人工智能基础篇:概念性名词浅谈(第十三讲)
本文系统介绍了两种自编码器模型。稀疏自编码器通过在传统自编码器中引入L1正则化或KL散度约束,使隐层神经元呈现稀疏激活状态,适用于高维特征提取。自编码器则包含编码器和解码器结构,最早由LeCun于1987年提出,经历了从玻尔兹曼机到深度学习的发展历程,可分为收缩型、正则型和变分型三类。两种模型均广泛应用于降维、特征学习、异常检测等领域,并随着深度学习技术发展在计算机视觉等方向取得重要进展。
大家好,今天继续讲述关于人工智能学习的基础篇。
(1)稀疏自编码器
稀疏自编码器是一种无监督机器学习算法,通过在传统自编码器中引入稀疏性约束提取数据有效特征。其核心结构包含编码器与解码器,通过最小化重构误差优化参数,并采用KL散度或L1正则化限制隐层神经元激活度,使大部分神经元处于非活跃状态。
该算法通过权重衰减项、稀疏惩罚因子等构建代价函数,抑制隐层神经元输出以实现高维稀疏表征 。与普通自编码器相比,其核心区别在于引入稀疏性约束机制,可应用于输入维度较高场景下的特征提取 。
稀疏自编码器广泛用于图像处理、语音识别、自然语言处理的特征提取,并在异常检测、数据生成等领域发挥作用。深度学习中常采用堆叠结构形成深度稀疏自编码器,工业应用中涉及设备故障诊断等场景。PyTorch、TensorFlow等框架通过定义编码器/解码器层及正则化项实现该算法。
自编码器最初提出是基于降维的思想,但是当隐层节点比输入节点多时,自编码器就会失去自动学习样本特征的能力,此时就需要对隐层节点进行一定的约束,与降噪自编码器的出发点一样,高维而稀疏的表达是好的,因此提出对隐层节点进行一些稀疏性的限值。稀疏自编码器就是在传统自编码器的基础上通过增加一些稀疏性约束得到的。这个稀疏性是针对自编码器的隐层神经元而言的,通过对隐层神经元的大部分输出进行抑制使网络达到一个稀疏的效果。
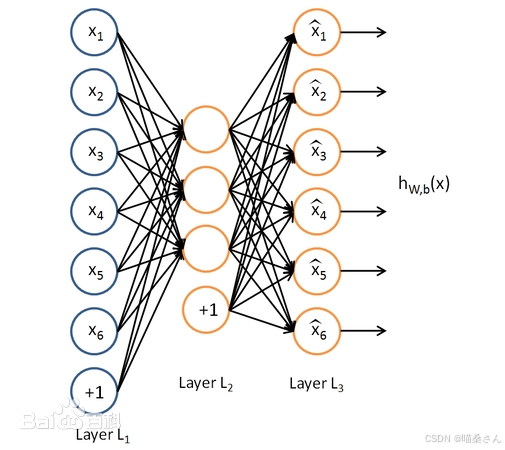
在自动编码器AutoEncoder的基础上加上L1的正则限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
如图三,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)。
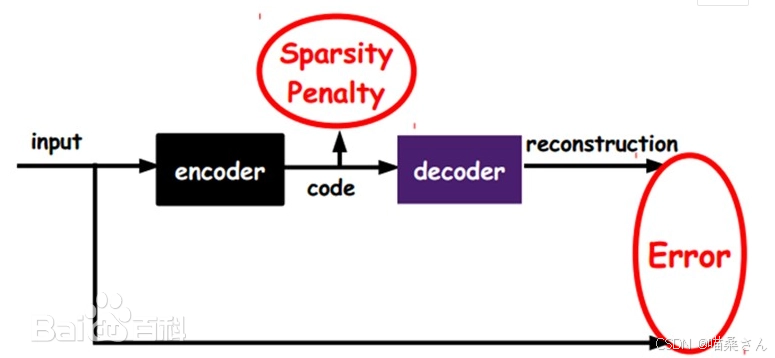
对于没有带类别标签的数据,由于为其增加类别标记是一个非常麻烦的过程,因此我们希望机器能够自己学习到样本中的一些重要特征。通过对隐藏层施加一些限制,能够使得它在恶劣的环境下学习到能最好表达样本的特征,并能有效地对样本进行降维。这种限制可以是对隐藏层稀疏性的限制。
如果给定一个神经网络,我们假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。自然地,我们就得到了输入的几种不同表示(每一层代表一种表示),这些表示就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
当然,我们还可以继续加上一些约束条件得到新的Deep Learning方法,如:如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束隐含层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
之所以要将隐含层稀疏化,是由于,如果隐藏神经元的数量较大(可能比输入像素的个数还要多),不稀疏化我们无法得到输入的压缩表示。具体来说,如果我们给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。
(2)自编码器
自编码器(autoencoder, AE)作为一类包含编码器(encoder)和解码器(decoder)的人工神经网络结构,最早由David H. Ackley、Geoffrey E. Hinton和Terrence J. Sejnowski于1985年在玻尔兹曼机上的研究中进行初步探索,并于1987年由Yann LeCun正式提出。其通过将输入信息作为学习目标实现表征学习(representation learning),按学习范式可分为收缩自编码器、正则自编码器和变分自编码器(Variational AutoEncoder, VAE),其中前两者为判别模型,后者为生成模型。该结构被广泛应用于降维、异常值检测、图像降噪及神经风格迁移等领域 。
自编码器的发展始于1985年基于玻尔兹曼机的联结主义模型研究 ,1986年反向传播算法的提出推动了自监督反向传播的实现。1987年LeCun使用多层感知机构建包含编解码器的神经网络结构 ,同年该结构被应用于语音数据表征学习。1988年Bourlard和Kamp通过MLP自编码器开展数据降维研究 。1994年Hinton与Richard S. Zemel基于最小描述长度原理构建了首个生成模型自编码器 。随着深度学习技术的发展,包含卷积层的自编码器在计算机视觉领域得到深度应用 。
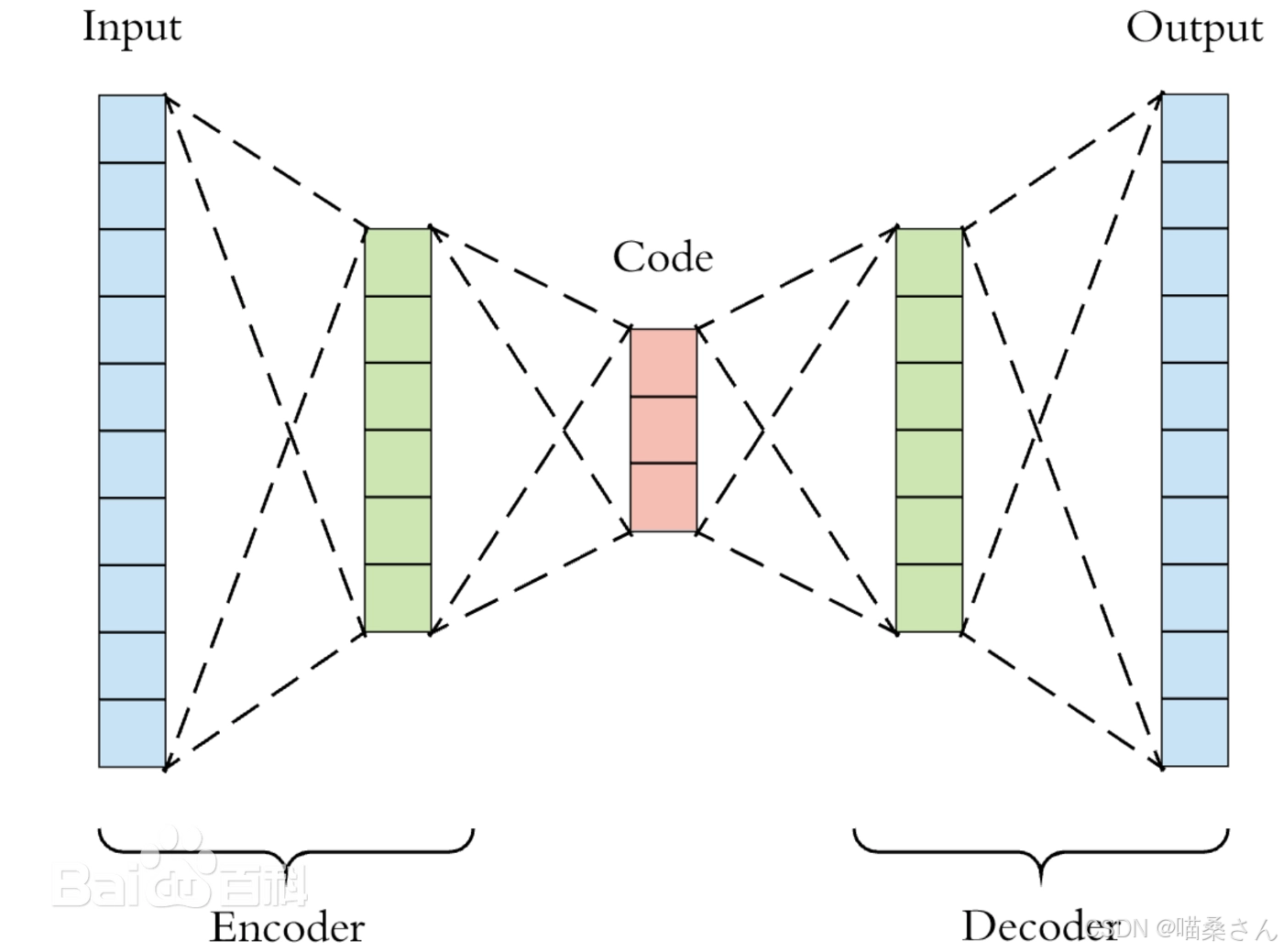
自编码器在其研究早期是为解决表征学习中的“编码器问题(encoder problem)”,即基于神经网络的降维问题而提出的联结主义模型的学习算法。1985年,David H. Ackley、Geoffrey E. Hinton和Terrence J. Sejnowski在玻尔兹曼机上对自编码器算法进行了首次尝试,并通过模型权重对其表征学习能力进行了讨论 。在1986年反向传播算法(Back-Propagation, BP)被正式提出后,自编码器算法作为BP的实现之一,即“自监督的反向传播(Self-supervised BP)”得到了研究 ,并在1987年被Jeffrey L. Elman和David Zipser用于语音数据的表征学习试验。自编码器作为一类神经网络结构(包含编码器和解码器两部分)的正式提出,来自1987年Yann LeCun发表的研究 。LeCun (1987)使用多层感知器(Multi-Layer Perceptron,MLP)构建了包含编码器和解码器的神经网络,并将其用于数据降噪。此外,在同一时期,Bourlard and Kamp (1988)使用MLP自编码器对数据降维进行的研究也得到了关注 。1994年,Hinton和Richard S. Zemel通过提出“最小描述长度原理(Minimum Description Length principle, MDL)”构建了第一个基于自编码器的生成模型 。2025年,字节跳动推出的InfinityStar框架通过知识继承策略使用预训练变分自编码器作为基础模块,降低了视频生成模型的训练时间和计算资源消耗。
今天就讲这些,下篇文章见。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)