YOLO11数据标注实战:LabelImg
上一篇已经将模型训练的粗略全过程输出,现在回过头来看,数据训练前期需要准备训练数据怎么来的。前提:已经安装完成conda环境,并切换激活至某一个环境下面。在网络找一批图片,用次本次训练的精准图片,保存一个统一的文件夹下面,方便用labelimg进行数据标注。
上一篇已经将模型训练的粗略全过程输出,现在回过头来看,数据训练前期需要准备训练数据怎么来的。
前提:已经安装完成conda环境,并切换激活至某一个环境下面。
在网络找一批图片,用次本次训练的精准图片,保存一个统一的文件夹下面,方便用labelimg进行数据标注。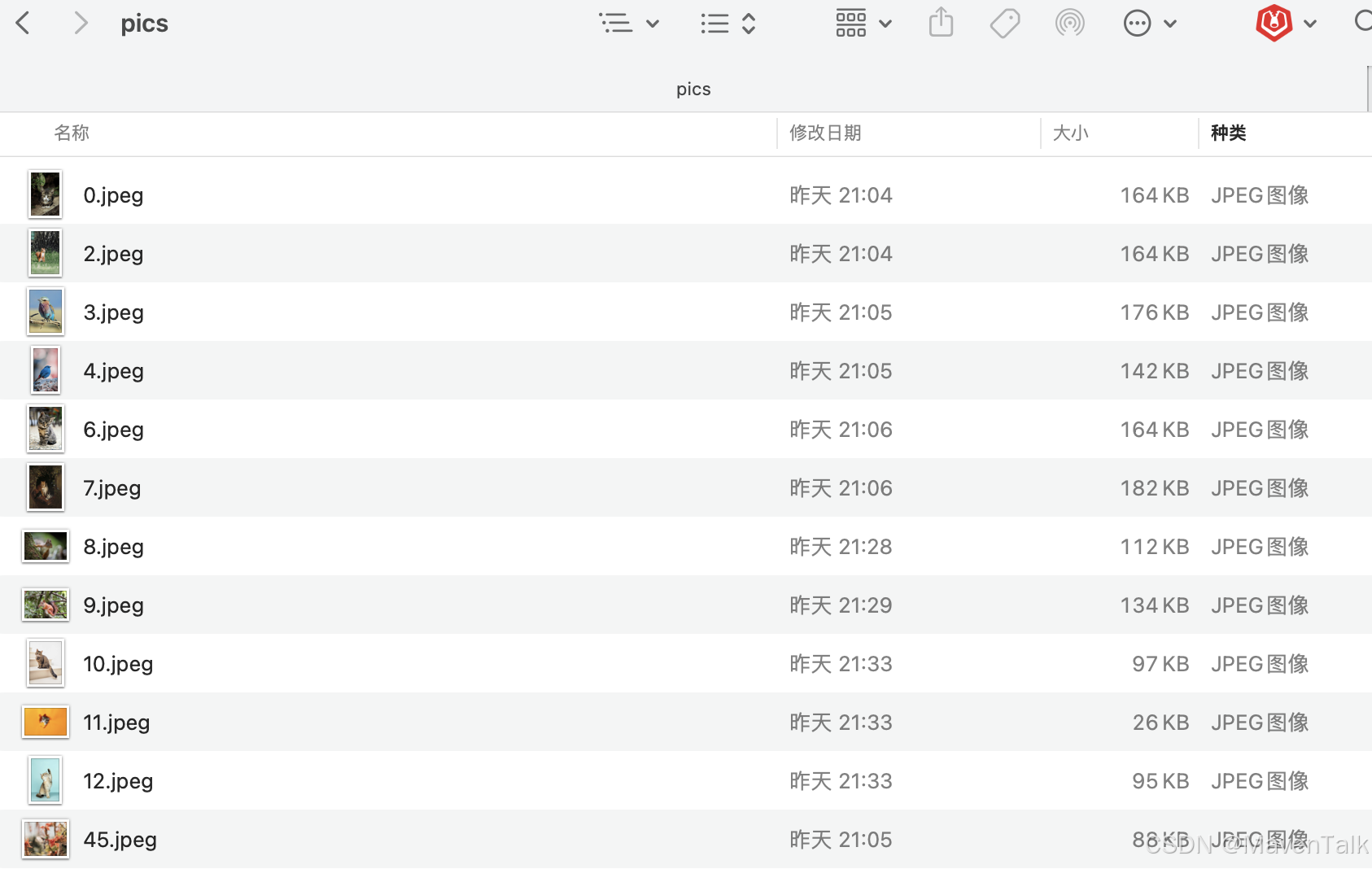
安装LabelImg
pip install labelimg
运行LabelImg
labelimg
选种刚才的目录,按照里面的操作指南,开始标注数据,俗称“拉框”。
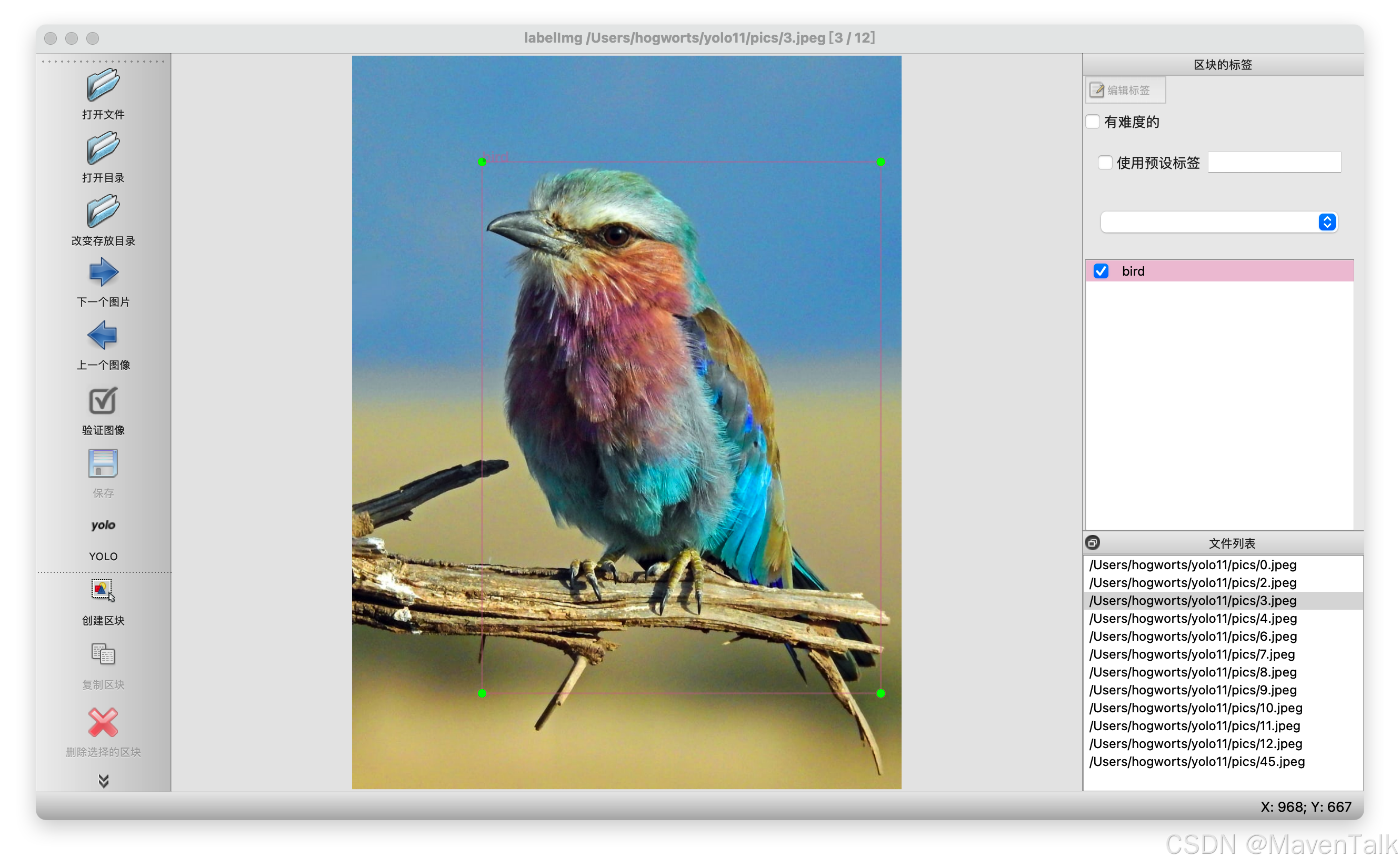
全部标注完成后,可以看到文件夹里的内容发生了变化,每个图片后面跟了一个同名的.txt文件。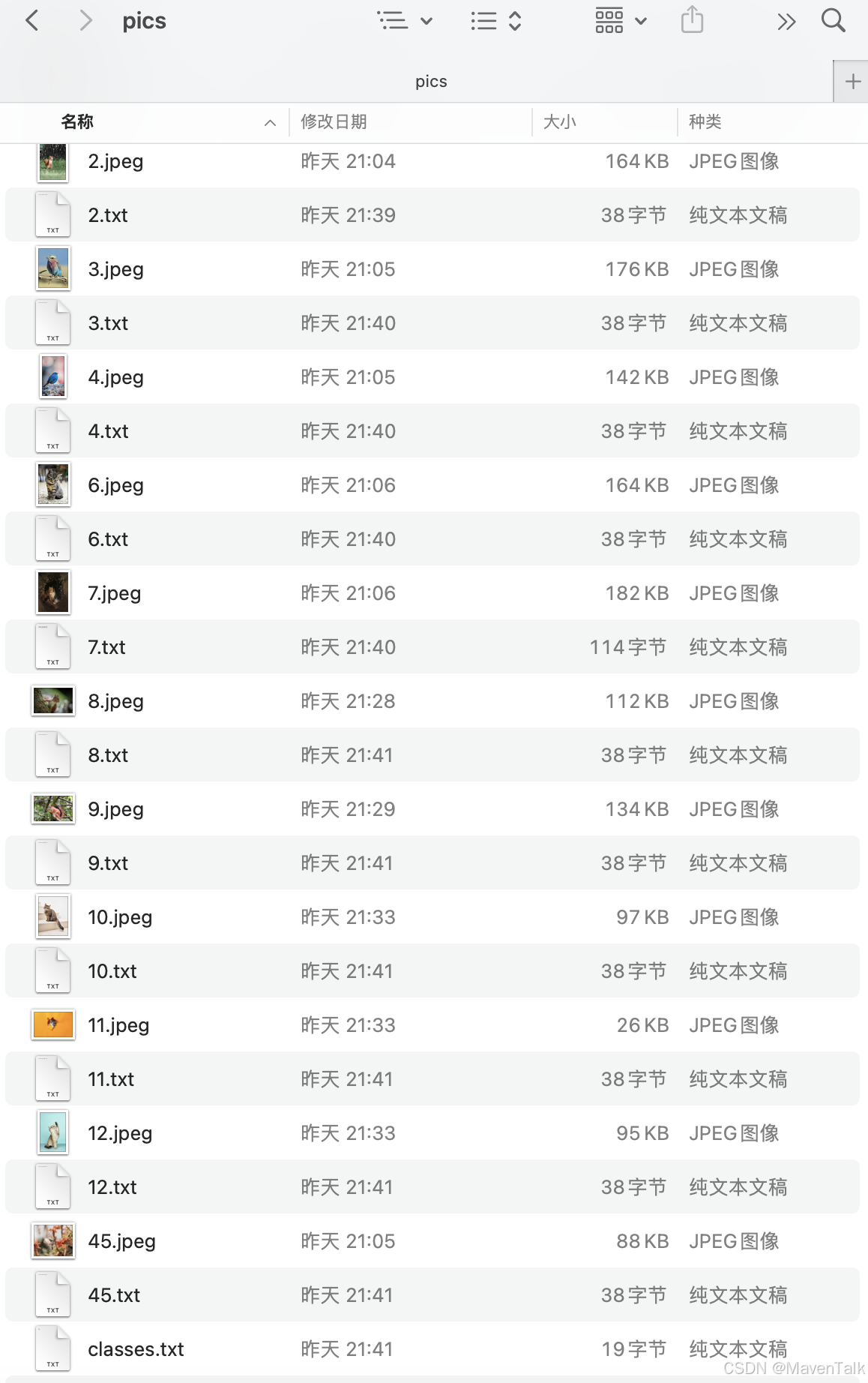
txt文件内容如下:
0 0.529444 0.527917 0.712222 0.712500
classes.txt内容如下:
cat
sequirrel
bird
这只是一个演示文件,真实的数据训练数据集要比这个大很多,比如成千上万张,才能保证模型的训练效果。
准备训练数据集与验证集

验证集的重要性
为什么需要验证集?
-
防止过拟合:监控模型在未见过的数据上的表现
-
调参依据:根据验证集性能调整超参数
-
早停判断:当验证集性能不再提升时停止训练
-
模型选择:选择在验证集上表现最好的模型
实际建议
-
数据量较少时(<100张):使用 80% 训练,20% 验证
-
数据量中等时(100-1000张):使用 70-80% 训练,20-30% 验证
-
数据量充足时(>1000张):使用 90% 训练,10% 验证
重要提醒:确保验证集中包含所有类别的样本,特别是对于不常见的类别,要保证验证集中至少有几个样本。
如何划分数据集与验证集呢
两者所需要数据结构是一样的,也就是都是标注的数据,这就需要我们按照一定的比例,划分为两个数据集。对于成千上万个标注后的数据,只能通过代码快速划分一条路了。
相关代码如下:
import os
import random
import shutil
def split_dataset(image_dir, label_dir, train_ratio=0.8):
"""
拆分数据集为训练集和验证集
"""
# 获取所有图片文件
image_files = [f for f in os.listdir(image_dir) if f.endswith(('.jpg', '.png', '.jpeg'))]
random.shuffle(image_files) # 随机打乱
# 计算分割点
split_point = int(len(image_files) * train_ratio)
train_files = image_files[:split_point]
val_files = image_files[split_point:]
# 创建目录
os.makedirs('images/train', exist_ok=True)
os.makedirs('images/val', exist_ok=True)
os.makedirs('labels/train', exist_ok=True)
os.makedirs('labels/val', exist_ok=True)
# 移动训练集文件
for file in train_files:
# 移动图片
shutil.copy2(os.path.join(image_dir, file), 'images/train/')
# 移动对应的标签文件
label_file = os.path.splitext(file)[0] + '.txt'
if os.path.exists(os.path.join(label_dir, label_file)):
shutil.copy2(os.path.join(label_dir, label_file), 'labels/train/')
# 移动验证集文件
for file in val_files:
# 移动图片
shutil.copy2(os.path.join(image_dir, file), 'images/val/')
# 移动对应的标签文件
label_file = os.path.splitext(file)[0] + '.txt'
if os.path.exists(os.path.join(label_dir, label_file)):
shutil.copy2(os.path.join(label_dir, label_file), 'labels/val/')
print(f"数据集拆分完成!")
print(f"训练集: {len(train_files)} 张图片")
print(f"验证集: {len(val_files)} 张图片")
# 使用示例
if __name__ == "__main__":
# 假设你的原始数据都在这些目录中
image_dir = "all_images" # 所有图片的目录
label_dir = "all_labels" # 所有标签的目录
split_dataset(image_dir, label_dir, train_ratio=0.8)
还一种更专业的使用sklearn来划分数据:
from sklearn.model_selection import train_test_split
import os
import shutil
def split_dataset_sklearn(image_dir, label_dir, test_size=0.2):
"""
使用sklearn进行数据集拆分
"""
# 获取所有图片文件(不含扩展名)
base_names = []
for f in os.listdir(image_dir):
if f.endswith(('.jpg', '.png', '.jpeg')):
base_names.append(os.path.splitext(f)[0])
# 拆分训练集和验证集
train_names, val_names = train_test_split(base_names, test_size=test_size, random_state=42)
# 创建目录
os.makedirs('images/train', exist_ok=True)
os.makedirs('images/val', exist_ok=True)
os.makedirs('labels/train', exist_ok=True)
os.makedirs('labels/val', exist_ok=True)
# 复制文件
for name in train_names:
# 复制图片
for ext in ['.jpg', '.png', '.jpeg']:
img_src = os.path.join(image_dir, name + ext)
if os.path.exists(img_src):
shutil.copy2(img_src, 'images/train/')
break
# 复制标签
label_src = os.path.join(label_dir, name + '.txt')
if os.path.exists(label_src):
shutil.copy2(label_src, 'labels/train/')
for name in val_names:
# 复制图片
for ext in ['.jpg', '.png', '.jpeg']:
img_src = os.path.join(image_dir, name + ext)
if os.path.exists(img_src):
shutil.copy2(img_src, 'images/val/')
break
# 复制标签
label_src = os.path.join(label_dir, name + '.txt')
if os.path.exists(label_src):
shutil.copy2(label_src, 'labels/val/')
print(f"训练集: {len(train_names)} 张图片")
print(f"验证集: {len(val_names)} 张图片")
# 安装sklearn: pip install scikit-learn
训练数据集的文件结构
my_dataset/
├── images/
│ ├── train/ # 训练图片 (70-80%)
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ └── val/ # 验证图片 (20-30%)
│ ├── image101.jpg
│ ├── image102.jpg
│ └── ...
└── labels/
├── train/ # 训练标签
│ ├── image1.txt
│ ├── image2.txt
│ └── ...
└── val/ # 验证标签
├── image101.txt
├── image102.txt
└── ...

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)