java 调用sparksql,【开发案例】Spark案例:通过JDBC访问Spark SQL程序
Spark案例:通过JDBC访问Spark SQL程序1.1场景说明适用版本FusionInsight HD V100R002C70、FusionInsight HD V100R002C80。场景说明用户自定义JDBCServer的客户端,使用JDBC连接来进行表的创建、数据加载、查询和删除。数据规划步骤 1确保以多主实例模式启动了JDBCServer服务,并至少有一个实例对外服务。在每个可用的J
Spark案例:通过JDBC访问Spark SQL程序
1.1场景说明
适用版本
FusionInsight HD V100R002C70、FusionInsight HD V100R002C80。
场景说明
用户自定义JDBCServer的客户端,使用JDBC连接来进行表的创建、数据加载、查询和删除。
数据规划
步骤 1确保以多主实例模式启动了JDBCServer服务,并至少有一个实例对外服务。在每个可用的JDBCServer节点上分别创建“/home/data”文件,内容如下:
M***da,32
Karlie,23
Candice,27
步骤 2确保其对启动JDBCServer的用户有读写权限。
步骤 3确保客户端classpath下有“hive-site.xml”文件,且根据实际集群情况配置所需要的参数。JDBCServer相关参数详情,请参见JDBCServer接口介绍。
----结束
1.2开发思路
1.在default数据库下创建child表。
2.把“/home/data”的数据加载进child表中。
3.查询child表中的数据。
4.删除child表。
1.3样例代码说明
1.3.1JAVA代码样例
功能简介
使用自定义客户端的JDBC接口提交数据分析任务,并返回结果。
样例代码
步骤 1定义SQL语句。SQL语句必须为单条语句,注意其中不能包含“;”。示例:
ArrayList sqlList = new
ArrayList();
sqlList.add("CREATE TABLE CHILD (NAME STRING, AGE INT) ROW FORMAT
DELIMITED FIELDS TERMINATED BY ','");
sqlList.add("LOAD DATA LOCAL INPATH '/home/data' INTO TABLE CHILD");
sqlList.add("SELECT * FROM child");
sqlList.add("DROP TABLE child");
executeSql(url, sqlList);

样例工程中的data文件需要放到JDBCServer所在机器的home目录下。
步骤 2拼接JDBC URL。
String securityConfig =
";saslQop=auth-conf;auth=KERBEROS;principal=spark/hadoop.hadoop.com@HADOOP.COM"
+ ";";
Configuration config = new Configuration();
config.addResource(new Path(args[0]));
String zkUrl = config.get("spark.deploy.zookeeper.url");
String zkNamespace = null;
zkNamespace =
fileInfo.getProperty("spark.thriftserver.zookeeper.namespace");
if (zkNamespace != null) {
//从配置项中删除冗余字符
zkNamespace = zkNamespace.substring(1);
}
StringBuilder sb = new StringBuilder("jdbc:hive2://"
+ zkUrl
+
";serviceDiscoveryMode=zooKeeper;zooKeeperNamespace="
+ zkNamespace
+ securityConfig);
String url = sb.toString();

由于KERBEROS认证成功后,默认有效期为1天,超过有效期后,如果客户端需要和JDBCServer新建连接则需要重新认证,否则就会执行失败。因此,若长期执行应用过程中需要新建连接,用户需要在“url”中添加user.principal和user.keytab认证信息,以保证每次建立连接时认证成功,例如,“url”中需要加上“user.principal=sparkuser;user.keytab=/opt/client/user.keytab”。
步骤 3加载Hive JDBC驱动。
Class.forName("org.apache.hive.jdbc.HiveDriver").newInstance();
步骤 4获取JDBC连接,执行HQL,输出查询的列名和结果到控制台,关闭JDBC连接。
连接字符串中的“zk.quorum”也可以使用配置文件中的配置项“spark.deploy.zookeeper.url”来代替。
在网络拥塞的情况下,您还可以设置客户端与JDBCServer连接的超时时间,可以避免客户端由于无限等待服务端的返回而挂起。使用方式如下:
在执行“DriverManager.getConnection”方法获取JDBC连接前,添加“DriverManager.setLoginTimeout(n)”方法来设置超时时长,其中n表示等待服务返回的超时时长,单位为秒,类型为Int,默认为“0”(表示永不超时)。
static void executeSql(String url,
ArrayList sqls) throws ClassNotFoundException, SQLException {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver").newInstance();
} catch (Exception e) {
e.printStackTrace();
}
Connection connection = null;
PreparedStatement statement = null;
try {
connection =
DriverManager.getConnection(url);
for (int i
=0 ; i < sqls.size(); i++) {
String sql = sqls.get(i);
System.out.println("---- Begin executing sql: " + sql + "
----");
statement
= connection.prepareStatement(sql);
ResultSet result = statement.executeQuery();
ResultSetMetaData resultMetaData = result.getMetaData();
Integer colNum = resultMetaData.getColumnCount();
for (int j =1; j <= colNum; j++) {
System.out.println(resultMetaData.getColumnLabel(j) + "\t");
}
System.out.println();
while (result.next()) {
for (int j =1; j <= colNum; j++){
System.out.println(result.getString(j) + "\t");
}
System.out.println();
}
System.out.println("---- Done executing sql: " + sql + "
----");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null !=
statement) {
statement.close();
}
if (null !=
connection) {
connection.close();
}
}
}
----结束
1.3.2Scala代码样例
功能简介
使用自定义客户端的JDBC接口提交数据分析任务,并返回结果。
样例代码
步骤 1定义SQL语句。SQL语句必须为单条语句,注意其中不能包含“;”。示例:
val sqlList = new ArrayBuffer[String]
sqlList += "CREATE TABLE CHILD (NAME STRING, AGE INT) " +
"ROW FORMAT DELIMITED FIELDS TERMINATED BY ','"
sqlList += "LOAD DATA LOCAL INPATH '/home/data' INTO TABLE CHILD"
sqlList += "SELECT * FROM child"
sqlList += "DROP TABLE child"
样例工程中的data文件需要放到JDBCServer所在机器的home目录下。
步骤 2拼接JDBC URL。
val securityConfig: String =
";saslQop=auth-conf;auth=KERBEROS;principal=spark/hadoop.hadoop.com@HADOOP.COM"
+ ";"
val config: Configuration = new Configuration
config.addResource(new Path(args(0)))
val zkUrl: String = config.get("spark.deploy.zookeeper.url")
var zkNamespace: String = null
zkNamespace =
fileInfo.getProperty("spark.thriftserver.zookeeper.namespace")
//从配置项中删除冗余字符
if (zkNamespace != null) zkNamespace =
zkNamespace.substring(1)
val sb = new StringBuilder("jdbc:hive2://"
+ zkUrl
+ ";serviceDiscoveryMode=zooKeeper;zooKeeperNamespace="
+ zkNamespace
+ securityConfig)
val url = sb.toString()
由于KERBEROS认证成功后,默认有效期为1天,超过有效期后,如果客户端需要和JDBCServer新建连接则需要重新认证,否则就会执行失败。因此,若长期执行应用过程中需要新建连接,用户需要在“url”中添加user.principal和user.keytab认证信息,以保证每次建立连接时认证成功,例如,“url”中需要加上“user.principal=sparkuser;user.keytab=/opt/client/user.keytab”。
步骤 3加载Hive JDBC驱动,获取JDBC连接,执行HQL,输出查询的列名和结果到控制台,关闭JDBC连接。
连接字符串中的“zk.quorum”也可以使用配置文件中的配置项“spark.deploy.zookeeper.url”来代替。
在网络拥塞的情况下,您还可以设置客户端与JDBCServer连接的超时时间,可以避免客户端由于无限等待服务端的返回而挂起。使用方式如下:
在执行“DriverManager.getConnection”方法获取JDBC连接前,添加“DriverManager.setLoginTimeout(n)”方法来设置超时时长,其中n表示等待服务返回的超时时长,单位为秒,类型为Int,默认为“0”(表示永不超时)。
def executeSql(url: String, sqls: Array[String]): Unit
= {
//加载Hive JDBC驱动。
Class.forName("org.apache.hive.jdbc.HiveDriver").newInstance()
var connection: Connection = null
var statement: PreparedStatement = null
try {
connection = DriverManager.getConnection(url)
for (sql
println(s"---- Begin executing sql: $sql ----")
statement = connection.prepareStatement(sql)
val result = statement.executeQuery()
val resultMetaData = result.getMetaData
val colNum = resultMetaData.getColumnCount
for (i
print(resultMetaData.getColumnLabel(i) +
"\t")
}
println()
while (result.next()) {
for (i
print(result.getString(i) +
"\t")
}
println()
}
println(s"---- Done executing sql: $sql ----")
}
} finally {
if (null != statement) {
statement.close()
}
if (null != connection) {
connection.close()
}
}
}
----结束
1.4样例代码获取
FusionInsight客户端方式
获取客户端解压文件“FusionInsight_Services_ClientConfig”中“Spark”目录下的“sampleCode”目录下的样例工程:
安全模式:spark-examples-security目录下的“SparkThriftServerJavaExample”、“SparkThriftServerScalaExample”。
非安全模式:spark-examples-normal目录下的“SparkThriftServerJavaExample”、“SparkThriftServerScalaExample”。
Maven工程方式
从华为云代码广场上将代码下载到本地。网址:https://codehub-cnsouth-
1.devcloud.huaweicloud.com/codehub/7076065/home
安全模式:
components/spark/spark-examples-security/SparkThriftServerJavaExample
components/spark/spark-examples-security/SparkThriftServerScalaExample
·非安全模式:
components/spark/spark-examples-normal/SparkThriftServerJavaExample
components/spark/spark-examples-normal/SparkThriftServerScalaExample
1.5调测程序
1.5.1编包并运行程序
操作场景
在程序代码完成开发后,您可以上传至Linux客户端环境中运行应用。使用Scala或Java语言开发的应用程序在Spark客户端的运行步骤是一样的。
lSpark应用程序只支持在Linux环境下运行,不支持在Windows环境下运行。
l使用Python开发的Spark应用程序无需打包成jar,只需将样例工程拷贝到编译机器上即可。
l用户需保证worker和driver的Python版本一致,否则将报错:"Python in worker has different version %s
than that in driver %s."。
操作步骤
步骤 1在IntelliJ IDEA中,在生成Jar包之前配置工程的Artifacts信息。
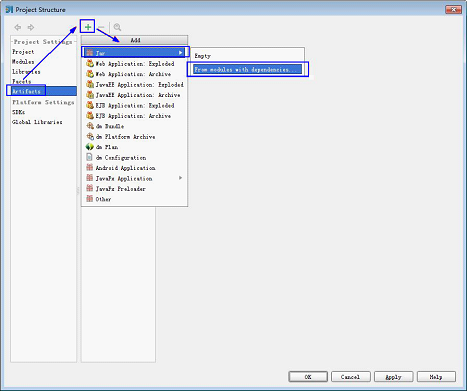
1.在IDEA主页面,选择“File > Project Structures...”进入“Project Structure”页面。
2.在“Project Structure”页面,选择“Artifacts”,单击“+”并选择“Jar
> From modules with dependencies...”。
图1-1 添加Artifacts
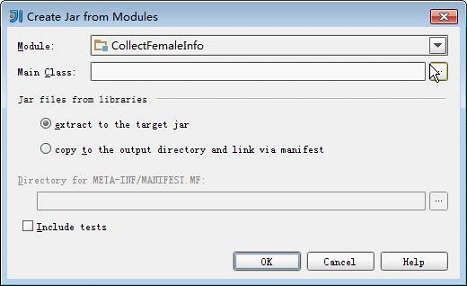
3.选择对应的Module,Java样例工程中对应的Module为CollectFemaleInfo,单击“OK”。
图1-2 Create
Jar from Modules
4.您可以根据实际情况设置Jar包的名称、类型以及输出路径。
图1-3 设置基本信息
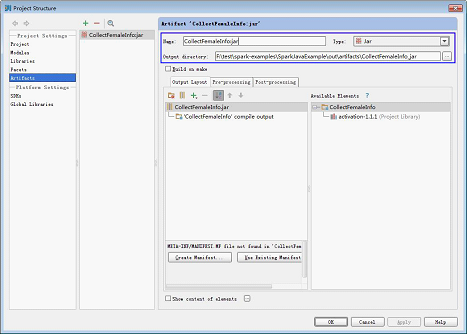
5.选中“CollectFemaleInfo”,右键选择“Put into Output Root”。然后单击“Apply”。
图1-4 Put
into Output Root
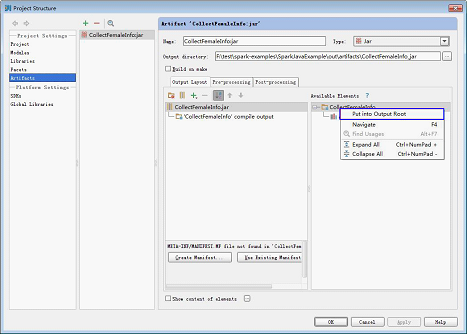
6.最后单击“OK”完成配置。
步骤 2生成Jar包。
1.在IDEA主页面,选择“Build > Build Artifacts...”。
图1-5 Build
Artifacts
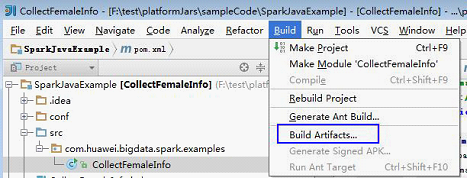
2.在弹出的菜单中,选择“CollectFemaleInfo
> Build”开始生成Jar包。
图1-6 Build
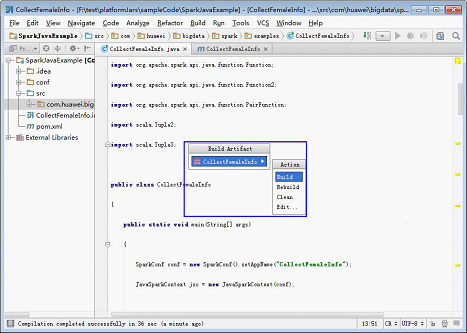
3.当Event log中出现如下类似日志时,表示Jar包生成成功。您可以从步骤1.4中配置的路径下获取到Jar包。
21:25:43 Compilation completed successfully in 36 sec
步骤 3将步骤2中生成的Jar包(如CollectFemaleInfo.jar)拷贝到Spark运行环境下(即Spark客户端),如“/opt/hadoopcliet/Spark”。运行Spark应用程序。

在Spark任务运行过程中禁止重启HDFS服务或者重启所有DataNode实例,否则可能会导致任务失败,并可能导致JobHistory部分数据丢失。
l运行Spark Core(Scala和Java)样例程序。
进入Spark客户端目录,调用bin/spark-submit脚本运行代码。
其中,指HDFS文件系统中input的路径。
bin/spark-submit --class com.huawei.bigdata.spark.examples.FemaleInfoCollection
--master yarn-client /opt/female/FemaleInfoCollection.jar
l运行Spark SQL样例程序(Scala和Java语言)。
进入Spark客户端目录,调用bin/spark-submit脚本运行代码。
其中,指HDFS文件系统中input的路径。
bin/spark-submit --class com.huawei.bigdata.spark.examples.FemaleInfoCollection
--master yarn-client /opt/female/FemaleInfoCollection.jar
l运行Spark Streaming样例程序(Scala和Java语言)。
进入Spark客户端目录,调用bin/spark-submit脚本运行代码。
由于Spark
Streaming Kafka的依赖包在客户端的存放路径与其他依赖包不同,如其他依赖包路径为“$SPARK_HOME/lib”,而Spark Streaming Kafka依赖包路径为“$SPARK_HOME/lib/streamingClient”。所以在运行应用程序时,需要在spark-submit命令中添加配置项,指定Spark Streaming
Kafka的依赖包路径,如--jars
$SPARK_HOME/lib/streamingClient/kafka-clients-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/kafka_2.10-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/spark-streaming-kafka_2.10-1.5.1.jar。
Spark Streaming Write To Print代码样例
bin/spark-submit --master yarn-client --jars
$SPARK_HOME/lib/streamingClient/kafka-clients-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/kafka_2.10-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/spark-streaming-kafka_2.10-1.5.1.jar
--class com.huawei.bigdata.spark.examples.FemaleInfoCollectionPrint
/opt/female/FemaleInfoCollectionPrint.jar
Spark Streaming Write To Kafka代码样例
bin/spark-submit --master yarn-client --jars
$SPARK_HOME/lib/streamingClient/kafka-clients-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/kafka_2.10-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/spark-streaming-kafka_2.10-1.5.1.jar
--class com.huawei.bigdata.spark.examples.FemaleInfoCollectionKafka
/opt/female/FemaleInfoCollectionKafka.jar
l运行“通过JDBC访问Spark SQL”样例程序(Scala和Java语言)。
进入Spark客户端目录,使用java -cp命令运行代码。
java -cp $SPARK_HOME/lib/*:$SPARK_HOME/conf:/opt/female/ThriftServerQueriesTest.jar
com.huawei.bigdata.spark.examples.ThriftServerQueriesTest
$SPARK_HOME/conf/hive-site.xml $SPARK_HOME/conf/spark-defaults.conf
上面的命令行中,您可以根据不同样例工程,最小化选择其对应的运行依赖包。样例工程对应的运行依赖包详情,请参见参考信息。
l运行“Spark on HBase”样例程序(Scala和Java语言)。
a.检查查Spark客户端的“spark-defaults.conf”配置文件中的配置项是否配置正确。
若运行“Spark
on HBase”样例程序,需要在Spark客户端的“spark-defaults.conf”配置文件中将配置项“spark.hbase.obtainToken.enabled”设置为“true”(该参数值默认为“false”,改为“true”后对已有业务没有影响。如果要卸载HBase服务,卸载前请将此参数值改回“false”),将配置项“spark.inputFormat.cache.enabled”设置为“false”。
表1-1 参数说明
参数
描述
默认值spark.hbase.obtainToken.enabled
是否打开获取HBase
token的功能。
false
spark.inputFormat.cache.enabled
是否缓存HadoopRDD对应的InputFormat。若设置为“true”,表示同一个Executor的task使用同一个InputFormat对象,此时InputFormat类型需要是线程安全的;否则需要设置为“false”。
true
b.进入Spark客户端目录,调用bin/spark-submit脚本运行代码。运行样例程序时,程序运行顺序为:TableCreation、TableInputData、TableOutputData。
其中,在运行TableInputData样例程序时需要指定,指HDFS文件系统中input的路径。
bin/spark-submit --class com.huawei.bigdata.spark.examples.TableInputData
--master yarn-client /opt/female/TableInputData.jar
l运行Spark HBase to
HBase样例程序(Scala和Java语言)。
进入Spark客户端目录,调用bin/spark-submit脚本运行代码。
bin/spark-submit --class com.huawei.bigdata.spark.examples.SparkHbasetoHbase
--master yarn-client /opt/female/FemaleInfoCollection.jar
l运行Spark Hive to
HBase样例程序(Scala和Java语言)。
进入Spark客户端目录,调用bin/spark-submit脚本运行代码。
bin/spark-submit --class com.huawei.bigdata.spark.examples.SparkHivetoHbase
--master yarn-client /opt/female/FemaleInfoCollection.jar
l运行Spark Streaming
Kafka to HBase样例程序(Scala和Java语言)。
进入Spark客户端目录,调用bin/spark-submit脚本运行代码。
在运行样例程序时需要指定,其中指应用程序结果备份到HDFS的路径,指读取Kafka上的topic名称,指Kafka服务器IP地址。
由于Spark
Streaming Kafka的依赖包在客户端的存放路径与其他依赖包不同,如其他依赖包路径为“$SPARK_HOME/lib”,而Spark Streaming Kafka依赖包路径为“$SPARK_HOME/lib/streamingClient”。所以在运行应用程序时,需要在spark-submit命令中添加配置项,指定Spark Streaming
Kafka的依赖包路径,如--jars
$SPARK_HOME/lib/streamingClient/kafka-clients-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/kafka_2.10-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/spark-streaming-kafka_2.10-1.5.1.jar。
Spark Streaming To HBase代码样例
bin/spark-submit --master yarn-client --jars
$SPARK_HOME/lib/streamingClient/kafka-clients-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/kafka_2.10-0.8.2.1.jar,$SPARK_HOME/lib/streamingClient/spark-streaming-kafka_2.10-1.5.1.jar
--class com.huawei.bigdata.spark.examples.streaming.SparkOnStreamingToHbase
/opt/female/FemaleInfoCollectionPrint.jar
l提交Python语言开发的应用程序。
进入Spark客户端目录,调用bin/spark-submit脚本运行代码。
其中,指HDFS文件系统中input的路径。
由于样例代码中未给出认证信息,请在执行应用程序时通过配置项“spark.yarn.keytab”和“spark.yarn.principal”指定认证信息。
bin/spark-submit --master yarn-client --conf
spark.yarn.keytab=/opt/FIclient/user.keytab --conf
spark.yarn.principal=sparkuser /opt/female/SparkPythonExample/collectFemaleInfo.py
----结束
参考信息
“通过JDBC访问Spark SQL”样例程序(Scala和Java语言),其对应的运行依赖包如下:
l通过JDBC访问Spark SQL样例工程(Scala)
−avro-1.7.7.jar
−commons-collections-3.2.2.jar
−commons-configuration-1.6.jar
−commons-io-2.4.jar
−commons-lang-2.6.jar
−commons-logging-1.1.3.jar
−guava-12.0.1.jar
−hadoop-auth-2.7.2.jar
−hadoop-common-2.7.2.jar
−hadoop-mapreduce-client-core-2.7.2.jar
−hive-exec-1.2.1.spark.jar
−hive-jdbc-1.2.1.spark.jar
−hive-metastore-1.2.1.spark.jar
−hive-service-1.2.1.spark.jar
−httpclient-4.5.2.jar
−httpcore-4.4.4.jar
−libthrift-0.9.3.jar
−log4j-1.2.17.jar
−slf4j-api-1.7.10.jar
−zookeeper-3.5.1.jar
−scala-library-2.10.4.jar
l通过JDBC访问Spark SQL样例工程(Java)
−commons-collections-3.2.2.jar
−commons-configuration-1.6.jar
−commons-io-2.4.jar
−commons-lang-2.6.jar
−commons-logging-1.1.3.jar
−guava-12.0.1.jar
−hadoop-auth-2.7.2.jar
−hadoop-common-2.7.2.jar
−hadoop-mapreduce-client-core-2.7.2.jar
−hive-exec-1.2.1.spark.jar
−hive-jdbc-1.2.1.spark.jar
−hive-metastore-1.2.1.spark.jar
−hive-service-1.2.1.spark.jar
−httpclient-4.5.2.jar
−httpcore-4.4.4.jar
−libthrift-0.9.3.jar
−log4j-1.2.17.jar
−slf4j-api-1.7.10.jar
−zookeeper-3.5.1.jar
1.5.2查看调测结果
操作场景
Spark应用程序运行完成后,,可通过如下方式查看应用程序的运行情况。
l通过运行结果数据查看应用程序运行情况。
l登录Spark WebUI查看应用程序运行情况。
l通过Spark日志获取应用程序运行情况。
操作步骤
l查看Spark应用运行结果数据。
结果数据存储路径和格式已经由Spark应用程序指定,可通过指定文件获取。
l查看Spark应用程序运行情况。
Spark主要有两个Web页面。
−Spark UI页面,用于展示正在执行的应用的运行情况。
页面主要包括了Jobs、Stages、Storage、Environment和Executors五个部分。Spark Streaming应用会多一个Streaming标签页。
页面入口:在YARN的Web UI界面,查找到对应的Spark应用程序。单击应用信息的最后一列“ApplicationMaster”,即可进入SparkUI页面。
−History Server页面,用于展示已经完成的和未完成的Spark应用的运行情况。
页面包括了应用ID、应用名称、开始时间、结束时间、执行时间、所属用户等信息。单击应用ID,页面将跳转到该应用的SparkUI页面。
l查看Spark日志获取应用运行情况。
您可以查看Spark日志了解应用运行情况,并根据日志信息调整应用程序。相关日志信息可参考《管理员指南》中“日志介绍”章节Spark相关内容。
本帖最后由 lWX387225 于 2018-06-29 15:11 编辑

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)