基于粒子群算法优化BP神经网络实现多输出预测
基于粒子群算法优化BP神经网络算法多输出预测多输入多输出预测代码含详细注释,不负责数据存入Excel,替换方便,在数据预测领域,多输入多输出的预测任务经常遇到。BP神经网络是一种强大的预测模型,但它容易陷入局部最优解。粒子群算法(PSO)作为一种智能优化算法,可以有效解决这个问题。今天就来聊聊基于粒子群算法优化BP神经网络的多输出预测,并且数据存放在Excel中,方便替换。
基于粒子群算法优化BP神经网络算法多输出预测 多输入多输出预测 代码含详细注释,不负责 数据存入Excel,替换方便,
在数据预测领域,多输入多输出的预测任务经常遇到。BP神经网络是一种强大的预测模型,但它容易陷入局部最优解。粒子群算法(PSO)作为一种智能优化算法,可以有效解决这个问题。今天就来聊聊基于粒子群算法优化BP神经网络的多输出预测,并且数据存放在Excel中,方便替换。
一、BP神经网络基础
BP神经网络即误差反向传播神经网络,通过将误差从输出层反向传播至输入层,调整各层神经元之间的连接权重,以最小化预测值与真实值之间的误差。以下是一个简单的BP神经网络Python代码框架(假设使用numpy库):
import numpy as np
# 定义sigmoid激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# BP神经网络类
class BPNeuralNetwork:
def __init__(self, input_size, hidden_size, output_size):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# 随机初始化权重
self.W1 = np.random.rand(self.input_size, self.hidden_size)
self.b1 = np.zeros((1, self.hidden_size))
self.W2 = np.random.rand(self.hidden_size, self.output_size)
self.b2 = np.zeros((1, self.output_size))
def forward_propagation(self, X):
self.z1 = np.dot(X, self.W1) + self.b1
self.a1 = sigmoid(self.z1)
self.z2 = np.dot(self.a1, self.W2) + self.b2
self.a2 = sigmoid(self.z2)
return self.a2
def back_propagation(self, X, Y, output):
m = X.shape[0]
self.dZ2 = output - Y
self.dW2 = (1 / m) * np.dot(self.a1.T, self.dZ2)
self.db2 = (1 / m) * np.sum(self.dZ2, axis=0, keepdims=True)
self.dZ1 = np.dot(self.dZ2, self.W2.T) * (self.a1 * (1 - self.a1))
self.dW1 = (1 / m) * np.dot(X.T, self.dZ1)
self.db1 = (1 / m) * np.sum(self.dZ1, axis=0, keepdims=True)
def update_weights(self, learning_rate):
self.W1 -= learning_rate * self.dW1
self.b1 -= learning_rate * self.db1
self.W2 -= learning_rate * self.dW2
self.b2 -= learning_rate * self.db2
在这段代码中,BPNeuralNetwork类首先初始化了输入层、隐藏层和输出层的大小,并随机生成权重。forwardpropagation方法实现了前向传播过程,计算每一层的输出。backpropagation方法则是反向传播,计算梯度。update_weights方法根据计算得到的梯度更新权重。
二、粒子群算法优化BP神经网络
粒子群算法模拟鸟群觅食行为,每个粒子代表一个潜在解,通过跟踪自身历史最优位置和全局最优位置来更新自己的位置。
import numpy as np
# 适应度函数,这里用均方误差作为适应度
def fitness(weights, input_size, hidden_size, output_size, X, Y):
W1 = weights[:input_size * hidden_size].reshape(input_size, hidden_size)
b1 = weights[input_size * hidden_size:input_size * hidden_size + hidden_size].reshape(1, hidden_size)
W2 = weights[input_size * hidden_size + hidden_size:input_size * hidden_size + hidden_size + hidden_size * output_size].reshape(
hidden_size, output_size)
b2 = weights[-output_size:].reshape(1, output_size)
z1 = np.dot(X, W1) + b1
a1 = 1 / (1 + np.exp(-z1))
z2 = np.dot(a1, W2) + b2
a2 = 1 / (1 + np.exp(-z2))
mse = np.mean(np.square(a2 - Y))
return mse
# 粒子群算法
def particle_swarm_optimization(input_size, hidden_size, output_size, X, Y, num_particles, max_iter, c1=1.5, c2=1.5, w=0.7):
dim = input_size * hidden_size + hidden_size + hidden_size * output_size + output_size
positions = np.random.rand(num_particles, dim)
velocities = np.zeros((num_particles, dim))
pbest_positions = positions.copy()
pbest_fitness = np.array([fitness(p, input_size, hidden_size, output_size, X, Y) for p in positions])
gbest_index = np.argmin(pbest_fitness)
gbest_position = pbest_positions[gbest_index]
gbest_fitness = pbest_fitness[gbest_index]
for i in range(max_iter):
r1 = np.random.rand(num_particles, dim)
r2 = np.random.rand(num_particles, dim)
velocities = w * velocities + c1 * r1 * (pbest_positions - positions) + c2 * r2 * (gbest_position - positions)
positions = positions + velocities
fitness_values = np.array([fitness(p, input_size, hidden_size, output_size, X, Y) for p in positions])
improved_indices = fitness_values < pbest_fitness
pbest_positions[improved_indices] = positions[improved_indices]
pbest_fitness[improved_indices] = fitness_values[improved_indices]
current_best_index = np.argmin(pbest_fitness)
if pbest_fitness[current_best_index] < gbest_fitness:
gbest_fitness = pbest_fitness[current_best_index]
gbest_position = pbest_positions[current_best_index]
return gbest_position
在上述代码中,fitness函数计算给定权重下BP神经网络的均方误差,作为粒子群算法的适应度值。particleswarmoptimization函数实现了粒子群算法的主要逻辑,通过不断更新粒子的位置和速度,寻找最优解。
三、数据处理与多输出预测
假设数据存放在Excel文件中,我们可以使用pandas库来读取和处理数据。
import pandas as pd
# 读取Excel数据
data = pd.read_excel('data.xlsx')
X = data.iloc[:, :-2].values # 假设最后两列是输出
Y = data.iloc[:, -2:].values
input_size = X.shape[1]
hidden_size = 5
output_size = Y.shape[1]
# 使用粒子群算法优化权重
optimized_weights = particle_swarm_optimization(input_size, hidden_size, output_size, X, Y, num_particles=30, max_iter=100)
# 使用优化后的权重构建BP神经网络
W1 = optimized_weights[:input_size * hidden_size].reshape(input_size, hidden_size)
b1 = optimized_weights[input_size * hidden_size:input_size * hidden_size + hidden_size].reshape(1, hidden_size)
W2 = optimized_weights[input_size * hidden_size + hidden_size:input_size * hidden_size + hidden_size + hidden_size * output_size].reshape(
hidden_size, output_size)
b2 = optimized_weights[-output_size:].reshape(1, output_size)
# 进行预测
z1 = np.dot(X, W1) + b1
a1 = 1 / (1 + np.exp(-z1))
z2 = np.dot(a1, W2) + b2
predictions = 1 / (1 + np.exp(-z2))在这段代码中,首先使用pandas读取Excel文件中的数据,并将其分为输入X和输出Y。然后利用粒子群算法优化BP神经网络的权重,最后使用优化后的权重进行预测。
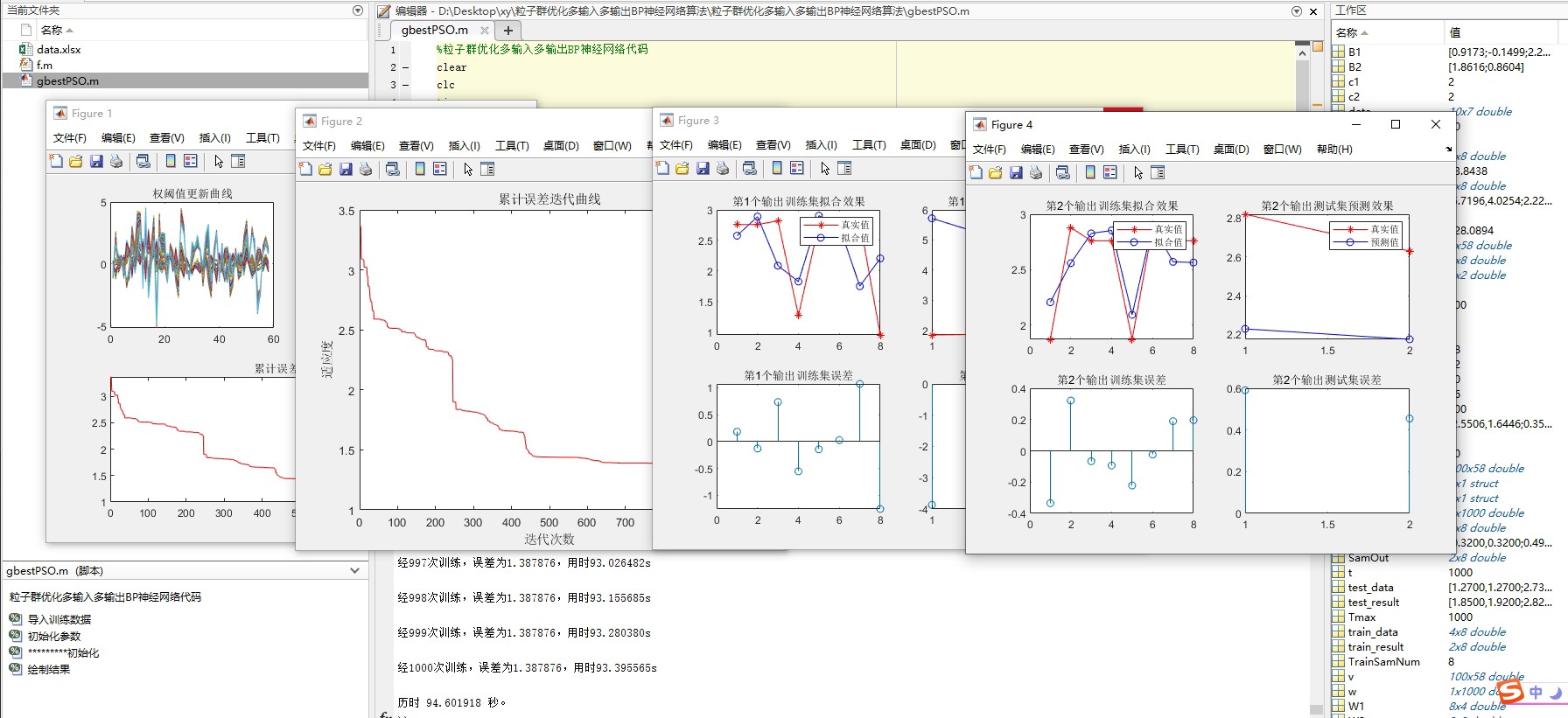
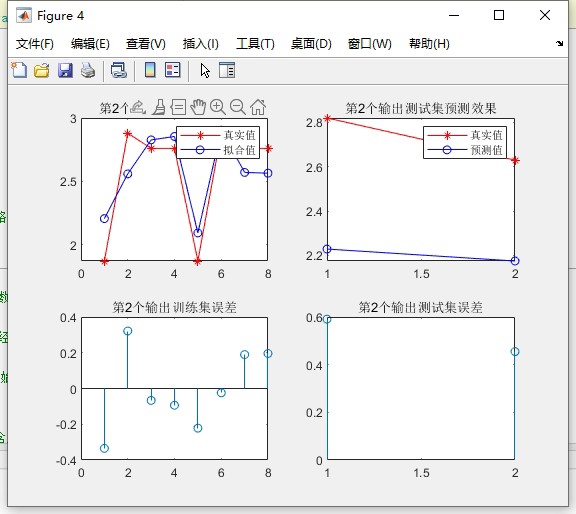
通过以上步骤,我们基于粒子群算法优化BP神经网络实现了多输入多输出的预测,并且数据以Excel格式存放,方便替换和更新,为各种预测任务提供了一个可灵活调整的数据处理和预测框架。
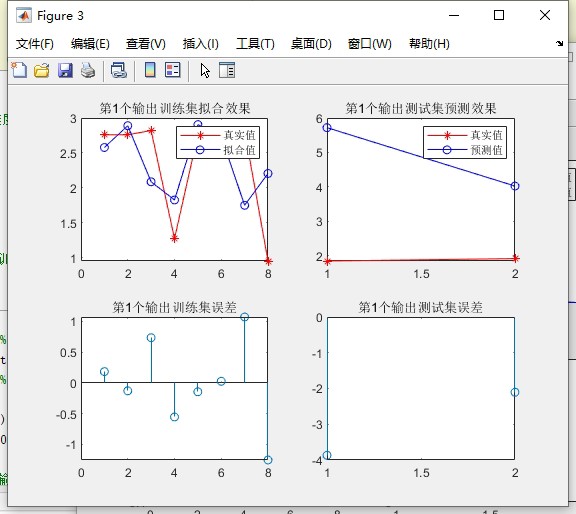
以上代码只是示例,实际应用中可能需要根据具体数据和任务进行更多的参数调整和优化。希望这篇博文能帮助你在多输出预测领域有所进展!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)