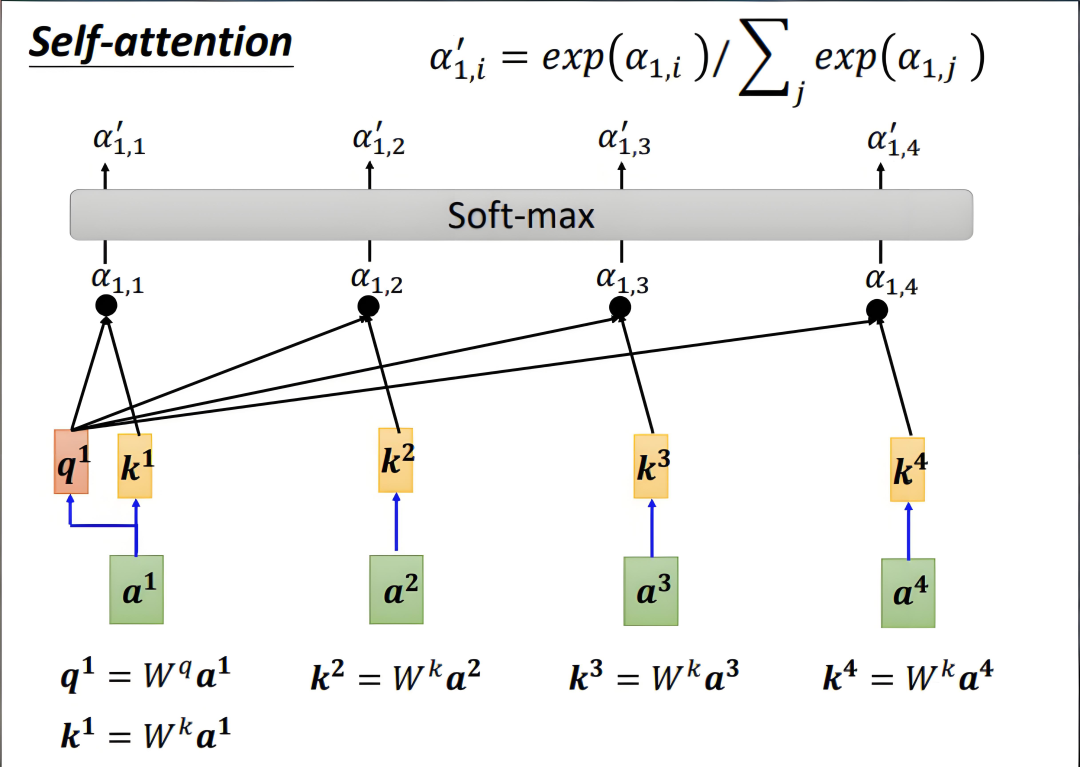
二、注意力评分函数有哪些?
常见的注意力评分函数有两种,一种是加性注意力,另一种是缩放点积注意力。
加性注意力:该评分函数不用考虑查询q和键k是否长度一致,其公式为:
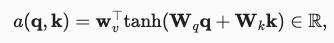
q代表查询,k代表键,但是自注意力中这两者是相同的,都是输入张量X。

缩放点积注意力:该评分函数需要查询q和键k保持长度一致,其公式为:
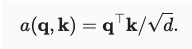

三、什么是多头注意力机制?
多头注意力机制就是将多个注意力汇聚的结果拼接在一起,这样得出来的结果会包含更多的行为信息,如下图所示:
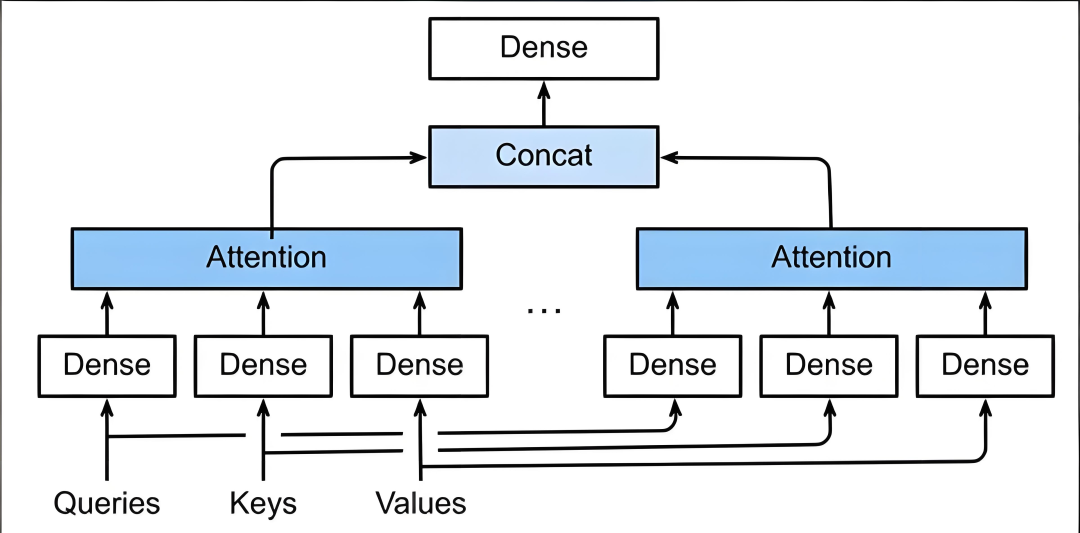
代码实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
# 分割d_model维度为num_heads
self.depth = d_model // num_heads
# 定义线性变换层
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
# 定义线性变换层来合并多头输出
self.dense = nn.Linear(d_model, d_model)
self.num_heads = num_heads
self.scale = 1 / (self.depth ** 0.5)
def split_heads(self, x, batch_size):
# 将输入x分割成多个头
x = x.reshape(batch_size, -1, self.num_heads, self.depth)
return x.permute(0, 2, 1, 3)
def forward(self, v, k, q, mask=None):
batch_size = q.shape[0]
# 分割头
q = self.split_heads(self.wq(q), batch_size)
k = self.split_heads(self.wk(k), batch_size)
v = self.split_heads(self.wv(v), batch_size)
# 计算注意力分数, 此处为缩放点积注意力
scores = torch.matmul(q, k.transpose(-2, -1)) * self.scale
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 应用softmax获得注意力权重
attention_weights = F.softmax(scores, dim=-1)
# 计算加权和
output = torch.matmul(attention_weights, v)
# 合并头
output = output.permute(0, 2, 1, 3).contiguous().reshape(batch_size, -1, self.num_heads * self.depth)
# 应用线性变换层
output = self.dense(output)
return output, attention_weights
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 17
17 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)