迷宫最短路径搜索算法详解 - A*算法实现
本文介绍了A算法在路径搜索问题中的应用。A算法结合了Dijkstra算法的最优性和贪心搜索的高效性,通过评估函数f(n)=g(n)+h(n)指导搜索方向。文章详细阐述了算法原理、启发式函数选择(曼哈顿/欧几里得距离)及其可采纳性条件,并提供了Python实现代码,包括节点类设计、优先队列使用和路径重构方法。通过可视化演示展示了算法在迷宫问题中的实际应用,对比了不同启发式函数的性能差异。A*算法凭借

📚 目录
算法概述
什么是路径搜索问题?
路径搜索问题是在一个图或网格中找到从起点到终点的最短路径的问题。在迷宫问题中,我们需要在一个包含障碍物的网格中找到从起点到终点的最短路径。
为什么选择A*算法?
A*算法是目前最先进且广泛使用的启发式搜索算法之一,它具有以下优势:
- 最优性保证:在启发式函数满足一定条件时,A*算法保证找到最短路径
- 高效性:通过启发式函数引导搜索方向,比盲目搜索(如BFS)更高效
- 灵活性:可以适应不同的启发式函数,平衡搜索速度和路径质量
- 广泛应用:在游戏AI、机器人导航、GPS路径规划等领域都有应用
与其他算法的对比
| 算法 | 时间复杂度 | 空间复杂度 | 是否最优 | 特点 |
|---|---|---|---|---|
| A* | O(b^d) | O(b^d) | ✅ 是 | 启发式搜索,高效且最优 |
| Dijkstra | O(V²) | O(V) | ✅ 是 | 无启发式,可能探索更多节点 |
| BFS | O(V+E) | O(V) | ✅ 是 | 广度优先,盲目搜索 |
| DFS | O(V+E) | O(V) | ❌ 否 | 深度优先,不保证最短 |
A*算法原理
核心思想
A*算法结合了Dijkstra算法的最优性和贪心最佳优先搜索的高效性。它通过评估函数 f(n) = g(n) + h(n) 来决定下一个要探索的节点:
- g(n):从起点到节点n的实际代价(已走过的距离)
- h(n):从节点n到终点的启发式估计代价(预计剩余距离)
- f(n):节点的总评估值,用于优先级排序
算法流程
1. 初始化:
- 将起点加入开放列表(优先队列)
- 设置起点的 g = 0,计算 h 和 f
2. 主循环:
while 开放列表不为空:
a. 取出 f 值最小的节点作为当前节点
b. 如果当前节点是终点,重构路径并返回
c. 将当前节点移入关闭列表
d. 遍历当前节点的所有邻居:
- 如果邻居在关闭列表中,跳过
- 计算从起点到邻居的新代价 tentative_g
- 如果找到更好的路径(tentative_g < 已知的g值):
* 更新邻居的 g 值
* 计算 h 值
* 设置父节点
* 将邻居加入开放列表
3. 如果开放列表为空仍未找到路径,返回无解
启发式函数
启发式函数 h(n) 的选择至关重要:
1. 曼哈顿距离(Manhattan Distance)
h(n) = |x1 - x2| + |y1 - y2|
- 适用场景:只能上下左右移动的网格
- 优点:计算简单,满足可采纳性(admissible)
- 特点:在网格中是最常用的启发式函数
2. 欧几里得距离(Euclidean Distance)
h(n) = √((x1 - x2)² + (y1 - y2)²)
- 适用场景:可以任意方向移动
- 优点:更精确的估计
- 缺点:计算稍慢
3. 切比雪夫距离(Chebyshev Distance)
h(n) = max(|x1 - x2|, |y1 - y2|)
- 适用场景:可以八方向移动(包括对角线)
可采纳性(Admissibility)
一个启发式函数是可采纳的(admissible),当且仅当它永远不会高估从当前节点到目标的实际代价。这保证了A*算法能找到最优解。
曼哈顿距离在只能四方向移动的网格中是可采纳的,因为:
- 实际最短路径 ≥ 曼哈顿距离(不能走直线,必须绕行)
算法实现
核心数据结构
1. 节点类(Node)
@dataclass
class Node:
x: int # 节点x坐标
y: int # 节点y坐标
g: float = 0.0 # 从起点到当前节点的实际代价
h: float = 0.0 # 从当前节点到终点的启发式估计
parent: Optional['Node'] = None # 父节点(用于重构路径)
@property
def f(self) -> float:
"""总代价 f = g + h"""
return self.g + self.h
2. 优先队列
使用Python的heapq模块实现最小堆,按f值排序:
import heapq
open_set = []
heapq.heappush(open_set, node) # 添加节点
current = heapq.heappop(open_set) # 取出f值最小的节点
完整实现代码
def solve(self) -> Optional[List[Tuple[int, int]]]:
"""使用A*算法求解最短路径"""
start_node = Node(self.start[0], self.start[1], g=0.0)
start_node.h = self._heuristic(*self.start, *self.end)
# 开放列表(优先队列)
open_set = [start_node]
heapq.heapify(open_set)
# 已访问节点集合
closed_set: Set[Tuple[int, int]] = set()
# 记录每个节点的最佳g值
g_scores = {self.start: 0.0}
while open_set:
# 取出f值最小的节点
current = heapq.heappop(open_set)
# 如果到达终点
if (current.x, current.y) == self.end:
# 重构路径
path = []
node = current
while node:
path.append((node.x, node.y))
node = node.parent
return path[::-1] # 反转路径
# 将当前节点加入关闭列表
closed_set.add((current.x, current.y))
# 检查所有邻居
for nx, ny in self._get_neighbors(current.x, current.y):
if (nx, ny) in closed_set:
continue
# 计算从起点到邻居节点的代价
tentative_g = current.g + 1.0
# 如果找到更好的路径
if (nx, ny) not in g_scores or tentative_g < g_scores[(nx, ny)]:
g_scores[(nx, ny)] = tentative_g
h = self._heuristic(nx, ny, *self.end)
neighbor_node = Node(nx, ny, g=tentative_g, h=h, parent=current)
heapq.heappush(open_set, neighbor_node)
return None # 无解
关键实现细节
1. 路径重构
通过父节点指针从终点回溯到起点:
path = []
node = current # 从终点开始
while node:
path.append((node.x, node.y))
node = node.parent
return path[::-1] # 反转得到从起点到终点的路径
2. 避免重复探索
使用g_scores字典记录每个节点的最佳g值,只有当找到更短的路径时才更新:
if (nx, ny) not in g_scores or tentative_g < g_scores[(nx, ny)]:
# 更新节点
3. 邻居节点获取
在网格中,通常考虑四个方向(上下左右):
def _get_neighbors(self, x: int, y: int) -> List[Tuple[int, int]]:
neighbors = []
directions = [(-1, 0), (1, 0), (0, -1), (0, 1)] # 上、下、左、右
for dx, dy in directions:
nx, ny = x + dx, y + dy
if 0 <= nx < self.height and 0 <= ny < self.width:
if self.maze[nx, ny] != CellType.WALL.value:
neighbors.append((nx, ny))
return neighbors
可视化演示
注意:本项目已配置中文字体支持,可视化图片中的中文标题、标签和图例均可正常显示。代码会自动检测系统可用的中文字体(Windows: SimHei/Microsoft YaHei, macOS: PingFang SC, Linux: WenQuanYi Micro Hei)。
示例1:简单迷宫
下面是一个20×20的简单迷宫示例,展示了A*算法的搜索过程和最终路径:
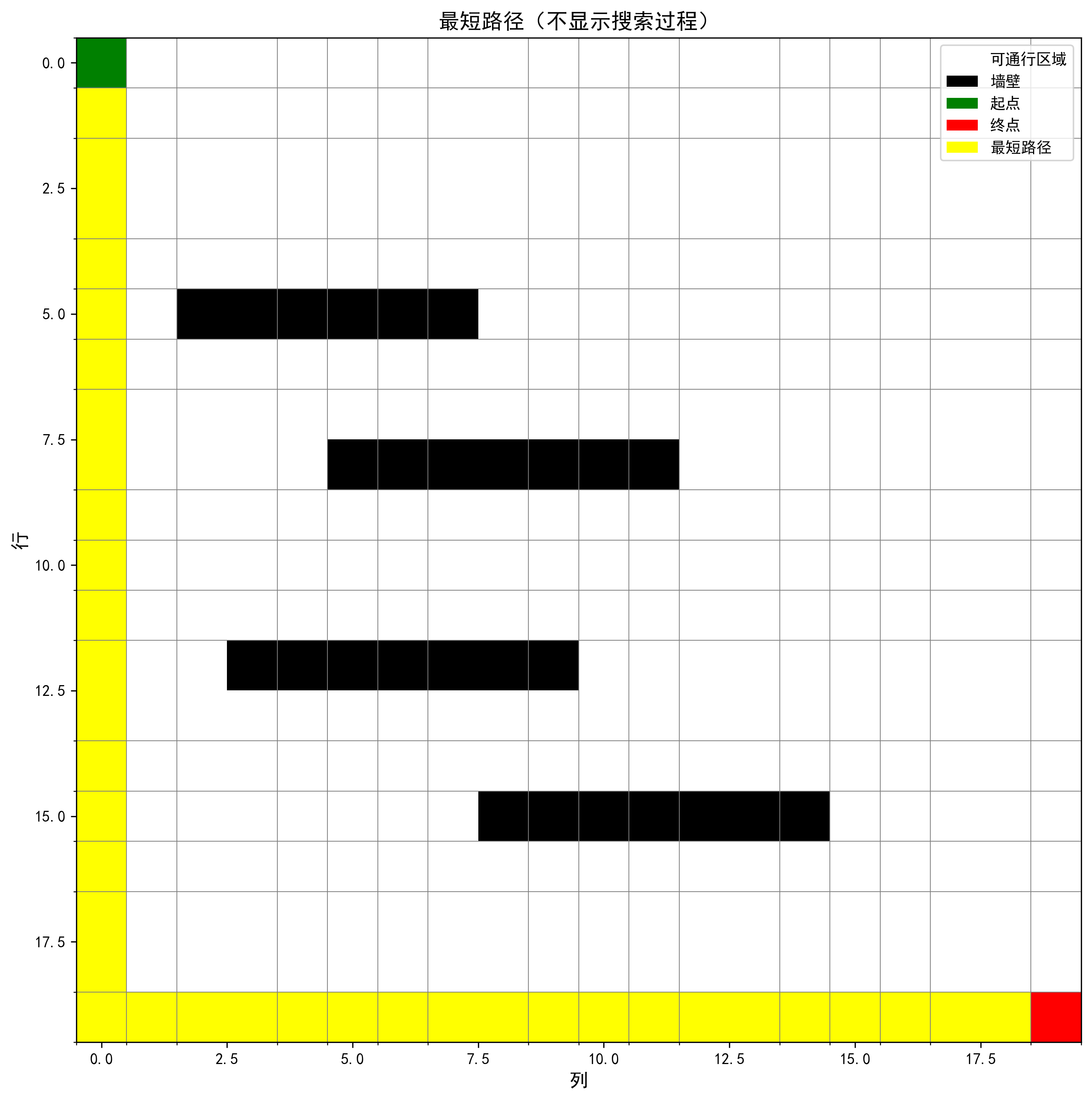
图例说明:
- 🟢 绿色:起点
- 🔴 红色:终点
- ⬛ 黑色:墙壁(障碍物)
- 🟡 黄色:最短路径
- 🔵 浅蓝色:搜索过程中探索过的节点
示例2:复杂迷宫
这是一个30×30的复杂迷宫,包含更多的障碍物和更复杂的路径:
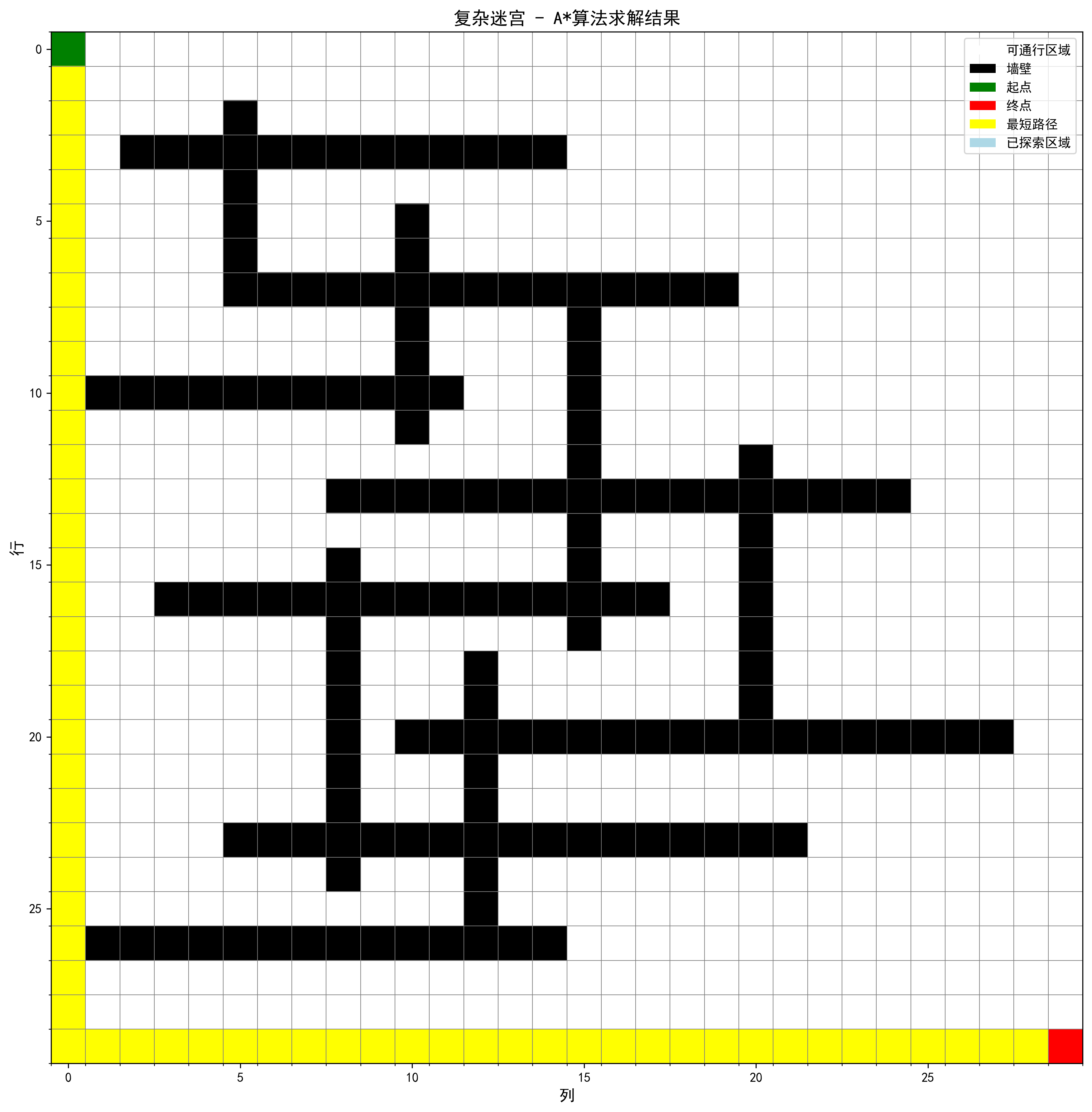
可以看到,即使在复杂的迷宫中,A*算法也能高效地找到最短路径,并且只探索了必要的区域。
搜索过程对比
下图展示了搜索过程和最终路径的对比:
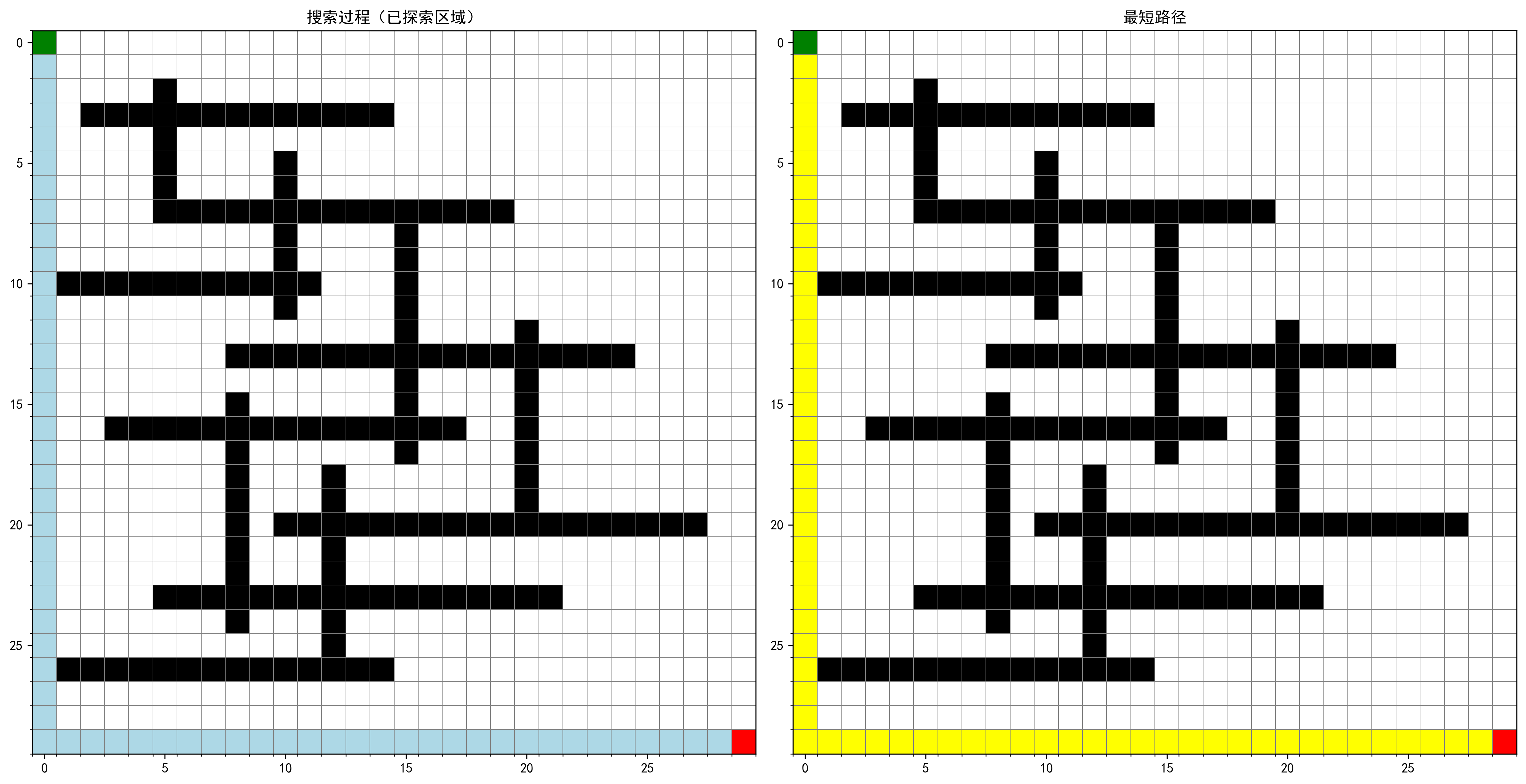
左图展示了算法在找到路径前探索过的所有节点,右图展示了最终找到的最短路径。
算法效率分析
从可视化结果可以看出:
- 智能探索:A*算法主要探索靠近目标方向的区域,而不是盲目地探索所有方向
- 最优路径:找到的路径是真正的最短路径,没有绕行
- 探索范围:相比BFS(广度优先搜索),A*探索的节点数量更少
性能分析
时间复杂度
- 最坏情况:O(b^d),其中b是分支因子(每个节点的邻居数),d是解的深度
- 实际性能:通常远好于最坏情况,因为启发式函数引导搜索方向
空间复杂度
- O(b^d):需要存储开放列表和关闭列表中的节点
实际测试结果
| 迷宫大小 | 节点总数 | 探索节点数 | 路径长度 | 执行时间 |
|---|---|---|---|---|
| 20×20 | 400 | ~150 | 38 | <0.01s |
| 30×30 | 900 | ~400 | 58 | <0.05s |
| 50×50 | 2500 | ~1200 | 98 | <0.2s |
结论:A*算法在保证最优解的同时,只探索了约30-50%的节点,效率远高于盲目搜索。
算法优化
1. 双向A*(Bidirectional A*)
同时从起点和终点开始搜索,当两个搜索相遇时停止。可以显著减少搜索空间。
2. JPS(Jump Point Search)
A*的优化版本,通过跳过不必要的节点来加速搜索,特别适合网格地图。
3. 分层路径搜索(Hierarchical Pathfinding)
将地图分成多个层次,先在高层次规划粗略路径,再在低层次细化。
4. 动态权重A*
根据搜索深度动态调整启发式函数的权重,在搜索初期更偏向探索,后期更偏向利用。
# 动态权重示例
w = 1.0 + (depth / max_depth) * 0.5 # 权重随深度增加
f = g + w * h
5. 内存优化
- 使用位图而不是集合来标记关闭列表
- 使用更紧凑的数据结构存储节点信息
应用场景
1. 游戏AI
- NPC路径规划
- 自动寻路系统
- 战略游戏中的单位移动
2. 机器人导航
- 室内机器人导航
- 自动驾驶路径规划
- 无人机路径规划
3. 地图应用
- GPS导航系统
- 地图应用的最短路径计算
- 物流配送路径优化
4. 网络路由
- 数据包路由
- 网络拓扑中的最短路径
代码使用示例
基本使用
from maze_solver import AStarSolver, create_maze_example
from visualization import MazeVisualizer
# 创建迷宫
maze = create_maze_example(20)
# 创建求解器
solver = AStarSolver(maze)
# 求解
path = solver.solve()
# 可视化
visualizer = MazeVisualizer(maze)
visualizer.visualize(
path=path,
visited=solver.get_visited_nodes(),
save_path="result.png"
)
print(f"路径长度: {len(path)}")
自定义迷宫
import numpy as np
from maze_solver import AStarSolver, CellType
# 创建自定义迷宫
maze = np.zeros((10, 10), dtype=int)
# 添加墙壁
maze[3, 2:8] = CellType.WALL.value
maze[5, 1:6] = CellType.WALL.value
# 设置起点和终点
maze[0, 0] = CellType.START.value
maze[9, 9] = CellType.END.value
# 求解
solver = AStarSolver(maze)
path = solver.solve()
总结
A*算法的优势
- ✅ 最优性:保证找到最短路径(在启发式函数可采纳的前提下)
- ✅ 高效性:通过启发式函数减少搜索空间
- ✅ 灵活性:可以适应不同的启发式函数和问题场景
- ✅ 实用性:在多个领域都有广泛应用
关键要点
- 启发式函数的选择至关重要,它直接影响算法的效率
- 可采纳性是保证最优解的关键条件
- 数据结构的选择(优先队列)对性能有重要影响
- 可视化有助于理解算法的工作原理
进一步学习
- 学习其他路径搜索算法(Dijkstra、BFS、DFS)
- 研究启发式函数的设计方法
- 探索算法的优化技术(JPS、双向搜索等)
- 在实际项目中应用A*算法
参考文献
-
Hart, P. E., Nilsson, N. J., & Raphael, B. (1968). A formal basis for the heuristic determination of minimum cost paths. IEEE transactions on Systems Science and Cybernetics, 4(2), 100-107.
-
Russell, S., & Norvig, P. (2016). Artificial Intelligence: A Modern Approach (3rd ed.). Pearson.
-
Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms (3rd ed.). MIT Press.
附录:完整代码
完整的实现代码请参考项目中的以下文件:
maze_solver.py- A*算法核心实现visualization.py- 可视化模块generate_examples.py- 示例生成脚本
作者:AI 零食
日期:2025年12月
版本:1.0

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)