数据结构——栈与堆的区别
栈(stack)及堆(heap)概念的最初了解起始于对C语言的基础学习。而对于他们的理解也只是浅尝辄止,停留在:栈内存由系统自动分配,函数调用时对其局部变量分配内存,调用结束则进行回收;堆内存由用户手动分配,需进行内存释放操作——即初步了解了free和malloc,calloc等;而在进行数据结构方面知识学习后,也进一步的对二者有了更深的理解应当说,对二者的初步理解总体上正确。在编程里,堆内存与栈
目录
前言
栈(stack)及堆(heap)概念的最初了解起始于对C语言的基础学习。
而对于他们的理解也只是浅尝辄止,停留在:
栈内存由系统自动分配,函数调用时对其局部变量分配内存,调用结束则进行回收;
堆内存由用户手动分配,需进行内存释放操作——即初步了解了free和malloc,calloc等;
而在进行数据结构方面知识学习后,也进一步的对二者有了更深的理解
应当说,对二者的初步理解总体上正确。在编程里,堆内存与栈内存属于内存管理的概念,二者在用途、分配方式、性能等方面,都存在显著差异。
在理解两个概念时,需要放到具体的场景下,因为不同场景下,堆与栈代表不同的含义
程序内存管理场景下,堆与栈表示两种内存管理方式。
数据结构场景下,堆与栈表示两种常用的数据结构。
一、程序内存管理:
1、栈内存:
栈内存是内存中被操作系统自动管理的一块区域,主要用于存储局部变量、函数调用信息等。
当进入一个函数时,函数内的局部变量会被自动分配到栈上;而当函数执行完毕返回时,这些变量所占用的栈空间会被自动释放。如:
#include <bits/stdc++.h>
int main()
{
int a;
double b[3];
char c;
return 0;
}其中函数中定义的局部变量按照定义的顺序依次压入栈中,也就是说:
相邻变量的地址之间不会存在其它变量。(这点也可以在结构体内存对齐中体现)
栈的内存地址生长方向与堆相反,由高到底,所以后定义的变量地址低于先定义的变量,
“生长方向” :
描述的是栈和堆在内存中分配新空间时地址变化的趋势。
而对应变量的生存期与作用域也被限制于了对应函数内部。
通常情况下,栈内存的访问速度比堆内存快,因为栈的操作是基于指针的移动,操作简单;
但是空间通常比较小,如果递归调用过深或者局部变量过大,可能会导致栈溢出错误。
由此也就体现了各种递归算法时间复杂度的问题:
如常规的阶乘递归写法,相对的就是O(n);而一旦变得较为复杂,如斐波那契数列的递归计算,时间复杂度立刻飙升为O(2^n)
在程序运行时,系统会为每个线程分配一个调用栈,用于存储函数调用的上下文信息,像局部变量、返回地址等。每进行一次函数调用,系统就会在栈上创建一个新的栈帧,调用结束后再将栈帧弹出。递归调用时,每次递归调用都会创建新的栈帧,若递归深度过大,栈空间就会被耗尽,从而引发栈溢出错误。
2、堆内存:
堆内存是一个用于动态内存分配的内存区域,程序在运行时可以根据需要从堆中分配和释放内存,较为常见的就是C语言的malloc,C++的new等;同样的,如果分配内存过大而始终不回收,就可能导致堆内存分配过度,带来内存泄漏。
#include <bits/stdc++.h>
int main()
{
char *s;
s = (char*)malloc(sizeof(char) * 100);
return 0;
}更重要的,虽然某些高级语言有着自我回收的机制,如Java、python等。
但在事实上,堆内存的分配并非是"继续地"紧随连续内存的分配,如声名一个变量后进行堆内存分配,动态分配的内存并不是紧接着前一个变量,而是从内存区获取一块大小足够满足需求的内存,而这块分配的内存,本身则是连续的。
这也就会带来另一个问题,当堆内存分配大小不一且过于碎片化时,虽然内存中总体上可能有足够的空闲空间,但这些空闲空间被分割成许多不连续的小块。当程序需要分配较大的连续内存块时,可能无法找到足够大的连续空闲区域来满足分配请求,尽管总的空闲内存量可能是足够的,从而导致显示内存不够的错误。这种内存碎片化问题在长期运行且频繁进行内存分配和释放的程序中较为常见,会降低内存的使用效率,甚至可能影响程序的正常运行。

如示:内存足够,但因为碎片化而造成了分配失败,进而导致了内存浪费。
堆的内存地址生长方向与栈相反,由低到高;堆内存的空间相对较大,可以存储大量的数据,适合存储对象、数组等动态数据结构。
但由于堆内存的分配和释放需要更复杂的管理机制,堆内存的访问速度比栈内存慢。
关于堆上内存空间的分配过程,首先应该知道,操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。
另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中相关释放内存的语句才能正确地释放本内存空间。由于找到的堆节点的大小不一定正好等于申请的大小,系统会自动地将多余的那部分重新放入空闲链表。
3、二者的区别:
做个稍微系统的总结:
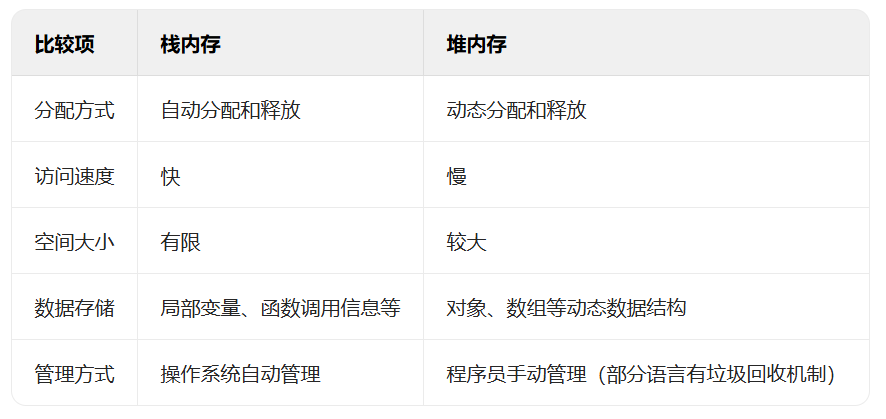
(1)管理方式不同
栈由操作系统自动分配释放,无需手动控制;
堆的申请和释放工作由程序员控制,容易产生内存泄漏。
(2)空间大小不同
每个进程拥有的栈大小要远远小于堆大小,理论上,进程可申请的堆大小为虚拟内存大小。
(3)生长方向不同
堆的生长方向向上,内存地址由低到高;
栈的生长方向向下,内存地址由高到低。
(4)分配方式不同
堆都是动态分配的,没有静态分配的堆。
栈有 2 种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloc函数分配,但是栈的动态分配和堆是不同的,它的动态分配是由操作系统进行释放,无需手动实现。
(5)分配效率不同
栈由操作系统自动分配,会在硬件层级对栈提供支持,这就决定了栈的效率比较高。
堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,内存申请容易产生内存碎片,效率比栈要低得多。
(6)存放内容不同
栈存放的内容:函数返回地址、相关参数、局部变量和寄存器内容等。
当主函数调用另外一个函数的时候,要对当前函数执行断点进行保存,需要使用栈来实现,首先入栈的是主函数下一条语句的地址,然后是当前栈帧的底部地址,再然后是被调函数的实参等,一般情况下是按照从右向左的顺序入栈,之后是被调函数的局部变量。
注意:静态变量存放在data段或者 BSS 段,不入栈。
出栈的顺序正好相反,最终栈顶指向主函数下一条语句的地址,主程序又从该地址开始执行。
堆中具体的存放内容则是由用户填充。
无论是堆还是栈,在内存使用时都要防止越界,越界导致的非法访问可能会摧毁程序的堆、栈数据,轻则导致程序运行处于不确定状态,获取不到预期结果,重则导致程序异常崩溃,这些都是编程时应该注意的问题。
二、数据结构:
1、栈:
栈是一种运算受限的线性表,其限制是指:只仅允许在表的一端进行插入和删除操作,这一端被称为栈顶(top),相对地,把另一端称为栈底(bottom)。
把新元素放到栈顶元素的上面,使之成为新的栈顶元素称作进栈、入栈或压栈(push);
把栈顶元素删除,使其相邻的元素成为新的栈顶元素称作出栈或退栈(pop)。
这种受限的运算使栈拥有“先进后出”的特性(First In Last Out),简称 FILO。
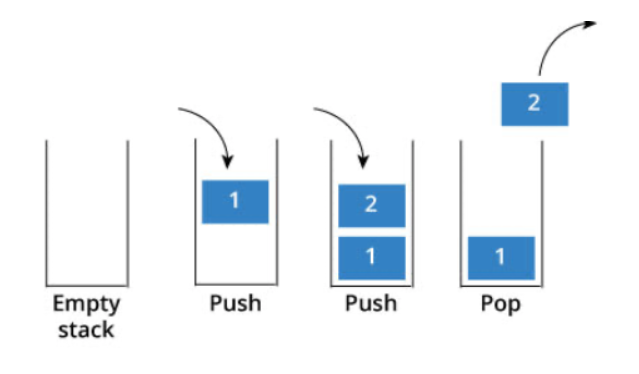
栈分顺序栈和链式栈两种:
栈是一种线性结构,所以可以使用数组或链表(单向链表、双向链表或循环链表)作为底层数据结构。
使用数组实现的栈叫做顺序栈,使用链表实现的栈叫做链式栈,二者的区别是顺序栈中的元素地址连续,链式栈中的元素地址不连续。
利用C实现一个简单的栈:
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
// 定义栈结构
typedef struct {
int data[MAX_SIZE];
int top;
} Stack;
// 初始化栈
void initStack(Stack *s) {
s->top = -1;
}
// 判断栈是否为空
int isEmpty(Stack *s) {
return s->top == -1;
}
// 判断栈是否已满
int isFull(Stack *s) {
return s->top == MAX_SIZE - 1;
}
// 入栈操作
void push(Stack *s, int value) {
if (isFull(s)) {
printf("栈已满,无法入栈!\n");
return;
}
s->data[++(s->top)] = value;
}
// 出栈操作
int pop(Stack *s) {
if (isEmpty(s)) {
printf("栈为空,无法出栈!\n");
return -1;
}
return s->data[(s->top)--];
}
// 获取栈顶元素
int peek(Stack *s) {
if (isEmpty(s)) {
printf("栈为空,无栈顶元素!\n");
return -1;
}
return s->data[s->top];
}
int main() {
Stack s;
initStack(&s);
push(&s, 10);
push(&s, 20);
push(&s, 30);
printf("栈顶元素: %d\n", peek(&s));
printf("出栈元素: %d\n", pop(&s));
printf("出栈元素: %d\n", pop(&s));
printf("栈顶元素: %d\n", peek(&s));
return 0;
} 上述代码实则为顺序栈;相对的链式栈,其实可以理解为一个头插法的链表。在实际的使用中,如做题,顺序栈足够用。甚至理论上只需一个指定内容为特定类型的数组,亦可以实现栈的所有功能。
2、堆:
(1)概念理解:
堆是一种特殊的完全二叉树:
当且仅当满足所有节点的值总是不大于或不小于其父节点的值的完全二叉树被称之为堆,这一特性称之为堆序性。
因此,在一个堆中,根节点是最大或最小节点,也就是所谓的大顶堆(或大根堆)或小顶堆(或小根堆)。堆的左右孩子没有大小的顺序。如图一个小顶堆示例:
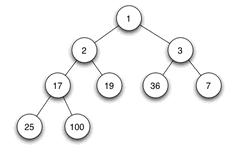
堆通常用于实现优先队列
优先队列是一种特殊的队列,其中的元素按照优先级排序,优先级高的元素先出队。
(2)基本操作:(以小根堆为例)
插入操作
- 将新元素插入到堆的末尾,然后通过 “上浮” 操作来调整堆,使其保持堆的性质。
- 具体步骤:
- 把新元素添加到堆数组的最后一个位置。
- 比较新元素与其父节点的值,如果新元素小于父节点的值,则交换它们的位置。
- 重复上述步骤,直到新元素不小于父节点的值或者到达根节点。
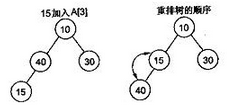
删除操作
- 一般删除堆顶元素,删除堆顶元素后,需要通过 “下沉” 操作来调整堆。
- 具体步骤:
- 将堆的最后一个元素移动到堆顶位置,覆盖原来的堆顶元素,同时删除堆的最后一个元素。
- 比较堆顶元素与它的子节点的值,如果堆顶元素大于子节点中的较小值,则将堆顶元素与较小的子节点交换位置。
- 重复上述步骤,直到堆顶元素小于或等于它的子节点的值,或者堆顶元素没有子节点。
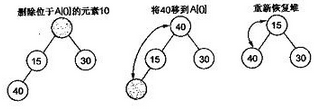
构建堆
- 给定一个数组,将其构建成一个堆。
- 具体步骤:
- 从数组的中间位置开始,依次对每个非叶子节点进行 “下沉” 操作,确保以该节点为根的子树满足堆的性质。
- 重复上述步骤,直到根节点,这样整个数组就被构建成了一个堆。
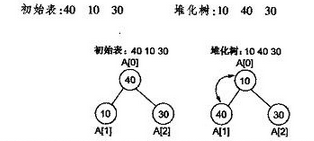
以下为C语言实现一个堆:
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
// 交换两个元素的值
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 上浮操作
void heapify_up(int heap[], int index) {
while (index > 0) {
int parent = (index - 1) / 2;
if (heap[index] >= heap[parent]) {
break;
}
swap(&heap[index], &heap[parent]);
index = parent;
}
}
// 下沉操作
void heapify_down(int heap[], int size, int index) {
while (1) {
int left_child = 2 * index + 1;
int right_child = 2 * index + 2;
int smallest = index;
if (left_child < size && heap[left_child] < heap[smallest]) {
smallest = left_child;
}
if (right_child < size && heap[right_child] < heap[smallest]) {
smallest = right_child;
}
if (smallest == index) {
break;
}
swap(&heap[index], &heap[smallest]);
index = smallest;
}
}
// 插入元素到堆中
void insert(int heap[], int *size, int value) {
if (*size >= MAX_SIZE) {
printf("Heap is full!\n");
return;
}
heap[*size] = value;
(*size)++;
heapify_up(heap, *size - 1);
}
// 删除堆顶元素
int delete_min(int heap[], int *size) {
if (*size <= 0) {
printf("Heap is empty!\n");
return -1;
}
int min = heap[0];
heap[0] = heap[*size - 1];
(*size)--;
heapify_down(heap, *size, 0);
return min;
}
// 构建堆
void build_heap(int heap[], int size) {
for (int i = (size - 2) / 2; i >= 0; i--) {
heapify_down(heap, size, i);
}
}
// 打印堆
void print_heap(int heap[], int size) {
for (int i = 0; i < size; i++) {
printf("%d ", heap[i]);
}
printf("\n");
}
int main() {
int heap[MAX_SIZE];
int size = 0;
// 插入元素
insert(heap, &size, 5);
insert(heap, &size, 3);
insert(heap, &size, 7);
insert(heap, &size, 2);
insert(heap, &size, 4);
printf("Heap after insertions: ");
print_heap(heap, size);
// 删除堆顶元素
int min = delete_min(heap, &size);
printf("Deleted min: %d\n", min);
printf("Heap after deletion: ");
print_heap(heap, size);
// 构建堆
int arr[] = {9, 6, 8, 2, 5, 1};
int arr_size = sizeof(arr) / sizeof(arr[0]);
build_heap(arr, arr_size);
printf("Heap after building: ");
print_heap(arr, arr_size);
return 0;
} (3)堆排序
- 利用堆的性质进行排序,以升序排序为例,可以使用大根堆。
- 具体步骤:
- 首先将待排序的数组构建成一个大根堆。
- 然后将堆顶元素与堆的最后一个元素交换位置,此时堆的最后一个元素就是数组中的最大值,将其从堆中移除。
- 对剩余的元素重新调整为大根堆,重复上述步骤,直到堆中只剩下一个元素,此时数组就已经按照升序排列好了。
#include <stdio.h>
// 交换两个元素
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 堆化操作
void heapify(int arr[], int n, int i) {
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
swap(&arr[i], &arr[largest]);
heapify(arr, n, largest);
}
}
// 堆排序函数
void heapSort(int arr[], int n) {
// 构建最大堆
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
// 一个个交换元素
for (int i = n - 1; i > 0; i--) {
swap(&arr[0], &arr[i]);
heapify(arr, i, 0);
}
}
// 打印数组
void printArray(int arr[], int n) {
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
int main() {
int arr[] = {12, 11, 13, 5, 6, 7};
int n = sizeof(arr) / sizeof(arr[0]);
heapSort(arr, n);
printf("排序后的数组: \n");
printArray(arr, n);
return 0;
} 时间复杂度为O(nlogn)
总的来说,堆排序在事实上的效率与快速排序相差不多。但是堆排序一般优于快速排序的重要一点是数据的初始分布情况对堆排序的效率没有大的影响。
堆排序与快速排序的效率对比
一、堆排序的特性:初始分布不影响效率
堆排序的核心是基于堆结构(大根堆或小根堆)进行元素的选择和交换,其时间复杂度始终为 O(nlogn),原因如下:
1.构建堆的过程:
无论数据初始是有序、逆序还是随机分布,构建堆的时间复杂度均为 O(n)。例如,对于数组[3, 1, 4, 2, 5],构建大根堆的过程需从最后一个非叶子节点开始调整,操作次数仅与数组长度相关,与元素初始顺序无关。2.元素交换过程:
每次将堆顶元素(最大值或最小值)与堆尾元素交换后,重新调整堆的时间复杂度为O(logn)。整个排序过程共需进行n - 1次交换和调整,总时间复杂度固定为 O(nlogn)。
数据初始分布不会改变堆排序每一步操作的模式(始终基于堆结构调整),因此效率稳定。二、快速排序的短板:依赖初始分布
因为快速排序通过选择基准元素将数组划分为两部分,虽然平均时间复杂度为 O(nlogn),但最坏情况下会退化为 O(n^2),具体包括:
1.有序 / 逆序数组:
若选择第一个或最后一个元素作为基准(未优化的快速排序),每次划分会产生一个长度为 n - 1的子数组和一个空数组。例如,对有序数组[1, 2, 3, 4, 5],每次基准均为最小值,递归深度达n层,每层操作次数为 O(n),总时间复杂度退化为 O(n^2)。2.重复元素较多:
若数组包含大量相同元素,未优化的基准选择可能导致划分不均匀,影响效率。
快速排序的效率依赖基准元素的选择和数据分布,极端情况下性能显著下降。这也是为什么,虽然理论二者时间复杂度相同,堆排序仍优于快速排序。
以上就是对于与堆与栈的区别的了解

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)