大模型开发步骤和示例
这个框架提供了大模型开发的基本结构,实际应用中需要根据具体需求调整和扩展。生成式/分类/视觉/多模态。公开数据/专业数据公司。基于人类反馈的强化学习。
·
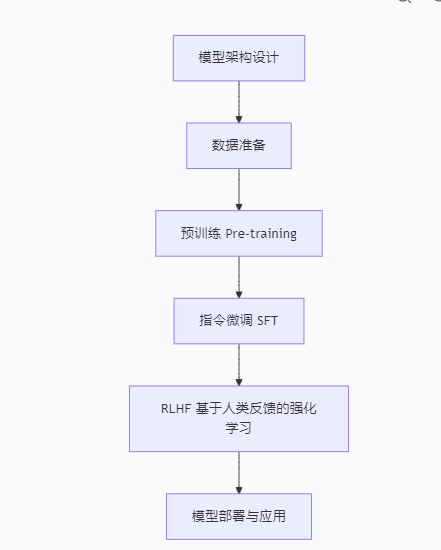
大模型开发步骤
1. 模型架构设计
- 根据需求选择合适的算法和模型类型,例如:
- 生成式模型(如GPT系列)
- 分类模型
- 视觉或多模态模型
2. 数据准备(模型语料)
- 使用大规模数据进行模型训练,数据来源包括:
- 互联网公开数据
- 专业数据公司提供的高质量语料
- 支持 NLP、跨模态(文本、图像、音频等)处理
3. 预训练(Pre-training)
- 使用大量无标注数据进行初步训练,使模型初步具备通用能力
- 训练过程中进行效果评估,使用各类测试数据集验证模型性能
4. 指令微调(SFT,Supervised Fine-Tuning)
- 使用高质量、人工标注的数据进行有监督微调
- 特别注重各行业专业知识,提升模型在特定领域的理解与回答能力
5. 基于人类反馈的强化学习(RLHF)
- 通过人类对模型输出的反馈,训练一个奖励模型
- 利用强化学习算法(如PPO)优化模型参数
- 使模型输出更符合人类偏好(如流畅性、安全性、有用性等)
大模型开发步骤示意图与代码示例
一、流程图(使用Mermaid绘制)
二、代码示例(PyTorch伪代码框架)
1. 模型架构设计示例
import torch
import torch.nn as nn
from transformers import AutoModel, AutoTokenizer
class CustomLLM(nn.Module):
"""
自定义大语言模型架构示例
"""
def __init__(self, model_name="bert-base-uncased", num_classes=None):
super().__init__()
# 加载预训练基础模型
self.base_model = AutoModel.from_pretrained(model_name)
hidden_size = self.base_model.config.hidden_size
# 根据任务添加自定义层
if num_classes:
self.classifier = nn.Sequential(
nn.Linear(hidden_size, 512),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(512, num_classes)
)
else:
# 生成式模型
self.lm_head = nn.Linear(hidden_size, self.base_model.config.vocab_size)
def forward(self, input_ids, attention_mask=None):
outputs = self.base_model(input_ids, attention_mask=attention_mask)
if hasattr(self, 'classifier'):
# 分类任务
return self.classifier(outputs.last_hidden_state[:, 0, :])
else:
# 生成任务
return self.lm_head(outputs.last_hidden_state)
2. 数据准备示例
import datasets
from datasets import Dataset, DatasetDict
import pandas as pd
class DataPreprocessor:
"""数据预处理类"""
def __init__(self, tokenizer, max_length=512):
self.tokenizer = tokenizer
self.max_length = max_length
def prepare_pretraining_data(self, text_data):
"""准备预训练数据"""
def tokenize_function(examples):
return self.tokenizer(
examples["text"],
truncation=True,
padding="max_length",
max_length=self.max_length,
return_special_tokens_mask=True
)
dataset = Dataset.from_dict({"text": text_data})
tokenized_dataset = dataset.map(tokenize_function, batched=True)
return tokenized_dataset
def prepare_sft_data(self, instructions, responses):
"""准备SFT微调数据"""
def format_sft_example(instruction, response):
return f"Instruction: {instruction}\nResponse: {response}"
formatted_data = [
format_sft_example(i, r)
for i, r in zip(instructions, responses)
]
return self.prepare_pretraining_data(formatted_data)
3. 预训练流程示例
class Pretrainer:
"""预训练器"""
def __init__(self, model, tokenizer, device="cuda"):
self.model = model.to(device)
self.tokenizer = tokenizer
self.device = device
def pretrain_step(self, batch):
"""预训练单步"""
inputs = {
"input_ids": batch["input_ids"].to(self.device),
"attention_mask": batch["attention_mask"].to(self.device),
"labels": batch["input_ids"].to(self.device) # 自回归任务
}
outputs = self.model(**inputs)
loss = outputs.loss if hasattr(outputs, 'loss') else outputs[0]
return loss
def train_epoch(self, dataloader, optimizer):
"""训练一个epoch"""
self.model.train()
total_loss = 0
for batch in dataloader:
optimizer.zero_grad()
loss = self.pretrain_step(batch)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
4. SFT微调示例
class SFTTrainer:
"""SFT指令微调训练器"""
def __init__(self, model, tokenizer, device="cuda"):
self.model = model.to(device)
self.tokenizer = tokenizer
self.device = device
def compute_sft_loss(self, batch):
"""计算SFT损失"""
# 假设batch包含input_ids, attention_mask, labels
inputs = {
key: value.to(self.device)
for key, value in batch.items()
if key in ["input_ids", "attention_mask", "labels"]
}
outputs = self.model(**inputs)
return outputs.loss
def fine_tune(self, train_dataloader, val_dataloader, epochs=3, lr=1e-5):
"""微调过程"""
optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
for epoch in range(epochs):
# 训练阶段
self.model.train()
train_loss = 0
for batch in train_dataloader:
optimizer.zero_grad()
loss = self.compute_sft_loss(batch)
loss.backward()
optimizer.step()
train_loss += loss.item()
# 验证阶段
val_loss = self.evaluate(val_dataloader)
print(f"Epoch {epoch+1}: Train Loss = {train_loss/len(train_dataloader):.4f}, "
f"Val Loss = {val_loss:.4f}")
5. RLHF框架示例
class RLHFTrainer:
"""RLHF训练器(简化版)"""
def __init__(self, policy_model, reward_model, device="cuda"):
self.policy_model = policy_model.to(device)
self.reward_model = reward_model.to(device)
self.device = device
def collect_responses(self, prompts, num_samples=4):
"""收集模型对同一提示的多个响应"""
responses = []
for prompt in prompts:
# 使用不同采样策略生成多个响应
for _ in range(num_samples):
response = self.generate_response(prompt, temperature=0.7)
responses.append({
"prompt": prompt,
"response": response,
"score": None # 等待奖励模型评分
})
return responses
def compute_rewards(self, responses):
"""使用奖励模型计算响应得分"""
scored_responses = []
for item in responses:
# 奖励模型评分(简化示例)
score = self.reward_model.score_response(
item["prompt"],
item["response"]
)
item["score"] = score
scored_responses.append(item)
return scored_responses
def rlhf_step(self, scored_responses):
"""RLHF优化步骤"""
# 这里简化了PPO等强化学习算法的实现
# 实际使用中会使用TRL(Transformer Reinforcement Learning)等库
# 1. 计算优势函数
advantages = self.compute_advantages(scored_responses)
# 2. 策略梯度更新
loss = self.policy_gradient_loss(scored_responses, advantages)
return loss
def train(self, prompts, iterations=100):
"""RLHF训练循环"""
for i in range(iterations):
# 收集响应
responses = self.collect_responses(prompts)
# 奖励模型评分
scored_responses = self.compute_rewards(responses)
# RL优化
loss = self.rlhf_step(scored_responses)
print(f"Iteration {i+1}: RLHF Loss = {loss:.4f}")
6. 完整训练流程示例
def full_training_pipeline():
"""完整的大模型训练流程"""
# 1. 初始化
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = CustomLLM(model_name="bert-base-uncased")
# 2. 数据准备
preprocessor = DataPreprocessor(tokenizer)
# 预训练数据
pretrain_texts = [...] # 大量无标注文本
pretrain_dataset = preprocessor.prepare_pretraining_data(pretrain_texts)
# SFT数据
instructions = [...] # 指令数据
responses = [...] # 对应响应
sft_dataset = preprocessor.prepare_sft_data(instructions, responses)
# 3. 预训练
pretrainer = Pretrainer(model, tokenizer)
pretrain_dataloader = DataLoader(pretrain_dataset, batch_size=16, shuffle=True)
print("开始预训练...")
for epoch in range(10):
loss = pretrainer.train_epoch(pretrain_dataloader, optimizer)
print(f"预训练 Epoch {epoch+1}: Loss = {loss:.4f}")
# 4. SFT微调
sft_trainer = SFTTrainer(model, tokenizer)
sft_dataloader = DataLoader(sft_dataset, batch_size=8, shuffle=True)
print("开始SFT微调...")
sft_trainer.fine_tune(sft_dataloader, sft_dataloader, epochs=3)
# 5. RLHF训练(简化示例)
print("开始RLHF训练...")
# 这里需要初始化奖励模型和RLHF训练器
# rlhf_trainer = RLHFTrainer(model, reward_model)
# rlhf_trainer.train(prompts, iterations=50)
# 6. 保存模型
model.save_pretrained("./final_model")
tokenizer.save_pretrained("./final_model")
print("模型训练完成!")
# 运行训练流程
if __name__ == "__main__":
full_training_pipeline()
三、关键说明
-
实际开发建议:
- 使用成熟的库(如Hugging Face Transformers、TRL、DeepSpeed)
- 预训练需要大规模分布式训练
- RLHF实现复杂,建议使用TRL等专门库
-
资源需求:
- 预训练:需要大量GPU资源(数十到数千张卡)
- SFT:相对较少资源,但需要高质量标注数据
- RLHF:中等资源,需要奖励模型和策略优化
-
实用工具推荐:
- Hugging Face Transformers
- Hugging Face TRL(Transformer Reinforcement Learning)
- DeepSpeed(分布式训练)
- Weights & Biases(实验跟踪)
这个框架提供了大模型开发的基本结构,实际应用中需要根据具体需求调整和扩展。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)