深入理解余弦退火:让模型训练更高效的学习率调度策略
摘要:余弦退火学习率调度策略通过模拟余弦曲线实现学习率平滑衰减,解决了固定学习率训练中的收敛问题。该策略结合Warmup(预热)机制,先线性升温再余弦降温,能有效提升模型训练稳定性。相比传统阶梯式下降,余弦退火具有过渡平滑、能逃离局部最优等优势,特别适用于大型模型微调和长周期训练任务。PyTorch提供了现成实现,配合5%-10%的Warmup步数和合理的最小学习率设置,可显著提升各类深度学习任务
在深度学习训练中,学习率是最重要的超参数之一。合适的学习率调度策略能帮助模型更快收敛、避开局部最优解,而余弦退火(Cosine Annealing) 正是近年来备受青睐的调度方法。本文将从原理、实现到应用,全面解析这一策略。
一、为什么需要学习率调度?
固定学习率的训练存在明显缺陷:
- 初始学习率过大会导致模型震荡,难以收敛;
- 后期学习率过小会导致收敛速度缓慢,甚至陷入局部最优。
学习率调度的核心思想是:在训练过程中动态调整学习率—— 前期用较大的学习率快速探索参数空间,后期用较小的学习率精细优化。
二、余弦退火的核心原理
余弦退火由 Loshchilov 和 Hutter 在 2016 年的论文《SGDR: Stochastic Gradient Descent with Warm Restarts》中提出,其灵感来源于模拟退火算法:像金属冷却过程一样,让学习率随时间按余弦曲线平滑衰减。
1. 数学公式
余弦退火的学习率更新公式如下:
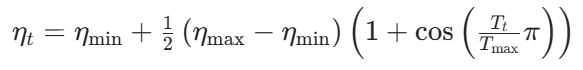
其中:

2. 直观理解

整个过程中,学习率从最大值平滑地余弦衰减到最小值,避免了阶梯式下降的剧烈波动。
三、带 Warmup 的余弦退火:更实用的改进
在实际训练中,直接使用余弦退火可能存在初始阶段不稳定的问题(尤其是大型模型)。因此,常结合Warmup(热身) 策略,形成 "先升温、后降温" 的调度曲线。
1. 实现逻辑
def lr_lambda(current_step):
warmup_steps = 1000 # 热身步数
if current_step < warmup_steps:
# 第一阶段:线性升温(从0到最大学习率)
return float(current_step) / float(max(1, warmup_steps))
else:
# 第二阶段:余弦退火(从最大学习率衰减到0)
progress = float(current_step - warmup_steps) / float(
max(1, total_steps - warmup_steps)
)
return 0.5 * (1. + math.cos(math.pi * progress))2. 曲线特点
- Warmup 阶段(前 1000 步):学习率从 0 线性增加到预设最大值,避免初始梯度过大导致模型震荡。
- 余弦退火阶段:学习率按余弦曲线平滑衰减,让模型在后期精细优化参数。
四、余弦退火的优势与适用场景
核心优势
- 平滑过渡:相比阶梯式衰减(如 StepLR),余弦退火的学习率变化更连续,减少训练波动。
- 逃离局部最优:缓慢的衰减过程给模型更多机会探索参数空间,可能找到更优解。
- 通用性强:适用于各类神经网络(CNN、Transformer 等)和任务(分类、检测、生成等)。
适用场景
- 大型预训练模型微调(如 BERT、CLIP)
- 数据量较大、训练周期较长的任务
- 对收敛稳定性要求高的场景(如多模态学习、迁移学习)
五、PyTorch 中的余弦退火实现
PyTorch 提供了两种常用的余弦退火调度器:
| 调度器 | 特点 |
|---|---|
CosineAnnealingLR |
基础版余弦退火,需指定周期步数\(T_{\text{max}}\) |
CosineAnnealingWarmRestarts |
带重启的余弦退火(多个周期,每次重启学习 |
基础用法示例
import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 定义余弦退火调度器(T_max为周期步数,eta_min为最小学习率)
scheduler = CosineAnnealingLR(optimizer, T_max=10000, eta_min=0)
# 训练循环中更新
for epoch in range(epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step() # 每步更新学习率六、实践建议
-
参数设置:
- Warmup 步数:通常取总步数的 5%~10%(如 1000~5000 步)
- 最小学习率:可为最大值的 1/10~1/100,或直接设为 0
- 总周期:根据任务调整,建议至少覆盖完整训练过程
-
与其他策略结合:
- 可搭配分层学习率(如不同层使用不同初始学习率)
- 大型模型训练中,可结合梯度裁剪(Gradient Clipping)进一步提升稳定性
-
监控与调优:
- 训练过程中记录学习率变化曲线和损失曲线,观察是否匹配预期
- 若后期损失下降缓慢,可适当调大最小学习率
总结
余弦退火通过模拟余弦函数的平滑衰减特性,有效平衡了模型训练的 "探索" 与 "收敛" 需求。结合 Warmup 策略后,更能适应复杂场景下的训练需求。在实际应用中,合理配置余弦退火参数,往往能带来模型性能的显著提升 —— 这也是它成为现代深度学习训练标配策略的核心原因。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)