一文看懂多模态大语言模型CLIP架构!
一文看懂多模态大语言模型CLIP架构!
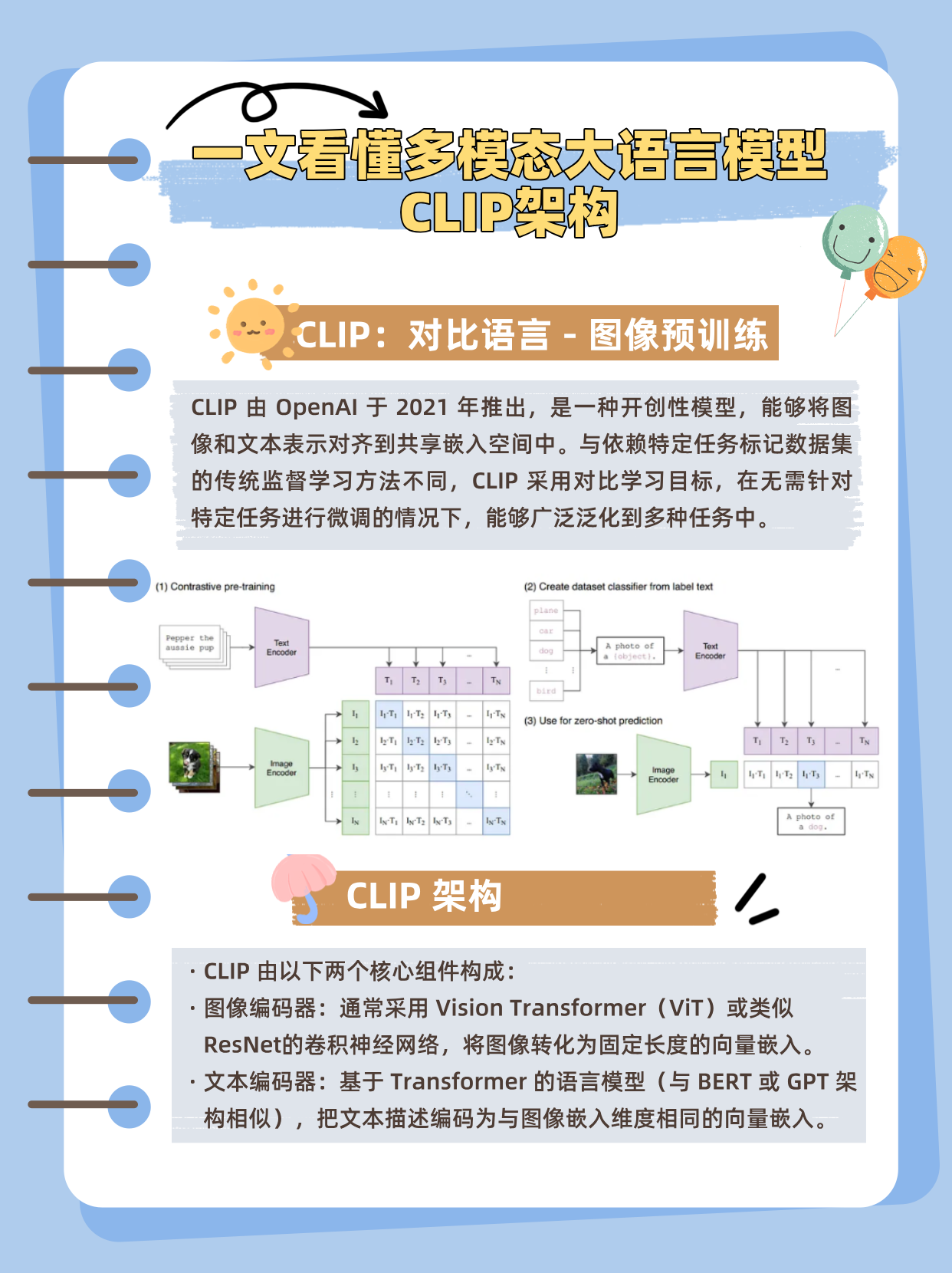
1. CLIP:对比语言 - 图像预训练
CLIP 由 OpenAI 于 2021 年推出,是一种开创性模型,能够将图像和文本表示对齐到共享嵌入空间中。与依赖特定任务标记数据集的传统监督学习方法不同,CLIP 采用对比学习目标,在无需针对特定任务进行微调的情况下,能够广泛泛化到多种任务中。
1.1 CLIP 架构
CLIP 由以下两个核心组件构成:
→图像编码器:通常采用 Vision Transformer(ViT)或类似 ResNet 的卷积神经网络,将图像转化为固定长度的向量嵌入。
→文本编码器:基于 Transformer 的语言模型(与 BERT 或 GPT 架构相似),把文本描述编码为与图像嵌入维度相同的向量嵌入。
这两个编码器协同工作,将图像和文本映射到共享潜在空间。在此空间中,语义相关的图像 - 文本对(如狗的图像与 “一张狗的照片” 这一标题)彼此靠近,而语义不相关的对则相距较远。

1.2 CLIP 训练目标
CLIP 在约 4 亿个从网络爬取的图像 - 文本对上进行训练。训练过程采用受 InfoNCE(噪声对比估计)启发的对比损失函数。对于包含 N 个图像 - 文本对的批次:
→计算所有 N×N 种图像和文本嵌入组合的余弦相似度。
→目标是最大化 N 个正确(匹配)对的相似度,同时最小化 N²−N 个错误(不匹配)对的相似度。
→通过优化相似度分数上的对称交叉熵损失实现。
同样计算文本到图像方向的损失,总损失为两者的平均值。
其中,控制分布软硬度的温度参数。这种对称形式确保图像和文本两种模态的表示能有效对齐。

1.3 CLIP 的零样本学习能力
CLIP 的优势在于其零样本学习能力。预训练后,它能够通过构建提示(例如 “一张 [类别] 的照片”)并比较图像嵌入与可能类别的文本嵌入,执行图像分类等任务,而无需特定任务的训练数据。
零样本 CLIP 在应对分布偏移时,比标准 ImageNet 模型具有更强的鲁棒性。左图展示了理想鲁棒模型(虚线)在 ImageNet 分布和其他自然图像分布上的表现一致。零样本 CLIP 模型将这种 “鲁棒性差距” 缩小了高达 75%。图中显示了对 logits 转换值的线性拟合以及基于自助法估计的 95% 置信区间。右图则可视化了香蕉类别的分布偏移情况,该类别在 7 个自然分布偏移数据集中有 5 个共享。最佳零样本 CLIP 模型(ViT-L/14@336px)的表现与在 ImageNet 验证集上表现相同的 ResNet-101 模型进行了对比。(来源:OpenAI)
更多课程内容可以听取工信部电子标准院《人工智能大模型应用工程师》课程获得详解。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 5
5 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)