VLA-视觉语言动作模型
应用领域多样,如仿人机器人、自动驾驶汽车、医疗和工业机器人、精准农业、增强现实导航等。主要挑战涉及实时控制、多模态动作表示、系统可扩展性、对未知任务的泛化以及道德部署风险等。视觉 - 语言 - 动作(VLA)模型是人工智能领域的变革性进展,致力于将感知、自然语言理解和实体动作统一于一个计算框架。VLA模型最新综述!近80多个VLA 模型,涉及架构、训练,实时推理等。
·
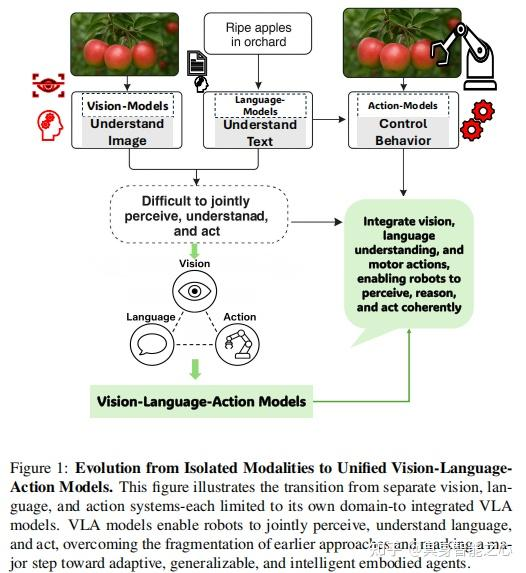
视觉 - 语言 - 动作(VLA)模型是人工智能领域的变革性进展,致力于将感知、自然语言理解和实体动作统一于一个计算框架。
应用领域多样,如仿人机器人、自动驾驶汽车、医疗和工业机器人、精准农业、增强现实导航等。主要挑战涉及实时控制、多模态动作表示、系统可扩展性、对未知任务的泛化以及道德部署风险等。
reference
---
VLA模型最新综述!近80多个VLA 模型,涉及架构、训练,实时推理等

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)