从芯粒到服务器:一文读懂大模型浪潮下的开放互连
本文梳理了UCIe/CXL/UAL/UEC等开放互连标准的特性, 探讨了它们在AI场景下的应用和竞合,并从AI云基础设施视角出发,如何看待SUE?Scale-Up域的边界在何方?以及CXL在AI背景下的未来。过去的五到六年见证了AI大潮的汹涌澎湃,而在这巨浪之下,也涌动着开放互连标准的蓬勃发展:笔者有幸代表阿里云以UCIe和CXL董事会董事的身份,参与了UCIe 1.0~3.0标准, 以及CXL
By 阿里云服务器研发团队 陈健
编者按:
本文梳理了UCIe/CXL/UAL/UEC等开放互连标准的特性, 探讨了它们在AI场景下的应用和竞合,并从AI云基础设施视角出发,如何看待SUE?Scale-Up域的边界在何方?以及CXL在AI背景下的未来。
前言
过去的五到六年见证了AI大潮的汹涌澎湃,而在这巨浪之下,也涌动着开放互连标准的蓬勃发展:
- 2019年3月,Compute Express Link(CXL)联盟成立,旨在解决当时异构XPU编程以及内存带宽和容量扩展所带来的挑战,以内存为切入点构建一个可编排的机柜级服务器架构。阿里作为以创始成员的身份成为CXL联盟董事会董事。 彼时,Transformer架构已发布近两年,其潜力已在BERT上牛刀小试。
- 2022年3月,Universal Chiplet Interconnect Express(UCIe)联盟成立。此时,基于芯粒(Chiplet)的芯片设计范式已成为后摩尔时代设计高算力芯片的业界共识,但整个行业还缺乏一个有号召力的,开放的Die-to-Die互连标准。UCIe旨在填补这一空白。同年8月,阿里正式成为UCIe联盟董事会,成为中国大陆唯一个UCIe董事会成员。 那时,距离ChatGPT的发布还有3个月。
- 2023年7月,Ultra Ethernet Consortium(UEC)联盟成立。此时,整个行业正处在被ChatGPT点燃的百模大战中,大模型训练的需求爆炸式增长,而基于传统以太网的集群面对这波泼天富贵已显得力不从心。UEC的成立正当其时,它旨在为AI和HPC重建一个高效开放的以太网。 同年11月,阿里云正式加入UEC联盟,成为General会员(UEC两级会员体系中的高阶会员)。
- 2024年10月,Ultra Accelerator Link (UAL)联盟成立,旨在应对模型尺寸以及推理上下文快速增长带来的对Scale-up网络的需求。2025年1月,阿里以董事会董事的身份加入UAL,成为中国大陆唯一个UAL董事会成员。
笔者有幸代表阿里云以UCIe和CXL董事会董事的身份,参与了UCIe 1.0~3.0标准, 以及CXL 3.x~4.0(即将发布)标准的制定和发布;同样来自服务器团队的廷钰代表阿里云以UAL董事会董事的身份,参与了UAL 1.0 标准的制定。正是因为这些在开放互连中的长远布局使阿里在AI大潮中占据了极为有利的硬件生态位,引领国内开放互连生态的发展。 本文旨在通过介绍UCIe/CXL/UAL/UEC的基本概念和特性,系统的梳理各个层次的开放互连在AI Infrastructure中的作用,帮助大家深入理解这些不同字母组合背后的含义和关系。
背景
大模型的迭代在Scaling Law的信仰下,高潮迭起,你方唱罢我登场, 令人目不暇接。现在回望,所谓的Scaling Law大致有三个阶段:
- Pre-training Scaling:在模型预训练阶段,通过增加模型参数数量,训练用的数据量,以及用于训练的计算资源(即传统的算法,数据和算力三要素),来提升基础大模型的输出精度。
- Post-training Scaling: 在模型后训练阶段,通过基于专业数据集(Domain-Specific Dataset)的微调,Reinforcement Learning with Human Feedback(RLHF)以及 Teacher-Student调教和蒸馏(Distillation)等手段, 使大模型的输出更具有专业素养,符合人类沟通习惯和价值观。
- Test-time Scaling: 在模型Inference阶段,通过生成更多用于协助推理的token,从而形成更高质量的模型输出。常见的方式比如:Chain-of-Thought(CoT)Prompting: 通过将问题分解为多个步骤,展示推理过程;Sampling and Voting: 通过针对一个Prompt生成多种可能的响应结果,借助Majority Voting选择最佳结果。
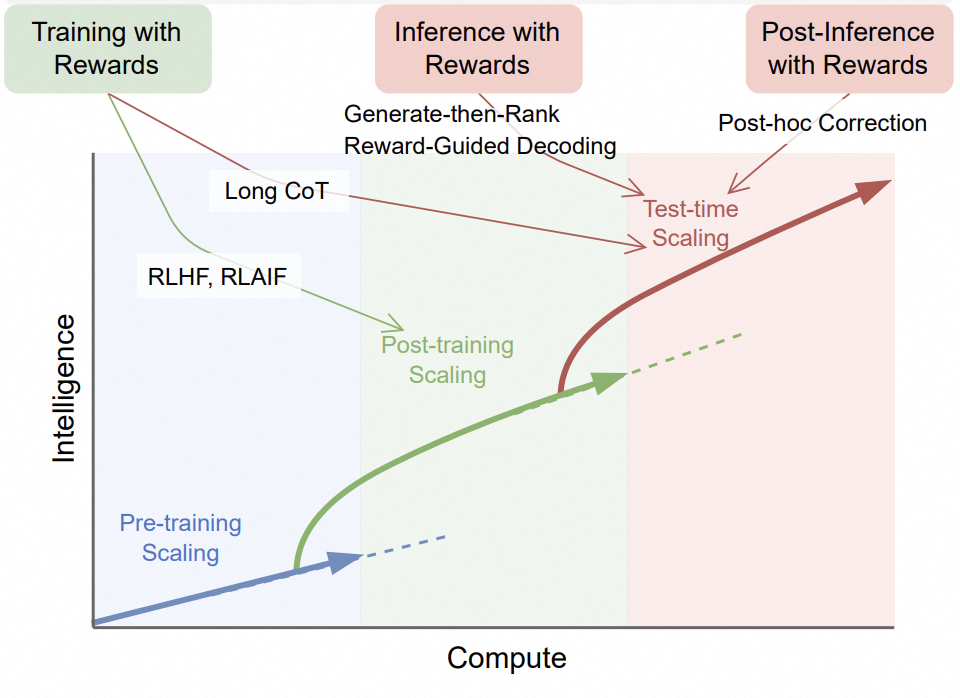
图1. 大模型Scaling Laws. Source: [3]
如今,这三阶段Scaling Law依然在大模型的演进中起着各自的作用, 但是,Scaling的重心已经转移到了Test-time Scaling。这是从大模型竞赛到大模型落地应用自然过渡的结果;但另一方面,推理是对客服务的,它对延时指标(e.g. Time To First Token (TTFT),Time Per Output Token (TPOT)) 和吞吐指标(Token Per Second(TPS)) 都有刚性需求,这对AI Infrastructure提出了与Pre-training Scaling截然不同的新挑战。
为此,当黄教主端出了热气腾腾的GB-200 NVL72全家桶时,广大CSP们无不为之垂涎:NVIDIA-HBI(High Bandwidth Interface)连接了两颗Blackwell Die,构成了一个完整Blackwell GPU;同时,Grace CPU通过NVLink C2C(利用其Chip-2-Chip互连功能)连接了两个Backwell GPU, 并以2CPU:4GPU的方式构建一个计算节点(A.K.A.,Compute Tray);接着,NVLink连接起72个GPU(18个计算节点),构成一个Scale-up网络;Backend 网络( 或Scale-out网络 )? CX-7 (IBTA RDMA or RoCE)顶上。这全家桶,从计算到互连,都是业界顶流,全面回应了CSP所面临Test-time Scaling的痛点,着实让人心动。但这里问题是其核心互连都是NVidia独家私有。 对于CSP来说,这意味着,在商业上,弱势的议价能力和Vendor Lock-in;在技术上,丧失了独立的优化空间;在产品上,不具备差异化特性和竞争力。
因此,我们需要拥抱开放互连标准。 开放意味更多参与者,带来更多的选择性,更为健壮的供应链,也意味着更大的定制和优化空间。 而作为开放互连的代表,UCIe/CXL/UAL/UEC涵盖了从芯粒互连到Scale-out网络的全链条,是我们构建AI Infra核心竞争力的重要阵地和抓手。
UCIe:芯粒?成本!
何以芯粒?
基于芯粒(Chiplet)的设计方式已经成为当前高性能CPU/GPU的主流设计范式, 这是在后摩尔时代,应对单位晶体管成本下降缓慢的必然选择。为什么这么说呢? 这是因为基于芯粒的设计在多个层面解决了成本的问题,如下图所示:
- 提升良率:通过将单一大尺寸硅片切分成小的硅片,再合封在一起的方式,缩小了晶圆上单个缺陷所影响的范围, 从而提高了硅片产出的良率,降低了单位硅片的成本。
- 制程节点优化:通过将芯片的电路进行合理的切分,提升了电路功能和对应制程的契合程度。 比如,将DDR控制器,PCI控制器等IO模块集中在IO Die中,而由于IO Die中模拟电路占比较高,对高端制程无刚性要求,因此可以采用较为成熟的制程,从而降低IO Die的制造成本。
- 跨产品的芯粒复用:传统的单片SoC设计中, 如果要做多个不同的产品SKU,要么在一个硅片上做个多个产品SKU的超集,然后在硬件上关闭某些核心或者加速器,形成不同的SKU;要么针对每个SKU都设计一个硅片单独流片,这两者的整体成本都比较高。而基于芯粒的设计通过对Core芯粒和加速器芯粒的复用和组合,构成不同的产品SKU。这种复用和组合灵活性带来的成本分摊,充分体现了芯粒设计的价值。
- 芯粒市场化:如果说跨产品的芯粒复用是在公司内部的芯粒复用,那么芯粒供应货架化则是跨公司的芯粒复用。它是当前板级设计中芯片货架化的商业模式在芯片内部的自然延伸,能使芯粒的设计和制造成本得到最大程度的分摊(Economy of Scale)。同时,通过市场竞争提升进一步提升可选择性和供应链的健壮性。
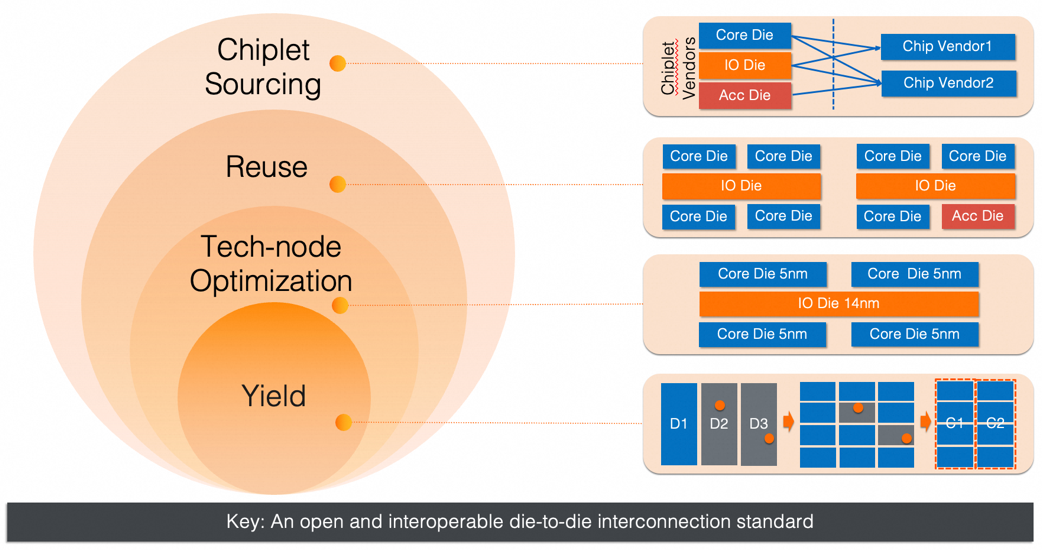
图2. 基于芯粒设计的价值支柱
除了成本方面的优势,基于芯粒的设计模式还解决了芯片的极致性能问题,这在GPU侧体现的尤为突出。硅片的大小受到光罩尺寸(Reticle Size)的限制,对于EUV制程来说,它通常在850mm^2左右。 当前,GPU对更高单芯片算力的追求已使硅片面积经触及了光罩尺寸,而芯粒提供了一种突破光罩尺寸对算力限制的途径:将多个大尺寸硅片合封在一起,提供远超单一硅片能实现的单芯片算力。 这实际就是NVIDIA的Blackwell GPU(2 Die合封)和Rubin Ultra GPU(4 Die 合封)(参见下图 3.)背后的逻辑。

图3. Rubin Ultra 4个Reticle Size GPU 合封
目前,前三个芯粒价值已经在芯片大厂(AMD,Intel,NVidia等)中得到充分渗透,但基本是通过私有Die2Die互连实现的(比如,AMD的Infinity Fabric,NVidia的NVLink C2C)。而芯粒的市场化依然比较遥远,它的实现有赖于一个开放和可互操作的Die2Die互连协议。 不仅如此,开放的Die2Die协议还能让广大的芯片创业公司都快速搭上芯粒设计的大船, 与芯片大厂同台竞技,而不必投入大量资源自研的相关协议。从这层意义上来说,开放协议涉及到平权和产业的繁荣,这也是我们为什么要坚定的支持开放的另一个原因。 但是光有开放还不够,一个协议要有生命力,必须要有足够好的KPI和产业链上主流厂商的背书;能够体察业界痛点,持续演进;被业界广泛采纳。 UCIe具备了这些维度上的特点:它的KPI在已有的芯粒互连协议中最具有竞争力;在产业链上得到了从Fab(TSMC,三星)到封装(日月光)到设计(Intel,AMD,ARM,NVIDIA,Qualcomm)到应用(Alibaba,Google,Meta,Microsfot)主流公司的支持;3年时间已经迭代到3.0版本,国内外主要EDA厂商已经开始销售UCIe IP。
UCIe协议概览
任何一个通信协议的设计都与它所要应对的信道状态和应用场景息息相关,UCIe也不列外。作为芯粒间的互连标准,UCIe要面对的是:
- 极短的信道长度:对于2D/2.5D封装,信道长度在毫米级,而对于3D封装,若通过混合键合(Hybrid Bonding)来实现,其信道长度在亚微米级。 这意味信道衰减较低,无需对传输数据做前向纠错(FEC)。
- 多元的信道介质:不同的封装技术会让信道处在不同的介质中,标准封装工艺通常会让信道穿越有机基板或玻璃基板,而先进封装通常会采用Silicon Interposer(e.g., TSMC的Chip-on-Wafer-on-Substrate (CoWoS)) 或者硅桥(e.g. Intel的Embedded Multi-die Interconnect Bridge (EMIB) 等。不同的介质支持不同的信道密度,需要区别对待。
- 有限的IO Pad空间:硅片上Micro-bump资源相较于芯片的引脚资源来说更为丰富,但依然非常有限,毕竟当前的硅片设计大部分情况下都属于IO Pad Limited,即IO Pad的面积决定了硅片的面积。这意味着Die2Die协议需要有很高的带宽密度(GB/s/mm or GB/s/mm^2)来减少对硅片IO资源的占用。这进而意味着更小的Micro-bump Pitch,更高效的Micro-bump排布。
- 极致的延时要求:芯粒合封通常有两个来源:一种是原本独立的板级加速设备被合封进芯片内部,此时跨Die传输延时相较于板级传输延时有天然的数量级优势,因此这种情况下,对跨Die延时的要求不高;另一种,也是更为重要的一种是通过切分将SoC分到多个Die上进行合封,此时跨Die延时越小越好。 UCIe将目标设为<2ns (TX+RX),这是一个极具竞争力又极具挑战性的目标。为达成这一目标,UCIe采用了并行接口设计,以避免数据串行化带来的额外延时。这是综合考虑了信道长度和介质对信号完整性的影响,以及延时需求和IO Pad成本之间的权衡。 当前做得好的IP可以把延时控制在10ns以内。
- 高标准的链接可靠性:Die与Die的物理链接要么经过Micro-bump(2D/2.5D),要么经过键合,两者对工艺的要求极高。如果在micro-bump焊点处或者键合处有杂质或缺陷,使用过程中容易出现电迁移造成链接失效。如果在服务器主板上出现这样的问题, 可以替换部件重新焊接;但在芯片内部,这种问题会导致整个芯片失效。 因此,跨Die链接需要引入冗余机制, 构建对此类问题的修复能力,提升可靠性。
- 支持多种协议的灵活性:如上所述, 芯粒合封通常有两种场景:一是将加速芯粒以CXL或PCIe设备的形式合封,此时跨Die通信的协议是CXL或PCIe;另一种是各类多核计算芯粒的合封,此时跨Die通信涉及到连接片上网络(NoC)的各种一致性协议(e.g. CHI)甚至是自定义协议。 因此,UCIe要做的是提供足够的灵活性,支持好各类已有的上层协议,而不是另起炉灶再定义一套上层协议。
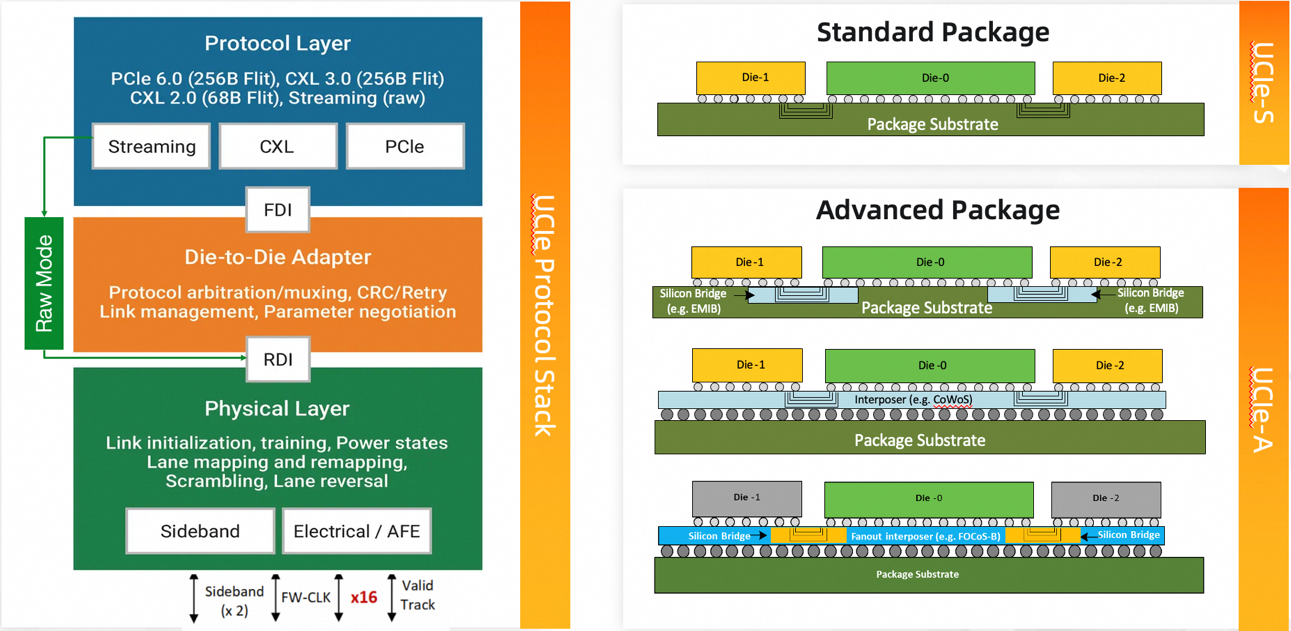
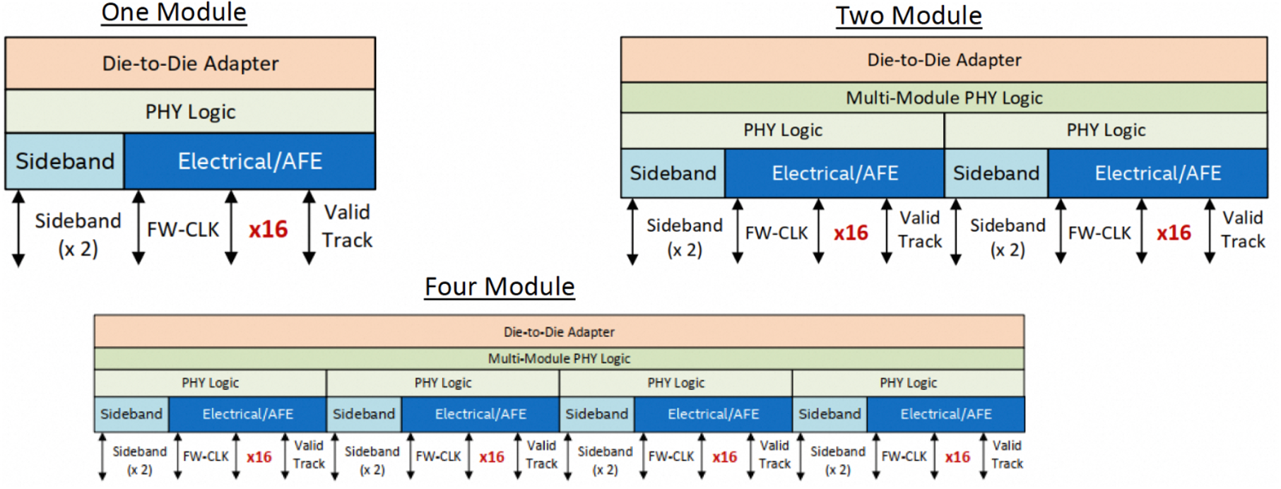
图4. UCIe协议框架
综合上述需求, UCIe构建了三层协议栈:物理层,Die-to-Die适配层和协议层。协议层和D2D适配层通过Flit-Aware Die-to-Die Interface(FDI)衔接,而Die-to-Die适配层与物理层之间通过Raw Die-to-Die Interface(RDI)衔接。 那么,为什么在UCIe协议中需要有这样的接口,而通常其他的协议栈中并没有呢?这和UCIe协议所要提供的上层协议灵活性有关。在UCIe中,协议层实质是个筐,各种协议都可以往里装:PCIe,CXL和以Streaming形式出现的其他协议。FDI负责将这些协议物理层以上的数据通过Arbitration/Mux的方式导入到Die-to-Die适配层。另外,Streaming在Raw Mode下可以绕过D2D适配层直接进入到物理层。 因此,我们需要RDI将来自于D2D适配层的数据和Raw streaming数据进行Mux。这也就是我们需要有FDI/RDI的原因:多个协议数据流之间的Arb/Mux。
D2D适配层主要通过CRC和Retry保证数据在跨Die传输的正确性。 物理层是UCIe协议中的大头,它负责链接初始化,Lane映射和重映射(出现通道失效,冗余备份通道被激活时需要重映射)等。 一个物理层对应一个模组信号,包括x16或x64的TX和RX数据信号,一个前向时钟,一个Valid和x2的侧信道。 一个D2D适配层可以支持1,2,4个这样的模组信号。 为适配不同的信道介质,UCIe区分了标准封装(UCIe-S)和先进封装(UCIe-A)两个Profile,其中UCIe-S只支持x16数据信号,而UCIe-A支持x64数据信号,但两者都支持32GT/s的传输速率。先进封装单模组的带宽可达256GB/s,更高的速率也在定义中。
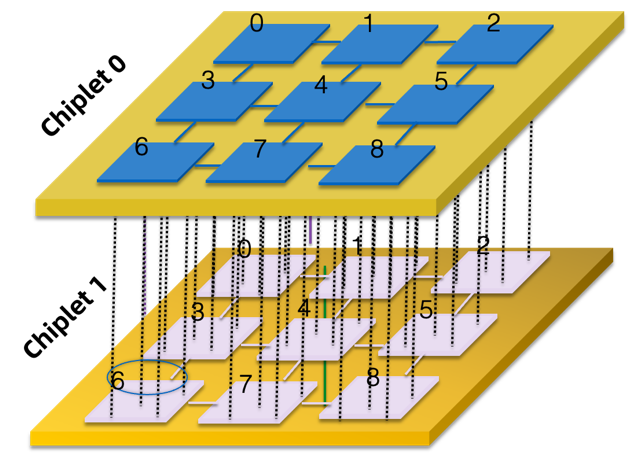
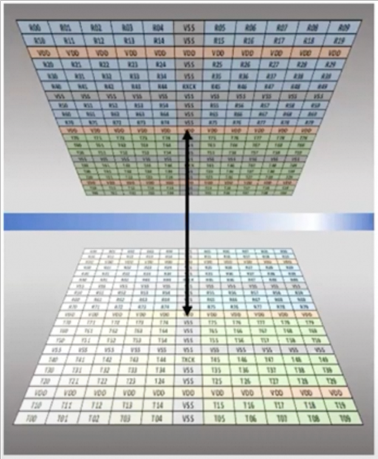
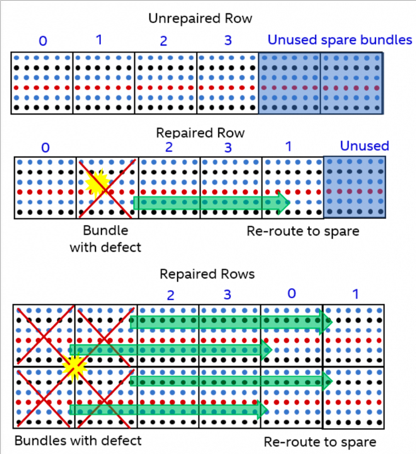
图5. UCIe-3D 层次结构
UCIe-3D是UCIe 2.0中引入的新的Die2Die互连Profile,建立在混合键合3D封装技术之上。 由于其信道长度几乎可以忽略,因此,UCIe-3D的物理层可以也必须极致简化:一个信号驱动即可。 同时,由于3D封装将原先2D/2.5D封装中的Shoreline拓展到了整个Die平面, 如何组织这些信号端口就变的尤为突出。 如上图所示,为了便于管理, UCIe-3D把这些信号以0.02mm^2为单位组织成一个bundle,每个bundle中的有x80 TX/RX信号,并以9um bump pitch进行排布。相比之下, 2D/2.5D的先进封装中的bump-pitch在25~55um之间。 由于混合键合易受到杂质的干扰,因此,UCIe-3D在每一行的bundle中定义了两个冗余的bundle,用于应对杂质/缺陷的影响。为什么要有两个冗余的bundle?因为如果一个缺陷正好处在四个bundle的交接处,它就会让四个bundle变得不可用,正好每行两个。 这里Bundle的remapping并没有在UCIe-3D标准中定义,它需要上层的逻辑电路将该因素考虑进去,并提供相应的支持。
UCIe协议的应用:
UCIe芯粒合封的一个典型应用场景如下图(a)所示:两个计算Die通过UCIe相连,通过CHI协议实现计算Die之间的Cache一致性;同时一个计算Die再通过UCIe与加速Die互连,通过CXL协议,将加速器内存和计算Die内存构成统一空间,实现互访。
UCIe也推动了光电共封(Co-Packaged Optics,CPO)的发展。当前的产业链下,Optics Engine(OE)和计算芯粒通常分属不同公司。要实现共封,大概有几种方式:1. 计算芯片大厂收购光模块公司后,通过私有Die2Die协议实现光电共封;2. 通过私有Die2Die协议IP对光模块公司的定向授权,实现CPO;3. 通过计算Die和OE共同遵循开放Die2Die协议UCIe,来实现光电共封。我们认为第三种方式成本最低,灵活度最高,可以灵活实现标准封装或先进封装下的CPO;但在实操中,实现来自两家公司UCIe的互操作,还存在前期系统验证和EDA工具不成熟等生态方面的挑战。而随着CPO在AI集群互连中变得日益重要, 它反过来对UCIe生态也是一种良性的促进。
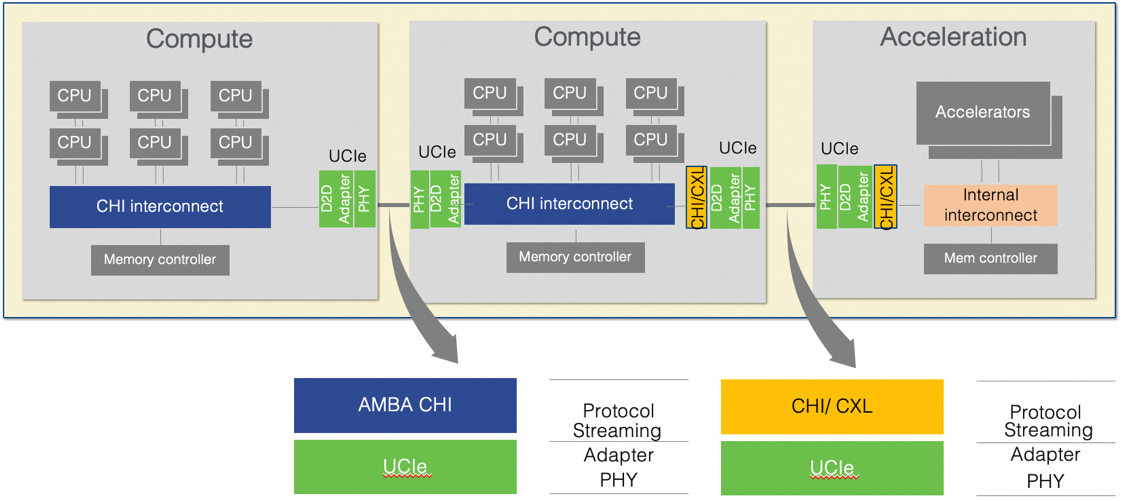
(a) Core Die以及加速器Die的片上互连
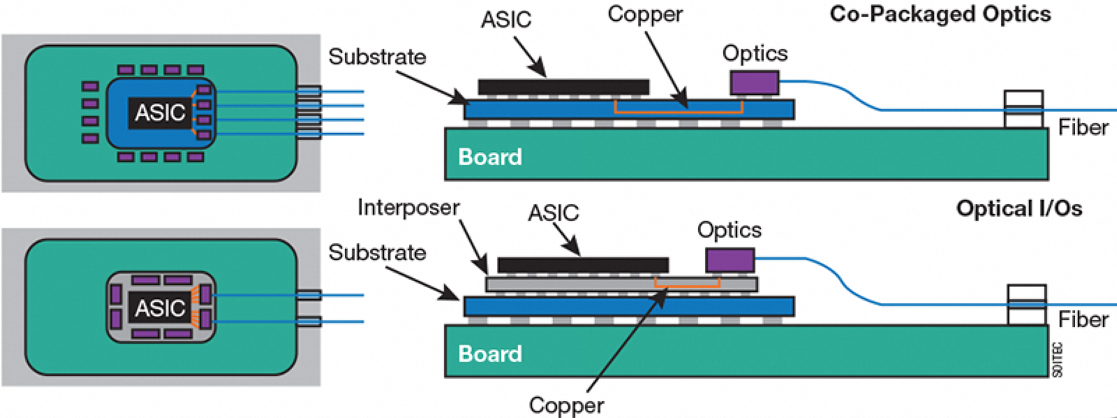
(b). UCIe-based CPO
图6. UCIe互连应用场景
CXL:重塑服务器组织形态
CXL联盟成立于大模型爆发之前,那时深度学习和各类卸载所带来的XPU盛行,整个行业所面临的问题是: 如何在服务器层面对这些异构设备进行灵活的编排和高效的编程;同时,在CPU核心数快速增长的背景下,如何应对内存带宽需求增长和芯片有限引脚资源的矛盾。 因此CXL以内存为切入点,构建一个基于内存语义的一致性互连, 并通过解耦计算和内存,实现可编排的机柜级服务器硬件架构。但它仍然是CPU-centric的,又受到到PCIe带宽的限制,因此在大模型爆发的时代,无法直击核心痛点,未能成为AI基础设施海量投资的焦点。即便如此,这种对服务器组织形态的重构依然意义深远,而且随着PCIe速率的提升,CXL对AI基础设施的效能提升还在不断增强。
CXL主要特性:
关于CXL协议的核心概念,可参考“服务器CXL之路:CXL核心概念及标准演进”文章,这里就不再赘述。 上表总结了CXL1.0到CXL3.2标准所支持的特性清单。在这里,我们简单梳理下在笔者看来对AI有较大助力的CXL特性。
表1. CXL1.0~3.2支持的主要特性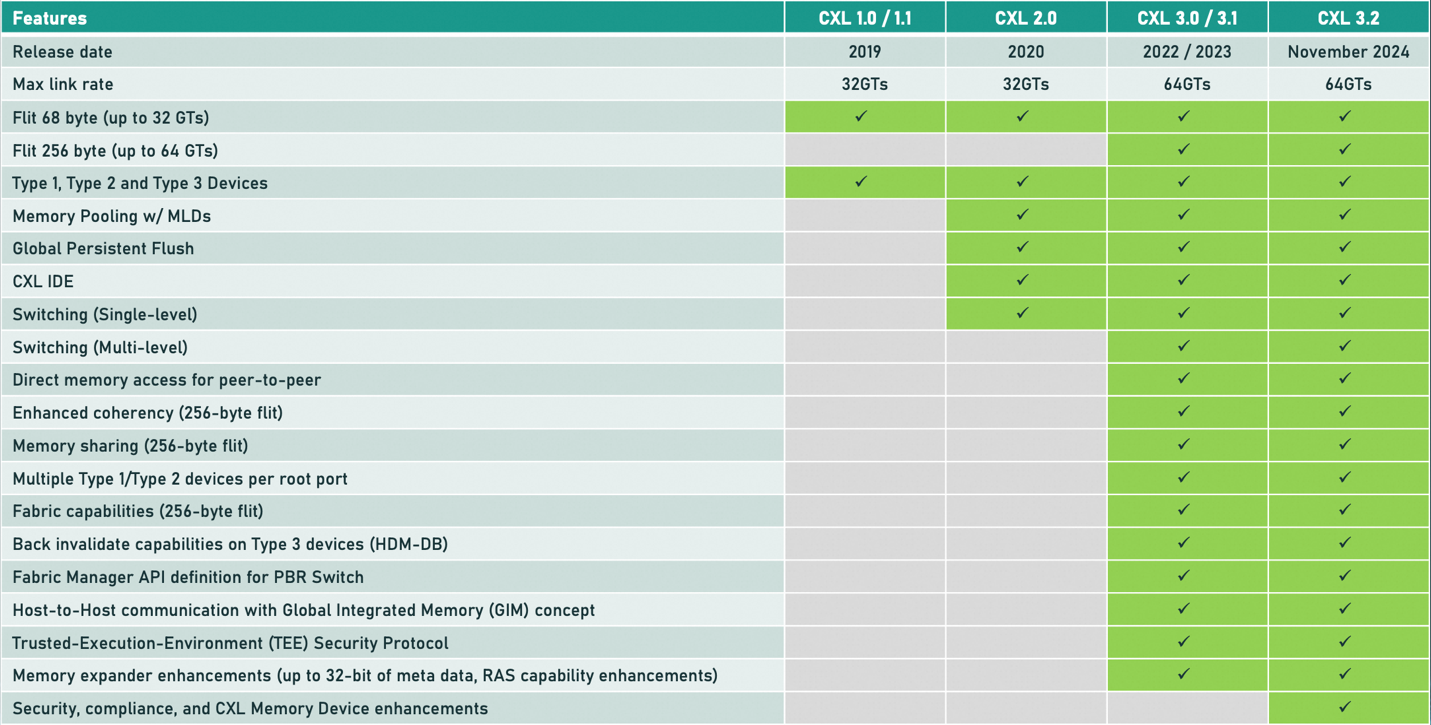
- 内存扩展(Memory Expansion)和内存池化(Memory Pooling): 内存扩展应该是目前为止CXL最为成熟的应用, 它能够通过CXL串行端口和 CXL Memory Module(Type 3 CXL Device,说人话就是CXL协议打包的DDR内存) 拓展Host内存容量。 同时,随着XConn的CXL 2.0交换机逐步推向市场, 通过交换机的内存池化又为内存容量的扩展提供了更加广阔的扩展空间。CXL池化有两种形态:一种是以设备为粒度的池化,每个设备为 Single-Logic-Device(SLD),它只能以一个整体分配给某个Host;另一种是将设备的物理资源分成多个逻辑设备(Up to 16) 并分配给不同Host,这种设备被称为Multi-Logic-Device (MLD)。MLD常见于CXL存储设备,比如像AliSCM的CXL Storage Class Memory。每个MLD中的逻辑设备(LD)都有一个ID来区分(LD-ID),但是这个LD-ID并不是Host可见的。CXL Switch根据Transaction中的Host Port来找到其对应的LD-ID,并通过Fabric Manager来构建和维护这样的映射表。内存扩展和池化为LLM推理服务系统提供了一个分层的缓存系统。
- 统一的一致性内存空间: CXL通过将Host内存和设备内存统一编址,构建了统一的内存空间,并借助CXL.cache实现一致性。由于可以通过Host CPU扩展大容量的DDR内存,这种特性在理论上能够很好的弥补当前GPU显存不足且昂贵的缺陷。 这个其实和GB200通过NVLink C2C实现Grace和Blackwell统一内存是一样的。但是在CXL上遇到了一些比较现实的挑战:首先,由于CXL基于PCIe PHY,而当前相对成熟的PCIe Gen5/6的速率远低于NVLink,这导致Host与Device之间数据搬移的延时较大,严重影响了统一内存的实际效果 。其次,设备对Host内存的访问需要通过CXL.cache协议,但该协议的实现复杂性较高,到目前为止,尚未见到成熟的支持CXL.cache的设备;而PCIe Gen5/6较低的速率进一步削弱了在GPU上集成CXL的动力。这种情况估计要等到PCIe Gen7(128GT/s的传输速率)成为主流后才能有所改变。
- 通过GIM(Global Integrated Memory)的Host-to-Host内存共享 : GIM是CXL 3.1提出的概念,用来实现Host之间的一致性内存访问。具体来说,GIM指的是映射到本地主机物理地址空间中的远程主机的内存, 它可以让在同一CXL Fabric中的Hosts实现内存互访。这在一定程度上弥补了CXL1.1/2.0种非对称内存访问的短板(即只能实现Host与Device之间互访内存),结合设备之间的P2P内存访问,CXL 3.0+在形式上实现了对称的内存共享和互访。尽管在实现机理上有所不同:Host与Device之间通过CXL.mem以及CXL.cache, 而Host与Host,Device与Device之间通过UIO(Unordered IO),但这种全域的内存共享能力,为当前内存受限的AI基础设施提供了很大的想象空间。
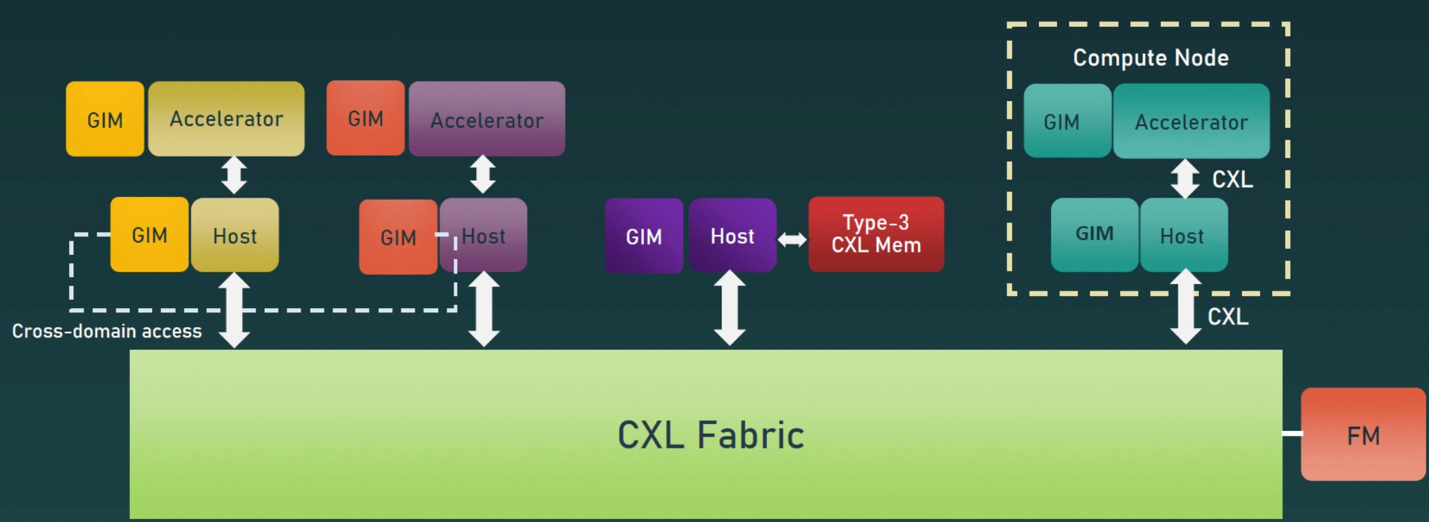
图7. CXL Global Integrated Memory
CXL在AI场景中的应用:
- 分层KV Cache缓存: 在用于大模型推理服务的集群中,由于需要同时服务多个用户,KVcache的内存占用量非常庞大。如果单纯依赖GPU上的HBM或者GDDR来保存这些数据,整个AI推理系统会变得极其昂贵且效率低下,经济上不可持续。 利用CXL的内存池化,我们可以构建一个分层的KV Cache缓存体系: Host经由CXLSwitch到CXL内存(e.g., Alimemory),CXL Storage Class Memory (e.g., AliSCM),乃至CXL SSD(e.g., AliFlash)。在这基础上,利用KV Cache的访问热度,将KV值分配到不同的缓存层级中,可极大的缓解KV Cache在显存中的存储压力, 降低成本的同时又可提高GPU的运行效率。
- Retrieval-Augumented Generation (RAG)向量数据库:为解决大模型推理受训练数据的时效限制的影响,最新主流的ChatBot服务以及主流的LLM推理框架都支持RAG:依据输入的Embedding,查询向量数据库,从而获取与输入相关度较高的最新上下文信息。由于RAG处在整个推理的关键路径上,因此提高向量数据库的查询性能将直接影响到推理系统的性能。这里,至少有两个途径CXL可以发挥作用:一种途径是,通过内存扩展或者池化,创建一个巨大的Host侧内存空间,这样整个向量数据库都可以常驻内存,变成In-memory database,使得延时和吞吐上都优于基于SSD存储的向量数据库;另一个种途径是,利用存内计算(In-Memory Computing)或近存计算(Near-Storage Computing)将RAG所需要的Approximate Nearest Neighbor Search (ANNS)卸载到CXL设备上,这样可以减少主机CPU和设备之间数据传输,进一步提升向量数据库查询效率。
UAL:内存语义下的精简Scale-Up互连
严格意义上来说,Scale-up是一个节点内扩展的概念:我们通常所说的单机4卡,单机8卡即属于该范畴。但是随着模型尺寸的不断增加,上下文的增长,即便是单机16卡也无法放下一个模型。那就只能将一个模型放在多个机子的多张卡上,这在HPC语境下是再自然不过事:将一个负载任务拆分成多个Partition分布到多个节点上,再通过Message Passing等方式进行节点间的同步和通信。 问题在于大模型和典型的HPC负载有着明显的不同: 典型的HPC负载通常存在通信本地性(Locality),比如,计算流体动力学(CFD)中,基本的通信模式是3D Nearest Neighbor(A.K.A., 3D Stencil),即一个分区仅和它直接相邻的分区进行通信,这就从根本上避免了昂贵的All-to-All通信;而大模型负载又“大”又“紧”,“大”是指计算量大,对内存容量要求大,故需要多张GPU卡,需要做切分;“紧”是指负载内部通信的紧耦合,即便是对切分比较亲和的专家并行(Expert Parallelism)也存在All-to-All等密集数据通信(单次通信GB级别,且无法通过overlapping被隐藏)。因此,我们就有了这样的需求: 既要分布在多个物理节点上的多张GPU卡,又要求卡间通信与单个物理节点内的通信在性能上无明显区别,这就是所谓的超节点Scale-up网络。
UAL协议概览:
要实现对Scale-Up网络的支持, UAL需要:
- 支持内存语义,避免RDMA中Producer-consumer编程模式所带来的Doorbell/Interrupt延时开销。
- 精简协议栈, 减少在协议处理链路上的延时。
- 采用高速率串口, 支持通道聚合,以满足scale-up带宽要求。
- Time-to-Market,充分复用现有技术,降低研发复杂度,能够快速实现应用和部署,充分挖掘大模型推理爆发式增长带来的红利。
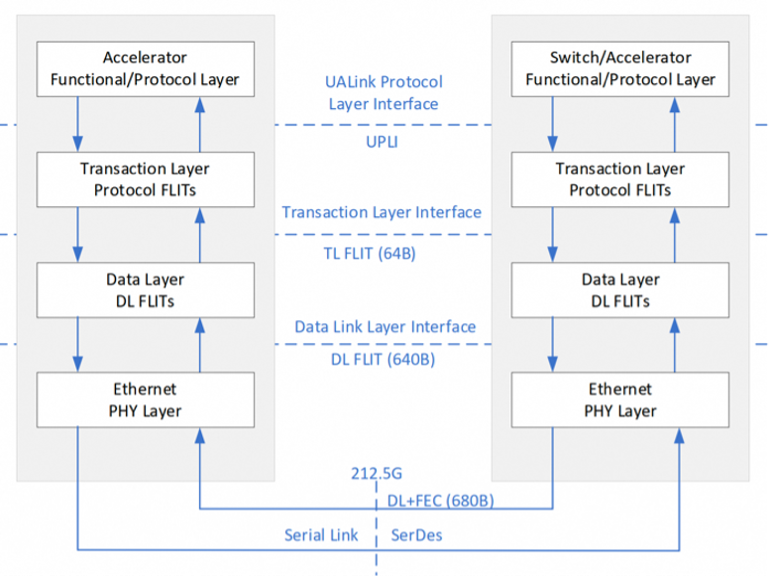
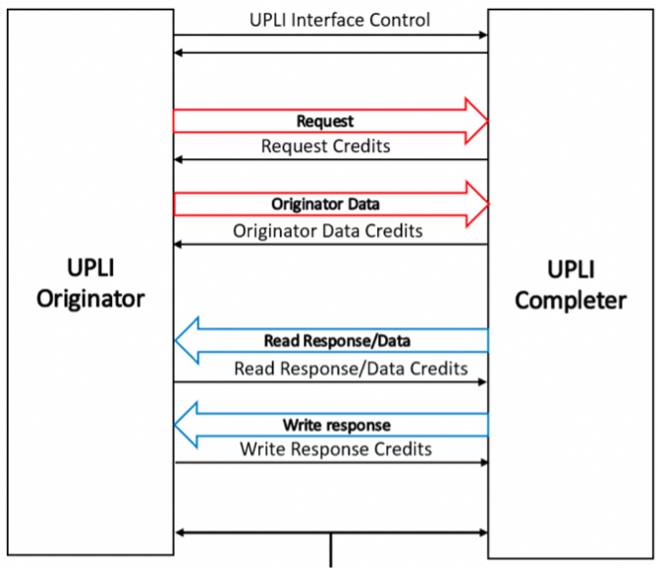
图8. UAL协议框架
基于上述需求,UALink定义了四层协议栈,包含了协议层(Protocol Layer),事务层(Transaction Layer),数据链路层(Data Link Layer)和物理层(Physical Layer)。
- 物理层: UALink复用了IEEE802.3dj以太网的物理层,采用224G SerDes来实现200Gb/s的传输速率。在减少了协议IP设计成本的同时,又实现了远高于PCIe Gen5/6的传输速率。 这里考虑了40Byte 前向纠错码(FEC)和256B/257B的信道编码所带来的带宽损耗。这一通道速率已经与NVLink 5.0齐平,相较于CXL带宽问题有了极大的缓解。此外,4条这样的通道一起构成了一个UALink Station,它可以是一个x4的UALink端口,也可以bifurcate成2个x2,或者4个x1的端口。UALink通过这样4通道汇集以及对Bifucation的支持兼顾了高带宽与连接的灵活性。
- 为了实现内存语义互访,UALink在协议层接口(UALink Protocol Layer Interface(UPLI))定义了四个逻辑信号通道,分别是:Request,Originator Data,Read Response/Data,Write Response。其中,请求通道(Request Channel)包含请求地址、请求类型(读取、写入、原子操作以及其他自定义命令)、请求长度、Source标识符、Destination标识符等;读取响应/数据通道(Read Response/Data Channel)最多可包含四个节拍,每拍的64字节,共256字节数据;写入响应通道(Write Response Channel)主要的任务是告知原写请求的完成状态, 因此它不包含数据。通过这些通道,UALink实现了对Load/Store内存语义操作的原生支持。
- 事务层要解决的问题是如何高效的将来自于协议层的请求打包成TL Flit。在UALink中,每个TL Flit大小为64 Byte,其中0-31Byte构成Lower TL Half-Flit,32-63 Byte构成Upper TL Half-Flit。TL数据以Half-Flit为单位进行打包,并且第一个lower Half-Flit用来存放控制信息,这样的设计极大的降低了包解析时的复杂度,减少了延时开销。 但是32字节的空间用来放置请求控制信息显然是绰绰有余。 如下图(a)所示,此时控制信息占据了16Byte,剩余的16byte都为NOP信息;同时,由于TL Flit以64 Byte为一个整体,因此4号Flit在其Upper TL Half-flit用来填充载荷数据后,其Lower Half-flit绝大部份也被NOP占据, 仅有4个字节用于Flow Control(FC)。 可见这样的打包方式带宽利用率较低低,因此就有了下图(b)这样,将两个写请求合在一起打包,这样就可以充分利用原本被NOP占据的lower Half-flit。此外,我们还可以附带上两个与当前请求无关的WriteResponse请求,因为它不带有载荷数据。 但此时,算上FC信息后,还有共8个字节的空间被NOP占据,我们能否把这些闲置资源也利用起来呢?于是就有了下图(c)这种模式。这里我们打包了三个完整的写请求以及三个Compressed Write Response (CWR),这样没有空间被NOP闲置。 问题是,我们还能进一步提升打包的效率吗? 这就涉及到了请求信息压缩。请求信息中相当一部分为地址信息(e.g.,64-bit地址信息),但是由于访问的时空本地化(Temporal-Spatial Locality),通常一段时间内只会访问一段邻近的地址空间。因此,如果在发送端和接收端做地址Cache,我们就可以仅传输一小部分的地址位(通常是低地址位)并通过地址Cache重新构建完整的地址。在此基础上,再通过对请求信息的其他部分重新编码,就可以实现用8字节代表原先完整的16字节请求字段。这样,我们就可以实现如下图(d)所示的,对5个写请求和5个CWR的打包。 除了高效打包,TL还负责基于Credit的流控管理,在TL Flit中的FC域就是用来传递credit信息的主要途径。具体来说,在链接初始化时,所有虚拟通道(Virtual Channel)上的发送方都会收到接收方的缓存credit, 发送方据此设定对应的Credit计数器;每次发送端发送一个TL flit, 发送端根据TL Flit的大小,降低credit计数器的值,而接收方在处理完相应Flit,并从缓存中移除该Flit,新释放的credit被接受方放入相应Response Flit的FC域中;发送方在收到Response后,根据FC中的信息增加credit计数。由于在UPLI的设计中,无论请求是读或写,都有相应的Response,因此发送方的credit计数器都能得到及时更新。
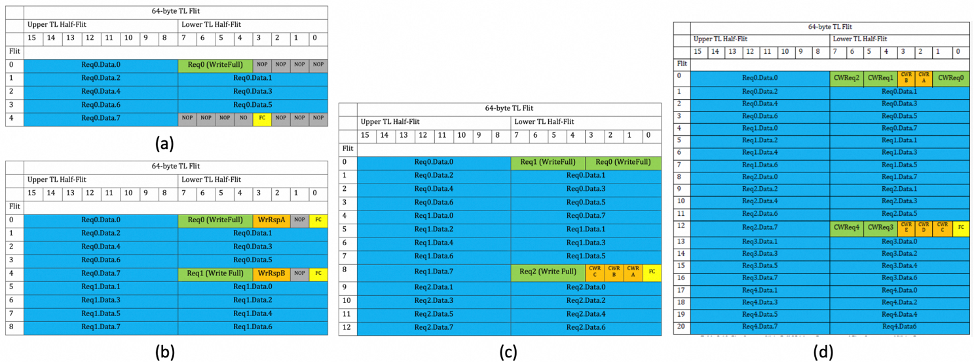
图9. TL Flit的组织形式
- 数据链路层在功能上,将事务层的TL Flits打包成640字节的DL Flit,或者将DL Flit解包多个TL Flits。这640 Byte的DL Flit还包含了 4Byte的CRC编码,3Byte的Flit Header以及5 Byte的Segment Header。由于要维持TL Flit的原子性(即,一个TL Flit不能被分割到不同的DL Flit上),一个DL Flit中包含9个TL Flit,考虑到用于CRC和Header的12 字节,还剩52字节空余。这部分剩余空间可以用来容纳DL-to-DL 消息或者只做Padding。数据链路层还需要支持 UALink构建Lossless 的Scale-up网络, 这也是为何需要有CRC的原因:用它来检测传输过程中是否出现了误码,并由此决定是否要启用链路层重传(Link-Level Retry)。支持重传也就意味着发送端需要保存发送出去的DL Flit,直到它收到来自接收端相应的ACK;但链路层支持重传所需的Flit缓存大小相较于端到端重传在源端的缓存小很多,实现复杂度也更低。这里有必要再提下物理层中加入的40Byte FEC,你可能会问,既然已经有了CRC,为什么还需要FEC?这是因为这里FEC通过纠正物理链路上传输出现的错误减少了循环冗余校验出错的概率,从而也减少了重传的概率,毕竟纠错的效率远高于重传;但是,FEC的纠错能力也是有限的,当误码率超过其纠错能力时,就由CRC兜底,通过重传来修复。另一方面,FEC涵盖的错误发生在物理传输链路上,而CRC还能涵盖部分缓存逻辑电路上的软错误。 因此,这两者是相辅相成的。
地址转换:同NVLink一样,UALink通过PGAS(Partitioned Global Address Space)编程模型将不同节点加速器上的内存组织起来构成一个全局统一的内存空间,实现基于地址的跨节点互访。这里就涉及到三个方面的地址: Gest Virtual Address (GVA),即源端加速器上所运行程序生成的地址; Network Physical Address(NPA),即网络物理地址,其中的部分信息用于指导UALink 交换机路由;System Physical Address(SPA),即远端加速器上的物理地址,它指向最终要访问的内存。 这三个地址之间存在GVA到NPA再到SPA的单向映射转换关系,其中GVA到NPA的转换由源端的MMU负责,而NPA到SPA的转换由Link MMU负责。当然,GVA不一定指向远端的地址,也有可能也是本地的地址,这也由源端MMU来负责区别和翻译。 UALink通过使用10-bit ReqDstPhysAccID来查找交换器内部的路由表来进行路由操作,因此UALink可以支持最多1024个节点;而这10bit的ReqDstPhysAccID通常是从NPA中提取或转换得到的。
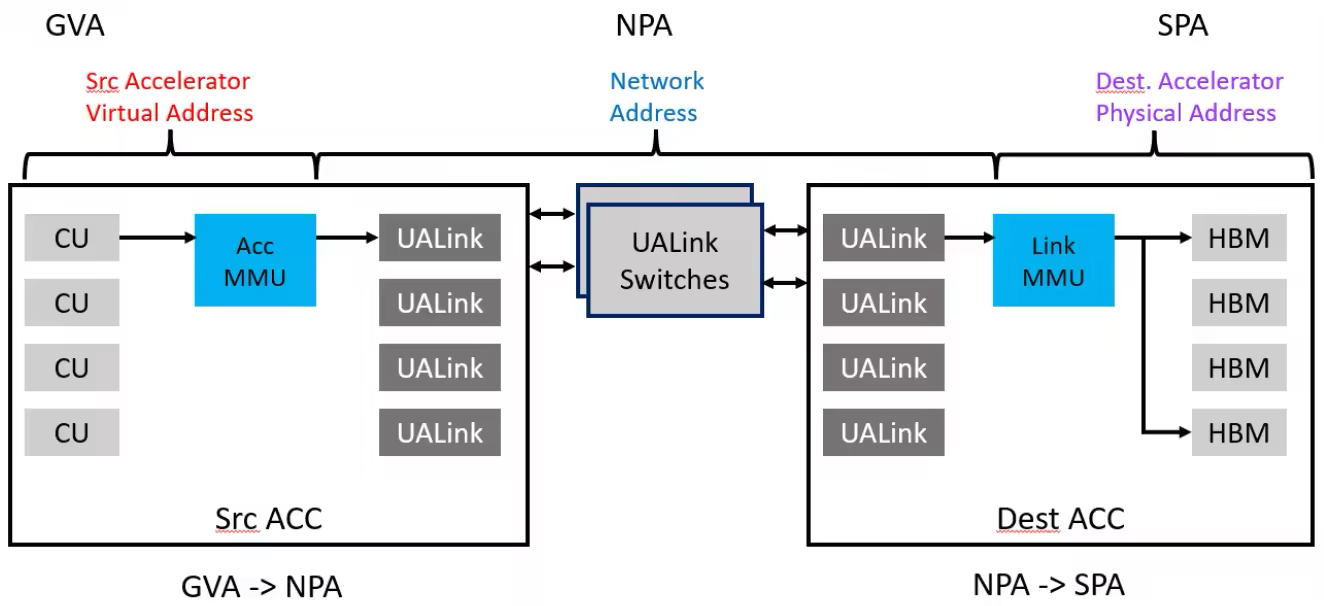
图10. UAL地址转换
UAL协议:探讨
UAL尽管实现了内存语义,但是它不支持硬件层面的内存一致性。 这是因为一方面,选择硬件层面不支持内存一致性,可以显著降低协议复杂性和实现成本,也降低了协议的延时开销; 另一方面在Scale-Up域,面向PGAS的编程对跨GPU的内存一致性并没有刚性需求,因为计算时的数据是以“Share Nothing”的方式分布的,但是GPU内部也有cache,如何保证GPU间通信时能拿到最新数据,就依赖于软件同步,比如显式的Cache Flush,Invalidation和memory fence等。 因此与CXL不同, UAL选择了轻硬件,重软件的模式,这对于专注于Scale-up的新协议来说,是一个务实明智的选择。 就像NVLink 2.0才开始在硬件层面支持内存一致性一样, 不排除UAL在生态站稳后,开始支持硬件一致性。
当前的UAL版本有点像CXL.mem,但是不同的是,UAL协议上是64-byte 寻址,而CXL是byte-addressable的。 基于64-byte的寻址是AI类负载在Scale-up域中访存行为特征的反应,能有效简化数据包的组织形式,提升带宽利用率;而CXL的细粒度访存能力为更加通用的场景提供了编程灵活性。 另一个不同点是: UAL支持原生的原子操作指令,但CXL.mem并没有原生原子操作命令,它需要CXL.cache的参与才能支持原子操作。 当然最终,原子操作都是有赖于目标端设备来实现。
UAL采用Credit-based Flow Control和Link Level Retry来实现链路的无损传输。这样可以快速从丢包中恢复,避免端到端重传带来的长尾延时, 这对于AI集群系统的性能至关重要。
UEC:再造以太
传统的以太网,尽管在广域网互连中取得了巨大的成功,但是在数据中心场景,尤其是面向AI和HPC应用的场景中,出现了水土不服,这在RDMA上显的尤为突出。尽管借助ROCEv2,RDMA在数据中心得到了广泛的应用,但它依然面临着不少问题和挑战[4],比如:
- RDMA网络规模扩展性问题。RDMA所依赖的Queue Pair配置是在RDMA环境初始化时设置完成的。尽管这种控制面和数据面分离的方式有它天然的好处,即在进行数据面操作时,无需考虑控制面,从而达到极高的传输效率,但这也意味着,初始化时需要将所有可能的QP都分配好。由于任意两个节点间的每个进程对都需要一个QP,对于一个N个节点,每个节点有P个进程参与通信的系统,这意味着整个系统需要分配P*P*(N-1)个QP。而对于一个scale-out训练用集群,这个N可能会达到几万到数十万。考虑到一个连接状态信息可能多大1KB, 显然,要维持这样规模数量的QP,对硬件来说极为昂贵。
- 在一个有损(Lossy)网络上构建RDMA的天然缺陷问题。传统以太网是一个有损网络,没有链路层重传(LLR),所有的重传都要通过端到端的传输层协议来实现,这一设计理念在广域网中是一个极具智慧的选择。它一方面降低了网卡和交换机的硬件成本,提升了网络规模扩展的效率;另一方面, 它也是一种高效的错误隔离手段,避免了因为硬件缺陷结合链路层重传而导致的错误扩散。但是RDMA要构建在无损网络之上,为了支持数据中心RDMA,RoCEv2通过三层的ECN(Explicit Congestion Notification)和CNP(Congestion Notification Package)再结合二层的PFC(Priority Flow Control)构成的DCQCN来创建处一个近乎无损的网络。这是一个复杂的,混合了二层/三层的技术组合,带着浓浓的应对先天不足的无奈。
因此,在面向AI和HPC负载的场景中,我们需要一个从头重新思考和构建的新以太,而不是在原有协议上的修修补补。
UEC协议概览:
UEC依然采用传统以太网的四层协议架构,但是在数据链路层加入了Credit-based Flow Control以及链路层重传的支持,实现了原生的无损网络,并对传输层做了根本上的重构,通过定义Semantics Sublayer(SES),Packet Delivery Sublayer(PDS),Congestion Management Sublayer(CMS),以及Transport Security Sublayer(TSS)四个子层,实现了对上层语义,短时连接,多路径,拥塞控制,传输安全等方面的支持。 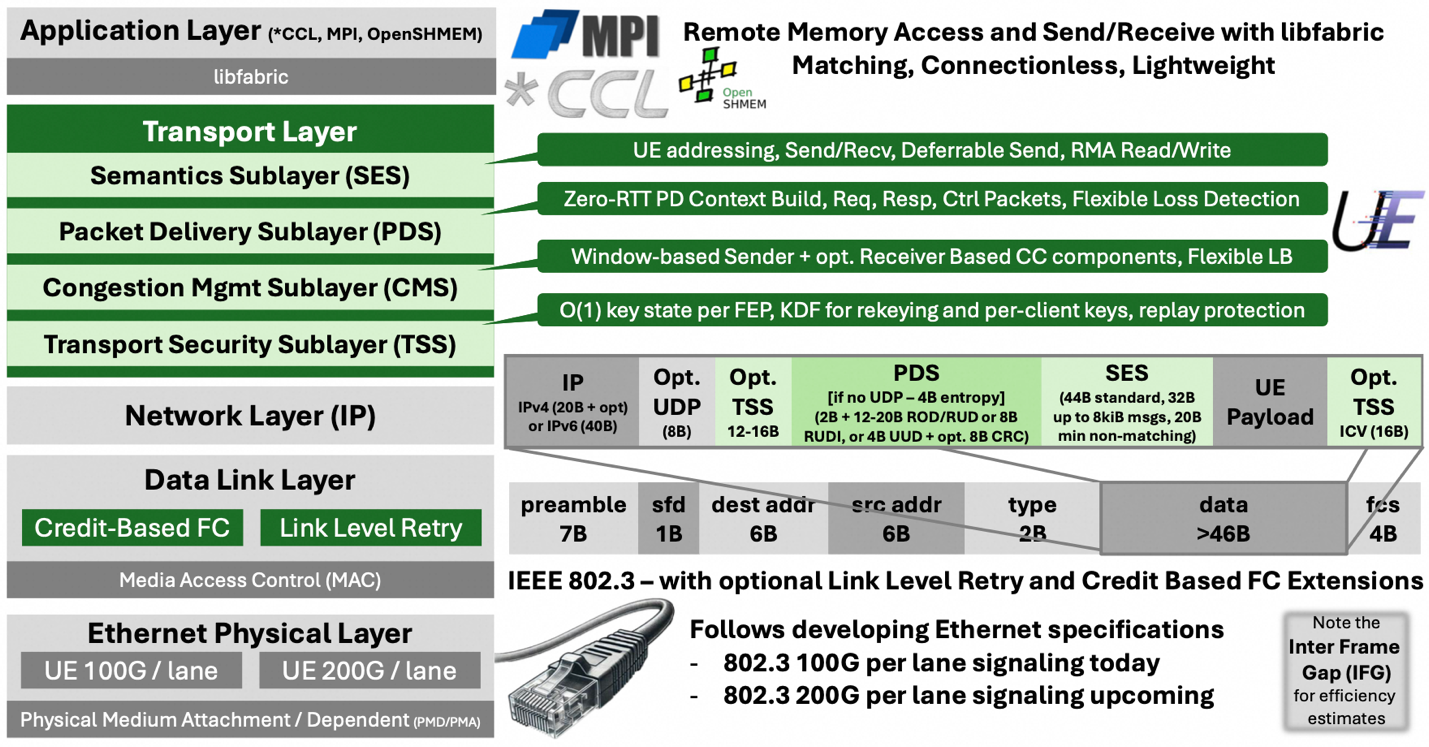
图11. UE 整体架构图(Source:[2])
短时连接(Ephemeral Connection):为应对RDMA网络规模扩展性的问题,UEC重新构建了QP的配置方式。它基于这样一个观察:一个节点不可能同时与所有其他节点及进程通信, 即便像是All-to-all这样的集合通信,它也是分解成点对点通信以一定的顺序完成(e.g.,Recursive-Doubling算法)。因此,从一开始就为每个节点设置所有可能的QP其实是一种保守的资源over provisioning。 一种更为高效的做法是预留少量的QP资源池,在实际通信时动态的复用和释放这些QP资源,这就是Ephemeral Connection的核心想法。具体来说,UEC在PDS子层中定义了Packet Delivery Context(PDC),这是一个动态创建的为连接提供上下文的逻辑结构,与它相关联的信息包含:Job_ID, source Fabric Address, destination Fabric Address, Resource Index, Traffic Class等。 下图展示了短时链接构建的流程: 当源端发起连接的首个包时,它将源端的PDC ID和它期望目的端分配的Context信息放入包头,并将SYN设为1;当目的地端收到这些PDS请求包时, 由于SYN=1,它将检查相关连接是否已经建立;若没有,它分配一个PDCID并从相应的资源池中获取与之相关联的缓存资源,其中在PDC中Resource Index,可以被看作是指向缓存队列的指针;之后,目的地端将新分配的PCD ID通过ACK返回给源端;源端收到ACK后,后续的PDS请求中DPDCID被设为目的地新分配的PCDID,同时SYN被置为0;至此,连接构建完成。可以看到,短时连接的建立过程极为高效,它和数据传输是同步进行的。
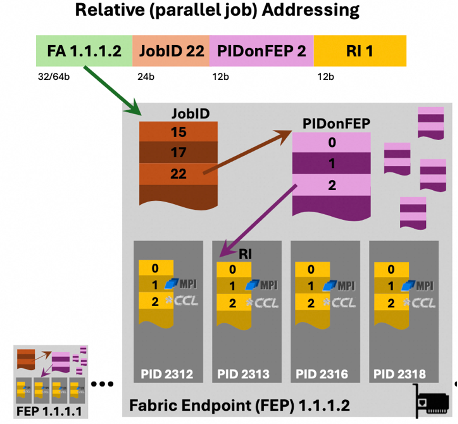
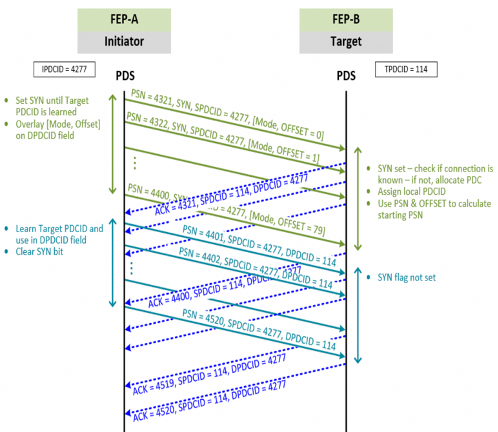
图12. 短时链接构建流程
多路径(Multipath)和包喷洒(Packet Spray): 传统的ECMP(Equal-Cost Multi-Path)是面向基于五元组(源和目的地址、源和目的端口,以及协议类型)定义的流。不同的流会被哈希到不同的路径上, 但同一个流中的所有数据包都沿同一条确定性路径转发。显然,对于AI场景中常见的大象流,这种方式并不能充分利用多路径带来的带宽。因此,在UEC中, 多路径的对象成了数据包,使得同一个flow中的不同数据包也可以走不同的路径。为达到这一目的, UE在UET包头中引入了一些随机机制或者Entropy,并参与到选择路径的哈希中。具体来说,当UEC使用UDP封装时,随机生成的UDP源端口被用作Entropy。这是因为UDP中,一般发送方不期望得到接受方的回复,因此源端口通常是可选的,UEC利用了这一点,将随机性注入数据包头中。若UEC不使用UDP封装而是仅采用IP封装,那么,就必须使用UET Entropy Value(EV),作为PDS包头的一部分。网络节点可以通过选择不同的EV,让每个数据包经过不同路径发送;也可以对数据包使用相同EV,确保它们能够按序交付。
乱序包交付,顺序消息交付(Out-of-Order Packet Delivery with In-order Message Delivery):在使用多路径和包喷洒的情况下,必然出现数据包的乱序到达。好在包括AI/ML类负载在内的大部分应用并不关注数据包到达的顺序,只关注消息到达的顺序。但也有些应用需要In-order Packet Delivery,比如一些Legacy的HPC应用,网络入侵检测系统等。为此,UEC定义了可靠无序交付模式(Reliable Unordered Delivery,RUD),不可靠无序交付模式(Unreliable Unordered Delivery, UUD),可靠有序交付(Reliable Ordered Delivery,ROD),以及幂等可靠无序交付 (Reliable Unordered Delivery for Idempotent Operations,RUDI) 四种模式,来应对各种场景需求。 其中RUD是UEC默认的传输模式,它充分利用了多路径带来的高带宽利用率,结合RDMA所带来的Direct Data Placement,让数据包直接放入应用的内存空间中,避免了NIC缓存中转。为确保消息的顺序交付, 每个消息都关连一个ID(Message ID,MID),每发送/接收一个消息都会在本地递增该消息ID。这样,若一个消息的数据包都到达,但是它的ID大于当前预期的ID,该消息就被Hold住,直到前面的所有消息完成交付。 在这种模式下,若出现丢包现象,则采用选择性重传(Selective Retransmission)以实现高效的丢包恢复。 而ROD模式禁用了包喷洒,确保数据包能够顺序到达, 并采用传统的Go-Back-N重传的方式应对可能出现的丢包情况。
拥塞控制: UEC的拥塞控制主要承载在CMS上。它定义了两个互补的拥塞控制算法:一个是主要运行在发送端的基于网络信号拥塞控制(Network Signal-based Congestion Control,NSCC);另一个是主要运行在接收端的基于接受端信用拥塞控制( Receiver Credit-based Congestion Control,RCCC)。 它们可以单独使用,也可以一起使用。
- NSCC综合考虑两个网络指标: ECN标识和Round-Trip Time(RTT)。与传统的DCQCN不同, ECN标识的拥塞信息不是通过CNP包反馈给源端,而是通过ACK包头上的Congestion Control(CC)State域来传递的,从这层意义上来说,它和DCTCP相似。不同的是,NSCC还综合考虑RTT,而RTT的测量是基于时间戳(Timestamp)来实现的:发送端会记录发送PDS请求的时间戳,同时也会记录对应ACK到达发送端的时间戳,两者的差再减去ACK包在接收端生成的时间,就是RTT较为精确的测量值。于是,我们就有了是否有ECN标识以及RTT高低所构成的四种不同状态组合,NSCC将根据这些状态组合来调整发送窗口的大小,从而实现拥塞控制。
- RCCC通过以Credit表示的接收端可用缓冲区大小来做拥塞控制。从大的方面来讲, RCCC的控制机制和传统的基于Credit拥塞控制方式差别不大:都是在发送端和接收端都维持Credit Counter,在发送端每发送一个数据包,相应的credit 计数器减一,当credit计数器到零时,发送端暂停发送数据包;当它收到来自于接收端的Credit更新(包含在ACK报文中), 相应的Credit计数器将增加相应的量。 那么,发送端是如何在一开始知道接收端Credit数量的呢?这就是RCCC和传统的基于握手方式不同之处:RCCC一开始通过一个小的“Eager Window”发送数据包,这个窗足够小,确保接收端不会出现credit耗尽的情况,同时,利用这期间的ACK,发送端就可以知道接收端的Credit数量。
安全: UEC专门强调了数据传输安全并由TSS来承载, 解决了传统RDMA网络上没有原生加密支持,依赖于IPsec,性能开销大的问题。 TSS可以有选择性的对PDS包头(不包含Entropy域)和Payload数据进行加密。这里我们介绍两点UEC的安全特性:
- 密钥分发:由于面向AI的负载,来自于一个租户的任务需要大量节点共同参与,如果采用传统的点对点密钥的方式,那么系统就要分发和管理Nx(N-1) 份密钥,这不仅带来了高昂的密钥分发成本,而且也因管理密钥造成了不小的性能开销。事实上,这种点对点的加密对于一个租户来说没有必要。因此TSS定义了一个Secure Domain(SD),所有在这个SD内的节点都共享相同的Secure Domain Key(SDK)。 这个SDK通过安全的带外通道分享给所有SD节点。 每个节点上,TSS采用Key Derivation Function (KDF),结合每个工作任务的Session,从SDK中推演出相应的密钥。这样每个Session,所有节点都有相同的密钥,不同session的密钥不同,而且也避免了每次Session密钥分发的开销。
- 重放攻击(Replay Attack)的防护机制。所谓Replay攻击,是指攻击方通过劫持或拷贝原通信数据包,然后向目的地重新发送这些数据包,使系统在未经用户授权的情况下,让系统重复之前的操作。由于PDS连接本质是无状态的,因此在建立PDS的时候,如果可以接受任意起始的 Package Sequence Number(PSN),UEC系统就容易受到Replay 攻击。为此,TSS在一个SD中保留了start_psn和expected_psn。当接收端收到的连接请求中PSN小于 expected_psn,接收端会生成一个NACK,指示应使用的起始PSN;否则,该请求将被接受。当PDC关闭时,目标端的 expected_psn 会被更新为该PDC的当前PSN+1。这样当Replay攻击者发送之前的包文时, 由于报文的PSN小于expected_psn,因此该报文不会被接受,从而避免了重放攻击。新的 expected_psn 值会作为关闭PDC确认(ACK)的一部分返回给源端,源端随后将 start_psn 更新为此值,以确保后续连接可以以零往返时间建立。
UEC协议:探讨
综上,可以看到UEC是对传统以太网在数据中心中应用的经验提炼,对RDMA网络所面临问题的全面思考,并在此基础之上提供了一个崭新的网络基座。 很多传统以太网在数据中心中遇到的问题将不复存在。
和UAL一样,UEC也通过CBFC和LLR,实现了链路层的无损传输,这充分响应了大规模AI集群在长尾延时方面的诉求。同时,对可能出现的失效因LLR的扩散问题,在数据中心的高可观察/高可控环境下,有多种技术和手段予以应对。
UEC所面对的Scale-out网络规模大约在万卡到数十万卡量级。 这样的规模决定了其通信时延的量级,进而决定了UEC必然要采用面向连接的消息语义,而非面向内存的LD/ST语义。 面向连接的消息语义意味着有消息准备和消息到达通知等开销,通信粒度较大,时延较长,但是它可以在程序层面通过异步非阻塞(non-blocking)通信机制让计算隐藏一部分的通信延时;而面向内存的LD/ST语义则意味着更细的通信粒度(Cacheline级别),更短的延时(数百纳秒内),在GPU上,Load延时隐藏通常通过Warp的快速切换来实现。这两种截然不同的机制决定了Scale-out网络和Scale-up网络存在着清晰的边界。Scale-Up网络无法支撑起Scale-out网络的规模;反过来, Scale-out网络也无法实现Scale-up网络的性能。
竞合的互连江湖
Scale-up Ethernet (SUE): 何方神圣?
如果你了解UALink的成立过程, 你会发现博通一开始是在创始成员名单中,但后来并不在董事会成员中,而是自立门户,拉起了一杆SUE的大旗。 这里就有两个问题: 首先SUE是个啥?根据博通在25年7月发布的"33页"SUE规范,我们可以发现SUE和UAL有着诸多相似之处:都采用200G 以太网的PHY,都支持LLR和CBFC,都支持内存语义, 支持的超节点规模都是1024个。 但技术上,两者最根本的区别在对数据的封装上。UAL定义了全新的传输层和数据链路层的封装格式,其中传输层的包头包含了内存操作类型,支持原生的内存语义;而SUE要么采用传统的UDP+IP+以太网包头封装,要么采用AI Forwarding Header Gen 1/2格式的封装,如下图所示。 SUE上内存操作请求被放在SUE Payload中,发送到对端。可以看到,SUE的封装沿用了很多传统以太网的做法,相较于UAL复杂度更高,链路所需的延时也更高,大约比UAL多出数百纳秒。


图13. SUE的几种数据打包格式
那么,博通为什么弃UAL而推SUE? 这得从另一方面的信息来解读: 几乎在发布SUE规范的同时, 博通就发布了支持SUE的Tomhawk Ultra Switch芯片,并且和Tomhawk 5.0实现了Pin脚兼容。这说明,博通在SUE上已经在背后耕耘了很久。起初推动UAL成立的目的大概率是看看能否将SUE的这套规范推进到UAL,从而以近乎零成本占据Scale-up互连的最佳生态位。但在UAL坚持从头设计精简的封装模式后,如果还留在UAL,那反而成了后续SUE产品的反向宣传,不如退出。那么,博通为什么选择SUE这条路线呢?我们推断这是因为它在以太网交换机上有太多的利益。在以太网基础上进行轻量化改造,能够实现快速time-to-market, 先下手为强,抢到Scale-up互连的蛋糕, 不香么? 相比之下,最早支持UAL的芯片或交换机可能要等到2026年年末。
我们乐见博通能从NVLink虎口夺食, 但不认为SUE是Scale-Up协议发展的趋势。 如前所述,一个好的Scale-Up协议必须是延时导向的,内存语义原生的精简协议,才能解决Scale-Up网络的需求。而SUE复用了不少以太网的封装模式,看起来更多的是一个产品策略。虽然博通声称SUE是开放标准,谁都可以使用,但是相比UAL标准的253页和UEC的563页,SUE这33页规范,像是个产品说明书,多少让人感觉少了些诚意。
Scale-up域,何处是边界?
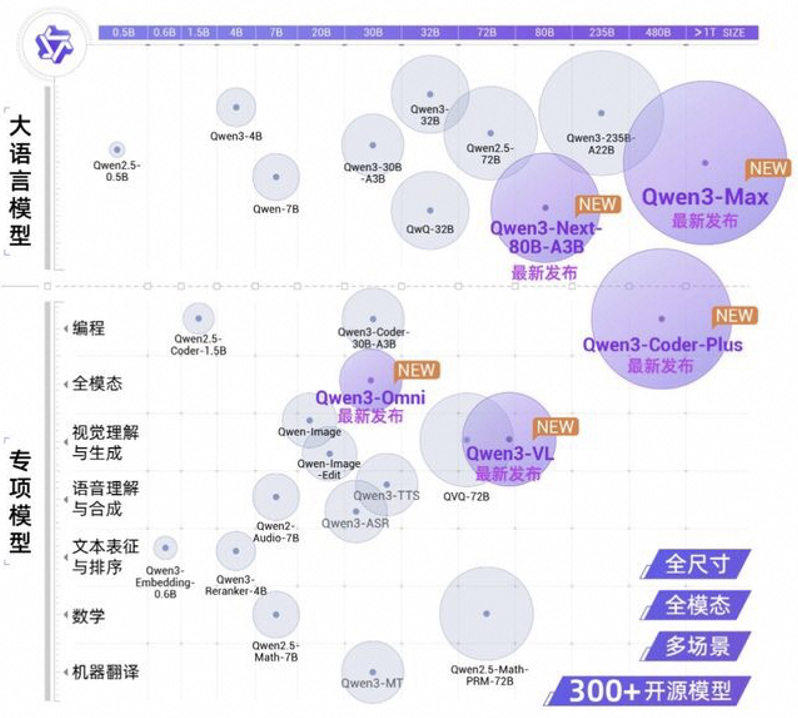
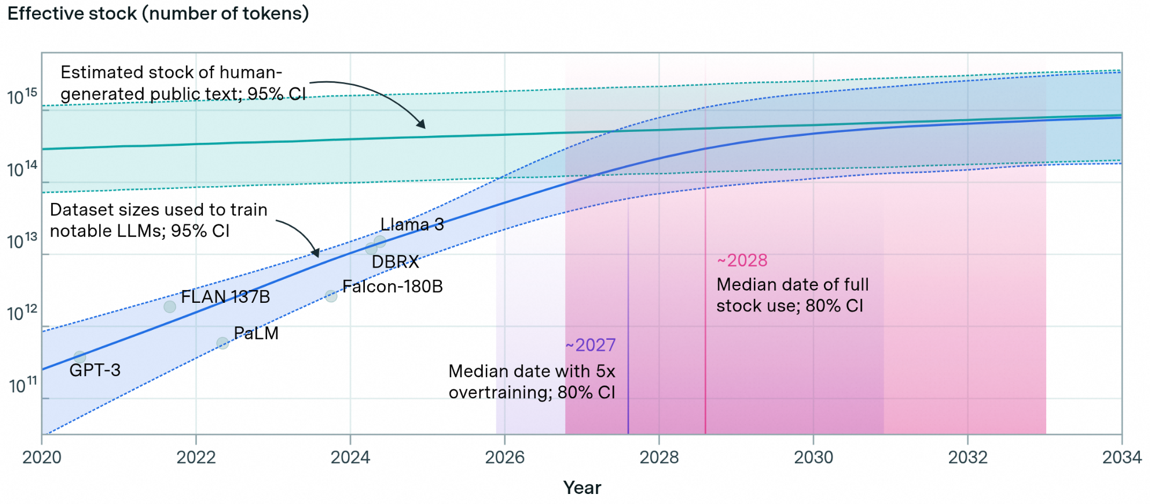
Scale-up域的大小根本上由两个因素决定:模型的大小和GPU算力及显存大小。模型的大小主要由两方面决定:静态的模型参数规模和动态的内存KV Cache。 下图(a)展示了QWen系列模型的大小。可以看到,突破模型大小边界的任务还是由语言类大模型来承担,其他各种专项或者多模态模型明显小于同代次LLM模型参数规模。但是即便是LLM,它模型参数的增长已经过了爆发式增长期,开始逐渐减缓。这背后一个更深层次的原因是,用来训练的数据已经接近人类产生的公开文本数据的上限,如下图(b)所示。 这在某种程度上也解释了为何当前Pre-training Scaling逐渐变缓。但也是因为随着scaling的重心转移到test-time scaling上, 长上下文所带来的KV cache的内存需求迅速增加,对内存容量的需求甚至超过了模型参数。 但为了应对KVCache对内存容量的挑战,业界也有大量的针对KVcache 的量化,压缩,和注意力稀疏化的工作,来减少KVcache的增加对内存容量和性能的影响。 所以,综合来看,我们的判断是大模型对内存容量的需求在未来还会持续增长,但是增长速度会明显放缓。
(a)
(b)
图14. (a)通义大模型参数规模;(b) LLM训练用数据vs人类产生的数据 [5]
接着,我们再来看GPU算力/显存密度。下表展示了NVIDIA和华为的GPU/NPU产品线在算力和显存容量上的对比。 可以看到,NVIDIA的单位GPU的FP4算力几乎以每年两倍的速度在增长,而显存容量在Rubin Ultra这一代比之前增加到近4倍。相比之下华为的昇腾系列,虽然算力也以每年两倍左右的速度在增长,但由于起点较低,在算力密度上和NV产品线保持着大约25倍的差距。显存容量方面, 昇腾960和Rubin相仿,但是与Rubin Ultra相比也差了4倍。 虽然国内还有众多其他的GPU生产商, 但这些差距基本反映了当前国内在半导体制程,HBM,以及先进封装方面整体落后于美国的现状。
表2. 两家GPU产品线的算力和显存对比
|
NVIDIA |
Blackwell 200 (2025) |
Rubin (exp. 2026) |
Rubin Ultra(exp. 2027) |
|
算力 |
20 PFLOPS @ FP4 |
50 PFLOPS @FP4 |
100 PFLOPS @FP4 |
|
显存 |
192GB |
288GB |
~1TB |
|
华为 |
昇腾910C (2025) |
昇腾950PR/DT (exp. 2026) |
昇腾960 (exp. 2027) |
|
算力 |
800 TFLOPS @ FP16 |
2 PFLOPS @FP4 |
4 PFLOPS @FP4 |
|
显存 |
128GB |
144GB for 950DT |
288GB |
基于这样的现状和地缘政治,我们可以推断中美两国AI集群将呈现两种不同的形态:美式AI集群,由于单卡算力和显存密度高,其Scale-up域会尽量锚定在一个机柜内,毕竟这样Scale-up域无需经过多级交换机,整体通信延时是最优的。尽管NVIDIA将推出Vera Rubin CPX Dual Rack产品,但这是一种PD分离的组织方案, 两个机柜并不在一个Scale-up域:Rubin CPX机柜专用于Prefill,通过InfiniBand或Ethernet 与VR NVL144机柜相连。国内的AI集群,由于单卡算力密度和显存密度较低,其Scale-up域必然比美式集群的Scale-up域大。一个典型的例子就是华为的CloudMatrix384 [6],它有16个机柜,其中12个用于计算,4个用于互连交换;384个NPU被分配到48个计算节点中,每个计算节点含8个NPU;所有NPU通过两级UB(Unified Bus)交换机连接,其中,一级交换机在计算节点内部,一级和二级交换机间通过LPO(Linear Pluggbale Optics)互连。两级交换可以支撑更大规模的Scale-Up域,384NPU处理器显然不是它能达到的上限。因此,我们预计Scale-up集群规模会经历扩大再收缩的过程: 规模扩大是因为当前国产单卡的算力和内存密度演进速度还未赶上大模型的发展速度,扩展超节点规模是最直接的应对方式;但是随着单卡算力和内存密度的快速提升,系统对互连延时的敏感性也迅速增加,过长的延时将使集群算力利用率迅速下降,因此像CloudMatrix384这样的两级交换超节点架构,必然要回归到单级交换,单机柜超节点的形态。 这必然对机柜的高密度架构设计,供电和散热都提出了巨大挑战。从这层意义上来说说, 单机柜的硬件工程能力(高密,供电,散热)决定了超节点规模的边界。 阿里云在这一领域也走在业界的最前沿。
CXL能否王者归来?
在2021-2022年,CXL几乎统一了包含GenZ,OpenCAPI,CCIX在内的主要服务器级内存一致性互连,风头盛极一时。但随着LLM大模型的兴起,大量的资本被吸引到AI基础设施的建设上,CXL领域的投入因为无法看到短期收益而大幅减少,其发展从聚光灯下,移到了幕后。但是CXL标准并没有停止演进,自从CXL 3.1推出GIM之后,CXL就开始摆脱非对称内存访问的标签。从功能上来讲, CXL具备了UAL的几个关键特性:内存语义,设备间内存互访;此外,它还具有UAL不具备的特性,比如,Host和设备的统一编址(UMA)以及通过CXL交换机的GPU资源池化,前者可以为推理系统提供更加庞大且相对廉价的内存,而后者则为节点的GPU Scale-Up提供了另外一种技术路径。 但是不幸的是,PCIe的速率问题严重影响了CXL潜力的发挥:当前主流的PCIe Gen5的速率才达到32GT/s,而PCIe Gen 8 虽然速率将达到 256GT/s,其x4的带宽和UAL 1.0的x4带宽基本持平,但是它要到2028年才可能有相应的IP,而要被集成到GPU中,则需要等待更长的时间。 这里的有两个问题需要回答:
- GPU集成CXL的动因是什么?由于GPU是以PCIe设备的形式呈现给操作系统的,因此GPU上必须要集成PCIe接口。即便是像GB200那样,CPU和GPU之间通过NVLink-C2C相连,它们之间也需有一个x1的PCIe通道来做GPU的枚举和设备配置等控制面的工作,而NVLink-C2C则负责数据面的数据搬移工作。但这是NVIDIA的专属方案,在开放世界中,最主要的方式依然是采用PCIe来同步承接控制面和数据面的工作,并且常以x16的端口形态出现,以满足CUDA Kernel Launch时数据搬移所需带宽。但除此以外,在AI集群中,GPU的PCIe端口带宽利用率很低,这其实是一个不小的浪费。而当PCIe演进到Gen7/8,在这之上的CXL一方面提供了与UAL相近的带宽,另一方面也实现了Host和GPU的UMA,两者结合可以极大的改善带宽利用率。相对于PCIe,它不增加额外引脚数,不会对芯片紧张的IO Pad面积增加额外的压力。这里面的巨大正收益将驱使非NVIDIA的GPU集成CXL,使它们与NVIDIA GPU在UMA上处在同一水位上。
- 对于集成CXL的GPU,其集群的组织形态有什么变化?像GB200那样,Host CPU和GPU之间的直连是利用CXL-enabled GPU的最直接的方式。此时由于CPU引脚资源受限,同时又要预留较多引脚给DDR内存,因此单个CPU直连的GPU数目较少,CXL在这里的作用就是构建Host与GPU之间的UMA。但CXL还提供了另外一种集群组织形态:GPU通过CXL 3.1 Switch连到CPU。此时,CPU与挂载在Switch上的各个GPU之间构成统一的内存空间;同时,GPU与GPU之间通过 CXL Switch实现点对点通信。 由于CXL的P2P通信地址分配和UAL的地址分配存在冲突,因此,在采用CXL Switch后,GPU就只能通过它来构成Scale-Up域。该Scale-Up域的GPU数量取决于CXL Switch的端口数量,64或32是一个可以实现的配置(当然,可以通过两级交换机的方式实现单个 Scale-Up域更多的GPU数量支持,但访存延时将增加)。而Scale-Out通信则通过挂载在同一个CXL Switch上的多张网卡来实现。与现有超节点集群不同,这个组织架构一定程度上回归了传统基于PCIe交换机的集群构建模式,但因为CXL,也具有了一些令人期待的特性:通过CXL Switch,它提供了更加灵活的CPU-GPU配比;通过CXL Memory,提供了更加灵活和低成本的内存扩展等。我们认为这是一个值得探索的方向,当然也有赖于整个CXL上下游生态的共同努力。诺能成, 则是CXL的高光时刻,我们拭目以待。
结语:
过去几年,大模型的爆发式发展对AI基础设施提出了巨大的需求,我们见证了私有互连的春天:那些具有完整芯片产品线且积极布局互连技术的公司,比如NVIDIA(NVLink),AMD(Infinity-Fabric),以及华为(Unified Bus),是最先吃到这波AI基建浪潮红利的玩家。 而开放互连的春天要来的晚一些:UAL和UEC相应的产品落地可能需要到26年年底。好在整个行业已经通过UCIe/CXL/UAL/UEC构建起了一个从芯粒互连到Scale-Out互连的完整技术路图。 或许感受到了来自于开放互连的压力,NVIDIA也开始尝试NVLink IP授权的商业模式,结合近期Intel和NVIDIA的合作,不难想象在不久的将来,我们可能会看到在x86 CPU通过NVLink与NV GPU相连的服务器产品。这反过来把压力传递到了开放互连这边。 这是“独行快,众行远”的生动展现;我们也希望通过私有和开放的相互竞争,彼此成就,推动互连技术的发展,最终实现AI的普惠。
参考文献:
[1]. Yiren Zhao, Ran Shu, and Yongqiang Xiong. 2025. SRC: A Scalable Reliable Connection for RDMA with Decoupled QPs and Connections. In Proceedings of the 9th Asia-Pacific Workshop on Networking (APNET '25). Association for Computing Machinery, New York, NY, USA, 44–50. https://doi.org/10.1145/3735358.3735366
[2]. Hoefler T, Schramm K, Spada E, Underwood K, Alexander C, Alverson B, Bottorff P, Caulfield A, Handley M, Huang C, Raiciu C. Ultra Ethernet's Design Principles and Architectural Innovations. arXiv preprint arXiv:2508.08906. 2025 Aug 12.
[3]. Wu, X., 2025. Sailing by the Stars: A Survey on Reward Models and Learning Strategies for Learning from Rewards. arXiv preprint arXiv:2505.02686.
[4]. Hoefler, Torsten, Duncan Roweth, Keith Underwood, Bob Alverson, Mark Griswold, Vahid Tabatabaee, Mohan Kalkunte et al. "Datacenter ethernet and rdma: Issues at hyperscale." arXiv preprint arXiv:2302.03337 (2023).
[5]. https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
[6]. Zuo, P., Lin, H., Deng, J., Zou, N., Yang, X., Diao, Y., Gao, W., Xu, K., Chen, Z., Lu, S. and Qiu, Z., 2025. Serving Large Language Models on Huawei CloudMatrix384. arXiv preprint arXiv:2506.12708.
[7]. https://01.me/en/2023/09/towards-compute-native-networking/

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)