【ICML 2025 解读】FedSWA & FedMoSWA:高异质联邦学习中的“全球平坦最优”新范式(含 SWA 通俗讲解)
本文提出FedSWA和FedMoSWA两种新方法,旨在解决高度异质数据下联邦学习的泛化性能问题。研究发现,传统SAM方法在高异质场景下表现不佳。FedSWA通过分层线性衰减学习率和指数滑动平均聚合,使模型更接近平坦最优点;FedMoSWA进一步引入动量式随机控制变量,有效减少客户端漂移。理论分析提供了泛化误差上界和收敛保证。实验表明,在多种数据集和模型架构下,FedMoSWA的泛化性能、测试精度和
🚀【ICML 2025 解读】FedSWA & FedMoSWA:高异质联邦学习中的“全球平坦最优”新范式(含 SWA 通俗讲解)
🏷 标签:Federated Learning / 联邦学习 / SWA / SAM / FedSWA / FedMoSWA / 泛化性能
📝 适用读者:做联邦学习、优化算法、模型泛化、Non-IID 异质性问题的研究者与工程师
🔥 阅读收益:看懂 SAM 为什么“失效”,SWA 为什么“起效”,FedSWA/FedMoSWA 如何提升泛化

论文:Improving Generalization in Federated Learning with Highly Heterogeneous Data via Momentum-Based Stochastic Controlled Weight Averaging(FedSWA / FedMoSWA)
📌 论文摘要(中文翻译)
在高度异质(highly heterogeneous)数据下提升联邦学习(FL)的泛化能力,是当前 FL 研究中的核心挑战之一。现有工作通常从优化层面出发,通过修改客户端或服务器端的优化策略,以改善局部更新一致性、减少客户端漂移。然而,这类方法往往 忽略了全局模型的泛化性能。
另一方面,Sharpness-Aware Minimization(SAM)框架在中心化训练中表现优秀,被认为有助于找到“平坦”解,从而提升泛化;但我们发现:在高度异质的联邦场景中,SAM 的表现甚至比 FedAvg 更差。
为此,我们提出 FedSWA 与 FedMoSWA 两种新方法,旨在显著提升高异质 FL 场景下的泛化性能。FedSWA 采用分层线性衰减学习率(tiered linear-decay LR)与指数滑动平均(EMA)聚合,从而使全局模型更易接近平坦最优点。进一步地,FedMoSWA 在 FedSWA 的基础上引入动量式随机控制变量(momentum-based stochastic controlled updates),在不显著增加计算成本的前提下,有效减少客户端漂移。
我们提供了统一稳定性(uniform stability)框架下的泛化误差上界,并给出了 FedMoSWA 的非凸优化收敛保证。实验结果显示,在多个数据集、不同模型架构(包括 ResNet、ViT 等)和不同异质性水平(Dirichlet 0.1 / 0.6)下,FedMoSWA 的泛化性能、测试精度与收敛速度均显著优于现有最先进方法,包括 FedSAM、FedAvgM、SCAFFOLD、MoFedSAM、FedASAM 等。
一作 Junkang Liu(刘俊康)的公开资料/简介链接。
🔗 Google 学术个人主页
https://scholar.google.com/citations?user=N7pJWIoAAAAJ&hl=zh-CN (谷歌学术)
ℹ️ 关于 Junkang Liu 的简要背景
- 他目前是 Tianjin University(天津大学)的 PhD 学生,同时也曾在 Xidian University(西安电子科技大学)攻读 MS。(OpenReview)
- 他的研究方向包括联邦学习(Federated Learning)、优化算法、分布式训练等。(OpenReview)
- 除了最近的 FedSWA / FedMoSWA(Improving Generalization in Federated Learning …)论文之外,他也参与其他与 Federated Learning 优化相关的研究,例如 FedBCGD 等。(OpenReview)
本文工作由天津大学、西安电子科技大学以及鹏城实验室联合完成,作者团队包括 Junkang Liu、Yuanyuan Liu、Fanhua Shang、Hongying Liu、Jin Liu 和 Wei Feng 等。该团队长期关注联邦学习、优化算法与模型泛化理论,在 ICML、NeurIPS 等国际顶级会议和权威期刊上发表多篇相关成果。本篇 FedSWA / FedMoSWA 工作延续了他们在“高异质联邦学习 + 平坦最优 + 稳定收敛”方向上的研究思路,是其在 FL 泛化问题上的又一次系统性推进。
📄 论文地址
-
arXiv(预印本):
https://arxiv.org/abs/2507.20016 (arXiv) -
PDF 直链:
https://arxiv.org/pdf/2507.20016 (arXiv) -
ICML 2025 页面 / OpenReview 附件(会议版本 PDF):
- OpenReview PDF 附件:(OpenReview)
- ICML 2025 日程页中也列出了这篇论文:(ICML)
💻 开源代码(GitHub)
- FedSWA & FedMoSWA 官方代码仓库:
https://github.com/junkangLiu0/FedSWA (arXiv)
这个仓库里就包含 FedSWA / FedMoSWA 的实现,适合你直接跑实验或对照论文复现。
🌈 目录
- 一、FL 为什么难?真正的“痛点”是泛化
- 二、SAM 在高异质条件下为什么会失效?
- 三、SWA 算法到底做了什么?(超级易懂版)
- 四、FedSWA:把 SWA 引入联邦学习
- 五、FedMoSWA:加上动量控制后更稳更强
- 六、理论结果:泛化误差 & 收敛速度
- 七、实验:CNN + ViT 大幅提升泛化性能
- 八、如何调参?(来自论文的最佳实践)
- 九、消融实验:谁才是提升的关键?
- 十、总结:一个新的 FL 泛化范式
一、FL 为什么难?真正的“痛点”是泛化
联邦学习(Federated Learning, FL)允许多个客户端 不共享原始数据 协同训练模型,这在移动端、医疗、金融中极具价值。
但真正的难点是——每个客户端的数据分布完全不同(Non-IID):
- 📱 用户 A 大量拍猫
- 📱 用户 B 大量拍狗
- 📱 用户 C 数据很少
- 📱 用户 D 分布奇怪
于是服务器聚合后全局模型会出现:
训练能收敛,但泛化非常差。
原因在于客户端数据的差异让 FL 很容易掉进“每个客户端自己喜欢的尖锐最优点”,而服务器聚合后并不平坦。
联邦学习(Federated Learning, FL)让多个客户端在不上传原始数据的前提下协同训练一个全局模型,非常适合医疗、金融、移动端等对隐私要求极高的场景。
现实问题是:不同客户端的数据分布差异巨大(高度 Non-IID / 高异质):
- 有的客户端只有少量类别;
- 有的客户端数据量很少;
- 有的客户端分布和全局分布差很多。
结果就是:
即使训练损失下降,全局模型在测试集上的泛化能力依然很差,容易掉进某个“尖锐”的局部最优(sharp minima),跨客户端表现不稳定。
这篇 ICML 2025 的工作专门盯上了“高异质数据下的泛化问题”,提出了两个新算法:
- FedSWA:把 Stochastic Weight Averaging(SWA)引入联邦学习;
- FedMoSWA:在 FedSWA 上再加上动量式的随机控制变量,进一步对齐本地与全局更新方向。
二、SAM 在高异质条件下为什么会失效?
SAM(Sharpness-Aware Minimization)本意很好:
👉 寻找平坦解 → 提升泛化能力。
但在高异质 FL 中,它表现反而比 FedAvg 更差。
❌ 原因:SAM 找到的是“各自为战的平坦点”
每个客户端都在自己的数据集上进行:
“我附近哪里平坦?”
然而所有客户端的损失地形都不一样!
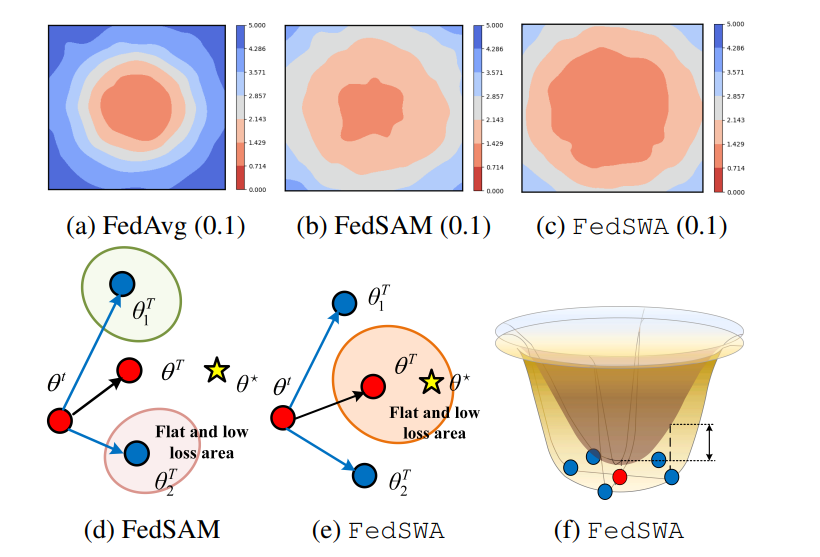
图 1 想说明两件事:
-
(a)(b)©:不同算法的“坑”不一样
- (a) FedAvg:全局模型落在一个尖锐的低谷,训练还行,但泛化差。
- (b) FedSAM:在高度异质数据(Dir-0.1)下反而更糟,找到的地方既不够平坦,loss 还高,测试精度最低。
- © FedSWA:找到的是又平坦又低的谷底,对应的测试精度最高(50.3% > 45.8% > 40.1%)。(arXiv)
-
(d)(e)(f):本地 vs 全局 & 训练 vs 测试
- 外层曲面 = 训练 loss,内层曲面 = 测试 loss。
- 蓝点 = 各客户端模型,红点 = 服务器全局模型。
- (d) 里 FedSAM:各客户端在自己数据上看起来“平坦”,但全局/测试上仍然“高、陡、泛化差”,本地平坦 ≠ 全局平坦。
- (e)(f) 里 FedSWA:全局模型落在一个对训练和测试都平坦且低的区域,客户端模型和服务器模型更一致,泛化误差(双箭头间的间隔)显著变小。(arXiv)
一句话概括:
图 1 用 loss 曲面可视化告诉你:FedSAM 在高异质下会“平坦错地方”,而 FedSWA 能在全局上找到真正平坦、泛化好的最优点。
在中心化训练中,**SAM(Sharpness-Aware Minimization)**已经被证明有利于找到更“平坦”的最优点,从而提升泛化。很多工作也把 SAM 搬到了联邦学习中,比如 FedSAM、MoFedSAM、FedASAM、FedLESAM 等。
但是论文作者发现一个“反直觉”的现象:
在 高数据异质性 场景下,FedSAM 的表现甚至 比普通 FedAvg 还差。
原因核心在于:
- SAM 在每个客户端上只是在“局部”寻找平坦点;
- 客户端之间的损失曲面差异巨大;
- 本地的“平坦点”汇总到服务器后,对全局来说可能既不平坦,loss 也不低。
论文中的可视化结果表明:
- FedAvg:收敛到尖锐的局部最优,测试泛化差;
- FedSAM:局部看似“平坦”,但全局损失面仍然很高,测试集表现很差;
- FedSWA:能找到对全局而言更平坦、损失更低的区域。
一句话总结:FedSAM 找到的是“各自为战”的本地平坦点,而不是大家都认可的全球平坦解。
最终服务器获得的是:
- A 客户端的平坦点
- B 客户端的平坦点
- C 客户端的平坦点
- ……
这些平坦点合起来 对全局模型不一定平坦,也不一定好!
所以 FedSAM、MoFedSAM 在高异质性下“翻车”。
三、SWA 算法到底做了什么?(超级易懂版)
这是本篇的重点补充!
SWA(Stochastic Weight Averaging)是 2018 由 Pavel Izmailov 提出的提升深度学习泛化的“超级简单但神奇”的技巧。
🎯 SWA 简而言之:
在训练后期,SGD 会在一大片好区域里晃来晃去,而不是停在中心点。
SWA 做的事情就是:
把这些“好点”全部平均一下。
如下图: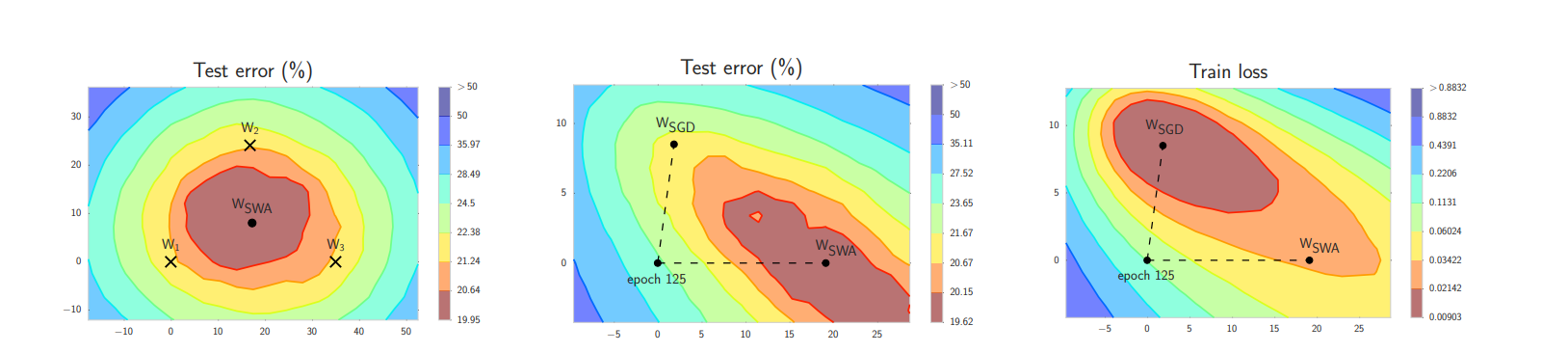
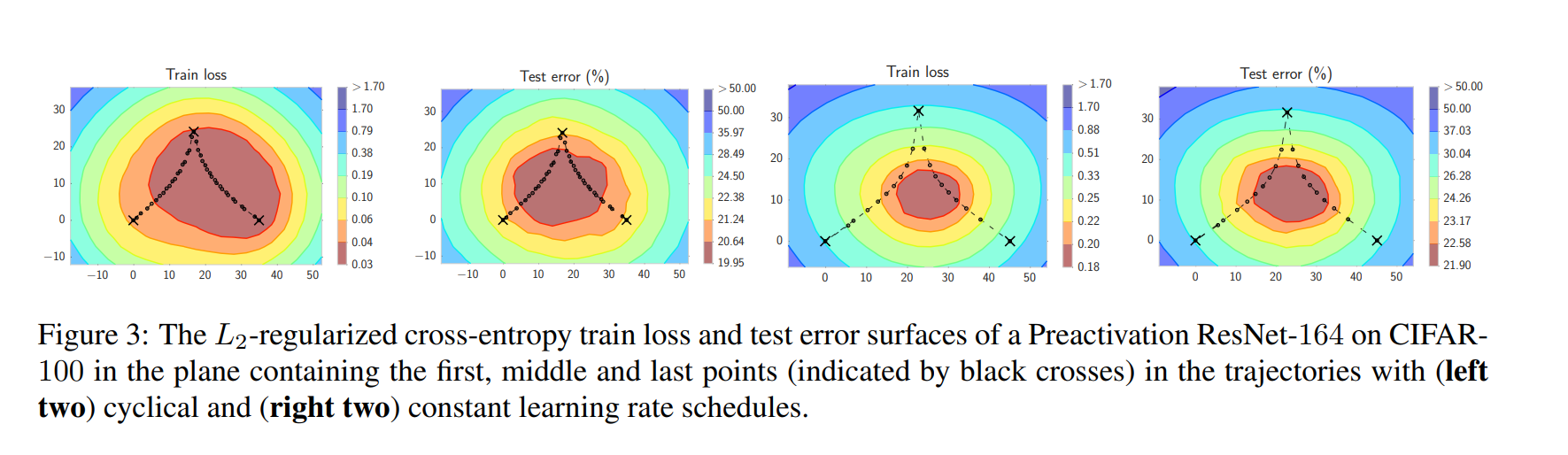

🌟 为什么 SWA 能提升泛化?
因为深度学习模型的损失地形非常复杂:
- 尖锐最优(sharp minima)泛化差
- 平坦最优(flat minima)泛化好
而 SGD 在后期会在“平坦区域附近弹跳”:
θ1 → θ2 → θ3 → … → θN
这些点虽然每个都不错,但都不是最中心。
如果你把它们平均:
θ_SWA = average(θ1, θ2, ..., θN)
就会到达区域的中心点,也更平坦、更稳定。
⏳ SWA 的学习率秘诀
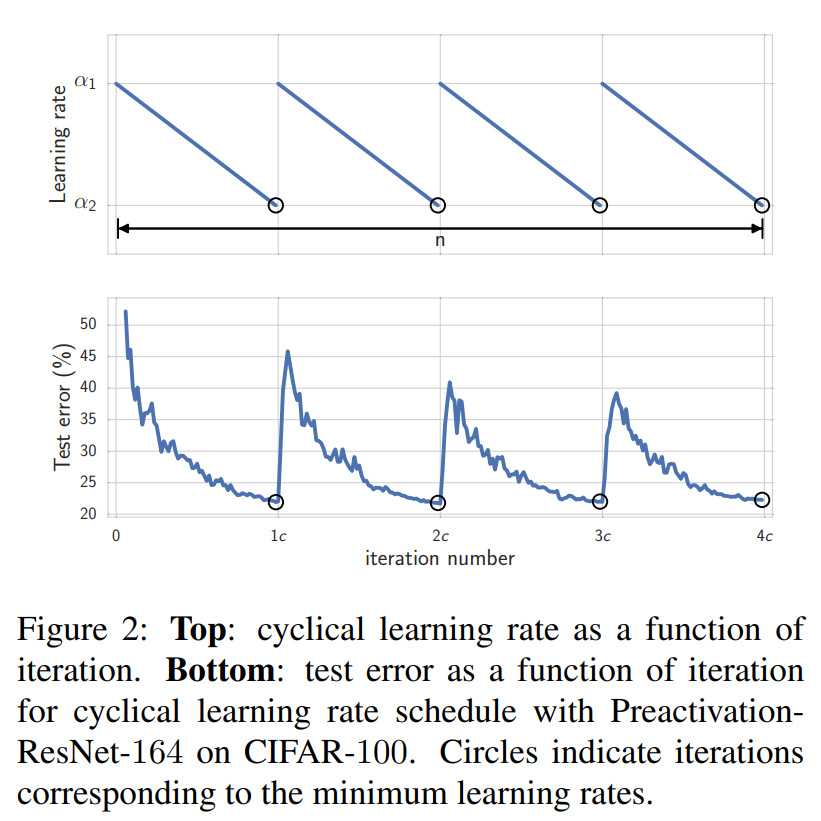
SWA 常用 周期性学习率(cyclic LR):
大 → 小 → 大 → 小 ……
每次“大”可以跳出局部最优,“小”可细调。
这与本文 FedSWA 完美对应。

四、FedSWA:在联邦学习中做“权重平均 + EMA 聚合”
4.1 基本目标
FedSWA 主要针对两个问题:
- 在高异质数据下找到“全局”的平坦最优点,而不是每个客户端各自平坦;
- 避免 FedSAM 那样的高计算开销(需要两次前向 + 两次反向)。
4.2 本地更新:带衰减的“周期性”学习率
论文在客户端采用了一个逐步线性衰减的局部学习率策略:
记第 (t) 轮的第 (k) 次本地迭代学习率为 (\eta^t_k):
η 0 t = η l , η K t = ρ η l , η k t = η l ( 1 − k K ) + k K ρ η l \eta^t_0 = \eta_l,\quad \eta^t_K = \rho \eta_l,\quad \eta^t_k = \eta_l\left(1 - \frac{k}{K}\right) + \frac{k}{K} \rho \eta_l η0t=ηl,ηKt=ρηl,ηkt=ηl(1−Kk)+Kkρηl
其中:
- η l \eta_l ηl:本地初始学习率;
- K K K:本地总步数;
- ρ ∈ [ 0 , 1 ] \rho\in[0,1] ρ∈[0,1]:衰减系数,越小衰减越快。
本地参数更新很标准:
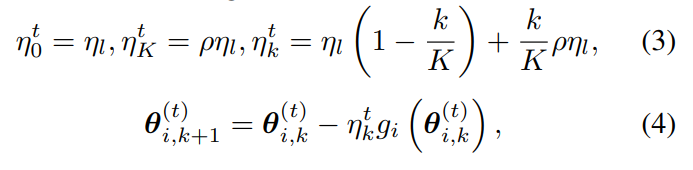
其中 (g_i(\cdot)) 是基于 mini-batch 的梯度。
直观上:局部采用类似“周期性/退火”学习率,每一轮从大步长慢慢走到小步长,然后在下一轮又重启大 lr,便于跳出差的局部最优。
4.3 服务器端:用 EMA 而不是简单平均
和 FedAvg 直接做简单平均不同,FedSWA 在服务器端使用**指数滑动平均(EMA)**来整合历史模型:
记第 (t) 轮客户端上传的平均模型为:
v t = 1 s ∑ i = 1 s θ i , K ( t ) v_t = \frac{1}{s}\sum_{i=1}^s \theta_{i,K}^{(t)} vt=s1i=1∑sθi,K(t)
服务器参数更新为:
θ t = θ t − 1 + α ( v t − θ t − 1 ) \theta_t = \theta_{t-1} + \alpha (v_t - \theta_{t-1}) θt=θt−1+α(vt−θt−1)
其中 α > 0 \alpha > 0 α>0 是“外层步长”, a l p h a > 1 alpha > 1 alpha>1 时类似 LookAhead/加速更新,(\alpha=1) 退化为普通平均。
对比 FedAvg / FedSAM:
-
FedAvg / FedSAM:
- 本地学习率通常固定;
- 服务器直接做简单平均。
-
FedSWA:
- 本地使用“下降 + 重启”的学习率;
- 服务器用 EMA 聚合,能更稳定地走向更平坦的区域。
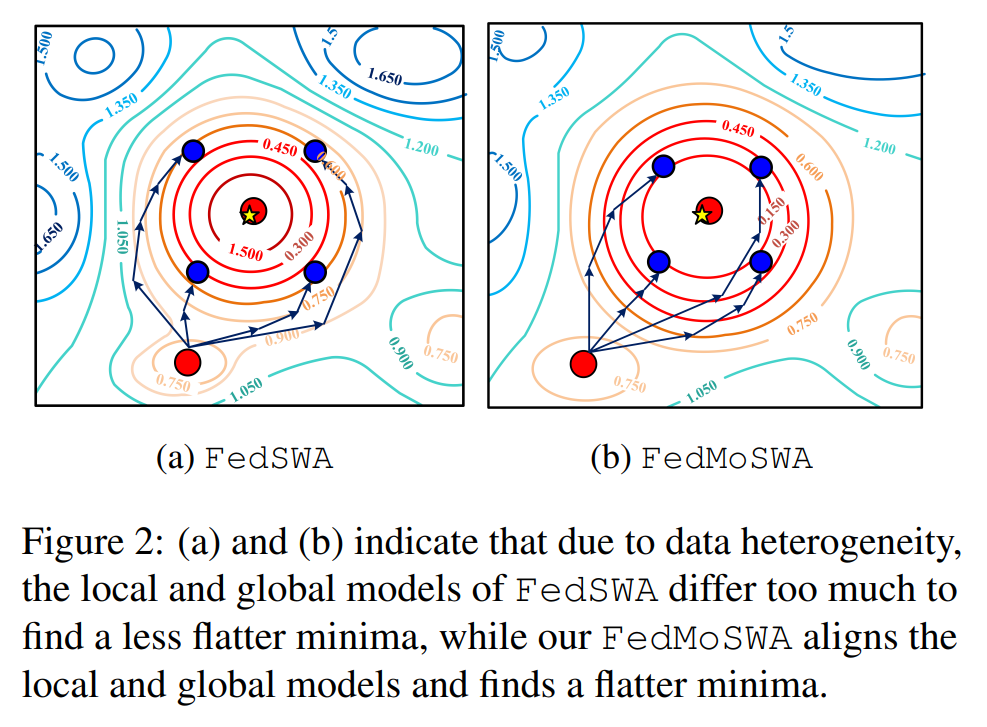
五、FedMoSWA:用“动量式控制变量”对齐本地和全局
仅有 FedSWA 还不够,因为:
即使全局模型在平坦区域,本地模型也可能漂得很远,特别是高度异质数据下。
5.1 加入控制变量 c i , m c_i, m ci,m
FedMoSWA 在每个客户端引入一个本地控制变量 c i c_i ci,在服务器端引入全局控制变量 m m m:
本地更新变为:
θ i , k + 1 ( t ) = θ i , k ( t ) − η k t ( g i ( θ i , k ( t ) ) − c i + m ) \theta_{i,k+1}^{(t)} = \theta_{i,k}^{(t)} - \eta_k^t \big(g_i(\theta_{i,k}^{(t)}) - c_i + m\big) θi,k+1(t)=θi,k(t)−ηkt(gi(θi,k(t))−ci+m)
- c i c_i ci:刻画客户端 (i) 的“偏移趋势”;
- m m m:服务器对整体更新方向的“动量估计”。
与 SCAFFOLD 的差别在于:
SCAFFOLD 的全局控制变量更新对新旧客户端用相同权重,当参与率低时会产生严重“延迟”;
FedMoSWA 则采用类似动量的更新方式:
m ← m + γ ⋅ 1 s ∑ i ∈ S ( c i + − m ) m \leftarrow m + \gamma \cdot \frac{1}{s}\sum_{i \in S} (c_i^+ - m) m←m+γ⋅s1i∈S∑(ci+−m)
* γ \gamma γ:动量系数,给新上传的客户端更多权重,降低旧信息的影响。
5.2 控制变量的两种更新方式
论文给了两个选项来更新 (c_i^+):
-
选项 I(更稳定)
直接用当前轮的全局梯度估计:
c i + ← g i ( θ ( t ) ) c_i^+ \leftarrow g_i(\theta^{(t)}) ci+←gi(θ(t)) -
选项 II(低开销,论文默认)
用本地历史步的参数差来近似:
c i + ← c i − m + ∑ k η k t ( θ t − 1 − θ i , k ( t ) ) c_i^+ \leftarrow c_i - m + \sum_k \eta_k^t (\theta_{t-1} - \theta_{i,k}^{(t)}) ci+←ci−m+k∑ηkt(θt−1−θi,k(t))
实验中作者使用的是 选项 II,在保持收敛稳定的同时更省计算。
直觉理解:
- (c_i) 记录客户端的“个性偏移”;
- (m) 是服务器对全局更新方向的一个“动量估计”;
- ((m - c_i)) 则是用来纠正本地更新方向的偏差,从而让本地优化更贴近全局目标。
六、理论结果:泛化误差 & 收敛速度



作者用**统一稳定性(Uniform Stability)**来分析泛化误差,并且给出了 non-convex 场景下的具体上界形式。
6.1 泛化误差分解
经典泛化误差分解:
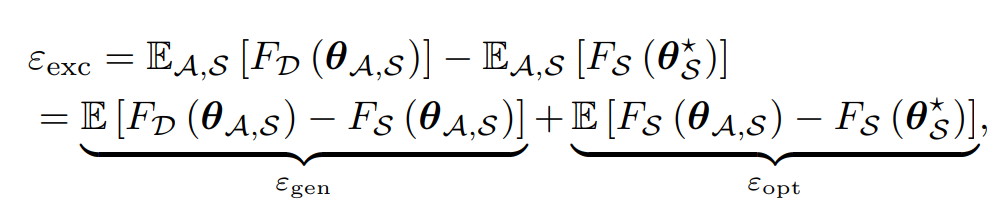
- ( ε gen ) (\varepsilon_{\text{gen}}) (εgen):泛化误差(经验风险 vs. 真实风险);
- ( ε opt ) (\varepsilon_{\text{opt}}) (εopt):优化误差(估计解 vs. 经验最优)。
6.2 非凸情形下的泛化比较(重点)
在非凸场景(深度网络常见)下,论文给出的结论大致如下(略去常数与细节):
- FedSAM 的泛化误差上届含有一个比较大的系数 ©,并且和数据异质性 (\sigma_g) 紧密相关;
- FedSWA:用一个更小的 (\tilde{c}) 替换了 ©,使得和 (\sigma_g) 相关的项更小;
- FedMoSWA:进一步把第二项中和 (\sigma_g) 相关的系数从 (\tilde{c}\sigma_g) 降到“纯 (\sigma_g)”,理论上显著减弱了数据异质性的影响。
两个关键点:
- m(客户端数)和 mn(总样本量)越大,泛化误差越小;
- 局部迭代步数 K 太多反而会伤泛化,这与实践中“局部 epoch 太多会引起 client drift”现象一致。
6.3 优化误差:FedMoSWA 收敛速度优于同类方法
在优化误差上,论文证明:
-
FedMoSWA 在强凸和非凸场景下都可达到较优的收敛速度;
-
与 SCAFFOLD 相比,FedMoSWA 的优化误差上界中对客户端数 (m) 的依赖更友好;
-
收敛速度会随:
- 更多客户端参与(s 增大);
- 本地迭代次数 K 合理增大;
- 动量参数 α \alpha α 调整合适
而加快。
七、实验:CNN + ViT 大幅提升泛化性能
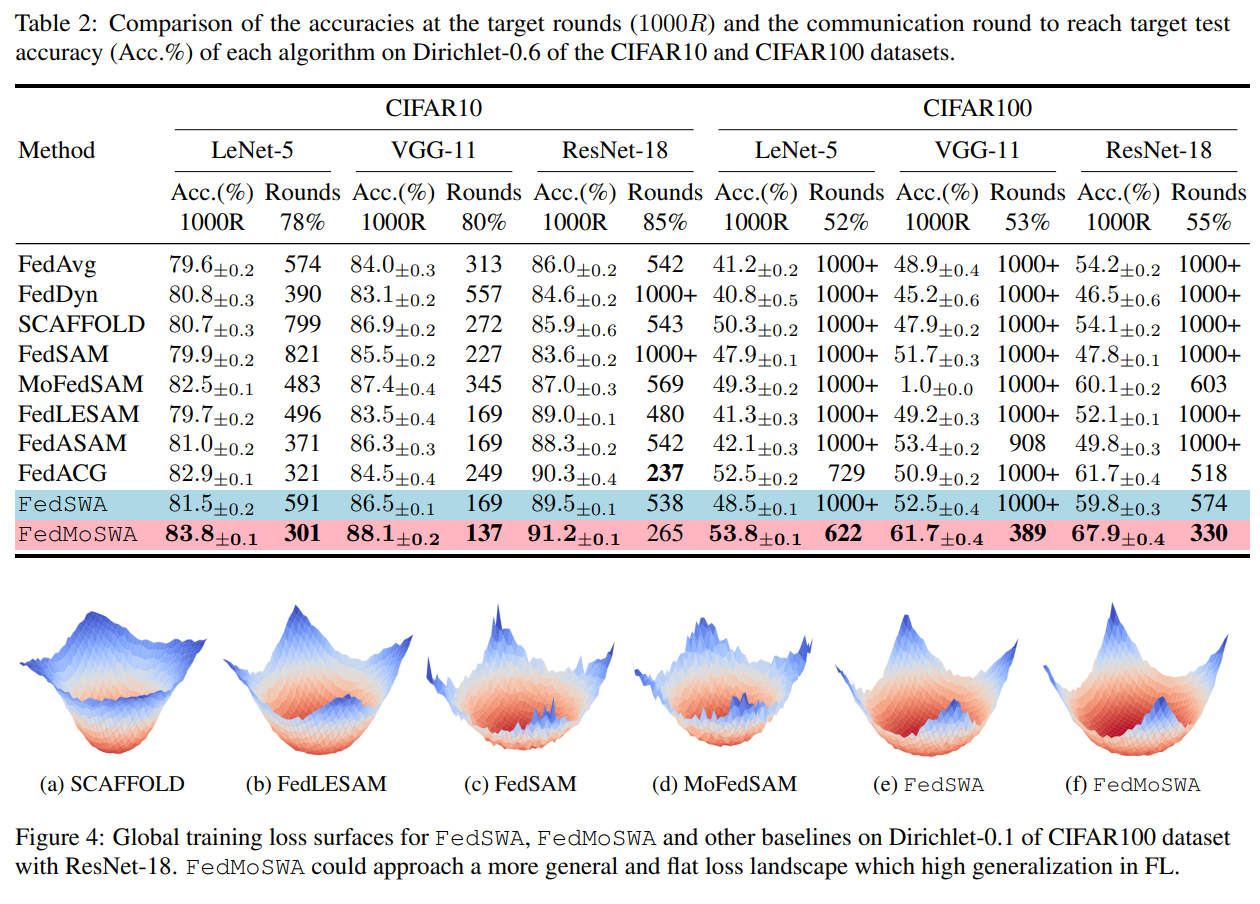
论文使用:
- CIFAR10 / CIFAR100
- Tiny ImageNet
- ResNet-18 / VGG-11 / LeNet-5
- ViT-Base(大模型!)
结果亮点:
🔥 1)CIFAR100 + ResNet-18 + Dirichlet=0.1(极高异质性)
FedMoSWA 相比 MoFedSAM:
+10.4% 精度提升
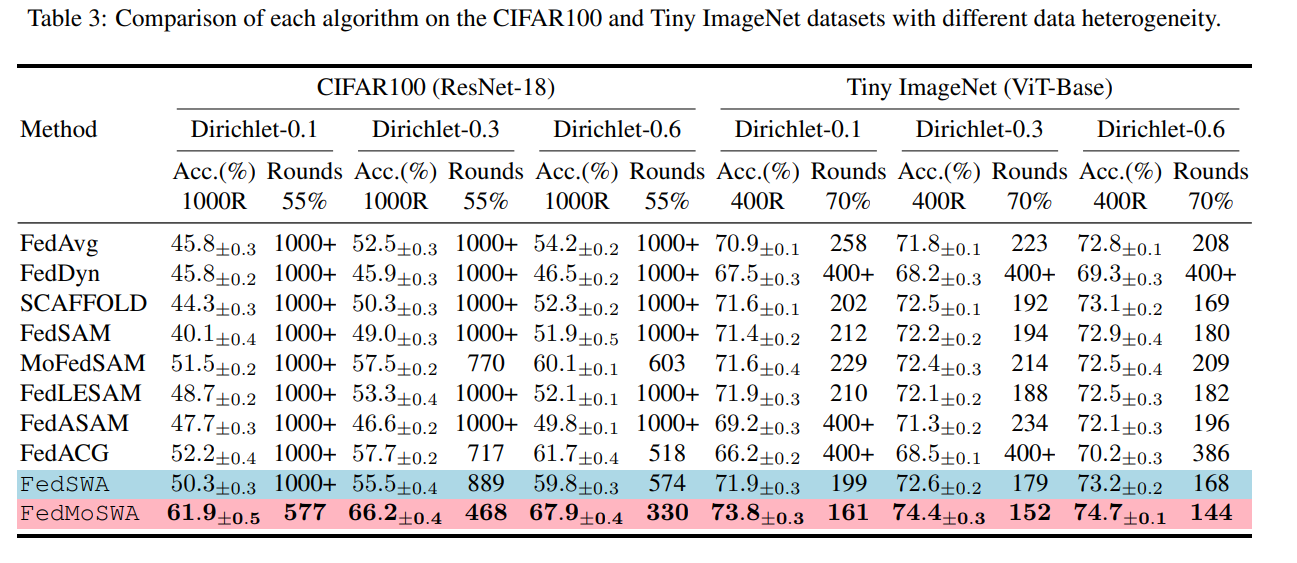
🔥 2)Tiny ImageNet + ViT-Base
大模型依然提升显著:
- 最终精度最高
- 收敛速度快
- loss landscape 最平坦
八、如何调参?(来自论文的最佳实践)
| 参数 | 推荐值 | 原因 |
|---|---|---|
| α(服务器 EMA 步长) | 1.5 | 加速收敛又不至于震荡 |
| γ(动量系数) | 0.2 | 全局动量足够强,更新更平滑 |
| ρ(学习率衰减比) | 0.1 | 周期性学习率效果最佳 |
九、消融实验:谁才是提升的关键?
实验展示:
- SWA 单独使用(FedSWA)就能大幅提升泛化性能
- 动量控制变量(FedMo)单独使用也能显著对抗 Non-IID
- 二者结合(FedMoSWA)提升最大
十、总结:一个新的 FL 泛化范式
FedMoSWA 的贡献可以总结为:
🧩 1)SWA 让全局模型更“平坦”
- 更好的泛化
- 更低的测试误差
- 更稳的 loss landscape
🧩 2)动量控制让客户端不乱跑
- 本地更新方向更一致
- 客户端漂移显著减少
- 在极端 Non-IID 下依然稳定
🧩 3)理论完善 + 实验全面
- 泛化误差显著降低
- CNN / ViT / CIFAR / TinyImageNet 全面验证
- 与最强的 FedSAM / MoFedSAM / FedLESAM 均拉开差距

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)