彻底搞懂深度学习-卷积神经网络(CNN)(动图讲解)
卷积神经网络(CNN)通过局部感知和权重共享机制,模仿人类视觉系统处理图像。它采用卷积层提取局部特征(如边缘、纹理),通过池化层压缩信息保留关键特征,形成层次化特征学习。相比传统全连接网络,CNN能有效利用图像空间结构信息,大幅提升图像识别效率。其核心组件包括卷积核、步长、填充等,共同实现高效的特征提取和数据处理。
想象一下,如果你在识别一张猫的照片时,需要逐个像素地分析整张图片的每一个细节,你还能快速准确地识别出这是一只猫吗?这正是传统全连接神经网络处理图像时面临的问题——它们把图像当作一维数据,忽略了像素间的空间关系,就像把一幅画撕碎后再试图理解画的内容一样。卷积神经网络(CNN)的出现,让神经网络学会了像人类一样"看图"。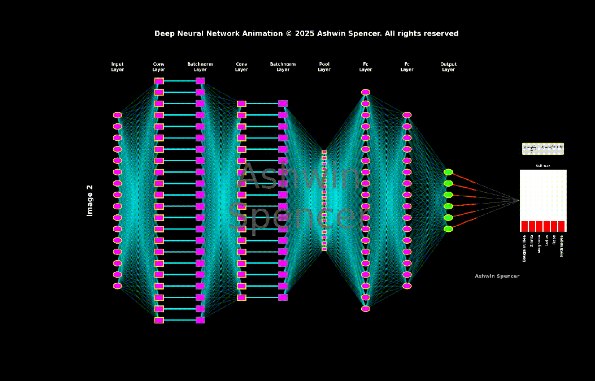
一、CNN - 神经网络学会了视觉
CNN的核心创新是什么?
CNN最大的突破是引入了局部感知和权重共享的思想——就像人类视觉系统一样,先关注局部特征,再逐步组合成复杂的概念。
传统的全连接神经网络将图像展平成一维向量处理,一张28×28的手写数字图片就有784个像素点,每个像素都要与下一层的每个神经元相连。这种做法不仅参数量巨大,更严重的是完全忽略了图像的空间结构信息——相邻像素通常具有相似的特征,而距离较远的像素关联性较弱。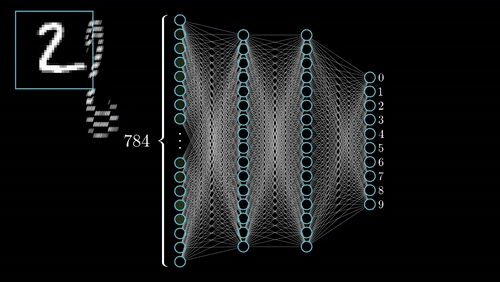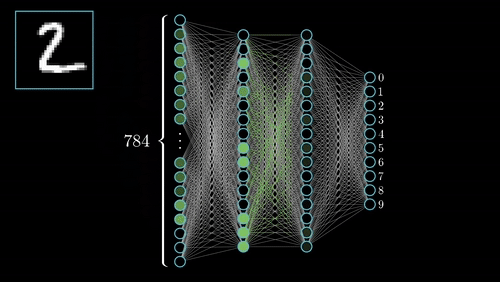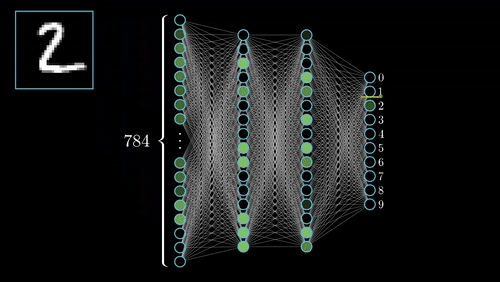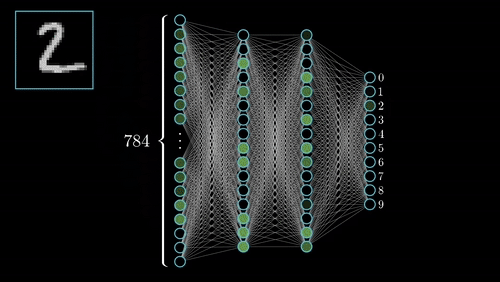
而CNN采用"局部连接"策略,每个神经元只与输入图像的一个小区域(称为感受野)相连。这个小区域通常是3×3或5×5的窗口,让神经元专注于检测局部特征。同时CNN让同一个卷积核在整个图像上共享相同的权重参数,这样无论一个特征(比如垂直边缘)出现在图像的左上角还是右下角,都用同一组参数来检测。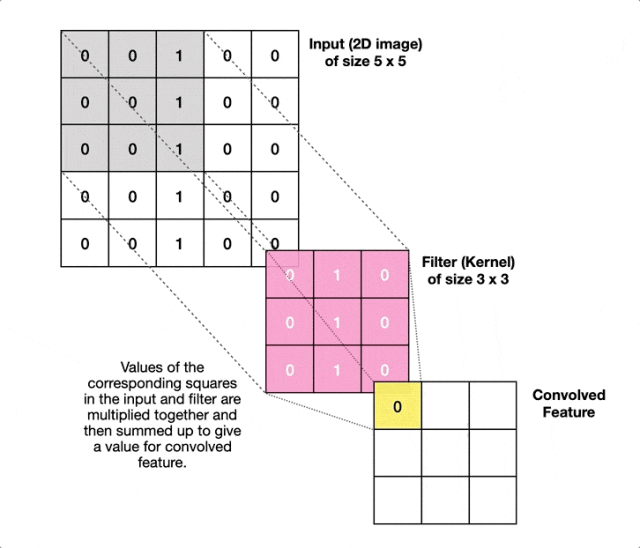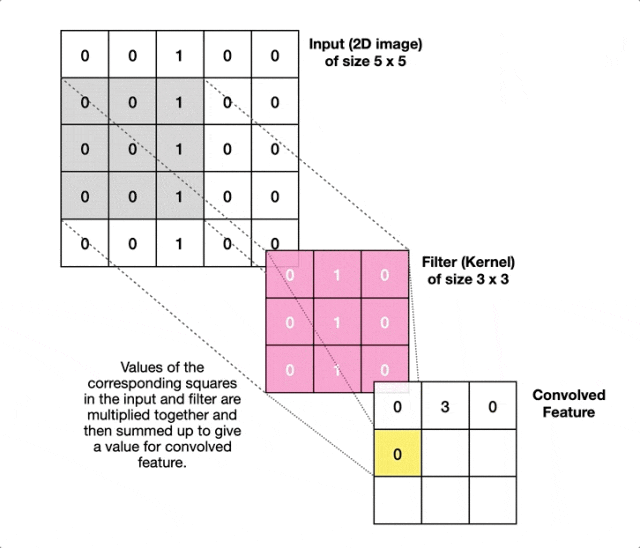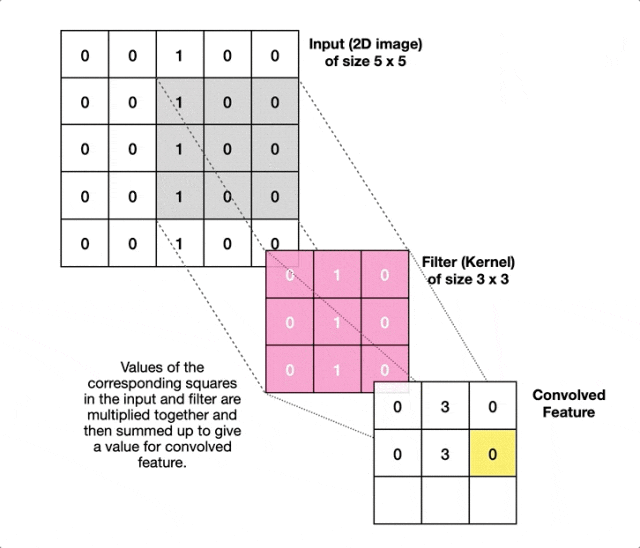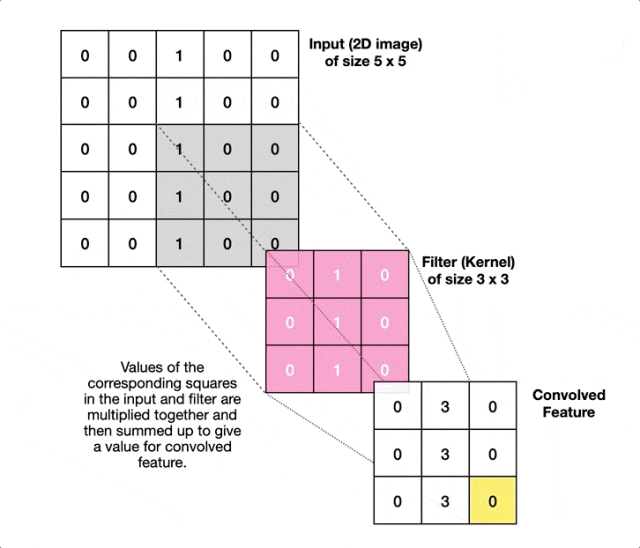
CNN的工作原理是什么?
CNN的工作过程模仿了人类视觉系统的层次化处理。就像我们看东西时,先识别边缘、线条等基础特征,再组合成形状、纹理,最后形成对物体的整体认知。
CNN通过多层级联的方式实现这种层次化特征学习。
第一层级:底层特征检测
- 卷积操作:使用多个小尺寸卷积核(如3×3)作为"特征检测器",在图像上滑动扫描
- 每个卷积核专门检测一种基础模式:水平边缘检测器、垂直边缘检测器、斜线检测器等
- 生成特征图:展示该特征在图像中的分布强度和位置信息
第二层级:特征激活与选择
- 激活函数:通过ReLU等非线性函数,增强有意义的强特征响应,抑制弱信号和噪声
- 特征竞争:让网络学会关注最显著、最有区分度的特征信息
第三层级:信息整合与压缩
- 池化操作:在局部区域内提取最重要的信息(最大值或平均值)
- 降维处理:减少数据量的同时保持关键特征,增强模型对位置变化的鲁棒性
随着网络层数加深,低层的简单特征逐步组合成高层的复杂概念——从边缘到纹理,从纹理到部件,从部件到完整对象。
二、卷积层 - 特征提取的艺术
卷积的设计思路是什么?
卷积操作就像用一个"特征检测器"在图像上滑动扫描——这个检测器(卷积核)通过数学运算来识别特定的图像模式。
卷积核本质是一个小矩阵,它在图像上滑动时会与对应区域进行数学运算(逐元素相乘后求和)。这个过程中卷积核就像一个小印章,在图像上一步步移动。每到一个位置,它就把自己的数值与下面的像素逐个相乘,然后把结果加起来。如果加起来的数值很大,说明找到了匹配的特征。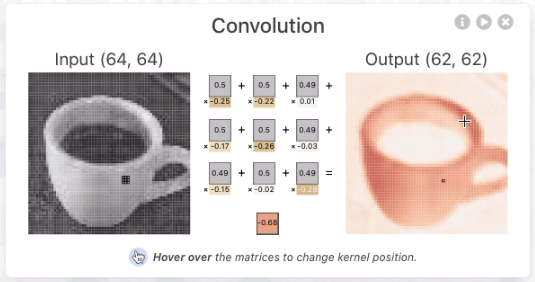
举个简单例子,有这样一个垂直边缘检测器。
[1 0 -1][1 0 -1][1 0 -1]
它的工作原理很直观:左边的像素值乘以1,中间的像素值乘以0(被忽略),右边的像素值乘以-1。
如果左边是亮像素(大值),右边是暗像素(小值),那么计算结果是:大值×1 + 小值×(-1) = 正数;如果左边是暗像素(小值),右边是亮像素(大值),那么结果是:小值×1 + 大值×(-1) = 负数。无论哪种情况,结果的绝对值都很大,说明检测到了明显的垂直边缘!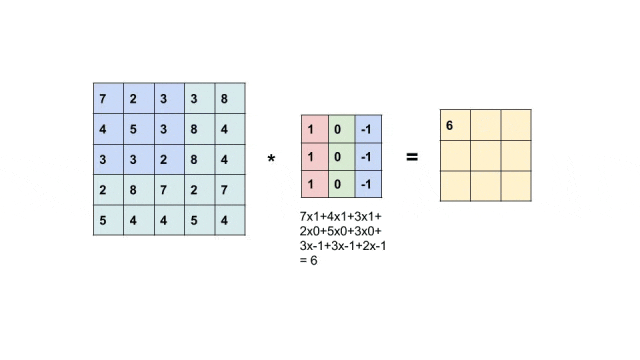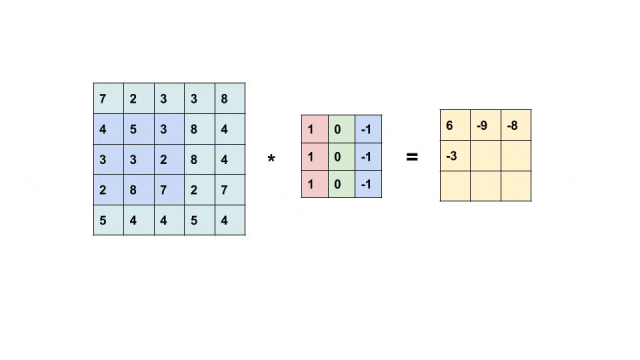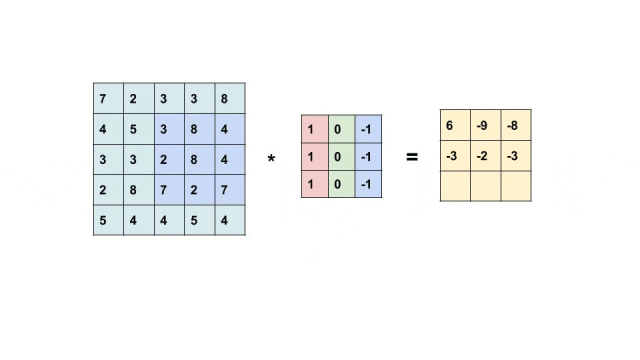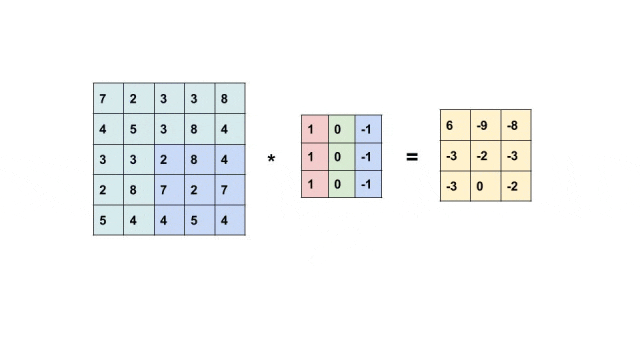
卷积层的核心组件是什么?
1. 卷积核(Filter/Kernel) - 特征检测器
卷积层的核心创新,像一个特定的"模式识别器"在图像上滑动扫描。每个卷积核专门检测一种特征模式,比如水平边缘、垂直边缘、圆形等。通过学习,这些检测器能够自动发现图像中的重要特征。
2. 步长(Stride) - 扫描步伐控制器
决定卷积核每次移动的距离。步长为1表示逐像素扫描(精细但慢),步长为2表示跳跃扫描(快速但可能遗漏细节)。合理的步长平衡了特征提取的精度和计算效率。
3. 填充(Padding) - 边界信息保护器
解决边缘像素信息丢失的问题,确保图像边缘的重要信息不会因为卷积操作而丢失。
(1)有效填充:保持输出尺寸与输入相同
(2)零填充:在图像边缘补零,让卷积核能完整扫描边缘区域
4. 特征图(Feature Map) - 特征可视化结果
每个卷积核扫描完图像后生成的结果。一个特征图显示了某种特征在图像中的分布情况——亮的区域表示该特征强烈存在,暗的区域表示特征较弱或不存在。
这四个组件通过协同工作,让卷积层能够有效提取图像特征。
三、池化层 - 信息压缩的智慧
池化层的设计思路是什么?
卷积层证明了局部特征提取的有效性,但也带来了一个问题:我们真的需要保留所有细节信息吗?池化层的想法很直接,能不能在保持重要特征的同时,让数据更紧凑?
池化操作就像一个"信息筛选器",在特征图上滑动扫描——这个筛选器通过特定策略来保留最重要的信息,同时压缩数据量。
池化的工作过程也很直观:将特征图分割成小块,然后在每个小块中应用筛选策略。就像把一张大照片分成很多小格子,每个格子只保留最重要的信息,最后重新拼成一张更紧凑的图片。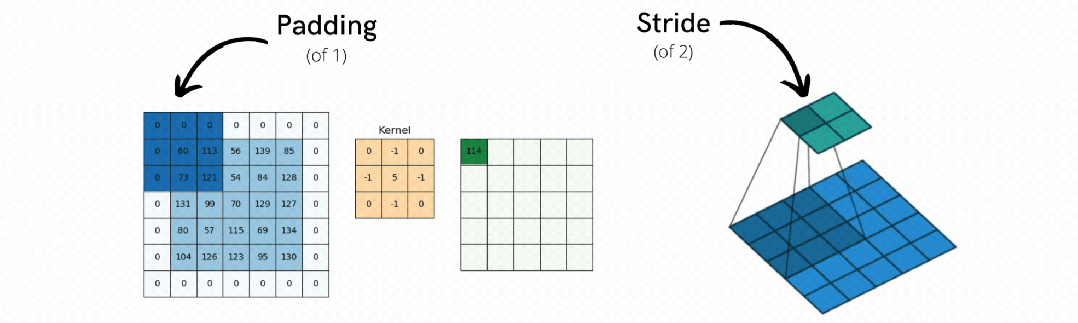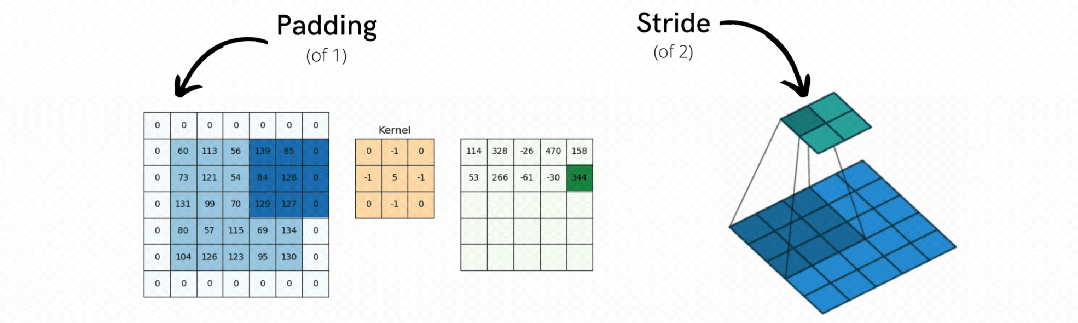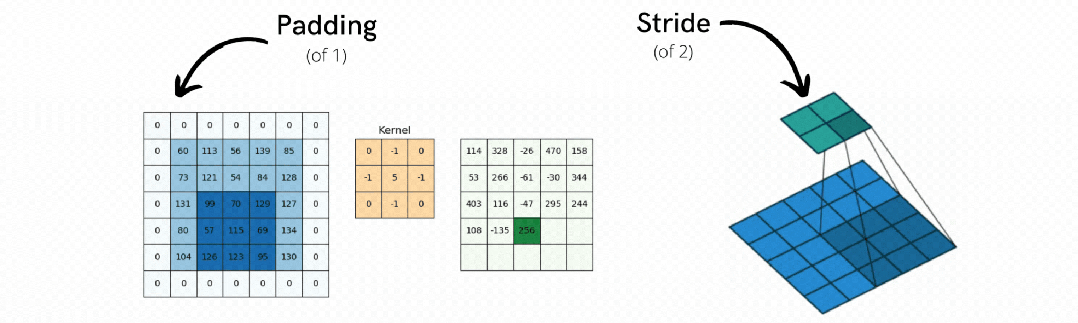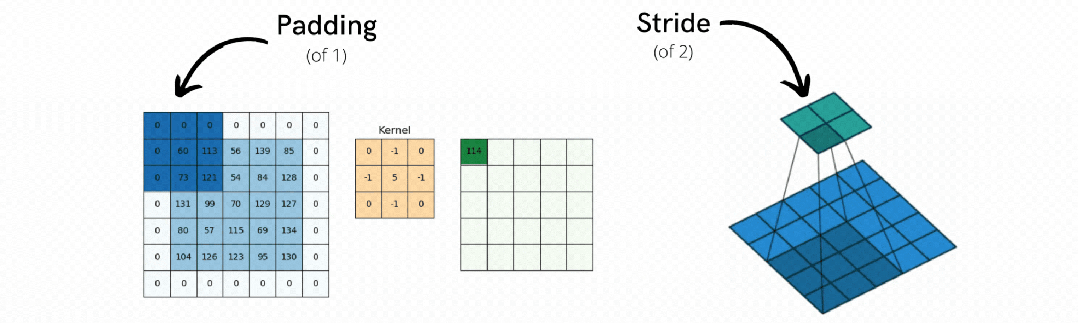
池化层的主要类型是什么?
最大池化和平均池化两种池化方式——最大池化善于捕捉显著特征,平均池化则保持信息的连续性。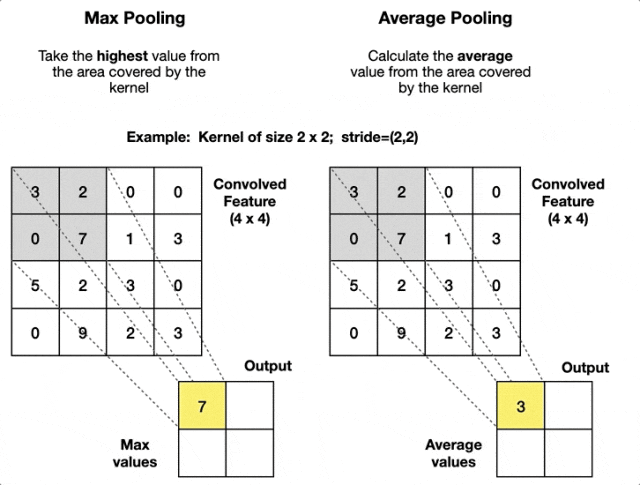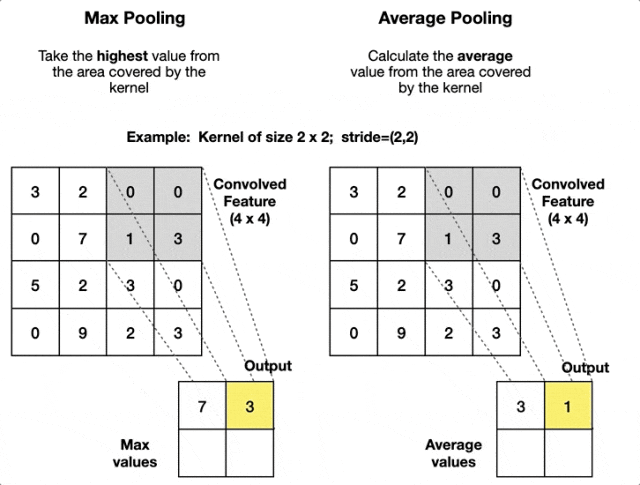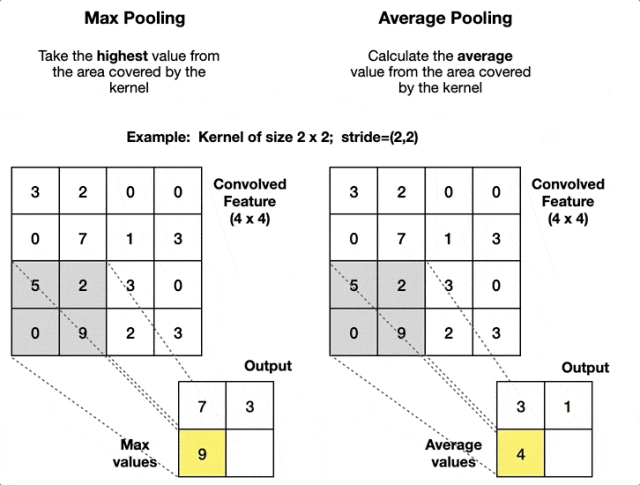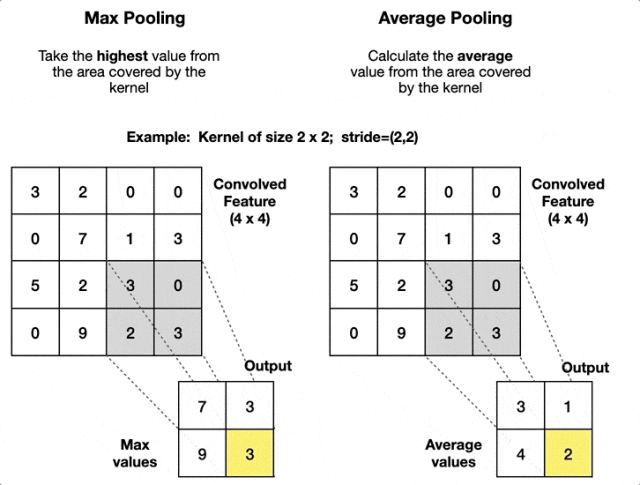
1. 最大池化 - 强者生存策略
最大池化像一个"选拔赛",在每个小区域中选出响应最强的特征。
举个简单例子,在一个2×2的区域中:
[8 3] → [8][1 5]它的工作原理很直观:在这个小块中,8是最大的数值,所以8被选中代表整个区域。其他数值虽然也包含信息,但在"选拔赛"中败下阵来。
这种方法特别适合检测特征是否存在——只要特征在某个位置被激活(数值较大),就会被保留下来,具有很好的位置不变性。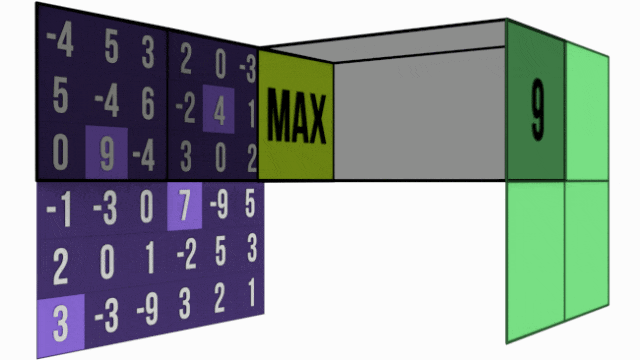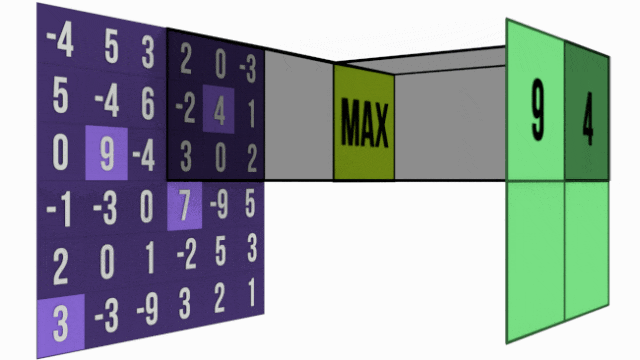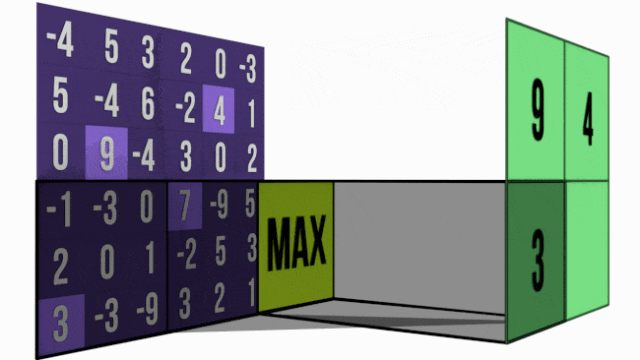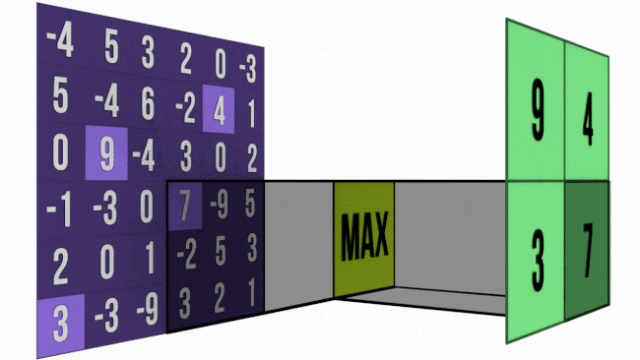
2. 平均池化 - 信息综合策略
平均池化是池化层最温和的设计,它不做激烈的选择,而是综合考虑区域内所有信息。
同样是2×2区域的例子:
[8 3] → [4.25][1 5] (8+3+1+5)/4 = 4.25
它通过计算平均值来保持特征的整体强度,就像一个"民主投票"的过程——每个像素都有发言权,最终结果代表了大家的集体意见。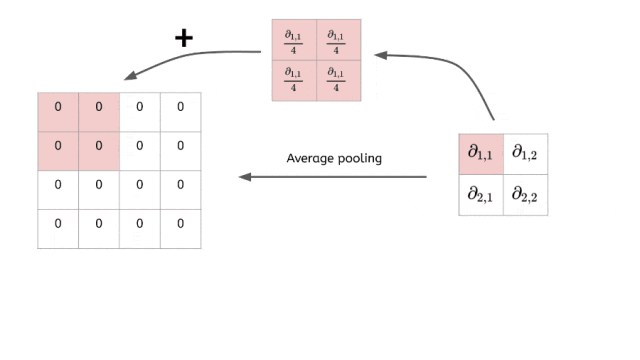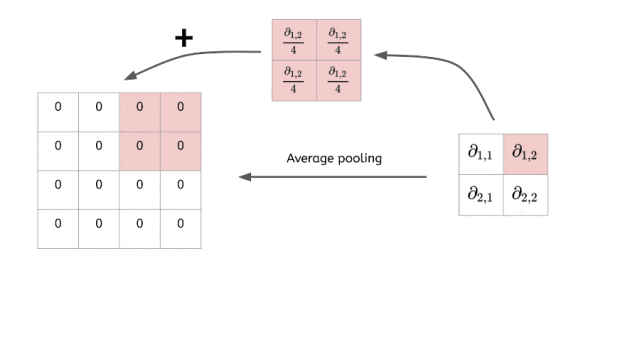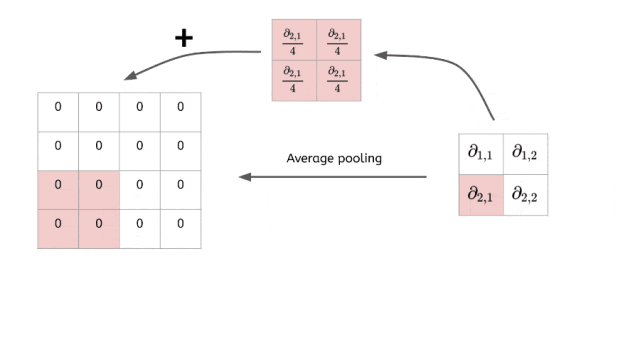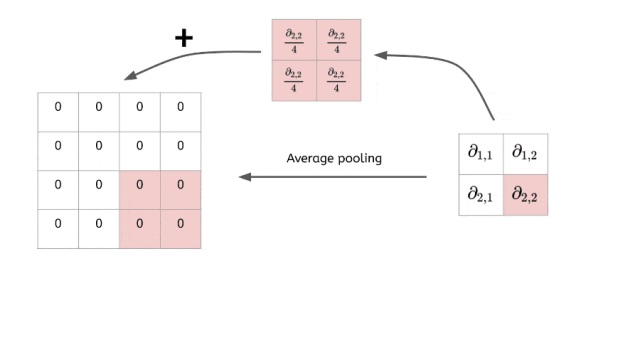
池化层是如何工作的?
池化层通过三个核心组件(池化窗口、池化策略、步长控制)的协同配合来实现特征压缩。
1. 池化窗口(Pool Size) - 区域划分器
第一步操作:将特征图按窗口大小分割成不重叠的小块,每块独立处理。
池化窗口决定每次处理的区域大小,就像一个移动的"取景框"。常见的2×2窗口意味着每4个像素合并成1个,实现4倍的数据压缩窗口越大,压缩比越高,但细节丢失也越多。
2. 池化策略(Pooling Operation) - 信息选择器
第二步操作:在每个小块内应用选定的池化策略,每个小块产生一个代表性数值。
池化策略决定如何从窗口内的多个数值中选择代表值,这是池化的核心决策。最大池化选择最强响应,平均池化综合所有响应每种策略适合不同的应用场景和特征类型。
3. 步长控制(Stride) - 滑动步伐控制器
第三步操作:按步长移动窗口,将所有处理结果按空间关系重新排列
步长控制决定池化窗口每次移动的距离,控制最终的压缩程度。通常步长等于窗口大小,确保不重叠处理,实现标准压缩小于窗口大小时会产生重叠,保留更多信息但增加计算量。
这三个组件通过有机配合,让池化层能够像一个智能的"数据压缩器"——既保持了重要特征信息,又实现了高效的维度降低。
感谢大家的观看和支持,俺在这边整理了一份卷积神经网络原理到实战的资料
感兴趣的朋友可以直接扫码领取哈~

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)