动手学Agent:工具使用(1)构建数据分析ChatBI MCP Server,大模型入门到精通,收藏这篇就足够了!
今天我们直接动手开发一个用于数据分析的MCP Server,为接下来的数据洞察Agent做准备。
我们暂时先跳过MCP(Model Context Protocol)原理的介绍,这类文章网上已经有很多讲得不错的文章了,今天我们直接动手开发一个用于数据分析的MCP Server,为接下来的数据洞察Agent做准备。
概述
首先介绍一下我们要实现的ChatBI部分,BI是Business Intelligence的简称,是借助数据仓库、数据挖掘等技术,来生成报表、统计图等,用于做商业决策的,ChatBI是大模型火了之后,借助大模型强大的代码能力来自动合成代码进行数据分析的一项技术。
ChatBI又大致分为通过生成Python代码来做分析和通过生成SQL代码来做分析两种,生成Python代码来做数据分析的这一脉,基本上是ChatGPT带火的,属于比较轻量级的数据分析,大家常用的大模型产品,ChatGPT、元宝、豆包、Kimi等,都提供上传Excel然后直接统计分析的功能,就属于这一脉;生成SQL代码则相对“正规”一些,毕竟严肃的数据分析是要建立在清洗之后的数据基础上的,而这些数据一般在企业的数据中台存储,这就意味着背后通常是以数据仓库做承载的。
本期我们先介绍使用大模型生成Python代码的ChatBI这一脉,这一脉也有比较有名库——PandasAI,还是YC投资的项目,不过为了便于大家熟悉原理,我们不借助这个库,直接使用LLM、Pandas这些库来完成数据分析。
总体的处理流程如下图所示:
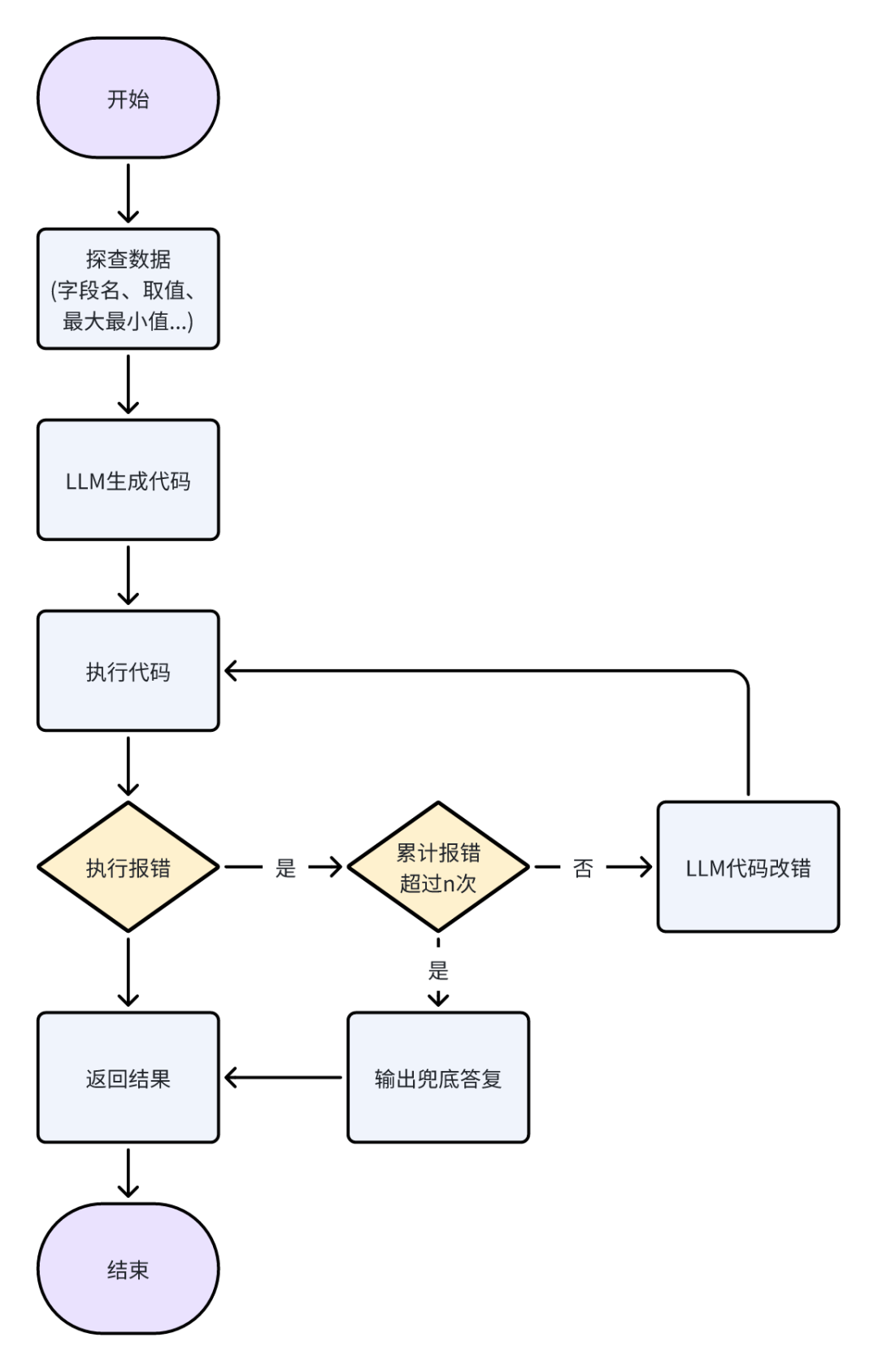
核心代码
代码已开源,地址在:https://github.com/Steven-Luo/chatbi-mcp-server
ChatBI
ChatBI的部分代码相对来说比较多,核心其实是通过Prompt,让大模型生成符合要求的代码,当然需要提供必要的数据信息,这也就是上面流程图中“数据探查”部分做的事情。
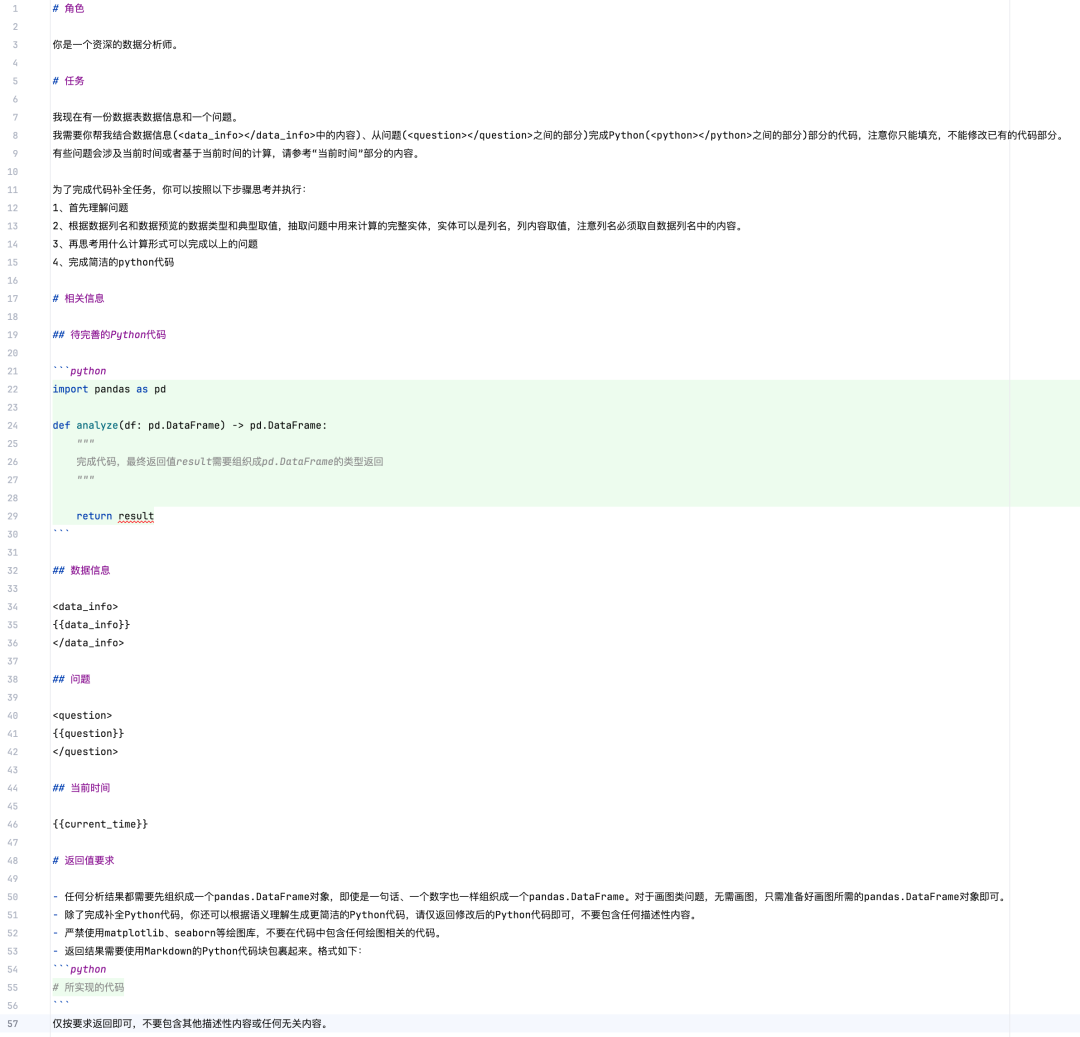
MCP Server
MCP Server的部分,则相对来说比较简单。我们主要实现两个工具:
- get_preview_data:预览数据,返回数据探查结果,以便大模型对数据有基本的认识
- analyze_data:分析数据,根据问题,数据地址,生成结果表格
由于ChatBI生成代码时需要使用LLM,此处添加了Header校验机制,供需要对MCP Server做认证鉴权的小伙伴们参考,先添加如下的函数,对token进行校验:
from fastmcp import FastMCP, Contextdef get_bearer_token(ctx): request = ctx.get_http_request() headers = request.headers # Check if 'Authorization' header is present authorization_header = headers.get('Authorization') if authorization_header: # Split the header into 'Bearer <token>' parts = authorization_header.split() if len(parts) == 2 and parts[0] == 'Bearer' and parts[1] == ACCESS_TOKEN: return parts[1] else: raise ValueError("Invalid Authorization header format") else: raise ValueError("Authorization header missing")
然后在需要进行认证的工具参数中,添加一个context参数,如下所示:
@mcp.tool(name='get_preview_data', description='数据描述信息')defget_preview_data( path_or_url, context: Context) -> str: token = get_bearer_token(ctx)# 其他逻辑
另外,很多文章的样例代码,在客户端获取到工具列表后,拿不到工具的参数类型和描述,为了让大模型在调用工具时能更精准地传参,建议使用Annotated和Field对字段类型和描述进行声明:
from pydantic import Fieldfrom typing importList, Dict, Annotated# 导入其他类@mcp.tool(name='get_preview_data', description='数据描述信息')defget_preview_data( path_or_url: Annotated[str, Field(description="数据文件路径或URL,仅支持Excel和CSV")], context: Context) -> str:""" 以AI易读的格式获取数据信息 Args: path_or_url: 数据文件路径或URL,仅支持Excel和CSV Returns: 以Markdown形式组织的预览结果 """ logger.info(f'filepath: {path_or_url}') token = get_bearer_token(context) logger.info(f"Client token: {token}") data_accessor = get_data_accessor(path_or_url)return"当前数据信息如下:\n" + data_accessor.description
使用
使用的部分,主要借助Cherry Studio这款客户端,总体是非常好用的,但基本上每个版本都多少有些bug,我使用的版本是v1.5.4,下方示例中使用的Qwen3-32B、GLM 4.5模型均为支持工具调用的API服务,并且工具调用方式为“函数”,如果大家运行结果与文章不一致,可以按此设置进行排查。
启动MCP Server
使用代码仓库中的部署指南,启动MCP Server后,记下服务地址。
注意:仓库中默认使用Streamable-HTTP作为传输协议,大家可以按照自己需要修改
pandas_mcp_server.py文件中的最下方,有备注。
添加MCP Server
使用任意支持MCP Server的客户端,比如Cherry Studio,配置如下:
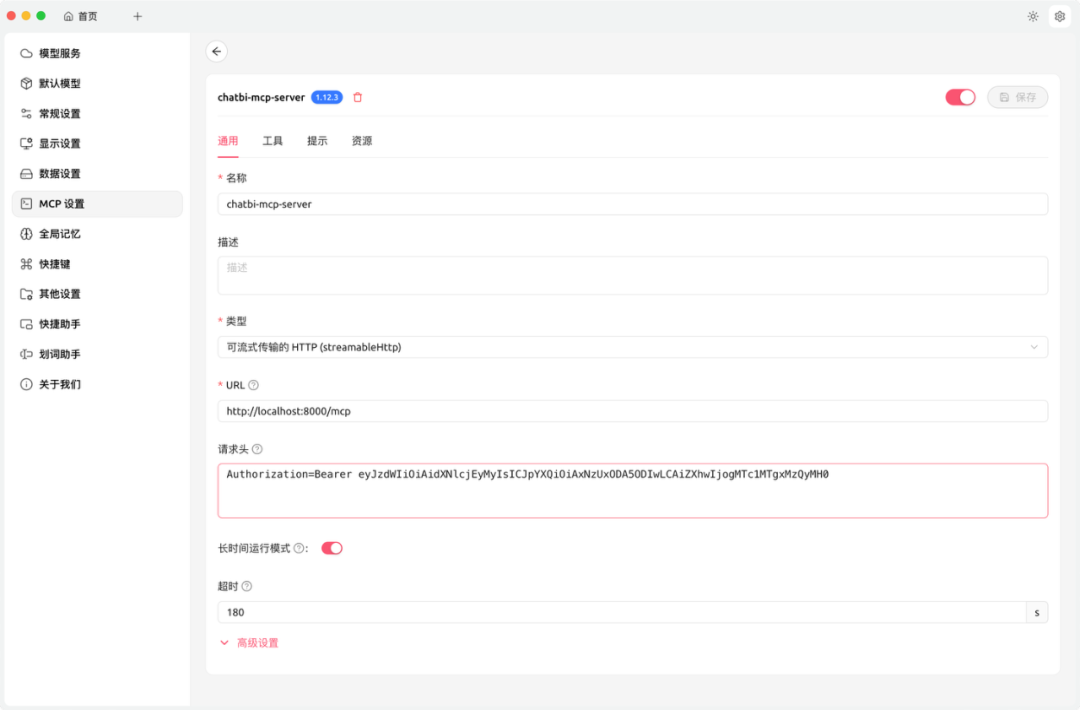
其中验证信息,在config.yaml中,可以自行修改。默认值为eyJzdWIiOiAidXNlcjEyMyIsICJpYXQiOiAxNzUxODA5ODIwLCAiZXhwIjogMTc1MTgxMzQyMH0。
注意:超时时间设置长一点,因为涉及LLM生成代码、如果出错还需要改错
添加完成后,点击“保存”,然后点击右上方的开启选项,切换到“工具”标签页:
如果能正常列出工具,说明配置正确。
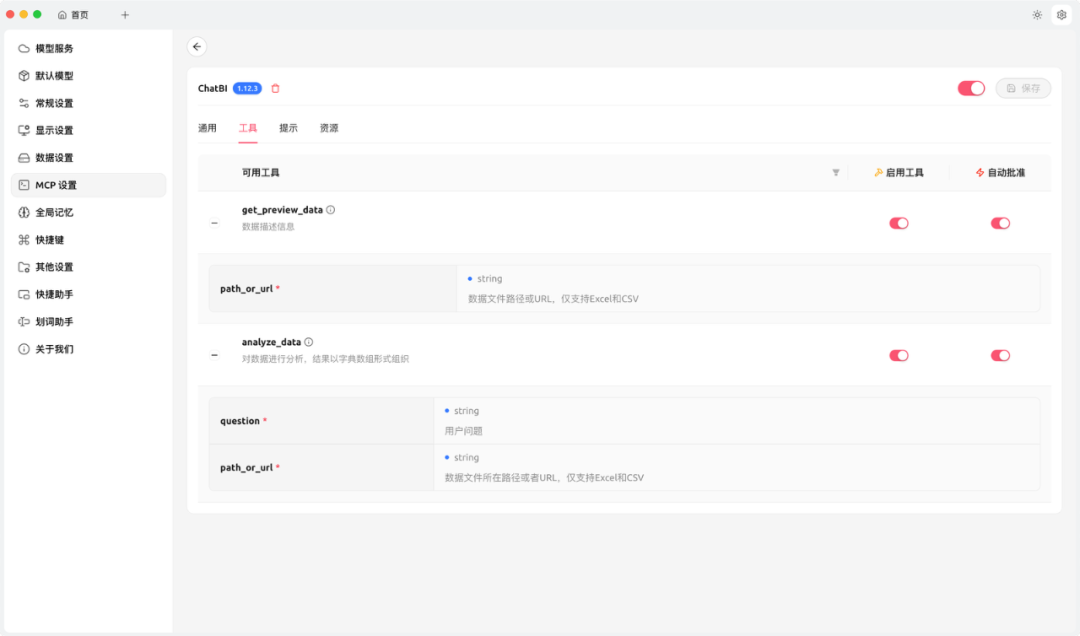
常规统计
使用时,记得开启这个MCP Server:
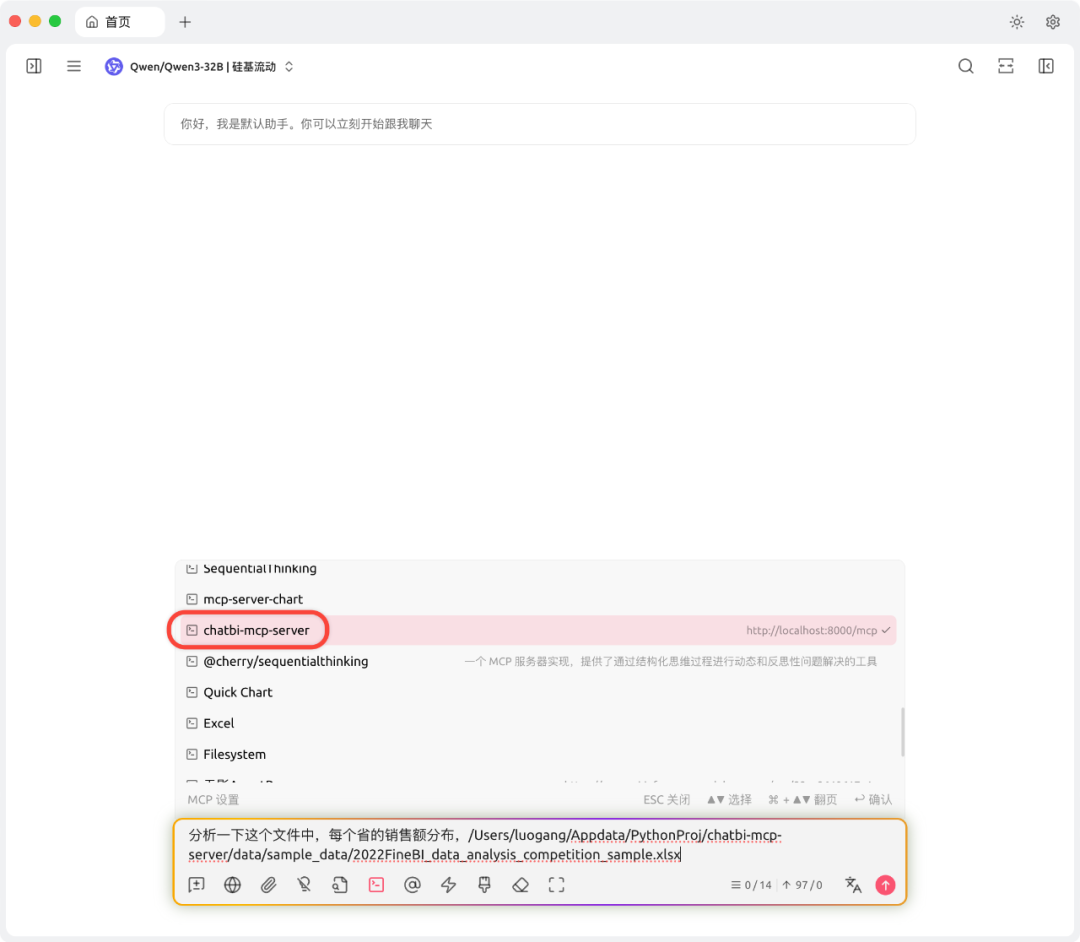
简单统计:
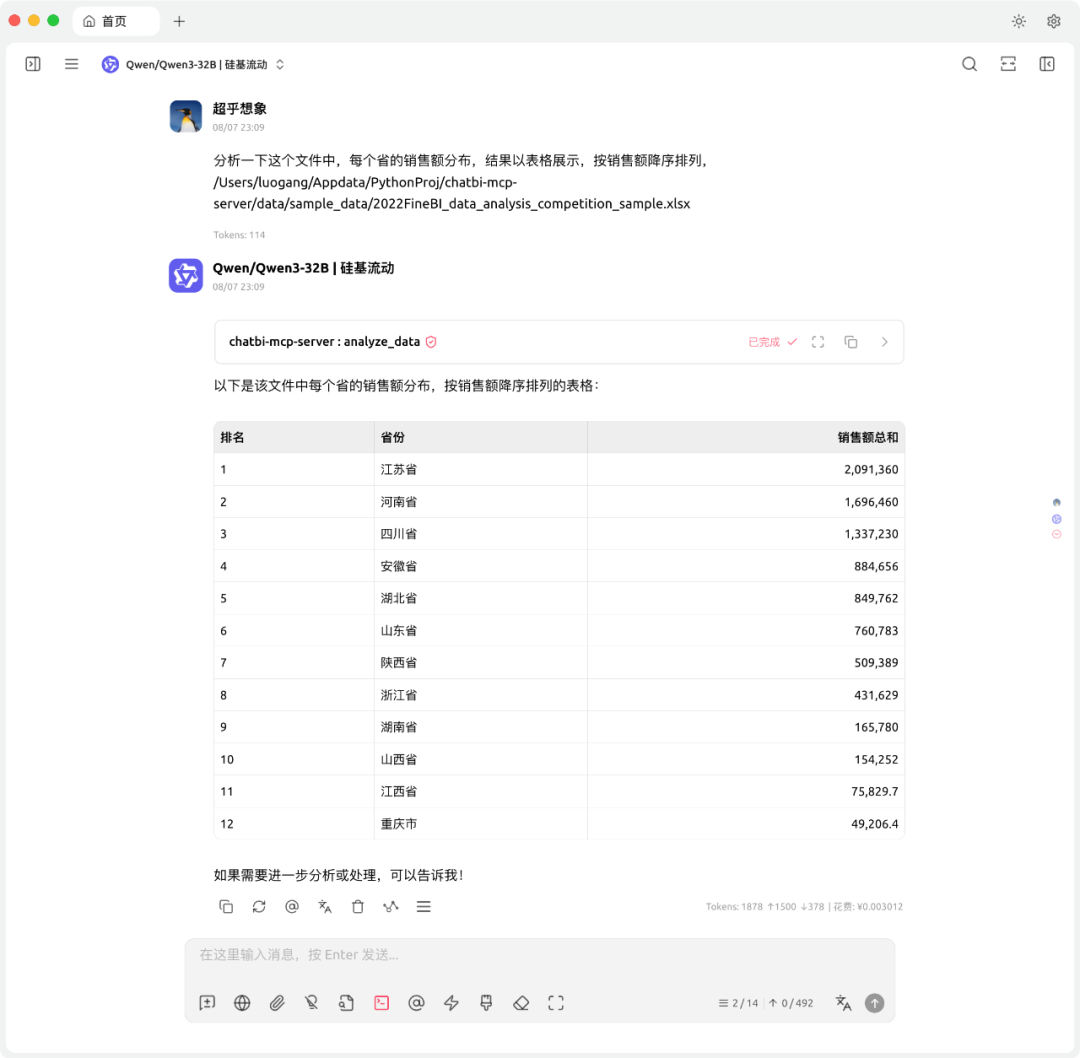
结合可视化库
结合mcp-server-chart这个MCP Server,可以对分析结果方便地进行可视化:
数据洞察Agent
上面介绍的方式,虽然可以分析,但适合对数据本身已经非常了解的小伙伴,但很多时候做数据分析,其实难在无从下手,或者要做系统地分析,即使很熟悉数据分析的情况下,也需要几个小时,接着这种方式,完全可以让大模型自己根据数据的特点,自己拆解分析较多,自己分析,给我们一个初步的认识,以便后续更深入的分析。
这部分如何实现我们后面的文章会介绍。
生成数据分析计划
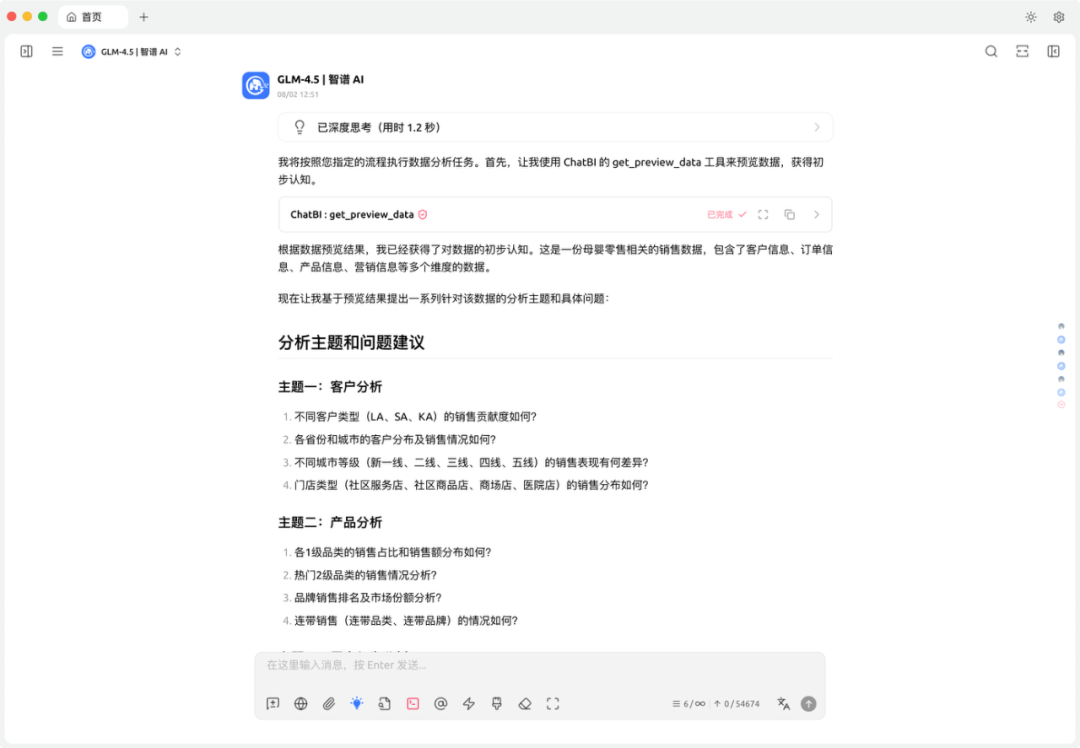
开始分析
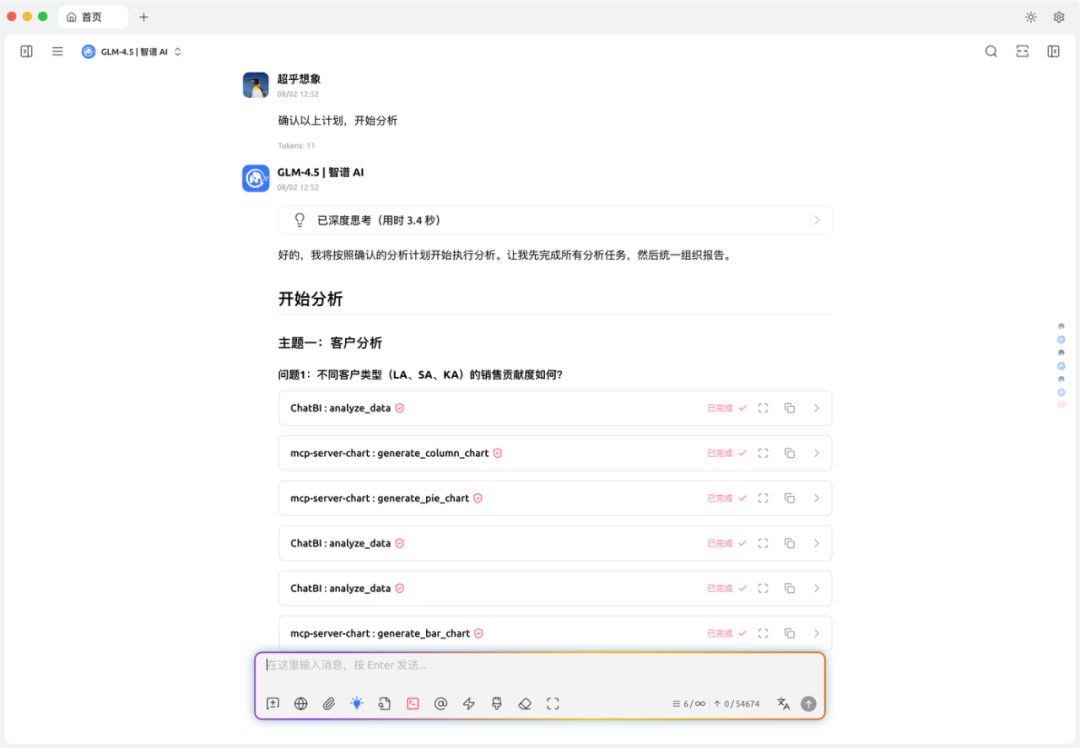
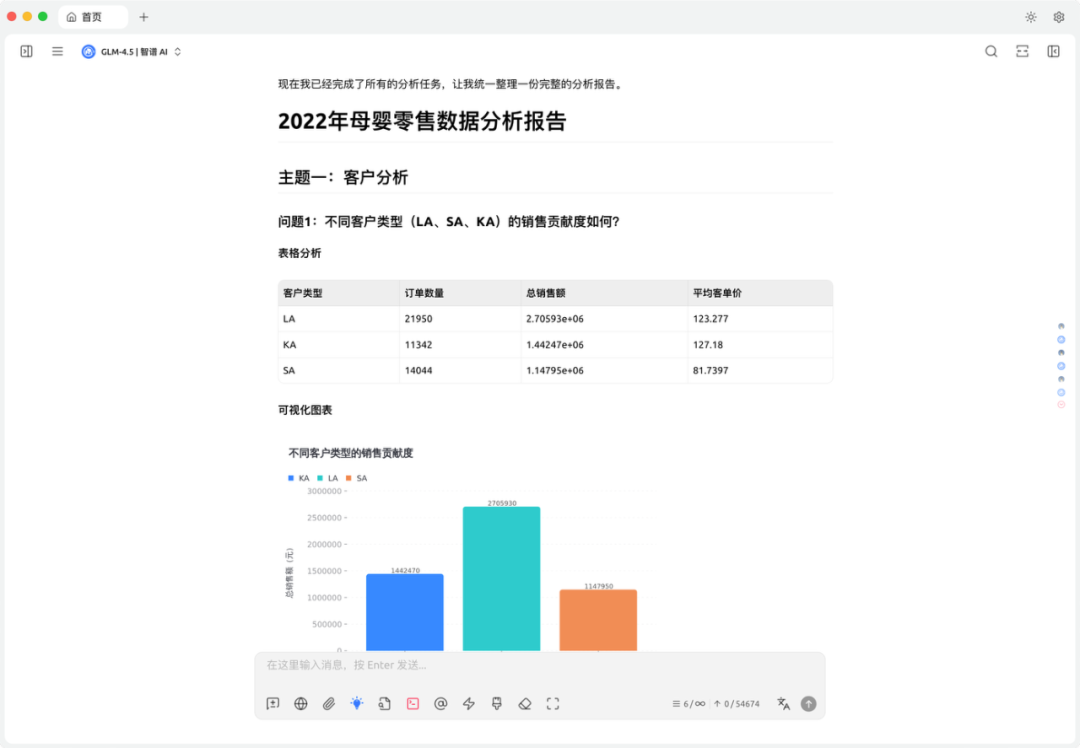
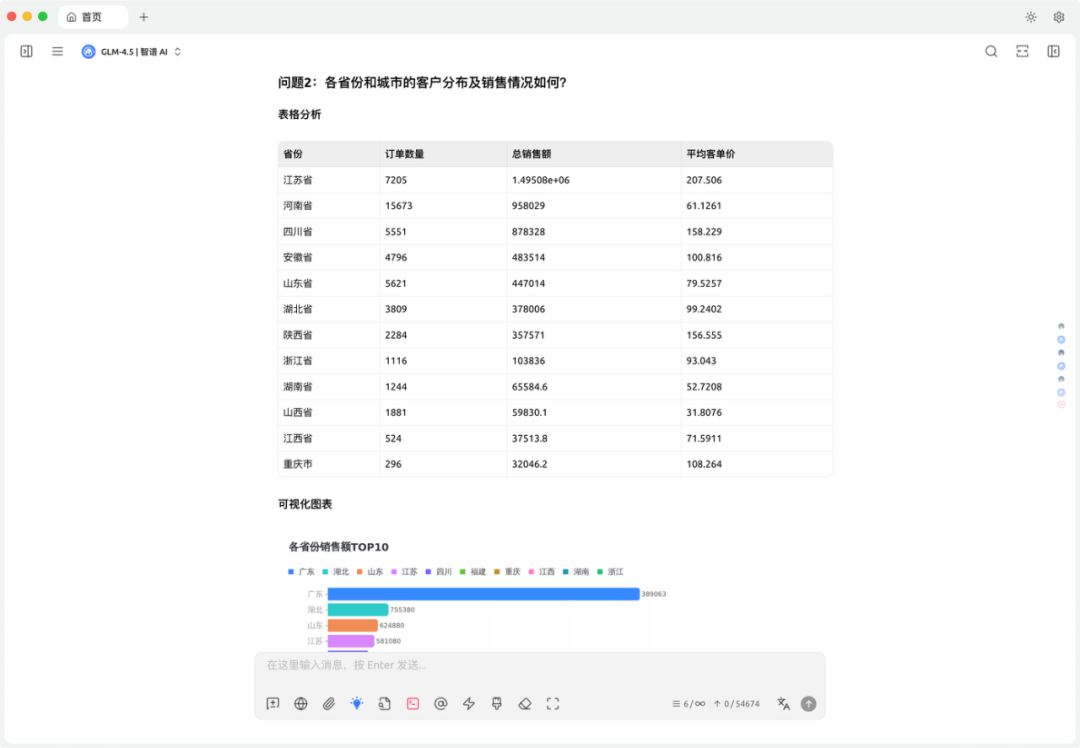
结果报告
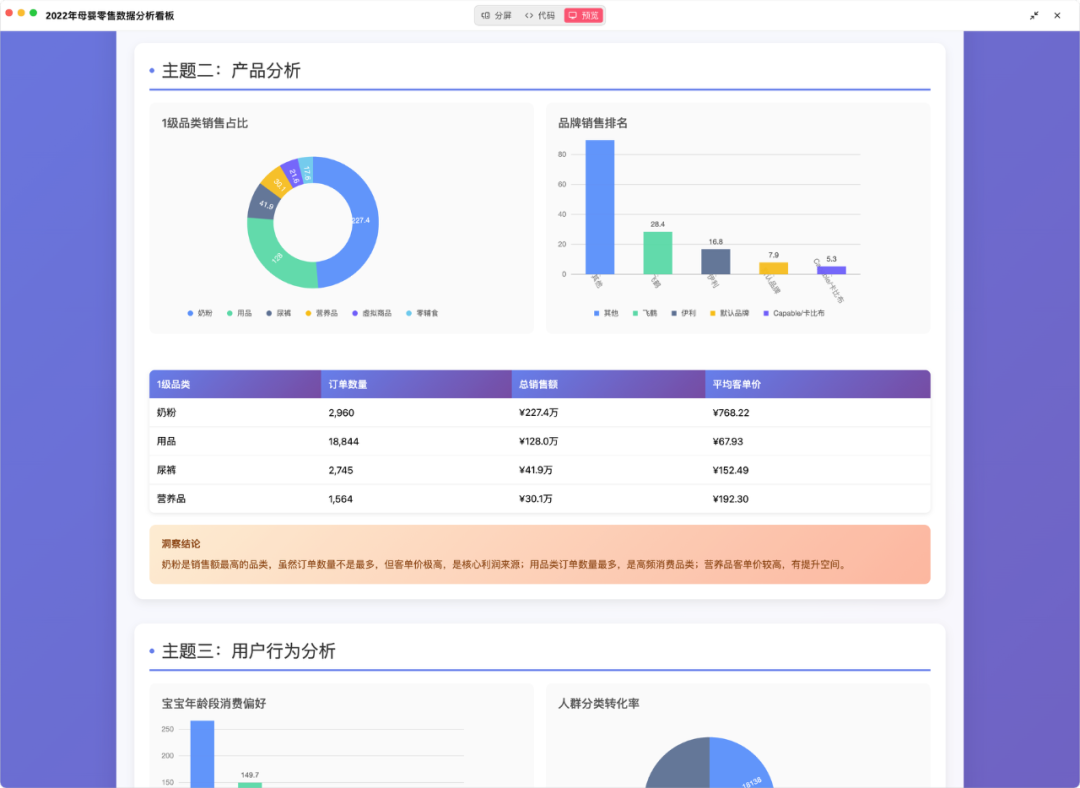
生成的数据看板
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献207条内容
已为社区贡献207条内容

所有评论(0)