yolov5的C3,yolov8的C2f,yolov11的C3k2,yolov12的A2C2f模块的设计核心理念
用 “分支并行 + 灵活卷积核”,解决了这些痛点:
一.YOLOv5中的C3模块
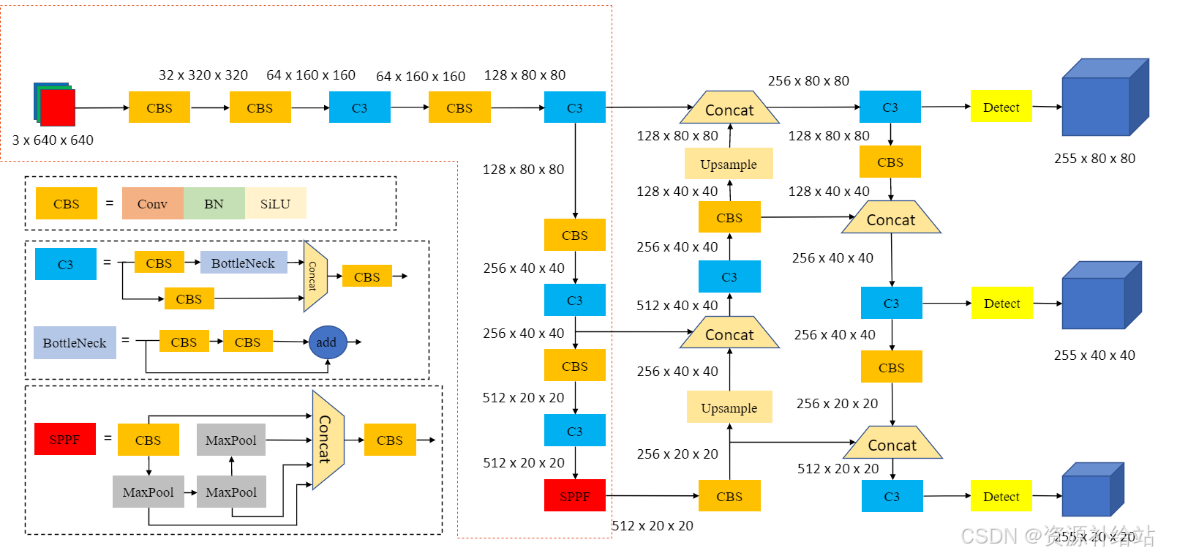
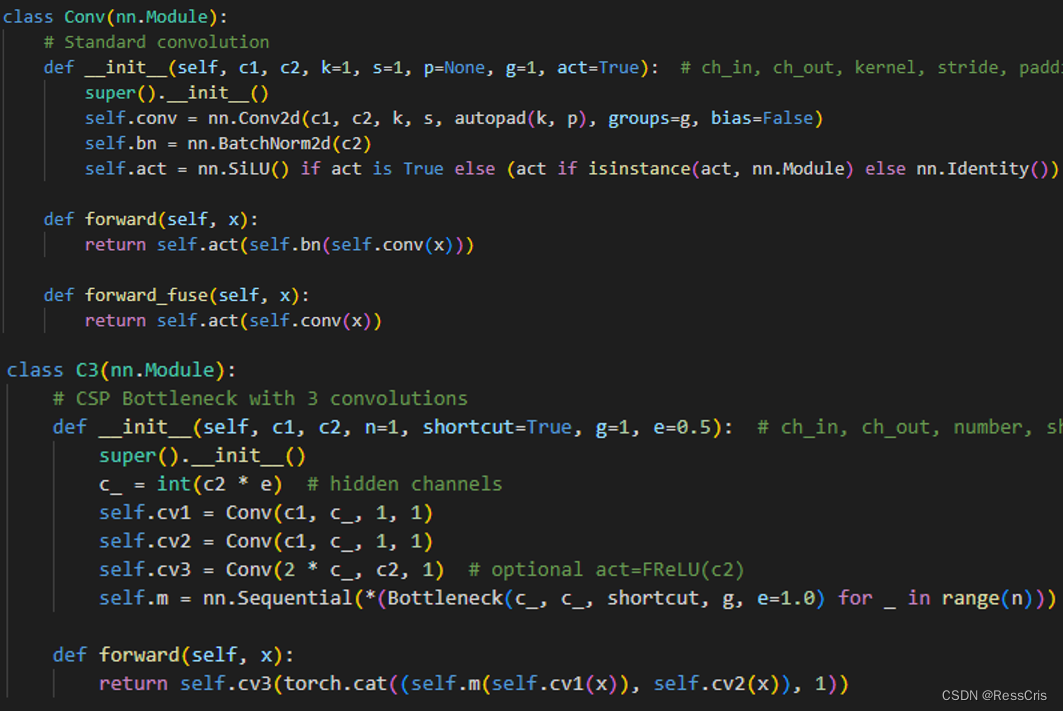
代码:
1.C3模块的主要特点和功能
YOLOv5中的C3模块是一个关键的网络结构组件,它在特征提取和模型性能提升方面起着重要作用。以下是C3模块的主要特点和功能:
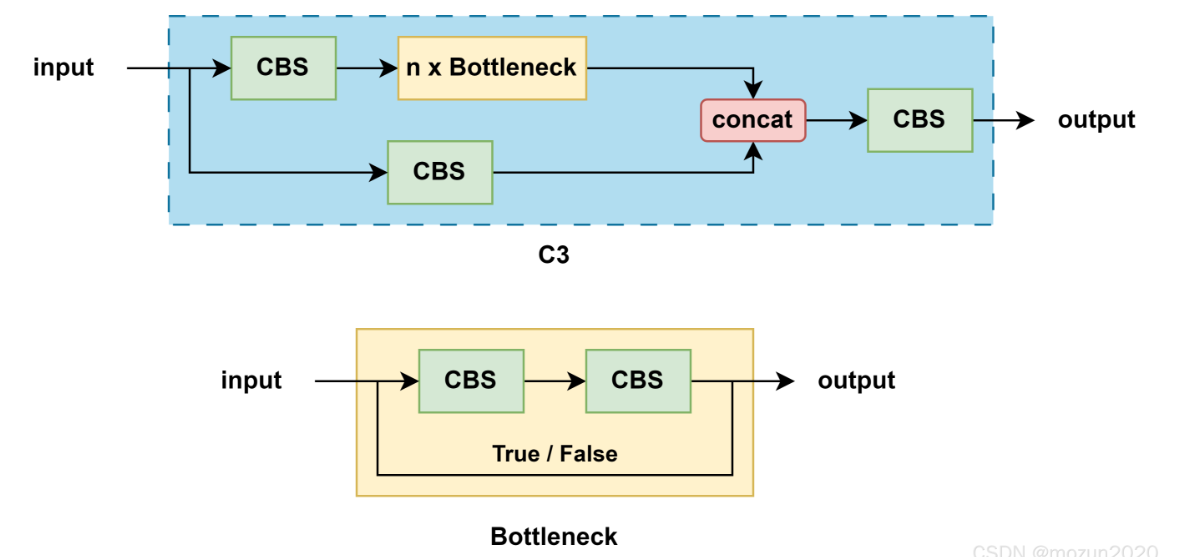
- 结构组成:C3模块由三个卷积层(Conv)和多个Bottleneck模块组成。这些Bottleneck模块的数量由配置文件(.yaml)中的n和depth_multiple参数决定。
- 功能作用:C3模块的主要作用是增加网络的深度和感受野,提高特征提取的能力。它通过残差连接和特征融合,进一步增强了网络的特征提取能力。
- 残差连接:C3模块包含两个分支,一个分支通过多个Bottleneck层进行深层次特征提取,另一个分支仅经过一个基本卷积模块,最后将两支进行concat操作,实现特征的融合。
- 激活函数变化:与BottleneckCSP模块相比,C3模块在concat后的标准卷积模块中的激活函数由LeakyRelu变为了SiLU(也称为Hardswish)。
2.引入C3的动机以及解决的问题
在YOLOv5的改进中,引入C3模块的主要动机是为了解决模型过于庞大、参数量多导致的检测速度慢以及应用受限的问题。C3模块通过使用深度可分离卷积来替换原C3模块中的普通卷积,从而实现模型的轻量化,平衡速度和精度。这种改进思路是将原C3模块中使用的普通卷积全部替换为深度可分离卷积,其余结构不变,以此降低模型的复杂度,提高检测精度,同时适用于移动或嵌入式设备等对低延迟有要求的场景
3.改进的思路
1.添加注意力机制
YOLOv5的C3模块是一个基于卷积的瓶颈结构,通常用于提升模型的特征提取能力。你可以将不同的注意力机制(如GAM、NAM、CA)添加到这个模块中以增强模型的注意力集中能力。
(1).这些注意力机制都是为了使模型能更好地关注输入图像的重要部分。你可以在C3模块的输出上应用这些机制,替换ECA。但是,每种机制的实现方式和计算复杂度都不同,可能需要调整一些代码来适应。
(2).可以进行这样的对比实验。通过在相同网络结构的其他位置添加这些注意力机制,然后评估它们在绝缘子缺陷检测任务上的性能,可以比较它们的效果。选择表现最好的模块作为创新点进行实验介绍。
对比实验的设计看起来是合理的,但需要实际编写代码来实现这些模块并进行训练。以下是一个简单的思路:
- 需要了解每个注意力机制的工作原理和实现方法。例如,ECA(Efficient Channel Attention)主要关注通道注意力,而SE(Squeeze-and-Excitation)则同时考虑通道和空间注意力,GAM、NAM可能有更复杂的计算。
- 在YOLOv5的models/yolo.py文件中找到C3模块的定义,通常在def C3函数里。在这里添加你选择的注意力机制。例如,如果你要添加ECA,可以参考相关论文的代码实现。
2.结构组成方面:
能否再添加卷积层(Conv)或Bottleneck模块
3.残差连接方面:
能否继续添加分支,最后将两支进行concat操作,实现特征的融合
二.yolov8的C2f模块 YOLOv8中的C2f模块代码详解_yolov8 c2f-CSDN博客
代码:
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
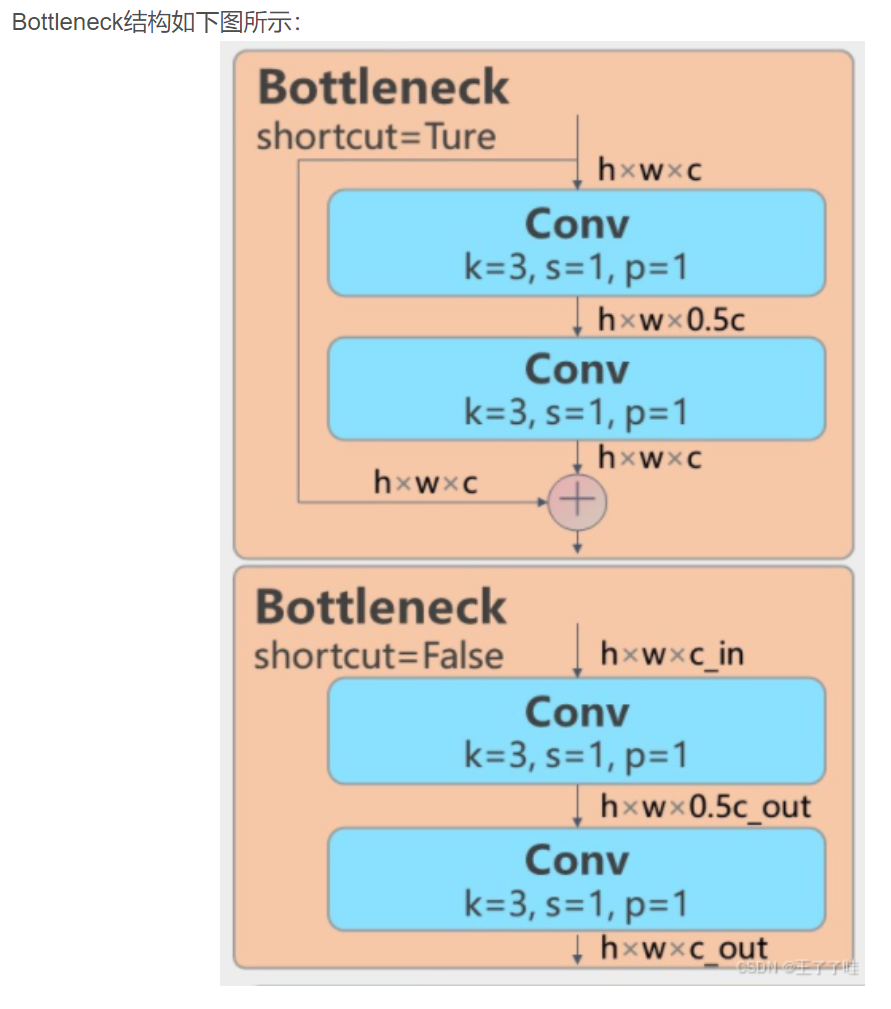
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
关键组件和参数说明
1.参数:
c1:输入通道数(ch_in)。
c2:输出通道数(ch_out)。
n:瓶颈块 (Bottleneck) 的数量。
shortcut:是否使用捷径连接(残差连接)。
g:分组卷积的组数(groups)。
e:扩展系数,控制隐藏通道数的比例。
2.组件:
self.c:隐藏通道数,由 c2 和扩展系数 e 计算得到 (self.c = int(c2 * e))。
self.cv1:第一个卷积层,将输入的通道数 c1 转换为 2 * self.c 的通道数。
self.cv2:第二个卷积层,将输入的通道数 ((2 + n) * self.c) 转换为输出通道数 c2。
self.m:一个包含 n 个瓶颈块的模块列表,每个瓶颈块的输入和输出通道数均为 self.c。
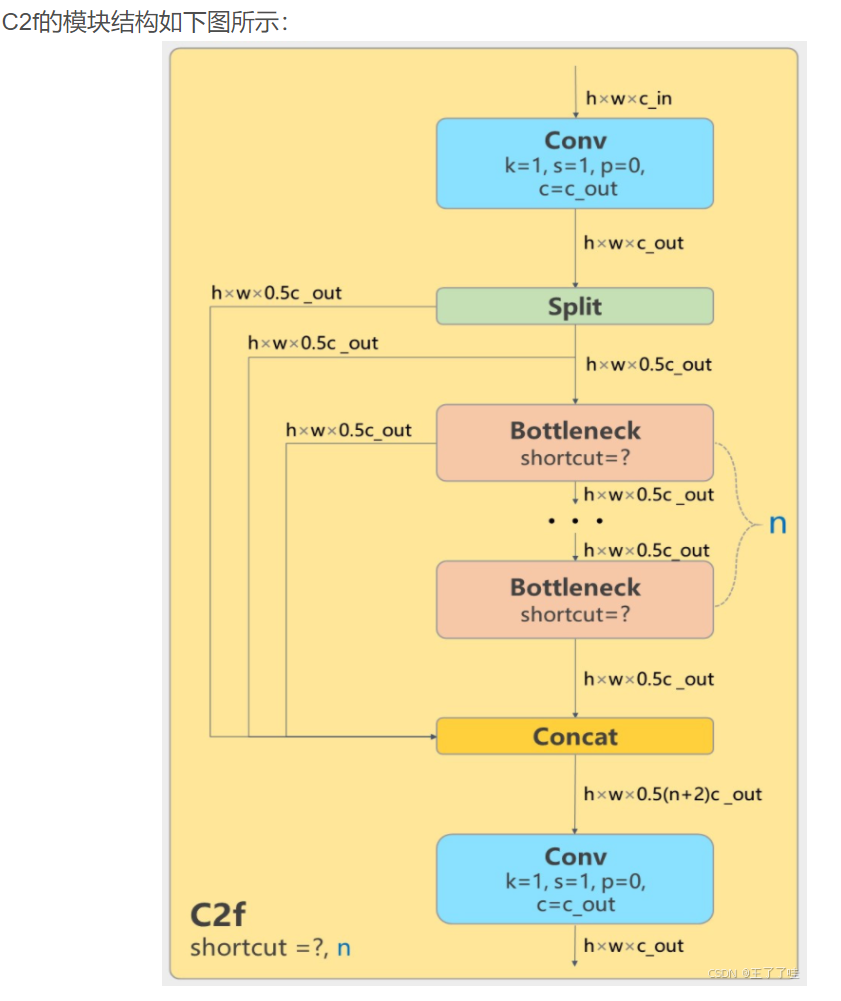
1.C2f模块的主要特点和功能
- Conv1: 首先对输入的特征图进行一次卷积,将通道数变为输入通道数的两倍。
- Bottleneck:接下来是多个Bottleneck模块,逐步提取特征。每个Bottleneck模块包含多个卷积层,并且可以配置是否使用shortcut连接(残差连接)。
- Concat:将多个Bottleneck模块的输出特征图与原始的特征图拼接起来。
- Conv2:最后通过一次卷积将拼接后的特征图再进行压缩,输出目标通道数的特征图。
功能
- 特征聚合:通过将不同Bottleneck模块的输出和原始特征图拼接在一起,C2F模块能够更好地聚合多尺度信息。
- 模型压缩:C2F模块中的卷积操作可以有效地压缩特征图,减少计算量,同时保持或增强模型的表达能力。
具体流程
- Conv1:输入特征图首先经过一个卷积层(通常为1x1卷积)处理,输出的特征图通道数增加一倍。这一步的目的是增加模型的特征表达能力。
- Split:在C2f模块内部,输入特征图被一分为二,一部分进入Bottleneck模块,另一部分直接参与后续的拼接。
- Bottleneck:经过分割后的特征图在多个Bottleneck模块中逐层处理,提取更深层次的特征。Bottleneck模块可以配置是否使用shortcut连接,用于增强梯度传播和信息流动。
- Concat:将所有Bottleneck模块的输出以及之前分割的特征图进行拼接,增加特征的多样性。
- Conv2:最终通过一个卷积层将拼接后的特征图通道数压缩到所需的输出通道数,以适应下一步的处理需求。
2.引入C2f的动机以及解决的问题
在YOLOv8中,引入C2f模块的动机是为了替代YOLOv5中的C3结构,以提高梯度信息传输效率并重构主干网络。C2f模块通过增加跨层连接和使用不同的卷积核大小,能够捕捉更丰富的上下文信息,从而提升特征提取能力。这种改进有助于提升算法对于不同大小目标的检测性能,特别是在工业场景中占据重要地位,面对光照变化、目标遮挡、复杂背景等现实挑战,YOLOv8能快速且精准地识别各类目标。
3.改进的思路
1.调参
能否调整相关参数
2.结构模块
能否继续添加卷积模块
3.分支
能否再添加分支:比如6或9个分支
三.yolov11的C3k2模块
 代码
代码
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
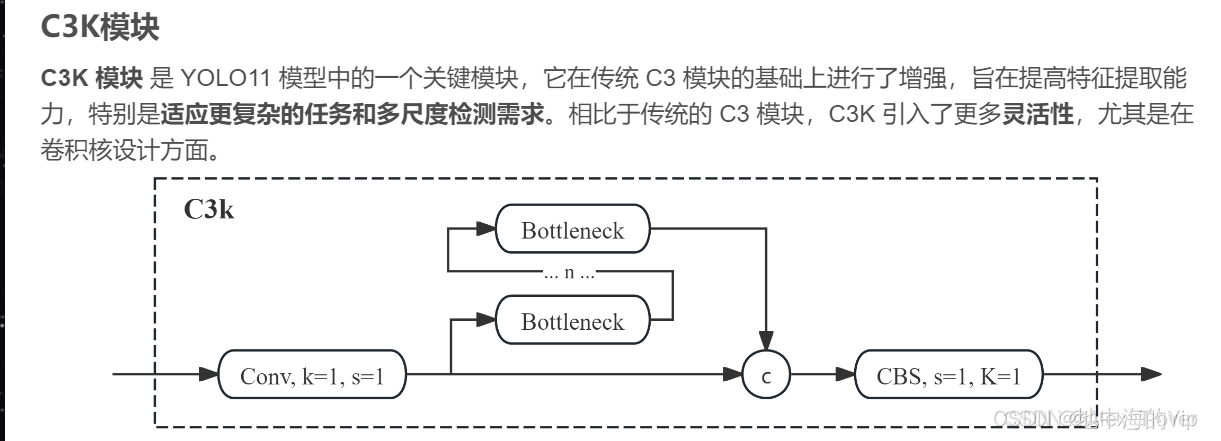
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
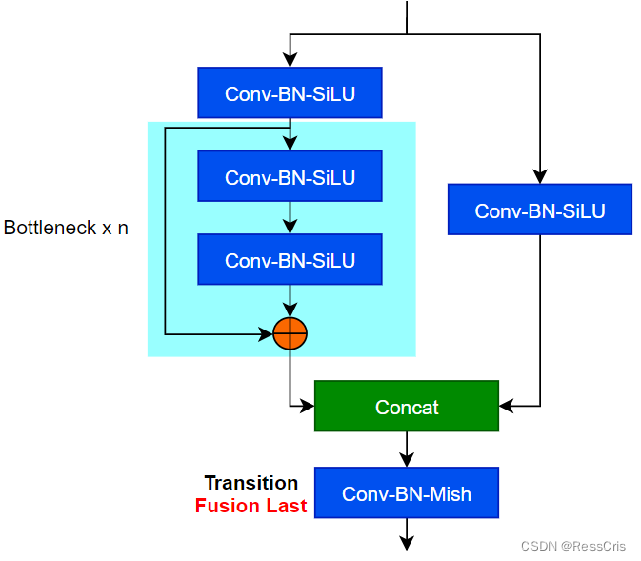
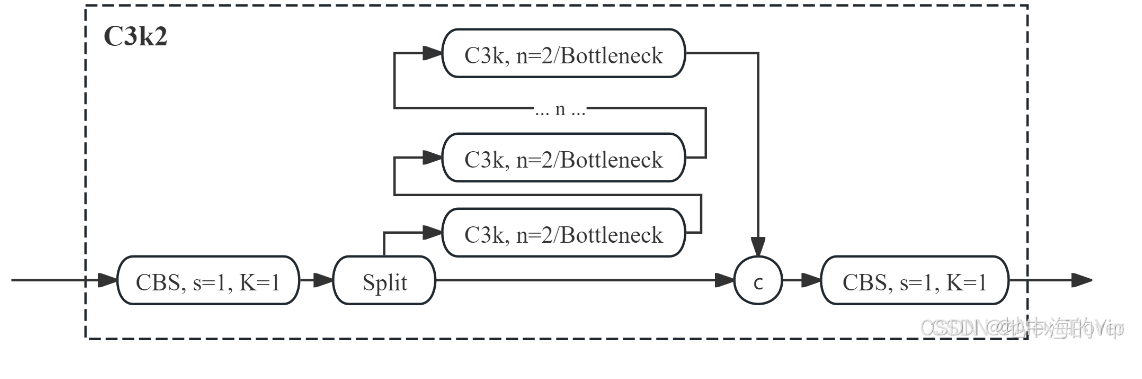
1.C3K2模块的特点和功能
C3k2 是 YOLO11 对传统特征提取模块的优化,核心就是 “更快、更准地抓图像里的关键特征”(比如检测目标的轮廓、细节 ),而且得适配 “实时检测” 需求(不能让模型算太久 )
拆解 C3k2 的 “工作逻辑”
第一步:“分支处理”(把任务拆成两拨人做)
- 操作:把输入的图像特征,分成 “直接传递组” 和 “深度处理组” 两路。
- 直接传递组:啥都不干,直接把原始特征 “原样保留”(保证浅层信息不丢,比如简单的边缘、颜色 )。
- 深度处理组:用一堆小模块(类似迷你画笔),对特征做 “深加工”(提取复杂的深层特征,比如目标的独特形状 )。
第二步:“灵活卷积核”(不同画笔应对不同场景)
- 操作:深度处理组里,能用 不同大小的卷积核(比如 3×3、5×5 这些 “画笔尺寸” )。
- 小核(3×3):抓小细节(比如小猫的胡须 )。
- 大核(5×5):抓大轮廓、复杂背景里的目标(比如大卡车的整体形状 )。
- 效果:遇到简单场景(比如清晰的小目标),用小核快速处理;遇到复杂场景(比如大目标、背景乱 ),用大核兜底,保证特征抓得全。
第三步:“融合出结果”(把两拨人的成果合并)
- 操作:把 “直接传递组” 的浅层特征,和 “深度处理组” 的深层特征,拼接融合 到一起。
- 效果:输出一个 “既有简单基础信息,又有复杂深层特征” 的新特征图,方便后面的模块接着分析(就像把草稿和细化内容合并成一幅完整的画 )。
- 为啥叫 C3k2?
- C3:继承了经典的 C3 模块思路(核心是 “分支处理 + 残差连接”,保证轻量化还能高效提取特征 )。
- k2:代表它的 灵活性—— 能自由切换不同大小的卷积核(k 就是 kernel,卷积核的意思 ),适配各种检测场景。
2.引入C3k2f的动机以及解决的问题
在YOLOv11中,引入C3k2f模块的动机是为了提高计算效率和处理速度,同时增强特征提取能力。C3k2模块结合了C2f和C3的优势,外层采用C2f结构,内层嵌入C3的框架。
具体来说,C3k2模块基于C2f结构,将其特征提取层(BottleNeck)替换为新设计的C3k层。C3k层与传统C3层类似,但将卷积核的大小调整为两个核大小为3的卷积层。通过超参数配置,C3k可根据需求灵活调整卷积块的结构:当C3k=True时,启用C3k层;否则保留原始C2f结构。相比于C3,C3k模块提供了更高的灵活性,允许用户根据具体应用场景自定义卷积块大小。相比于C3,C3k模块提供了更高的灵活性,允许用户根据具体应用场景自定义卷积块大小。
C3k2f模块的主要优点在于能够保存信息。n个瓶颈模块(旨在降低计算成本),这些模块管理信息流,同时最大限度地减少压缩过程中的损失。与C3模块只考虑瓶颈的最终输出不同,C2f/C3K2连接了所有中间瓶颈的输出。这样可以保留更多信息,并生成更丰富、更全面的表示形式,这有助于改进梯度流,实现更有效的学习和更快的收敛
总结
用 “分支并行 + 灵活卷积核”,解决了这些痛点:
分支并行:减少冗余计算,速度更快(适合实时检测,比如视频里的连续帧检测 )。
灵活卷积核:不管目标大小、场景复杂与否,都能精准抓特征(小目标细节、大目标轮廓都不丢 )。
3.改进的思路
1.引入动态特征融合(DFF)模块
YOLOv11改进 |创新 C3k2模块 | 引入动态特征融合(DFF)模块_yolov11的c3k2-CSDN博客
四.yolov12的A2C2f模块
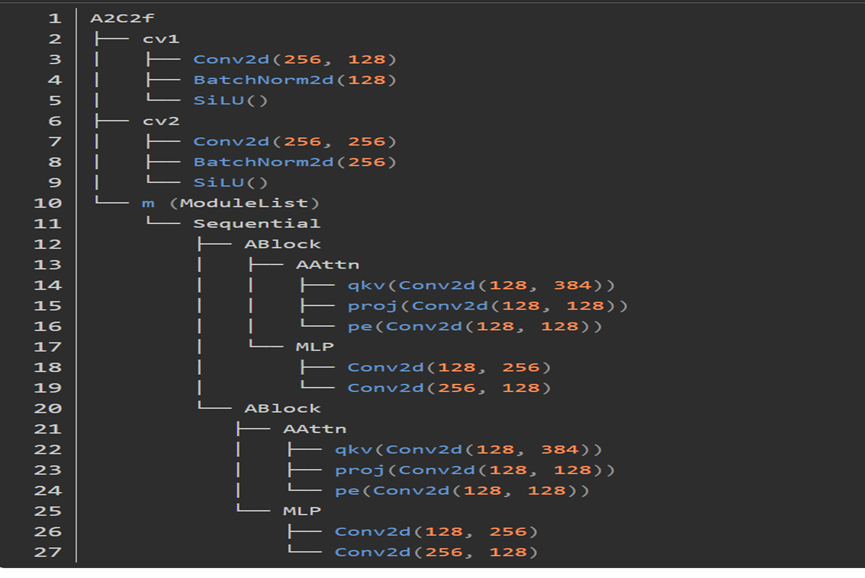
代码:
class A2C2f(nn.Module):
"""
A2C2f module with residual enhanced feature extraction using ABlock blocks with area-attention. Also known as R-ELAN
This class extends the C2f module by incorporating ABlock blocks for fast attention mechanisms and feature extraction.
Attributes:
c1 (int): Number of input channels;
c2 (int): Number of output channels;
n (int, optional): Number of 2xABlock modules to stack. Defaults to 1;
a2 (bool, optional): Whether use area-attention. Defaults to True;
area (int, optional): Number of areas the feature map is divided. Defaults to 1;
residual (bool, optional): Whether use the residual (with layer scale). Defaults to False;
mlp_ratio (float, optional): MLP expansion ratio (or MLP hidden dimension ratio). Defaults to 1.2;
e (float, optional): Expansion ratio for R-ELAN modules. Defaults to 0.5;
g (int, optional): Number of groups for grouped convolution. Defaults to 1;
shortcut (bool, optional): Whether to use shortcut connection. Defaults to True;
Methods:
forward: Performs a forward pass through the A2C2f module.
Examples:
>>> import torch
>>> from ultralytics.nn.modules import A2C2f
>>> model = A2C2f(c1=64, c2=64, n=2, a2=True, area=4, residual=True, e=0.5)
>>> x = torch.randn(2, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
"""
def __init__(self, c1, c2, n=1, a2=True, area=1, residual=False, mlp_ratio=2.0, e=0.5, g=1, shortcut=True):
super().__init__()
c_ = int(c2 * e) # hidden channels
assert c_ % 32 == 0, "Dimension of ABlock be a multiple of 32."
num_heads = c_ // 32
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv((1 + n) * c_, c2, 1) # optional act=FReLU(c2)
init_values = 0.01 # or smaller
self.gamma = nn.Parameter(init_values * torch.ones((c2)), requires_grad=True) if a2 and residual else None
self.m = nn.ModuleList(
nn.Sequential(*(ABlock(c_, num_heads, mlp_ratio, area) for _ in range(2))) if a2 else C3k(c_, c_, 2, shortcut, g) for _ in range(n)
)
def forward(self, x):
"""Forward pass through R-ELAN layer."""
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in self.m)
if self.gamma is not None:
return x + self.gamma.view(1, -1, 1, 1) * self.cv2(torch.cat(y, 1))
return self.cv2(torch.cat(y, 1))1.A2C2f模块的特点及功能
A2C2f 模块的主要功能是通过结合区域注意力和快速注意力机制来增强特征提取。它通过以下方式实现这些目标:
- 残差连接:通过残差连接,模块可以学习到更深层次的特征,同时避免梯度消失问题。
- 区域注意力:通过将特征图划分为多个区域,每个区域独立进行注意力计算,从而提高计算效率。
- 快速注意力机制:使用 ABlock 模块实现快速注意力机制,进一步优化计算效率。
- MLP 扩展:通过 MLP(多层感知机)扩展比率来调整隐藏层的维度,增强特征的表示能力。
2.引入A2C2f模块的动机以及解决的问题
YOLOv12中引入A2C2f模块的动机是为了充分利用注意力机制在性能上的优势,同时保持与之前基于CNN的YOLO框架相当的推理速度,从而在实时性与精度之间实现更好的平衡。A2C2f模块是基于Transformer注意力构建的,它通过结合区域注意力(Area-Attention)和残差连接,主要用于提升特征提取的效率和精度。这种改进有助于提升算法对于不同大小目标的检测性能
3.改进的思路
1.引入注意力机制(CBAM,CA)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)