从零开始搭建一个简单的神经网络(三)
简单代码实战
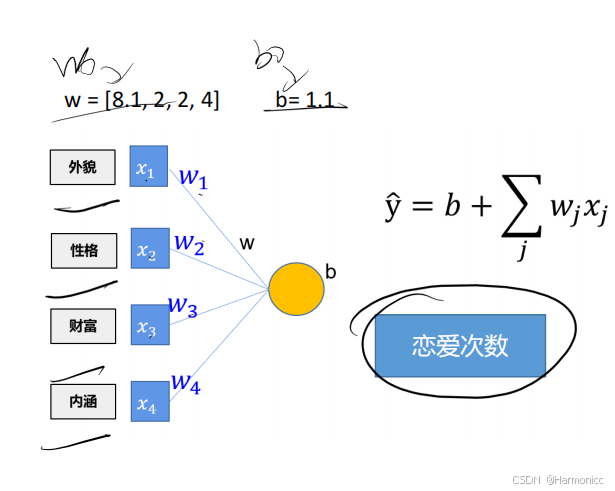
一个简单的线性回归模型训练示例,通过四个自变量预测最后的一个因变量的结果。
1.导库
import numpy as np
import torch
import matplotlib.pyplot as plt
import random2.创建数据和数据可视化
def create_data(w, b, data_num): # 创建数据
x = torch.normal(0, 1, (data_num, len(w))) # 行数是数据量,列数是w_i的个数,0为均值,1为方差
y = torch.matmul(x, w) + b # matmul表示矩阵相乘
noise = torch.normal(0, 0.01, y.shape)
y += noise # 噪声加到y上
return x,y
num = 500
#静态真实值,目的是要逼近
true_w = torch.tensor([8.1,2,2,4])
true_b = torch.tensor(1.1)
X,Y = create_data(true_w,true_b,num)
plt.scatter(X[:,3],Y,1)
plt.show()create_data函数生成模拟数据。它接受权重w、偏置b和数据量data_num作为输入,生成符合正态分布的输入特征x,然后根据线性关系y = xw + b加上一些噪声生成输出y,使用matplotlib绘制了输入特征x的第四个维度与输出y的散点图,用于直观展示数据分布,这里的维度可以是四个当中任意的。
3.提供训练集所需要的数据
#专门提供数据的函数,因为这里Loss一批一批算,为什么要一批一批算?提高泛化能力,不容易陷进局部最优
def data_provider(data,label,batchsize):
length = len(label)
indices = list(range(length)) #长度为0-100的列表
#要把数据打乱来取不能按顺序取
random.shuffle(indices)
for each in range(0,length,batchsize):
get_indices = indices[each:each+batchsize] #保证数据能取满
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data,get_label #有记忆的return
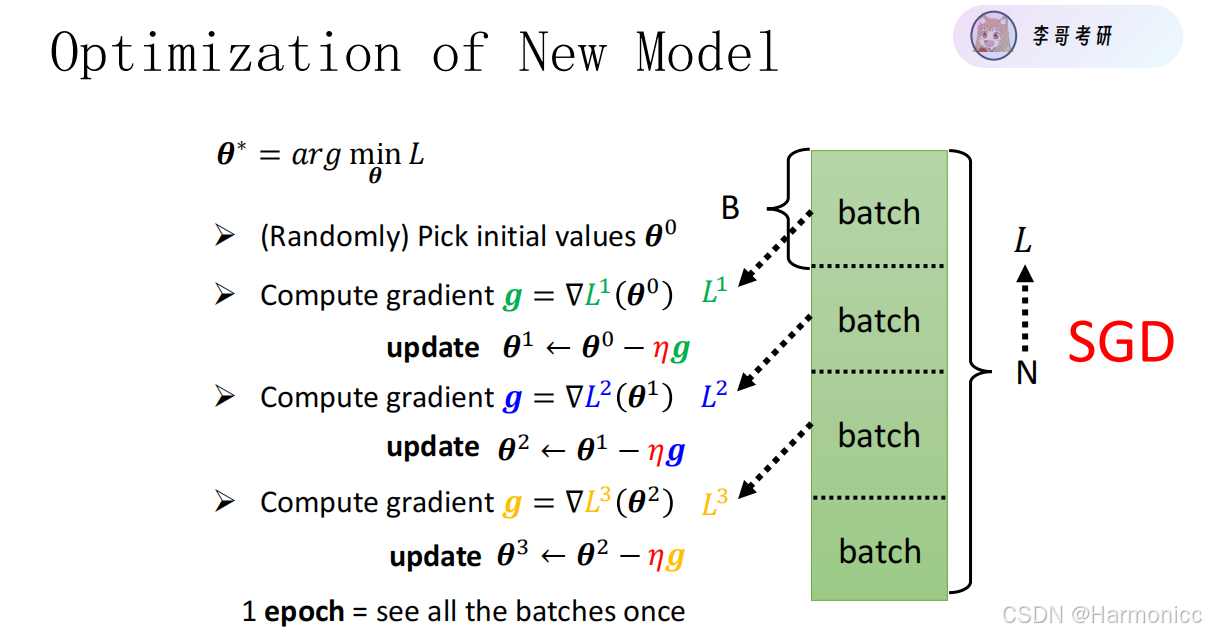
batchsize = 16 #干什么用的,分批提供模型,分成16批data_provider函数是一个生成器,用于批量提供数据。它将数据随机打乱,然后按照指定的批次大小batchsize分批提供数据,这在训练神经网络时很常见,有助于提高模型的泛化能力。
泛化能力可以通俗理解为模型的 “举一反三” 能力。 想象你在学习数学题,有一堆练习题(训练数据),通过做这些题掌握了解题方法(训练模型)。泛化能力强的话,遇到没做过但类似的新题目(测试数据),也能凭借之前学到的方法把题做对。 在机器学习和深度学习里,模型基于已有的数据进行训练,学习数据中的规律和模式。如果模型泛化能力好,当面对新的、没见过的数据时,也能准确地进行预测或分类。比如用一些猫狗图片训练一个识别模型,泛化能力强的模型,碰到没训练过的其他猫狗图片,也能精准判断是猫还是狗。 相反,如果模型泛化能力差,就会 “死记硬背” 训练数据,把每道题(每个训练样本)孤立记住,而不是真正理解解题思路(数据的本质规律)。这样遇到新题目(新数据)就不会做了,就像模型在训练数据上表现很好,一到新数据上就错误百出 。
4.搭建网络
定义模型,损失函数以及优化器
#线性模型的前向传播过程,即pred_y = xw + b
def fun(x,w,b):
pred_y = torch.matmul(x,w)+b #预测值
return pred_y
#loss值的定义,评估指标
def maeloss(pred_y,y):
return torch.sum(abs(pred_y-y)/len(y))
#梯度是自带的,直接梯度下降更新参数
def sgd(paras, lr):
with torch.no_grad(): #理解成不要算冗余的梯度
for para in paras:
para -= para.grad * lr
para.grad.zero_() #处理冗余的梯度- 代码中使用的损失函数是平均绝对误差(MAE),另一种常见的选择是均方误差(MSE),它对于离群点更加敏感。
5.模型训练
#学习率
lr = 0.03
#初始参数
w_0 = torch.normal(0,0.01,true_w.shape,requires_grad=True) #这个w需要计算梯度
b_0 = torch.tensor(0.01,requires_grad=True)
print(w_0,b_0)
#训练轮数
epochs = 50
for epoch in range(epochs):
data_loss = 0
for batch_x,batch_y in data_provider(X,Y,batchsize):
pred_y = fun(batch_x,w_0,b_0)
loss = maeloss(pred_y,batch_y)
loss.backward()
sgd([w_0,b_0],lr)
data_loss +=loss
print('epoch %03d:loss %.6f'%(epoch,data_loss))
- 设置学习率
lr和初始参数w_0、b_0。 - 在指定的训练轮数
epochs内,通过循环遍历数据批次,计算损失,反向传播梯度,更新参数。 - 在每轮结束后,打印出当前轮数的总损失。
6.输出结果
print('真实函数值为',true_w,true_b)
print('训练后的参数值为',w_0,b_0)loss的迭代结果
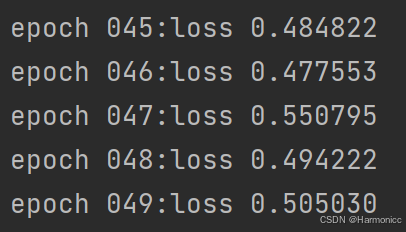
为什么loss值会随着轮数增加在一个固定的值附近波动而不是趋于0?
多种因素影响,通常很难将损失值降低到0,重要的是要找到一个平衡点,使模型在训练数据和未见过的数据上都能表现良好就行了。

一些要点
关于不同变量之间的解释
true_w和true_b是模型的“真实”或目标权重和偏置。这些是我们希望通过训练过程让模型学习到的值。X和Y是训练数据集。这些数据是通过create_data函数生成的,其中加入了噪声以模拟真实世界的数据。batch_x和batch_y是从一个批次中抽取的数据和标签。w_0和b_0是模型的初始权重和偏置。它们通过训练过程逼近true_w和true_b。pred_y是模型的预测输出。
确保维度匹配
- 在进行矩阵运算时,确保张量的维度匹配是非常重要的。
x的列数必须与w的行数相匹配。同样地,pred_y的形状必须与y的形状相匹配。
完整代码如下(自己的注释):
import numpy as np
import torch
import matplotlib.pyplot as plt
import random
def create_data(w, b, data_num): # 创建数据
x = torch.normal(0, 1, (data_num, len(w))) # 行数是数据量,列数是w_i的个数,0为均值,1为方差
y = torch.matmul(x, w) + b # matmul表示矩阵相乘
noise = torch.normal(0, 0.01, y.shape)
y += noise # 噪声加到y上
return x,y
num = 500
#静态真实值,目的是要逼近
true_w = torch.tensor([8.1,2,2,4])
true_b = torch.tensor(1.1)
X,Y = create_data(true_w,true_b,num)
plt.scatter(X[:,3],Y,1)
plt.show()
#专门提供数据的函数,因为这里Loss一批一批算,为什么要一批一批算?提高泛化能力,不容易陷进局部最优
def data_provider(data,label,batchsize):
length = len(label)
indices = list(range(length)) #长度为0-100的列表
#要把数据打乱来取不能按顺序取
random.shuffle(indices)
for each in range(0,length,batchsize):
get_indices = indices[each:each+batchsize] #保证数据能取满
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data,get_label #有记忆的return
batchsize = 16 #干什么用的,分批提供模型,分成16批
#真实值?不是
# for batch_x,batch_y in data_provider(X, Y,batchsize):
# print(batch_x,batch_y)
#线性模型的前向传播过程,即pred_y = xw + b
def fun(x,w,b):
pred_y = torch.matmul(x,w)+b #预测值
return pred_y
#loss值的定义,评估指标
def maeloss(pred_y,y):
return torch.sum(abs(pred_y-y)/len(y))
#梯度是自带的,直接梯度下降更新参数
def sgd(paras, lr):
with torch.no_grad(): #理解成不要算冗余的梯度
for para in paras:
para -= para.grad * lr
para.grad.zero_() #处理冗余的梯度
#学习率
lr = 0.03
#初始参数
w_0 = torch.normal(0,0.01,true_w.shape,requires_grad=True) #这个w需要计算梯度
b_0 = torch.tensor(0.01,requires_grad=True)
print(w_0,b_0)
#训练轮数
epochs = 50
for epoch in range(epochs):
data_loss = 0
for batch_x,batch_y in data_provider(X,Y,batchsize):
pred_y = fun(batch_x,w_0,b_0)
loss = maeloss(pred_y,batch_y)
loss.backward()
sgd([w_0,b_0],lr)
data_loss +=loss
print('epoch %03d:loss %.6f'%(epoch,data_loss))
print('真实函数值为',true_w,true_b)
print('训练后的参数值为',w_0,b_0)
#维度很重要
名词解释&问题示例
1.为什么要有batchsize(为什么数据要一批一批算)?
2.噪声
3.泛化能力
4.优化器
5.搭建一个简单的神经网络的关键步骤
本小节结束

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)