深入浅出大模型量化(一):LLM.int8()与GPTQ原理解析
深入浅出大模型量化(一):LLM.int8()与GPTQ原理解析
深入浅出大模型量化:LLM.int8()与GPTQ原理解析
大家好!我是你们的老朋友小雲。最近,大模型的热度持续不减,但随之而来的“甜蜜的负担”——巨大的模型体积和显存消耗,也让许多同学和开发者感到头疼。如何在有限的硬件资源下,高效地运行这些庞然大物? 模型量化技术应运而生,成为了解决这个问题的关键钥匙之一。
今天,我们就来聊聊两种在业界非常流行且效果显著的量化技术:LLM.int8() 和 GPTQ。我会用尽可能通俗易懂的语言,带你深入了解它们背后的原理和实践。这篇文章特别适合对大模型和NLP有基本了解,但对量化细节还不太清楚的同学们,希望能帮助大家在学习和面试中更有底气!
量化的目标:给大模型“瘦身”
在我们深入探讨具体技术之前,先明确一下,大模型量化到底是在对模型的哪些部分进行“瘦身”?
主要对象包括:
- 权重 (Weights): 模型参数的主体,占据了绝大部分存储空间。这是量化的首要目标。
- 激活 (Activations): 模型在推理过程中,层与层之间传递的中间数值。量化激活可以减少计算过程中的显存占用和访存开销。
- KV Cache: 在Transformer模型的自注意力机制中,为了加速生成过程,我们会缓存过去的键(Key)和值(Value)。对于长序列,KV Cache的显存占用非常可观,对其量化也很有必要。
- 梯度 (Gradients) & 优化器状态 (Optimizer States): 这两者主要在训练过程中出现。量化它们可以减少训练时的显存占用和节点间的通信带宽。不过,我们今天的重点是推理优化,所以主要关注前三者。
基于量化对象的不同,常见的量化方案有:
- 仅权重量化 (Weight-only Quantization): 比如 W4A16(权重4bit,激活16bit)、W8A16(权重8bit,激活16bit)。GPTQ 主要属于此类。
- 权重和激活同时量化 (Weight and Activation Quantization): 比如 W8A8(权重8bit,激活8bit)。SmoothQuant 是一个代表。LLM.int8() 在某种意义上也属于此范畴,但它更特殊一些。
- KV Cache 量化: 通常采用 INT8 量化。
现在,让我们正式进入今天的主角:LLM.int8() 和 GPTQ。
LLM.int8(): 巧妙处理“异常值”的混合精度量化
背景:大模型中的“捣乱分子”——离群特征
想象一下,你在整理一箱苹果,大部分苹果大小适中,但有几个特别巨大。如果让你用统一尺寸的盒子去装,要么小盒子装不下大苹果,要么用大盒子装小苹果会浪费很多空间。
LLM.int8() 的作者们在研究大模型时,发现了一个类似的现象:在模型的激活值中,存在一些数值特别大(绝对值远超其他值)的“离群值”(Outliers)。更关键的是,这些离群值往往集中在少数几个特征维度(Feature Dimensions)上。
以一个典型的矩阵乘法 Y = XW 为例,X 是输入激活(形状 [序列长度 T, 隐藏层维度 h]),W 是权重(形状 [隐藏层维度 h, 输出维度 h0])。这里的“特征维度”主要指 h 这个维度。
传统的量化方法,无论是 per-token(对 X 的每一行使用一个量化缩放因子)还是 per-channel(对 W 的每一列使用一个量化缩放因子),都很容易被这些极端离群值“带偏”。为了容纳这些离群值,量化范围必须拉得很大,导致大部分正常数值的精度损失严重,就像用大盒子装小苹果一样。
既然离群值只出现在少数特征维度上,LLM.int8() 的核心思想就来了:能不能把这些包含离群值的特征维度“拎出来”单独处理,剩下的“乖孩子”们再进行常规的 INT8 量化?
技术原理:混合精度分解 (Mixed Precision Decomposition)
LLM.int8() 正是基于上述思想,采用了一种混合精度分解的策略。它并没有直接修改量化算法本身,而是在矩阵乘法层面做了分解。
对于矩阵乘法 Y = XW,LLM.int8() 的计算过程大致分为三步:
-
识别与分离 (Identify & Separate):
- 首先,确定一个阈值(比如 6.0)。
- 遍历输入激活
X的每一列(即每个特征维度)。如果某一列包含绝对值大于阈值的离群值,则该列对应的整个特征维度被标记为“离群特征维度”。 - 将输入
X分解为两部分:X_outlier(只包含离群特征维度的列,其余列为0)和X_regular(只包含非离群特征维度的列,其余列为0)。 - 相应地,权重
W也根据“离群特征维度”的行(因为W的行对应X的列)进行分解,得到W_outlier和W_regular。
-
分别计算 (Separate Computation):
- 离群部分: 对离群特征维度,执行高精度(FP16)的矩阵乘法:
Y_outlier = X_outlier @ W(或者等价地X @ W_outlier)。注意,这里虽然分离了X_outlier,但乘法通常还是和完整的W(或者X与W_outlier) 进行,只是因为X_outlier中很多列是0,实际计算量集中在离群维度上。 (注:原论文图示更侧重分解 W,但实际操作中分解 X 更常见,核心思想一致) - 常规部分: 对非离群特征维度,执行 INT8 量化计算:
- 将
X_regular进行 vector-wise (per-token) INT8 量化,得到X_regular_int8和量化尺度S_X。 - 将
W_regular进行 row-wise/column-wise (per-channel) INT8 量化,得到W_regular_int8和量化尺度S_W。 - 执行 INT8 矩阵乘法:
Y_regular_int8 = X_regular_int8 @ W_regular_int8。
- 将
- 离群部分: 对离群特征维度,执行高精度(FP16)的矩阵乘法:
-
合并结果 (Combine Results):
- 将 INT8 乘法结果反量化回 FP16:
Y_regular_fp16 = Dequantize(Y_regular_int8, S_X, S_W)。 - 将离群部分和常规部分的结果相加,得到最终的 FP16 输出:
Y = Y_outlier + Y_regular_fp16。
- 将 INT8 乘法结果反量化回 FP16:
你可以参考论文中的这张图来理解这个分解过程:
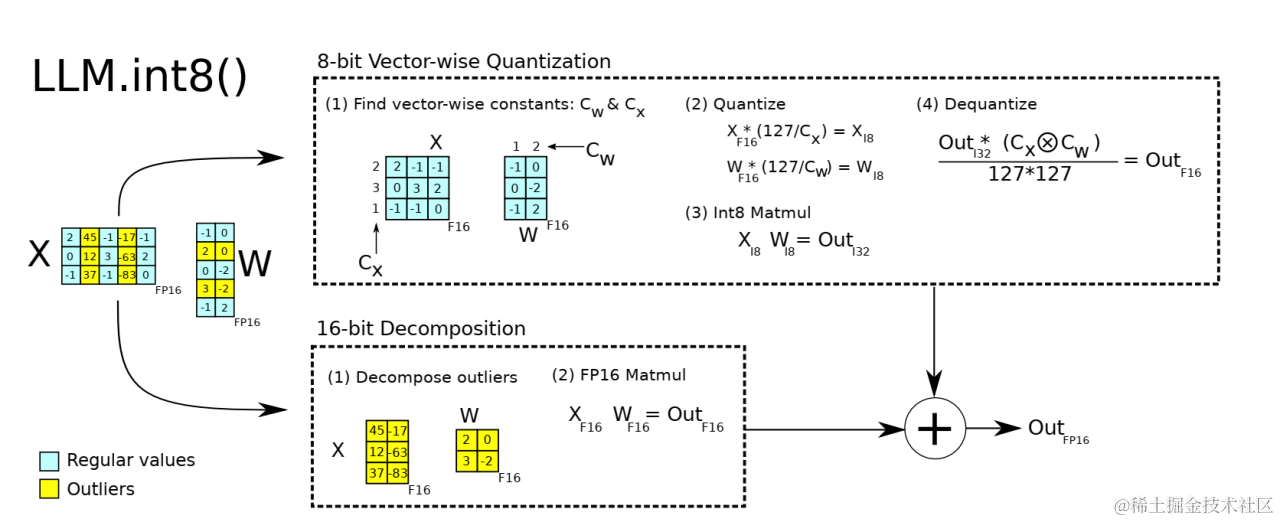
这种方法的巧妙之处在于,它没有牺牲离群值带来的重要信息(这些离群特征被认为对模型性能至关重要),同时让大部分计算享受了 INT8 量化带来的存储和潜在的计算优势。
性能与分析
实验结果表明,LLM.int8() 确实能很好地保持大型模型的性能,尤其是在6B参数以上,简单的INT8量化性能会急剧下降,而LLM.int8()能够几乎无损地恢复性能。
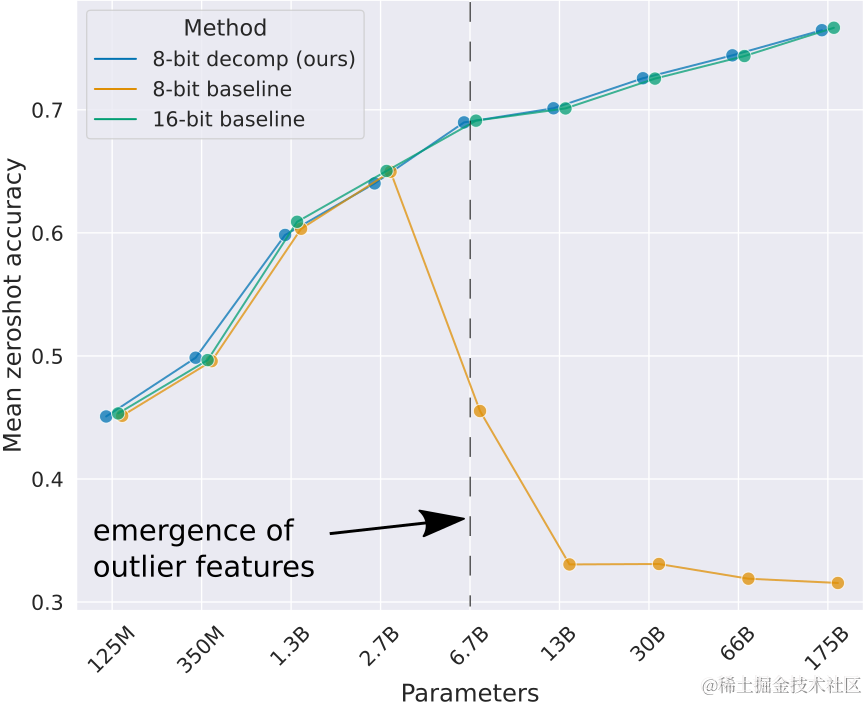
但是,天下没有免费的午餐。 这种混合精度计算和条件判断(分离离群值)引入了额外的开销,导致推理速度相较于纯 FP16 反而变慢了。对于 BLOOM-176B,速度大约降低了 15%-23%;对于小模型,这个差距可能更大。所以,LLM.int8() 主要的优势在于显著降低显存占用,使得大模型能在消费级硬件上运行起来,而不是追求极致的推理速度。
论文还深入分析了离群特征的出现与模型规模、性能(用困惑度 Perplexity 衡量)的关系。他们发现:
- 离群特征的出现并非模型规模独有,而是与模型的困惑度更相关。随着模型训练得更好(困惑度降低),离群特征会更显著。
- 大约在 6B 参数规模附近,离群特征出现的普遍性(影响的层数和特征维度比例)和强度(离群值的数值大小)会有一个“相变”式的急剧增长。这恰好解释了为什么普通 INT8 量化在这个规模开始失效。
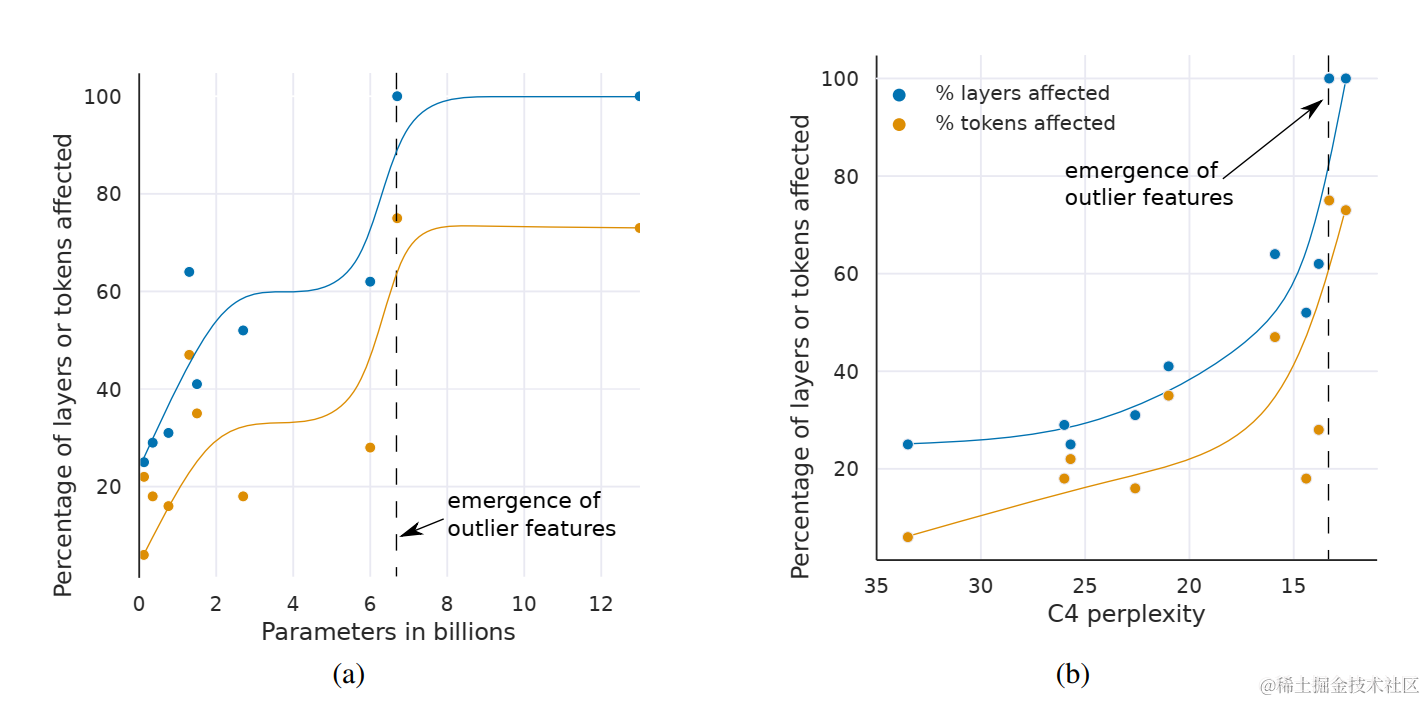
Transformer各层及所有序列维度中受大振幅离群值特征影响的比例,按(a)模型规模或(b)C4困惑度划分。图中曲线分别采用4段(a)和9段(b)线性分段的B样条插值拟合。一旦发生相变,离群值会存在于所有网络层及约75%的序列维度中。(a)显示参数规模存在突变的相变临界点,而(b)表明随着困惑度下降,相变呈现渐进的指数级变化趋势。值得注意的是,(a)中参数的剧烈相变与量化方法性能的突然下降存在强关联。
实现与应用
LLM.int8() 的实现主要依赖于 bitsandbytes 这个库。好消息是,Hugging Face 的 transformers 库已经深度集成了 bitsandbytes。这意味着你可以非常方便地加载一个 8-bit 量化后的大模型,几乎不需要修改代码。
它是一种“零样本量化”(Zero-shot Quantization),意味着你不需要额外的校准数据集。只要模型包含 torch.nn.Linear 层(大部分 Transformer 模型都满足),就可以直接用。
使用示例 (Transformers):
加载 8-bit 模型:
import torch
from transformers import AutoModelForCausalLM
# 假设你有足够的总显存,但单卡可能不够
# device_map='auto' 会自动将模型分片到多张GPU上
# load_in_8bit=True 启用 LLM.int8() 量化
model_8bit = AutoModelForCausalLM.from_pretrained(
'bigscience/bloom-1b7', # 换成你想用的模型
device_map='auto',
load_in_8bit=True,
# 可选:为每张卡设置最大显存限制
# max_memory={i: f'{int(torch.cuda.mem_get_info(i)[0]/1024**3)-2}GB' for i in range(torch.cuda.device_count())}
)
print(f"模型显存占用: {model_8bit.get_memory_footprint() / 1e9:.2f} GB")
bitsandbytes 后来还发展出了 4-bit 量化方案(如 NF4),同样可以通过 transformers 加载:
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model_id = "meta-llama/Llama-2-7b-hf" # 示例模型
# 配置 4-bit 量化参数
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # 使用 NF4 (NormalFloat 4-bit) 类型
bnb_4bit_use_double_quant=True, # 启用二次量化,进一步节省显存
bnb_4bit_compute_dtype=torch.bfloat16 # 计算时使用的中间数据类型
)
model_4bit = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=nf4_config,
device_map='auto' # 同样可以自动分片
)
print(f"4-bit 模型显存占用: {model_4bit.get_memory_footprint() / 1e9:.2f} GB")
总的来说,LLM.int8() (及其后续的 4-bit 方案) 是一个易用性极高、能大幅降低显存占用的量化方案,尤其适合资源有限但希望运行大模型的场景。它的主要缺点是可能牺牲推理速度。
GPTQ: 基于优化的精准权重量化
与 LLM.int8() 不同,GPTQ 是一种仅权重量化(Weight-only Quantization)方法,通常采用 W4A16(权重4bit,激活FP16)的方案。它不处理激活值的离群问题,而是专注于如何更精确地量化权重,以最小化量化带来的误差。
背景:从剪枝到量化的优化思想
GPTQ 的思想并非凭空产生,它借鉴了经典的模型剪枝方法。
- OBD (Optimal Brain Damage): 早期剪枝方法,假设移除一个权重对模型误差的影响可以通过该权重对应的 Hessian 矩阵(二阶导数)的对角线元素来近似。它假设权重间影响独立。
- OBS (Optimal Brain Surgeon): 改进了 OBD,认为权重间并非独立。它不仅计算移除哪个权重影响最小,还计算如何调整剩余权重以补偿移除权重带来的误差。这需要计算 Hessian 矩阵的逆。
- OBQ (Optimal Brain Quantization): 将 OBS 的思想从“剪枝”(将权重置为0)推广到“量化”(将权重近似到某个离散值)。量化可以看作是找到一个量化后的权重
W_hat,使得||WX - W_hat X||^2尽可能小,同时考虑了更新其他权重来补偿误差。
OBQ 的效果不错,但计算 Hessian 矩阵的逆非常耗时,对于动辄百亿、千亿参数的大模型来说,计算成本高到无法接受。
GPTQ (Generative Pre-trained Transformer Quantization) 的目标就是:在继承 OBQ 精确量化思想的同时,大幅提高量化速度,使其能够应用于超大规模模型。
技术原理:逐层优化与权重更新
GPTQ 采用逐层量化 (Layer-wise Quantization) 的策略,即一次只量化模型的一层。对于每一层,它的目标是找到量化后的权重 W ^ \hat{W} W^,使得该层的输出与原始输出之间的均方误差最小:
arg min ∥ W X − round ( W ) X ∥ 2 \arg\min \left\| WX - \text{round}(W)X \right\|^2 argmin∥WX−round(W)X∥2
这里 X X X 是该层的输入激活(通常来自一个小的校准数据集), round ( ⋅ ) \text{round}(\cdot) round(⋅) 代表量化操作。
GPTQ 的核心是逐列(或逐块)量化权重矩阵 W W W,并实时更新还未量化的权重,以补偿已量化权重引入的误差。这个过程有点像 OBS,但 GPTQ 做了几项关键优化:
-
按顺序量化,而非贪心选择: OBS/OBQ 需要计算 Hessian 逆来决定量化哪个权重影响最小(贪心策略)。GPTQ 发现,直接按顺序(例如,从第一列到最后一列)量化权重,性能损失很小。这大大简化了计算,避免了复杂的排序和索引。
-
分组量化 (Group-wise Quantization): 为了进一步平衡精度和效率,GPTQ 不是逐个元素量化,而是将权重矩阵的列(或行,取决于实现)分成小组(例如,每组 128 列,称为 groupsize \text{groupsize} groupsize)。组内的权重共享相同的量化参数(缩放因子和零点)。这降低了存储量化参数的开销。
-
权重更新: 这是关键步骤。当一个权重(或一个 group 的权重) w q w_q wq 被量化后,它会引入一个误差 error = w q − round ( w q ) \text{error} = w_q - \text{round}(w_q) error=wq−round(wq)。GPTQ 利用预计算的 Hessian 逆的块信息 ( H − 1 H^{-1} H−1),将这个误差分配到还未被量化的其余权重 W remaining W_{\text{remaining}} Wremaining 上:
Δ W remaining = error ⋅ ( H − 1 ) row q ( H − 1 ) q , q \Delta W_{\text{remaining}} = \text{error} \cdot \frac{(H^{-1})_{\text{row}_q}}{(H^{-1})_{q,q}} ΔWremaining=error⋅(H−1)q,q(H−1)rowqW remaining = W remaining + Δ W remaining W_{\text{remaining}} = W_{\text{remaining}} + \Delta W_{\text{remaining}} Wremaining=Wremaining+ΔWremaining
公式简化说明:这里的 H H H 是激活 X X X 计算出的 Hessian 矩阵 ( X T X ) (X^T X) (XTX)。更新公式来源于 OBS 的推导,目的是在量化 w q w_q wq 后,调整其他权重使总误差增量最小化。
-
高效实现技巧:
- Lazy Batch-Updates: OBQ 每次量化一个权重就更新所有剩余权重,这在 GPU 上访存效率低。GPTQ 采用延迟批量更新,一次量化一个小批量(如 128 列)的权重,然后一次性更新所有剩余权重。这能更好地利用 GPU 的并行计算能力和内存带宽。
- Cholesky 分解: 直接计算和存储 Hessian 矩阵的逆 H − 1 H^{-1} H−1 可能数值不稳定且耗内存。GPTQ 使用 Cholesky 分解等数值稳定的方法来处理 Hessian 矩阵,并在需要时高效地计算更新所需的项,提高了稳定性和效率。
下图展示了 GPTQ 的量化过程(块内递归应用):
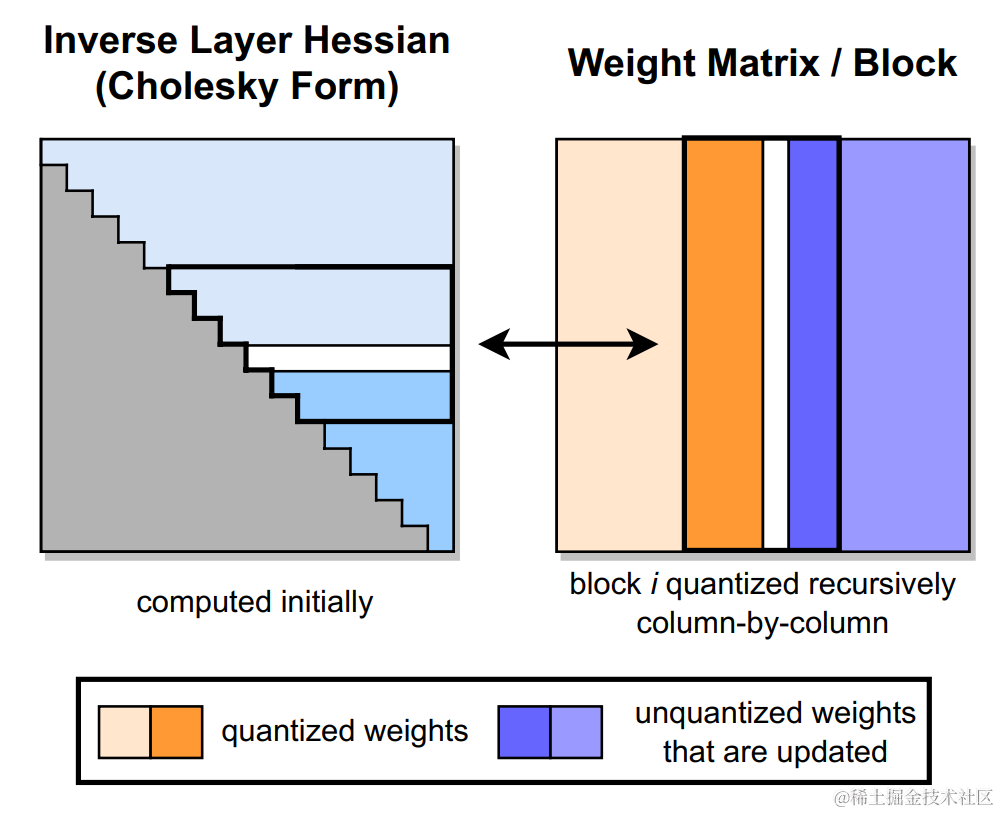
我们主要关注 Lazy Batch-Updates 是如何缓解 bandwidth 的压力的。
问题:虽然 GPTQ 降低了时间复杂度,但这个算法的计算/通信比太低,通信带宽成为了瓶颈。
例如在量化某个参数矩阵的情况下,每次量化一个参数,其他所有未量化的参数都要按公式全都要更新一遍:
如果每行的量化并行计算,那么每次更新过程就需要 read + write 一次参数矩阵。如果参数矩阵的维度为k * k,那么量化这个参数矩阵就需要读写 k 次参数,总共的 IO 量为k^3个元素。当 k 比较大时(>= 4096),需要读写的元素就非常多了,运行时间大都被 IO 占据。
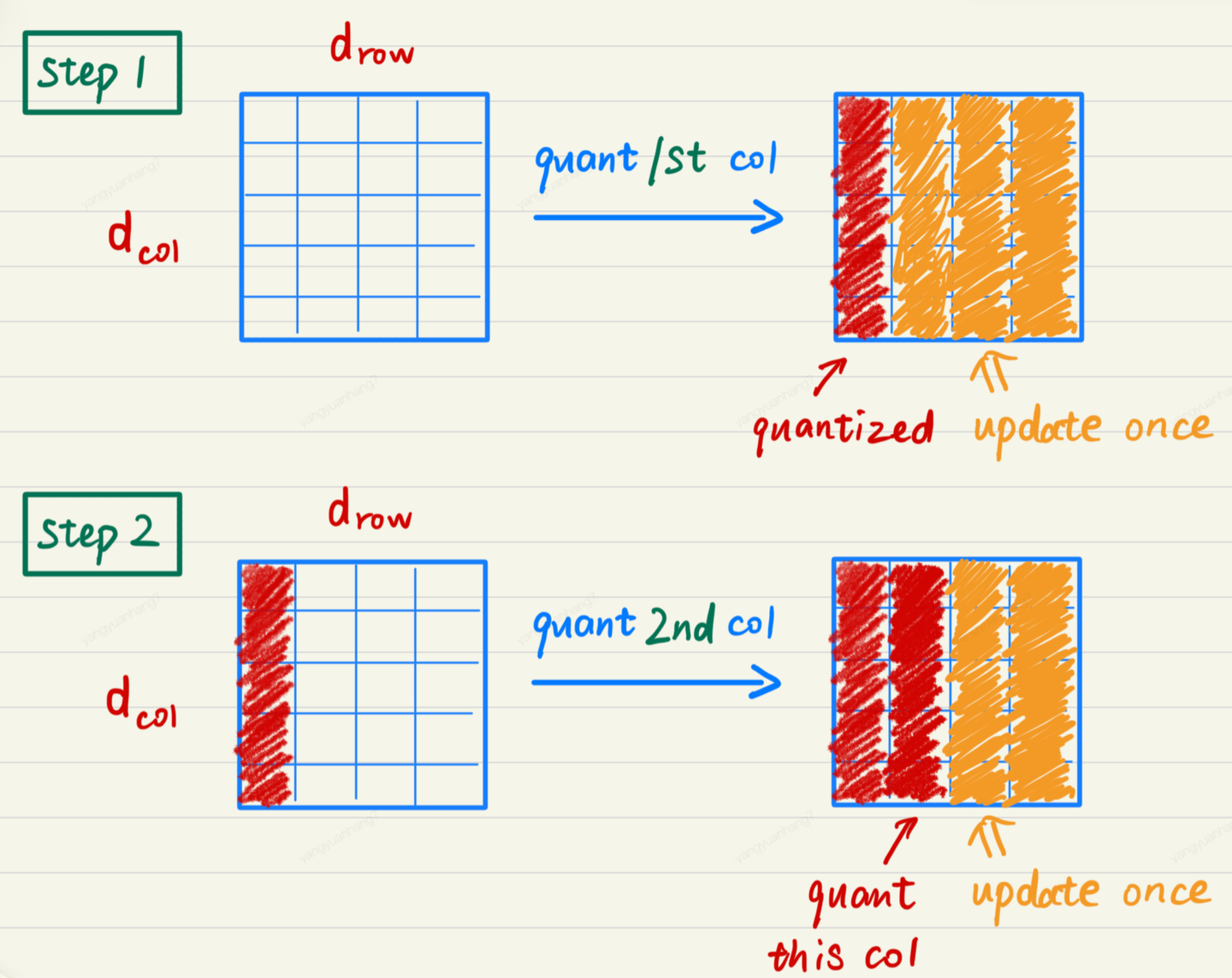
**思路:**由于参数量化是一列一列按次序进行的,第 i 列的参数的量化结果受到前 i-1 列量化的影响,但第 i 列的量化结果不影响前面列的量化。因此我们不需要每次量化前面的列,就更新一遍第 i 列的参数,而是可以先记录第 i 列的更新量,在量化到第 i 列时,再一次性更新参数,这样就可以减少 IO 的次数。
**具体实现:**将参数矩阵按每 128 列划分为一个个 group,量化某一列时,group 内的参数立即更新,而 group 后面的列只记录更新量,延迟更新。当一个 group 的参数全部量化完成,再统一对后面的所有参数做一次更新。这就是 Lazy Batch-Updates。
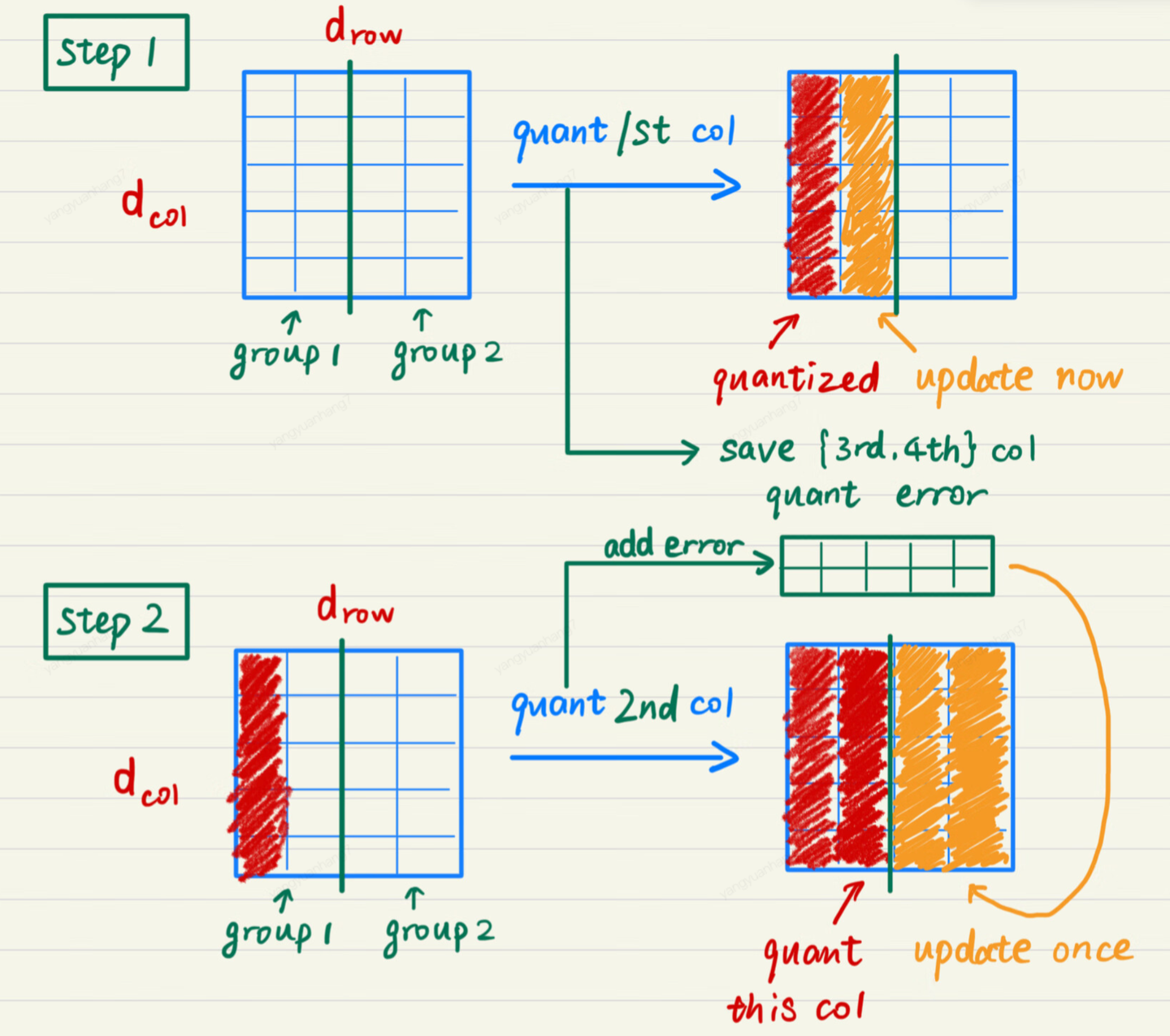
Lazy Batch-Updates 不减少实际的计算量,但它能有效解决吞吐的瓶颈问题。
GPTQ 伪代码概览:

伪代码展示了按列顺序处理 (循环 i 从 1 到 d_col)、计算量化误差 delta、以及更新剩余权重 W[:, i:d_col] 的过程,并融入了 Cholesky 和批量更新的思想。
优缺点与实现
优点:
- 高精度: 由于其基于优化的量化策略和权重更新机制,GPTQ 通常能在极低比特(如 4-bit)下保持相当高的模型精度,性能损失很小。
- 显著的内存节省: W4A16 方案能将模型权重大小压缩近 4 倍。
- 潜在的推理加速: 虽然激活仍然是 FP16,但权重的位宽降低,可以减少访存时间,尤其是在内存带宽受限的场景下,可能带来推理速度的提升(但这不绝对,需要特定的 Kernel 优化支持)。
缺点:
- 需要校准数据: GPTQ 需要一小部分代表性的数据(校准集)来计算激活
X和 Hessian 矩阵H,用于指导量化过程。 - 量化过程耗时: 虽然比 OBQ 快得多(数小时 vs 数天),但相比 LLM.int8() 的零样本加载还是要慢不少,需要在部署前进行离线量化。
实现与应用:
目前社区有多个流行的 GPTQ 实现库:
- AutoGPTQ: 一个用户友好、支持多种 Transformer 架构的库,并且已经集成到 Hugging Face 的
transformers和optimum库中,使用非常方便。 - GPTQ-for-LLaMa, Exllama, llama.cpp: 这些库通常针对 LLaMA 及其变种模型做了深度优化,可能在特定模型上性能更好,但通用性不如 AutoGPTQ。
使用示例 (Transformers + AutoGPTQ):
首先需要安装 optimum 和 auto-gptq。
# 安装依赖: pip install optimum auto-gptq
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m" # 使用一个小型模型作为示例
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 准备校准数据集 (这里使用 "c4" 的一个子集作为示例)
# 你也可以提供自己的数据集,格式通常是文本列表
calibration_dataset = "c4" # 或者 ["text 1", "text 2", ...]
# 配置 GPTQ 参数
# bits=4: 量化到 4 bit
# dataset=calibration_dataset: 指定校准数据集
# tokenizer=tokenizer: 需要 tokenizer 来处理数据集
quantization_config = GPTQConfig(
bits=4,
dataset=calibration_dataset,
tokenizer=tokenizer,
group_size=128, # 推荐的组大小
desc_act=False, # 是否基于激活排序量化顺序(通常设为False,使用顺序量化)
)
# 执行量化过程 (这步会比较耗时,取决于模型大小和校准数据量)
# 如果模型已经有预量化好的版本,可以直接加载
# 这里演示的是在线量化的过程
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map='auto' # 可以自动分配到 GPU
)
print(f"GPTQ 量化后模型显存占用: {quantized_model.get_memory_footprint() / 1e9:.2f} GB")
# 可以保存量化后的模型供后续直接加载
# quantized_model.save_pretrained("./opt-125m-gptq-4bit")
# tokenizer.save_pretrained("./opt-125m-gptq-4bit")
# 后续加载: model = AutoModelForCausalLM.from_pretrained("./opt-125m-gptq-4bit", device_map="auto")
GPTQ 因其出色的精度保持能力,在社区中被广泛用于生成低比特(尤其是 4-bit)的模型权重,供大家下载使用。
总结与对比
| 特性 | LLM.int8() | GPTQ |
|---|---|---|
| 量化对象 | 权重 & 激活 (混合精度) | 仅权重 (常用 W4A16) |
| 核心思想 | 分离处理离群特征,其余部分 INT8 | 逐层优化,最小化量化误差,更新剩余权重 |
| 精度保持 | 较好,尤其对>6B模型 | 非常好,通常优于 LLM.int8() (在同等比特下比较) |
| 推理速度 | 可能比 FP16 慢 | 可能比 FP16 快 (内存带宽受限时) |
| 显存节省 | 显著 (INT8) | 非常显著 (INT4) |
| 是否需校准数据 | 否 (零样本) | 是 |
| 量化耗时 | 加载时动态执行,相对较快 | 离线执行,相对耗时 |
| 易用性 (HF) | 非常高 (load_in_8bit=True) |
较高 (通过 GPTQConfig 和 AutoGPTQ) |
| 主要库 | bitsandbytes |
AutoGPTQ (及其他变种) |
简单来说:
- 如果你想快速、方便地让大模型在你的设备上跑起来,并且能接受一定的速度牺牲,LLM.int8() (或
bitsandbytes的 4-bit) 是个不错的选择。 - 如果你追求极致的压缩率和尽可能高的精度,并且愿意花时间进行离线量化和准备校准数据,那么 GPTQ 是更优的选择,它还有可能带来推理加速。
目前,这两种技术都在 Hugging Face transformers 生态中得到了很好的支持,大家可以根据自己的需求和场景灵活选用。
结语
大模型量化是一个充满活力且快速发展的领域,LLM.int8() 和 GPTQ 只是其中的两个优秀代表。理解它们的原理,不仅能帮助我们更好地利用这些工具,也能为我们理解更前沿的量化技术(如 SmoothQuant, AWQ, QuIP 等)打下基础。
希望这篇有点长的技术博客能帮助你理清思路。掌握这些知识,无论是在学术研究、工程实践还是技术面试中,相信都会让你更加从容自信!
码字不易,如果你觉得这篇文章对你有帮助,请不要吝啬你的点赞、收藏和关注哦!我们下次再见!
参考资料:
https://zhuanlan.zhihu.com/p/680212402

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)