(1w条数据库)基于情感分析的旅游景点评论数据可视化分析 基于大屏Echarts分析,haddop,spark,机器学习(附源码+文档)
本文介绍了基于大数据技术的旅游景点评论数据可视化分析系统。该系统通过Python、Django和Vue框架,结合Hadoop/Spark大数据处理技术,实现了从数据采集、清洗到可视化分析的全流程功能。系统能对景点评论进行情感分析、游客来源统计、时序趋势预测等多维度分析,并以Echarts图表直观展示结果。文章详细阐述了系统架构、技术实现和功能模块,包括数据管理、词云图、评分分析等,并提供了代码示例
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于情感分析的旅游景点评论数据可视化分析 基于大屏Echarts分析,haddop,spark,机器学习(附源码+文档)
1、旅游景点评论数据可视化分析-前言介绍
1.1背景
随着旅游业的蓬勃发展,旅游景点的评价成为了游客选择旅游目的地的重要参考依据。旅游景点评论不仅能反映景点的质量和游客的体验,还能影响景点的口碑和吸引力。近年来,随着大数据和互联网的普及,游客对景点评论的依赖程度不断增加,尤其是在旅游决策过程中,评论的数量、质量及其情感倾向都被认为是关键因素。然而,尽管旅游评论数据日益增多,传统的评论分析方法往往依赖人工处理,缺乏有效的自动化分析和实时反馈机制,导致游客和景点管理者难以快速获取有价值的见解。因此,如何通过大数据分析手段对大量的景点评论进行系统化的处理和分析,成为了旅游行业亟待解决的问题。本课题旨在开发一个基于大数据技术的旅游上榜景点评论数据可视化分析系统,旨在帮助景点管理者更好地理解游客的需求,优化服务体验。
1.2课题功能、技术
本课题提出了一种基于大数据的旅游上榜景点评论数据可视化分析系统,系统通过整合Python语言、Django后端框架、Vue前端框架以及Echarts可视化技术,结合Hadoop、Spark和Hive等大数据技术,实现了对旅游景点评论数据的全方位、多维度分析。系统能够提供总体评分分析、游客类型分析、用户排行分析、关联关系分析、时序趋势分析、游客来源分析和文本内容分析等功能。具体来说,系统首先采集并清洗大量的景点评论数据,接着利用大数据技术进行存储与处理,最后通过前端可视化界面展示分析结果,帮助用户实时掌握评论的趋势和反馈。尤其是在游客来源、评论情感和趋势预测等方面,系统能够提供精确的洞察,从而为景点的运营和决策提供数据支持。
1.3 意义
本课题的研究具有重要的理论价值和实践意义。首先,它为旅游行业的评论分析提供了一种基于大数据的新方法,利用先进的分析工具和可视化技术,能够高效处理海量数据并得出具有指导意义的结论。其次,系统能够帮助景点管理者及时了解游客的评价、需求变化及其情感倾向,从而为景点的市场定位、服务优化和品牌建设提供数据支持。此外,通过对游客类型、来源和评论趋势的分析,系统还能够促进旅游产业的精准营销,为旅游业的可持续发展提供理论依据和实践指导。综上所述,本课题不仅为学术界提供了大数据应用的新视角,也为旅游行业的智能化、数据化转型提供了可行的技术方案。
2、旅游景点评论数据可视化分析-研究内容
(1)数据采集与清洗:本系统通过爬虫技术或API接口采集旅游平台上的景点评论数据,并对收集的数据进行清洗。数据清洗包括去除重复数据、处理缺失值、标准化评论文本、统一格式等操作,以确保数据的质量和准确性,为后续分析奠定基础。
(2)大数据处理与分析:系统采用Hadoop、Spark和Hive等大数据技术,进行大规模评论数据的存储与分布式处理。通过聚合、筛选、分类等方法,从数据中提取出有价值的模式和趋势,帮助景点管理者识别游客的需求变化、情感倾向及其行为模式。
(3)数据可视化:通过Echarts图表和Vue.js前端技术,将处理后的数据以图形化方式展现。系统实现了总体评分、游客来源、时序趋势、用户排行等分析结果的可视化,使得数据易于理解,并通过交互设计提升用户体验,方便景点管理者实时监控数据。
(4)Web框架搭建:本系统使用Django框架进行后端开发,构建RESTful API实现数据交互。前端采用Vue.js框架,结合Echarts进行数据可视化展示。整体系统架构清晰,支持用户通过浏览器访问分析结果,并通过交互界面获得实时反馈和决策支持。
(5)系统测试:在系统开发完成后,进行全面的功能测试、性能测试和用户体验测试。通过模拟不同场景,验证系统的稳定性、响应速度及数据分析的准确性。同时,收集用户反馈,不断优化系统性能,确保其在实际应用中的可靠性和高效性。
3、旅游景点评论数据可视化分析 -开发技术与环境
- 开发语言:Python
- 大数据:Hadoop+Spark+Hive
- 数据处理:pandas
- 后端框架:Django
- 前端:Vue
- 数据库:MySQL
- 算法:K-means算法
- 开发工具:Pycharm
4、旅游景点评论数据可视化分析 -功能介绍
1、数据管理:信息列表展示。
2、词云图:词云图。
3、可视化分析:总体评分分析、游客类型分析、用户排行分析、关联关系分析、时序趋势分析、游客来源分析、文本内容分析
4、系统管理:登录注册、个人信息修改。
5、旅游景点评论数据可视化分析 -论文参考
6、旅游景点评论数据可视化分析 -成果展示
6.1演示视频
28基于大数据的旅游上榜景点评论数据可视化分析系统
6.2演示图片
☀️首页☀️
☀️登录☀️
☀️可视化分析☀️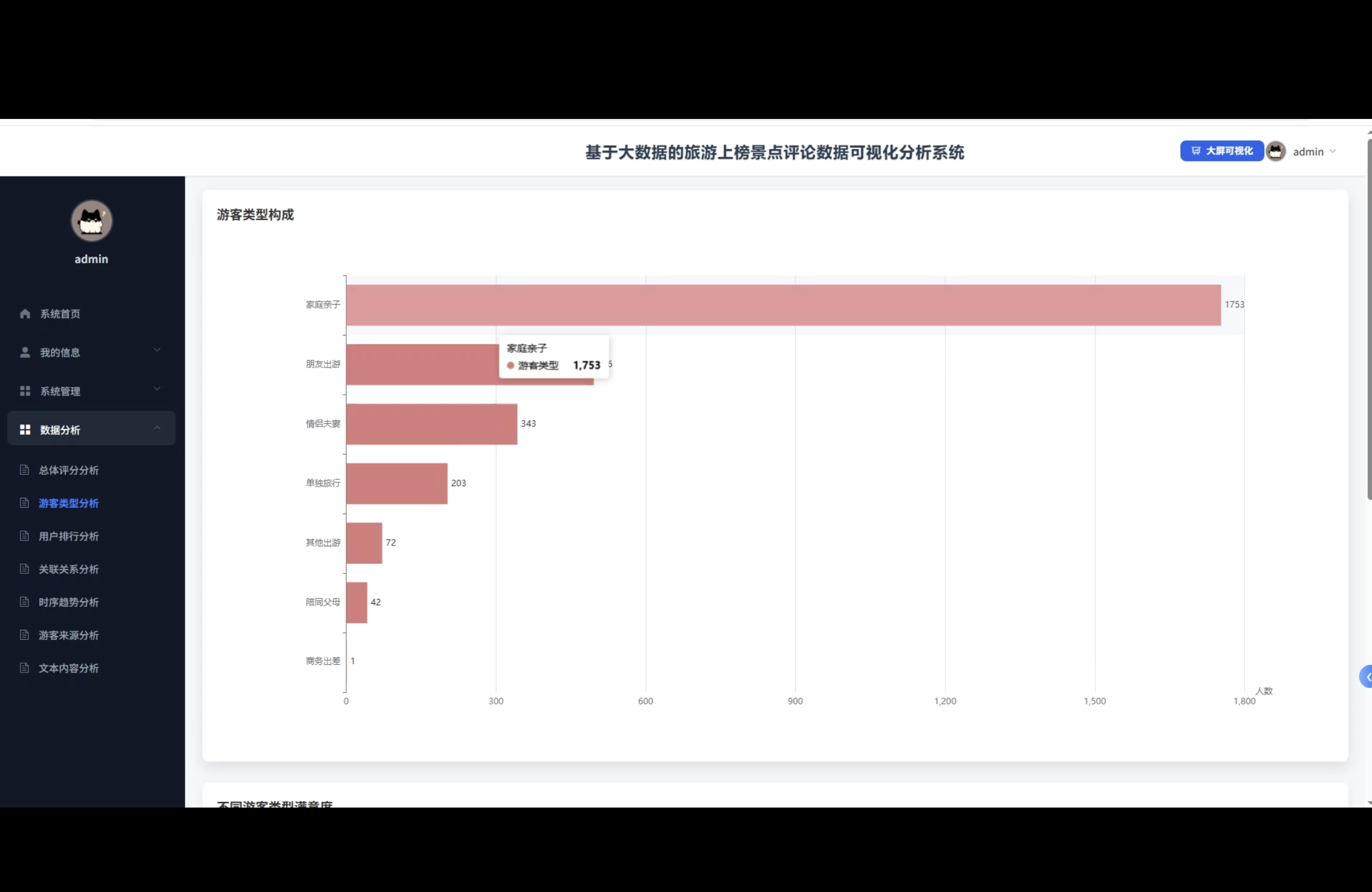

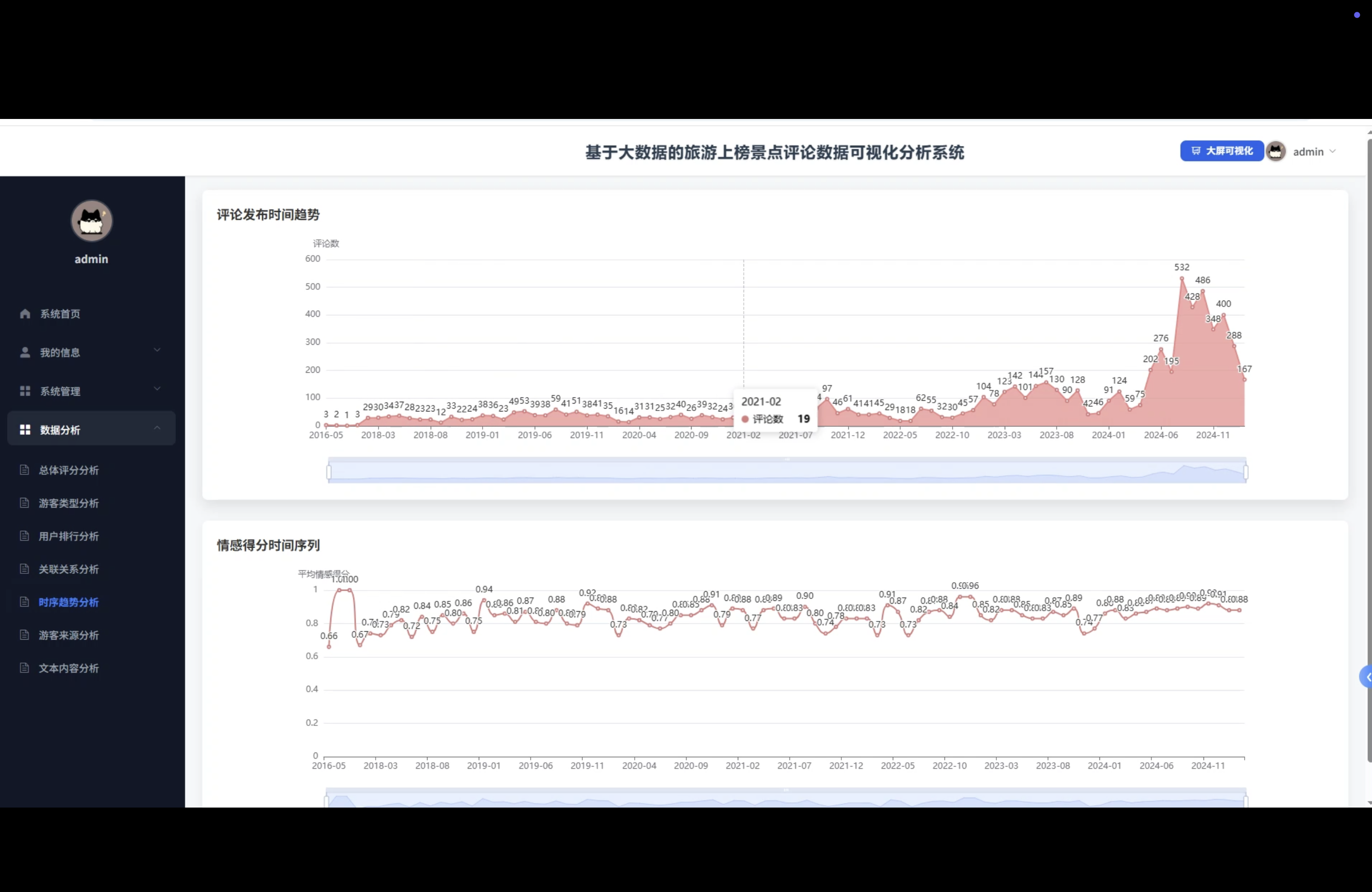
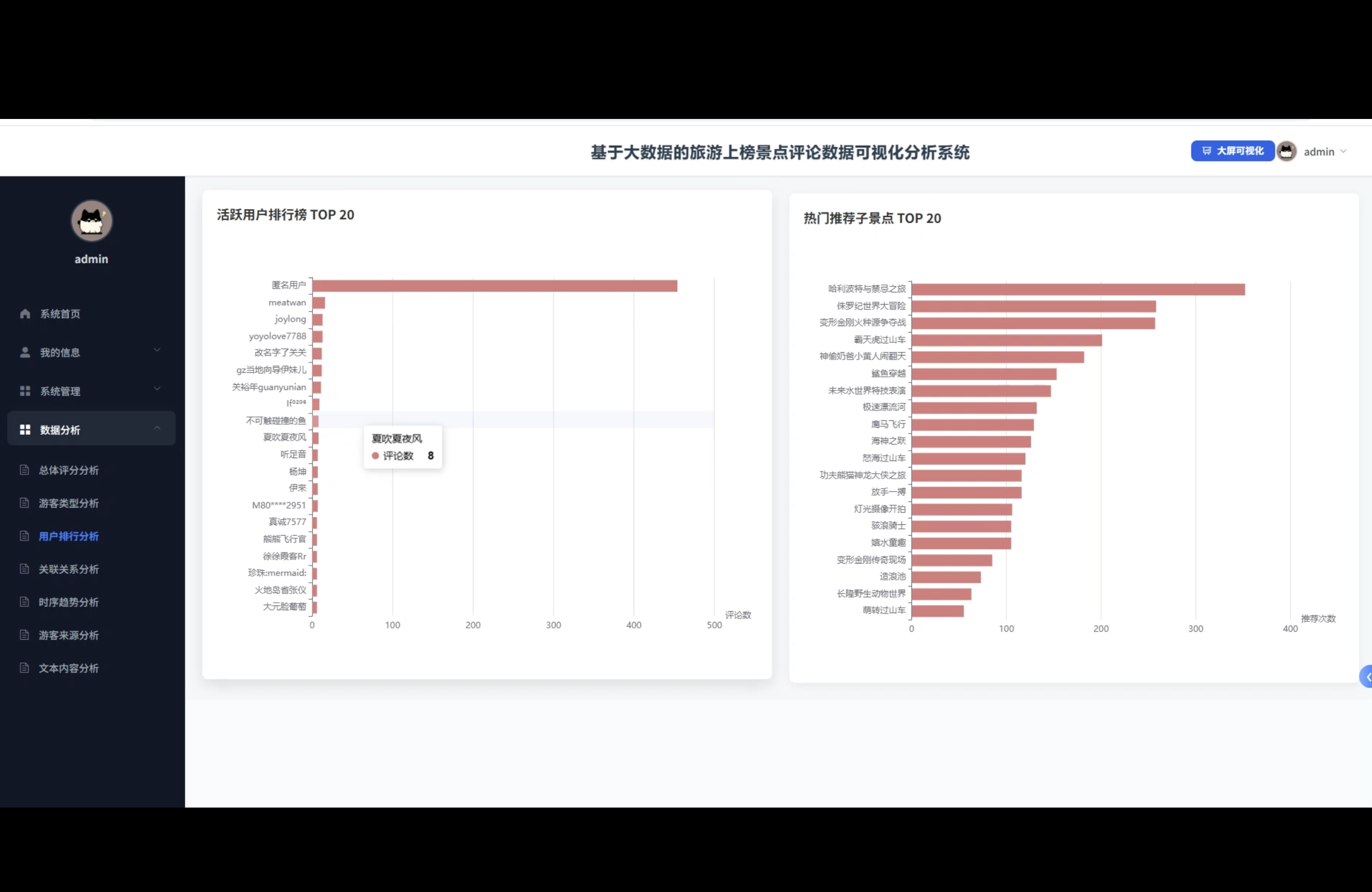
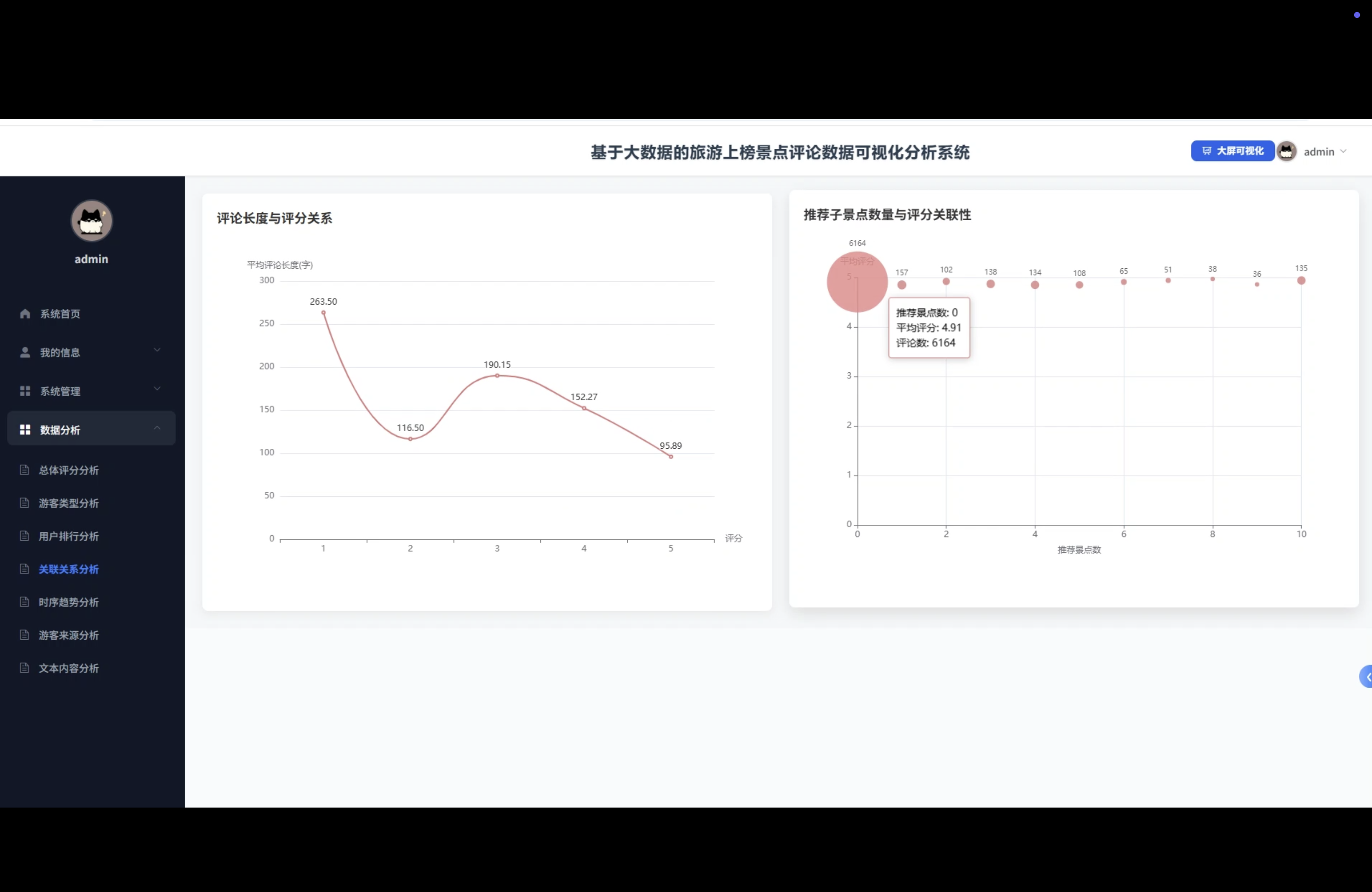
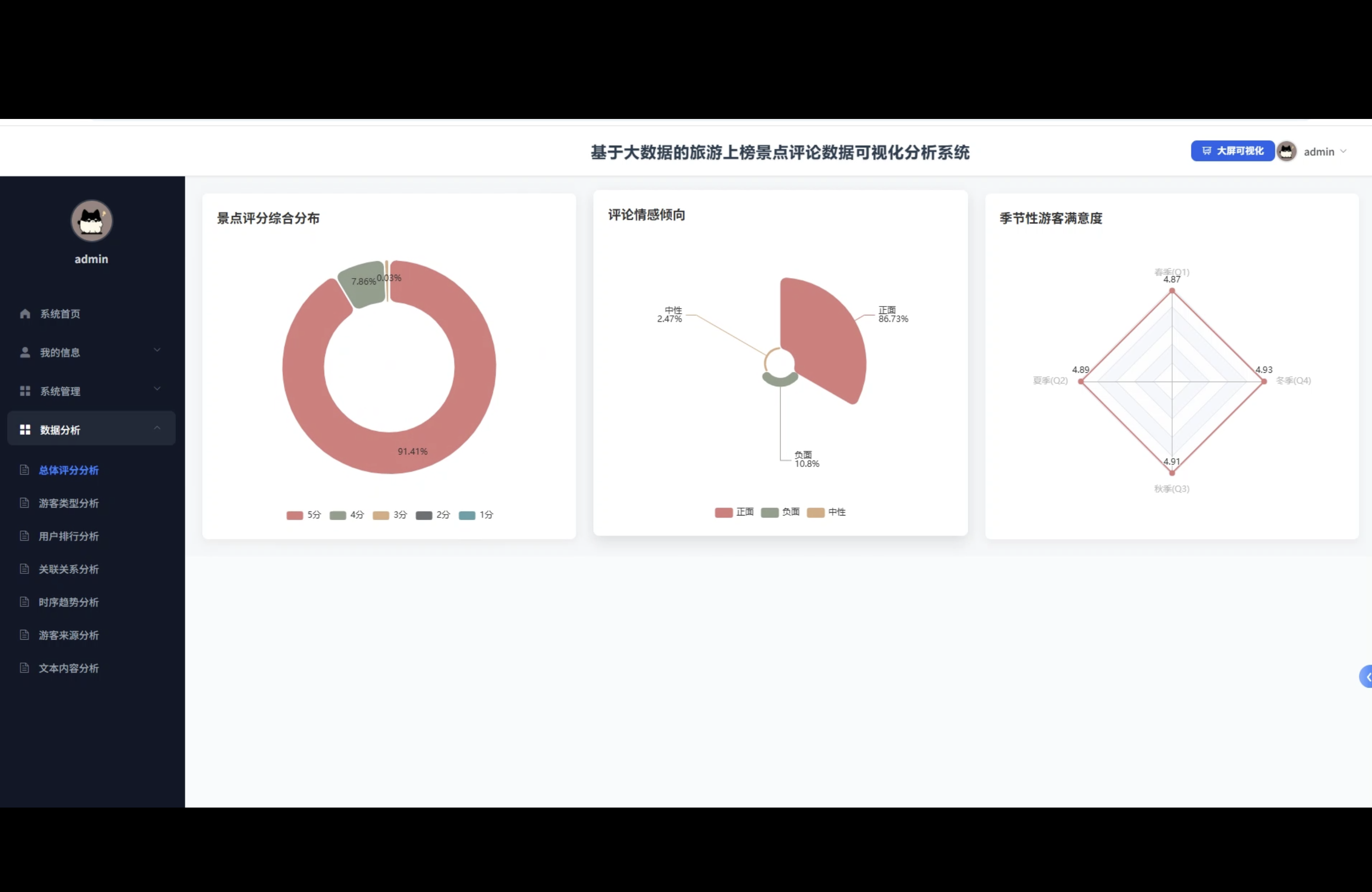

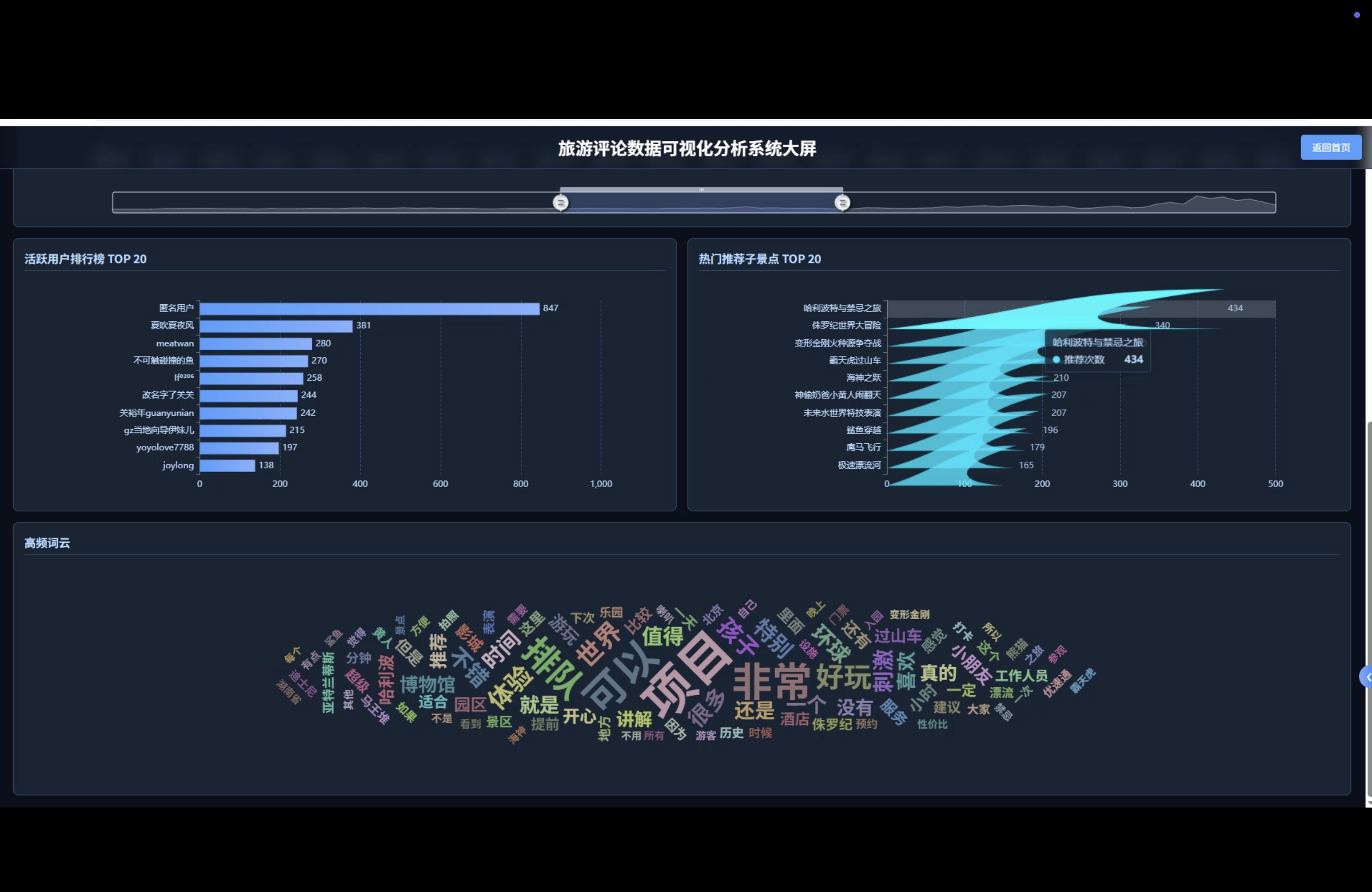
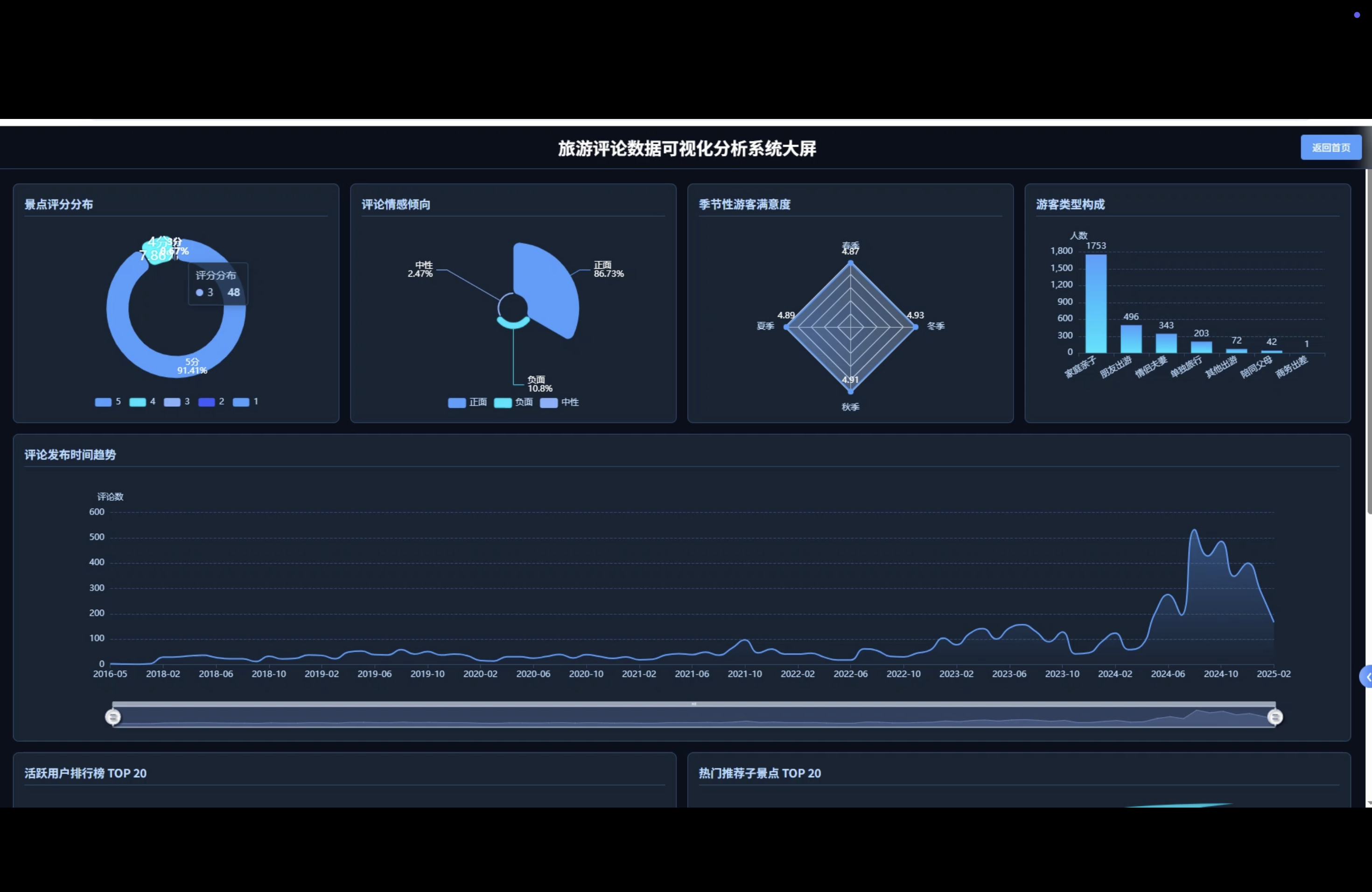
☀️大屏☀️
☀️XX数据管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv('tourist_reviews.csv')
# 1. 去除重复数据
df.drop_duplicates(subset=['review_id'], keep='first', inplace=True)
# 2. 填充缺失值(使用均值填充评分,最常见填充法)
df['rating'].fillna(df['rating'].mean(), inplace=True)
# 3. 标准化评论文本(去除特殊字符和空格)
df['review_text'] = df['review_text'].str.replace('[^a-zA-Z\s]', '', regex=True)
df['review_text'] = df['review_text'].str.strip()
# 4. 处理缺失的游客信息(如性别字段)
df['gender'].fillna('Unknown', inplace=True)
# 5. 将评分标准化到1-5分范围内
df['rating'] = df['rating'].apply(lambda x: min(max(x, 1), 5))
# 6. 删除包含空评论的行
df = df[df['review_text'].str.len() > 0]
# 7. 保存清洗后的数据
df.to_csv('cleaned_reviews.csv', index=False)
2.大数据处理【代码如下( 示例):】
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, year, month
# 初始化Spark会话
spark = SparkSession.builder.appName("TourismReviewAnalysis").getOrCreate()
# 读取评论数据(假设数据存储在HDFS或Hive中)
df = spark.read.csv('hdfs://path_to_reviews.csv', header=True, inferSchema=True)
# 1. 数据去重
df = df.dropDuplicates(subset=['review_id'])
# 2. 缺失值处理(以评分为例,填充为平均值)
avg_rating = df.select(avg(col('rating'))).collect()[0][0]
df = df.na.fill({'rating': avg_rating})
# 3. 过滤无效评论(评分为0的评论无意义)
df = df.filter(col('rating') > 0)
# 4. 提取评论年份和月份,并按年份和月份分组,计算每个月的平均评分和评论数
df = df.withColumn('year', year(col('review_date')))
df = df.withColumn('month', month(col('review_date')))
monthly_analysis = df.groupBy('year', 'month').agg(
avg('rating').alias('avg_rating'),
count('review_id').alias('review_count')
)
# 5. 按景点ID聚合,获取每个景点的评分信息
rating_by_attraction = df.groupBy('attraction_id').agg(
avg('rating').alias('avg_rating'),
count('review_id').alias('review_count')
)
# 6. 保存结果到Hive
monthly_analysis.write.format('hive').mode('overwrite').saveAsTable('tourism_reviews_monthly')
rating_by_attraction.write.format('hive').mode('overwrite').saveAsTable('tourism_reviews_by_attraction')
# 停止Spark会话
spark.stop()
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 29
29 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)