【Hadoop+Spark】基于Python大数据的唯品会商品数据分析可视化系统 电商用户行为分析系统 商品销量数据分析大屏
本文介绍了基于Python和大数据技术的唯品会商品数据分析可视化系统。系统采用Hadoop+Spark架构处理海量数据,结合Python+Django开发后端服务,使用Echarts实现前端可视化展示。主要功能包括品类销售分析(价格区间分布、折扣对比)、品牌定位分析(价格分布、跨品类分布)和促销活动效果分析(活动分布、折扣影响)等。通过多维度可视化图表,为电商运营提供数据支持。系统实现了从数据采集
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于Python+大数据的唯品会商品数据分析可视化系统 电商用户行为分析系统 商品销量数据分析大屏的功能,
唯品会商品数据分析可视化系统-系统前言简介
- 随着移动互联网和数字经济的深度融合,电子商务平台产生的数据量呈指数级增长,唯品会等特卖电商每日处理数百万笔交易记录和用户行为轨迹。然而现有的数据分析工具在面对海量、多维度、异构化的电商数据时存在处理效率低下、分析深度不足、可视化效果单一等问题,难以为运营决策提供及时准确的数据支撑。传统的静态报表无法动态展现商品销售趋势、用户消费行为模式以及市场变化规律,严重制约了电商平台的精细化运营和智能化决策能力。
- 本课题构建了基于大数据技术的唯品会商品数据分析可视化系统,采用Hadoop分布式存储架构和Spark实时计算引擎处理TB级商品数据,运用Python和Django框架开发后端服务,结合HTML和Echarts技术实现前端交互式数据展示。系统围绕品类分析、价格与折扣分析、品牌分析、促销活动分析四大功能模块,通过价格区间分布图、折扣策略对比、品牌定位热力图、促销效果关联分析等多维度可视化图表,深度挖掘商品销售规律和消费者行为特征。
- 该系统的建设为电商平台提供了科学的数据分析工具和决策支持平台,显著提升了商品运营效率和营销策略的精准度,推动了传统电商向数据驱动型智能商务模式的转型升级。研究成果对于电子商务行业的数据化运营具有重要的理论价值和实践指导意义,为类似电商平台的大数据应用提供了可借鉴的技术方案和实施经验。
唯品会商品数据分析可视化系统-开发技术与环境
- 亮点(大数据分析:hadoop+spark+hive、词云图)
- 开发技术:Python、Django框架、HTML、Echarts
- 大数据技术:hadoop、spark、hive
- 软件工具:Pycharm
- 数据库:MySQL
唯品会商品数据分析可视化系统-功能介绍
可视化统计信息(品类分析、价格与折扣分析、品牌分析、促销活动分析)
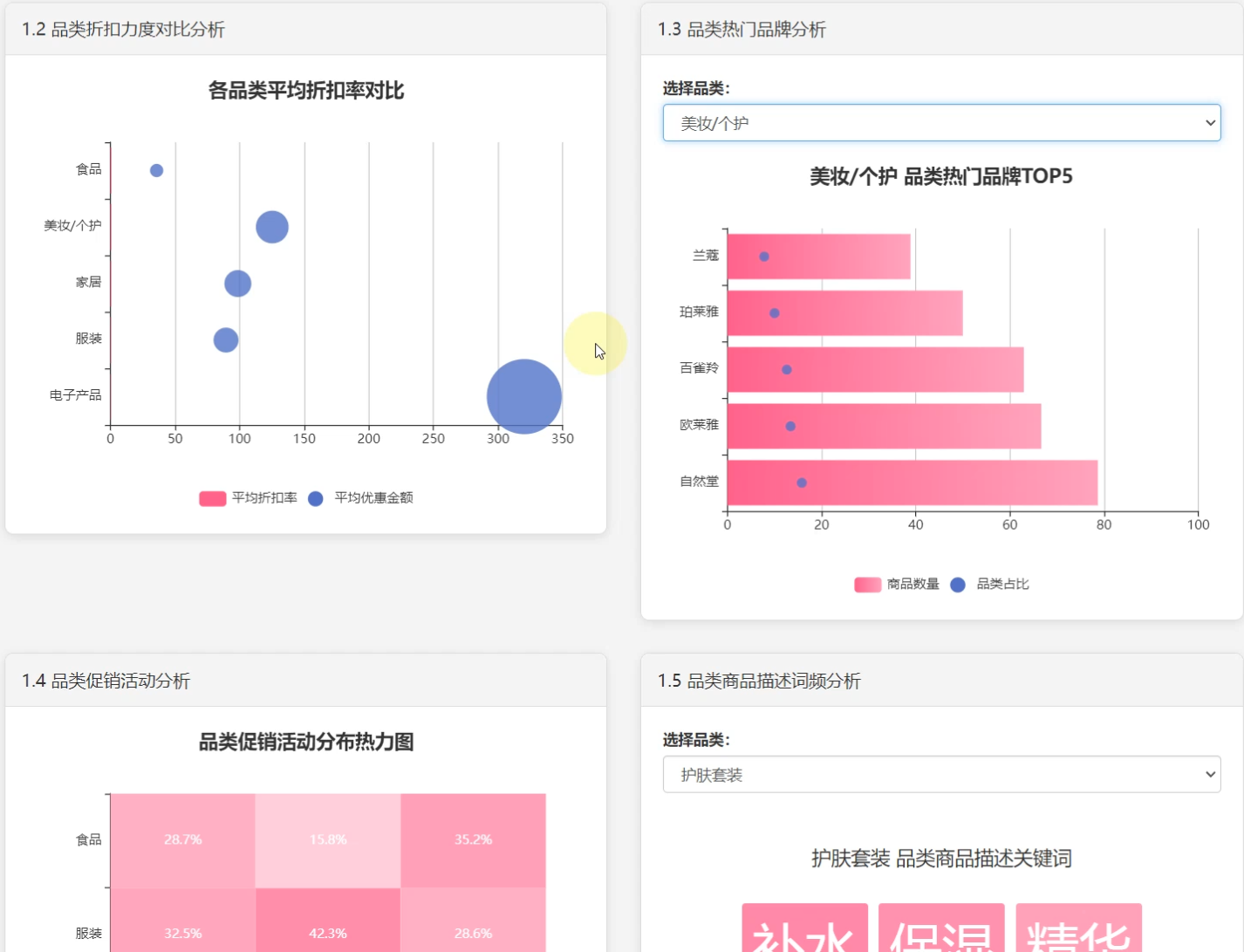
1、品类分析: 各品类价格区间分布、各品类折扣对比、热门品牌top5、活动分布热力图、商品描述词云图
2、价格与折扣分析: 商品价格区间分布、折扣与原价关系分析、商品特征分析、标签与折扣关系
3、品牌分析: 品牌价格定位分析、品牌折扣策略、品牌跨品类分布、品牌促销活动偏好分析
4、促销活动分析:促销类型分析、活动与商品价格关系分析、活动对折扣影响分析、热门促销标签组合。
唯品会商品数据分析可视化系统-视频演示
【Hadoop+Spark】基于Python大数据的唯品会商品数据分析可视化系统 电商用户行为分析系统 商品销量数据分析大屏
唯品会商品数据分析可视化系统-演示图片
☀️1.1品类销售价格分布分析☀️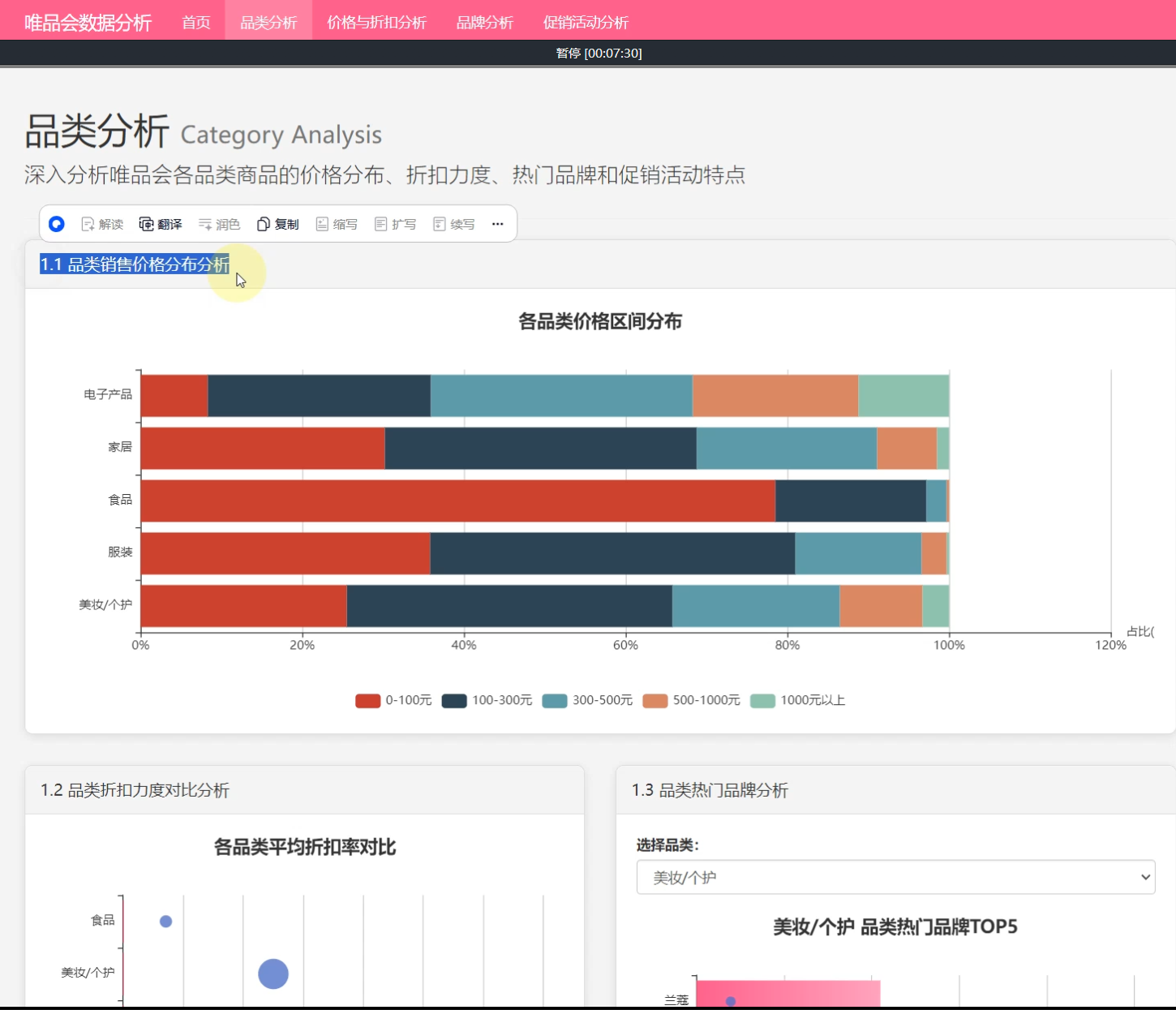
☀️1.2各品类折扣对比散点图☀️
☀️2.1价格与折扣区间价格分布☀️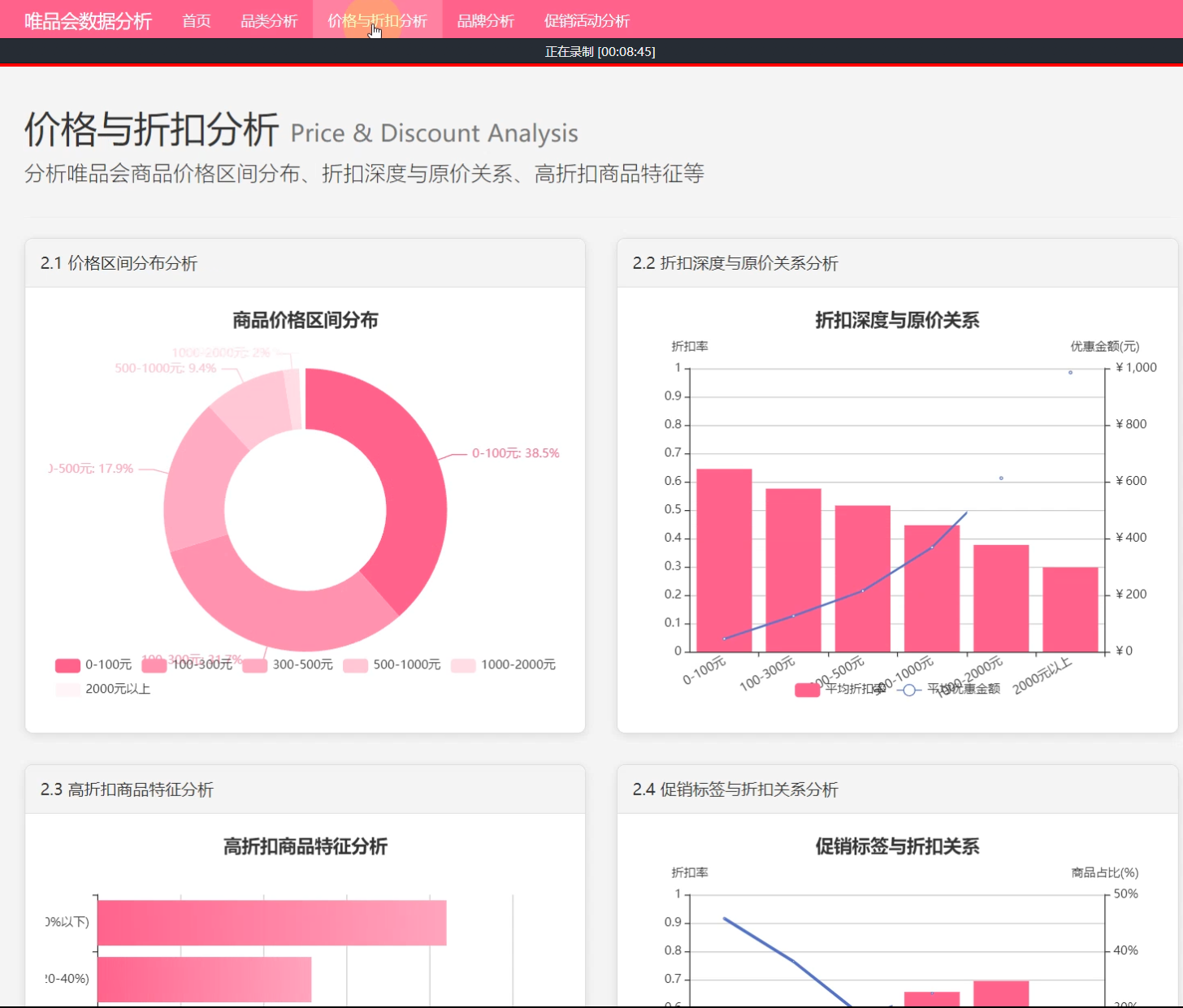
☀️2.2高折扣商品特征分析☀️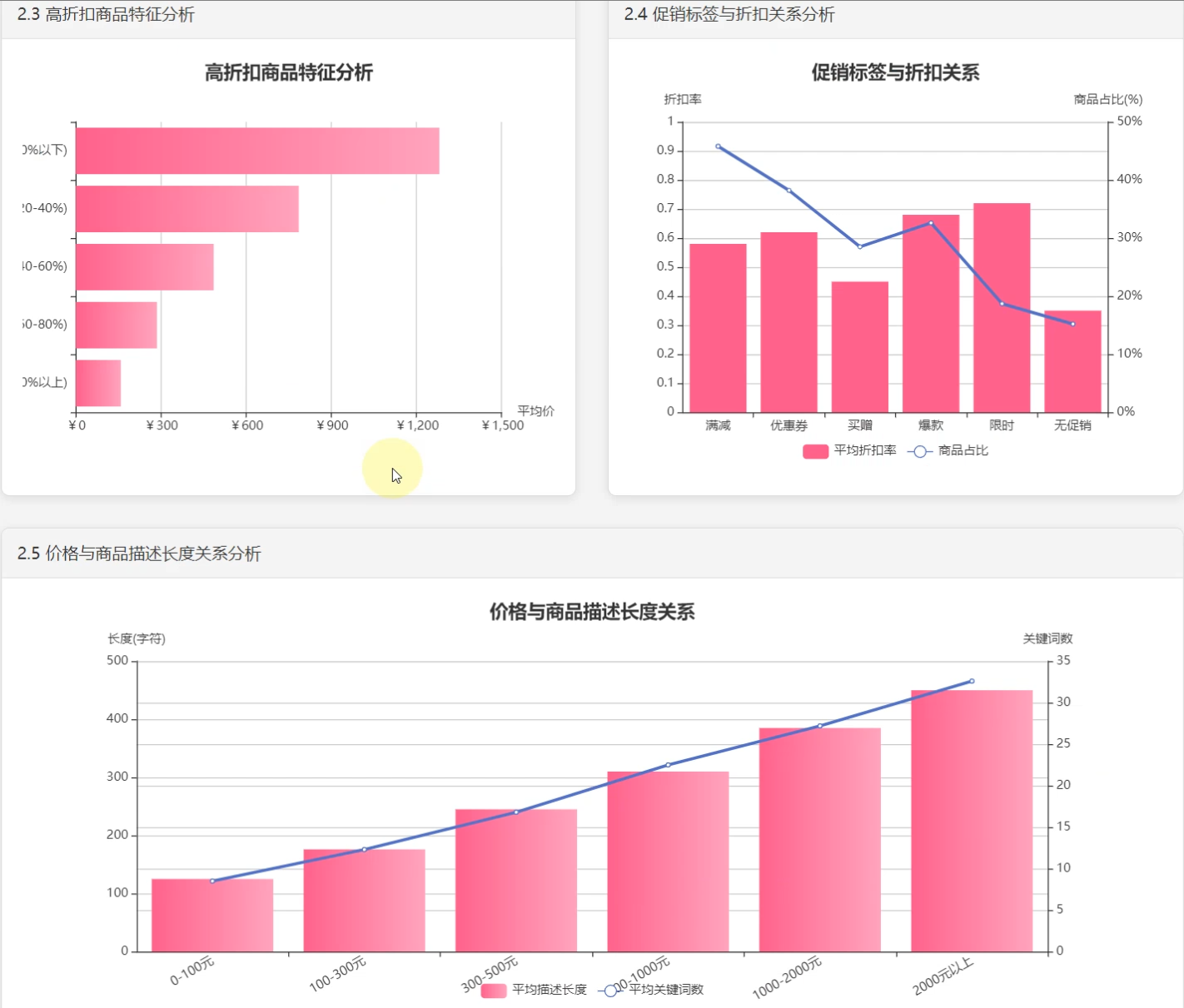
☀️3.1品牌价格分析☀️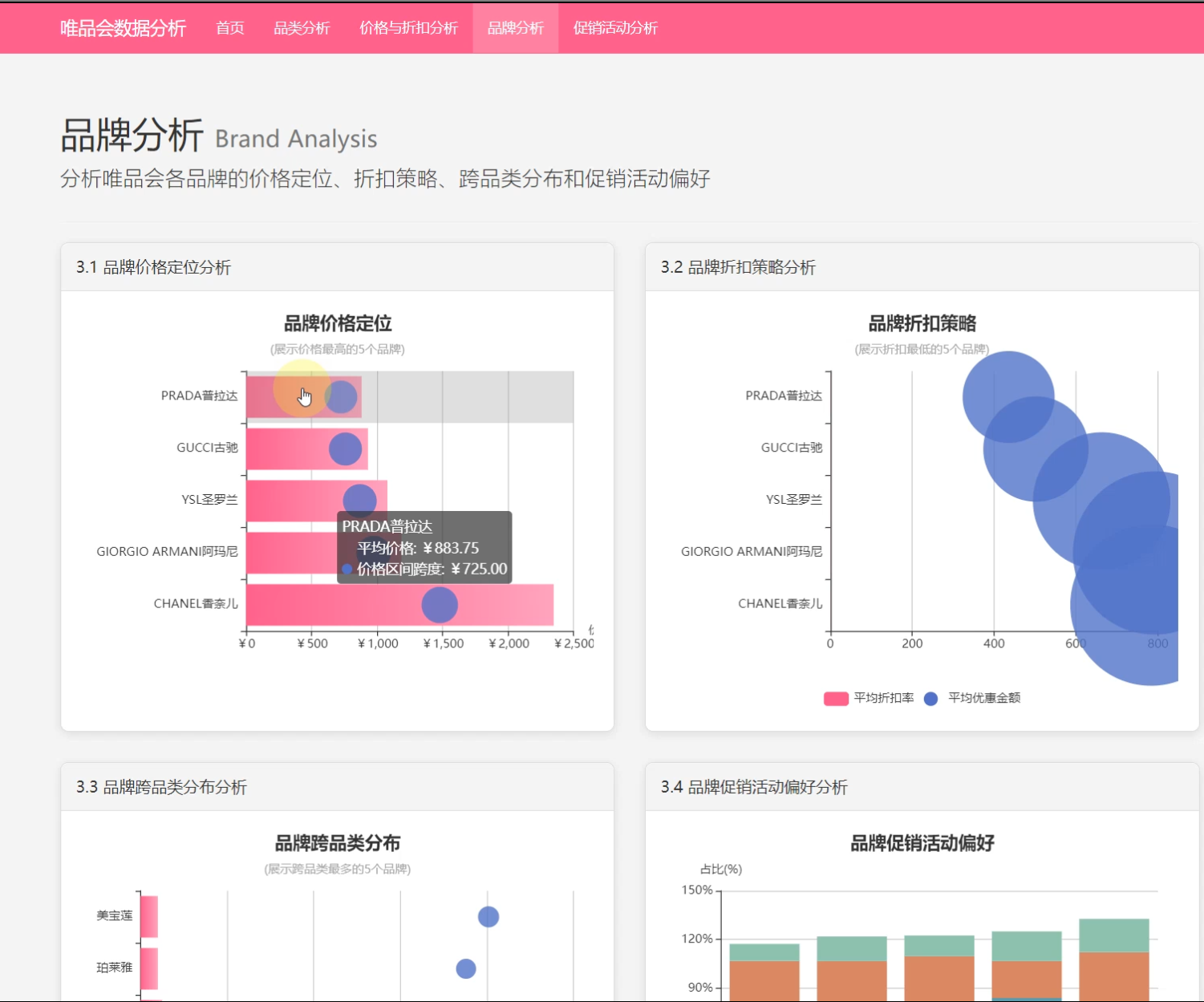
☀️3.2品牌跨品类分析☀️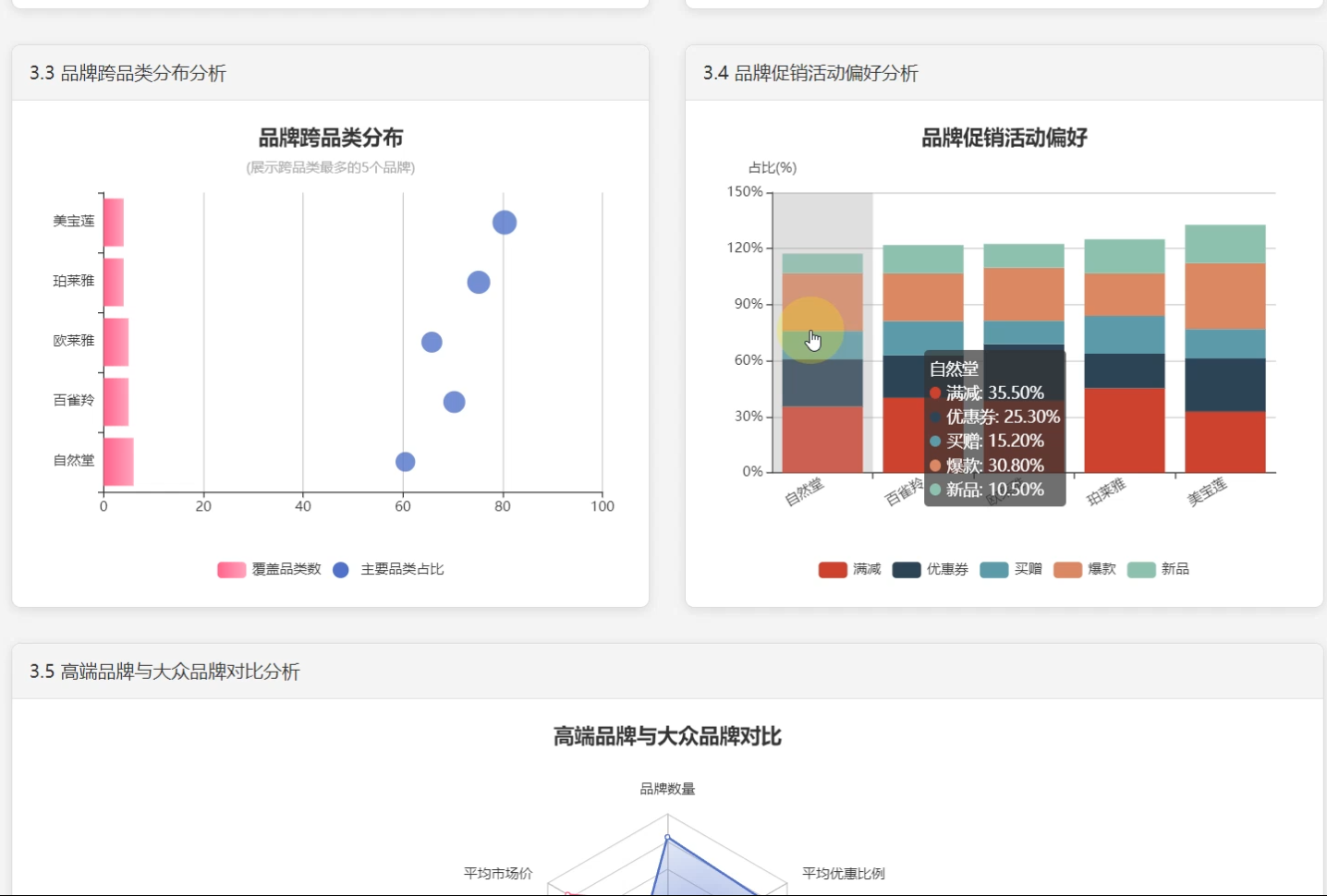
☀️4.1促销活动分布分析☀️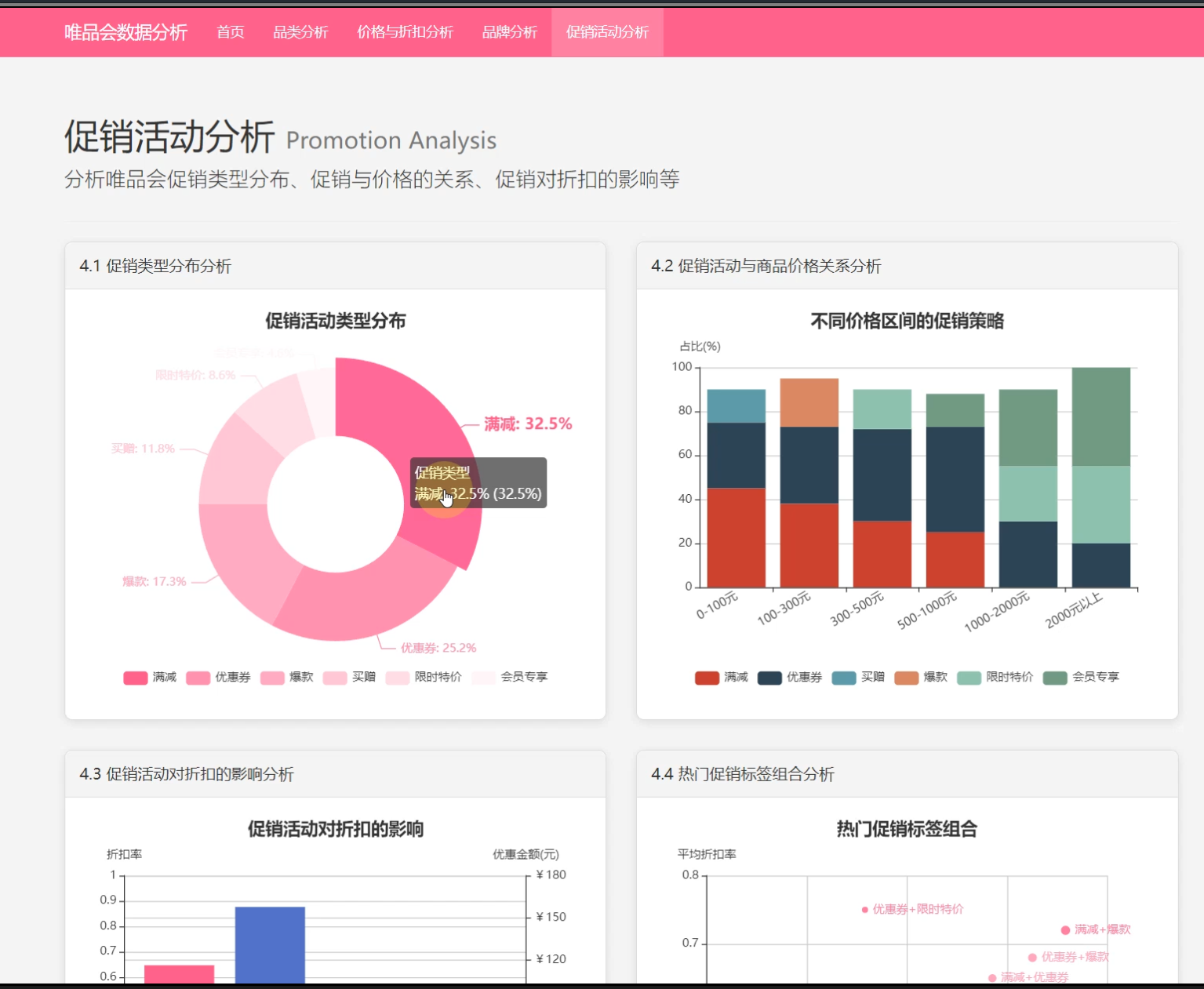
☀️4.2促销活动折扣影响分析☀️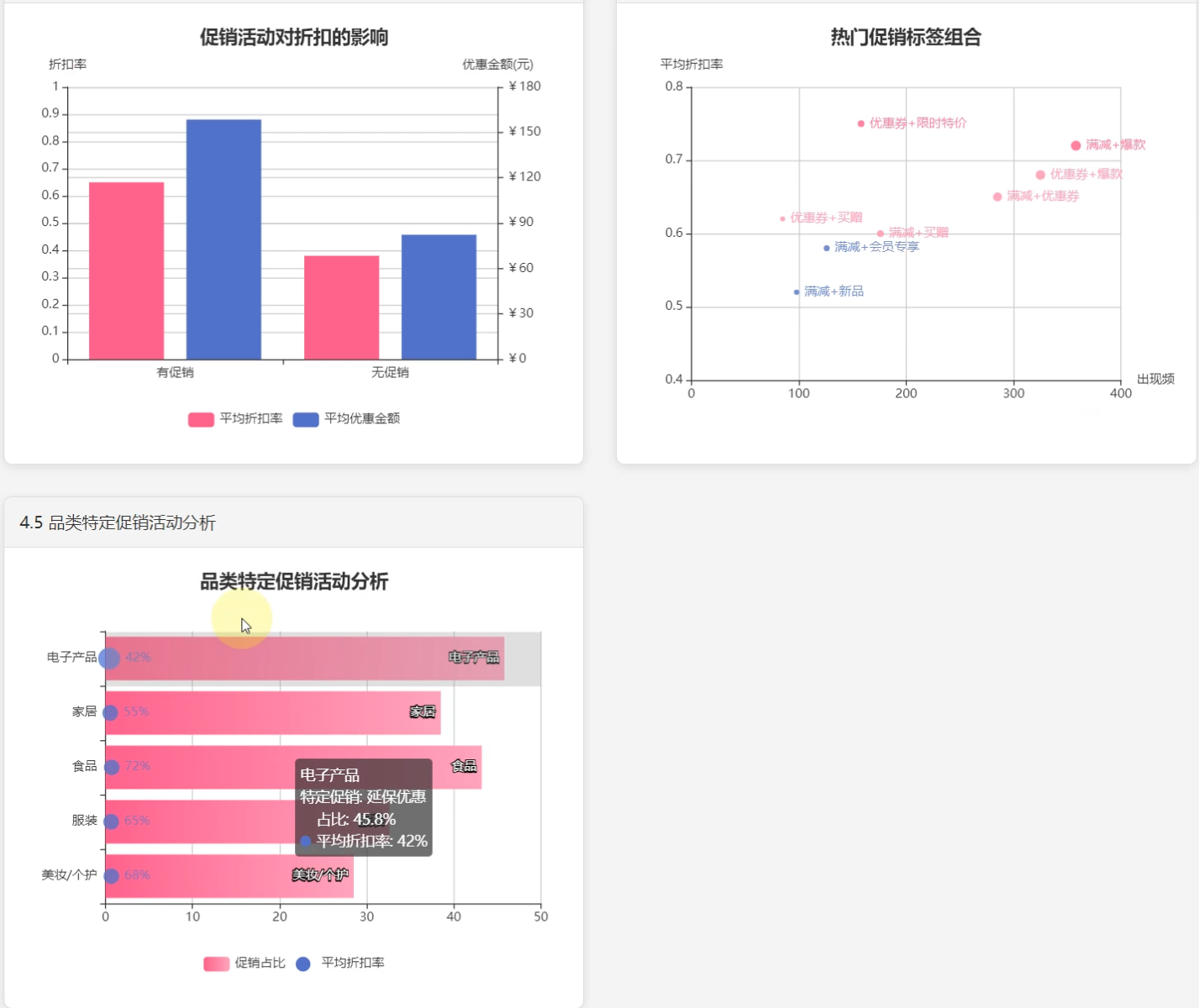
唯品会商品数据分析可视化系统-代码展示
1.大数据处理【代码如下(示例):】
class VipshopDataAnalyzer:
"""唯品会数据分析核心类"""
def __init__(self, db_path='vipshop_data.db'):
self.db_path = db_path
self.init_database()
def init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 创建商品表
cursor.execute('''
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id TEXT UNIQUE,
name TEXT,
brand TEXT,
category TEXT,
price REAL,
original_price REAL,
discount REAL,
rating REAL,
sales_count INTEGER,
review_count INTEGER,
create_time TEXT,
update_time TEXT
)
''')
# 创建价格历史表
cursor.execute('''
CREATE TABLE IF NOT EXISTS price_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id TEXT,
price REAL,
record_date TEXT,
FOREIGN KEY (product_id) REFERENCES products(product_id)
)
''')
conn.commit()
conn.close()
def generate_sample_data(self, n_products=1000):
"""生成模拟数据用于演示"""
np.random.seed(42)
brands = ['Nike', 'Adidas', 'Zara', 'H&M', 'Uniqlo', 'Coach', 'MK', 'Levi\'s', 'CK', 'Tommy']
categories = ['服装', '鞋类', '包包', '配饰', '家居', '美妆', '运动', '童装']
data = []
for i in range(n_products):
brand = np.random.choice(brands)
category = np.random.choice(categories)
original_price = np.random.uniform(50, 2000)
discount = np.random.uniform(0.3, 0.8)
price = original_price * discount
data.append(product)
# 保存到数据库
df = pd.DataFrame(data)
conn = sqlite3.connect(self.db_path)
df.to_sql('products', conn, if_exists='replace', index=False)
conn.close()
return df
2.可视化【代码如下(示例):】
def brand_analysis(self, df):
"""品牌分析"""
brand_stats = df.groupby('brand').agg({
'price': ['mean', 'count'],
'sales_count': 'sum',
'rating': 'mean',
'discount': 'mean'
}).round(2)
brand_stats.columns = ['平均价格', '商品数量', '总销量', '平均评分', '平均折扣']
brand_stats = brand_stats.sort_values('总销量', ascending=False)
return brand_stats
def create_visualizations(self, df):
"""创建可视化图表"""
# 1. 价格分布直方图
fig1 = px.histogram(df, x='price', nbins=30, title='商品价格分布',
labels={'price': '价格(元)', 'count': '商品数量'})
fig1.update_layout(showlegend=False)
# 2. 品牌销量对比
brand_sales = df.groupby('brand')['sales_count'].sum().sort_values(ascending=True)
fig2 = px.bar(x=brand_sales.values, y=brand_sales.index,
orientation='h', title='各品牌销量对比',
labels={'x': '总销量', 'y': '品牌'})
# 3. 分类占比饼图
category_counts = df['category'].value_counts()
fig3 = px.pie(values=category_counts.values, names=category_counts.index,
title='商品分类占比')
# 4. 价格vs销量散点图
fig4 = px.scatter(df, x='price', y='sales_count', color='category',
title='价格与销量关系',
labels={'price': '价格(元)', 'sales_count': '销量'})
# 5. 品牌评分对比
brand_rating = df.groupby('brand')['rating'].mean().sort_values(ascending=True)
fig5 = px.bar(x=brand_rating.values, y=brand_rating.index,
orientation='h', title='各品牌平均评分',
labels={'x': '平均评分', 'y': '品牌'})
return {
'price_dist': fig1,
'brand_sales': fig2,
'category_pie': fig3,
'price_sales_scatter': fig4,
'brand_rating': fig5,
'discount_box': fig6
}
唯品会商品数据分析可视化系统-结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目集
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)