YOLOV8使用及训练自定义数据集记录
YOLOV8使用及训练自定义数据集记录
1. 环境搭建
1.1 Anaconda 环境安装
1.1.1 为什么使用Anaconda
在使用python相关库开发时最大的一个问题就是python版本的支持, 有些库需要特定版本的python, 这个可以通过安装不同版本的python来解决,但是每次用到都要安装一个python比较麻烦。还有就是环境隔离,比如两个不同的应用所需的同一个库版本不同,就会冲突,这个可以通过venv虚拟环境解决,但是没办法解决python安装多个版本问题,而Anaconda 可对python管理,创建对应版本的python环境。
1.1.2 Anaconda 下载安装
https://www.anaconda.com/
直接跳过注册: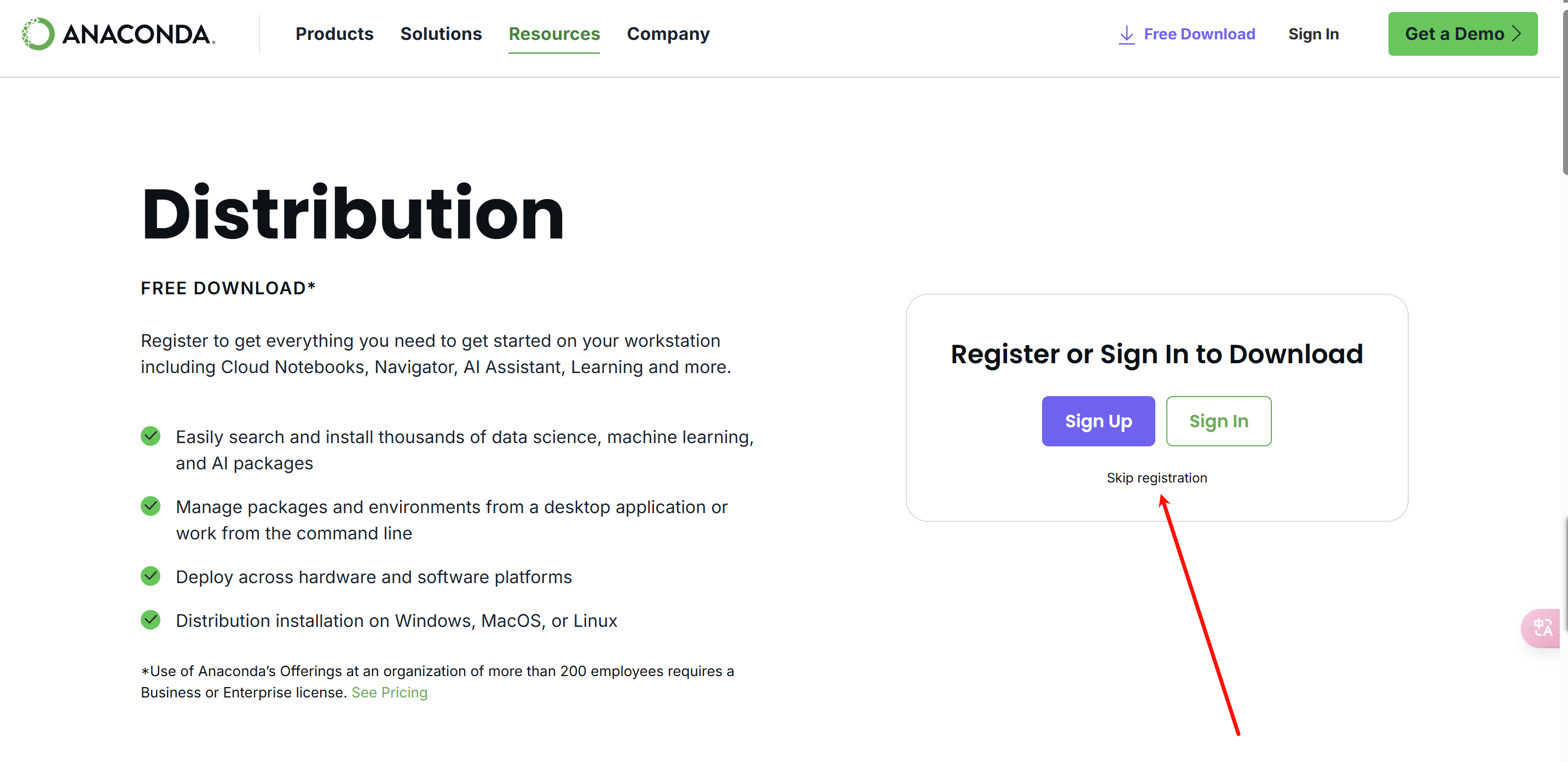
直接下载就可以, 使用mini版也是可以的,不会默认安装一些库,其他一样。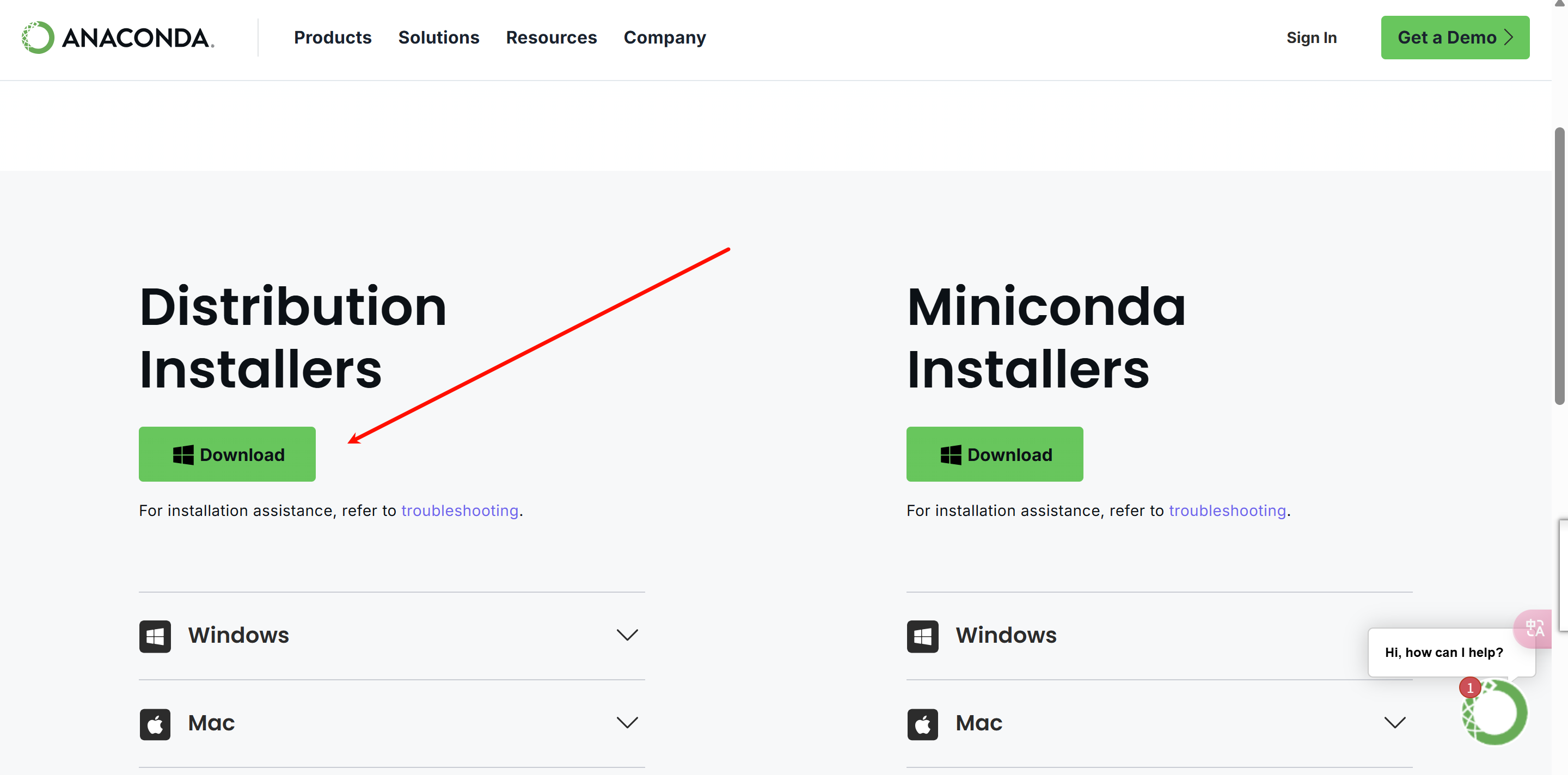
下载后直接下一步下一步安装就可以, 安装过程种勾选环境变量,或者安装完自己配置也可以。环境变量就下边三个:
测试环境变量可用后就安装完成,后续可以直接使用了。
1.2 Anaconda 使用
1.2.1 创建新环境
# 创建名为myenv的环境,指定Python版本
conda create -n myenv python=3.9
# 创建环境时同时安装包(如numpy、pandas)
conda create -n myenv python=3.9 numpy pandas matplotlib
1.2.2 激活 / 切换环境
# Windows
conda activate myenv
# Linux/macOS
source activate myenv # 旧版本Anaconda
conda activate myenv # 新版本Anaconda
1.2.3 查看所有环境
conda env list # 或 conda info --envs
1.2.4 退出当前环境
conda deactivate
1.2.5 删除环境
conda env remove -n myenv
2. 数据标记
2.1 创建conda 虚拟环境
使用上边安装anaconda 创建虚拟环境,用于安装LabelImg 标注工具, 太高版本的运行labeimg有问题,需要改源码比较麻烦,这里直接用3.8。
conda create -n py38 python=3.8
激活环境:
2.2 Labelimg 安装
确认环境上述 conda 创建的环境是激活的。
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
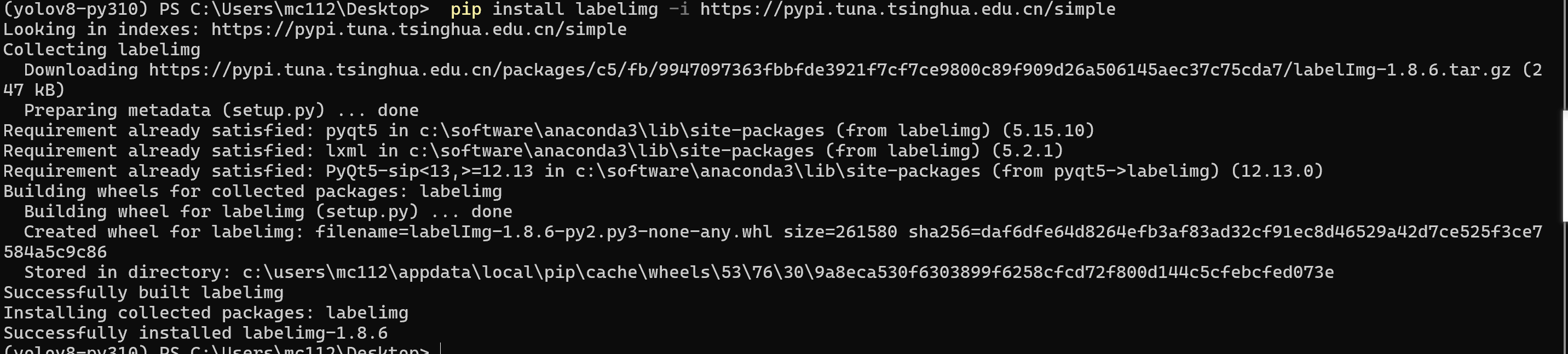
然后终端执行labelimg
2.3 数据标注
打开要标注的图片所在文件夹
选择要保存的标注信息(txt) 文件保存的位置, 放到新建的datasets/labels下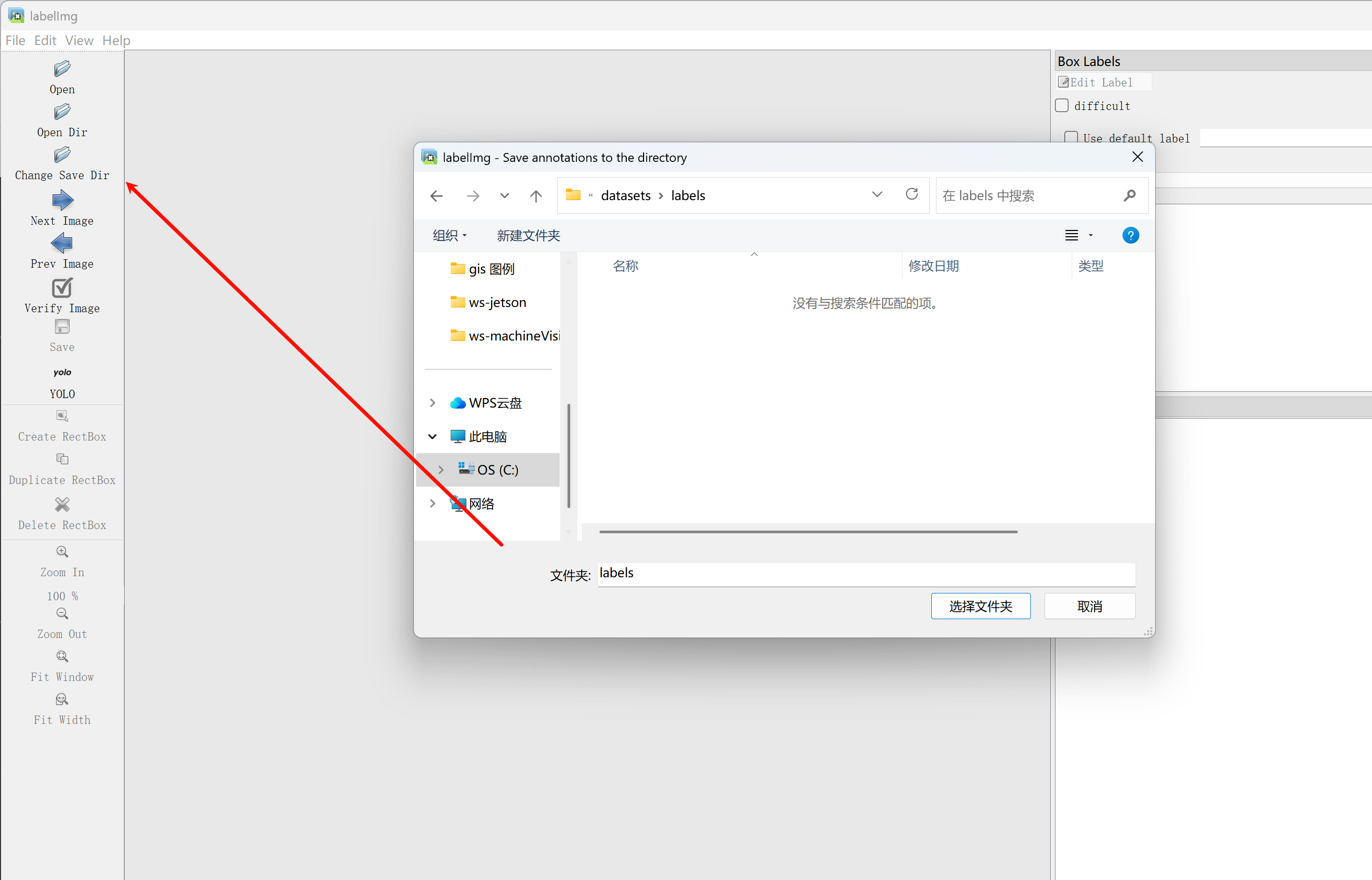
点击选择数据格式为yolo:
标注数据:
一张图片可以标注多个,可以标注多个类型,标注后保存就可以。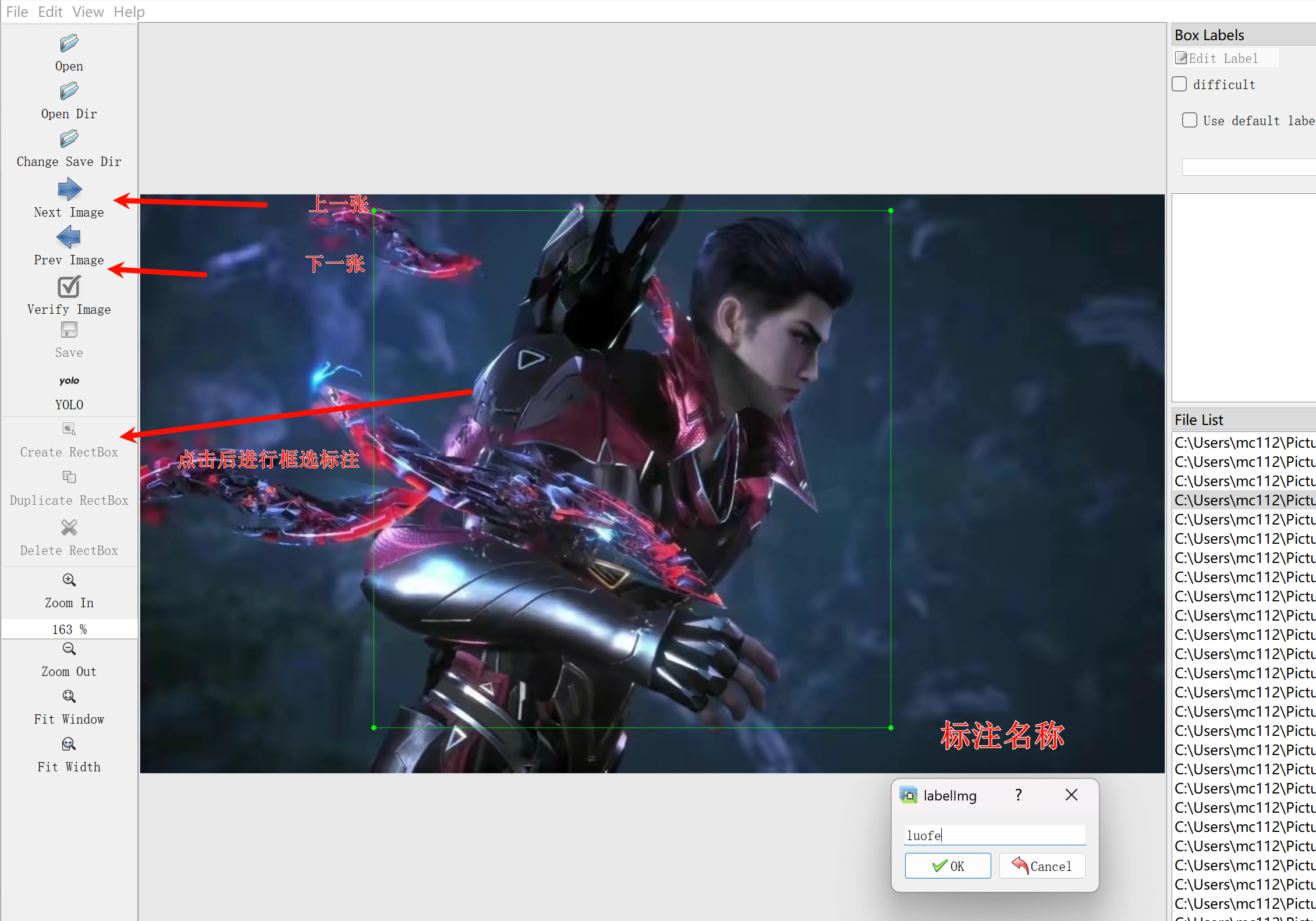
3. 数据划分
新建src-data目录,将之前标注的txt和图片整理放到这个目录下的labels和images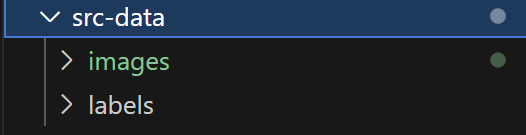
新建数据划分脚本dataset_partitioning.py, 放到src-data 同级目录下,使用python dataset_partitioning.py 执行来划分数据,分为训练集,测试集和验证集
import shutil
import random
import os
from pathlib import Path
# 原始路径
image_original_path = "src-data/images/"
label_original_path = "src-data/labels/"
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "datasets", "images", "train")
train_label_path = os.path.join(cur_path, "datasets", "labels", "train")
# 验证集路径
val_image_path = os.path.join(cur_path, "datasets", "images", "val")
val_label_path = os.path.join(cur_path, "datasets", "labels", "val")
# 测试集路径
test_image_path = os.path.join(cur_path, "datasets", "images", "test")
test_label_path = os.path.join(cur_path, "datasets", "labels", "test")
# 列表文件路径
list_train = os.path.join(cur_path, "datasets", "train.txt")
list_val = os.path.join(cur_path, "datasets", "val.txt")
list_test = os.path.join(cur_path, "datasets", "test.txt")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
def setup_directories():
"""创建并清空目标目录,使用更安全的方式"""
for dir_path in [
train_image_path, train_label_path,
val_image_path, val_label_path,
test_image_path, test_label_path
]:
path = Path(dir_path)
if path.exists():
# 安全删除目录下的文件,保留目录本身
for file in path.glob('*'):
if file.is_file():
file.unlink()
else:
path.mkdir(parents=True, exist_ok=True)
def clear_list_files():
"""清空或创建列表文件"""
for file_path in [list_train, list_val, list_test]:
if os.path.exists(file_path):
os.remove(file_path)
open(file_path, 'w').close() # 创建空文件
def main():
setup_directories()
clear_list_files()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
# 获取所有标签文件
total_txt = [f for f in os.listdir(label_original_path) if f.endswith('.txt')]
num_txt = len(total_txt)
if num_txt == 0:
print("错误:未找到标签文件")
return
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
# 随机划分数据集
train = random.sample(list_all_txt, num_train)
val_test = [i for i in list_all_txt if not i in train]
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
# 记录处理过程中的错误
errors = []
for i in list_all_txt:
label_file = total_txt[i]
name = os.path.splitext(label_file)[0] # 提取文件名(不含扩展名)
# 自动获取图片扩展名
image_files = [f for f in os.listdir(image_original_path) if f.startswith(name)]
if not image_files:
errors.append(f"找不到图片文件对应标签 {label_file}")
continue
# 假设只有一个匹配的图片文件
image_file = image_files[0]
srcImage = os.path.join(image_original_path, image_file)
srcLabel = os.path.join(label_original_path, label_file)
# 检查源文件是否存在
if not os.path.exists(srcImage):
errors.append(f"图片文件不存在: {srcImage}")
continue
if not os.path.exists(srcLabel):
errors.append(f"标签文件不存在: {srcLabel}")
continue
try:
if i in train:
dst_image = os.path.join(train_image_path, image_file)
dst_label = os.path.join(train_label_path, label_file)
shutil.copy2(srcImage, dst_image) # 使用copy2保留元数据
shutil.copy2(srcLabel, dst_label)
file_train.write(dst_image + '\n')
elif i in val:
dst_image = os.path.join(val_image_path, image_file)
dst_label = os.path.join(val_label_path, label_file)
shutil.copy2(srcImage, dst_image)
shutil.copy2(srcLabel, dst_label)
file_val.write(dst_image + '\n')
else:
dst_image = os.path.join(test_image_path, image_file)
dst_label = os.path.join(test_label_path, label_file)
shutil.copy2(srcImage, dst_image)
shutil.copy2(srcLabel, dst_label)
file_test.write(dst_image + '\n')
except Exception as e:
errors.append(f"复制文件 {name} 时出错: {str(e)}")
file_train.close()
file_val.close()
file_test.close()
# 输出错误信息
if errors:
print(f"处理过程中发生 {len(errors)} 个错误:")
for err in errors[:5]: # 只显示前5个错误
print(f" - {err}")
if len(errors) > 5:
print(f" ... 还有 {len(errors)-5} 个错误未显示")
if __name__ == "__main__":
main()
执行脚本前移出classes.txt 分类文件到上一级目录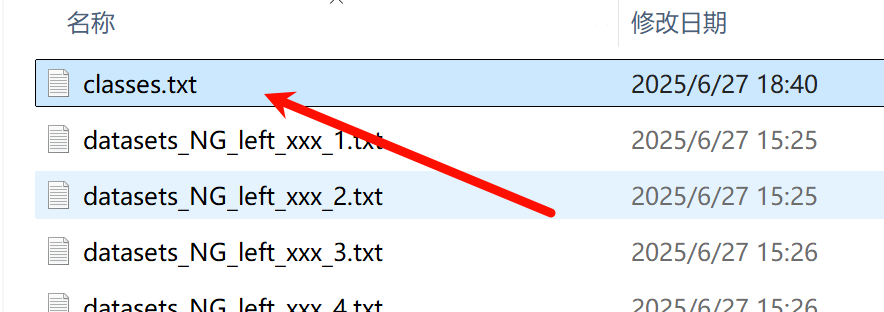
执行后划分数据如下:
4. YOLOV8 数据训练
4.1 yolov8 源码下载
https://github.com/ultralytics/ultralytics
访问不了的可以参考github加速:https://blog.csdn.net/qq_51355375/article/details/148614617?spm=1011.2415.3001.5331
4.2 yolov8 配置
4.2.1 数据集配置
复制项目 ultralytics\cfg\datasets\coco.yaml 文件改名为data_config.yaml
修改内容如下:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# COCO 2017 dataset https://cocodataset.org by Microsoft
# Documentation: https://docs.ultralytics.com/datasets/detect/coco/
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco ← downloads here (20.1 GB)
# 修改路径和上述划分后的数据集对应
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ./datasets # dataset root dir
train: train.txt # train images (relative to 'path') 118287 images
val: val.txt # val images (relative to 'path') 5000 images
test: test.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
nc: 3 # 类别数量
# 自定义标注的数量, 顺序参考 数据标注生成的 classes.txt
# Classes
names:
0: cat
1: dag
2: person
# Download script/URL (optional)
download: |
from pathlib import Path
from ultralytics.utils.downloads import download
# Download labels
segments = True # segment or box labels
dir = Path(yaml["path"]) # dataset root dir
url = "https://github.com/ultralytics/assets/releases/download/v0.0.0/"
urls = [url + ("coco2017labels-segments.zip" if segments else "coco2017labels.zip")] # labels
download(urls, dir=dir.parent)
# Download data
urls = [
"http://images.cocodataset.org/zips/train2017.zip", # 19G, 118k images
"http://images.cocodataset.org/zips/val2017.zip", # 1G, 5k images
"http://images.cocodataset.org/zips/test2017.zip", # 7G, 41k images (optional)
]
download(urls, dir=dir / "images", threads=3)
4.2.2 模型文件配置
复制 ultralytics\cfg\models\v8\yolov8.yaml 文件重命名为yolov8_config.yaml , 修改 类别名称nc为自己训练的对应数量。
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLOv8 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolov8
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 3 # number of classes # 修改类别数量
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 129 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPS
s: [0.33, 0.50, 1024] # YOLOv8s summary: 129 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPS
m: [0.67, 0.75, 768] # YOLOv8m summary: 169 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPS
l: [1.00, 1.00, 512] # YOLOv8l summary: 209 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPS
x: [1.00, 1.25, 512] # YOLOv8x summary: 209 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPS
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.3 yolov8 环境安装
4.3.1 创建conda 虚拟环境并激活
conda create -n py310-yolov8 python=3.10
conda activate py310-yolov8
4.3.2 GPU版本的PyTorch 安装
因为直接使用yolov8 依赖中的pytoch pip安装的pytorch是cpu版本的,训练需要用到gpu加速,需要单独安装gpu版本的。这一步需要已经安装cuda相关驱动和工具,未安装可自行百度安装。
-
查看CUDA 版本
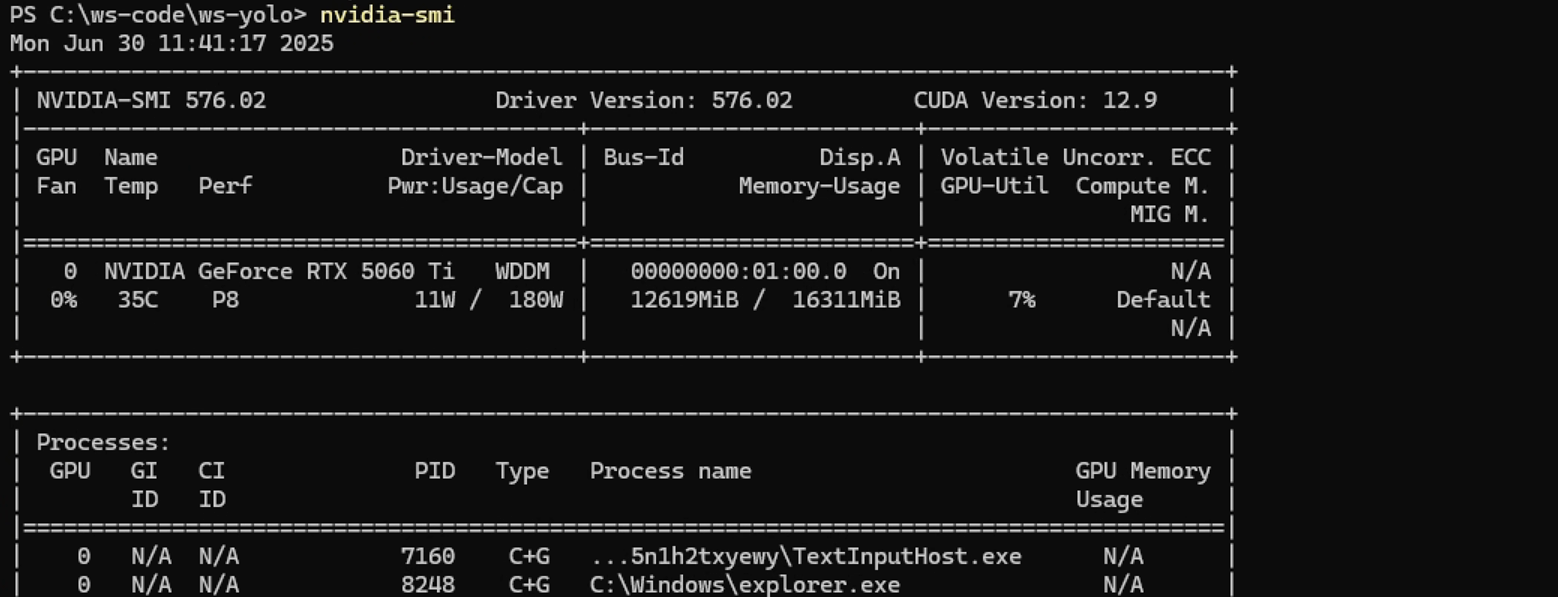
-
pytorch 安装
https://pytorch.org/get-started/locally/
根据cuda 版本在上述torch官网选择对应的版本, torch 对应的cuda版本不能高于实际电脑版本。
复制上述命令后直接在上述创建并激活的conda环境中安装即可。
4.3.3 yolov8 依赖安装
删除掉 pyproject.toml 中依赖部分的torch , 应为上述已经安装了, 没必要再安装cpu版本的。
在项目路径下打开终端并激活上边创建的conda虚拟环境,执行安装命令, (注意后边的参数 . 是当前路径, 区别于requitement.txt 安装):
pip install .
4.4 训练和测试
训练命令, 根据自己需要调整,在终端执行
yolo task=detect mode=train model=yolov8m.yaml data=data.yaml device=0 epochs=300 batch=16 imgsz=320 workers=10
参数详解:
-
task=detect
指定任务类型为目标检测。YOLOv8 支持多种任务(如检测、分割、分类等),这里明确使用检测任务。 -
mode=train
指定运行模式为训练模式。YOLOv8 的 CLI 支持多种模式(训练、验证、预测、导出等)。 -
model=yolov8m.yaml
指定模型配置文件路径。yolov8m 表示使用中号模型架构(M 代表 Medium),.yaml 文件定义了模型的网络结构和参数。 -
data=data.yaml
指定数据集配置文件路径。该文件包含训练 / 验证数据的路径、类别数量和类别名称等信息 -
device=0
指定训练使用的 GPU 设备 ID。0 表示使用第一块 GPU。若有多个 GPU,可指定 device=0,1 或 device=all。 -
epochs=300
设置训练的总轮数(Epoch)。一个 Epoch 表示所有训练样本都被模型处理一次。 -
batch=16
设置每个批次(Batch)的样本数量。Batch Size 影响训练稳定性和内存占用,需根据 GPU 显存调整。 -
imgsz=320
设置输入图像的尺寸(像素)。所有输入图像会被调整为 320×320 大小,需根据任务和模型调整。 -
workers=10
设置数据加载的工作线程数。更多的线程可加快数据加载速度,但会增加 CPU 负担。 -
常见调整建议:
显存不足:减小 batch 或 imgsz。
训练速度慢:增加 workers 或使用更大的 batch。
精度优化:增加 epochs 或更换更大的模型(如 yolov8l.yaml)。
如果需要进一步优化训练配置,可以调整这些参数或修改 data.yaml 和 yolov8m-test.yaml 文件中的具体设置。
使用代码训练, 根目录下新建train.py:
from ultralytics import YOLO
if __name__ == '__main__':
# 加载预训练模型
model = YOLO("yolov8n.pt")
model.train(data="ultralytics\cfg\datasets\data_config.yaml", # 数据集配置文件
imgsz=640,
epochs=300,
batch=4,
workers=10,
device='0'
)
然后conda 虚拟环境激活的终端执行 python train.py
训练号的数据在 runs\detect\train\weights\best.pt
找最新的train文件
测试:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO( runs\detect\train8\weights\best.pt')
model.val(data='data.yaml',
imgsz=640,
batch=16,
split='test',
workers=10,
device='0',
)
内容参考: https://blog.csdn.net/qq_42591591/article/details/140717589

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)