多标签分类实战教程-坐标轴分类数据集
介绍了多标签分类模型的实践过程。构建了一个基于坐标象限分类的简易数据集,通过坐标点(x,y)判断其所属象限(输出为两个二元标签)。实验发现,使用单层线性模型效果最佳,而更复杂的结构反而性能下降。重点比较了两种损失函数:nn.BCEWithLogitsLoss()在数值稳定性和计算效率上显著优于nn.Sigmoid()+nn.BCELoss()的组合。直观观察到模型输出的概率值在0.5边界附近的变化
文章目录
背景
最近在做专利分类,有的专利有多个类别,那么便需要训练多标签分类的模型。对多标签分类的损失函数还不太熟悉,故想着练一下手。
实战
找一个多标签分类的数据集也挺麻烦的,我便自己构建一个坐标轴的四个象限分类的多标签数据集。
简而言之,就是给一个坐标,使用模型判断 x 是否大于0,y是否大于0。
比如:
| 输入 | 输出 |
|---|---|
| (0.2, 0.5) | (1, 1) |
| (-0.2, 0.5) | (0, 1) |
| (0.2, -0.5) | (1, 0) |
| (-0.2, -0.5) | (0, 0) |
设计的这个数据集,可以很直接的看出来模型训练的效果。
在模型训练完成之后,概率值大于0.5的是1,小于0.5的是0。我以前对为什么分界线是0.5的理解不深刻,觉得就是随便设置的一个数0.5。
你在把上述的这个模型训练完成之后,你就会发现分界线就是0.5。你输入0.01、-0.01,就可以很清晰地看到概率值在0.5左右。
在理解分界线是0.5的问题上。我们构建的这个数据集,比那些复杂的数据集,能更直观地帮助大家看到多标签分类的效果。
代码开源地址:https://github.com/JieShenAI/csdn/blob/main/25/11/Multi-Label-Coordinate-Classification/run.ipynb
损失函数
在 数学计算上,nn.BCEWithLogitsLoss() 等价于 nn.Sigmoid() + nn.BCELoss(),但在 实际实现和数值稳定性 上有显著差异,这也是为什么在实践中几乎总是推荐使用 nn.BCEWithLogitsLoss()。
| 特性 | nn.Sigmoid() + nn.BCELoss() |
nn.BCEWithLogitsLoss() |
|---|---|---|
| 数学等价性 | 等价 | 等价 |
| 数值稳定性 | 差(易出现溢出/下溢) | 好(专门优化数值稳定性) |
| 计算效率 | 稍低(需额外计算 Sigmoid 激活) | 更高(融合计算,省去单独 Sigmoid 步骤) |
| 推荐场景 | 几乎不推荐(仅特殊情况需单独获取概率) | 二分类任务的首选损失函数 |
我在实验中发现 nn.BCEWithLogitsLoss()的效果比 nn.Sigmoid() + nn.BCELoss() 要好很多。
数据集构建
import torch
from torch import nn
from torch.utils.data import Dataset, random_split
directions = [
(1, 1),
(-1, 1),
(-1, -1),
(1, -1)
]
directions = torch.tensor(directions, dtype=torch.float32)
data = torch.randn(1000, 2).abs()
data = data.unsqueeze(1)
# 点乘,其中有广播扩充维度
dataset_data = data * directions # (1000, 4, 2)
dataset_data = dataset_data.reshape(-1, 2)
# label 设置
labels = torch.where(dataset_data > 0, torch.tensor(1.), torch.tensor(0.))
labels = labels.reshape(-1, 2)
在数据集的构建中,data * directions 这个点乘,可能有点难度,有的同学可能不理解。
查看数据集的shape:
dataset_data.shape, labels.shape
输出:
(torch.Size([4000, 2]), torch.Size([4000, 2]))
自定义数据集类:
class MultiLabelDataset(Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self):
return self.data.shape[0]
def __getitem__(self, idx):
return {
"data": self.data[idx],
"labels": self.labels[idx]
}
full_dataset = MultiLabelDataset(dataset_data, labels)
train_dataset, eval_dataset = random_split(full_dataset, [0.8, 0.2])
模型
class CustomModel(nn.Module):
def __init__(self):
super(CustomModel, self).__init__()
self.fc = nn.Linear(2, 2, bias=False)
def compute_loss(self, predictions, targets):
# criterion = nn.BCELoss()
criterion = nn.BCEWithLogitsLoss()
loss = criterion(predictions, targets)
return loss
def custom_sigmoid(self, x):
return 1 / (2 + torch.exp(-x))
def forward(self, data, labels=None):
x = self.fc(data)
return {
"loss": self.compute_loss(x, labels) if labels is not None else None,
"logits": x
}
我们的自定义模型只用了一个Linear,这个是最佳的模型架构。我后面想尝试多加几个Linear,哪怕我用了残差连接,模型的效果也出现了显著的下降。
custom_sigmoid: 不是真正的sigmoid。我们打算用这个修改后的sigmoid方法,帮助大家理解0.5分界线这个现象。
训练
from transformers import Trainer, TrainingArguments
评估函数:
import torch
import numpy as np
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score
def compute_metrics(eval_pred):
logits, labels = eval_pred
# 将 logits 转换为概率并得到预测结果
probs = torch.sigmoid(torch.tensor(logits)).numpy()
preds = (probs >= 0.5).astype(int)
# 计算整体准确率
accuracy = accuracy_score(labels, preds)
# 计算每个类别的 Precision, Recall, F1
precision_per_class = precision_score(labels, preds, average=None, zero_division=0)
recall_per_class = recall_score(labels, preds, average=None, zero_division=0)
f1_per_class = f1_score(labels, preds, average=None, zero_division=0)
# 计算宏观平均指标
precision_macro = precision_score(labels, preds, average='macro', zero_division=0)
recall_macro = recall_score(labels, preds, average='macro', zero_division=0)
f1_macro = f1_score(labels, preds, average='macro', zero_division=0)
# 构建结果字典
metrics = {
# 'accuracy': accuracy,
# 'precision_macro': precision_macro,
# 'recall_macro': recall_macro,
'f1': f1_macro
}
# 添加每个类别的指标
for i, (p, r, f) in enumerate(zip(precision_per_class, recall_per_class, f1_per_class)):
metrics[f'f1_class_{i}'] = f
return metrics
训练参数:
args = TrainingArguments(
output_dir="output",
num_train_epochs=30,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
eval_strategy="epoch",
save_strategy="epoch",
logging_dir="logs",
# report_to="tensorboard",
remove_unused_columns=False,
logging_steps=10,
learning_rate=5e-3,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
load_best_model_at_end=True,
metric_for_best_model="f1",
)
trainer = Trainer(
model=CustomModel(),
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
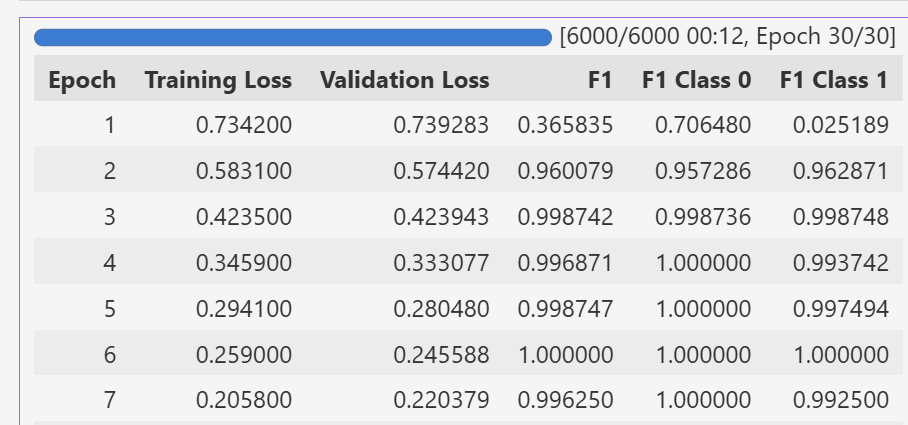
训练效果也是非常的好,几乎达到了100%左右的准确率。
预测
trainer.predict 是对数据集进行预测。
预测就写的简单一下,直接通过 trainer.model 拿到训练好的模型,进行预测就行。
pred_data = torch.tensor([[0.5, 0.5], [0.1, 0.9], [0.01, 0.999], [-0.01, 0.999], [-99, 99]]).to("cuda")
logits = trainer.model(pred_data)["logits"]
nn.Sigmoid()(logits)
输出:
tensor([[0.7751, 0.7310],
[0.5636, 0.8581],
[0.5088, 0.8806],
[0.4965, 0.8806],
[0.0000, 1.0000]], device='cuda:0', grad_fn=<SigmoidBackward0>)
一定要记得给logits加一个nn.Sigmoid() 这样得到的才是概率。概率大于0.5的label是1,小于0.5的label是0。
从预测的结果上可以看的很清楚,0.01与-0.01的概率值在0.5附近。这个可以的帮助大家理解多标签分类0.5分界线这个概念。
多标签分类概率是0.5分界线分析
logit 先经过 Sigmoid ,然后再计算损失。Sigmoid 的公式如下所示:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
当 x=0的时候,sigmoid的值是0.5。这才是多标签分界线是0.5的原因。
那么新的问题就产生了,为什么logits是0,会是多标签分界线。

这个问题的答案,其实隐藏在 损失函数(Loss Function) 的优化目标里。模型训练的过程,就是通过调整参数,让这个损失函数的值达到最小。
我们来把 nn.BCEWithLogitsLoss() 拆开来看,它其实做了两件事:
- 对模型输出的
logits应用 Sigmoid 函数,得到概率p。 - 用这个概率
p和真实标签y(0 或 1)计算 二元交叉熵(Binary Cross-Entropy, BCE) 损失。
关键在于损失函数的“推力”
让我们分别看一下,当真实标签是 1 或 0 时,损失函数是如何“推动” logits 变化的。
情况一:真实标签 y = 1 (正样本)
此时,损失函数简化为: Loss = -log(p) ,其中 p = σ(z) 是 Sigmoid 函数的输出。
我们的目标是最小化这个损失。
- 要让
-log(p)变小,就需要让log(p)变大。 - 要让
log(p)变大,就需要让p变大(因为log函数是递增的)。 - 要让
p = σ(z)变大,根据 Sigmoid 函数的特性,就需要让z(也就是logits) 尽可能地大。
所以,对于一个正样本,损失函数会“推动”模型,让它输出一个很大的正 logits。
情况二:真实标签 y = 0 (负样本)
此时,损失函数简化为: Loss = -log(1 - p) 。
同样,我们的目标是最小化这个损失。
- 要让
-log(1 - p)变小,就需要让log(1 - p)变大。 - 要让
log(1 - p)变大,就需要让1 - p变大。 - 要让
1 - p变大,就需要让p变小。 - 要让
p = σ(z)变小,根据 Sigmoid 函数的特性,就需要让z(也就是logits) 尽可能地小。
所以,对于一个负样本,损失函数会“推动”模型,让它输出一个很大的负 logits。
logits=0 是自然的“分水岭”
现在,我们把这两种情况放在一起看:
- 正样本被模型“推”向
logits为正无穷。 - 负样本被模型“推”向
logits为负无穷。
在训练过程中,模型会学习参数,使得所有正样本的 logits 都远远大于 0,所有负样本的 logits 都远远小于 0。
那么,logits = 0 这个点,就成了这两“股力量”的自然分界。它是 Sigmoid 函数 σ(z) = 0.5 的位置,也是模型在没有任何倾向性时的输出。
总结
模型训练的最终结果,是形成了一个决策边界。在 logits 空间里,这个边界就是 z = 0。
- 当一个新样本的
logits计算出来后,如果它 大于 0,模型就认为它更像一个正样本(因为正样本都被推到了z > 0的区域)。 - 如果它 小于 0,模型就认为它更像一个负样本(因为负样本都被推到了
z < 0的区域)。
因此,logits=0 成为分界点,是 Sigmoid 函数的数学特性 和 BCE 损失函数的优化目标 共同作用的必然结果。模型通过梯度下降,自动地将正负样本在 logits 空间中分开,而 z=0 就是它们的天然分界线。
验证实验
多标签类别的分界线是 x=0。如果我们修改一下, sigmoid函数,如下述公式所示。那么x=0时,概率的分界线应该是0.3左右。
σ ( x ) = 1 2 + e − x \sigma(x) = \frac{1}{2 + e^{-x}} σ(x)=2+e−x1
但是有一个问题,在之前说过了 nn.BCEWithLogitsLoss()比nn.Sigmoid() + nn.BCELoss()的效果好。 nn.BCEWithLogitsLoss()自带sigmoid,我们修改不方便。
于是我使用nn.Sigmoid() + nn.BCELoss()虽然训练的模型效果差了一些,不过也发现分界线的概率值小于0.4,大于0.3。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 19
19 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)