Deepseek-mHC(一文看懂mHC:让大模型训练更稳、更强的“残差连接2.0)
mHC的价值,不止是“修复”了HC的漏洞,更给大模型架构设计提供了新思路:拓扑创新要兼顾“灵活性”和“稳定性”:单纯拓宽信息通道(HC)不够,还要给通道加“约束规则”(流形约束),才能支撑大规模训练。架构优化要“软硬结合”:不仅要设计好算法逻辑,还要优化底层基建(核融合、通信重叠),才能在不牺牲效率的前提下提升性能。对于普通读者来说,mHC的落地意义很直接:未来的大模型会训练得更快、更稳定,AI产
在AI大模型越来越“卷参数、卷数据”的今天,训练稳定性和 scalability(可扩展性)成了核心痛点——模型越大,越容易出现训练崩溃、效率暴跌的问题。而DeepSeek-AI团队提出的Manifold-Constrained Hyper-Connections(mHC),正是针对这一痛点的“特效药”。它在不牺牲性能的前提下,解决了现有架构的稳定性难题,还能轻松适配大规模训练。下面用通俗的语言拆解这项技术的核心逻辑。
1 mHC小结
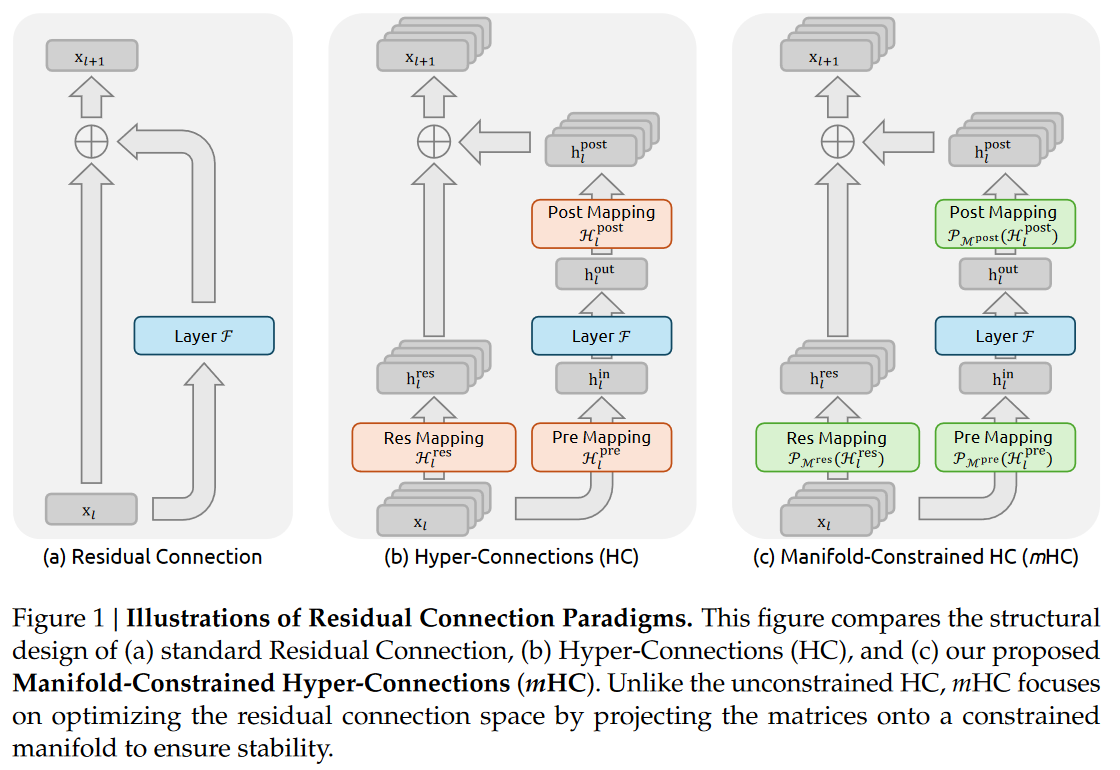
一、先搞懂:我们为什么需要“残差连接”?
要理解mHC,得先从AI架构的“基石”——残差连接(Residual Connection)说起。
你可以把神经网络的每一层想象成一个“信息加工厂”:输入数据(比如文本、图像特征)进去,经过复杂计算后输出。但随着模型层数变深(现在大模型动辄上百层),信息在传递中容易“损耗”或“失真”,就像信号在电线里传输会衰减一样。
残差连接的作用,就是给信息加了一条“直达通道”:让浅层的原始信息不经过复杂计算,直接传到深层。这样一来,深层网络既能拿到加工后的特征,又能保留原始信息,训练起来更稳定、收敛更快。这也是ResNet、Transformer等经典架构能成功的关键——残差连接就像“信息高速公路”,保证了信号的顺畅传递。
二、HC的“进步”与“漏洞”:拓宽公路,却没了交通规则
既然残差连接这么好用,研究者们自然想让它更强大——于是Hyper-Connections(HC,超连接)应运而生。
HC的核心思路是“拓宽信息高速公路”:把原来的单条残差流,扩展成n条并行流(比如n=4),还加入了可学习的“调节开关”(三个映射矩阵),让不同流之间的信息能灵活交互。这样一来,模型的拓扑复杂度提升了,能捕捉更多复杂特征,性能确实涨了。
但问题也随之而来:
-
训练不稳定:HC的“调节开关”是无约束的——就像拓宽了公路,却没有交通规则,车辆(信息)可能越跑越快(信号放大)或越跑越慢(信号消失),到了深层直接“堵车崩溃”(训练 loss 暴涨、梯度爆炸)。
-
资源开销大:n条并行流意味着更多的内存访问和通信成本,就像多车道公路需要更多收费站,反而拖慢了整体效率。
简单说,HC是“只顾拓宽路,没管交通秩序”,导致大模型训练时“容易崩、跑不快”。
三、mHC的核心创新:给“信息公路”加规则+优化基建
mHC的本质,是给HC的“无约束公路”加上“交通规则”,再优化“道路基建”,既保留HC的性能优势,又解决了它的痛点。核心分为两大块:
1. 核心约束:用“双随机矩阵”稳住信息传播
mHC的关键创新是“流形约束”——把HC中最关键的“残差映射矩阵(H_res)”,通过一种叫Sinkhorn-Knopp的算法,投影到“双随机矩阵”构成的流形上。
这句话听起来复杂,通俗解释就是:
-
双随机矩阵的规则:每行、每列的数值和都是1,且所有数值非负。
-
效果:信息在n条并行流中传递时,既不会被无限制放大(避免梯度爆炸),也不会消失(避免梯度消失),就像车辆按限速行驶,不会拥堵或掉队。
-
额外好处:这种矩阵的组合还能让不同流的信息更均匀地融合,相当于“优化了交通调度”,进一步提升模型性能。
更妙的是,当n=1时,mHC会自动退化成原始的残差连接,完全兼容现有架构——相当于“老公路也能无缝升级”。
2. 基建优化:让“公路”跑起来更高效
解决了稳定性问题,mHC还针对HC的资源开销痛点,做了三项关键优化:
-
核融合(Kernel Fusion):把多个零散的计算步骤合并成一个“超级计算单元”,减少内存读写次数,就像把收费站合并成“ETC快速通道”,提升通行效率。
-
选择性重计算(Recomputing):训练时只保存关键中间结果,其他结果在需要时再实时计算,大幅减少GPU内存占用——相当于“不占用多余停车场,却不影响车辆通行”。
-
通信重叠(Overlapping Communication):在大规模分布式训练中,让数据传输和计算同时进行,减少等待时间,就像“一边修路一边通车”,不浪费时间。
四、效果:稳定、能打、还不费资源
mHC的效果可以用“三赢”来概括:
1. 训练更稳:再也不怕“中途崩溃”
在27B参数的大模型训练中,HC在12k步左右就出现loss暴涨(训练崩溃),而mHC的loss全程平稳下降,梯度 norm(衡量训练稳定性的关键指标)和基线模型一样稳定——相当于“HC跑着跑着翻车了,mHC却能稳稳开到终点”。
2. 性能更强:推理、理解全面提升
在8个主流 benchmarks(比如BBH推理、MMLU知识问答、GSM8K数学题)中,mHC不仅全面超越基线模型,还在大多数任务上超过HC:
-
BBH推理任务提升2.1%,DROP阅读理解提升2.3%——相当于“不仅跑的稳,还跑的更快、更远”。
3. 效率更高:只多6.7%开销,换来了质的飞跃
虽然加了约束和优化,但mHC在n=4(常用扩展率)时,只增加了6.7%的训练时间开销,却解决了HC的致命问题——对于大模型训练来说,这是“性价比极高”的提升。
五、总结:mHC对AI架构的意义
mHC的价值,不止是“修复”了HC的漏洞,更给大模型架构设计提供了新思路:
-
拓扑创新要兼顾“灵活性”和“稳定性”:单纯拓宽信息通道(HC)不够,还要给通道加“约束规则”(流形约束),才能支撑大规模训练。
-
架构优化要“软硬结合”:不仅要设计好算法逻辑,还要优化底层基建(核融合、通信重叠),才能在不牺牲效率的前提下提升性能。
对于普通读者来说,mHC的落地意义很直接:未来的大模型会训练得更快、更稳定,AI产品(比如智能助手、代码生成工具)的性能和可靠性也会随之提升;对于AI研究者来说,mHC打开了“流形约束+基建优化”的新方向,可能会推动下一代基础模型的架构进化。
这项技术用“小改动”解决了大问题,堪称残差连接的“2.0升级”——毕竟在大模型竞争中,“能稳定跑完、还能持续变强”,才是最核心的竞争力。
2 搞懂mHC的“前辈们”:AI架构如何从“能跑”进化到“稳跑”?
用通俗的话讲,AI架构的进化分两大方向:“内部零件”优化(微观设计)和“整体框架”优化(宏观设计),逐个说清楚:
一、微观设计:给模型的“内部零件”升级
微观设计管的是模型的“核心组件”,比如数据怎么处理、特征怎么提取,相当于给汽车优化发动机、变速箱,让单个零件更高效。
-
早期:靠“卷积”打天下。卷积能高效处理图像、文本这类结构化数据,后来又出了深度可分离卷积、分组卷积,都是为了“少干活多办事”,降低计算成本。
-
现在:Transformer成了“主流架构”。核心是两个零件:注意力机制(负责全局信息沟通,比如理解文本上下文)和前馈网络(FFN,负责强化单个特征)。
-
优化方向:往“高效”走。比如注意力机制进化出MQA、GQA,前馈网络进化出MoE(专家混合模型),核心都是“不盲目堆参数”——比如MoE让模型只有部分“专家”干活,既提升能力又不增加太多计算量。
简单说,微观设计的核心是:把模型的“内部零件”磨得更锋利,让单个组件又快又能打。
二、宏观设计:给模型的“整体框架”铺路
宏观设计管的是模型的“层间连接”,比如信息怎么在不同层之间传递,相当于给汽车设计底盘和传动系统,让整体跑得更顺。
-
早期:ResNet的“残差连接”是里程碑。就像给信息加了“直达通道”,解决了深层模型信息损耗的问题,让模型能“堆层数”而不崩溃。
-
后来:往“拓宽通道”进化。比如DenseNet的稠密连接、DLA的深层聚合,都是想让层间信息交互更充分。
-
关键节点:HC(超连接)的出现。它把残差连接的“单通道”拓宽成n条并行流,还加了可学习的“调节开关”,让信息交互更灵活,性能确实涨了——但问题也来了:
-
没约束:“调节开关”想怎么调就怎么调,信息在深层会无限放大或消失,训练容易崩;
-
开销大:多通道需要更多内存和数据传输,相当于多车道公路多了一堆收费站,拖慢效率。
-
除此之外,还有RMT、MUDDFormer等架构,也都是在拓宽通道、优化层间连接,但都没解决“破坏恒等映射、导致不稳定”的核心问题。
简单说,宏观设计的核心是:把模型的“信息通道”修得更宽、更灵活,但却没给通道加“交通规则”,导致大模型跑起来容易“翻车”。
三、总结:mHC的“精准补位”价值
看了这些“前辈们”的进化史,就明白mHC的聪明之处了:
它没有颠覆现有架构,而是精准瞄准了宏观设计的“致命漏洞”——比如HC这类拓宽通道的架构,虽然拓扑更复杂、性能更强,但破坏了残差连接的“恒等映射”,导致不稳定、开销大。
mHC的核心动作就是“补坑”:给HC的“信息通道”加“交通规则”(双随机矩阵约束),再优化“道路基建”(核融合、重计算),既保留了拓宽通道的性能优势,又解决了稳定性和效率问题。
这也正是相关工作的意义:mHC不是凭空创造的,而是基于AI架构几十年的进化,针对行业痛点的“精准改进”——它证明了:好的技术不是颠覆,而是让成熟的框架“更稳、更快、更强”。
3 读懂HC的“致命短板”
一、先搞懂HC的“基础操作”:怎么拓宽信息通道?
HC的核心是“把单条信息通道拆成n条并行流”(比如n=4),但要让这n条流正常工作,它加了三个“辅助工具”(可学习映射):
-
H_pre:把n条流的信息“汇总”成1条,交给模型核心层处理;
-
H_post:把核心层的输出“拆分”回n条流,继续传递;
-
H_res:在n条流内部“调节”信息,让不同流的特征互相交流。
这三个工具的工作逻辑分两类:
-
动态映射:跟着输入数据变,比如处理不同文本时,调节规则不一样;
-
静态映射:固定的基础规则,保证信息传递不跑偏。
关键实验发现(消融实验):这三个工具里,H_res是“核心功臣”——只要有它,性能就能涨0.022;加上另外两个,性能只多涨0.005。也就是说,HC的性能提升,主要靠H_res在多流之间做信息融合。
而且HC很聪明:这三个工具的计算成本极低(n通常是4,远小于输入维度C),不会增加太多浮点运算(FLOPs),相当于“花小钱办大事”。
二、HC的第一个致命问题:数值不稳定,训练必崩
虽然H_res能提性能,但它有个大bug:“没规矩”——作为可学习映射,它的参数不受约束,就像让信息在多车道公路上随便跑,没有限速和交通灯。
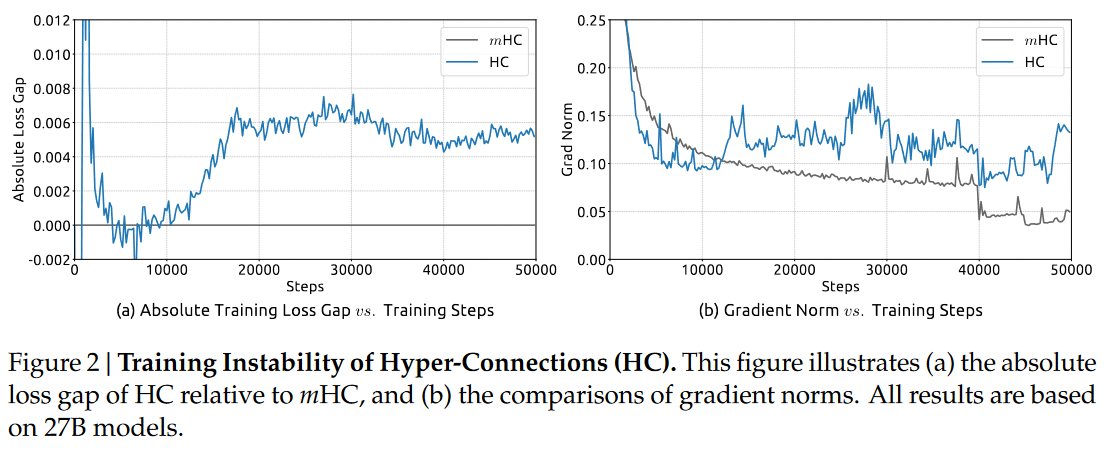
具体后果很严重:
-
当模型层数变深(比如几十层),H_res的影响会被“放大”,导致信息信号要么无限放大(梯度爆炸),要么越传越弱(梯度消失);
-
实验数据很直观:27B模型训练到12k步时,HC的损失值突然暴涨(直接崩溃),而它的“信号放大倍数”(Amax Gain)峰值高达3000——相当于正常信号被放大了3000倍,模型根本扛不住;
-
这直接违背了残差连接的初衷:残差连接是让信息“顺畅传递”,而HC的无约束设计,反而让信息传递“失控”。
三、HC的第二个致命问题:系统开销太大,跑不快
HC虽然没增加太多计算量,但在“硬件资源利用”上一塌糊涂,主要问题是“内存访问和通信成本太高”:
-
内存访问(I/O)成本:n条并行流意味着要读写更多数据,成本大概和n成正比(比如n=4,成本就约为原来的4倍),这就是行业说的“内存墙”——数据在内存里来回倒腾,比实际计算还费时间;
-
GPU内存占用:三个映射都有可学习参数,训练时要保存它们的中间结果,导致GPU内存不够用,不得不启用“梯度检查点”(一种省内存的技术),反而又拖慢了速度;
-
通信成本:大规模分布式训练时,HC需要n倍的通信量,比如n=4,数据传输量就是原来的4倍,导致训练时出现大量“空闲等待”,吞吐量暴跌。
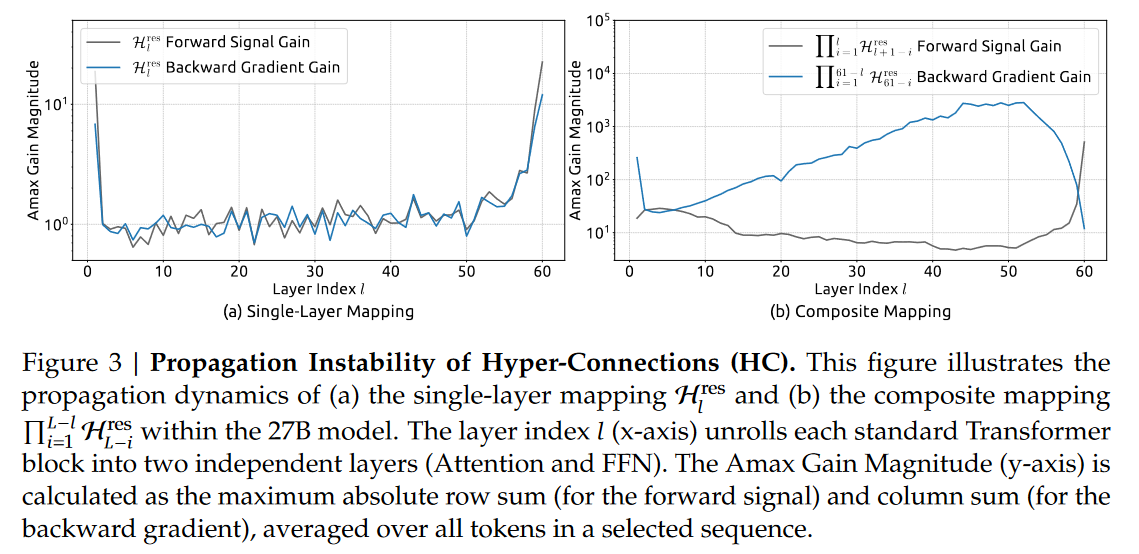
5 揭秘mHC的“解题思路”:怎么搞定大模型的“稳”与“快”
这一章直接给出mHC的“全套解决方案”。核心逻辑很简单:用“约束”解决稳定性,用“基建优化”解决效率问题,最终实现“稳、快、强”的三重目标。
用通俗的话拆解,mHC的解决方案分两大块:先给信息传播“立规矩”,再给硬件运行“提效率”。
一、核心约束:给信息传播立“交通规则”
mHC最关键的创新,是给HC的“无约束信息通道”加了一道硬限制——让核心的残差映射矩阵(H_res)变成“双随机矩阵”。这步操作看似复杂,其实就是三个核心逻辑:
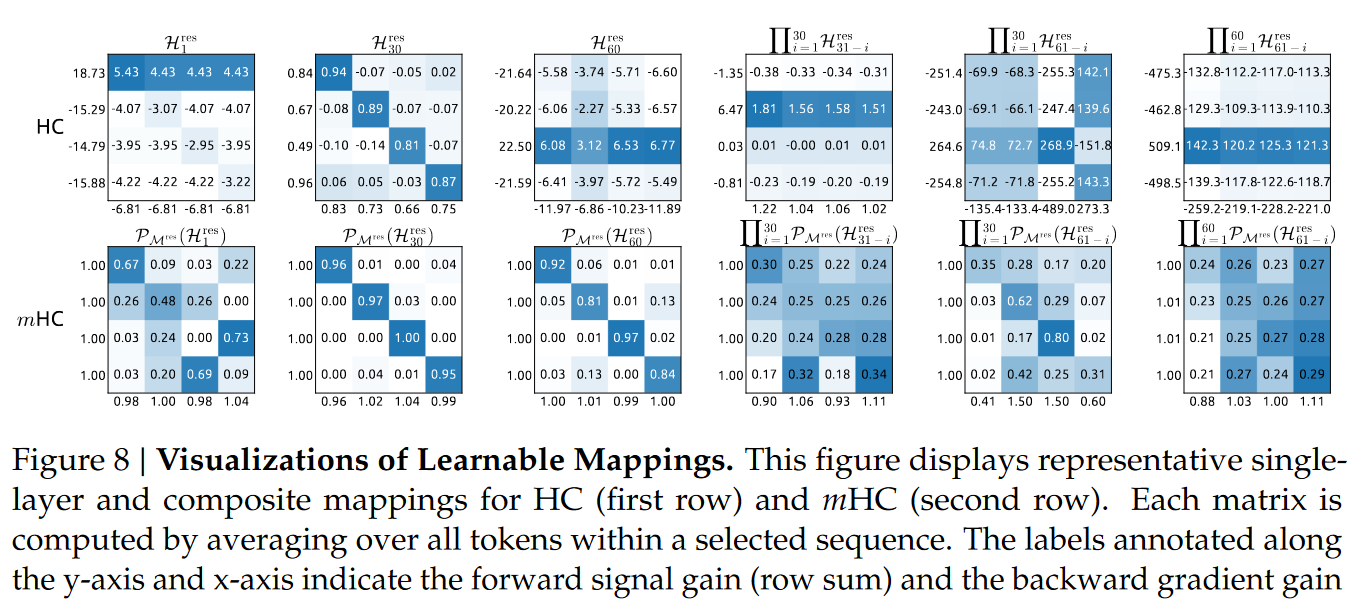
1. 双随机矩阵:信息传播的“限速+均衡”神器
双随机矩阵有两个铁规矩:
-
每行、每列的数值总和都是1,且所有数值都是非负数;
-
效果:信息在n条并行流里传递时,既不会被无限放大(梯度爆炸),也不会越传越弱(梯度消失),就像车辆按限速行驶,还能均匀分配车道资源。
更妙的是,这种矩阵有“组合不变性”——多个双随机矩阵相乘,结果还是双随机矩阵。这意味着哪怕模型有几十、上百层,信息传播的稳定性也能一直保持,从浅层到深层都不会“翻车”。
2. 怎么实现?Sinkhorn-Knopp算法的“魔法”
要把HC的无约束矩阵变成双随机矩阵,mHC用了一个经典算法:Sinkhorn-Knopp。它的工作流程超简单:
-
先把矩阵里的所有数值变成正数(避免正负抵消);
-
反复迭代调整行和列,直到每行、每列的和都等于1(实验中迭代20次就够,效率很高);
-
最终得到的矩阵,既满足约束,又能保留HC多流交互的性能优势。
3. 额外优化:给输入输出映射“加防护”
除了核心的H_res,mHC还对H_pre(信息汇总)和H_post(信息拆分)做了小约束——让它们的数值都是非负数。这样能避免正负系数抵消导致的信号失真,相当于给信息通道加了“防护栏”,进一步提升稳定性。
二、参数计算:怎么得到“合规”的映射矩阵?
mHC的参数计算逻辑很简洁,全程不复杂,核心是“先算基础值,再做约束”:
-
先把第l层的输入特征“压平”成一个向量,保留完整的上下文信息;
-
用和HC类似的方式,计算出H_pre、H_post、H_res的“基础版本”(包含动态映射和静态映射);
-
最后用约束规则“修正”:H_pre和H_post用Sigmoid函数变成非负数,H_res用Sinkhorn-Knopp算法变成双随机矩阵。
整个过程既兼容了HC的设计思路,又通过最后一步约束解决了核心问题,相当于“在原有框架上做精准修补”,升级成本极低。
三、基建优化:三招搞定“高开销”,只多6.7%成本
解决了稳定性,mHC还针对性优化了HC的高内存、高通信开销问题,三招让硬件效率拉满:
1. 核融合(Kernel Fusion):把“零散收费站”改成“ETC快速通道”
mHC把多个零散的计算步骤(比如矩阵乘法、归一化、偏置加法)合并成一个“超级计算单元”,减少了数据在内存里来回读写的次数。原本需要多次调用硬件资源的操作,现在一次就能完成,内存带宽利用率大幅提升,训练速度自然变快。
2. 选择性重计算:“不占多余停车场,还不影响通行”
训练大模型时,中间结果会占用大量GPU内存。mHC的做法是:只保存最关键的中间结果(比如每块图层的第一个输入),其他结果在反向传播时再实时计算。这样一来,GPU内存占用大幅减少,不用额外升级硬件就能支持更大模型。
3. 通信重叠:“一边修路,一边通车”
大规模分布式训练时,数据在不同设备间传输会浪费大量时间(比如A设备等B设备的数据,才能继续计算)。mHC优化了DualPipe调度策略,让数据传输和计算同时进行:比如在传输数据的同时,执行前馈网络的计算任务,彻底消除“等待时间”,提升整体吞吐量。
6 用数据说话:mHC的实验结果到底有多能打?
核心结论很直接:mHC在稳定性、性能、可扩展性上全面碾压HC和传统基线,还只多了6.7%的训练开销。
一、实验怎么设?覆盖“大小模型+多少数据”全场景
为了让结论有说服力,研究团队设计了全面的实验方案,避免“只在小模型上有效”的局限:
-
模型规模:覆盖3B、9B、27B三个参数级别,重点验证27B大模型(最能暴露训练稳定性问题);
-
数据场景:分两种情况——一是“模型+数据按比例缩放”(比如3B配39.3B tokens,27B配262B tokens),二是“固定模型测数据上限”(3B模型训练1.05T tokens,看长期训练效果);
-
关键参数:HC和mHC的扩展率n都设为4(行业常用值),统一基于DeepSeek-V3的MoE架构,保证对比公平;
-
评测标准:既看训练过程的稳定性(loss、梯度范数),也看下游任务性能(8个主流benchmark,涵盖推理、阅读理解、数学题等)。
简单说,实验设计得“够全面、够严谨”,结果说服力拉满。
二、核心结果:稳得住、性能强,双杀基线和HC
针对HC的两大痛点(训练崩、性能有瓶颈),mHC给出了完美的解决方案:
1. 训练稳定性:从“中途翻车”到“全程稳跑”
27B大模型训练中,HC在12k步左右突然出现loss暴涨(直接崩溃),而mHC的loss全程平稳下降,最终比基线模型还低0.021;梯度范数(衡量训练稳定性的核心指标)更是和基线模型几乎重合,完全没有波动——相当于“HC跑一半就熄火,mHC却能匀速冲线”。
2. 下游性能:全面超越,推理能力尤为突出
在8个主流任务中,mHC表现如下:
-
碾压基线:所有任务都比传统残差连接模型强,MMLU(知识问答)从59.0%涨到63.4%,GSM8K(数学题)从46.7%涨到53.8%;
-
超越HC:除了MATH(数学竞赛题)基本持平,其他任务都更优,尤其是推理类任务——BBH(复杂推理)提升2.1%,DROP(阅读理解)提升2.3%,这说明mHC的“信息融合”更高效,模型理解和推理能力更强。
三、缩放实验:模型越大、数据越多,优势越明显
大模型的核心需求是“可扩展”——能从小模型平滑升级到超大模型,数据喂得越多性能越好。mHC在这方面表现拉满:
-
模型缩放(3B→9B→27B):随着参数和计算量增加,mHC的性能优势没有衰减,反而保持稳定——27B模型的效果提升和3B、9B一致,说明它能支撑超大模型训练;
-
数据缩放(3B模型从39.3B→1.05T tokens):训练 tokens 增加到原来的26倍,mHC的loss依然持续下降,没有出现“数据喂饱后性能停滞”的问题,长期训练稳定性极强。
这意味着mHC不仅能适配“小模型快速迭代”,还能支撑“千亿级大模型规模化训练”,实用性拉满。
四、稳定性深挖:信号放大从3000倍降到1.6倍
为了搞清楚mHC为什么稳,研究团队还做了深层分析:
-
HC的问题:单层映射的信号放大倍数就不稳定,多层叠加后更是失控,复合映射的“最大绝对增益”峰值高达3000——相当于信号被放大3000倍,模型根本扛不住;
-
mHC的解决方案:通过双随机矩阵约束,单层映射的信号增益接近1,多层叠加后最大也才1.6,足足降低了三个数量级;而且所有传播路径的增益都很均匀,没有“局部失控”的情况——相当于“给信号装了精准限速器,不管传多少层都不超速”。
从矩阵可视化结果也能看出来:HC的映射矩阵数值波动极大,而mHC的矩阵每行每列和都接近1,分布均匀,信息传播稳定可控。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)