基于深度学习YOLOv8\YOLOv5的儿童手腕骨折金属检测骨科诊断系统
数据集收集是构建任何机器学习或深度学习模型的第一步,对于该目标检测系统,骨折等骨损伤的X光片数据集来源GRAZPEDWRI-DX数据集,对收集到的图像进行筛选,去除质量低下、不清晰或者与目标类别无关的图像。并对收集到的原始图像数据中不完整的图片进行标注。数据标注是将图像中的每个目标用边界框标出,并为其分配相应的类别标签,这一步骤对于模型学习识别和定位目标至关重要,本设计选择LabelImg工具进行
文末获取完整源码+数据集+配置和修改文档+开题报告+配套论文+远程操作等

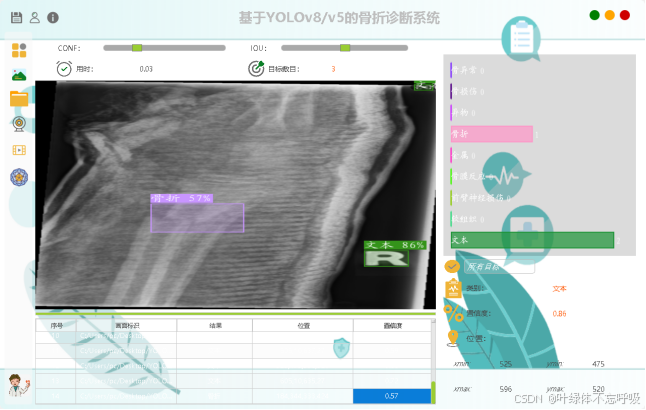
在医疗诊断中,骨折等骨科疾病的准确诊断对患者的及时治疗和康复极为关键。然而,传统的X光片诊断方法存在挑战,如需要医生具备丰富的经验和专业知识来识别骨折位置和类型,且过程耗时,对急诊或资源紧张地区不利。此外,X光图像的二维特性可能导致某些骨折等骨科疾病不易被发现,尤其是重叠区域或深处的损伤。
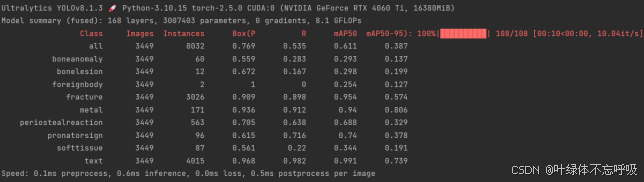
为解决这些问题,本设计采用了深度学习算法YOLO进行骨折等骨损伤的自动检测,医生可以选择将患者的骨科X光片传入该诊断助手,该诊断系统通过加载训练好的深度学习模型,进行特征的提取和融合,通过检测头、解锚框和极大值抑制推理输出X光片中骨折等骨损伤的信息,这些信息会在可视化界面上显示给用户,包括骨折等骨损伤的位置、坐标、置信度等,用户可以通过该系统快速地实现骨科X光片诊断。本系统在实时性和准确性上表现优异,实验结果显示,YOLOv8模型在保持49FPS实时性的同时,将所有类别的均值平均精确度从YOLOv5的60%提升至61.1%,精确率从72%提升至76.9%;特别是对于骨折和骨科金属支架的识别,YOLOv8的精确率均达到90%以上。YOLOv8在小目标检测,如轻微骨损伤方面,展现了明显优势,不仅提高了检测速度,也增强了诊断效果,有助于提升骨科诊断效率,为患者提供更迅速、更可靠的医疗服务。
关键词:目标检测,深度学习,YOLOv5,YOLOv8,骨科诊断
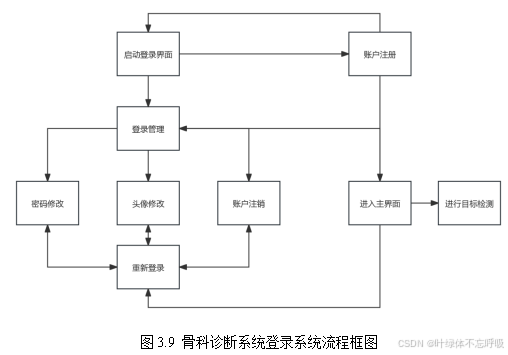
设计开发流程
该骨科诊断系统的开发主要由深度学习模型训练和可视化操作界面开发两部分组成,其开发流程如图3.1所示。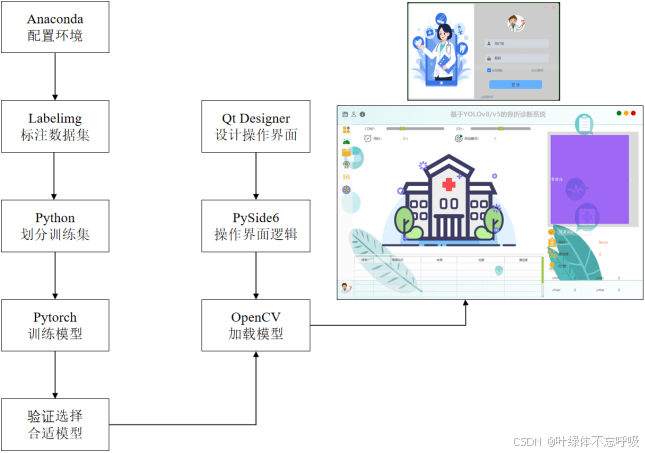
首先,选择在Anaconda平台中构建本次骨科诊断模型和可视化操作界面开发所需的Python环境,命名为YOLO_ENV。本次所选择的是2023年4月发行的Anaconda版本,通过Conda命令创建基于Python3.10的YOLO_ENV环境,该环境中所包含的部分第三方库如表3.1所示。

接着,使用LabelImg工具进行图像标注,其过程涉及以下步骤:打开图像、创建一个新的标注文件、选择预定义类别、在图像上绘制边界框、保存标注结果。这个过程虽然简单,但对于创建高质量的训练数据集至关重要。通过LabelImg绘制矩形框来标记图像中的对象,并为每个对象分配相应的类别标签,可以有效地准备用于训练机器学习模型的数据,从而提高模型的性能和准确性。数据集标注完成后需要借助Python脚本将数据集标签由VOC格式转换为YOLO格式,再将数据集随机划分为训练集、验证集和测试集,有助于模型在训练过程中避免过拟合,本设计划分的比例为8:1:1。
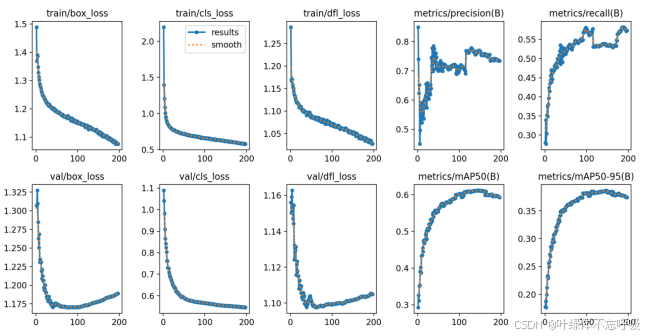
使用Python脚本完成手腕骨折数据集的随机划分后,根据具体任务需求,修改Yaml等配置文件,包括类别名称、路径设置、模型结构等,并设置训练周期为300轮,使用交叉熵损失和GIoU损失的组合,使用预训练模型的权重作为初始权重,对模型进行训练。利用TensorBoard可视化训练过程,帮助理解模型在训练过程中的表现和潜在问题,结合第二章所讲解的评价指标分析训练的模型的好坏,分析骨折等骨损伤数据集的特点和YOLOv8算法的优势,比较用YOLOv5训练的模型和用YOlOv8训练的模型,最终选择使用YOLOv8训练的模型作为该骨科诊断系统的深度学习核心模型。
数据集简介
数据集收集是构建任何机器学习或深度学习模型的第一步,对于该目标检测系统,骨折等骨损伤的X光片数据集来源GRAZPEDWRI-DX数据集,对收集到的图像进行筛选,去除质量低下、不清晰或者与目标类别无关的图像。并对收集到的原始图像数据中不完整的图片进行标注。数据标注是将图像中的每个目标用边界框标出,并为其分配相应的类别标签,这一步骤对于模型学习识别和定位目标至关重要,本设计选择LabelImg工具进行标注,如图3.2所示。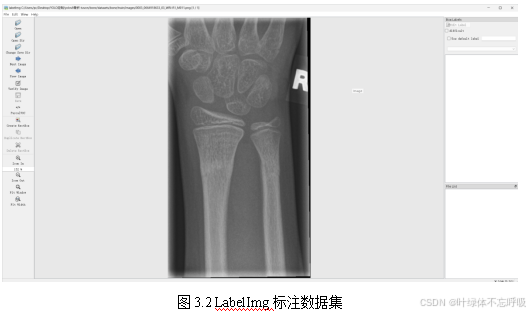
GRAZPEDWRI-DX 数据集包含 2008 年至 2018 年间在格拉茨大学医院儿科外科治疗的 6,091 名患者的带注释的儿科创伤腕部 X 光片,共有 10,643 项研究(20,327 幅图像)可用,覆盖前后和横向投影。该数据集带有 74,459 个图像标签和 67,771 个标记对象。通过LabelImg软件对所有收集的图片进行标注,先标注为XML格式,再通过Python脚本转换为YOLO格式,并将其进行划分。处理完成的数据集一共有16878张图片用于训练,3449张图片用于验证。检测的类别包括boneanomaly(骨异常)、bonelesion(骨损伤)、foreignbody(异物)、fracture(骨折)、metal(金属)、periostealreaction(骨膜反应)、pronatorsign(前臂神经损伤)、softtissue(软组织损伤)和text(文本标签)共9类,其中有216个boneanomaly、33个bonelesion、6个foreignbody、15064个fracture、647个metal、2890个periostealreaction、471个pronatorsign、377个softtissue和19707个text标注目标对象。将处理过的数据集输入YOLO算法进行模型训练,数据集中的目标数量如图3.3左上角所示,其显示了各个检测类别包含的样本数量;目标框的尺寸和数量如图3.3右上角所示,其展示了训练集中边界框的大小分布以及相应数量;目标框中心点相对于整幅图的位置坐标如图3.3左下角所示,其描述了边界框中心点在图像中的位置分布情况;数据集中目标相对于整幅图的高宽比例如图3.3右下角所示,其反映了训练集中目标高宽比例的分布状况。
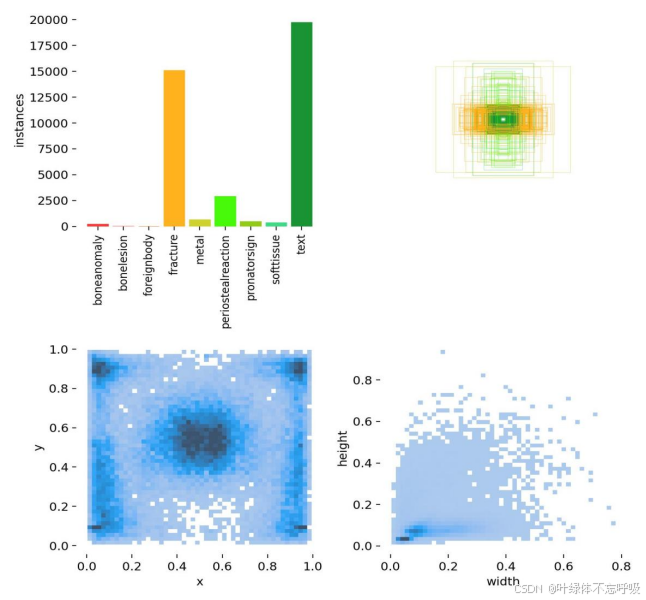
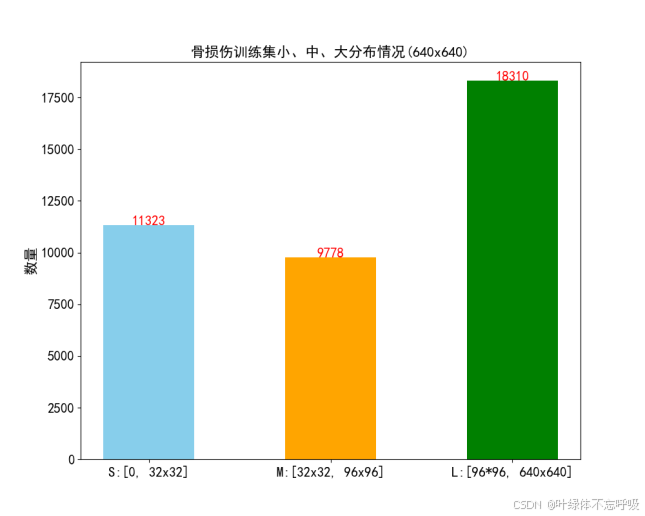
具体而言,数据集中除了fracture、metal、periostealreaction和text目标对象较多,其他的检测实例数量较少,导致类别不均衡问题,可以通过数据增强处理来改善此问题。另外,数据集中存在许多较小的目标,占比约为28.7%,而中型目标占比也达到了24.8%,各尺寸目标大小定义及具体数量如图3.4所示,横坐标为目标尺寸,纵坐标为目标的数量。在这种情况下,可以添加CBAM注意力机制以改进小目标检测效果。总之,在解决目标检测问题时,需要针对数据集中的具体情况进行相应的处理和优化,以提高模型的检测准确率和性能。
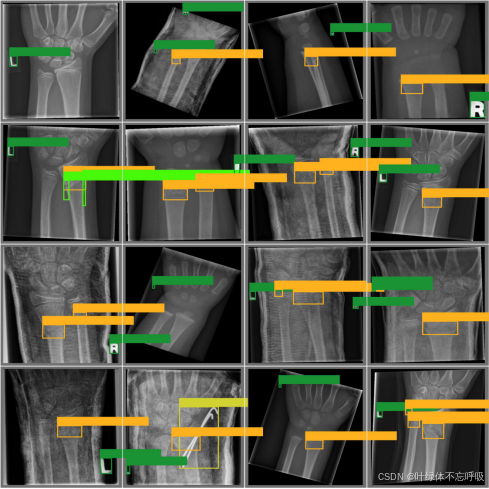
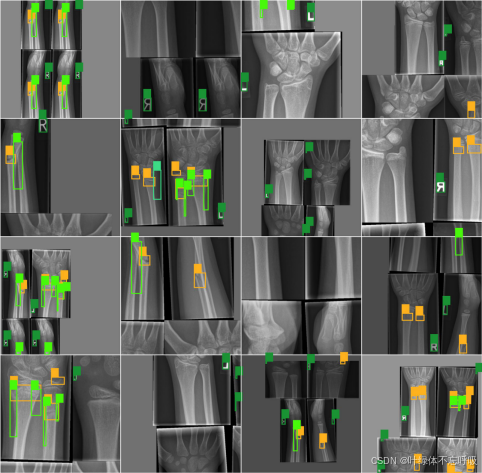
系统效果

模型评价指标
点击下方小卡片,那边对话框发送“资源”两个字
获取完整源码+数据集+源码说明+配置修改文档+配套论文+远程操作跑通程序等

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)